原文:普林斯顿大学算法课程
译者:飞龙
协议:CC BY-NC-SA 4.0
4.2 有向图
原文:
algs4.cs.princeton.edu/42digraph译者:飞龙
协议:CC BY-NC-SA 4.0
有向图。
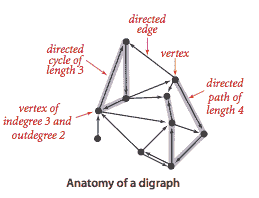
一个有向图(或有向图)是一组顶点和一组有向边,每条边连接一个有序对的顶点。我们说一条有向边从该对中的第一个顶点指向该对中的第二个顶点。对于 V 个顶点的图,我们使用名称 0 到 V-1 来表示顶点。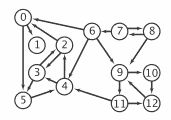
术语表。
这里是我们使用的一些定义。
-
自环 是连接顶点到自身的边。
-
如果两条边连接相同的顶点对,则它们是平行的。
-
一个顶点的outdegree是指指向它的边的数量。
-
一个顶点的indegree是指指向它的边的数量。
-
子图是构成有向图的一部分边(和相关顶点)的子集。
-
在有向图中,有向路径是一个顶点序列,其中每个顶点到其后继顶点有一条(有向)边,且没有重复的边。
-
一个有向路径是简单的,如果它没有重复的顶点。
-
一个有向循环是一条有向路径(至少有一条边),其第一个和最后一个顶点相同。
-
如果一个有向循环没有重复的顶点(除了第一个和最后一个顶点的必要重复),那么它是简单的。
-
一条路径或循环的长度是指它的边数。
-
我们说一个顶点
w是从顶点v可达的,如果存在一条从v到w的有向路径。 -
如果两个顶点
v和w是强连通的,那么它们是相互可达的:从v到w有一条有向路径,从w到v也有一条有向路径。 -
如果每个顶点到每个其他顶点都有一条有向路径,那么有向图是强连通的。
-
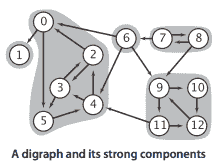
一个非强连通的有向图由一组强连通分量组成,这些分量是最大的强连通子图。
-
一个有向无环图(或 DAG)是一个没有有向循环的有向图。
有向图数据类型。
我们实现了以下有向图 API。
关键方法 adj() 允许客户端代码遍历从给定顶点邻接的顶点。
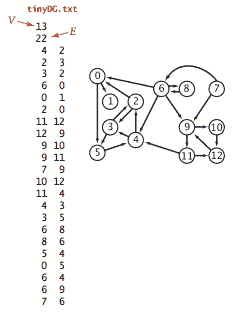
我们使用以下输入文件格式准备测试数据 tinyDG.txt。
图的表示。
我们使用邻接表表示法,其中我们维护一个以顶点为索引的列表数组,其中包含与每个顶点通过边连接的顶点。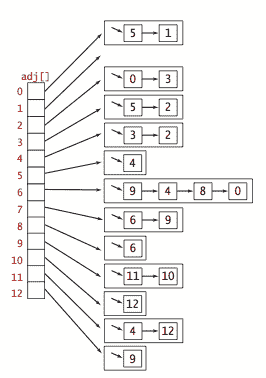
Digraph.java 使用邻接表表示法实现了有向图 API。AdjMatrixDigraph.java 使用邻接矩阵表示法实现了相同的 API。
有向图中的可达性。
深度优先搜索和广度优先搜索是基本的有向图处理算法。
-
单源可达性: 给定一个有向图和源
s,是否存在一条从 s 到 v 的有向路径?如果是,找到这样的路径。DirectedDFS.java 使用深度优先搜索来解决这个问题。 -
多源可达性: 给定一个有向图和一组源顶点,是否存在一条从集合中的任意顶点到 v 的有向路径?DirectedDFS.java 使用深度优先搜索来解决这个问题。
-
单源有向路径: 给定一个有向图和源
s,是否存在一条从 s 到 v 的有向路径?如果是,找到这样的路径。DepthFirstDirectedPaths.java 使用深度优先搜索来解决这个问题。 -
单源最短有向路径:给定一个有向图和源点
s,是否存在从 s 到 v 的有向路径?如果有,找到一条最短的这样的路径。BreadthFirstDirectedPaths.java 使用广度优先搜索来解决这个问题。
循环和 DAG。
在涉及处理有向图的应用中,有向循环尤为重要。输入文件 tinyDAG.txt 对应于以下 DAG: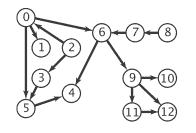
-
有向环检测:给定一个有向图,是否存在有向环?如果有,找到这样的环。DirectedCycle.java 使用深度优先搜索来解决这个问题。
-
深度优先顺序:深度优先搜索每个顶点恰好一次。在典型应用中,有三种顶点排序是感兴趣的:
-
前序:在递归调用之前将顶点放入队列。
-
后序:在递归调用后将顶点放入队列。
-
逆后序:在递归调用后将顶点放入栈。
DepthFirstOrder.java 计算这些顺序。

-
-
拓扑排序:给定一个有向图,按顶点顺序排列,使得所有的有向边都从顺序中较早的顶点指向顺序中较晚的顶点(或报告无法这样做)。Topological.java 使用深度优先搜索来解决这个问题。值得注意的是,在 DAG 中的逆后序提供了一个拓扑顺序。

命题。
有向图具有拓扑顺序当且仅当它是 DAG。
命题。
DAG 中的逆后序是拓扑排序。
命题。
使用深度优先搜索,我们可以在时间上将 DAG 进行拓扑排序,时间复杂度为 V + E。
强连通性。
强连通性是顶点集合上的等价关系:
-
自反性:每个顶点 v 与自身强连通。
-
对称性:如果 v 与 w 强连通,则 w 也与 v 强连通。
-
传递性:如果 v 与 w 强连通,且 w 与 x 强连通,则 v 也与 x 强连通。
强连通性将顶点划分为等价类,我们简称为强连通分量。我们试图实现以下 API:
令人惊讶的是,KosarajuSharirSCC.java 仅通过在 CC.java 中添加几行代码就实现了该 API,如下所示:
-
给定一个有向图 G,使用 DepthFirstOrder.java 来计算其反向图 G^R 的逆后序。
-
在 G 上运行标准 DFS,但考虑刚刚计算的顺序中的未标记顶点,而不是标准的数字顺序。
-
从构造函数中对递归
dfs()的调用到达的所有顶点都在一个强连通分量中(!),因此像在 CC 中一样识别它们。
命题。
Kosaraju-Sharir 算法使用预处理时间和空间与 V + E 成比例,以支持有向图中的常数时间强连通性查询。
传递闭包。
有向图 G 的传递闭包是另一个有向图,具有相同的顶点集,但如果且仅当在 G 中从 v 到 w 可达时,有一条从 v 到 w 的边。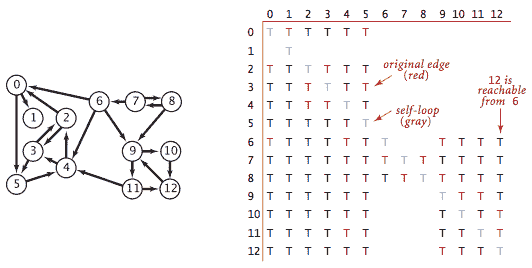
TransitiveClosure.java 通过从每个顶点运行深度优先搜索并存储结果来计算有向图的传递闭包。这种解决方案非常适合小型或密集的有向图,但不适用于我们在实践中可能遇到的大型有向图,因为构造函数使用的空间与 V² 成比例,时间与 V (V + E) 成比例。
练习
-
为 Digraph 创建一个复制构造函数,该函数以有向图 G 作为输入,并创建和初始化有向图的新副本。客户端对 G 所做的任何更改都不应影响新创建的有向图。
-
有向图在第 591 页上有多少个强连通分量?
解决方案: 10. 输入文件是 mediumDG.txt。
-
有向无环图(DAG)的强连通分量是什么?
解决方案: 每个顶点都是自己的强连通分量。
-
真或假:有向图的反向的逆后序与有向图的逆后序相同。
解决方案: 假。
-
真或假:如果我们修改 Kosaraju-Sharir 算法,在有向图 G 中运行第一个深度优先搜索(而不是反向有向图 G^R),并在 G^R 中运行第二个深度优先搜索(而不是 G),那么它仍然会找到强连通分量。
解决方案. 是的,有向图的强连通分量与其反向的强连通分量相同。
-
真或假:如果我们修改 Kosaraju-Sharir 算法,用广度优先搜索替换第二次深度优先搜索,那么它仍然会找到强连通分量。
解决方案. 真。
-
计算具有 V 个顶点和 E 条边的
Digraph的内存使用情况,根据第 1.4 节的内存成本模型。解决方案. 56 + 40V + 64E。MemoryOfDigraph.java 根据经验计算,假设没有缓存
Integer值—Java 通常会缓存-128 到 127 之间的整数。
创造性问题
-
有向欧拉回路。 有向欧拉回路是一个包含每条边恰好一次的有向循环。编写一个有向图客户端 DirectedEulerianCycle.java 来查找有向欧拉回路或报告不存在这样的回路。
提示: 证明一个有向图 G 有一个有向欧拉回路当且仅当 G 中的每个顶点的入度等于出度,并且所有具有非零度的顶点属于同一个强连通分量。
-
强连通分量。 描述一个计算包含给定顶点 v 的强连通分量的线性时间算法。基于该算法,描述一个简单的二次时间算法来计算有向图的强连通分量。
部分解决方案: 计算包含 s 的强连通分量
-
找到从 s 可达的顶点集
-
找到可以到达 s 的顶点集
-
取两个集合的交集,使用这个作为子程序,你可以在时间比例为 t(E + V)的情况下找到所有强连通分量,其中 t 是强连通分量的数量。
-
-
DAG 中的哈密顿路径。 给定一个 DAG,设计一个线性时间算法来确定是否存在一个访问每个顶点恰好一次的有向路径。
解决方案: 计算一个拓扑排序,并检查拓扑顺序中每对连续顶点之间是否有边。
-
唯一拓扑排序。 设计一个算法来确定一个有向图是否有唯一的拓扑排序。
提示: 一个有向图有一个唯一的拓扑排序当且仅当拓扑排序中每对连续顶点之间存在一个有向边(即,有向图有一个哈密顿路径)。如果有向图有多个拓扑排序,那么可以通过交换一对连续顶点来获得第二个拓扑排序。
-
2-可满足性。 给定一个布尔公式,其合取范式中有 M 个子句和 N 个文字,每个子句恰好有两个文字,找到一个满足的赋值(如果存在)。
解决方案草图: 用 2N 个顶点(每个文字及其否定一个)形成蕴含有向图。对于每个子句 x + y,从 y’到 x 和从 x’到 y 包括边缘。声明:如果没有变量 x 与其否定 x’在同一个强连通分量中,则公式是可满足的。此外,核心 DAG 的拓扑排序(将每个强连通分量缩减为单个顶点)产生一个满足的赋值。
-
基于队列的拓扑排序算法。 开发一个非递归的拓扑排序实现 TopologicalX.java,该实现维护一个顶点索引数组,用于跟踪每个顶点的入度。在一次遍历中初始化数组和源队列,就像练习 4.2.7 中那样。然后,执行以下操作,直到源队列为空:
-
从队列中移除一个源并标记它。
-
减少入度数组中与已移除顶点的边的目标顶点对应的条目。
-
如果减少任何条目使其变为 0��则将相应的顶点插入源队列。
-
-
最短有向循环。 给定一个有向图,设计一个算法来找到具有最少边数的有向循环(或报告图是无环的)。你的算法在最坏情况下的运行时间应该与E V成正比。
应用: 给出一组需要肾移植的患者,每个患者都有一个愿意捐赠肾脏但类型不匹配的家庭成员。愿意捐赠给另一个人,前提是他们的家庭成员得到肾脏。然后医院进行“多米诺手术”,所有移植同时进行。
解决方案: 从每个顶点 s 运行 BFS。通过 s 的最短循环是一条边 v->s,再加上从 s 到 v 的最短路径。ShortestDirectedCycle.java。
-
奇数长度的有向循环。 设计一个线性时间算法,以确定一个有向图是否有一个奇数长度的有向循环。
解决方案。 我们声称,如果一个有向图 G 有一个奇数长度的有向循环,那么它的一个(或多个)强连通分量作为无向图时是非二分的。
-
如果有向图 G 有一个奇数长度的有向循环,则此循环将完全包含在一个强连通分量中。当强连通分量被视为无向图时,奇数长度的有向循环变为奇数长度的循环。回想一下,无向图是二分的当且仅当它没有奇数长度的循环。
-
假设 G 的一个强连通分量是非二分图(当作无向图处理时)。这意味着在强连通分量中存在一个奇数长度的循环 C,忽略方向。如果 C 是一个有向循环,那么我们完成了。否则,如果边 v->w 指向“错误”的方向,我们可以用指向相反方向的奇数长度路径替换它(这保留了循环中边数的奇偶性)。要了解如何做到这一点,请注意存在一条从 w 到 v 的有向路径 P,因为 v 和 w 在同一个强连通分量中。如果 P 的长度为奇数,则我们用 P 替换边 v->w;如果 P 的长度为偶数,则这条路径 P 与 v->w 组合在一起就是一个奇数长度的循环。
-
-
DAG 中可达的顶点。 设计一个线性时间算法,以确定一个 DAG 是否有一个顶点可以从每个其他顶点到达。
解决方案。 计算每个顶点的出度。如果 DAG 有一个出度为 0 的顶点 v,那么它可以从每个其他顶点到达。
-
有向图中可达的顶点。 设计一个线性时间算法,以确定有向图是否有一个顶点可以从每个其他顶点到达。
解决方案。 计算强连通分量和核 DAG。将练习 4.2.37 应用于核 DAG。
-
网络爬虫。 编写一个程序 WebCrawler.java,使用广度优先搜索来爬取网络有向图,从给定的网页开始。不要显式构建网络有向图。
网络练习
-
符号有向图。 修改 SymbolGraph.java 以创建一个实现符号有向图的程序 SymbolDigraph.java。
-
组合电路。 给定输入,确定组合电路的真值是一个图可达性问题(在有向无环图上)。
-
权限提升。 如果 A 可以获得 B 的权限,则在用户类 A 到用户类 B 之间包含一个数组。找出所有可以在 Windows 中获得管理员访问权限的用户。
-
Unix 程序 tsort。
-
跳棋。 将跳棋规则扩展到一个 N×N 的跳棋棋盘。展示如何确定一个跳棋在当前移动中是否可以变成国王。(使用 BFS 或 DFS。)展示如何确定黑方是否有获胜的着法。(找到一个有向欧拉路径。)
-
优先附着模型。 网络具有无标度特性,并遵循幂律。新页面倾向于优先附着到受欢迎的页面上。从指向自身的单个页面开始。每一步中,一个新页面出现,出度为 1。以概率 p,页面指向一个随机页面;以概率(1-p),页面指向一个现有页面,概率与页面的入度成比例。
-
子类型检查。 给定单继承关系(一棵树),检查 v 是否是 w 的祖先。提示:v 是 w 的祖先当且仅当 pre[v] <= pre[w]且 post[v] >= post[w]。
-
子类型检查。 重复上一个问题,但使用有向无环图而不是树。
-
有根树的 LCA。 给定一个有根树和两个顶点 v 和 w,找到顶点 v 和 w 的最低共同祖先(lca)。顶点 v 和 w 的 lca 是离根最远的共同祖先。根树上最基本的问题之一。可以在 O(1)的查询时间内解决,预处理时间为线性时间(Harel-Tarjan,Bender-Coloton)。
找到一个有向无环图,其中最短的祖先路径通向一个不是 LCA 的共同祖先 x。
-
九个字母的单词。 找到一个九个字母的英文单词,使得在适当的顺序中依次删除每个字母后仍然是一个英文单词。使用单词和顶点构建一个有向图,如果一个单词可以通过添加一个字母形成另一个单词,则在两个单词之间添加一条边。
答案:一个解决方案是 startling -> starting -> staring -> string -> sting -> sing -> sin -> in -> i。
-
电子表格重新计算。 希望没有循环依赖。使用公式单元格图的拓扑排序来确定更新单元格的顺序。
-
嵌套箱子。 一个维度为 d 的箱子,其尺寸为(a1, a2, …, ad),如果第二个箱子的坐标可以重新排列,使得 a1 < b1, a2 < b2, …, ad < bd,则该箱子嵌套在第二个箱子内。
-
给出一个有效的算法,用于确定一个 d 维箱子嵌套在另一个箱子内的位置。提示:排序。
-
证明嵌套是传递的:如果箱子 i 嵌套在箱子 j 内部,箱子 j 又嵌套在箱子 k 内部,那么箱子 i 也嵌套在箱子 k 内部。
-
给定一组 n 个 d 维箱子,给出一个有效的算法,找到可以同时嵌套最多箱子的方法。
提示:创建一个有向图,如果箱子 i 嵌套在箱子 j 内部,则从箱子 i 到箱子 j 添加一条边。然后运行拓扑排序。
-
-
Warshall 的传递闭包算法。 WarshallTC.java 算法适用于稠密图。依赖于 AdjMatrixDigraph.java。
-
暴力强连通分量算法。 BruteSCC.java 通过首先计算传递闭包来计算强连通分量。时间复杂度为 O(EV),空间复杂度为 O(V²)。
-
Tarjan 的强连通分量算法。 TarjanSCC.java 实现了 Tarjan 算法来计算强连通分量。
-
Gabow 的强连通分量算法。 GabowSCC.java 实现了 Gabow 算法来计算强连通分量。
-
有向图生成器。 DigraphGenerator.java 生成各种有向图。
-
有限马尔可夫链. 回归状态:一旦在状态开始,马尔可夫链将以概率 1 返回。瞬时状态:有些概率它永远不会返回(某个节点 j,i 可以到达 j,但 j 无法到达 i)。不可约马尔可夫链=所有状态都是回归的。马尔可夫链是不可约的当且仅当它是强连通的。回归组件是核 DAG 中没有离开边的组件。马尔可夫链中的通信类是强连通分量。
定理. 如果 G 是强连通的,则存在唯一的稳态分布 pi。此外,对于所有 v,pi(v) > 0。
定理. 如果 G 的核 DAG 具有单个没有离开边的超节点,则存在唯一的稳态分布 pi。此外,对于所有回归的 v,pi(v) > 0 且对于所有瞬时的 v,pi(v) = 0。
-
后代引理. [R. E. Tarjan] 将 pre[v]和 post[v]分别表示为 v 的前序和后序编号,nd[v]表示 v 的后代数(包括 v)。证明以下四个条件是等价的。
-
顶点 v 是顶点 w 的祖先。
-
pre[v] <= pre[w] < pre[v] + nd(v).
-
post[v] - nd [v] < post[w] <= post[v]
-
pre[v] <= pre[w]且 post[v] >= post[w](嵌套引理)
-
-
边引理. [R. E. Tarjan] 证明边(v, w)是以下四种之一:
-
w 是 v 的子节点:(v, w)是一条树边。
-
w 是 v 的后代但不是子节点:(v, w)是一条前向边。
-
w 是 v 的祖先:(v, w)是一条后向边
-
w 和 v 无关且 pre[v] > pre[w]:(v, w)是一条交叉边。
-
-
路径引理. [R. E. Tarjan] 证明从 v 到 w 的任何路径,其中 pre[v] < pre[w],都包含 v 和 w 的共同祖先。
-
证明如果(v, w)是一条边且 pre[v] < pre[w],则 v 是 DFS 树中 w 的祖先。
-
后序引理. [R. E. Tarjan] 证明如果 P 是一条路径,最后一个顶点 x 在后序中最高,则路径上的每个顶点都是 x 的后代(因此与 x 有一条路径)。
解. 证明通过对 P 的长度进行归纳(或通过反证法)。设(v, w)是一条边,其中 w 是 x 的后代且 post[v] < post[x]。由于 w 是 x 的后代,我们有 pre[w] >= pre[x]。
-
如果 pre[v] >= pre[x],那么 v 是 x 的后代(通过嵌套引理)。
-
如果 pre[v] < pre[x],那么 pre[v] < pre[w],这意味着(通过前一个练习)v 是 w 的祖先,因此与 x 有关。但是 post[v] < post[x]意味着 v 是 x 的后代。
-
-
前拓扑排序. 设计一个线性时间算法来找到一个前拓扑排序:一种顶点的排序,使得如果从 v 到 w 有一条路径且 w 在排序中出现在 v 之前,则从 w 到 v 也必须有一条路径。
提示:反向后序是一种前拓扑排序。这是 Kosaraju-Sharir 算法正确性证明的关键。
-
Wordnet. 使用 WordNet 测量形容词的语义取向.
-
垃圾收集. 在像 Java 这样的语言中进行自动内存管理是一个具有挑战性的问题。分配内存很容易,但发现程序何时完成对内存的使用(并回收它)更加困难。引用计数:不适用于循环链接结构。标记-清除算法。根=局部变量和静态变量。从根运行 DFS,标记所有从根引用的变量,依此类推。然后,进行第二遍:释放所有未标记的对象并取消标记所有标记的对象。或者复制垃圾收集器将所有标记的对象移动到单个内存区域。每个对象使用一个额外的位。JVM 在进行垃圾收集时必须暂停。碎片化内存。
应用:C 泄漏检测器(泄漏=不可达的,未释放的内存)。
-
有向循环检测应用。 应用:检查非法继承循环,检查死锁。目录是文件和其他目录的列表。符号链接是对另一个目录的引用。在列出目录中的所有文件时,需要小心避免跟随符号链接的循环!
-
拓扑排序应用。 应用:课程先修条件、大型计算机程序组件的编译顺序、因果关系、类继承、死锁检测、时间依赖性、计算作业的管道、检查符号链接循环、电子表格中的公式求值。
-
强连通分量应用。 应用于 CAD、马尔可夫链(不可约)、蜘蛛陷阱和网络搜索、指针分析、垃圾回收。
-
单向街定理。 实现一个算法来定向无向图中的边,使其成为强连通图。罗宾斯定理断言,当且仅当无向图是双边连通的(没有桥)时,这是可能的。在这种情况下,一种解决方案是运行深度优先搜索(DFS),并将 DFS 树中的所有边定向远离根节点,将所有剩余的边定向朝向根节点。
-
定向混合图中的边以使其无环。 混合图是具有一些有向边和一些无向边的图。设计一个线性时间算法来确定是否可以定向无向边,使得结果有向图是无环的。
应用:老城区的狭窄道路希望使每条道路单向通行,但仍允许城市中的每个交叉口可从其他城市到达。
-
定向混合图中的边以形成有向循环。 混合图是具有一些有向边和一些无向边的图。设计一个线性时间算法来确定是否可以定向无向边,使得结果有向图具有有向循环。
应用:确定最大流是否唯一。
解决方案:一个算法。
-
后序引理变种。 设 S 和 T 是有向图 G 中的两个强连通分量。证明如果存在一条从 S 中的一个顶点到 T 中的一个顶点的边 e,则 S 中顶点的最高后序编号高于 T 中顶点的最高后序编号。
-
DAG 中路径的数量。 给定一个有向无环图(DAG)和两个特定顶点 s 和 t,设计一个线性时间算法来计算从 s 到 t 的有向路径数量。
提示:拓扑排序。
-
DAG 中长度为 L 的路径。 给定一个有向无环图(DAG)和两个特定顶点 s 和 t,设计一个算法来确定是否存在一条从 s 到 t 的路径,其中恰好包含 L 条边。
-
核心顶点。 给定一个有向图 G,如果从顶点 v 可以到达 G 中的每个顶点,则顶点 v 是一个核心顶点。设计一个线性时间算法来找到所有核心顶点。
提示:创建 G 的强连通分量并查看核心 DAG。
-
强连通分量和二分图匹配。 给定一个二分图 G,一个未匹配边是指不出现在任何完美匹配中的边。设计一个算法来找到所有未匹配边。
提示:证明以下算法可以胜任。在 G 中找到一个完美匹配;将匹配中的边从双分区的一侧定向到另一侧;将剩余的边定向到相反方向;在不在完美匹配中的边中,返回那些端点在不同强连通分量中的边。
-
有向图的传递闭包。 有向图的传递闭包是具有与原始有向图相同传递闭包的边数最少的有向图。设计一个 V(E + V)算法来计算有向图的传递闭包。请注意,有向图中的传递闭包不一定是唯一的,也不一定是原始有向图的子图。(有向无环图中的传递闭包是唯一的且是原始有向图的子图。)
-
奇长度路径。 给定一个有向图 G 和一个源顶点 s,设计一个线性时间算法,确定通过具有奇数边数的路径(不一定简单)从 s 可达的所有顶点。
解决方案:为 G 中的每个顶点 v 创建一个新的有向图 G’,其中包含两个顶点 v 和 v’。对于 G 中的每条边 v->w,包括两条边:v->w’和 w->v’。现在,在 G’中从 s 到 v’的任何路径对应于 G 中从 s 到 v 的奇长度路径。运行 BFS 或 DFS 以确定从 s 可达的顶点。
-
找到一个有向无环图(DAG)的拓扑排序,无论深度优先搜索(DFS)以何种顺序选择起始顶点,都无法计算为 DFS 的逆后序。展示出 DAG 的每一个拓扑排序都可以被计算为 DFS 的逆后序,只要 DFS 可以任意选择构造函数中起始顶点的顺序。
-
非递归 DFS。 编写一个��序 NonrecursiveDirectedDFS.java,使用显式栈而不是递归来实现深度优先搜索。编写一个程序 NonrecursiveDirectedCycle.java,在不使用递归的情况下找到一个有向环。
-
非递归拓扑排序。 将基于队列的拓扑排序算法 TopologicalX.java 从练习 4.2.39 扩展到在有向图存在有向环时找到该有向环。将程序命名为 DirectedCycle.java。
-
Cartalk 难题。 在字典中找到一个具有以下特性的最长单词:您可以一次删除一个字母(从任一端或中间),结果字符串也是字典中的单词。例如,STRING 是一个具有此特性的 6 字母单词(STRING -> STING -> SING -> SIN -> IN -> I)。
-
逆后序与前序。 真或假:有向图的逆后序与有向图的前序相同。
-
Kosaraju–Sharir 算法中的逆后序与前序。 假设您在 Kosaraju–Sharir 算法中使用有向图的前序而不是逆后序。它是否仍会产生强连通分量?
答案:不会,运行 KosarajuSharirPreorderSCC.java 在
tinyDG.txt上。
4.3 最小生成树
原文:
algs4.cs.princeton.edu/43mst译者:飞龙
协议:CC BY-NC-SA 4.0
最小生成树。
带权重的图 是一种我们为每条边关联权重或成本的图。带权重图的*最小生成树(MST)*是其边权重之和不大于任何其他生成树的生成树。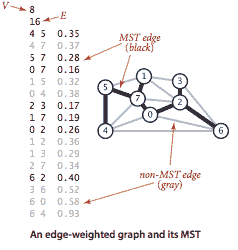
假设。
为了简化演示,我们采用以下约定:
-
图是连通的。 我们定义的生成树条件意味着图必须是连通的才能存在 MST。如果图不连通,我们可以调整算法以计算其每个连通分量的 MST,统称为最小生成森林。
-
边的权重不一定是距离。 几何直觉有时是有益的,但边的权重可以是任意的。
-
边的权重可能为零或负数。 如果边的权重都是正数,则定义最小生成树为连接所有顶点的总权重最小的子图即可。
-
边的权重都不同。 如果边可以具有相同的权重,则最小生成树可能不唯一。做出这种假设简化了我们一些证明,但我们的所有算法即使在存在相同权重的情况下也能正常工作。
基本原理。
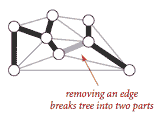
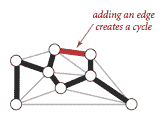
我们回顾树的两个定义性质:
-
添加连接树中两个顶点的边会创建一个唯一的循环。
-
从树中移除一条边会将其分成两个独立的子树。
图的切割是将其顶点划分为两个不相交集合。跨越边是连接一个集合中的顶点与另一个集合中的顶点的边。我们假设为简单起见,所有边的权重都是不同的。在此假设下,MST 是唯一的。定义切割和循环。以下性质导致多种 MST 算法。
命题。(切割性质)
在带权重图中的任何切割中(所有边权重不同),最小权重的跨越边在图的 MST 中。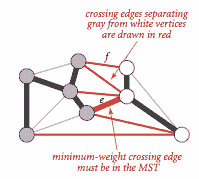
切割性质是��们考虑 MST 问题的算法的基础。具体来说,它们是贪心算法的特例。
命题。(贪心 MST 算法)
以下方法将所有连接的带权重图的 MST 中的所有边涂黑:从所有边都涂灰色开始,找到没有黑色边的切割,将其最小权重的边涂黑,继续直到涂黑 V-1 条边。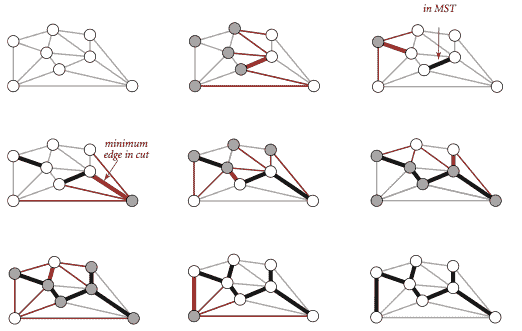
最小生成树问题](…/Images/fce4a44e5b52cd8391fb6ea99f7fa182.png)
带权重图数据类型。
我们使用以下 API 表示带权重的边:
either() 和 other() 方法用于访问边的顶点;compareTo() 方法通过权重比较边。Edge.java 是一个直接的实现。
我们使用以下 API 表示带权重的图:

我们允许平行边和自环。EdgeWeightedGraph.java 使用邻接表表示法实现 API。
MST API.
我们使用以下 API 计算带权重图的最小生成树: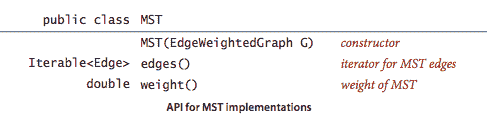
我们准备了一些测试数据:
-
tinyEWG.txt 包含 8 个顶点和 16 条边
-
mediumEWG.txt 包含 250 个顶点和 1,273 条边
-
1000EWG.txt 包含 1,000 个顶点和 8,433 条边
-
10000EWG.txt 包含 10,000 个顶点和 61,731 条边
-
largeEWG.txt 包含一百万个顶点和 7,586,063 条边
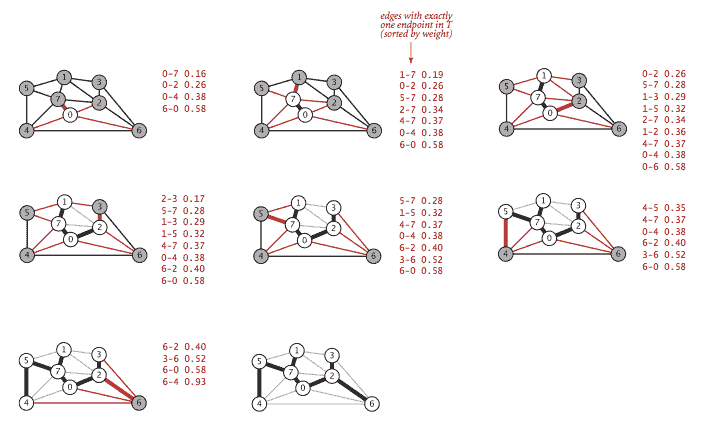
Prim 算法。
Prim 算法通过在每一步将新边附加到单个增长树上来工作:从任何顶点开始作为单个顶点树;然后向其添加 V-1 条边,始终取下一个(着色为黑色)连接树上顶点与尚未在树上的顶点的最小权重边(对于由树顶点定义的切割的跨越边)。
Prim 算法的一句描述留下了一个关键问题:我们如何(高效地)找到最小权重的跨越边?
-
懒惰实现. 我们使用优先队列来保存跨越边并找到最小权重的边。每次我们将一条边添加到树中时,我们也将一个顶点添加到树中。为了维护跨越边的集合,我们需要将从该顶点到任何非树顶点的所有边添加到优先队列中。但我们必须做更多的事情:连接刚刚添加的顶点到已经在优先队列中的树顶点的任何边现在变得不合格(它不再是跨越边,因为它连接了两个树顶点)。懒惰实现将这样的边留在优先队列中,推迟不合格测试到我们删除它们时。
LazyPrimMST.java 是这种懒惰方法的实现。它依赖于 MinPQ.java 优先队列。
-
急切实现. 为了改进 Prim 算法的懒惰实现,我们可以尝试从优先队列中删除不合格的边,以便优先队列只包含跨越边。但我们可以消除更多的边。关键在于注意到我们唯一感兴趣的是从每个非树顶点到树顶点的最小边。当我们将顶点 v 添加到树中时,与每个非树顶点 w 相关的唯一可能变化是,添加 v 使 w 比以前更接近树。简而言之,我们不需要在优先队列中保留所有从 w 到树顶点的边 - 我们只需要跟踪最小权重的边,并检查是否添加 v 到树中需要我们更新该最小值(因为边 v-w 的权重更低),我们可以在处理 s 邻接列表中的每条边时做到这一点。换句话说,我们只保留优先队列中的一条边用于每个非树顶点:连接它与树的最短边。

PrimMST.java 是这种急切方法的实现。它依赖于 IndexMinPQ.java 索引优先队列来执行减少键操作。
命题。
Prim 算法计算任何连通的边权重图的最小生成树。Prim 算法的懒惰版本使用空间与 E 成比例,时间与 E log E 成比例(在最坏情况下)来计算具有 E 条边和 V 个顶点的连通边权重图的最小生成树;急切版本使用空间与 V 成比例,时间与 E log V 成比例(在最坏情况下)。
Kruskal 算法。
Kruskal 算法按照它们的权重值(从小到大)的顺序处理边,每次添加不与先前添加的边形成循环的边作为 MST(着色为黑色),在添加 V-1 条边后停止。黑色边形成逐渐演变为单一树 MST 的树林。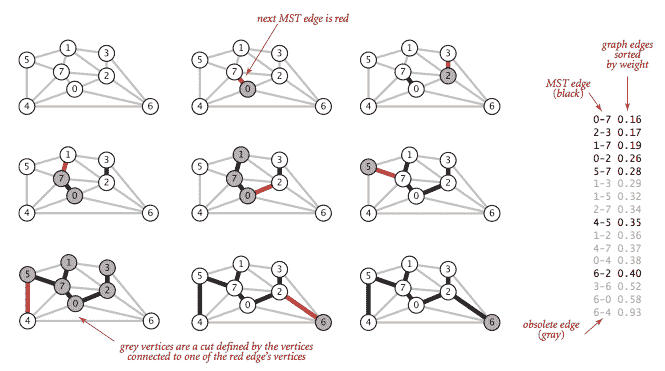
要实现 Kruskal 算法,我们使用优先队列按权重顺序考虑边,使用并查集数据结构标识导致循环的边,使用队列收集最小生成树边。程序 KruskalMST.java 按照这些方式实现了 Kruskal 算法。它使用了辅助的 MinPQ.java、UF.java 和 Queue.java 数据类型。
命题。
Kruskal 算法使用额外空间与 E 成正比,时间与 E log E 成正比(在最坏情况下)来计算具有 E 条边和 V 个顶点的任何连通边权图的最小生成树。
练习
-
证明,通过给所有权重加上一个正常数或将它们全部乘以一个正常数,不会影响最小生成树。
解决方案. Kruskal 算法只通过
compareTo()方法访问边权重。给每个权重添加一个正常数(或乘以一个正常数)不会改变compareTo()方法的结果。 -
证明,如果一个图的边都有不同的权重,那么最小生成树是唯一的。
解决方案. 为了推导矛盾,假设图 G 有两个不同的最小生成树,称为 T1 和 T2。设 e = v-w 是 G 中在 T1 或 T2 中的最小权重边,但不在两者中都存在。假设 e 在 T1 中。将 e 添加到 T2 中会创建一个循环 C。C 中至少有一条边,假设为 f,不在 T1 中(否则 T1 就是循环的)。根据我们选择的 e,w(e) ≤ w(f)。由于所有边的权重都不同,w(e) < w(f)。现在,在 T2 中用 e 替换 f 会得到一棵权重小于 T2 的新生成树(与 T2 的最小性相矛盾)。
-
如何找到边权图的最大生成树?
解决方案. 反转每条边的权重(或在
compareTo()方法中反转比较的意义)。 -
为 EdgeWeightedGraph.java 实现从输入流读取边权图的构造函数。
-
确定 EdgeWeightedGraph.java 用于表示具有 V 个顶点和 E 条边的图所使用的内存量,使用第 1.4 节的内存成本模型。
解决方案. 56 + 40V + 112E。MemoryOfEdgeWeightedGraph.java 通过假设没有缓存
Integer值来进行经验计算—Java 通常会缓存 -128 到 127 的整数。 -
给定边权图 G 的最小生成树,假设删除一个不会使 G 断开的边。描述如何在与 E 成正比的时间内找到新图的最小生成树。
解决方案. 如果边不在最小生成树中,则旧的最小生成树是更新后图的最小生成树。否则,从最小生成树中删除边会留下两个连通分量。添加一个顶点在每个连通分量中的最小权重边。
-
给定边权图 G 的最小生成树和一个新边 e,描述如何在与 V 成正比的时间内找到新图的最小生成树。
解决方案. 将边 e 添加到最小生成树会创建一个唯一的循环。删除此循环上的最大权重边。
-
为 EdgeWeightedGraph.java 实现
toString()。 -
假设你实现了 Prim 算法的急切版本,但是不使用优先队列来找到下一个要添加到树中的顶点,而是扫描
distTo[]数组中的所有V个条目,找到具有最小值的非树顶点。在具有 V 个顶点和 E 条边的图上,Prim 算法的急切版本的最坏情况运行时间的增长顺序是多少?如果有的话,什么时候这种方法是合适的?为什么?请解释你的答案。解决方案. Prim 算法的运行时间将与 V² 成正比,这对于稠密图是最佳的。
-
为 PrimMST.java 实现
edges()。
创意问题
-
最小生成森林。 开发 Prim 和 Kruskal 算法的版本,计算不一定连通的边权图的最小生成森林。
解决方案。 PrimMST.java 和 KruskalMST.java 实现了这一点。
-
认证。 编写一个名为
check()的方法,使用以下割优化条件来验证提议的边集是否实际上是最小生成树(MST):如果一组边是一棵生成树,并且每条边都是通过从树中移除该边定义的割的最小权重边,则这组边就是 MST。你的方法的运行时间增长率是多少?解决方案。 KruskalMST.java。
实验
-
Boruvka 算法。 开发 Boruvka 算法的实现 BoruvkaMST.java:通过将边添加到不断增长的树森林中来构建 MST,类似于 Kruskal 算法,但是分阶段进行。在每个阶段,找到将每棵树连接到另一棵树的最小权重边,然后将所有这样的边添加到 MST 中。假设边的权重都不同,以避免循环。提示:维护一个顶点索引数组,以标识连接每个组件到其最近邻居的边,并使用并查集数据结构。
备注。 由于每个阶段树的数量至少减少一半,所以最多有 log V 个阶段。这种方法高效且可以并行运行。
网页练习
-
最小瓶颈生成树。 图 G 的最小瓶颈生成树是 G 的一棵生成树,使得生成树中任意边的最大权重最小化。设计一个算法来找到最小瓶颈生成树。
解决方案。 每个 MST 都是最小瓶颈生成树(但不一定反之)。这可以通过割性质来证明。
-
最小中位数生成树。 图 G 的最小中位数生成树是 G 的一棵生成树,使得其权重的中位数最小化。设计一个高效的算法来找到最小中位数生成树。
解决方案。 每个 MST 都是最小中位数生成树(但不一定反之)。
-
迷宫生成。 使用随机化的 Kruskal 或 Prim 算法创建迷宫。
-
唯一 MST。 设计一个算法来确定给定图 G 的 MST 是否唯一。
-
随机生成树。 给定图 G,均匀随机生成 G 的一棵生成树。使用 Aldous 和 Broder 的以下显著定理:从任意顶点 s 开始,并进行随机游走,直到每个顶点都被访问过(在所有相邻边中均匀随机选择一条出边)。如果一个顶点以前从未被访问过,则将边添加到该顶点以形成生成树 T。那么 T 是图 G 的均匀随机生成树。预期的运行时间受限于 G 的覆盖时间,最多与 EV 成比例。
-
最小权重反馈边集。 图的反馈边集是包含图中每个循环中至少一条边的子集。如果删除反馈边集的边,则结果图将是无环的。设计一个高效的算法,在具有正边权的加��图中找到最小权重的反馈边集。
-
两个 MST 中边权重的分布。 假设加权有向图有两个 MST T1 和 T2。证明如果 T1 有权重为 w 的 k 条边,则 T2 也有权重为 w 的 k 条边。
-
美国计算奥林匹克问题。 在一个城市中有 N 栋房子,每栋房子都需要供水。在第 i 栋房子建造井的成本为 w[i]美元,在第 i 和第 j 栋房子之间建造管道的成本为 c[i][j]。如果一栋房子建有井或者有一条管道路径通向有井的房子,那么这栋房子就可以接收水。设计一个算法来找到供应每栋房子所需的最小金额。
解决方案.: 创建一个带有 N+1 个顶点的边权图(每个房子一个顶点加上一个源顶点 x)。包括每对顶点 i 和 j 之间的成本 c[i][j] 的边(表示潜在的管道)。包括源 s 和每个房子 i 之间成本为 w[i] 的边(表示潜在的开放井)。在这个边权图中找到一个最小生成树。
-
恰好有 k 条橙色边的生成树。 给定一个边缘着色为橙色或黑色的图,设计一个线性对数算法来找到一个包含恰好 k 条橙色边的生成树(或报告不存在这样的生成树)。
-
最小方差生成树。 给定一个连通的边权重图,找到一个最小生成树,使其边权重的方差最小化。
4.4 最短路径
原文:
algs4.cs.princeton.edu/44sp译者:飞龙
协议:CC BY-NC-SA 4.0
最短路径。
加权有向图是一个有向图,其中我们为每条边关联权重或成本。从顶点 s 到顶点 t 的最短路径是从 s 到 t 的有向路径,具有没有更低权重的其他路径的属性。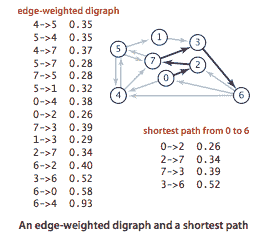
属性。
我们总结了几个重要的属性和假设。
-
路径是有方向的。 最短路径必须遵守其边的方向。
-
权重不一定是距离。 几何直觉可能有所帮助,但边的权重可能代表时间或成本。
-
并非所有顶点都需要可达。 如果 t 从 s 不可达,则根本没有路径,因此从 s 到 t 的最短路径也不存在。
-
负权重引入了复杂性。 目前,我们假设边的权重是正数(或零)。
-
最短路径通常是简单的。 我们的算法忽略形成循环的零权重边,因此它们找到的最短路径没有循环。
-
最短路径不一定是唯一的。 从一个顶点到另一个顶点可能有多条最低权重的路径;我们满足于找到其中任何一条。
-
并行边和自环可能存在。 在文本中,我们假设不存在并行边,并使用符号 v->w 来表示从 v 到 w 的边,但我们的代码可以轻松处理它们。
加权有向图数据类型。
我们使用以下 API 表示加权边:
from()和to()方法对于访问边的顶点很有用。DirectedEdge.java 实现了这个 API。
我们使用以下 API 表示加权有向图:
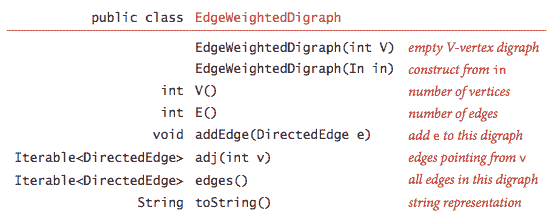
EdgeWeightedDigraph.java 使用邻接表表示实现了该 API。
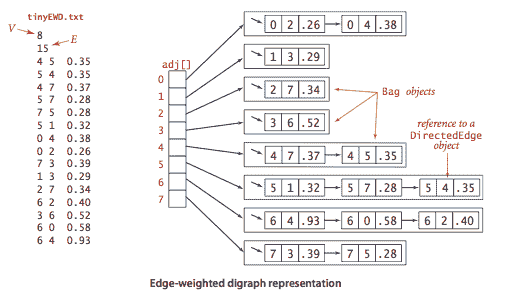
最短路径 API。
我们使用以下 API 计算加权有向图的最短路径:
我们准备了一些测试数据:
-
tinyEWD.txt 包含 8 个顶点和 15 条边
-
mediumEWD.txt 包含 250 个顶点和 2,546 条边
-
1000EWG.txt 包含 1,000 个顶点和 16,866 条边
-
10000EWG.txt 包含 10,000 个顶点和 123,462 条边
-
largeEWG.txt 包含一百万个顶点和 15,172,126 条边。
单源最短路径的数据结构。
给定一个加权有向图和一个指定的顶点 s,最短路径树(SPT)是一个子图,包含 s 和所有从 s 可达的顶点,形成以 s 为根的有向树,使得每条树路径都是图中的最短路径。
我们用两个顶点索引数组表示最短路径:
-
最短路径树上的边:
edgeTo[v]是从 s 到 v 的最短路径上的最后一条边。 -
到源的距离:
distTo[v]是从 s 到 v 的最短路径的长度。
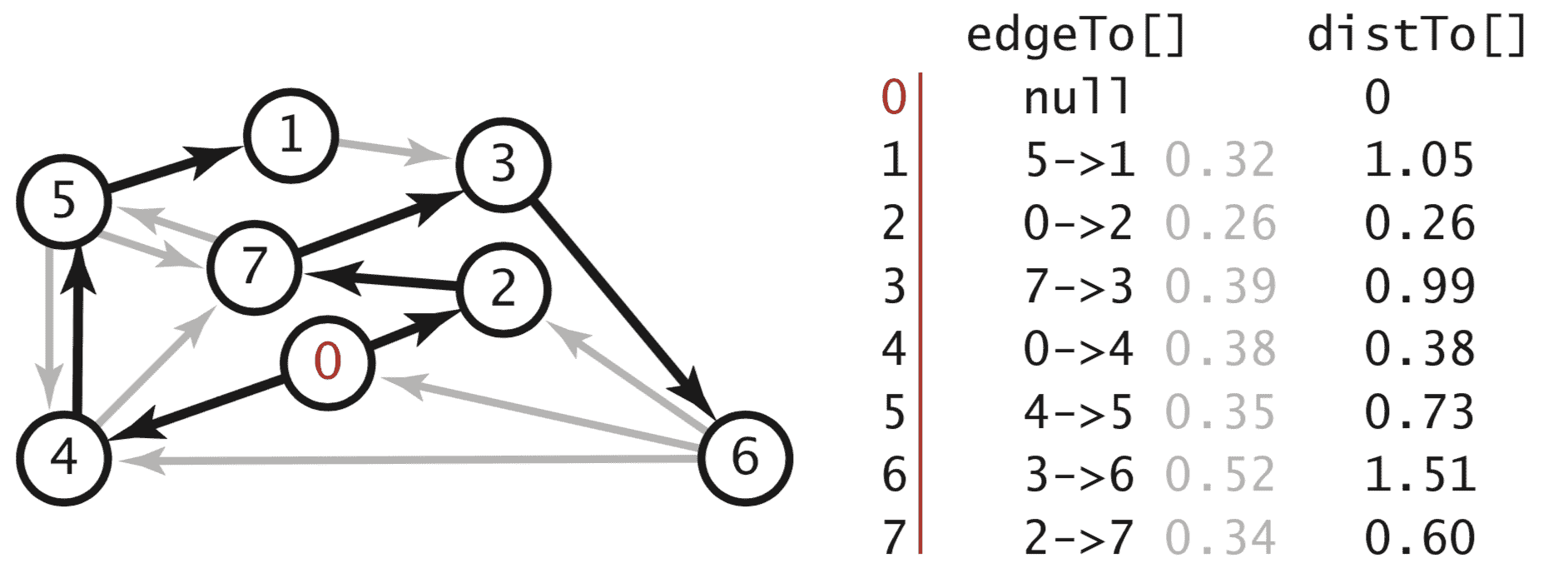
松弛。
我们的最短路径实现基于一种称为松弛的操作。我们将distTo[s]初始化为 0,对于所有其他顶点 v,将distTo[v]初始化为无穷大。
-
边松弛。 对边 v->w 进行松弛意味着测试从 s 到 w 的已知最佳路径是否是从 s 到 v,然后沿着从 v 到 w 的边,如果是,则更新我们的数据结构。
private void relax(DirectedEdge e) {int v = e.from(), w = e.to();if (distTo[w] > distTo[v] + e.weight()) {distTo[w] = distTo[v] + e.weight();edgeTo[w] = e;} }
-
顶点松弛。 我们所有的实现实际上都会松弛从给定顶点指向的所有边。
private void relax(EdgeWeightedDigraph G, int v) {for (DirectedEdge e : G.adj(v)) {int w = e.to();if (distTo[w] > distTo[v] + e.weight()) {distTo[w] = distTo[v] + e.weight();edgeTo[w] = e;}} }
迪杰斯特拉算法。
戴克斯特拉算法将dist[s]初始化为 0,将所有其他distTo[]条目初始化为正无穷。然后,它重复地放松并将具有最低distTo[]值的非树顶点添加到树中,继续直到所有顶点都在树上或没有非树顶点具有有限的distTo[]值。
DijkstraSP.java 是戴克斯特拉算法的高效实现。它使用 IndexMinPQ.java 作为优先队列。
命题。
戴克斯特拉算法使用额外空间与 V 成正比,时间与 E log V 成正比(在最坏情况下)解决了带非负权重的带权有向图中的单源最短路径问题。
无环带权有向图。
我们使用术语带权有向无环图来指代无环带权有向图。
-
带权有向无环图中的单源最短路径问题。我们现在考虑一种用于查找最短路径的算法,对于带权有向无环图而言,它比戴克斯特拉算法更简单且更快。
-
它在线性时间内解决了单源问题。
-
它处理负边权重。
-
它解决了相关问题,如查找最长路径。
该算法将顶点放松与拓扑排序结合起来。我们将
distTo[s]初始化为 0,将所有其他distTo[]值初始化为无穷大,然后按照拓扑顺序放松顶点。AcyclicSP.java 是这种方法的实现。它依赖于这个版本的 Topological.java,扩展以支持带权有向图。 -
-
带权有向无环图中的单源最长路径问题。我���可以通过将
distTo[]值初始化为负无穷大并在relax()中改变不等式的意义来解决带权有向无环图中的单源最长路径问题。AcyclicLP.java 实现了这种方法。 -
关键路径法。我们考虑并行的有前置约束的作业调度问题:给定一组指定持续时间的作业,其中有前置约束规定某些作业必须在某些其他作业开始之前完成,我们如何在相同数量的处理器上安排这些作业,以便它们在最短的时间内完成,同时仍然遵守约束条件?


通过将问题制定为带权有向无环图中的最长路径问题,可以解决此问题:创建一个带权有向无环图,其中包含一个源 s,一个汇 t,以及每个作业的两个顶点(一个起始顶点和一个结束顶点)。对于每个作业,从其起始顶点到其结束顶点添加一条权重等于其持续时间的边。对于每个前置约束 v->w,从对应于 v 的结束顶点到对应于 w 的开始顶点添加一条零权重边。还从源到每个作业的起始顶点和从每个作业的结束顶点到汇添加零权重边。
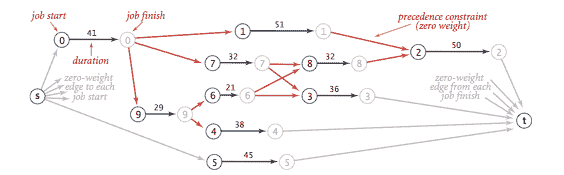
现在,根据从源到达的最长路径的长度安排每个作业的时间。
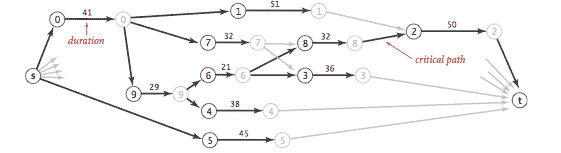
CPM.java 是关键路径法的实现。
命题。
通过按拓扑顺序放松顶点,我们可以在时间复杂度为 E + V 的情况下解决带权有向无环图的单源最短路径和最长路径问题。
一般带权有向图中的最短路径。
如果(i)所有权重为非负或(ii)没有循环,则可以解决最短路径问题。
-
负循环。负循环是一个总权重为负的有向循环。如果存在负循环,则最短路径的概念是没有意义的。
因此,我们考虑没有负循环的加权有向图。
-
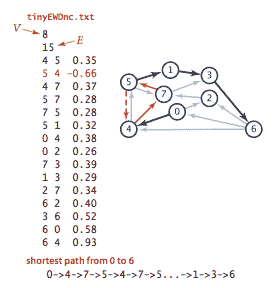
贝尔曼-福特算法。将
distTo[s]初始化为 0,将所有其他distTo[]值初始化为无穷大。然后,以任意顺序考虑有向图的边,并放松所有边。进行 V 次这样的遍历。for (int pass = 0; pass < G.V(); pass++)for (int v = 0; v < G.V(); v++)for (DirectedEdge e : G.adj(v))relax(e);我们不详细考虑这个版本,因为它总是放松 V E 条边。
-
基于队列的贝尔曼-福特算法。可能导致
distTo[]变化的唯一边是那些离开上一轮中distTo[]值发生变化的顶点的边。为了跟踪这样的顶点,我们使用一个 FIFO 队列。BellmanFordSP.java 通过维护两个额外的数据结构来实现这种方法:-
一个要放松的顶点队列
-
一个顶点索引的布尔数组
onQ[],指示哪些顶点在队列上,以避免重复
-
-
负循环检测。在许多应用中,我们的目标是检查并提取负循环。因此,我们向 API 添加以下方法:

当且仅当在所有边的第 V 次遍历后队列非空时,从源可达负循环。此外,我们
edgeTo[]数组中的边子图必须包含一个负循环。因此,为了实现negativeCycle(),BellmanFordSP.java 从edgeTo[]中的边构建一个加权有向图,并在该图中查找循环。为了找到循环,它使用 EdgeWeightedDirectedCycle.java,这是第 4.3 节中 DirectedCycle.java 的一个版本,适用于加权有向图。我们通过仅在每次第 V 次边放松后执行此检查来分摊此检查的成本。 -
套汇检测。考虑一个基于商品交易的金融交易市场。rates.txt 中的表显示了货币之间的转换率。文件的第一行是货币 V 的数量;然后文件每行给出货币的名称,然后是转换为其他货币的汇率。套汇机会是一个有向循环,使得交换率的乘积大于 1。例如,我们的表格显示,1000 美元可以购买 1000.00 × .741 = 741 欧元,然后我们可以用我们的欧元购买 741 × 1.366 = 1,012.206 加拿大元,最后,我们可以用我们的加拿大元购买 1,012.206 × .995 = 1,007.14497 美元,获得 7.14497 美元的利润!
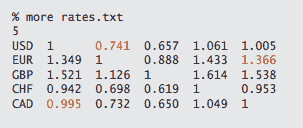

为了将套汇问题制定为负循环检测问题,将每个权重替换为其对数的负值。通过这种改变,在原问题中通过乘以边权重来计算路径权重对应于在转换后的问题中将它们相加。Arbitrage.java 通过解决相应的负循环检测问题来识别货币兑换网络中的套汇机会。
命题。
在加权有向图中,从 s 到 v 存在最短路径当且仅当从 s 到 v 存在至少一条有向路径,并且从 s 到 v 的任何有向路径上的顶点都不在负循环上。
命题。
贝尔曼-福特算法解决了给定源 s 的单源最短路径问题(或找到从 s 可达的负循环)对于具有 V 个顶点和 E 条边的任意加权有向图,在最坏情况下,时间复杂度为 E V,额外空间复杂度为 V。
问与答
Q. Dijkstra 算法能处理负权重吗?
A. 是和否。有两种已知的最短路径算法称为Dijkstra 算法,取决于一个顶点是否可以多次入队到优先队列。当权重为非负时,这两个版本是相同的(因为没有顶点会多次入队)。DijkstraSP.java 中实现的版本(允许一个顶点多次入队)在存在负边权(但没有负环)时是正确的,但其最坏情况下的运行时间是指数级的。(我们注意到 DijkstraSP.java 如果边权重为负数,则会抛出异常,以便程序员不会对这种指数级行为感到惊讶。)如果我们修改 DijkstraSP.java 以使一个顶点不能多次入队(例如,使用marked[]数组标记那些已经被松弛的顶点),那么算法保证在E log V时间内运行,但当存在负权边时可能产生错误结果。
练习
-
真或假。将每个边权重增加一个常数不会改变单源最短路径问题的解决方案。
解决方案。 假。
-
为 EdgeWeightedDigraph.java 提供
toString()的实现。 -
使用第 1.4 节的内存成本模型确定 EdgeWeightedDigraph.java 用于表示具有V个顶点和E条边的图所使用的内存量。
解决方案。 56 + 40V + 72E。MemoryOfEdgeWeightedDigraph.java 根据经验计算,假设没有缓存
Integer值 - Java 通常缓存-128 到 127 的整数。 -
从第 4.2 节中的
DirectedCycle和Topological类中使用本节的EdgeweightedDigraph和DirectedEdgeAPI,从而实现 EdgeWeightedDirectedCycle.java 和 Topological.java。 -
假设我们通过为
EdgeWeightedGraph中的每个Edge创建两个DirectedEdge对象(分别在每个方向上)来将EdgeWeightedGraph转换为EdgeWeightedDigraph,然后使用贝尔曼-福特算法。解释为什么这种方法会失败得惊人。解决方案: 即使带权图不包含负权重环,这可能会引入负成本循环。
-
如果在贝尔曼-福特算法的同一遍历中允许一个顶点被多次入队会发生什么?
答案: 算法的运行时间可能呈指数增长。例如,考虑所有边权重均为-1 的完全带权有向图会发生什么。
创意问题
-
有向无环图中的最长路径。 开发一个实现 AcyclicLP.java 的程序,可以解决带权有向无环图中的最长路径问题。
-
线上的所有对最短路径。 给定一个加权线图(无向连通图,所有顶点的度为 2,除了两个端点的度为 1),设计一个算法,在线性时间内预处理图,并能在常数时间内返回任意两个顶点之间最短路径的距离。
部分解决方案。 找到一个度为 1 的顶点 s,并运行广度优先(或深度优先)搜索以找到其余顶点出现的顺序。然后,计算从 s 到每个顶点 v 的最短路径长度,称为
dist[v]。顶点 v 和 w 之间的最短路径是|dist[v] - dist[w]|。 -
单调最短路径。 给定一个带权有向图,找到从 s 到每个其他顶点的单调最短路径。如果路径上每条边的权重要么严格递增要么严格递减,则路径是单调的。
部分解决方案: 按升序松弛边并找到最佳路径;然后按降序松弛边并找到最佳路径。
-
Dijkstra 算法的懒惰实现。 开发一个实现 LazyDijkstraSP.java 的 Dijkstra 算法的懒惰版本,该版本在文本中有描述。
-
Bellman-Ford 队列永不为空。 证明如果在基于队列的 Bellman-Ford 算法中从源可达到一个负循环,那么队列永远不会为空。
解决方案:考虑一个负循环,并假设对于循环 W 上的所有边,
distTo[w] <= distTo[v] + length(v, w)。对循环上的所有边进行这个不等式求和意味着循环的长度是非负的。 -
Bellman-Ford 负循环检测。 证明如果在通用 Bellman-Ford 算法的第 V 次遍历中有任何边被松弛,那么
edgeTo[]数组中就有一个有向循环,并且任何这样的循环都是负循环。解决方案:待定。
网络练习
-
最优子结构性质。 证明从 v 到 w 的最短路径上的每个子路径也是两个端点之间的最短路径。
-
唯一最短路径树。 假设从 s 到每个其他顶点都有唯一的最短路径。证明 SPT 是唯一的。
-
没有负循环。 证明如果通用算法终止,则从 s 可达的地方没有负循环。提示:在终止时,从 s 可达的所有边都满足
distTo[w] <= distTo[v] + e.weight()。将这个不等式对沿循环的所有边相加。 -
前驱图。 真或假。在没有负循环的边权重有向图中执行 Bellman-Ford 时,遵循
edgeTo[]数组总是会回到 s 的路径。对 Dijkstra 算法重复这个问题。 -
Yen 对 Bellman-Ford 的改进。 [参考] 将边分为两个 DAGs A 和 B:A 由从较低索引顶点到较高索引顶点的边组成;B 由从较高索引顶点到较低索引顶点的边组��。在 Bellman-Ford 的一个阶段中遍历所有边时,首先按顶点编号的升序(A 的拓扑顺序)遍历 A 中的边,然后按顶点编号的降序(B 的拓扑顺序)遍历 B 中的边。在遍历 A 中的边时,SPT 中从具有正确
distTo[]值的顶点开始并且仅使用 A 中的边的任何路径都会得到正确的distTo[]值;B 也是如此。所需的遍历次数是路径上 A-B 交替的最大次数,最多为(V+1)/2。因此,所需的遍历次数最多为(V+1)/2,而不是 V。 -
替换路径。 给定具有非负权重和源 s 以及汇 t 的边权重有向图,设计一个算法,找到从 s 到 t 的最短路径,该路径不使用每条边 e。你的算法的增长顺序应为 E V log V。
-
道路网络数据集。
-
来自DIMACS 挑战。这里是每个州的所有道路。
-
rome99.txt 是罗马的有向道路网络的大部分数据,来自DIMACS 挑战。该图包含 3353 个顶点和 8870 条边。顶点对应道路交叉口,边对应道路或道路段。边的权重是以米为单位的距离。
-
NYC.txt 是纽约市的无向道路网络。该图包含 264346 个顶点和 733846 条边。它是连通的,包含平行边,但没有自环。边的权重是旅行时间,且严格为正。
-
-
互联网路由。 OSPF(开放最短路径优先)是互联网路由中广泛使用的协议,使用了迪杰斯特拉算法。RIP(路由信息协议)是另一种基于贝尔曼-福特算法的路由协议。
-
具有跳过一条边的最短路径。 给定具有非负权重的边权重有向图,设计一个 E log V 算法,用于找到从 s 到 t 的最短路径,其中您可以将任意一条边的权重更改为 0。
解决方案。 计算从 s 到每个其他顶点的最短路径;计算从每个顶点到 t 的最短路径。对于每条边 e = (v, w),计算从 s 到 v 的最短路径长度和从 w 到 t 的最短路径长度的和。最小的这样的和提供了最短的这样的路径。
-
无向图中的最短路径。 编写一个程序 DijkstraUndirectedSP.java,使用迪杰斯特拉算法解决非负权重的无向图中的单源最短路径问题。
-
弗洛伊德-沃舍尔算法。 FloydWarshall.java 实现了弗洛伊德-沃舍尔算法,用于全对最短路径问题。其时间复杂度与 V³ 成正比,空间复杂度与 V² 成正比。它使用了 AdjMatrixEdgeWeightedDigraph.java。
-
随机贝尔曼-福特算法。 [参考资料] 假设我们在 Yen 算法中均匀随机选择顶点顺序(其中 A 包含所有从排列中较低顶点到较高顶点的边)。证明预期的通过次数最多为(V+1)/3。
-
苏尔巴勒算法。 给定具有非负边权重和两个特殊顶点 s 和 t 的有向图,找到从 s 到 t 的两条边不相交的路径,使得这两条路径的权重之和最小。
解决方案。 这可以通过巧妙地应用迪杰斯特拉算法来实现,即苏尔巴勒算法。
5. 字符串
原文:
algs4.cs.princeton.edu/50strings译者:飞龙
协议:CC BY-NC-SA 4.0
概述。
我们通过交换字符串来进行通信。我们考虑经典算法来解决围绕以下应用程序的基本计算挑战:
-
5.1 字符串排序 包括 LSD 基数排序、MSD 基数排序和用于对字符串数组进行排序的三向基数快速排序。
-
5.2 Trie 描述了用于实现具有字符串键的符号表的 R-way trie 和三向搜索 trie。
-
5.3 子字符串搜索 描述了在大段文本中搜索子字符串的算法,包括经典的 Knuth-Morris-Pratt、Boyer-Moore 和 Rabin-Karp 算法。
-
5.4 正则表达式 介绍了一种称为 grep 的基本搜索工具,我们用它来搜索不完全指定的子字符串。
-
5.5 数据压缩 介绍了数据压缩,我们试图将字符串的大小减少到最小。我们介绍了经典的 Huffman 和 LZW 算法。
游戏规则。
为了清晰和高效,我们的实现是基于 Java String 类表达的。我们简要回顾它们最重要的特性。
-
字符.
String是字符序列。字符的类型是char,可以有 2¹⁶ 种可能的值。几十年来,程序员们一直关注编码为 7 位 ASCII 或 8 位扩展 ASCII 的字符,但许多现代应用程序需要 16 位 Unicode。 -
不可变性.
String对象是不可变的,因此我们可以在赋值语句中使用它们,并且作为方法的参数和返回值,而不必担心它们的值会改变。 -
索引.
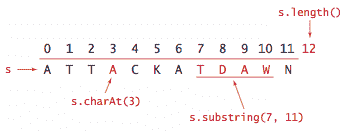
charAt()方法以常数时间从字符串中提取指定字符。 -
长度.
length()方法以常数时间返回字符串的长度。 -
子字符串.
substring()方法通常以常数时间提取指定的子字符串。警告:从 Oracle 和 OpenJDK Java 7,更新 6 开始,
substring()方法在提取的子字符串大小上需要线性时间和空间。由于我们没有预料到这种 drastical 变化,我们的一些字符串处理代码将受到影响。String API 对其任何方法,包括substring()和charAt(),都不提供性能保证。教训是自行承担风险。查看这篇文章获取更多细节。
-
连接.
+运算符执行字符串连接。我们避免逐个字符附加形成字符串,因为在 Java 中这是一个 二次时间 的过程。(Java 有一个 StringBuilder 类用于这种用途。) -
字符数组. Java 的
String不是原始类型。标准实现提供了上述操作,以便于客户端编程。相比之下,我们考虑的许多算法可以使用低级表示,比如一个char值数组,许多客户端可能更喜欢这种表示,因为它占用更少的空间并且耗时更少。
字母表。
一些应用程序涉及从受限字母表中获取的字符串。在这种应用程序中,使用具有以下 API 的 Alphabet.java 类通常是有意义的:
构造函数以 R 个字符的字符串作为参数,该字符串指定了字母表;toChar()和toIndex()方法在常数时间内在字符串字符和介于 0 和 R-1 之间的int值之间进行转换。R()方法返回字母表或基数中的字符数。包括一些预定义的字母表:

Count.java 是一个客户端程序,它在命令行上指定一个字母表,读取该字母表上的一系列字符(忽略不在字母表中的字符),计算每个字符出现的频率,
本章中的 Java 程序。
以下是本章中的 Java 程序列表。单击程序名称以访问 Java 代码;单击参考号以获取简要描述;阅读教科书以获取全面讨论。
REF 程序 描述 / JAVADOC - Alphabet.java 字母表 - Count.java 字母表客户端 5.1 LSD.java LSD 基数排序 5.2 MSD.java MSD 基数排序 - InplaceMSD.java 原地 MSD 基数排序¹ 5.3 Quick3string.java 三向字符串快速排序 - AmericanFlag.java 美国国旗排序¹ - AmericanFlagX.java 非递归美国国旗排序¹ 5.4 TrieST.java 多向字典树符号表 - TrieSET.java 多向字典树集合 5.5 TST.java 三向单词查找树 5.6 KMP.java 子字符串查找(Knuth–Morris–Pratt) 5.7 BoyerMoore.java 子字符串查找(Boyer–Moore) 5.8 RabinKarp.java 子字符串查找(Rabin–Karp) 5.9 NFA.java 正则表达式的 NFA - GREP.java grep - BinaryDump.java 二进制转储 - HexDump.java 十六进制转储 - PictureDump.java 图片转储 - Genome.java 基因组编码 - RunLength.java 数据压缩(行程长度编码) 5.10 Huffman.java 数据压缩(赫夫曼) 5.11 LZW.java 数据压缩(Lempel–Ziv–Welch)
Q + A
Q. 什么是 Unicode。
A. Unicode(通用字符编码)= 复杂的 21 位代码,用于表示国际符号和其他字符。
Q. 什么是 UTF-16。
A. UTF-16(Unicode 转换格式)= 复杂的 16 位可变宽度代码,用于表示 Unicode 字符。大多数常见字符使用 16 位(一个char)表示,但代理对使用一对char值表示。如果第一个char值在D800和DFFF之间,则与下一个char(在相同范围内)组合形成代理对。没有 Unicode 字符对应于D800到DFFF。例如,007A表示小写字母 Z,6C34表示中文水的符号,D834 DD1E表示音乐的 G 大调。
Unicode 参考。
Q. 什么是子字符串陷阱?
A. 字符串方法调用s.substring(i, j)返回 s 从索引 i 开始到 j-1 结束的子字符串(而不是在 j 结束,正如你可能会怀疑的那样)。
Q. 如何更改字符串的值?
A. 在 Java 中无法修改字符串,因为字符串是不可变的。如果你想要一个新的字符串,那么你必须使用字符串连接或返回新字符串的字符串方法之一,如toLowerCase()或substring()来创建一个新的字符串。
网页练习
-
**挤压空格。**编写一个程序 Squeeze.java,该程序接受一个字符串作为输入,并删除相邻的空格,最多保留一个空格。
-
**删除重复项。**给定一个字符串,创建一个新字符串,其中删除所有连续的重复项。例如,
ABBCCCCCBBAB变为ABCBAB。 -
**N 个 x 的字符串。**描述以下函数返回的字符串,给定一个正整数
N?public static String mystery(int N) {String s = "";while(N > 0) {if (N % 2 == 1) s = s + s + "x";else s = s + s;N = N / 2;}return s; } -
**回文检查。**编写一个函数,该函数以字符串作为输入,并在字符串是回文时返回
true,否则返回false。回文是指字符串从前往后读和从后往前读是相同的。 -
**Watson-Crick 互补回文检查。**编写一个函数,该函数以字符串作为输入,并在字符串是 Watson-Crick 互补回文时返回
true,否则返回false。Watson-Crick 互补回文是指 DNA 字符串等于其反向的互补(A-T,C-G)。 -
**Watson-Crick 互补。**编写一个函数,该函数以 A、C、G 和 T 字符的 DNA 字符串作为输入,并返回以其互补替换所有字符的反向字符串。例如,如果输入是 ACGGAT,则返回 ATCCGT。
-
**完美洗牌。**给定长度相同的两个字符串
s和t,以下递归函数返回什么?public static String mystery(String s, String t) {int N = s.length();if (N <= 1) return s + t;String a = mystery(s.substring(0, N/2), t.substring(0, N/2));String b = mystery(s.substring(N/2, N), t.substring(N/2, N));return a + b; } -
**二叉树表示。**编写一个名为
TreeString.java的数据类型,使用二叉树表示不可变字符串。它应该支持在常数时间内进行连接,并在与字符数成比例的时间内打印出字符串。 -
**反转字符串。**编写一个递归函数来反转一个字符串。不要使用任何循环。提示:使用 String 方法
substring()。public static String reverse(String s) {int N = s.length();if (N <= 1) return s;String a = s.substring(0, N/2);String b = s.substring(N/2, N);return reverse(b) + reverse(a); }你的方法效率如何?我们的方法具有线性对数运行时间。
-
**随机字符串。**编写一个递归函数,创建一个由字符’A’和’Z’之间的随机字符组成的字符串。
public static String random(int N) {if (N == 0) return "";if (N == 1) return 'A' + StdRandom.uniform(26);return random(N/2) + random(N - N/2); } -
**子序列。**给定两个字符串
s和t,编写一个程序 Subsequence.java,确定s是否是t的子序列。也就是说,s的字母应该按照相同的顺序出现在t中,但不一定是连续的。例如accag是taagcccaaccgg的子序列。 -
最长互补回文。 在 DNA 序列分析中,互补回文是一个等于其反向互补的字符串。腺嘌呤(A)和胸腺嘧啶(T)是互补的,胞嘧啶(C)和鸟嘌呤(G)也是互补的。例如,ACGGT 是一个互补回文。这样的序列作为转录结合位点,并与基因扩增和遗传不稳定性相关。给定一个长度为 N 的文本输入,找到文本的最长互补回文子串。例如,如果文本是
GACACGGTTTTA,那么最长的互补回文是ACGGT。提示:将每个字母视为奇数长度可能回文的中心,然后将每对字母视为偶数长度可能回文的中心。 -
DNA 转 RNA。 编写一个函数,该函数接受一个 DNA 字符串(A、C、G、T)并返回相应的 RNA 字符串(A、C、G、U)。
-
DNA 互补。 编写一个函数,该函数以 DNA 字符串(A、C、G、T)作为输入,并返回互补的碱基对(T、G、C、A)。DNA 通常以双螺旋结构存在。两条互补的 DNA 链以螺旋结构连接在一起。
-
从十六进制转换为十进制。 Hex2Decimal.java 包含一个函数,该函数接受一个十六进制字符串(使用 A-F 表示数字 11-15)并返回相应的十进制整数。它使用了一些字符串库方法和霍纳方法。
public static int hex2decimal(String s) {String digits = "0123456789ABCDEF"; s = s.toUpperCase();int val = 0;for (int i = 0; i < s.length(); i++) {char c = s.charAt(i);int d = digits.indexOf(c);val = 16*val + d;}return val; }替代方案:
Integer.parseInt(String s, int radix)。更加健壮,并且适用于负整数。
5.1 字符串排序
原文:
algs4.cs.princeton.edu/51radix译者:飞龙
协议:CC BY-NC-SA 4.0
本节正在大规模施工中。
LSD 基数排序。
程序 LSD.java 实现了用于固定长度字符串的 LSD 基数排序。它包括一种用于对待每个整数作为 4 字节字符串处理的 32 位整数进行排序的方法。当 N 很大时,这种算法比系统排序快 2-3 倍。
MSD 基数排序。
程序 MSD.java 实现了 MSD 基数排序。
三向字符串快速排序。
程序 Quick3string.java 实现了三向字符串快速排序。
问与答
练习
-
频率计数。 读入一个字符串列表并打印它们的频率计数。算法:将字符串读入数组,使用三向基数快速排序对它们进行排序,并计算它们的频率计数。加速奖励:在三向分区期间计算计数。缺点:使用空间存储所有字符串。备选方案:TST。
-
对均匀分布数据进行排序。 给定 N 个来自 [0, 1] 区间的随机实数,考虑以下算法对它们进行排序:将 [0, 1] 区间分成 N 个等间距子区间。重新排列(类似于累积计数)这 N 个元素,使每个元素都在其适当的桶中。对每个桶中的元素进行插入排序(或者等效地,只对整个文件进行插入排序)。也就是说,对一个级别进行 MSD 基数排序,然后切换到插入排序。[尝试原地进行?] 解决方案:平均总共需要 O(N) 的时间。设 n_i 是桶 i 中的元素数量。插入排序所有桶的预期时间是 O(n),因为 E[sum_i (n_i)²] <= 2n。
-
给定一个包含 N 个不同长度的十进制整数的数组,描述如何在 O(N + K) 的时间内对它们进行排序,其中 K 是所有 N 个整数的总位数。
-
美国国旗排序。(原地键索引计数)给定一个包含 N 个介于 0 和 R-1 之间的不同值的数组,以线性时间和 O® 的额外空间对它们进行升序排列。导致(本质上)原地字符串排序。
提示:计算
count[]数组,告诉你键需要放置的位置。扫描输入数组。取第一个键,找到它应该属于的桶,并将其交换到相应的位置(更新相应的count[]条目)。重复第二个键,但要小心跳过已知属于其位置的键。
网络练习
-
2-sum. 给定一个包含 N 个 64 位整数的数组
a[]和一个目标值 T,确定是否存在两个不同的整数 i 和 j,使得a[i]+a[j]等于 T。你的算法应该在最坏情况下线性时间运行。解决方案。在线性时间内对数组进行基数排序。从左到右扫描指针 i 和从右到左扫描指针 j:考虑 a[i] + a[j]。如果它大于 T,则推进 j 指针;如果它小于 T,则推进 i 指针;如果它等于 T,则我们找到了所需的索引。
注意,整数数组可以使用 Franceschini、Muthukrishnan 和 Patrascu 的高级基数排序算法在线性时间和常数额外空间内进行基数排序。
-
在排序的字符串数组中进行二分查找。 实现一个用于排序字符串数组的二分查找版本,它跟踪查询字符串与 lo 和 hi 端点之间已知相同字符的数���。利用这些信息在二分查找过程中避免字符比较。比较此算法与调用
compareTo()的版本的性能。(compareTo()方法的优点是它不需要调用charAt(),因为它是作为String数据类型的实例方法实现的。)
5.2 查找树
原文:
algs4.cs.princeton.edu/52trie译者:飞龙
协议:CC BY-NC-SA 4.0
本节正在大规模建设中。
具有字符串键的符号表。
可以使用标准符号表实现。而是利用字符串键的附加结构。为字符串(以及其他以数字表示的键)定制搜索算法。目标:像哈希一样快速,比二叉搜索树更灵活。可以有效地支持额外的操作,包括前缀和通配符匹配,例如,IP 路由表希望转发到 128.112.136.12,而实际上转发到 128.112 是它已知的最长匹配前缀。附带好处:快速且占用��间少的字符串搜索。
R 向查找树。 程序 TrieST.java 使用多向查找树实现了一个字符串符号表。
三向查找树。 程序 TST.java 使用三向查找树实现了一个字符串符号表。
参考:快速排序和搜索的算法 作者 Bentley 和 Sedgewick。
属性 A.(Bentley-Sedgewick)给定一个输入集,无论字符串插入的顺序如何,其 TST 中的节点数都是相同的。
证明。在集合中,TST 中每个不同字符串前缀都有一个唯一的节点。节点在 TST 中的相对位置可能会根据插入顺序而改变,但节点数是不变的。
高级操作。
通配符搜索,前缀匹配。R 向查找树和 TST 实现包括用于通配符匹配和前缀匹配的代码。
惰性删除 = 更改单词边界位。急切删除 = 清理任何死亡父链接。
应用:T9 手机文本输入。用户使用手机键盘键入;系统显示所有对应的单词(并在唯一时自动完成)。如果用户键入 0,系统会显示所有可能的自动完成。
问答
练习
-
编写 R 向查找树字符串集和 TST 的非递归版本。
-
长度为 L 的唯一子字符串。 编写一个程序,从标准输入中读取文本并计算其包含的长度为 L 的唯一子字符串的数量。例如,如果输入是
cgcgggcgcg,那么长度为 3 的唯一子字符串有 5 个:cgc、cgg、gcg、ggc和ggg。应用于数据压缩。提示:使用字符串方法substring(i, i + L)提取第 i 个子字符串并插入符号表。另一种解决方案:使用第 i 个子字符串的哈希值计算第 i+1 个子字符串的哈希值。在第一千万位数的π或者第一千万位数的π上测试它。 -
唯一子字符串。 编写一个程序,从标准输入中读取文本并计算任意长度的不同子字符串的数量。(可以使用后缀树非常高效地完成。)
-
文档相似性。 要确定两个文档的相似性,计算每个三字母组(3 个连续字母)的出现次数。如果两个文档的三字母组频率向量的欧几里德距离很小,则它们相似。
-
拼写检查。 编写一个程序 SpellChecker.java,它接受一个包含英语词汇的字典文件的名称,然后从标准输入读取字符串并打印出不在字典中的任何单词。使用一个字符串集。
-
垃圾邮件黑名单。 将已知的垃圾邮件地址插入到存在表中,并用于阻止垃圾邮件。
-
按国家查找 IP。 使用数据文件ip-to-country.csv来确定给定 IP 地址来自哪个国家。数据文件有五个字段(IP 地址范围的开始,IP 地址范围的结束,两个字符的国家代码,三个字符的国家代码和国家名称。请参阅IP-to-country 网站。IP 地址不重叠。这样的数据库工具可用于:信用卡欺诈检测,垃圾邮件过滤,网站上语言的自动选择以及 Web 服务器日志分析。
-
Web 的倒排索引。 给定一个网页列表,创建包含网页中包含的单词的符号表。将每个单词与出现该单词的网页列表关联起来。编写一个程序,读取一个网页列表,创建符号表,并通过返回包含该查询单词的网页列表来支持单词查询。
-
Web 的倒排索引。 扩展上一个练习,使其支持多词查询。在这种情况下,输出包含每个查询词至少出现一次的网页列表。
-
带有重复项的符号表。
-
密码检查器。 编写一个程序,从命令行读取一个字符串和从标准输入读取一个单词字典,并检查它是否是一个“好”密码。在这里,假设“好”意味着(i)至少有 8 个字符长,(ii)不是字典中的单词,(iii)不是字典中的单词后跟一个数字 0-9(例如,hello5),(iv)不是由一个数字分隔的两个单词(例如,hello2world)。
-
反向密��检查器。 修改上一个问题,使得(ii)-(v)也适用于字典中单词的反向形式(例如,olleh 和 olleh2world)。巧妙的解决方案:将每个单词及其反向形式插入符号表中。
-
随机电话号码。 编写一个程序,接受一个命令行输入 N,并打印 N 个形式为(xxx)xxx-xxxx 的随机电话号码。使用符号表避免多次选择相同的号码。使用这个区号列表来避免打印虚假的区号。使用 R 向 Trie。
-
包含前缀。 向
StringSET添加一个方法containsPrefix(),接受字符串 s 作为输入,并在集合中存在包含 s 作为前缀的字符串时返回 true。 -
子字符串匹配。 给定一个(短)字符串列表,您的目标是支持查询,其中用户查找字符串 s,您的任务是报告列表中包含 s 的所有字符串。提示:如果您只想要前缀匹配(字符串必须以 s 开头),请使用文本中描述的 TST。要支持子字符串匹配,请将每个单词的后缀(例如,string,tring,ring,ing,ng,g)插入 TST 中。
-
Zipf 定律。 哈佛语言学家乔治·齐普夫观察到,包含 N 个单词的英文文本中第 i 个最常见单词的频率大致与 1/i 成比例,其中比例常数为 1 + 1/2 + 1/3 + … + 1/N。通过从标准输入读取一系列单词,制表它们的频率,并与预测的频率进行比较来测试“齐普夫定律”。
-
打字猴和幂律。(Micahel Mitzenmacher)假设一个打字猴通过将每个 26 个可能的字母以概率 p 附加到当前单词来创建随机单词,并以概率 1 - 26p 完成单词。编写一个程序来估计生成的单词长度的频率分布。如果“abc”被生成多次,则只计算一次。
-
打字猴和幂律。 重复上一个练习,但假设字母 a-z 出现的概率与以下概率成比例,这是英文文本的典型概率。
CHAR FREQ CHAR FREQ CHAR FREQ CHAR FREQ CHAR FREQ A 8.04 G 1.96 L 4.14 Q 0.11 V 0.99 B 1.54 H 5.49 M 2.53 R 6.12 W 1.92 C 3.06 I 7.26 N 7.09 S 6.54 X 0.19 D 3.99 J 0.16 O 7.60 T 9.25 Y 1.73 E 12.51 K 0.67 P 2.00 U 2.71 Z 0.09 F 2.30 -
书的索引。 编写一个程序,从标准输入中读取一个文本文件,并编制一个按字母顺序排列的索引,显示哪些单词出现在哪些行,如下所示的输入。忽略大小写和标点符号。
It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness,age 3-4 best 1 foolishness 4 it 1-4 of 1-4 the 1-4 times 1-2 was 1-4 wisdom 4 worst 2 -
熵。 我们定义一个包含 N 个单词的文本语料库的相对熵为 E = 1 / (N log N) * sum (p[i] log(k) - log(p[i]), i = 1…k),其中 p_i 是单词 i 出现的次数的比例。编写一个程序,读取一个文本语料库并打印出相对熵。将所有字母转换为小写,并将标点符号视为空格。
-
最长前缀。 真或假。二进制字符串 x 在符号表中的最长前缀要么是 x 的下取整,要么是 x 的上取整(如果 x 在集合中则两者都是)。
错误。在 { 1, 10, 1011, 1111 } 中,1100 的最长前缀是 1,而不是 1011 或 1111。
创意练习
网页练习
5.3 �� 子字符串搜索
原文:
algs4.cs.princeton.edu/53substring译者:飞龙
协议:CC BY-NC-SA 4.0
本节正在大规模施工中。在长字符串中搜索 - 在线。
这个网站是一个关于精确字符串搜索算法的重要资源。
Java 中的高性能模式匹配用于一般字符串搜索,带通配符的搜索和带字符类的搜索。
程序 Brute.java 是暴力字符串搜索。基本上等同于 SystemSearch.java。
拉宾卡普。
程序 RabinKarp.java 实现了拉宾卡普随机指纹算法。
Knuth-Morris-Pratt。
程序 KMP.java 是 Knuth-Morris-Pratt 算法。KMPplus.java 是一个改进版本,时间和空间复杂度与 M + N 成正比(与字母表大小 R 无关)。
Boyer-Moore。
程序 BoyerMoore.java 实现了 Boyer-Moore 算法的坏字符规则部分。它不实现强好后缀规则。
入侵检测系统。
需要非常快速的字符串搜索,因为这些部署在网络的瓶颈处。应用
问答
练习
-
设计一个从右到左扫描模式的暴力子字符串搜索算法。
-
展示 Brute-Force 算法的跟踪,样式类似于图 XYZ,用于以下模式和文本字符串。
-
AAAAAAAB; AAAAAAAAAAAAAAAAAAAAAAAAB
-
ABABABAB; ABABABABAABABABABAAAAAAAA
-
-
确定以下模式字符串的 KMP DFA。
-
AAAAAAAB
-
AACAAAB
-
ABABABAB
-
ABAABAAABAAAB
-
ABAABCABAABCB
-
-
假设模式和文本是在大小为 R >= 2 的字母表上的随机字符串。证明字符比较的期望次数为(N - M + 1) (1 - R^-M) / (1 - R^-1) <= 2 (N - M + 1)。
-
构造一个例子,其中 Boyer-Moore 算法(仅使用坏字符规则)性能较差。
-
如何修改拉宾卡普算法以搜索给定模式,并附加条件中间字符是一个“通配符”(任何文本字符都可以匹配它)。
-
如何修改拉宾卡普算法以确定文本中是否存在 k 个模式子集中的任何一个(比如,所有长度相同)?
解决方案。 计算 k 个模式的哈希值,并将哈希值存储在一个集合中。
-
如何修改拉宾卡普算法以在 N×N 文本中搜索 M×M 模式?或者在 N×N 文本中搜索其他不规则形状的模式?
-
蒙特卡洛与拉斯维加斯拉宾卡普。
-
在线回文检测。 逐个读入字符。报告每个瞬间当前字符串是否是回文。提示:使用 Karp-Rabin 哈希思想。
-
串联重复。 在字符串 s 中,基本字符串 b 的串联重复是由至少一个连续的基本字符串 b 的副本组成的子字符串。给定 b 和 s,设计一个算法,在 s 中找到 b 的最大长度的串联重复。运行时间应与 M + N 成正比,其中 M 是 b 的长度,N 是 s 的长度。
解决方案。 这个问题是子字符串搜索的一般化(s 中是否至少有一个连续的 b 的副本?),所以我们需要一个泛化的子字符串搜索算法。创建 k 个 b 的连接副本的 Knuth-Morris-Pratt DFA,其中 k = n/m。现在,在输入 s 上模拟 DFA 并记录它达到的最大状态。从中,我们可以识别最长的串联重复。
-
后缀前缀匹配。 设计一个线性时间算法,找到一个字符串a的最长后缀,恰好匹配另一个字符串b的前缀。
-
循环旋转。 设计一个线性时间算法来确定一个字符串是否是另一个字符串的循环旋转。如果字符串a是字符串b的循环旋转,那么a和b具有相同的长度,a由b的后缀和前缀组成。
-
循环字符串的子串。 设计一个线性时间算法来确定一个字符串 a 是否是循环字符串 b 的子串。
-
最长回文子串。 给定一个字符串 s,找到最长的回文子串(或 Watson-crick 回文串)。解决方案:可以使用后缀树或Manacher’s algorithm在线性时��内解决。这里有一个通常在线性对数时间内运行的更简单的解决方案。首先,我们描述如何在线性时间内找到长度恰好为 L 的所有回文子串:使用 Karp-Rabin 迭代地形成每个长度为 L 的子串(及其反转)的哈希值,并进行比较。由于你不知道 L,重复将你对 L 的猜测加倍,直到你知道最佳长度在 L 和 2L 之间。然后使用二分查找找到确切的长度。
解决方案。 Manacher.java 是 Manacher 算法的实现。
-
重复子串。 [ Mihai Patrascu] 给定一个整数 K 和长度为 N 的字符串,找到至少出现 K 次的最长子串。
一个解决方案。 假设你知道重复字符串的长度 L。对长度为 L 的每个子串进行哈希处理,并检查任何哈希是否出现 K 次或更多。如果是,检查以确保你没有运气不佳。由于你不知道 L,重复将你对 L 的猜测加倍,直到你知道最佳长度在 L 和 2L 之间。然后使用二分查找找到正确的值。
-
最长公共子串。 给定两个(或三个)字符串,找到在所有三个字符串中都出现的最长子串。提示:假设你知道最长公共子串的长度 L。对长度为 L 的每个子串进行哈希处理,并检查任何哈希桶是否包含每个字符串的(至少)一个条目。
-
所有匹配。 修改 KMP 以在线性时间内找到所有匹配(而不是最左匹配)。
-
斐波那契字符串。 KMP 的有趣案例。F(1) = B, F(2) = A, F(3) = AB, F(4) = ABA, F(5) = ABAAB, F(N) = F(N-1) F(N-2)。
-
假设 x 和 y 是两个字符串。设计一个线性时间算法来确定是否存在整数 m 和 n 使得 x^m = y^n(其中 x^m 表示 x 的 m 个副本的连接)。
解决方案。 只需检查 xy = yx 的位置(这个事实并不平凡 - 它来自于 Lyndon-Schutzenberger 定理)。
-
字符串的周期。 让 s 为一个非空字符串。如果对于所有 i = 0, 1, …, N-p-1 都有 s[i] = s[i+p],则整数 p 被称为 s 的周期。字符串 s 的周期是是 s 的周期中最小的整数 p(可以是 N)。例如,ABCABCABCABCAB 的周期是 3。设计一个线性时间算法来计算字符串的周期。
-
字符串的边界。 给定一个非空字符串 s,如果 s = yw = wz 对于一些字符串 y、z 和 w 且 |y| = |z| = p,则我们将字符串 w 定义为 s 的边界,即 w 是 s 的既是前缀又是后缀的一个合适子串。字符串的边界是 s 的最长合适边界(可以为空)。例如,ABCABCABCABCAB 的边界是 w = ABCABCAB(其中 y = ABC,z = CAB,p = 3)。设计一个线性时间算法来计算字符串的边界。
-
变位词子串搜索。 给定长度为 N 的文本字符串 txt[] 和长度为 M 的模式字符串 pat[],确定 pat[] 或其任何变位词(其 M! 种排列之一)是否出现在文本中。
提示:在文本中维护长度为 M 的给定子串的字母频率直方图。
5.4 正则表达式
原文:
algs4.cs.princeton.edu/54regexp译者:飞龙
协议:CC BY-NC-SA 4.0
本节正在大力整理中。
正则表达式。
NFA.java, DFS.java, Digraph.java, 和 GREP.java.
运行时间。
M = 表达式长度,N = 输入长度。正则表达式匹配算法可以在 O(M)时间内创建 NFA,并在 O(MN)时间内模拟输入。
库实现。
Validate.java。
大多数正则表达式库实现使用回溯算法,在某些输入上可能需要指数级的时间。这样的输入可能非常简单。例如,确定长度为 N 的字符串是否与正则表达式(a|aa)*b匹配,如果选择字符串得当,可能需要指数级的时间。下表展示了 Java 1.4.2 正则表达式的失败情况。
java Validate "(a|aa)*b" aaaaaaaaaaaaaaaaaaaaaaaaaaaaaac 1.6 seconds
java Validate "(a|aa)*b" aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaac 3.7 seconds
java Validate "(a|aa)*b" aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaac 9.7 seconds
java Validate "(a|aa)*b" aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaac 23.2 seconds
java Validate "(a|aa)*b" aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaac 62.2 seconds
java Validate "(a|aa)*b" aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaac 161.6 secondsjava Validate "(a*)*|b*" aaaaaaaaaaaaaaaaaaaaac 1.28
java Validate "(a*)*|b*" aaaaaaaaaaaaaaaaaaaaaac 2.45
java Validate "(a*)*|b*" aaaaaaaaaaaaaaaaaaaaaaac 4.54
java Validate "(a*)*|b*" aaaaaaaaaaaaaaaaaaaaaaaac 8.84
java Validate "(a*)*|b*" aaaaaaaaaaaaaaaaaaaaaaaaac 17.74
java Validate "(a*)*|b*" aaaaaaaaaaaaaaaaaaaaaaaaaac 33.77
java Validate "(a*)*|b*" aaaaaaaaaaaaaaaaaaaaaaaaaaac 67.72
java Validate "(a*)*|b*" aaaaaaaaaaaaaaaaaaaaaaaaaaaac 134.73上述示例是人为的,但它们展示了大多数正则表达式库中的一个令人担忧��缺陷。在实践中确实会出现不良输入。根据Crosby 和 Wallach的说法,以下正则表达式出现在 SpamAssassin 的一个版本中,这是一个功能强大的垃圾邮件过滤程序。
[a-z]+@[a-z]+([a-z\.]+\.)+[a-z]+它试图匹配某些电子邮件地址,但在许多正则表达式库中,包括 Sun 的 Java 1.4.2 中,匹配某些字符串需要指数级的时间。
java Validate "[a-z]+@[a-z]+([a-z\.]+\.)+[a-z]+" spammer@x......................这尤其重要,因为垃圾邮件发送者可以使用一种病态的返回电子邮件地址来拒绝服务攻击一个运行 SpamAssassin 的邮件服务器。这个特定的模式现在已经修复,因为 Perl 5 正则表达式使用内部缓存来在回溯过程中在相同位置短路重复匹配。
这些缺陷不仅限于 Java 的实现。例如,GNU regex-0.12 对于匹配形式为aaaaaaaaaaaaaac的字符串与正则表达式(a*)*|b*需要指数级的时间。Sun 的 Java 1.4.2 同样容易受到这个问题的影响。此外,Java 和 Perl 正则表达式支持反向引用 - 对于这些扩展正则表达式的正则表达式模式匹配问题是NP 难的,因此在某些输入上这种指数级的增长似乎是固有的。
这是我实际写的一个,用来找到字符串NYSE之前的最后一个单词:regexp = “([\w\s]+).*NYSE”;
参考:正则表达式匹配可以简单快速(但在 Java、Perl、PHP、Python、Ruby 等中很慢)。比较了 Thompson NFA 和回溯方法。包含了一些针对 Thompson NFA 的性能优化。还有一些历史注释和参考资料。
Q + A
Q. Java 正则表达式库的文档?
A. 这里是 Oracle 关于使用正则表达式的指南。它包括更多操作,我们不会探索。还请参阅String方法matches()、split()和replaceAll()。这些是使用Pattern和Matcher类的简写。这里有一些常见的正则表达式模式。
Q. 用于电子邮件地址、Java 标识符、整数、小数等的工业级别正则表达式?
A. 这里有一个有用的正则表达式库,提供了工业级别的模式,用于匹配电子邮件地址、URL、数字、日期和时间。试试这个正则表达式工具。
Q. 我困惑为什么(a | b)*匹配所有的 a 和 b 的字符串,而不仅仅是所有 a 的字符串或所有 b 的字符串?
A. *操作符复制正则表达式(而不是匹配正则表达式的固定字符串)。因此,上述等同于ε | (a|b) | (a|b)(a|b) | (a|b)(a|b)(a|b) | …
Q. 历史?
A. 在 1940 年代,沃伦·麦卡洛克和沃尔特·皮茨将神经元建模为有限自动机来描述神经系统。1956 年,史蒂夫·克利纳发明了一种数学抽象称为正则集来描述这些模型。神经网络和有限自动机中事件的表示,《自动机研究》,3-42 页,普林斯顿大学出版社,新泽西州普林斯顿,1956 年。
Q. 有哪些可视化正则表达式的工具?
A. 尝试Debuggerx。
练习
-
为以下每组二进制字符串编写正则表达式。只使用基本操作。
-
0 或 11 或 101
-
只有 0
答案:0 | 11 | 101, 0*
-
-
为以下每组二进制字符串编写正则表达式。只使用基本操作。
-
所有二进制字符串
-
所有二进制字符串,除了空字符串
-
以 1 开头,以 1 结尾
-
以 00 结尾
-
包含至少三个 1
答案:(0|1), (0|1)(0|1), 1 | 1(0|1)*1, (0|1)*00, (0|1)1(0|1)1(0|1)1(0|1)或 010101(0|1)。
-
-
编写一个正则表达式描述字母表{a, b, c}上按排序顺序的输入。答案:abc*。
-
为以下每组二进制字符串编写正则表达式。只使用基本操作。
-
包含至少三个连续的 1
-
包含子串 110
-
包含子串 1101100
-
不包含子串 110
答案:(0|1)111(0|1), (0|1)110(0|1), (0|1)1101100(0|1), (0|10)1。最后一个是最棘手的。
-
-
为至少有两个 0 但不连续的 0 的二进制字符串编写正则表达式。
-
为以下每组二进制字符串编写正则表达式。只使用基本操作。
-
至少有 3 个字符,并且第三个字符为 0
-
0 的数量是 3 的倍数
-
以相同字符开头和结尾
-
奇数长度
-
以 0 开头且长度为奇数,或以 1 开头且长度为偶数
-
长度至少为 1 且最多为 3
答案:(0|1)(0|1)0(0|1), 1 | (1010101), 1(0|1)1 | 0(0|1)0 | 0 | 1, (0|1)((0|1)(0|1)), 0((0|1)(0|1)) | 1(0|1)((0|1)(0|1)), (0|1) | (0|1)(0|1) | (0|1)(0|1)(0|1)。
-
-
对于以下每个问题,指出有多少长度为 1000 的位字符串与正则表达式匹配:
0(0 | 1)*1,0*101*,(1 | 01)*。 -
编写一个正则表达式,匹配字母表{a, b, c}中包含的所有字符串:
-
以 a 开头且以 a 结尾
-
最多一个 a
-
至少有两个 a
-
偶数个 a
-
a 的数量加上 b 的数量为偶数
-
-
找出字母按字母顺序排列的长单词,例如,
almost和beefily。答案:使用正则表达式’^abcdefghijklmnopqrstuvwxyz$'。 -
编写一个 Java 正则表达式,匹配电话号码,带有或不带有区号。区号应为(609) 555-1234 或 555-1234 的形式。
-
找出所有以
nym结尾的英语单词。 -
找出所有包含三连字母
bze的英语单词。答案:subzero。 -
找出所有以 g 开头,包含三连字母
pev且以 e 结尾的英语单词。答案:grapevine。 -
找出所有包含三个 r 且至少有两个 r 的英语单词。
-
找出可以用标准键盘顶行写出的最长英语单词。答案:proprietorier。
-
找出所有包含字母 a、s、d 和 f 的单词,不一定按照顺序。解决方案:
cat words.txt | grep a | grep s | grep d | grep f。 -
给定一个由 A、C、T 和 G 以及 X 组成的字符串,找到一个字符串,其中 X 匹配任何单个字符,例如,CATGG 包含在 ACTGGGXXAXGGTTT 中。
-
编写一个 Java 正则表达式,用于 Validate.java,验证形式为 123-45-6789 的社会安全号码。提示:使用
\d表示任何数字。答案:[0-9]{3}-[0-9]{2}-[0-9]{4}。 -
修改上一个练习,使
-成为可选项,这样 123456789 就被视为合法输入。 -
编写一个 Java 正则表达式,匹配包含恰好五个元音字母且元音字母按字母顺序排列的所有字符串。 答案:
[^aeiou]*a[^aeiou]*e[^aeiou]*i[^aeiou]*o[^aeiou]*u[^aeiou]* -
编写一个 Java 正则表达式,匹配有效的 Windows XP 文件名。这样的文件名由除了冒号以外的任意字符序列组成。
/ \ : * ? " < > |此外,它不能以空格或句号开头。
-
编写一个 Java 正则表达式,描述有效的 OS X 文件名。这样的文件名由除冒号以外的任意字符序列组成。此外,它不能以句点开头。
-
给定一个代表 IP 地址的名称为
s的字符串,采用dotted quad表示法,将其分解为其组成部分,例如,255.125.33.222。确保四个字段都是数字。 -
编写一个 Java 正则表达式,描述形式为Month DD, YYYY的所有日期,其中Month由任意大写或小写字母字符串组成,日期是 1 或 2 位数字,年份正好是 4 位数字。逗号和空格是必需的。
-
编写一个 Java 正则表达式,描述形式为 a.b.c.d 的有效 IP 地址,其中每个字母可以表示 1、2 或 3 位数字,句点是必需的。是:196.26.155.241。
-
编写一个 Java 正则表达式,匹配以 4 位数字开头并以两个大写字母结尾的车牌。
-
编写一个正则表达式,从 DNA 字符串中提取编码序列。它以 ATG 密码子开头,以停止密码子(TAA、TAG 或 TGA)结尾。参考
-
编写一个正则表达式来检查序列 rGATCy:即,它是否以 A 或 G 开头,然后是 GATC,最后是 T 或 C。
-
编写一个正则表达式来检查一个序列是否包含两个或更多次重复的 GATA 四核苷酸。
-
修改 Validate.java 使搜索不区分大小写。 提示: 使用
(?i)嵌入式标志。 -
编写一个 Java 正则表达式,匹配利比亚独裁者穆阿迈尔·卡扎菲姓氏的各种拼写,使用以下模板:(i)以 K、G、Q 开头,(ii)可选地跟随 H,(iii)后跟 AD,(iv)可选地跟随 D,(v)可选地跟随 H,(vi)可选地跟随 AF,(vii)可选地跟随 F,(vii)以 I 结尾。
-
编写一个 Java 程序,读取类似
(K|G|Q)[H]AD[D][H]AF[F]I的表达式,并打印出所有匹配的字符串。这里的符号[x]表示字母x的 0 或 1 个副本。 -
为什么
s.replaceAll("A", "B");不会替换字符串s中所有出现的字母 A 为 B?答案:使用
s = s.replaceAll("A", "B");代替。replaceAll方法返回结果字符串,但不会改变s本身。字符串是不可变的。 -
编写一个程序 Clean.java,从标准输入中读取文本并将其打印出来,在一行上去除任何尾随空格,并用 4 个空格替换所有制表符。
提示: 使用
replaceAll()和正则表达式\s匹配空格。 -
编写一个正则表达式,匹配在文本
a href ="和下一个"之间的所有文本。 答案:href=\"(.*?)\"。?使.*变得不贪婪而是懒惰。在 Java 中,使用Pattern.compile("href=\\\"(.*?)\\\"", Pattern.CASE_INSENSITIVE)来转义反斜杠字符。 -
使用正则表达式提取在
<title>和<\title>标签之间的所有文本。(?i)是另一种使匹配不区分大小写的方法。$2指的是第二个捕获的子序列,即title标签之间的内容。String pattern = "(?i)(<title.*?>)(.+?)(</title>)"; String updated = s.replaceAll(pattern, "$2"); -
编写一个正则表达式来匹配在<TD …>和标签之间的所有文本。 答案:
<TD[^>]*>([^<]*)</TD>
创意练习
-
FMR-1 三联重复区域。 “人类 FMR-1 基因序列包含一个三联重复区域,在该区域中序列 CGG 或 AGG 重复多次。三联体的数量在个体之间高度变化,增加的拷贝数与脆性 X 综合征相关,这是一种导致 2000 名儿童中的一名智力残疾和其他症状的遗传疾病。”(参考:Durbin 等人的《生物序列分析》)。该模式由 GCG 和 CTG 括起来,因此我们得到正则表达式 GCG (CGG | AGG)* CTG。
-
广告拦截。 Adblock 使用正则表达式来阻止 Mozilla 和 Firebird 浏览器下的横幅广告。
-
解析文本文件。 一个更高级的例子,我们想要提取匹配输入的特定部分。这个程序代表了解析科学输入数据的过程。
-
PROSITE 到 Java 正则表达式。 编写一个程序,读取 PROSITE 模式并打印出相应的 Java 正则表达式。PROSITE 是蛋白质家族和结构域的“第一个和最著名”的数据库。其主要用途是确定从基因组序列翻译而来的未知功能蛋白质的功能。生物学家使用PROSITE 模式语法规则在生物数据中搜索模式。这是CBD FUNGAL(访问代码 PS00562)的原始数据。每行包含各种信息。也许最有趣的一行是以 PA 开头的行 - 它包含描述蛋白质基序的模式。这些模式很有用,因为它们通常对应于功能或结构特征。
PA C-G-G-x(4,7)-G-x(3)-C-x(5)-C-x(3,5)-[NHG]-x-[FYWM]-x(2)-Q-C.每个大写字母对应一个氨基酸残基。字母表由对应于 2x 氨基酸的大写字母组成。连字符
-表示连接。例如,上面的模式以 CGG(Cys-Gly-Gly)开头。符号x扮演通配符的角色 - 它匹配任何氨基酸。这对应于我们符号中的.。括号用于指定重复:x(2)表示恰好两个氨基酸,x(4,7)表示 4 到 7 个氨基酸。这对应于 Java 符号中的.{2}和.{4,7}。花括号用于指定禁止的残基:{CG}表示除 C 或 G 之外的任何残基。星号具有其通常的含义。 -
文本转语音合成。 grep 的原始动机。“例如,如何处理发音多种不同的二连音 ui:fruit, guile, guilty, anguish, intuit, beguine?”
-
具有挑战性的正则表达式。 为以下每组二进制字符串编写一个正则表达式。只使用基本操作。
-
除了 11 或 111 之外的任何字符串
-
每个奇数符号是 1
-
包含至少两个 0 和最多一个 1
-
没有连续的 1s
-
-
二进制可被整除。 为以下每组二进制字符串编写一个正则表达式。只使用基本操作。
-
以二进制数解释的比特串可被 3 整除
-
以二进制数解释的比特串可被 123 整除
-
-
波士顿口音。 编写一个程序,将所有的 r 替换为 h,将句子翻译成波士顿版本,例如将“Park the car in Harvard yard”翻译为波士顿版本的“Pahk the cah in Hahvahd yahd”。
-
文件扩展名。 编写一个程序,以文件名作为命令行参数,并打印出其文件类型扩展名。扩展名是跟在最后一个
.后面的字符序列。例如,文件sun.gif的扩展名是gif。提示:使用split("\\.");请记住.是一个正则表达式元字符,因此您需要转义它。 -
反向子域。 为了进行网络日志分析,方便地根据子域(如
wayne.faculty.cs.princeton.edu)组织网络流量。编写一个程序来读取域名并以反向顺序打印出来,如edu.princeton.cs.faculty.wayne。 -
银行抢劫。 你刚刚目睹了一起银行抢劫案,并且得到了逃跑车辆的部分车牌号。它以
ZD开头,中间有一个3,以V结尾。帮助警官写出这个车牌的正则表达式。 -
排列的正则表达式。 找到 N 个元素的所有排列集合的最短正则表达式(仅使用基本操作),其中 N = 5 或 10。例如,如果 N = 3,则语言是 abc,acb,bac,bca,cab,cba。*答案:*困难。解决方案的长度与 N 呈指数关系。
-
解析带引号的字符串。 读取一个文本文件并打印出所有带引号的字符串。使用类似
"[^"]*"的正则表达式,但需要担心转义引号。 -
解析 HTML。 一个>,可选地跟随空格,后跟
a,后跟空格,后跟href,可选地跟随空格,后跟=,可选地跟随空格,后跟"http://,后跟字符直到",可选地跟随空格,然后是一个<。< \s* a \s+ href \s* = \s* \\"http://[^\\"]* \\" \s* > -
子序列。 给定一个字符串
s,确定它是否是另一个字符串t的子序列。例如,abc 是 achfdbaabgabcaabg 的一个子序列。使用正则表达式。现在不使用正则表达式重复这个过程。答案:(a) a.*b.c.,(b) 使用贪婪算法。 -
亨廷顿病诊断。 导致亨廷顿病的基因位于染色体 4 上,并且具有可变数量的 CAG 三核苷酸重复。编写一个程序来确定重复次数并打印
不会患 HD,如果重复次数少于 26,则打印后代有风险,如果数字为 37-35,则打印有风险,如果数字在 36 和 39 之间,则打印将患 HD。这就是遗传测试中识别亨廷顿病的方式。 -
基因查找器。 基因是基因组的一个子字符串,以起始密码子(ATG)开始,以终止密码子(TAG,TAA,TAG 或 TGA)结束,并由除起始或终止密码子之外的密码子序列(核苷酸三联体)组成。基因是起始和终止密码子之间的子字符串。
-
重复查找器。 编写一个程序
Repeat.java,它接受两个命令行参数,并查找指定由第二个命令行参数指定的文件中第一个命令行参数的最大重复次数。 -
字符过滤器。 给定一个包含坏字符的字符串
t,例如t = "!@#$%^&*()-_=+",编写一个函数来读取另一个字符串s并返回删除所有坏字符后的结果。String pattern = "[" + t + "]"; String result = s.replaceAll(pattern, ""); -
通配符模式匹配器。 不使用 Java 内置的正则表达式,编写一个程序 Wildcard.java 来查找与给定模式匹配的字典中的所有单词。特殊符号匹配任意零个或多个字符。因此,例如模式"ward"匹配单词"ward"和"wildcard"。特殊符号.匹配任何一个字符。您的程序应将模式作为命令行参数读取,并从标准输入读取单词列表(由空格分隔)。
-
通配符模式匹配器。 重复上一个练习,但这次使用 Java 内置的正则表达式。*警告:*在通配符的上下文中,*的含义与正则表达式不同。
-
搜索和替换。 文字处理器允许您搜索给定查询字符串的所有出现并用另一个替换字符串替换每个出现。编写一个程序 SearchAndReplace.java,它接受两个字符串作为命令行输入,从标准输入读取数据,并用第一个字符串替换所有出现的第一个字符串,并将结果发送到标准输出。*提示:*使用方法
String.replaceAll。 -
密码验证器。 假设出于安全原因,您要求所有密码至少包含以下字符之一
~ ! @ # $ % ^ & * |为
String.matches编写一个正则表达式,如果密码包含所需字符之一,则返回true。答案:“[~!@# %^&*|]+ ” -
字母数字过滤器。 编写一个程序 Filter.java,从标准输入中读取文本,并消除所有不是空格或字母数字的字符。答案 这是关键行。
String output = input.replaceAll("[^\\s0-9a-zA-Z]", ""); -
将制表符转换为空格。 编写一个程序,将 Java 源文件中的所有制表符转换为 4 个空格。
-
解析分隔文本文件。 存储数据库的一种流行方式是将其存储在一个文本文件中,每行一个记录,每个字段由称为分隔符的特殊字符分隔。
19072/Narberth/PA/Pennsylvania 08540/Princeton/NJ/New Jersey编写一个程序 Tokenizer.java,它读取两个命令行参数,一个是分隔符字符,另一个是文件名,并创建一个标记数组。
-
解析分隔文本文件。 重复上一个练习,但使用
String库方法split()。 -
检查文件格式。
-
拼写错误。 编写一个 Java 程序,验证这个常见拼写错误列表中只包含形式为的行
misdemenors (misdemeanors) mispelling (misspelling) tennisplayer (tennis player)第一个单词是拼写错误,括号中的字符串是可能的替换。
-
有趣的英语单词
-
DFA 的大小与 RE 的大小呈指数关系。 给出一个 RE,用于表示所有最后一个字符为 1 的比特串集合。RE 的大小应该与 k 成线性关系。现在,给出同一组比特串的 DFA。它使用了多少个状态?
提示:对于这组比特串,每个确定有限自动机(DFA)至少需要有 2^k 个状态。
5.5 数据压缩
原文:
algs4.cs.princeton.edu/55compression译者:飞龙
协议:CC BY-NC-SA 4.0
本节正在大规模施工中。
数据压缩:将文件大小缩小以节省空间存储和在传输时节省时间。摩尔定律:芯片上的晶体管数量每 18-24 个月翻一番。帕金森定律:数据会扩张以填满可用空间。文本、图像、声音、视频等。维基百科提供公共转储以供学术研究和再发布。使用 bzip 和 SevenZip 的 LZMA。对 300GB 数据进行压缩可能需要一周的时间。
古代思想。
摩尔斯电码,十进制数系统,自然语言,旋转电话(较低的号码拨号速度更快,所以纽约是 212,芝加哥是 312)。
二进制输入和输出流。
我们使用 BinaryStdIn.java、BinaryStdOut.java、BinaryDump.java、HexDump.java 和 PictureDump.java。
固定长度编码。
需要 ceil(lg R) 位来指定 R 个符号中的一个。Genome.java。使用 Alphabet.java。
运行长度编码。
RunLength.java。
变长编码。
希望有唯一可解码的编码。实现这一目标的一种方法是向每个码字附加一个特殊的停止符号。更好的方法是前缀无码:没有字符串是另一个字符串的前缀。例如,{ 01, 10, 0010, 1111 } 是前缀无码,但 { 01, 10, 0010, 1010 } 不是,因为 10 是 1010 的前缀。
给出传真机的例子。
Huffman 编码。
构建最佳前缀无码的特定方式。由 David Huffman 在 1950 年在 MIT 时发明。Huffman.java 实现了 Huffman 算法。
属性 A. 没有前缀无码使用更少的比特。
LZW 压缩。
使用 TST.java 中的前缀匹配代码,LZW.java 实现了 LZW 压缩。
现实世界:Pkzip = LZW + Shannon-Fano,GIF,TIFF,V.42bis 调制解调器,Unix 压缩。实际问题:
-
将所有内容编码为二进制。
-
限制符号表中元素的数量(GIF = 丢弃并重新开始,Unix 压缩 = 不起作用时丢弃)。
-
最初字典有 512 个元素(其中填充了 256 个 ASCII 字符),因此我们每个整数传输 9 位。当填满时,我们将其扩展到 1024 并开始每个整数传输 10 位。
-
只遍历树一次(可能会破坏我们的字符串表抽象)。
实际问题:限制符号表中元素的数量。
总结。
Huffman:固定长度符号的变长编码。LZW:变长字符串的固定长度编码。
通用压缩算法。
不可能压缩所有文件(通过简单计数论证)。直观论证:压缩莎士比亚的生平作品,然后压缩结果,再次压缩结果。如果每个文件都严格缩小,最终将只剩下一个比特。
参考文献。
卡内基梅隆大学的 Guy Blelloch 在 数据压缩 方面有一章非常出色。
错误校正/检测。
假设用于发送信息的信道存在噪声,每个比特以概率 p 翻转。发送每个比特 3 次;解码时取 3 个比特的大多数。解码比特的正确概率为 3p² - 2p³。这小于 p(如果 p < 1/2)。可以通过多次发送每个比特来减少解码比特错误的概率,但这在传输速率方面是浪费的。
Reed-Solomon 编码。
参考资料。用于大容量存储系统(CD 和 DVD)和卫星传输(旅行者号探测器,火星探路者)当错误是突发性的时候。将要发送的数据视为一个度为 d 的多项式。只需要 d+1 个点来唯一指定多项式。发送更多点以实现纠错/检测错误。如果我们要发送的编码是 a0,a1,…,am-1(每个元素在有限域 K 上),将其视为多项式 p(x) = a0 + a1x + … + am-1 x^m-1。发送 p(0),p(b),p(b²),…,其中 b 是 K 上的乘法循环群的生成元。
香农编码定理。
大致来说,如果信道容量为 C,则我们可以以略低于 C 的速率发送比特,使用编码方案将解码错误的概率降低到任意所需水平。证明是非构造性的。
问答
练习
-
以下哪些编码是前缀自由的?唯一可解码的?对于那些唯一可解码的编码,给出编码为 1000000000000 的编码。
code 1 code 2 code 3 code 4 A 0 0 1 1 B 100 1 01 01 C 10 00 001 001 D 11 11 0001 000 -
给出一个不是前缀自由的唯一可解码编码的例子。
解决方案。 任何无后缀编码都是唯一可解码的,例如,{ 0, 01 }。
-
给出一个不是前缀自由或无后缀的唯一可解码编码的例子。
解决方案。 { 0011, 011, 11, 1110 }或{ 01, 10, 011, 110 }。
-
{ 1, 100000, 00 },{ 01, 1001, 1011, 111, 1110 }和{ 1, 011, 01110, 1110, 10011 }是唯一可解码的吗?如果不是,找到一个具有两个编码的字符串。解决方案。 第一组编码是唯一可解码的。第二组编码不是唯一可解码的,因为 111-01-1110-01 和 1110-111-1001 是 11101111001 的两种解码方式。第三组编码不是唯一可解码的,因为 01110-1110-011 和 011-1-011-10011 是 011101110011 的两种解码方式。
-
唯一可解码性测试。 实现 Sardinas-Patterson 算法,用于测试一组编码词是否是唯一可解码的:将所有编码词添加到一个集合中。检查所有编码词对,看看是否有一个是另一个的前缀;如果是,提取悬挂后缀(即,长字符串中不是短字符串前缀的部分)。如果悬挂后缀是一个编码词,则编码不是唯一可解码的;否则,将悬挂后缀添加到列表中(前提是它尚未存在)。重复此过程直到没有剩余的新悬挂后缀为止。
该算法是有限的,因为添加到列表中的所有悬挂后缀都是有限一组编码词的后缀,并且悬挂后缀最多只能添加一次。
-
{ 0, 01, 11 }。编码词 0 是 01 的前缀,因此添加悬挂后缀 1。{ 0, 01, 11, 1 }。编码词 0 是 01 的前缀,但悬挂后缀 1 已经在列表中;编码词 1 是 11 的前缀,但悬挂后缀 1 已经在列表中。没有其他悬挂后缀,因此得出该集合是唯一可解码的结论。
-
{ 0, 01, 10 }。编码词 0 是 01 的前缀,因此将悬挂后缀 1 添加到列表中。{ 0, 01, 10, 1 }。编码词 1 是 10 的前缀,但悬挂后缀 0 是一个编码词。因此,得出该编码不是唯一可解码的结论。
-
-
Kraft-McMillan 不等式。 考虑一个具有长度为 n1, n2, …, nN 的 N 个编码词的编码 C。证明如果编码是唯一可解码的,则 K© = sum_i = 1 to N 2^(-ni) ≤ 1。
-
Kraft-McMillan 构造。 假设我们有一组满足不等式 sum_i = 1 to N 2^(-ni) ≤ 1 的整数 n1, n2, …, nN。证明总是可以找到一个编码长度为 n1, n2, …, nN 的前缀自由编码。因此,通过将注意力限制在前缀自由编码上(而不是唯一可解码编码),我们不会失去太多。
-
Kraft-McMillan 最优前缀自由编码等式。 证明如果 C 是一个最优前缀自由编码,那么 Kraft-McMillan 不等式是一个等式:K© = sum_i = 1 to N 2^(-ni) = 1。
-
假设所有符号概率都是 2 的负幂次方。描述哈夫曼编码。
-
假设所有符号频率相等。描述哈夫曼编码。
-
找到一个哈夫曼编码,其中概率为 pi 的符号的长度大于 ceil(-lg pi)。
解决方案. .01 (000), .30 (001), .34 (01), .35 (1)。码字 001 的长度大于 ceil(-lg .30)。
-
真或假。任何最优前缀自由编码都可以通过哈夫曼算法获得。
解决方案. 错误。考虑以下符号和频率集合(A 26, B 24, C 14, D 13, E 12, F 11)。
C1 C2 C3 A 26 01 10 00 B 24 10 01 01 C 14 000 111 100 D 13 001 110 101 E 12 110 001 110 F 11 111 000 111在任何哈夫曼编码中,字符 A 和 B 的编码必须以不同的位开始,但是代码 C3 没有这个属性(尽管它是一个最优前缀自由编码)。
-
以下输入的 LZW 编码是什么?
-
T O B E O R N O T T O B E
-
Y A B B A D A B B A D A B B A D O O
-
A A A A A A A A A A A A A A A A A A A A A
-
-
描述 LZW 编码中的棘手情况。
解决方案. 每当遇到 cScSc,其中 c 是一个符号,S 是一个字符串,cS 在字典中但 cSc 不在字典中。
-
作为 N 的函数,编码 N 个符号 A 需要多少位?N 个序列 ABC 需要多少位?
-
让 F(i) 为第 i 个斐波那契数。考虑 N 个符号,其中第 i 个符号的频率为 F(i)。注意 F(1) + F(2) + … + F(N) = F(N+2) - 1。描述哈夫曼编码。
解决方案. 最长的码字长度为 N-1。
-
显示对于给定的 N 个符号集合,至少有 2^(N-1) 种不同的哈夫曼编码。
解决方案. 有 N-1 个内部节点,每个节点都可以任意选择其左右子节点。
-
给出一个哈夫曼编码,其中输出中 0 的频率远远高于 1 的频率。
解决方案. 如果字符 ‘A’ 出现一百万次,字符 ‘B’ 出现一次,那么 ‘A’ 的码字将是 0,‘B’ 的码字将是 1。
-
证明有关哈夫曼树的以下事实。
-
两个最长的码字长度相同。
-
如果符号 i 的频率严格大于符号 j 的频率,则符号 i 的码字长度小于或等于符号 j 的码字长度。
-
-
描述如何在一组符号 { 0, 1, …, N-1 } 上传输哈夫曼编码(或最优前缀自由编码),使用 2N - 1 + N ceil(lg N) 位。
提示:使用 2N-1 位来指定相应 trie 的结构。
-
假设在一个扩展 ASCII 文件(8 位字符)中,最大字符频率最多是最小字符频率的两倍。证明固定长度的 8 位扩展 ASCII 码是最优的。
-
香农-范诺编码。 证明哈夫曼算法的以下自顶向下版本不是最优的。将码字集合 C 分成两个子集 C1 和 C2,其频率(几乎)相等。递归地为 C1 和 C2 构建树,从 0 开始为 C1 的所有码字,从 1 开始为 C2 的所有码字。为了实现第一步,香农和范诺建议按频率对码字进行排序,并尽可能地将集合分成两个子数组。
解决方案. S 32, H 25, A 20, N 18, O 5。
-
LZMW 编码(米勒-韦格曼 1985)。 LZ 变种:在字典中搜索最长的已经存在的字符串(当前匹配);将前一个匹配与当前匹配的连接添加到字典中。字典条目增长更快。当字典填满时,也可以删除低频率条目。难以实现。
-
LZAP 编码。 类似于 LZMW:不仅添加前一个匹配与当前匹配的连接,还添加前一个匹配与当前匹配的 所有前缀 的连接。比 LZMW 更容易实现,但字典条目更多。
-
确定一个不是前缀自由的最优编码。
提示:只需要 3 个具有相等频率的符号。
-
确定对于相同输入的两个最优前缀自由编码,其码字长度分布不同。
提示:只需要 4 个符号。
-
最小方差 Huffman 编码。 由于与打破平局相关的不确定性,Huffman 算法可能生成具有不同码字长度分布的编码。在生成压缩流时传输,希望以(近)恒定速率传输比特。找到最小化 sum_i (p_i (l_i - l_average(T)) ²) 的 Huffman 编码。
解决方案。 在组合 tries 时,通过选择具有最小概率的最早生成的 trie 来打破平局。
-
用于 Huffman 编码的双队列算法。 证明以下算法计算出 Huffman 编码(如果输入符号已按频率排序,则在线性时间内运行)。维护两个 FIFO 队列:第一个队列包含输入符号,按频率升序排列,第二个队列包含组合权重的内部节点。只要两个队列中有超过一个节点,就通过检查两个队列的前端出队两个权重最小的节点。创建一个新的内部节点(左右子节点 = 两个节点,权重 = 两个节点的权重之和)并将其加入第二个队列。
要获得最小方差的 Huffman 编码,通过从第一个队列中选择节点来打破平局。
提示:证明第二个队列按频率升序排列。
-
兄弟属性。 如果(i)每个节点(除了根节点)都有一个兄弟节点,且(ii)二叉树可以按概率的非递增顺序列出,使得在列表中所有兄弟节点都相邻,则二叉树具有 兄弟属性。证明二叉树表示 Huffman 树当且仅当它具有兄弟属性。
-
相对编码。 不是压缩图像中的每个像素,而是考虑像素与前一个像素之间的差异并对差异进行编码。直觉:通常像素变化不大。与颜色表字母上的 LZW 一起使用。
-
可变宽度 LZW 编码。 在第 2^p 个码字插入表后,将表的宽度从 p 增加到 p+1。与颜色表字母一起使用。
-
自适应 Huffman 编码。 一次通过算法,不需要发送前缀自由码。根据迄今为止读入的字符的频率构建 Huffman 树。在读入每个字符后更新树。编码器和解码器需要协调处理平局的约定。
-
香农熵。 具有可能值 x1, …, xN 且以概率 p1, …, pN 出现的离散随机变量 X 的熵 H 定义为 H(X) = -p1 lg p1 - p2 lg p2 - … - pN lg pN,其中 0 lg 0 = 0 与极限一致。
-
一个公平硬币的熵是多少?
-
一个硬币的熵是什么,其中两面都是正面?
-
一个六面骰子的熵是多少?
解决方案。 -lg (1/6) 大约为 2.584962。
-
两个公平骰子的和的熵是多少?
-
给定一个取 N 个值的随机变量。什么分布使熵最大化?熵是信息论中的一个基本概念。香农的源编码定理断言,要压缩来自一系列独立同分布随机变量流的数据,至少需要每个符号 H(X) 位。例如,发送一系列公平骰子投掷结果至少需要每次骰子投掷 2.584962 位。
-
-
经验熵。 经验熵 是通过计算每个符号出现频率并将其用作离散随机变量的概率来获得的一段文本的熵。计算你最喜欢小说的经验熵。将其与 Huffman 编码实现的数据压缩率进行比较。
-
香农实验。 进行以下实验。给一个主体一段文本(或 Leipzig 语料库)中的 k 个字母序列,并要求他们预测下一个字母。估计主体在 k = 1, 2, 5, 100 时答对的比例。
-
真或假。固定长度编码是���一可解码的。
解决方案。 真,它们是前缀自由的。
-
给出两棵不同高度的 Huffman 树字符串 ABCCDD。
-
前缀自由编码。 设计一个高效的算法来确定一组二进制码字是否是前缀自由的。提示:使用二进制 trie 或排序。
-
唯一可解码编码。 设计一个唯一可解码的编码,它不是前缀自由编码。提示:后缀自由编码 = 前缀自由编码的反向。后缀自由编码的反向是前缀自由编码 -> 可以通过以相反顺序读取压缩消息来解码。不太方便。
-
哈夫曼树。 修改 Huffman.java,使得编码器打印查找表而不是先序遍历,并修改解码器以通过读取查找表构建树。
-
真或假。在最佳前缀自由三进制编码中,出现频率最低的三个符号具有相同的长度。
解答。 False.
-
三进制哈夫曼编码。 将哈夫曼算法推广到三进制字母表(0, 1 和 2)上的码字,而不是二进制字母表。也就是说,给定一个字节流,找到一个使用尽可能少的三进制位(0、1 和 2)的前缀自由三进制编码。证明它产生最佳前缀自由三进制编码。
解答。 在每一步中合并最小的 3 个概率(而不是最小的 2 个)。当有 3 + 2k 个符号时,这种方法有效。为了将其减少到这种情况,添加概率为 0 的 1 或 2 个虚拟符号。(或者,如果符号数量不是 3 + 2k,则在第一步中合并少于 3 个符号。)例如:{ 0.1, 0.2, 0.2, 0.5 }。
-
非二进制哈夫曼编码。 将哈夫曼算法扩展到 m 进制字母表(0, 1, 2, …, m-1)上的码字,而不是二进制字母表。
-
考虑以下由 3 个 a、7 个 c、6 个 t 和 5 个 g 组成的 21 个字符消息。
a a c c c c a c t t g g g t t t t c c g g以下的 43 位是否是上述消息的可能哈夫曼编码?
0000001111000101010010010010101010111001001尽可能简洁而严谨地证明你的答案。
解答。 对于一条消息的哈夫曼编码会产生使用最少位数的编码,其中 2 位二进制码 a = 00, c = 01, g = 10, t = 11 是一个使用 21 * 2 = 42 位的前缀自由编码。因此,哈夫曼编码将使用少于 43 位。
-
如果一个二叉树是满的,则除了叶子节点外的每个节点都有两个子节点。证明与最佳前缀自由编码对应的任何二叉树都是满的。
提示:如果内部节点只有一个子节点,请用其唯一子节点替换该内部节点。
-
Move-to-front 编码(Bentley, Sleator, Tarjan 和 Wei 1986)。 编写一个名为
MoveToFront的程序,实现 move-to-front 编码和解码。维护符号字母表的列表,其中频繁出现的符号位于前面。一个符号被编码为列表中在它之前的符号数。编码一个符号后,将其移动到列表的前面。参考 -
Move-ahead-k 编码。 与 move-to-front 编码相同,但将符号向前移动 k 个位置。
-
等待-c-并移动。 与 move-to-front 编码相同,但只有在符号在上次移动到前面后遇到 c 次后才将其移动到前面。
-
双哈夫曼压缩。 找到一个输入,对该输入应用 Huffman.java 中的
compress()方法两次比仅应用compress()一次导致输出严格较小。 -
合并 k 个排序数组。 你有 k 个已排序的列表,长度分别为 n1、n2、…、nk。假设你可以执行的唯一操作是 2 路合并:给定长度为 n1 的一个已排序数组和长度为 n2 的另一个已排序数组,用长度为 n = n1 + n2 的已排序数组替换它们。此外,2 路合并操作需要 n 个单位的时间。合并 k 个已排序数组的最佳方法是什么?
解决方案. 将列表长度排序,使得 n1 < n2 < … < nk。重复地取最小的两个列表并应用 2 路合并操作。最优性的证明与哈夫曼编码的最优性证明相同:重复应用 2 路合并操作会产生一棵二叉树,其中每个叶节点对应于原始排序列表中的一个,每个内部节点对应于一个 2 路合并操作。任何原始列表对总体成本的贡献是列表长度乘以其树深度(因为这是其元素参与 2 路合并的次数)。
6. 上下文
原文:
algs4.cs.princeton.edu/60context译者:飞龙
协议:CC BY-NC-SA 4.0
本章节正在大规模施工中。
概述。
本章中的 Java 程序。
以下是本章节中的 Java 程序列表。点击程序名称以访问 Java 代码;点击参考编号以获取简要描述;阅读教材以获取详细讨论。
REF 程序 描述 / JAVADOC 6.1 CollisionSystem.java 碰撞系统 - Particle.java 粒子 6.2 BTree.java B 树 6.3 SuffixArray.java 后缀数组(后缀排序) - SuffixArrayX.java 后缀数组(优化) - LongestRepeatedSubstring.java 最长重复子串 - KWIK.java 上下文关键词 - LongestCommonSubstring.java 最长公共子串 6.4 FordFulkerson.java 最大流-最小割 - FlowNetwork.java 带容量网络 - FlowEdge.java 带流量的容量边 - GlobalMincut.java 全局最小割(Stoer-Wagner)⁵ - BipartiteMatching.java 二分图匹配(交替路径) - HopcroftKarp.java 二分图匹配(Hopcroft-Karp) - AssignmentProblem.java 加权二分图匹配 - LinearProgramming.java 线性规划(单纯形法) - TwoPersonZeroSumGame.java 双人零和博弈