写在前面:代码运行环境为jupyter,如果结果显示不出来的地方就加一个print()函数。
一、数据基本处理
缺失值处理:
import numpy as np
import pandas as pd#加载数据train.csv
df = pd.read_csv('train_chinese.csv')
df.head()# 查看数据基本信息(非空值数量、数据类型)
df.info()# 查看每个数据是否为空值,每个特征中空值总数
df.isnull().sum()# 年龄列填充缺失值为0,到一个副本
df.fillna({'年龄':0}).head(7)
df.loc[df['客舱'].isnull(), '客舱'] = 0
# 同理可以填充平均值,众数等……df.isnull().sum()# 整张表处理(缺失值处填0)
df = df.fillna(0)
df.head()重复值(删除):
数据表里重复值其所有信息一样:(0行与1行重复)
| name | age | hobby | |
| 0 | xx | 20 | gg |
| 1 | nn | 19 | f |
| 2 | xx | 20 | gg |
# 定义一个数据表
a = pd.DataFrame({'name':['xx','dd','ff','gg','xx'],'habits':[11,22,33,44,11]})
print(a)# 查看是否有重复行(所有信息重复)
print(a.duplicated())# 处理(删除陈重复行):
a.drop_duplicates()离散化处理(分箱):
# 将连续变量Age划分为[0,5) [5,15) [15,30) [30,50) [50,80)五个年龄段,并分别用类别变量12345表示
# 左闭右开:right=False
df['age_bins'] = pd.cut(df['年龄'], [0,15,25,35,45,80], right=False, labels = list('abcde'))df.tail()# 按百分比分段
df['age_binsPercent'] = pd.qcut(df['年龄'],[.1,.2,.3,.5,.7,.9],duplicates="drop",labels=list('12345'))
df.head()变换文本变量:
例如性别包括男和女,用0表示男,1表示女。
# 查看有哪些类型
df['性别'].unique()
df['客舱'].unique()
df['登船港口'].unique()# 将男/女替换为0/1
# inplace默认为False,返回一个副本df['性别'].replace({"male",'female'},{0,1}, inplace = True)
df.head()# 按顺序替换为数字
from sklearn.preprocessing import LabelEncoderdf['客舱'] = LabelEncoder().fit_transform(df['客舱'])
df['登船港口'] = LabelEncoder().fit_transform(df['登船港口'])
df.head() 
one-hot编码:
# one-hot编码
for column in ['登船港口','性别']:# 函数x = pd.get_dummies(df[column],prefix=column)# 拼接在一起df = pd.concat([df,x],axis=1)
df.head() 
提取字符串里的某一部分:
这里用到正则表达式。里面的称呼特点是都有后缀(.)

df['title'] = df.姓名.str.extract('([A-Za-z]+)\.')
df 
二、数据的横向与纵向合并
这里进行数据重构操作
横向合并:
| hobby1 | hobby2 | |
| 0 | gg | 11 |
| 1 | ff | 22 |
| 2 | gg | 33 |
| name | age | |
| 0 | xx | 20 |
| 1 | nn | 19 |
| 2 | xx | 20 |
| name | age | hobby1 | hobby2 | |
| 0 | xx | 20 | gg | 11 |
| 1 | nn | 19 | ff | 22 |
| 2 | xx | 20 | gg | 33 |
# 导入基本库
import numpy as np
import pandas as pd# 载入data中的文件
left_up = pd.read_csv('data/train-left-up.csv')
left_down = pd.read_csv('data/train-left-down.csv')right_up = pd.read_csv('data/train-right-up.csv')
right_down = pd.read_csv('data/train-right-down.csv')#将两个数据横向合并
result_up = pd.concat([left_up, right_up], axis = 1)
result_down = pd.concat([left_down , right_down], axis = 1)result_up.head()# 横向合并
up = left_up.join(right_up)
down = left_down.join(right_down)up.head()纵向合并:
| name | age | |
| 0 | xx | 20 |
| name | age | |
| 1 | nn | 19 |
| 2 | xx | 20 |
| name | age | |
| 0 | xx | 20 |
| 1 | nn | 19 |
| 2 | xx | 20 |
# 两个数据up和down
up = left_up.join(right_up)
down = left_down.join(right_down)# 纵向合并
result1 = up.append(down)
result1.head()# 横向连接
up2 = pd.merge(left_up,right_up, left_index=True, right_index=True)
up2.head()down2 = pd.merge(left_down,right_down, left_index=True, right_index=True)
down2.head()# 纵向合并
result2 = up.append(down)
result2.head()
result2.shaperesult2.to_csv('result.csv')将DataFrame数据变为Series类型的数据:
data = pd.read_csv('result.csv')
data.head()# 转换
data.stack()三、数据重构
groupby函数:
# 载入data文件中的:result.csv
text = pd.read_csv('result.csv')
text.head()# 查看性别中的0是什么:(所以女性的数据)
list(text.groupby('Sex'))[0]# 找到不同性别的数据
group = text.groupby('Sex')
# 计算这些特征数据的统计描述
print(group.describe())# 只想得到关于年龄的信息(加一个Age索引)
print(text.groupby('Sex')['Age'].describe())
# 只得到平均值
print(text.groupby('Sex')['Age'].mean())# 计算泰坦尼克号男性与女性的平均票价
# 修改索引为票价
print(text.groupby('Sex')['Fare'].mean())
# method__2
df = text['Fare'].groupby(text['Sex'])
means = df.mean()
means# 统计泰坦尼克号中男女的存活人数
survived_sex = text.groupby('Sex')['Survived'].sum()survived_sex = text['Survived'].groupby(text['Sex']).sum()
survived_sex.head()# 计算客舱不同等级的存活人数
survived_pclass = text.groupby('Pclass')['Survived'].sum()survived_pclass = text['Survived'].groupby(text['Pclass'])
survived_pclass.sum()agg函数:
# agg里面可以使用多个方法
survived_pclass = text.groupby('Pclass')['Survived'].sum()
survived_pclass = text.groupby('Pclass').agg({'Survived':'sum'})# 性别中对费用求平均,对存活求和
text.groupby('Sex').agg({'Fare': 'mean', 'Survived': 'count'})# 重命名方便阅读,显示为‘mean_fare’
text.groupby('Sex').agg({'Fare': 'mean', 'Pclass': 'count'}).rename(columns={'Fare': 'mean_fare', 'Pclass': 'count_pclass'})
# 统计在不同等级的票中的不同年龄的船票花费的平均值
# 再加一个Pclass
text.groupby(['Pclass','Age'])['Fare'].mean().head()# 将任务二和任务三的数据合并,并保存到sex_fare_survived.csv
# 使用index查看列索引,相同则可以合并
# 我在上面没有赋值,使用这个元素不存在
means.index
survived_sex.index
# 确定类型,使用merge不能是series
type(means)# 变为dataframe
means.to_frame()# 保存起来使用merge
result = pd.merge(means,survived_sex,on='Sex')
resultresult.to_csv('sex_fare_survived.csv')# 得出不同年龄的总的存活人数,然后找出存活人数最多的年龄段,最后计算存活人数最高的存活率(存活人数/总人数#不同年龄的存活人数
text.groupby(['Age'])['Survived'].sum()survived_age = text['Survived'].groupby(text['Age']).sum()
survived_age.head()#找出最大值的年龄段
survived_age[survived_age.values==survived_age.max()]#首先计算总人数
_sum = text['Survived'].sum()print("sum of person:"+str(_sum))precetn =survived_age.max()/_sumprint("最大存活率:"+str(precetn))四、数据可视化
import numpy as np
import pandas as pd
# 画图用
import matplotlib.pyplot as plttext = pd.read_csv(r'result.csv')
text.head()# 男女中生存人数分布情况
sex = text.groupby('Sex')['Survived'].sum()
# 柱状图bar
sex.plot.bar()
# 标题
plt.title('survived_count')
plt.show() 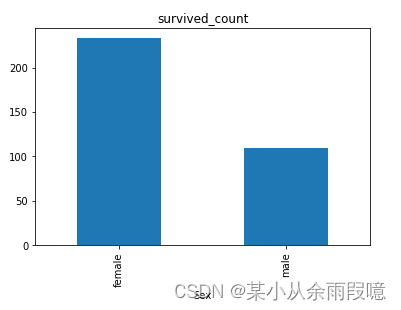
# 男女中生存人与死亡人数的比例图# unstack:旋转数据,转置
s = text.groupby(['Sex','Survived'])['Survived'].count().unstack()
# 绘制男女死亡人数柱状图
died = s[0]
died.plot.bar()
plt.title('died')

s.plot.bar()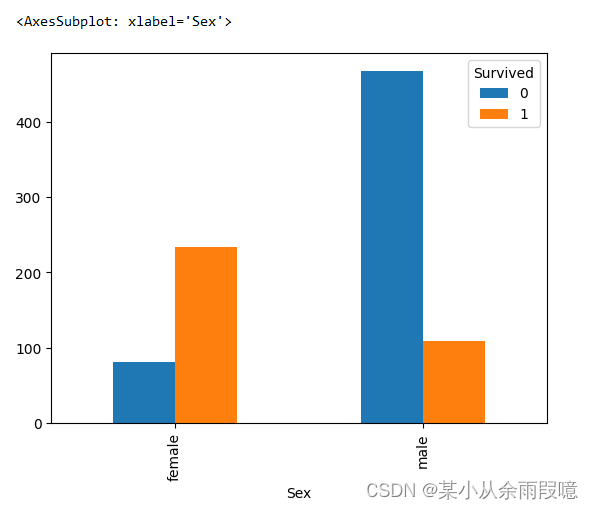
# 提示:计算男女中死亡人数 1表示生存,0表示死亡
# 柱子叠起来,参数:stacked='True'
text.groupby(['Sex','Survived'])['Survived'].count().unstack().plot(kind='bar',stacked='True')
plt.title('survived_count')
plt.ylabel('count')
# 查看不同票价的生存死亡人数
c = text.groupby(['Fare','Survived'])['Survived'].count().unstack()
c
c.plot()
# 1表示生存,0表示死亡
# 不同仓位等级的人生存和死亡人员的分布情况
pclass_sur = text.groupby(['Pclass'])['Survived'].value_counts()
pclass_surimport seaborn as sns
sns.countplot(x="Pclass", hue="Survived", data=text)
# 不同年龄的人生存与死亡人数分布情况
# 0表示死亡人数,1生存。不同年龄的死亡人数
# 画频率直方图。分区间:bins; alpha :颜色透明度
# density密度
text.Age[text.Survived == 0].hist(bins=5, alpha = .5, density=1)
text.Age[text.Survived == 1].hist(bins=5,alpha = .5, density=1)# 密度曲线
text.Age[text.Survived == 0].plot.density()
text.Age[text.Survived == 1].plot.density()# 图例
plt.legend((0,1))
plt.xlabel('age')
# plt.ylabel('count')
plt.ylabel('density') 
# 参考代码
facet = sns.FacetGrid(text, hue="Survived",aspect=3)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, text['Age'].max()))
facet.add_legend()
# 不同仓位等级的人年龄分布情况
# 查看种类
unique_placss = text.Pclass.unique()print(unique_placss)for i in unique_placss:# 密度曲线text.Age[text.Pclass == i].plot.density()
# 图例
plt.legend(unique_placss)
plt.xlabel('age')
# plt.ylabel('count')
plt.ylabel('density') 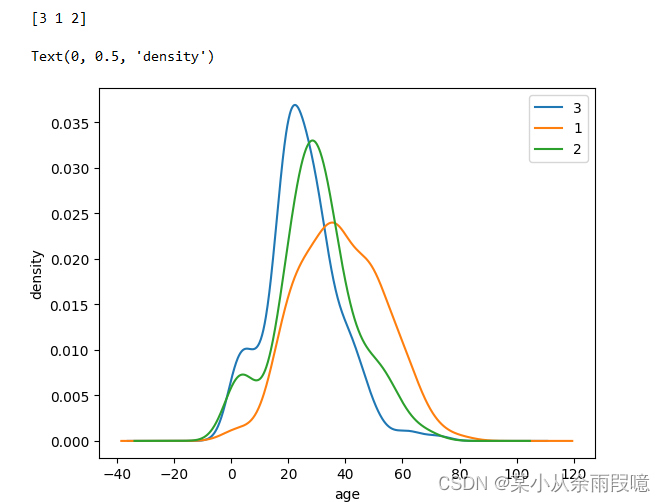
import seaborn as sns
for i in unique_placss:# 密度曲线sns.kdeplot(text.Age[text.Pclass == i])# 不同仓位等级的人年龄分布情况
text.Age[text.Pclass == 1].plot(kind='kde')
text.Age[text.Pclass == 2].plot(kind='kde')
text.Age[text.Pclass == 3].plot(kind='kde')
plt.xlabel("age")
plt.legend((1,2,3),loc="best")