为什么要学习Git
为什么要学习Git软件
为什么学习 因为在主流开发中,基于互联网软件开发的项目都会使用Git软件来进行项目开发过程中的资源管理
比如人力资源
代码资源 比如前端资源 .html .java等代码资源
文档资源 像项目开发中涉及到的需求文档等
这种项目中管理资源的软件被称为(软件配置管理)SCM软件
软件配置管理(SCM)是指通过执行版本控制、变更控制的规程,以及使用合适的配置管理软件,来保证所有配置项的完整性和可跟踪性。配置管理是对工作成果的一种有效保护。
SCM(Software Configuration Management,软件配置管理)是一种标识、组织和控制修改的技术。它应用于整个软件生存周期。作为评价一个大中型软件开发过程是否正确,合理,有效的重要手段,
为什么要学习Git软件
那么多软件,为什么要学Git
常见的SCM软件
左边的软件都需要中央服务器,如果中央服务器损坏,那么项目的资源就会可能丢失,我们的Git就没这种问题
Git软件比Subversion、CVS、Perforce和ClearCase等SCM(Software Configuration Management软件配置管理)工具具有性价比更高的本地分支、方便的暂存区域和多个工作
Git免费开源
Git基础概念
Git是一个免费的,开源的分布式版本控制软件系统,学习Git软件的具体操作前,我们需要对一些基础的概念和名词进行解释
2.版本控制
2.1什么是版本
软件版本
- 比如JDK1.8 JDK17 JDK20
- MYSQL5.7 MYSQL8.0
- IDEA2022 IDEA2023
- 这些数字都是软件的版本号
文件版本
- 保存重要的历史记录
- 能够实现恢复数据的功能
2.2 版本控制的基础功能
- 保存和管理文件
- 提供客户端功能进行访问

- 提供不同版本文件的比对功能
没有进行版本控制或者版本控制本身缺乏正确的流程管理,在软件开发过程中将会引入很多问题,如软件代码的一致性、软件内容的冗余、软件过程的事物性、软件开发过程中的并发性、软件源代码的安全性,以及软件的整合等问题。
3.集中式、分布式版本控制的区别
3.1集中式版本控制

多个用户同时改写了同一个文件,导致文件内容被覆盖,也就是文件冲突问题
1. VSS解决方法 可以通过给文件加锁,限定用户进行修改来解决
- 比如用户1拿了一个文件,要进行修改,就给这个文件加锁,其他用户可以下载,但是不能修改,当用户1修改好了这个文件并上传,其他用户重新下载到本地,这时候才能进行修改文件
- 但是这样存在缺陷,不同的用户只能串行的进行修改文件
2. CVS SVN的解决方法:一个文件的部分用来以一个用户的修改为准
3.2分布式版本控制

1.Git工作区域
Git软件为了更方便地对文件进行版本控制,根据功能得不同划分了三个区域

- 存储区域:Git软件用于存储资源得区域。一般指得就是.git文件夹
- 工作区域:Git软件对外提供资源得区域,此区域可人工对资源进行处理。
- 暂存区:Git用于比对存储区域和工作区域得区域。Git根据对比得结果,可以对不同状态得文件执行操作。
我们的本地仓库指的就是存储区域,我们commit就是将工作区的修改提交到我们的本地仓库,而我们的暂存区的作用就是对比工作区和存储区域的不同

2.Git分支
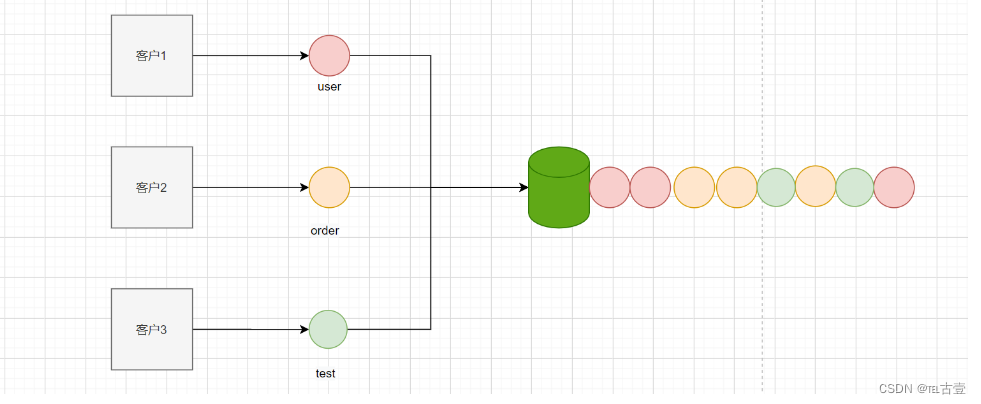
如果我们每个用户负责一个模块,直接提交给版本库带来的问题
- 历史提交记录中没有规律可言,非常乱
- 这样频繁的修改会导致大量的版本信息,会导致仓库更大
- 这样频繁的修改会引起大量的文件冲突
如果所有的操作都是基于一条主线完成的。就好比,咱们学习的时候,记学习笔记,今天学点,那么就写一点,明天学点,再写一点,最后,完全学完了,这个笔记也就记全了。但实际上,有些文件可能在不同的场合需要同时使用不同的内容,而且还不能冲突,比如项目的配置文件,我需要本地进行测试,同时还要部署到服务器上进行测试。本地和服务器上的环境是不一样的,所以同一个配置文件就需要根据环境的不同,进行不同的修改。本地环境没问题了,修改配置文件,提交到服务器上进行测试,如果测试有问题,再修改为本地环境,重新测试,没问题了,再修改为服务器配置,然后提交到服务器上进行测试。依次类推,形成迭代式开发测试。
从上面的描述上看,就会显得非常繁琐,而且本质上并没有太重要的内容,仅仅是因为环境上的变化,就需要重新修改,所以如果将本地测试环境和服务器测试环境区分开,分别进行文件版本维护,是不是就会显得更合理一些。这个操作,在Git软件中,我们称之为branch,分支。
这里的分支感觉上就是树上的分叉一样,会按照不同的路线生长下去。有可能以后不再相交,当然,也可能以后会不断地纠缠下去,都是有可能的。
3.引入分支之后



- 给我们的每个用户都分配一个备份的版本库,每个备份的版本库就是一个分支,我们经理的分支就是main
- 这里的分支原理,我们只是方便理解,其真正的实现并不是这样,在后面的版本号会详解解析
4.利用GithupDeskTop测试分支

5.主干分支
- 默认情况下,Git软件就存在分支的概念,而且就是一个分支,称之为master分支,也称之为主干分支。
- 这就意味着,所有文件的版本管理操作都是在master这一个分支路线上进行完成的。
- 不过奇怪的是,为什么之前的操作没有体现这个概念呢,那是因为,默认的所有操作本身就都是基于master分支完成的。而master主干分支在创建版本库时,也就是git init时默认就会创建。
6.其他分支
就像之前说的,如果仅仅是一个分支,在某些情况并不能满足实际的需求,那么就需要创建多个不同的分支。(分支导致命名冲突问题,可以进行编辑删除一些,但是会导致内容合并)
7.Git合并
无论我们创建多少个分支,都是因为我们需要在不同的工作环境中进行工作,但是,最后都应该将所有的分支合在一起。形成一个整体。作为项目的最终结果。
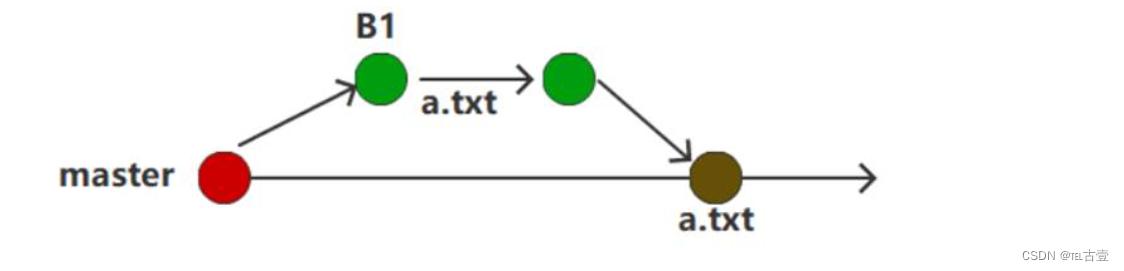
4.版本号
1.什么是版本号

-
每次提交都会生成一个版本号,这个版本号是一个40位的16进制长度的数字字符串
-
为什么git软件产生的版本号这么长,git尝试的版本号是根据我们当前提交内容利用SHA-1加密算法得出,所以重复的概率很小(由40个16进制组成的版本号)
- 为什么需要保证重复的几率很小——Git是分布式版本控制软件系统,所以我们的版本库可能不止一个,而且会涉及到版本库的合并,所以我们的版本号重复会出现问题

- 根据版本号定位到仓库中的文件 2+38(前两位是文件夹,后38位的文件名)
- 在存储区中查找,也就是.git/objects

2.文件操作对应的版本号
这里的演示是连续的操作初始化—添加文件—修改文件—
3.初始化仓库对应版本号
git cat-file - 版本号 友好查看文件




100 表示一个普通文件 644表示文件权限 blob表示当前普通文件对象 后面字符串是个版本号

- 一次初始化创建了两个文件.gitattributesh和README.md文件(可选),且创建了多个版本号,一个版本
4.添加一个文件对应版本号

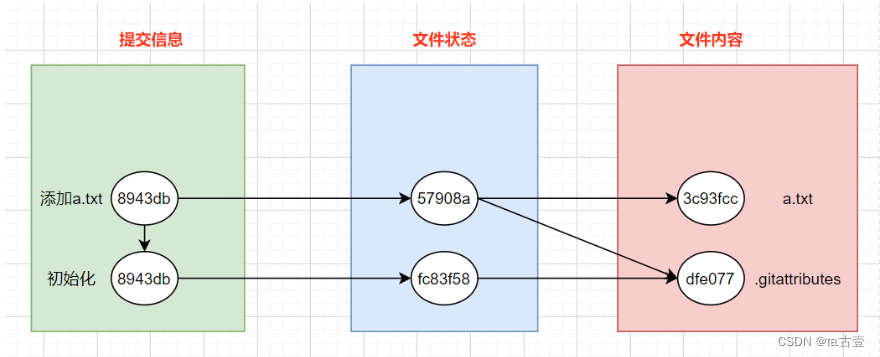
- 我们的添加操作对应的提交信息中有指向上一次操作对应提交信息的文件 也就是对应parent的值
- 我们的文件状态文件会指向我们的新添加的a.txt。也会指向我们初始化操作添加的文件
5.修改文件对应的版本号


- 修改操作对应的版本的提交信息的文件中的parent指向上一次添加a.txt的操作的提交信息文件
- 对应版本的文件状态文件中会指向修改后的a.txt文件,也会指向我们初始化操作添加的文件
6.删除文件对应的版本信息


- 删除操作对应的版本的提交信息的文件中的parent指向上一次修改a.txt的操作的提交信息文件
- 对应删除操作的文件状态信息中只有指向初始化添加的文件,没有a.txt文件了
7.分支操作对应的原理
根据上面的图进行解释
8.认识两个文件

- 我们发现main文件下的内容就是我们上述操作中的最后一步操作,删除a.txt文件的提交信息文件的版本号

- HEAD就表示当前我们的分支是哪个,然后通过分支对应的文件指向对应的操作,来知道当前分支的操作最新操作是什么
9. 我们添加一个分支并切换该分支

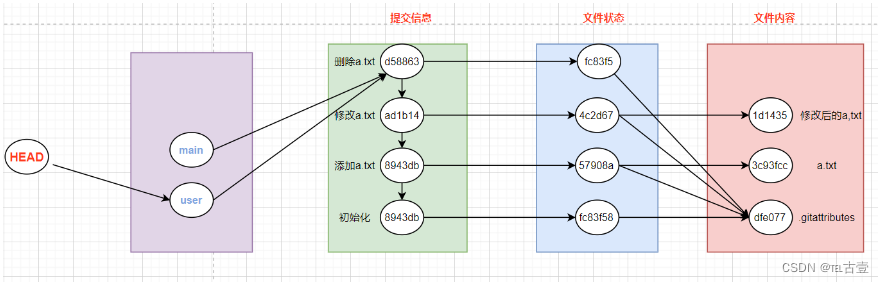
- 我们发现切换分支,我们的HEAD的文件中的内容就改变了
- 所以我们Git中就是通过heads文件下文件中内容指向不同版本的提交信息文件来实现分支的功能
10.命令行操作
Git软件是免费、开源的。最初Git软件是为辅助 Linux 内核开发的一套软件,所以在使用时,简单常用的linux系统操作指令是可以直接使用的