报错
HTTPError Traceback (most recent call last)
Cell In[3], line 52 from sklearn.datasets import fetch_california_housing3 from sklearn.model_selection import train_test_split
----> 5 X, Y = fetch_california_housing(return_X_y=True)6 print(X.shape), # (20640, 8)7 print(Y.shape) # (20640, )File ~\miniconda3\lib\site-packages\sklearn\datasets\_california_housing.py:138, in fetch_california_housing(data_home, download_if_missing, return_X_y, as_frame)132 raise IOError("Data not found and `download_if_missing` is False")134 logger.info(135 "Downloading Cal. housing from {} to {}".format(ARCHIVE.url, data_home)136 )
--> 138 archive_path = _fetch_remote(ARCHIVE, dirname=data_home)140 with tarfile.open(mode="r:gz", name=archive_path) as f:141 cal_housing = np.loadtxt(142 f.extractfile("CaliforniaHousing/cal_housing.data"), delimiter=","143 )File ~\miniconda3\lib\site-packages\sklearn\datasets\_base.py:1324, in _fetch_remote(remote, dirname)1302 """Helper function to download a remote dataset into path1303 1304 Fetch a dataset pointed by remote's url, save into path using remote's(...)1320 Full path of the created file.1321 """1323 file_path = remote.filename if dirname is None else join(dirname, remote.filename)
-> 1324 urlretrieve(remote.url, file_path)1325 checksum = _sha256(file_path)1326 if remote.checksum != checksum:File ~\miniconda3\lib\urllib\request.py:241, in urlretrieve(url, filename, reporthook, data)224 """225 Retrieve a URL into a temporary location on disk.226 (...)237 data file as well as the resulting HTTPMessage object.238 """239 url_type, path = _splittype(url)
--> 241 with contextlib.closing(urlopen(url, data)) as fp:242 headers = fp.info()244 # Just return the local path and the "headers" for file://245 # URLs. No sense in performing a copy unless requested.File ~\miniconda3\lib\urllib\request.py:216, in urlopen(url, data, timeout, cafile, capath, cadefault, context)214 else:215 opener = _opener
--> 216 return opener.open(url, data, timeout)File ~\miniconda3\lib\urllib\request.py:525, in OpenerDirector.open(self, fullurl, data, timeout)523 for processor in self.process_response.get(protocol, []):524 meth = getattr(processor, meth_name)
--> 525 response = meth(req, response)527 return responseFile ~\miniconda3\lib\urllib\request.py:634, in HTTPErrorProcessor.http_response(self, request, response)631 # According to RFC 2616, "2xx" code indicates that the client's632 # request was successfully received, understood, and accepted.633 if not (200 <= code < 300):
--> 634 response = self.parent.error(635 'http', request, response, code, msg, hdrs)637 return responseFile ~\miniconda3\lib\urllib\request.py:563, in OpenerDirector.error(self, proto, *args)561 if http_err:562 args = (dict, 'default', 'http_error_default') + orig_args
--> 563 return self._call_chain(*args)File ~\miniconda3\lib\urllib\request.py:496, in OpenerDirector._call_chain(self, chain, kind, meth_name, *args)494 for handler in handlers:495 func = getattr(handler, meth_name)
--> 496 result = func(*args)497 if result is not None:498 return resultFile ~\miniconda3\lib\urllib\request.py:643, in HTTPDefaultErrorHandler.http_error_default(self, req, fp, code, msg, hdrs)642 def http_error_default(self, req, fp, code, msg, hdrs):
--> 643 raise HTTPError(req.full_url, code, msg, hdrs, fp)HTTPError: HTTP Error 403: Forbidden
先手动下载数据(https://www.dcc.fc.up.pt/~ltorgo/Regression/cal_housing.tgz)
PS:
-
报错文件
File ~\miniconda3\lib\site-packages\sklearn\datasets\_california_housing.py:138, in fetch_california_housing(data_home, download_if_missing, return_X_y, as_frame)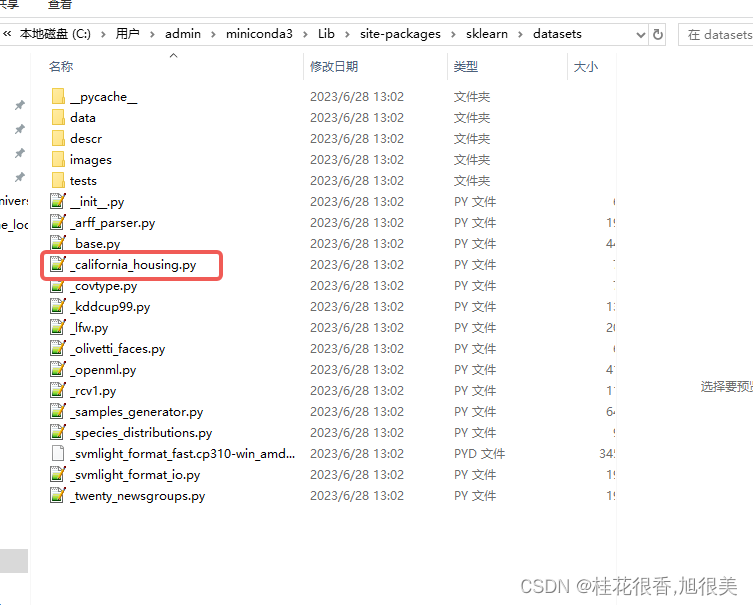
-
找到文件打开,43行有下载地址
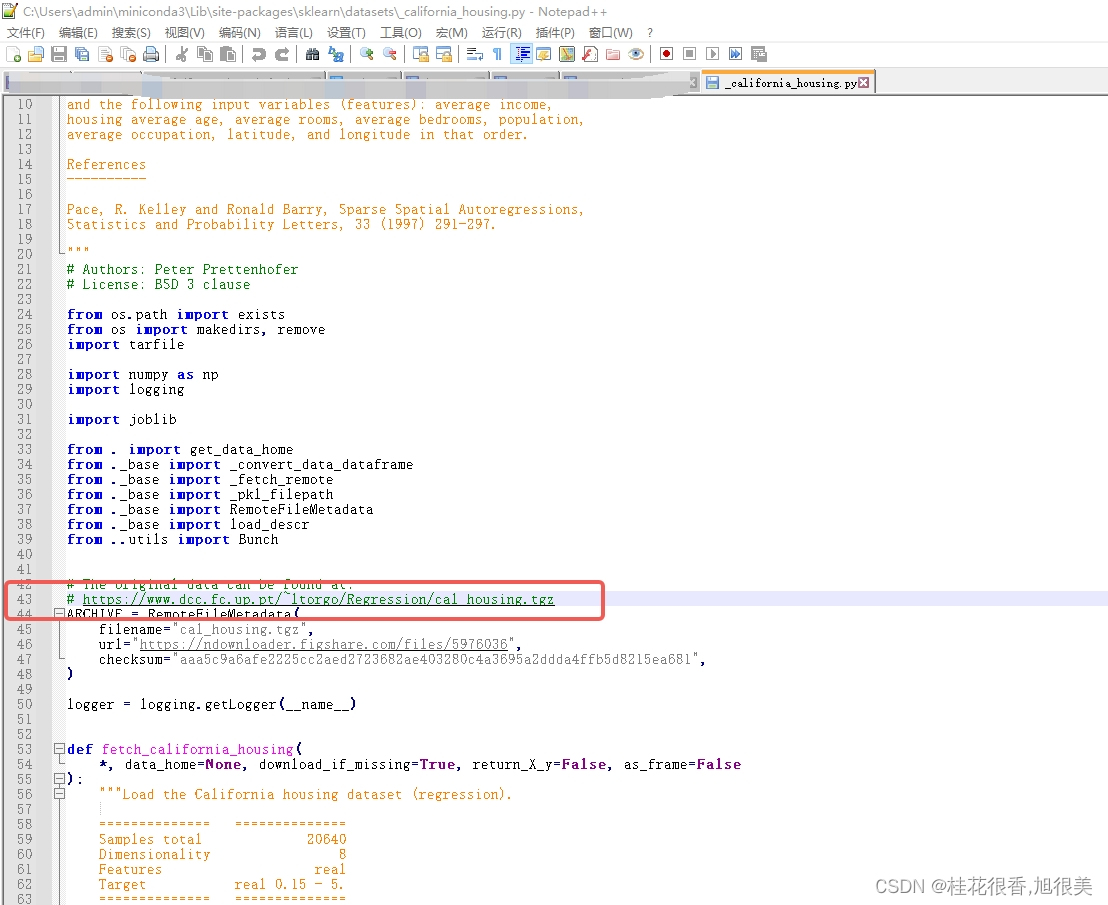
-
复制下载后的
cal_housing.tgz文件到指定文件夹,无需解压。需要复制到的文件夹需要从代码里获取,获取代码如下:

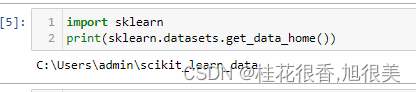
4.更改_california_housing.py文件,将def fetch_california_housing()这个函数内的archive_path这段代码更改为如下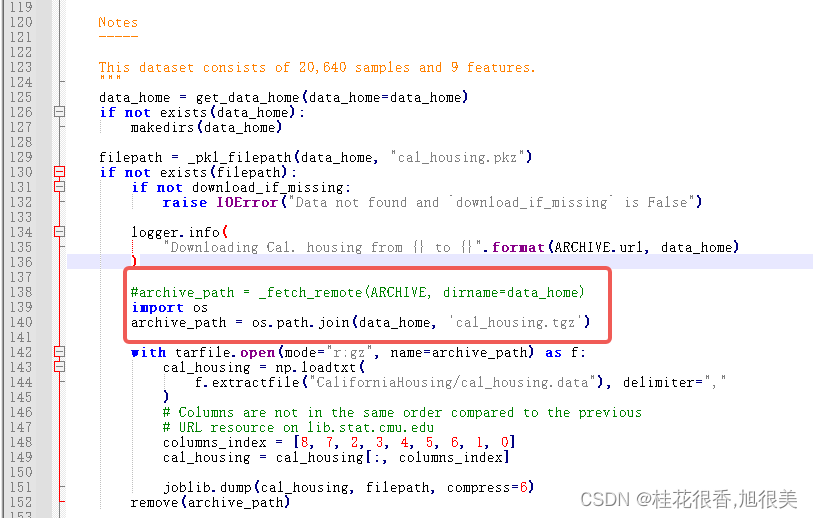
重启 jupyter notebook即可,Windows系统也相同操作