第一步:收集相关参数
首先,我们打开飞书开放平台的开发文档,链接地址是 https://open.feishu.cn/document/server-docs/docs/bitable-v1/notification
我们清楚我们的目的是读取数据而已,所以我们直奔主题。
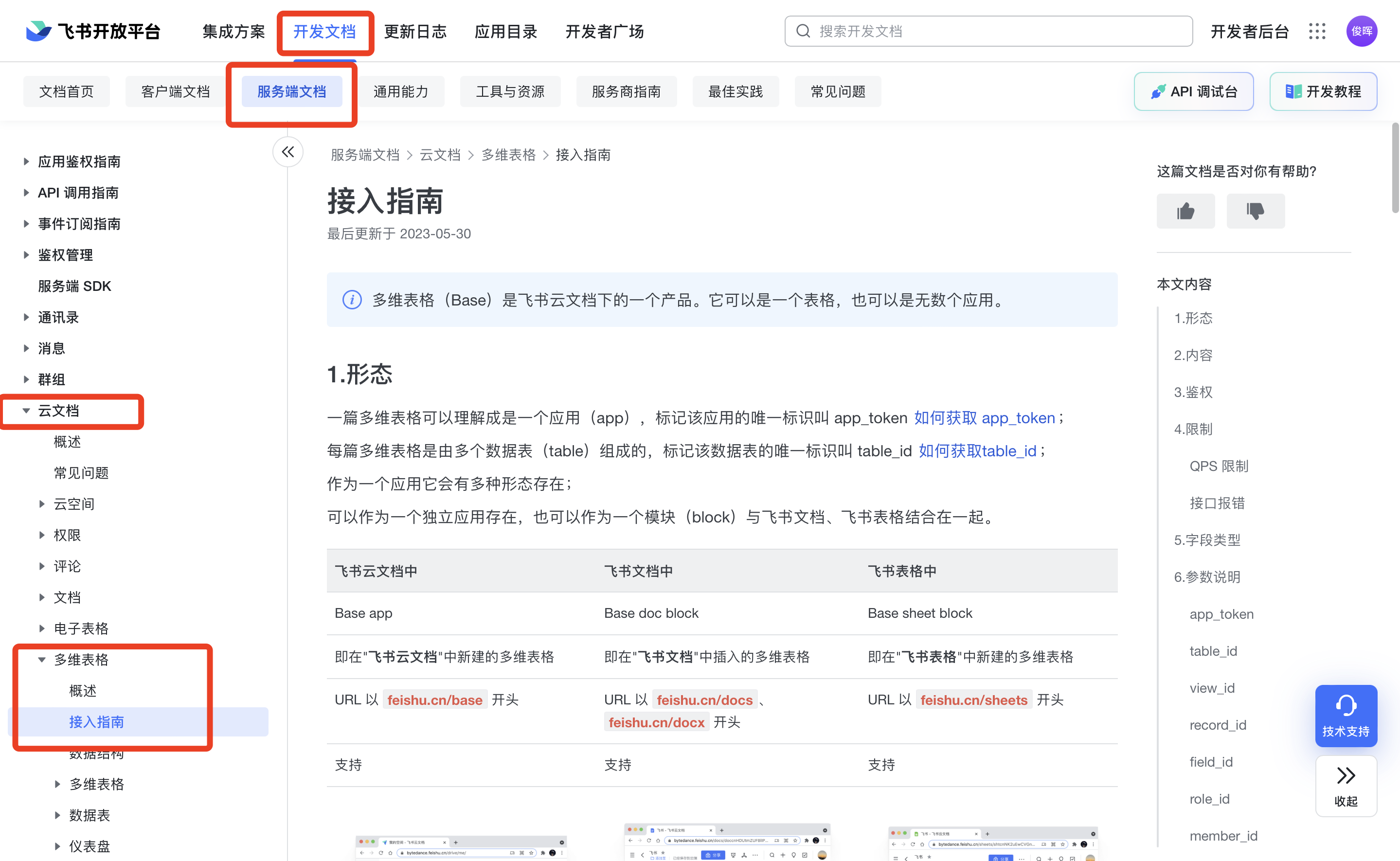
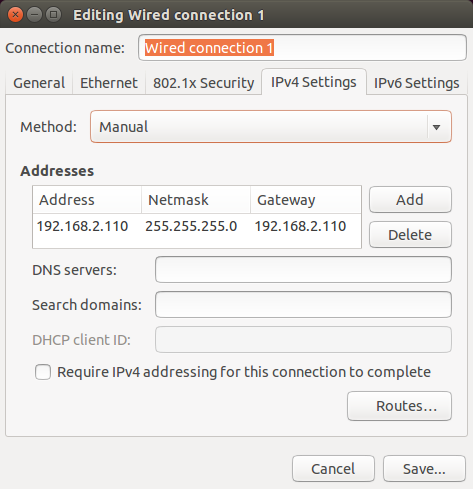
获得API的链接及另外2个参数
阅读本页的文档可知,我们要获取多维表格的数据,是需要通过访问这个链接:

https://open.feishu.cn/open-apis/bitable/v1/apps/:app_token/tables/:table_id/records/:record_id
而这里面的:app_token、:table_id 需要换成我们自己的内容。
这两个内容的获取方法如下图:


寻找获得token所需要参数
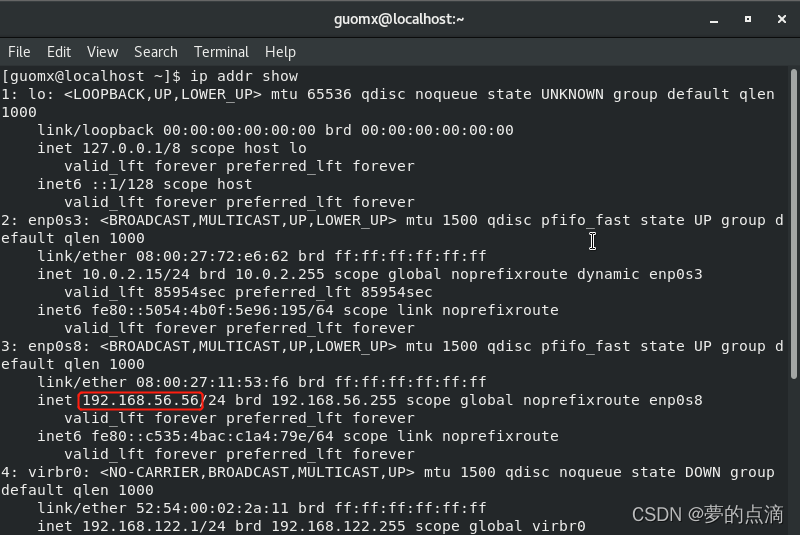
阅读第3部分可知,除了以上参数外,我们还需一个user_access_token或者tenant_access_token。
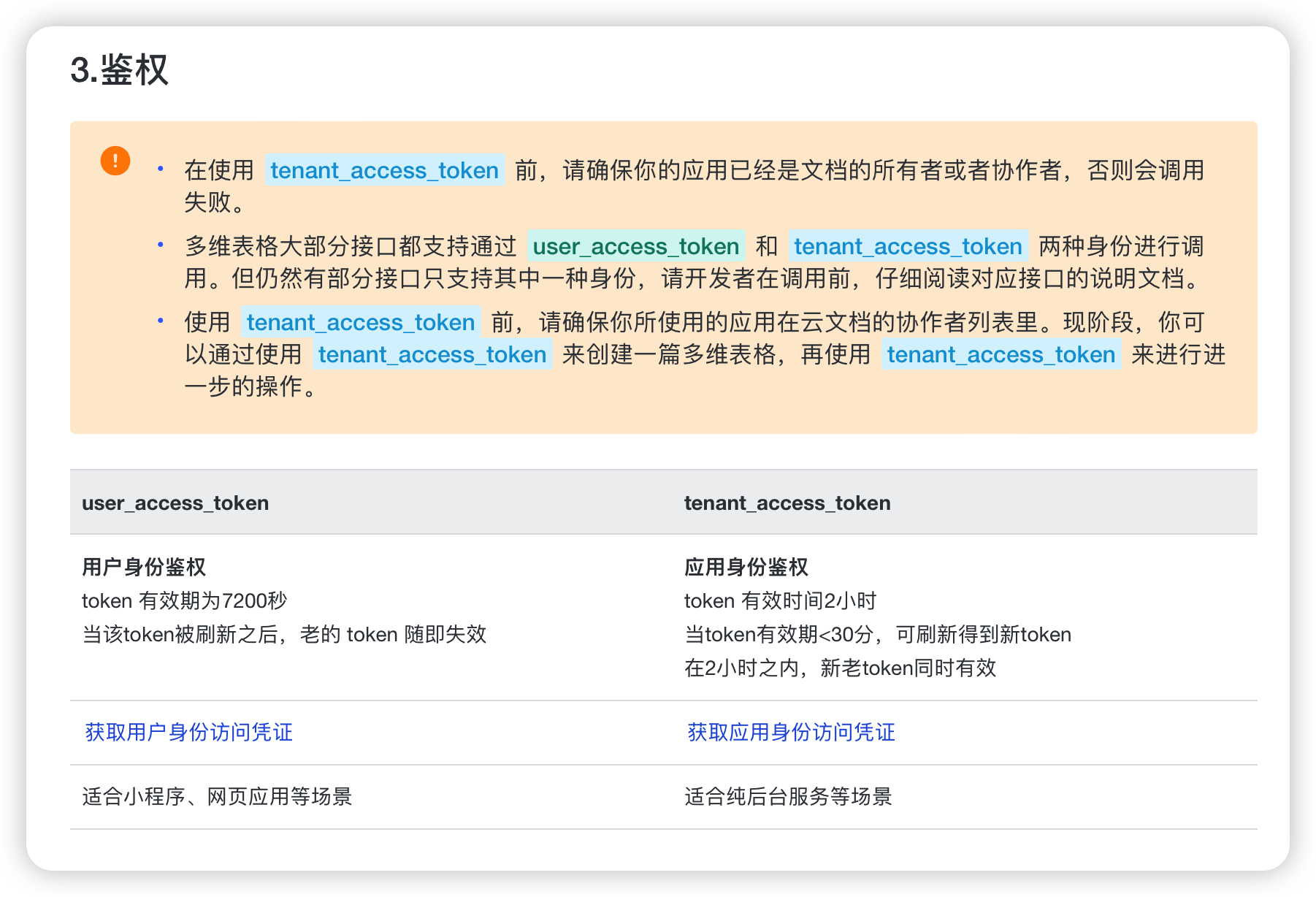
token就是访问凭证,上图给我们提供了两个链接获取用户身份访问凭证和获取应用身份访问凭证。
我们先点开获取用户身份访问凭证看看。
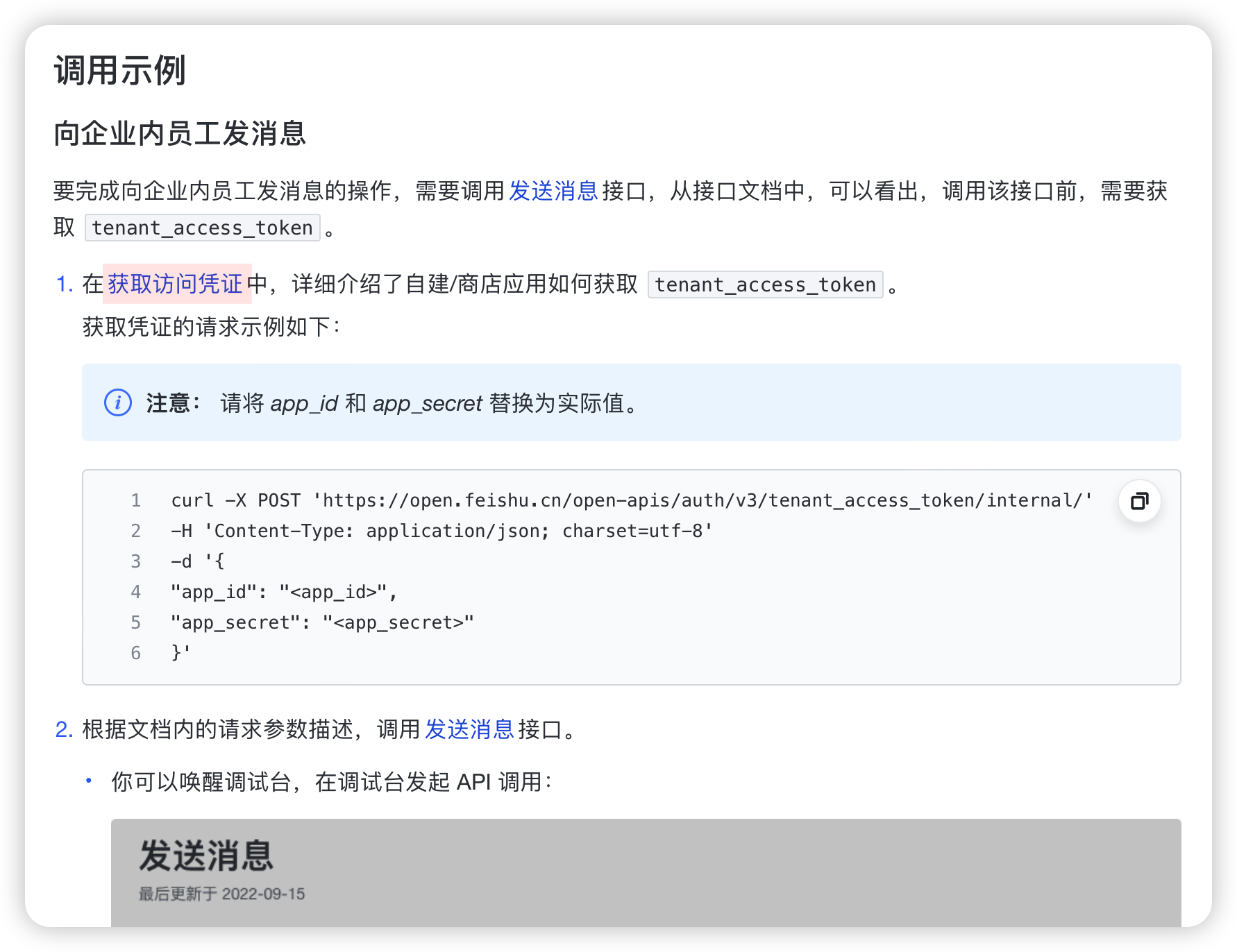
好吧,这些内容我也看不懂,好在我看到了个获取访问凭证,那就点开来看一看吧。
嗯,它的第3部分讲得还是很明白的。我们就参着它说的试试吧。也就是登录、创建、获取。
于是,我们先点击进入开发者后台
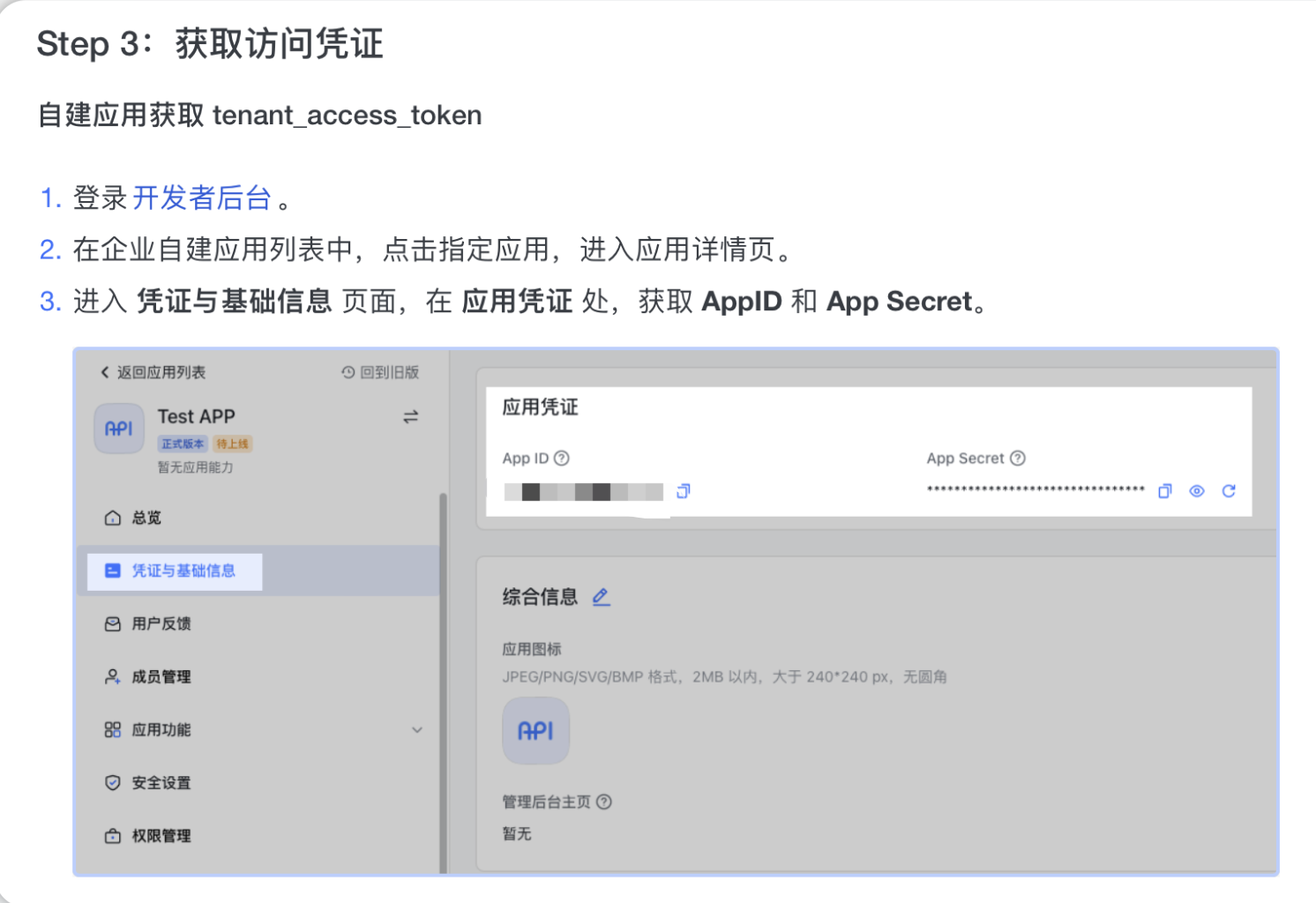
照着文档所教的,点创建企业自建应用,创建一个自己的应用。
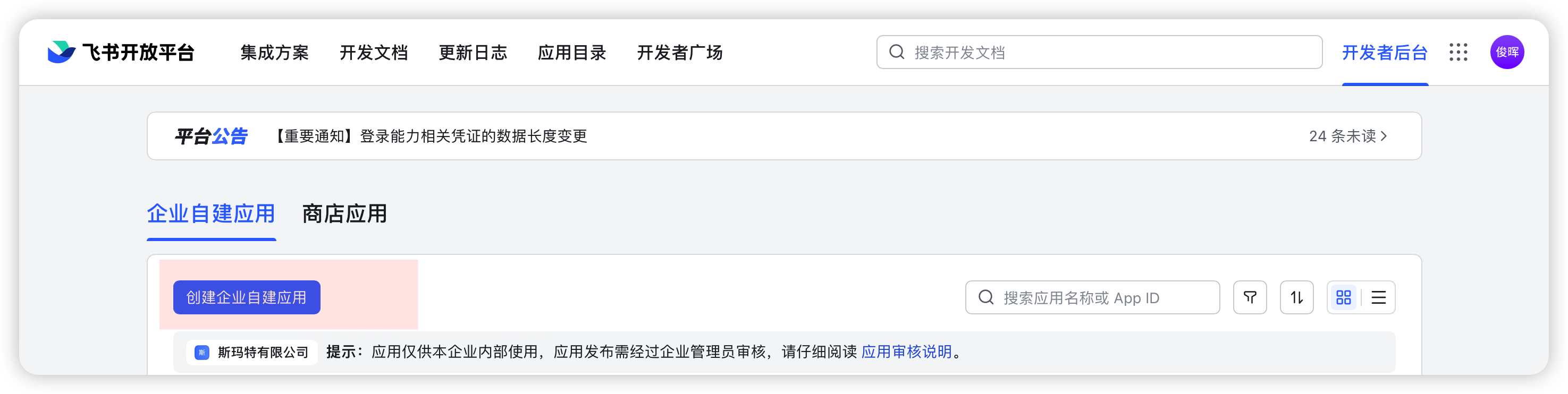
点击这个应用,进入这个应用设置中心。在凭证与基础信息中获得我们要的
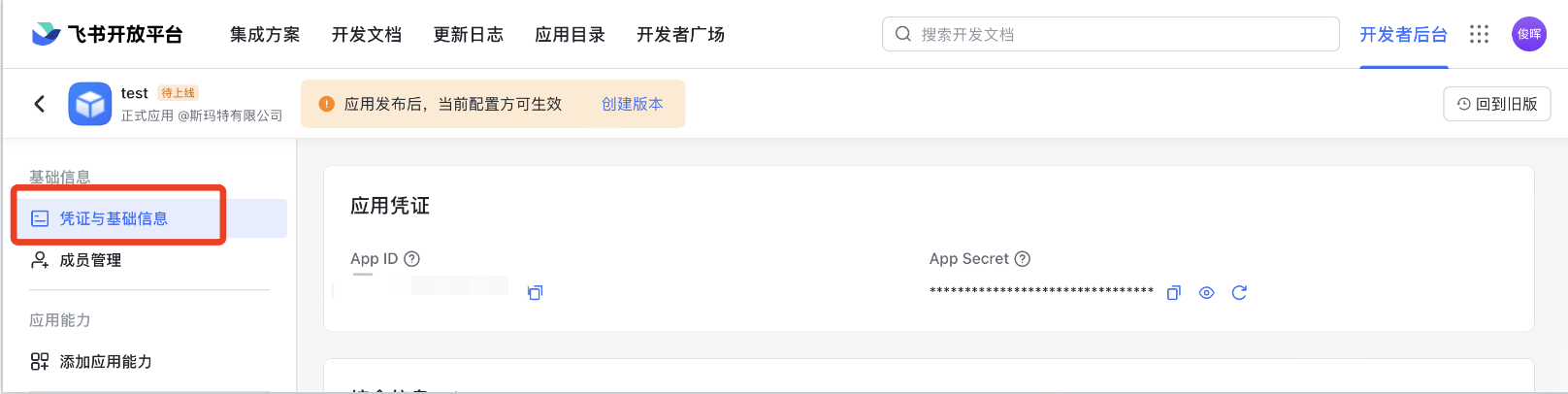
比如,笔者的这个App ID是“***************************”,App Secret是“***************************”
找到使用App ID和App Secret获取token的方法
接下来,我们就是要用App ID和App Secret去获取我们的tenant_access_token。
在鉴权管理下我们可以找到获取tenant_access_token的方法,如下图所示
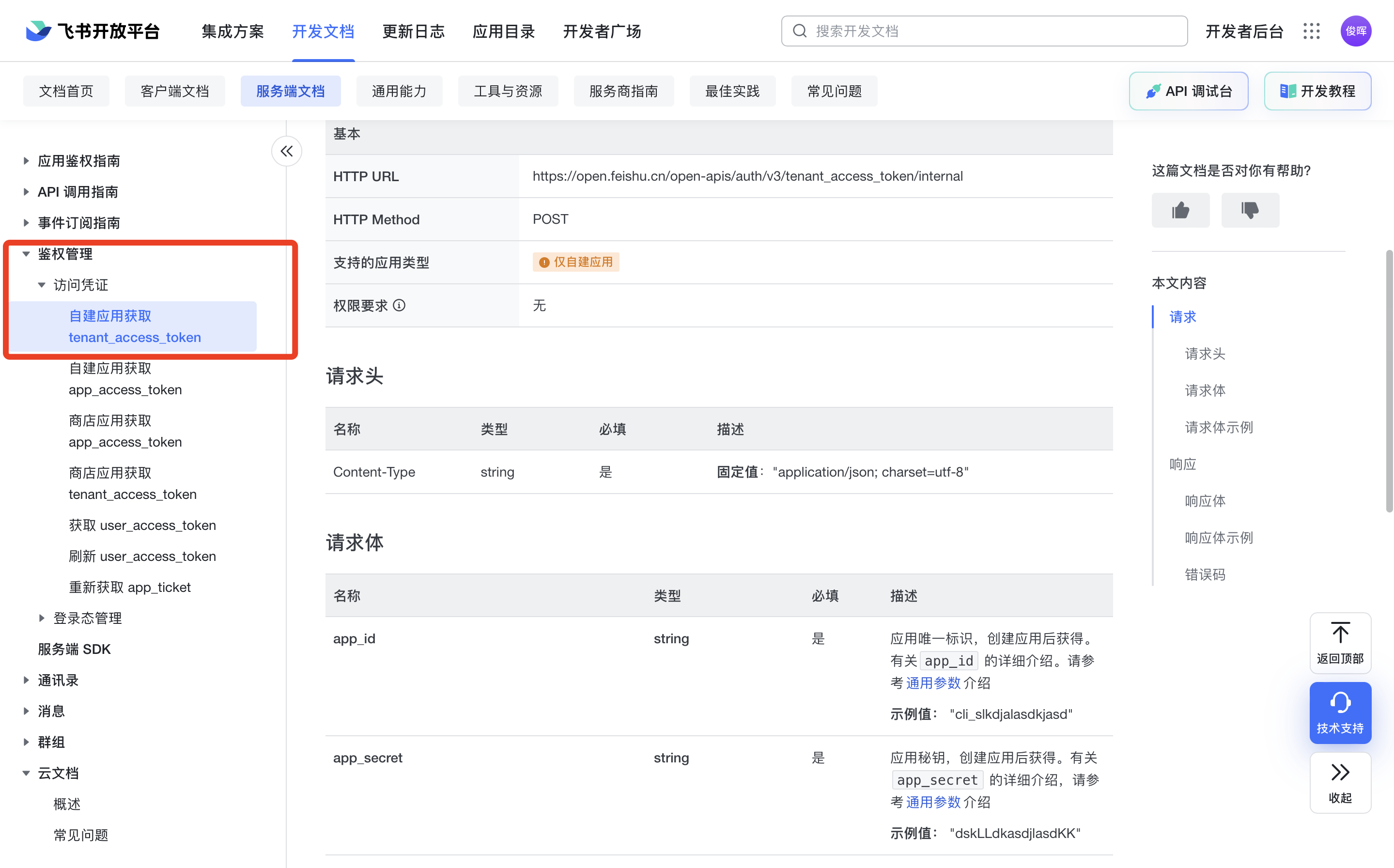
阅读文档可知,我们要使用POST方法向https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal这个链接发一个请求。
headers为:
headers={"Content-Type":"application/json; charset=utf-8"
}
param为:
params={"app_id":"你的App ID","app_secret":"你们的App Sceret"
}
使用python编写爬虫
使用python获取token
至此,我们所需要参数都已集齐了。然而,我们不会写python爬虫,更不会使用M函数实现爬虫怎么办?
那就请教chatGPT吧!

给它发一个问题,它的回答如下图:
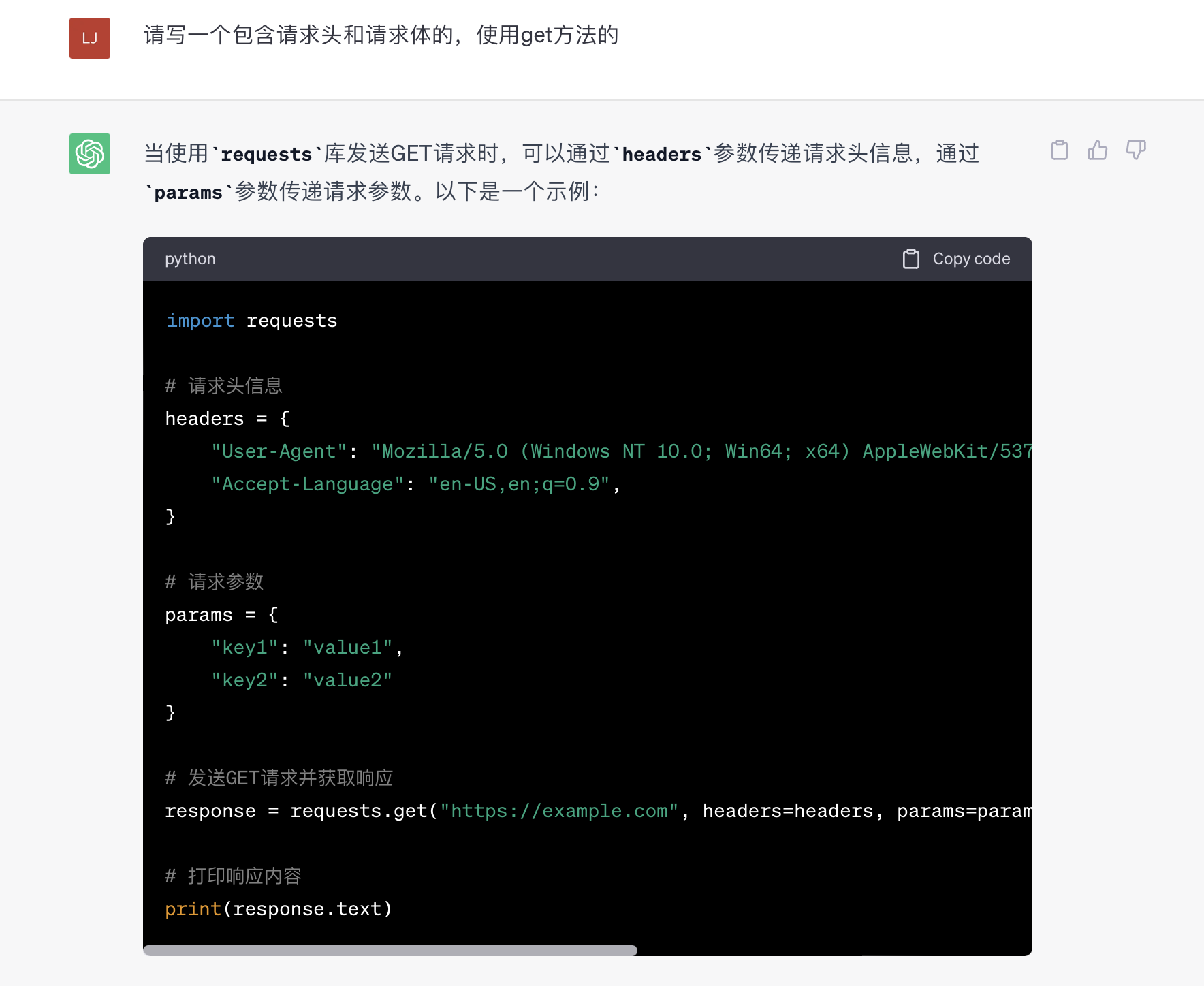
这是它给的代码
import requests# 请求头信息
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36","Accept-Language": "en-US,en;q=0.9",
}# 请求参数
params = {"key1": "value1","key2": "value2"
}# 发送GET请求并获取响应
response = requests.get("https://example.com", headers=headers, params=params)# 打印响应内容
print(response.text)我们更换一下url、headers和params。
import requests
import jsonheaders={"Content-Type":"application/json; charset=utf-8"
}
params={"app_id":"**************","app_secret":"**********************"
}
response = requests.post("https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal", headers=headers, params=params)
token=json.loads(response.text)['tenant_access_token']
print(token)
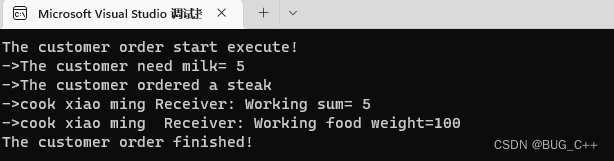
打开vs code尝试运行一下,没有问题,能正确获得token。
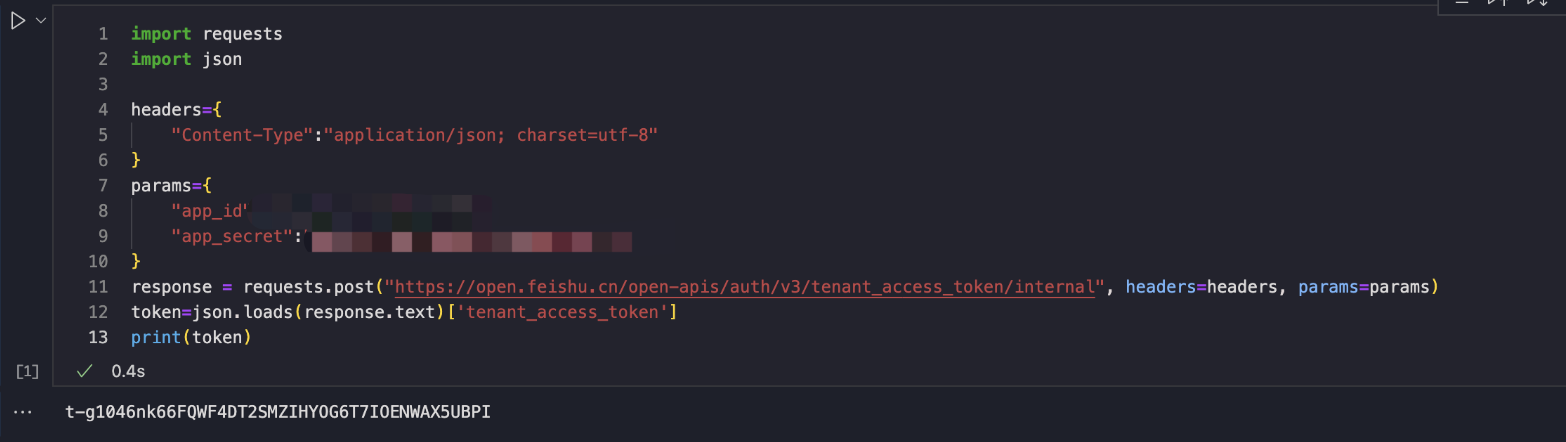
使用python获取表格中的数据
依样画葫芦,我们再增加一些代码,使它在获取到token之后,使用该token,去获取表格数据。
import requests
import jsonheaders={"Content-Type":"application/json; charset=utf-8"
}
params={"app_id":"************************","app_secret":"**********************"
}
response = requests.post("https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal", headers=headers, params=params)
token=json.loads(response.text)['tenant_access_token']app_token="**************************"
table_id="************************"
url=f"https://open.feishu.cn/open-apis/bitable/v1/apps/{app_token}/tables/{table_id}/records"
headers={"Authorization":"Bearer "+token
}
res = requests.get(url, headers=headers)
print(res.text)
运行它之后,得到这样一个错误提示:

不知道它是什么意思。没关系,我们问chatGPT。
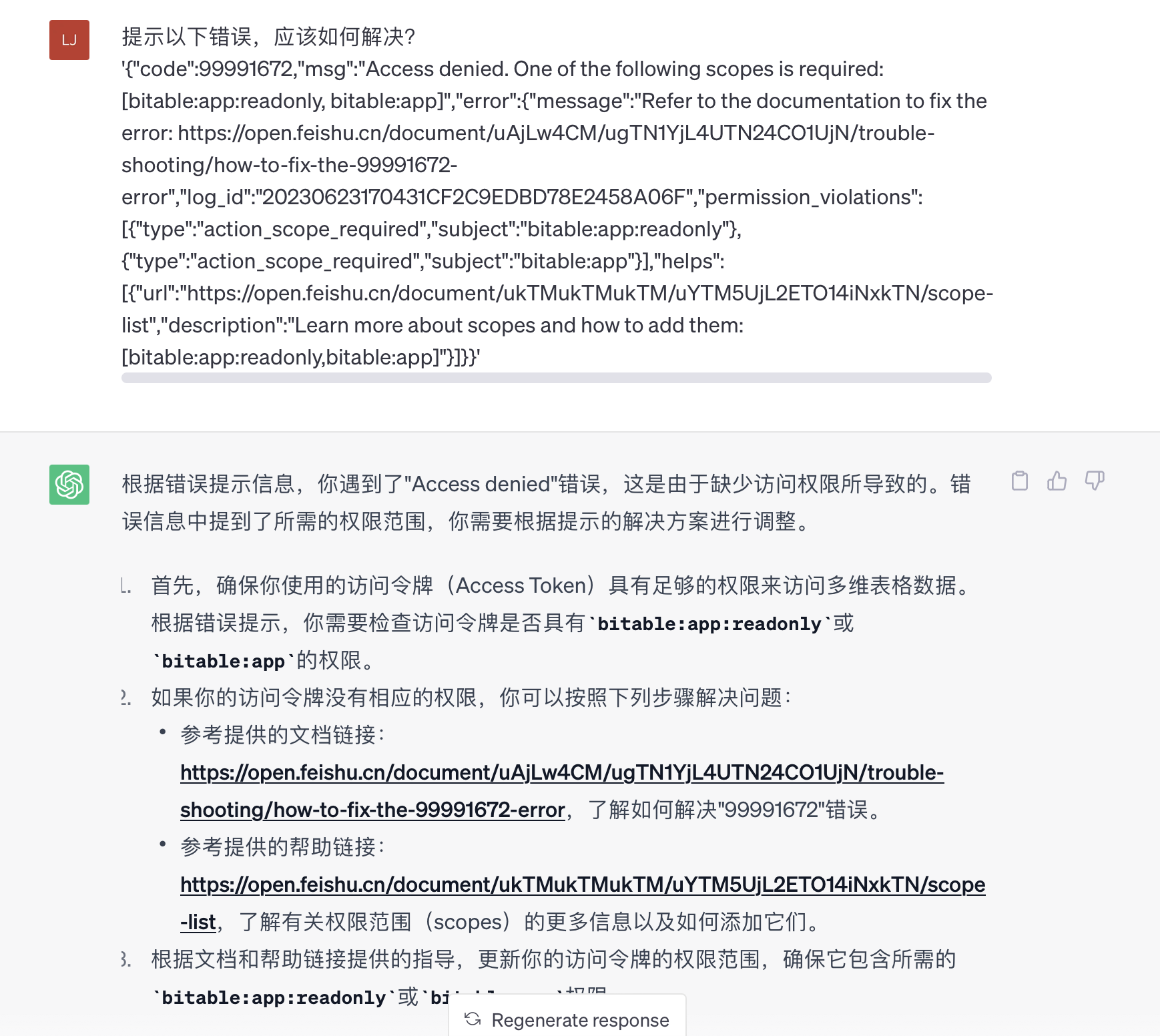
很清楚了,我们需要bitable:app:readonly或bitable:app的权限。
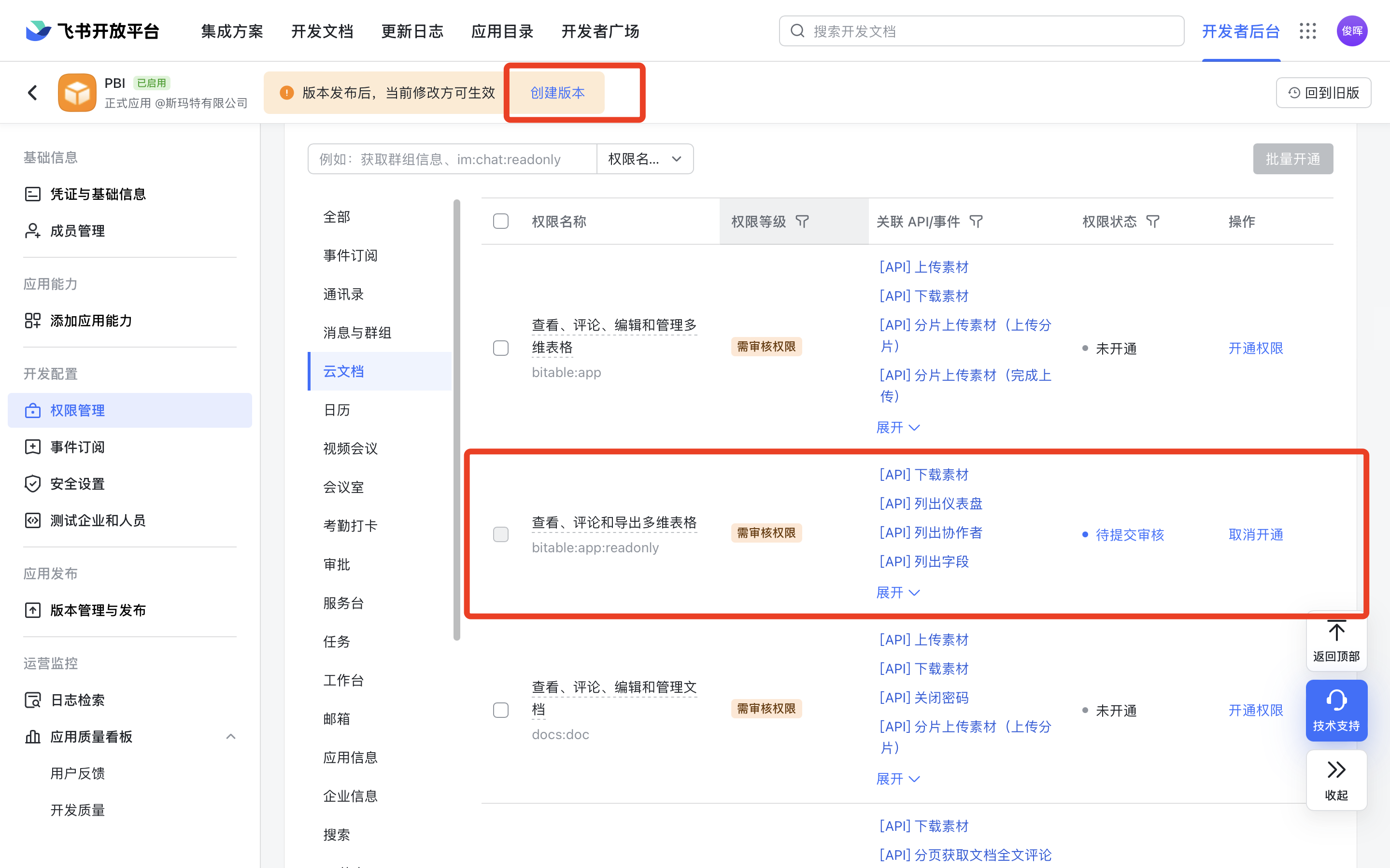
设置一下个人应用的权限
回到我们的应用中心,就是前面获得App ID和App Secret的地方。到权限管理菜单里申请一下权限,并创建版本。
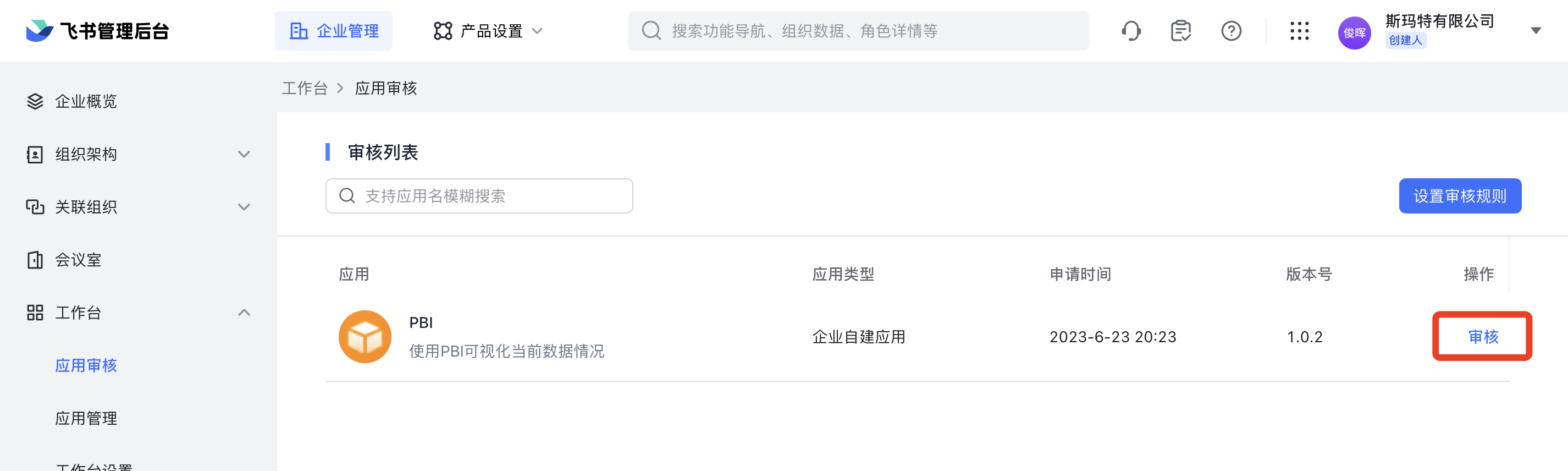
再进我们的飞书管理台后(https://r0kc290lpx2.feishu.cn/admin/) 审核一下。记得点完审核,还要再点一下通过。
再运行一下我们的python脚本,已经可以正确得获取到一串json文本了。
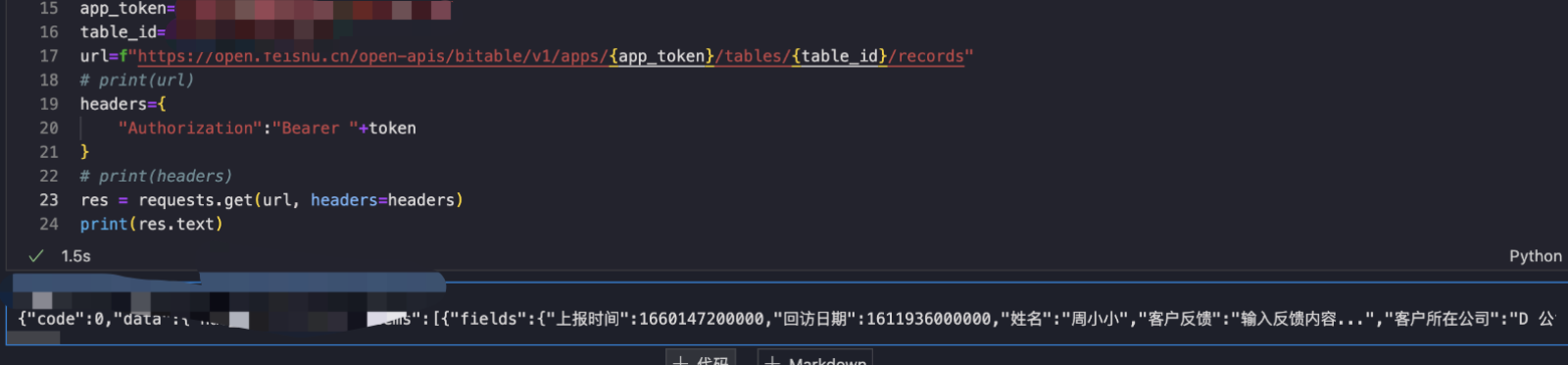
使用将python爬虫转化为Power Query中的M语言
到现在为止,我们已经可以用python来获取飞书的数据了。可是,我们在Power BI中用M语言更便利,怎么把它转成M语言呢?还是问我们的chatGPT吧。
直接问它提问。

它给我们如下回答:
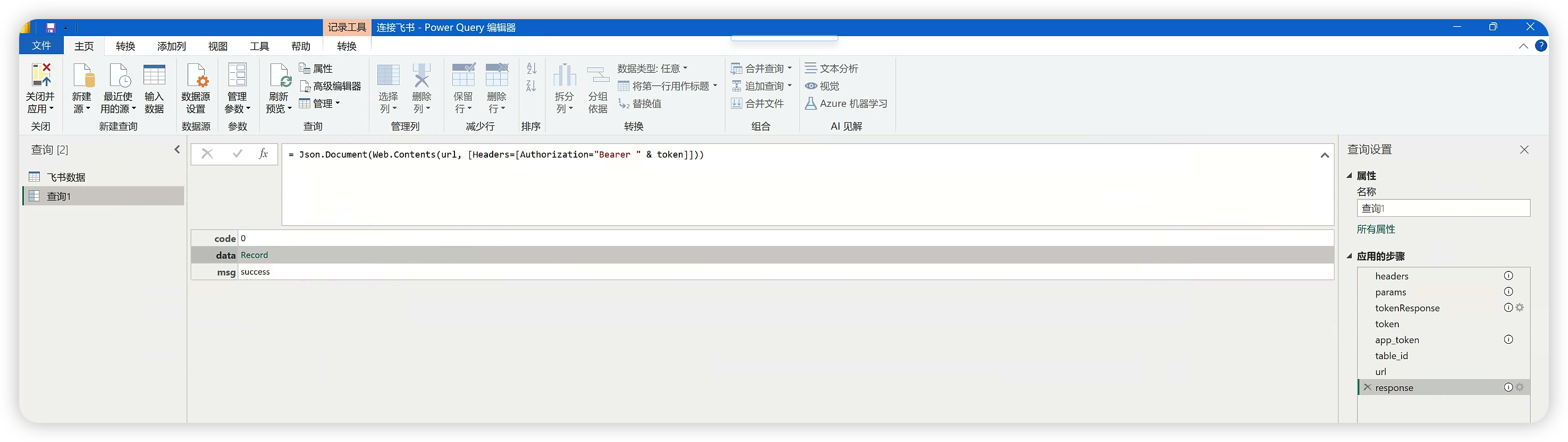
let// 定义请求头headers = [#"Content-Type"="application/json; charset=utf-8"],// 定义请求参数params = [app_id = "************************",app_secret = "******************************"],// 发送POST请求获取访问令牌tokenResponse = Json.Document(Web.Contents("https://open.feishu.cn/open-apis/auth/v3/tenant_access_token/internal", [Headers=headers, Query=params])),token = tokenResponse[tenant_access_token],// 定义API请求URL和参数app_token = "********************",table_id = "********************",url = "https://open.feishu.cn/open-apis/bitable/v1/apps/" & app_token & "/tables/" & table_id & "/records",// 发送GET请求获取数据response = Json.Document(Web.Contents(url, [Headers=[Authorization="Bearer " & token]])),data = response[records]
indata
把它贴进Power BI中试一下,发现报错了。

从上往下一步步检查,发现第三步,发get请求获取token那一步报错了。是请求体写错了,我们自己改一下就好了。
把Query=params,改成Content=Json.FromValue(params)就OK了。再把最后一步删除,我们就可以看到,PQ可以正确得抓取到Json数据了。
最后的将Json转化为表格的步骤,不再赘述。感兴趣的小伙伴直接下载附件文件来看吧。
注意事项:
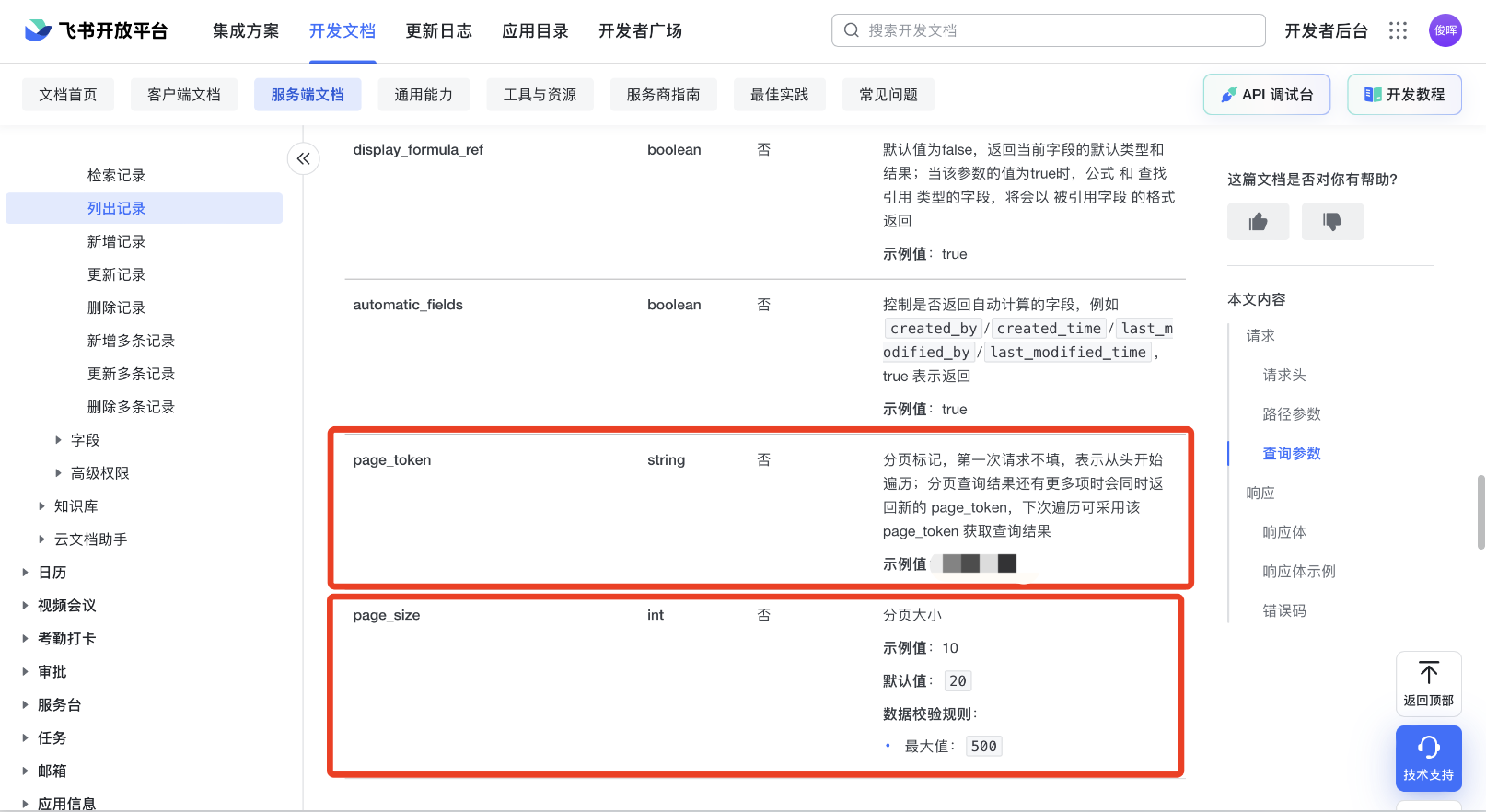
使用以上方法,一次只能获取最前面的500行记录。如果你的数据大于500行的话,需要使用到前一次访问获得page_token参数,在下一次访问时填入,以获得接下去的500行数据。此访问,每秒钟最多20次,也就是1万行记录。具体做法,下回分解。
附件下载
链接:百度网盘