一、按钮点击
具体网页信息如下:

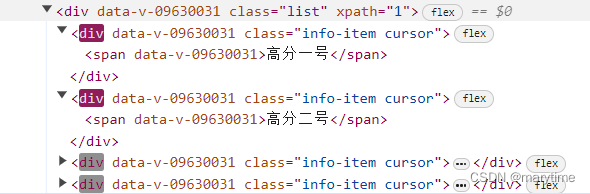
定位的时候driver.find_element(By.CLASS_NAME, 方法搞不定。
定位方法:
方法一:通过文本定位
driver.find_element(By.XPATH, "//*[text()='高分一号']").click()
time.sleep(3)如果是部分文字
#部分文字python:browser.find_element_by_xpath("//*[contains(text(),'一号')]").click()方法二:使用JS脚步,通过类名来定位
因为一共有7个,写了个循环,
for i in range(7):name='info-item cursor'js="document.getElementsByClassName('info-item cursor')[{}].click();".format(i)driver.execute_script(js);注意一些按钮点击后需要回到上一步再次点击。用相同的方法点击上一层按钮即可。
二、图片定位并下载保存
网页信息如下:
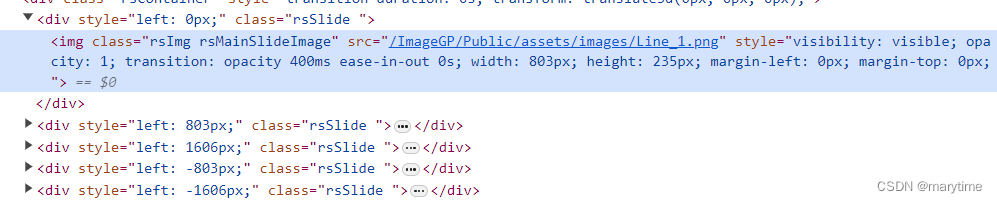
定位方法:
使用标签tag=img查找到元素,用requests库下载图片
driver=get_url(url)就是对获取网页这一功能做一个封装,形成一个单独的函数方便使用。
def get_url(url):chrome_options = Options().add_argument("start-maximized")service = Service(executable_path=r"C:\Users\***\PycharmProjects\chromedriver\chromedriver-win64\chromedriver.exe")#chromedriver.exe的位置driver = webdriver.Chrome(service=service, options=chrome_options)driver.get(url)return driverdef img_extr1_ImageGP():#按标签tag来检索图片,并且保存url_str2 = 'https://www.bic.ac.cn/ImageGP/index.php/Home/Index/Lineplot.html'driver = get_url(url_str2)images = driver.find_elements(By.TAG_NAME, "img")#使用标签tag=img进行查找print(images)i=13for image in images:image_url = image.get_attribute("src")print(image_url)# 这里可以使用Python的requests库或其他下载工具来下载图片img_data = requests.get(image_url).contentwith open("./{}.jpg".format(i), 'wb') as fp:fp.write(img_data)i=i+1# 关闭浏览器driver.quit()三、网页截图,分别保存和拼接
代码如下:
def test_screen_shot1(driver,img_id):#拼接图片
def test_screen_shot2(driver,image_id):#不拼接
函数使用的参数分别为:
driver=get_url(url)上方代码中有该函数。就是对获取网页这一功能做一个封装,形成一个单独的函数方便使用。
img_id是图片编号的起始序号
def test_screen_shot1(driver,img_id):#拼接图片width = driver.execute_script("return document.documentElement.scrollWidth")page_height = driver.execute_script("return document.documentElement.scrollHeight")window_height = driver.get_window_size()['height']# 获取页面宽度及其宽度print(width, page_height, window_height)i = img_iddriver.save_screenshot('{}.png'.format(i))if page_height > window_height:n = page_height // window_height # 需要滚动的次数base_mat = np.atleast_2d(Image.open('{}.png'.format(i))) # 打开截图并转为二维矩阵i=i+1for j in range(n):driver.execute_script(f'document.documentElement.scrollTop={window_height * (j + 1)};')time.sleep(.5)driver.save_screenshot(f'{j+i}.png') # 保存截图mat = np.atleast_2d(Image.open(f'{j+i}.png')) # 打开截图并转为二维矩阵base_mat = np.append(base_mat, mat, axis=0) # 拼接图片的二维矩阵Image.fromarray(base_mat).save('{}.png'.format(n+img_id))# 截图并关掉浏览器# driver.get_screenshot_as_file('{}.png'.format(i))def test_screen_shot2(driver,image_id):#不拼接driver.implicitly_wait(10)driver.set_page_load_timeout(6)# 获取网页高度body_height = driver.execute_script('return document.body.scrollHeight;')window_height = driver.execute_script('return window.innerHeight;')js = "window.scroll(0,arguments[0]*arguments[1])"print(body_height,window_height)i = 0driver.get_screenshot_as_file(f"{i+image_id}.png")while i * window_height < body_height:driver.execute_script(js, window_height, i)time.sleep(5)driver.get_screenshot_as_file(f"{i+image_id}.png")i += 1附录(本博客使用的头文件):
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from PIL import Image
import numpy as np
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import selenium.webdriver.support.ui as uiimport requests
![LeetCode[题解] 1261. 在受污染的二叉树中查找元素](https://img-blog.csdnimg.cn/img_convert/9f0b899745d6a3a7cddc13a738e5e4d9.jpeg)