说明:该系列文章从本人知乎账号迁入,主要原因是知乎图片附件过于模糊。
知乎专栏地址:
语音生成专栏
系列文章地址:
【GPT-SOVITS-01】源码梳理
【GPT-SOVITS-02】GPT模块解析
【GPT-SOVITS-03】SOVITS 模块-生成模型解析
【GPT-SOVITS-04】SOVITS 模块-鉴别模型解析
【GPT-SOVITS-05】SOVITS 模块-残差量化解析
【GPT-SOVITS-06】特征工程-HuBert原理
1.概述
HuBert 模型目的在于提取音频自编码特征,其核心架构如下:
说明:代码主要参考 HuggingFace 的transformers 开源库
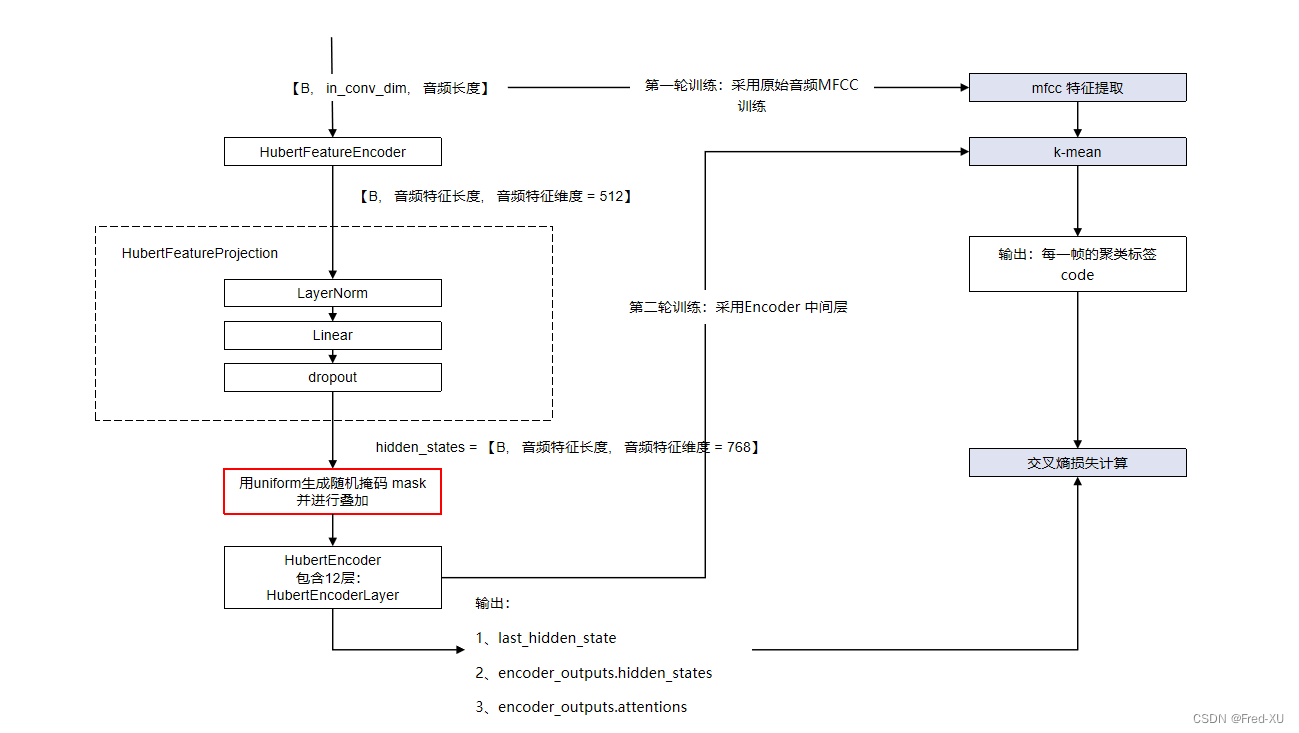
- 输入原始音频数据,通过类似Bert原理的编码器形成隐变量,即在进入多头注意力模块前增加了随机的掩码
- 训练时,第一轮比对原始音频的 MFCC 特征做 kmean 编码,类似残差向量量化网络。针对隐变量与编码做交叉熵损失
- 训练时,第二轮比对编码器生成的隐变量(第6/9层)做 kmean 编码,再针对隐变量与编码做交叉熵损失
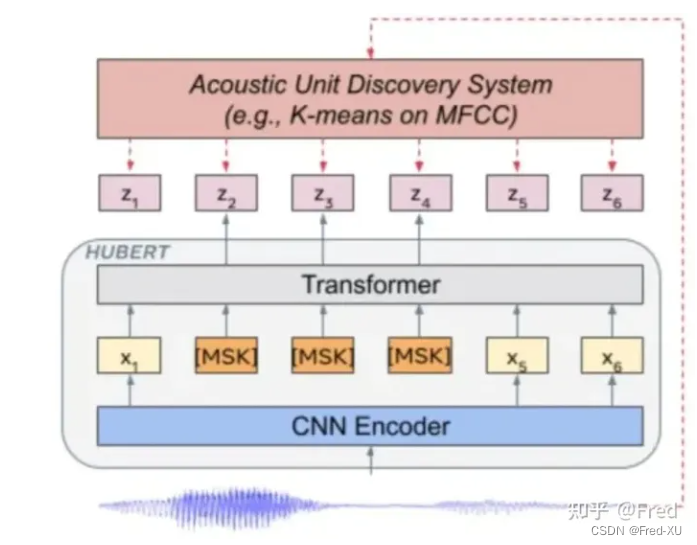
与论文中的截图做一下对比:

2.核心源码解析
2.1、特征提取:HubertFeatureEncoder
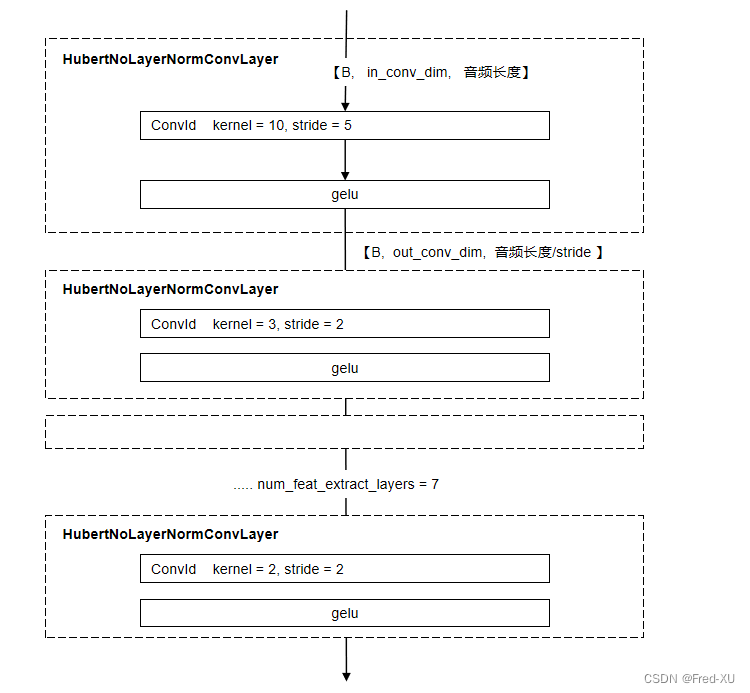
默认为 7层一维卷积,每层卷积参数,主要是 kernel 和 stride 不同
2.2、核心编码器:HubertEncoder
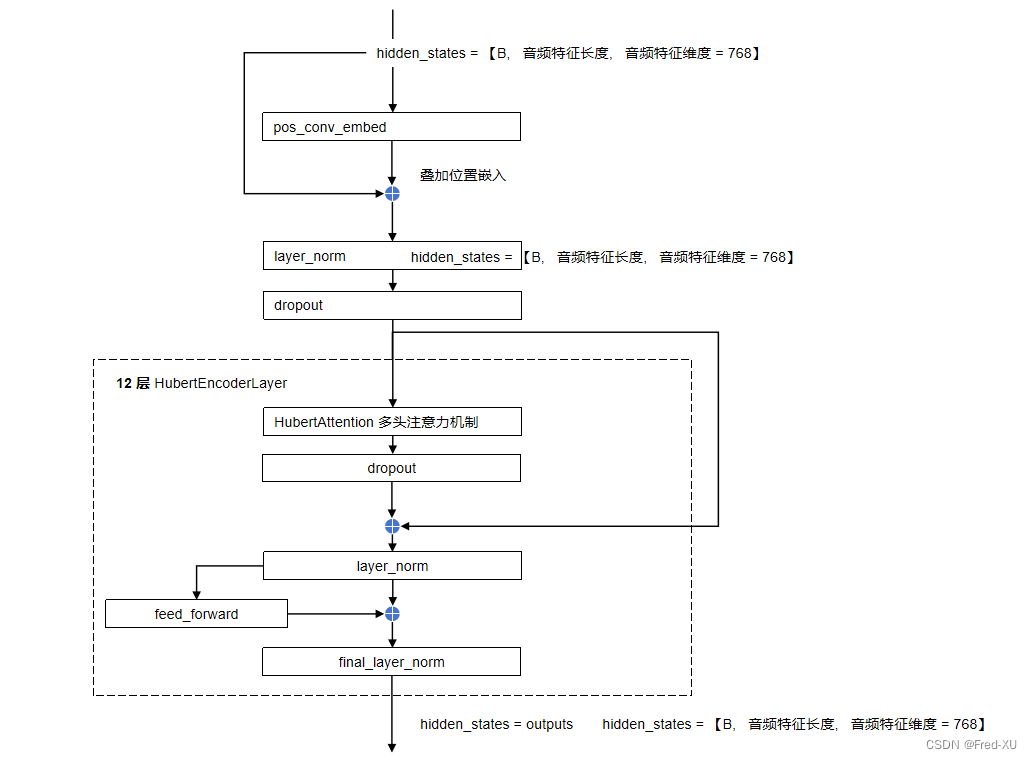
- 默认为 12层编码器模块
- 在输出时,包含了最终层的输出,以及中间各层的输出
2.3、有监督微调:HubertForCTC
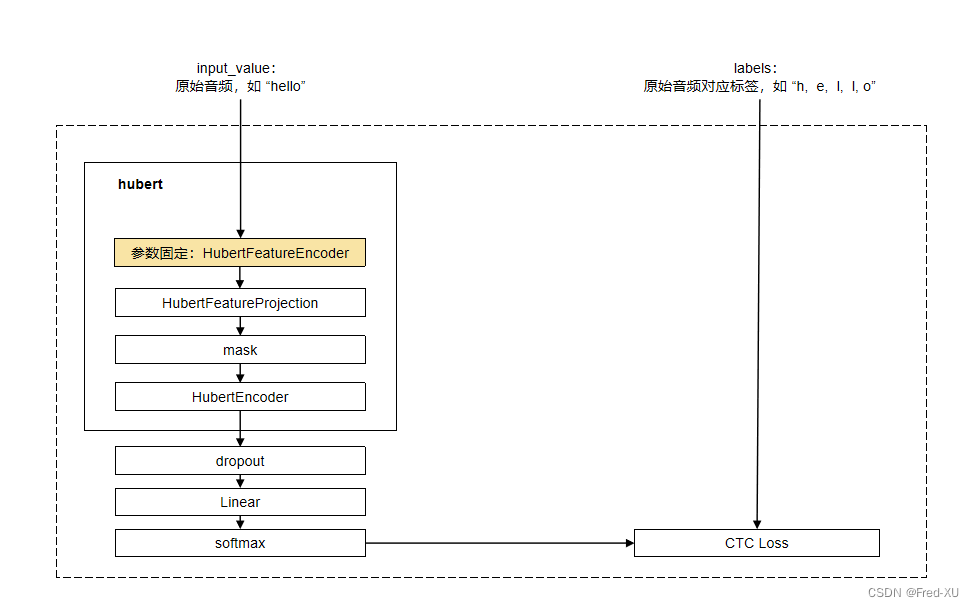
- 论文中同样给出了基于CTC损失的微调
- 在微调时,特征提取编码器参数固定
CTC 损失的价值,主要是用于输出和标签的不一致性。举例:
假设 hello 这个单词在10秒内完成,则按秒分帧,每一秒对应一个字母的概率。即可能是 hhhhellooo。损失计算的时候是要对比 hhhhellooo 和 hello 的差异。
3、调试代码参考
from transformers import HubertModel, HubertConfig
import torch
import librosa
import torch.nn as nndef _test_pred_vec():config = HubertConfig()model = HubertModel(config)device = "cuda" if torch.cuda.is_available() else "cpu"model.to(device)wav_in = "../data/test.wav"audio, sr = librosa.load(wav_in, sr=16000)audio = torch.from_numpy(audio).to(device)x = audio[None, :]vec = model.forward(x)print(vec)def _test_ctc_loss():ctc_loss = nn.CTCLoss()log_probs = torch.randn(50, 16, 20).log_softmax(2).requires_grad_()targets = torch.randint(1, 20, (16, 30), dtype=torch.long)input_lengths = torch.full((16,), 50, dtype=torch.long)target_lengths = torch.randint(10, 30, (16,), dtype=torch.long)loss = ctc_loss(log_probs, targets, input_lengths, target_lengths)print(loss)if __name__ == '__main__':#_test_pred_vec()_test_ctc_loss()