一、Jmeter元件
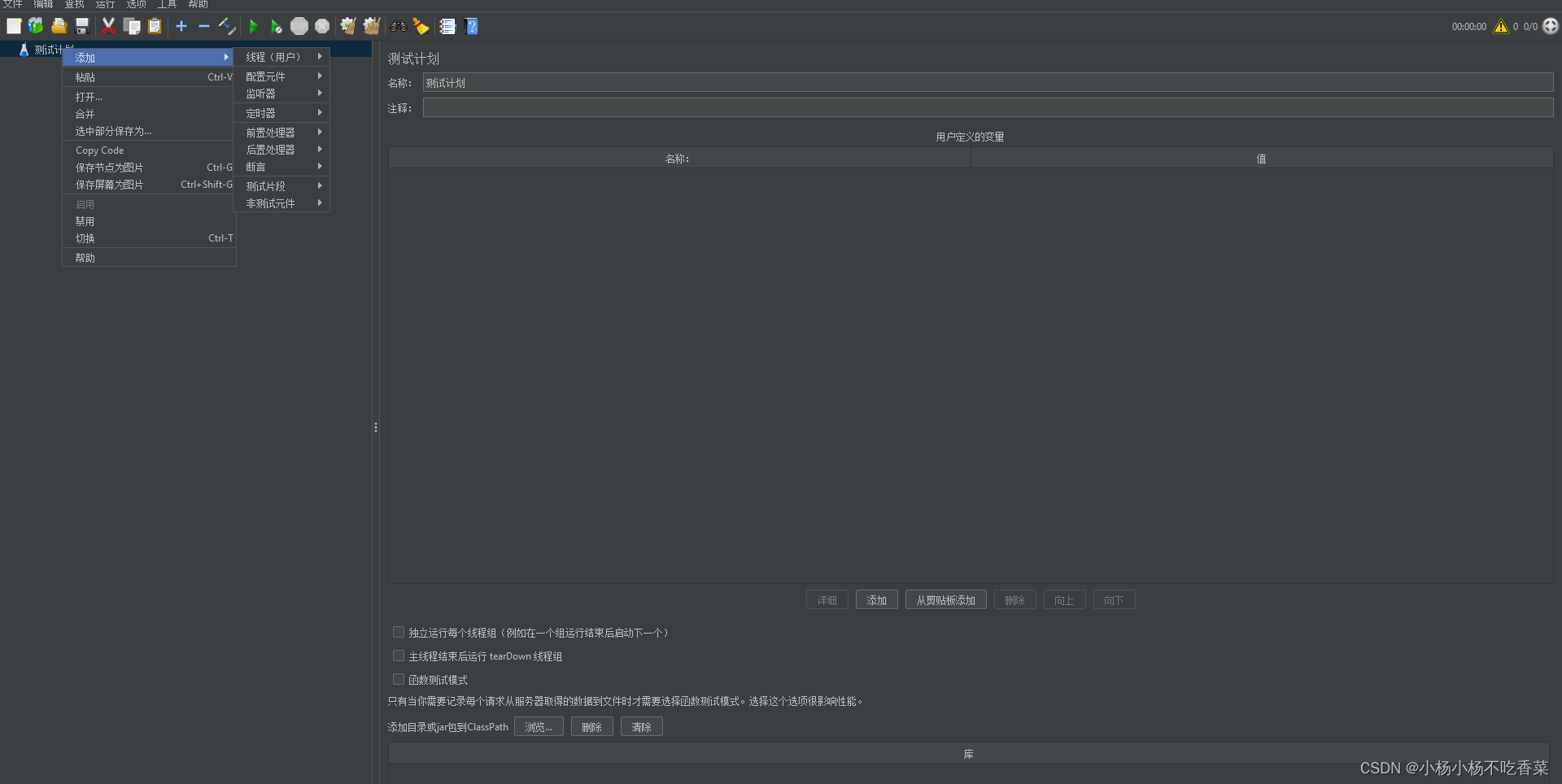
#线程组
添加HTTP请求
#配置元件
配置元件内的元件都是用于进行初始化的东西
#监听器
监听器主要是用来获取我们使用取样器发送请求后的响应数据相关信息
#定时器
定时器主要用来控制我们多久后执行该取样器(发送请求)
#前置处理器
前置处理器是对我们的请求参数在执行前进行处理
#后置处理器
后置处理器是对我们请求后所返回的响应进行处理
#断言
判断结果是否符合预期的功能
执行顺序:
配置元件 - 前置处理程序 - 定时器 - 取样器 - 后置处理程序 - 断言 - 监听器
1.Jmeter线程
#线程组
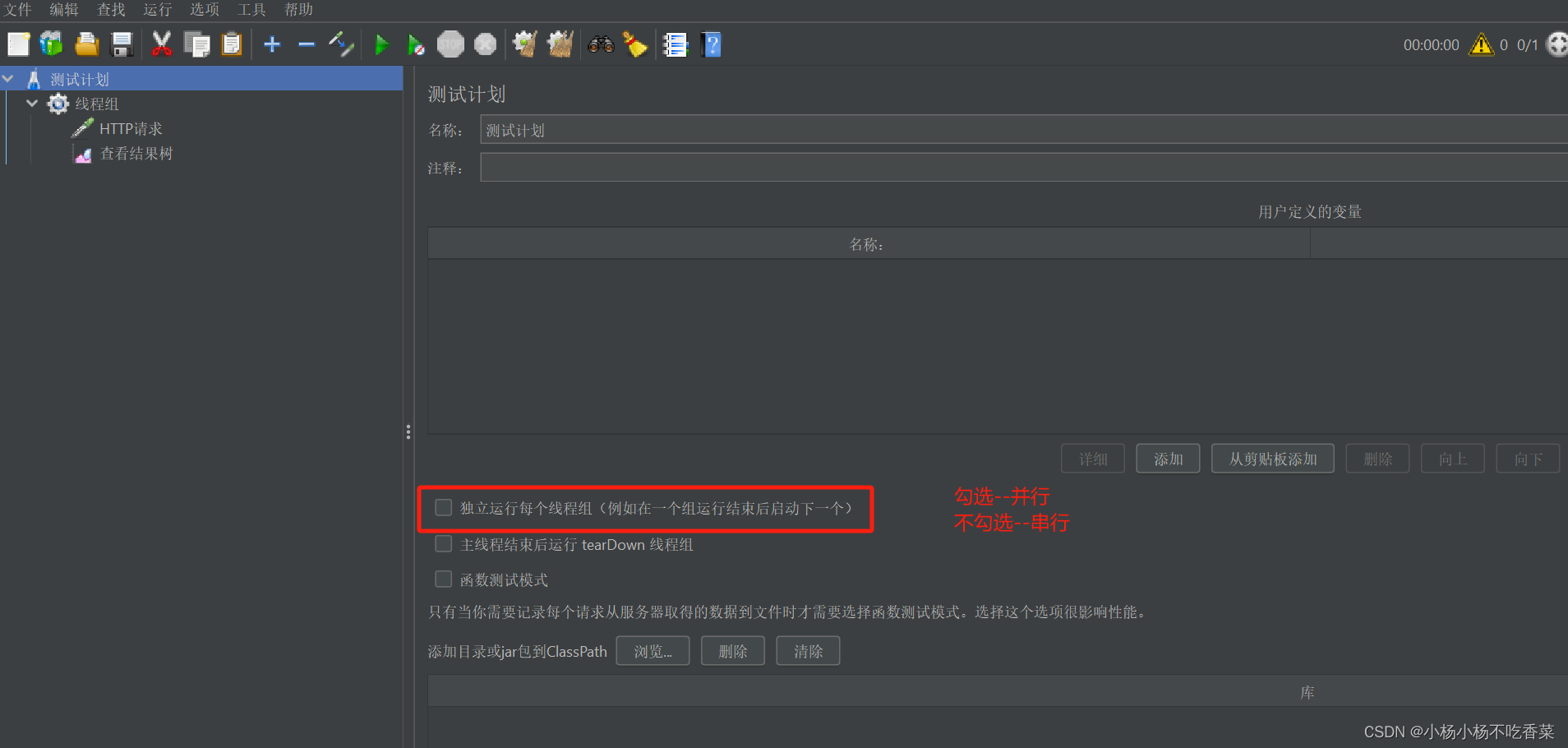
控制Jmeter用于执行测试的一组用户,用于执行测试用例,可以有1个或者多个(并行/串行)
#Setup线程组
预测试操作,所有脚本之前执行
比如:测试用户购物功能时,用于执行用户的注册、登录等操作
#tearDown线程组
测试后操作,所有脚本之后执行
测试用户购物功能时,用于执行用户的退出等操作
tips:默认情况下,如果测试按预期完成,则TearDown线程组将不会运行。
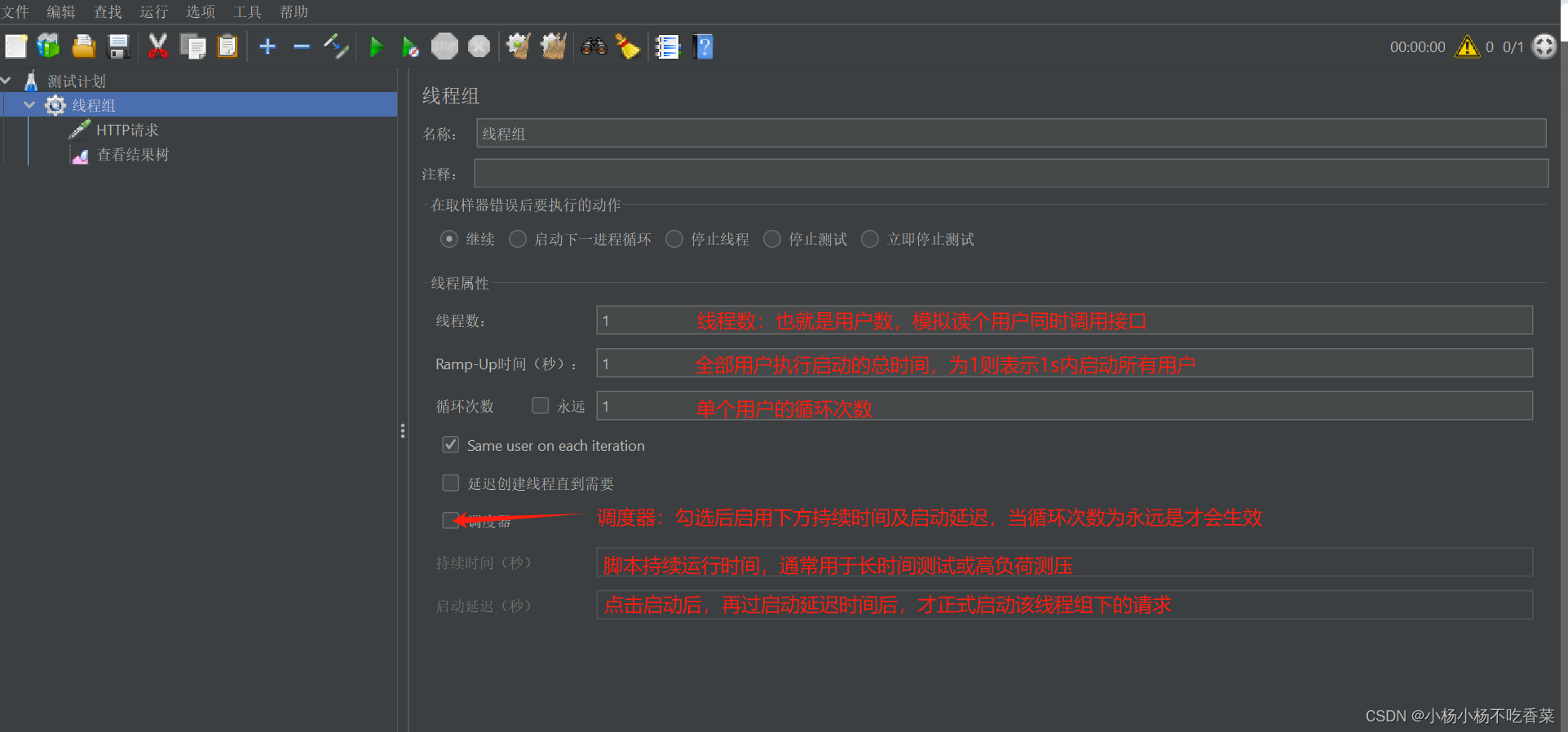
线程组的并行或串行启动的开关按钮:
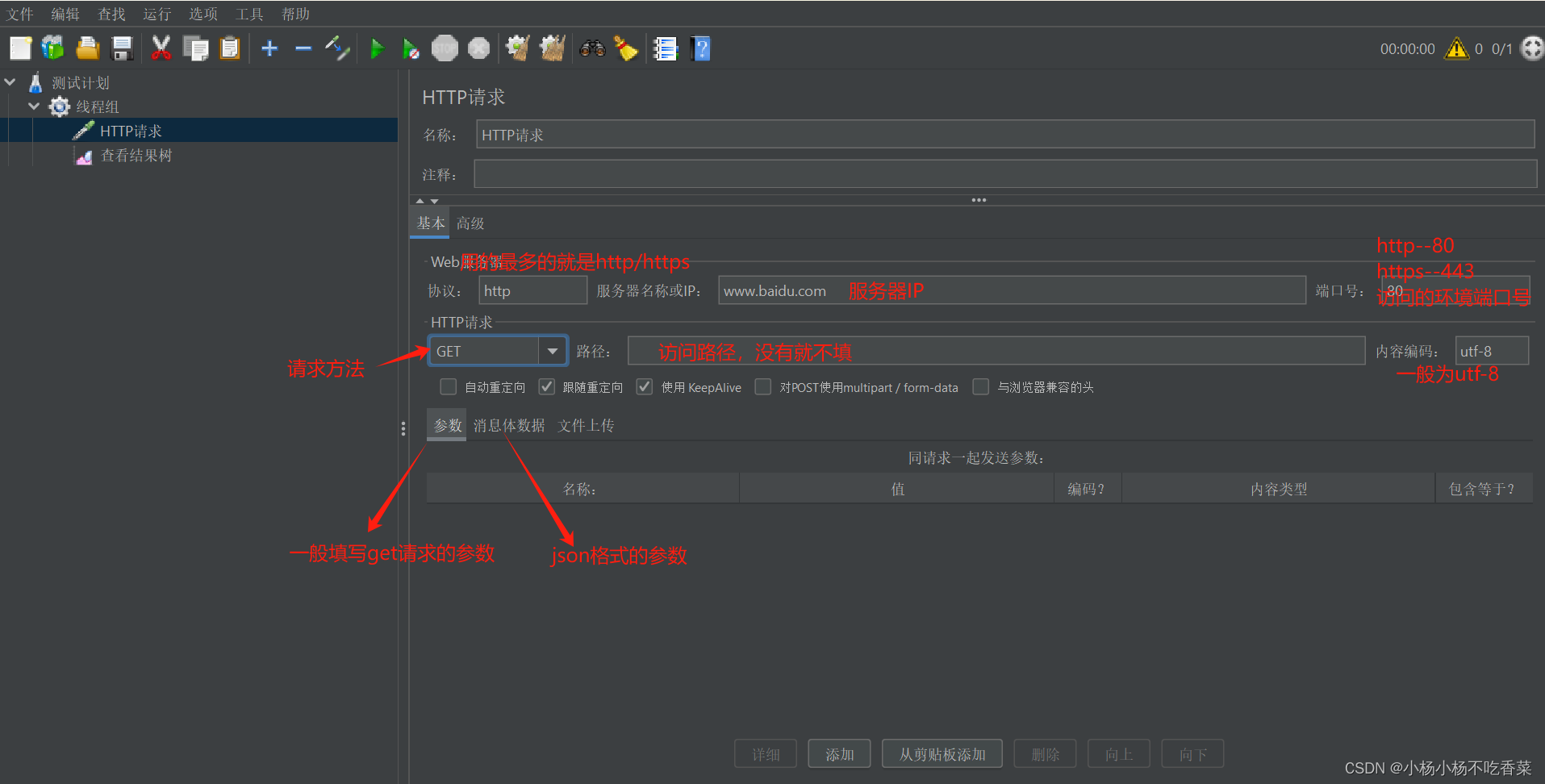
2.HTTP请求参数填写
3.参数处理
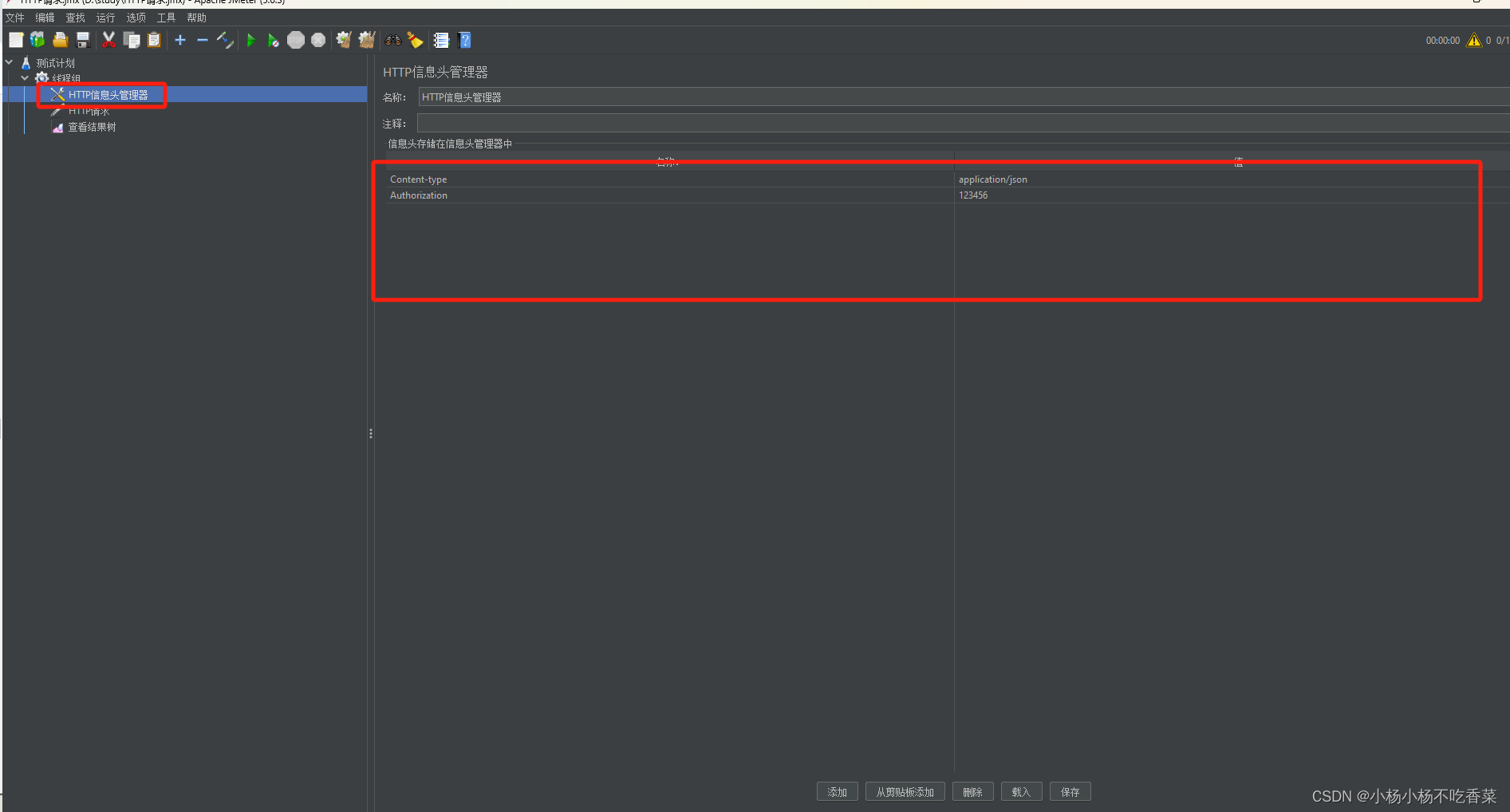
- 全局参数
HTTP请求头管理器,避免添加多个HTTP请求时,需要多次添加HTTP请求头信息
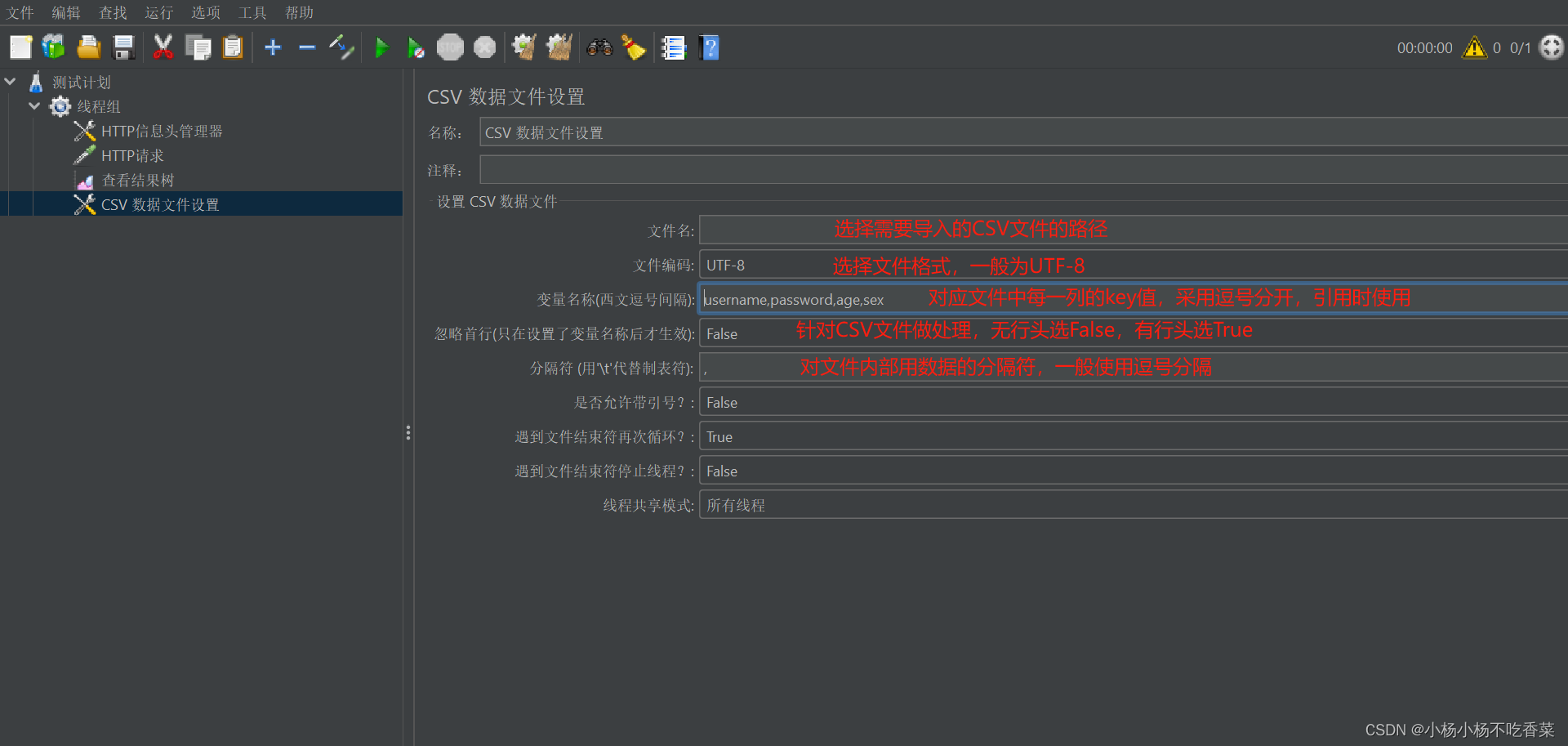
- 数据文件
CSV数据文件设置—文件方式参数化
使用:只需要在需要导入的地方采用${变量名}就可以使用
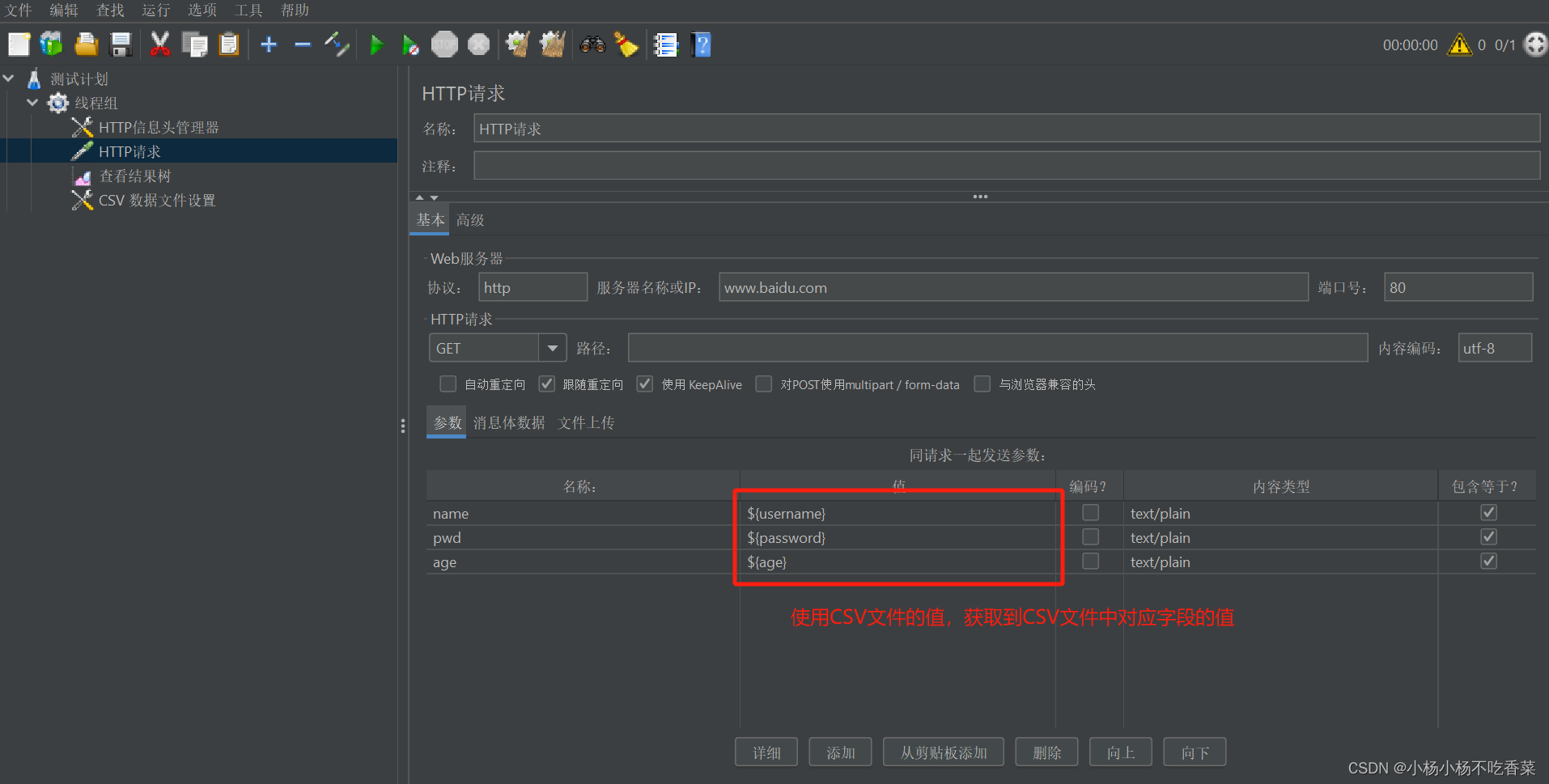
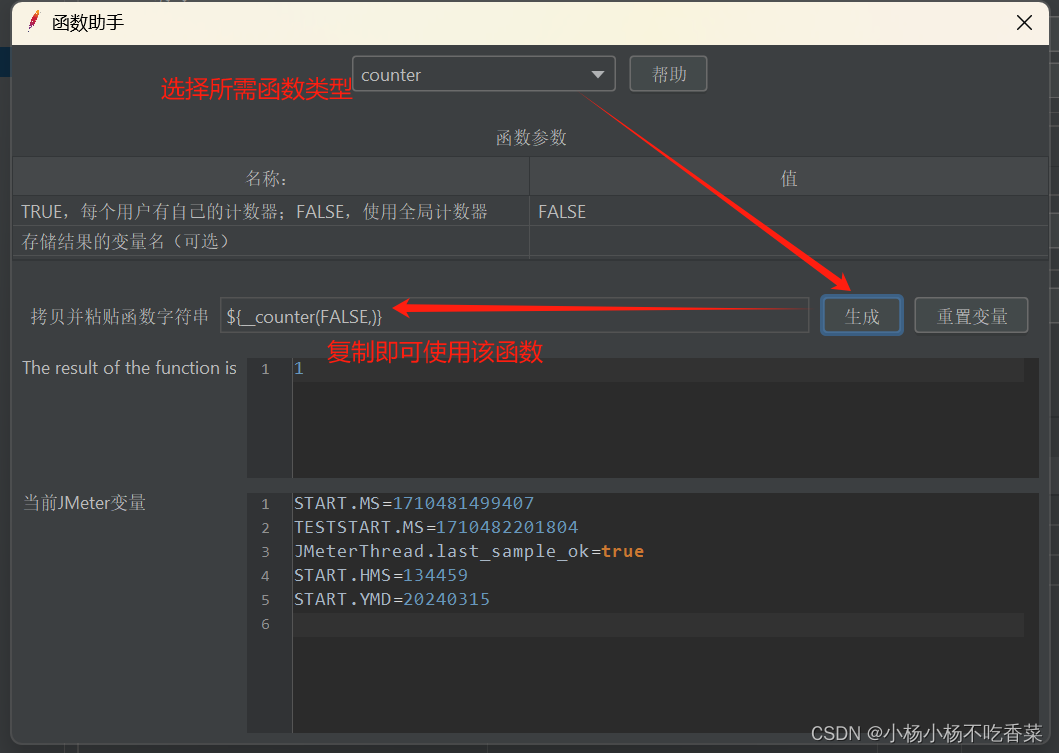
- 函数–生成随机数据
打开方式:工具–函数助手对话框
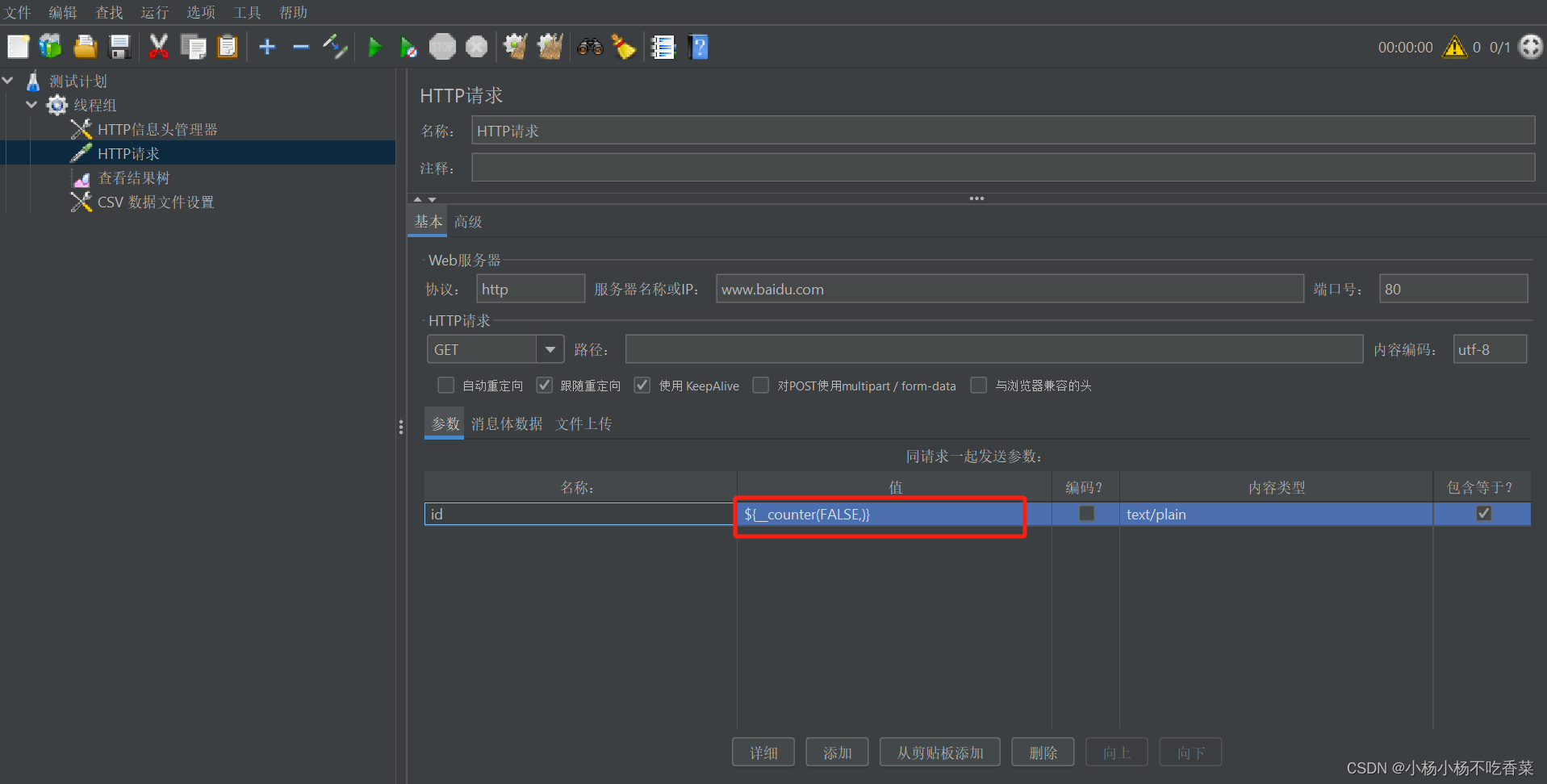
总结
#全局变量
作用:定义全局变量
局限性:每次取值(无论用户)都是固定值
#数据文件
作用:保证不同用户在不同循环中取到不同参数
局限性:需要手动设置数据,当用户循环过多,数据设置过多显得繁杂
#函数参数
作用:自动生成不重复的数据,让每个用户每次循环都获取到不同的数据,且不需要提前定义
局限性:针对特定要求的场景,无法使用,泛用性较低(例如需要输入正确的账号密码进行登录时)
4.Jmeter断言
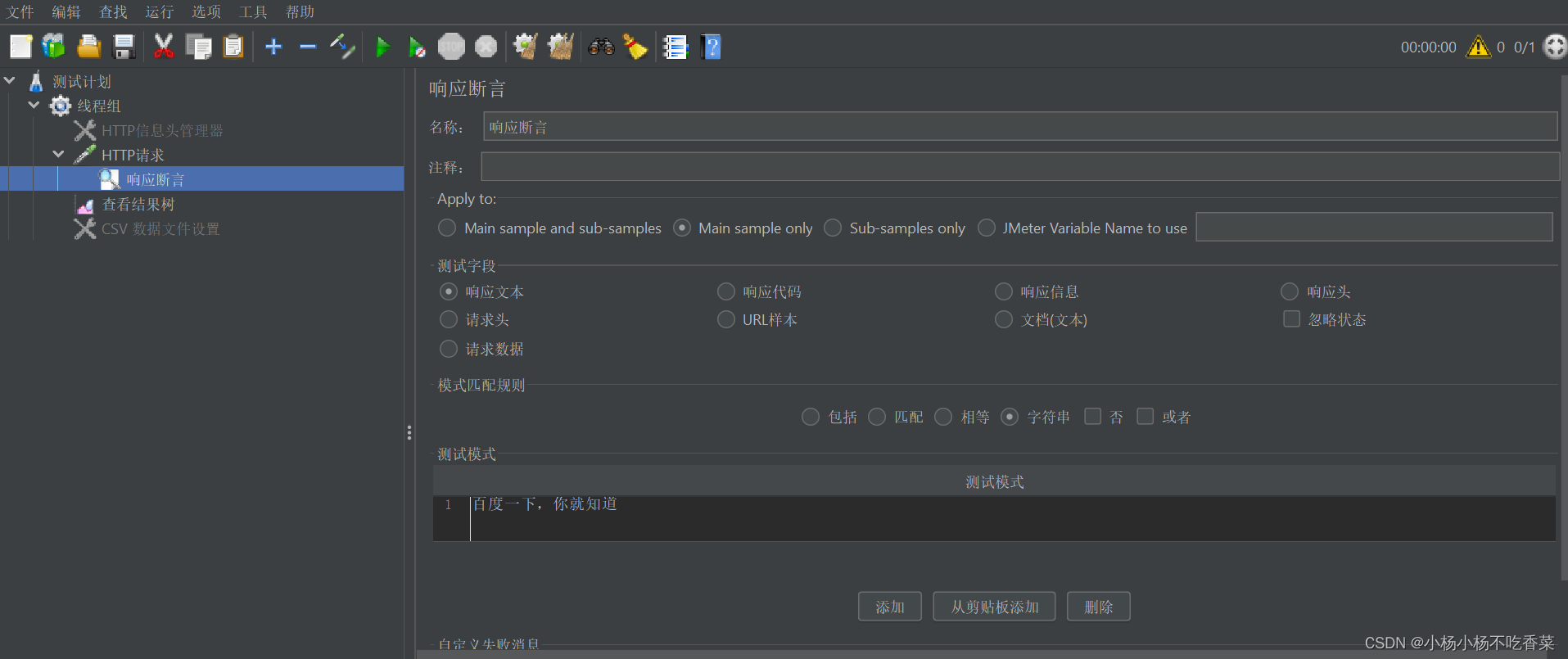
- 响应断言
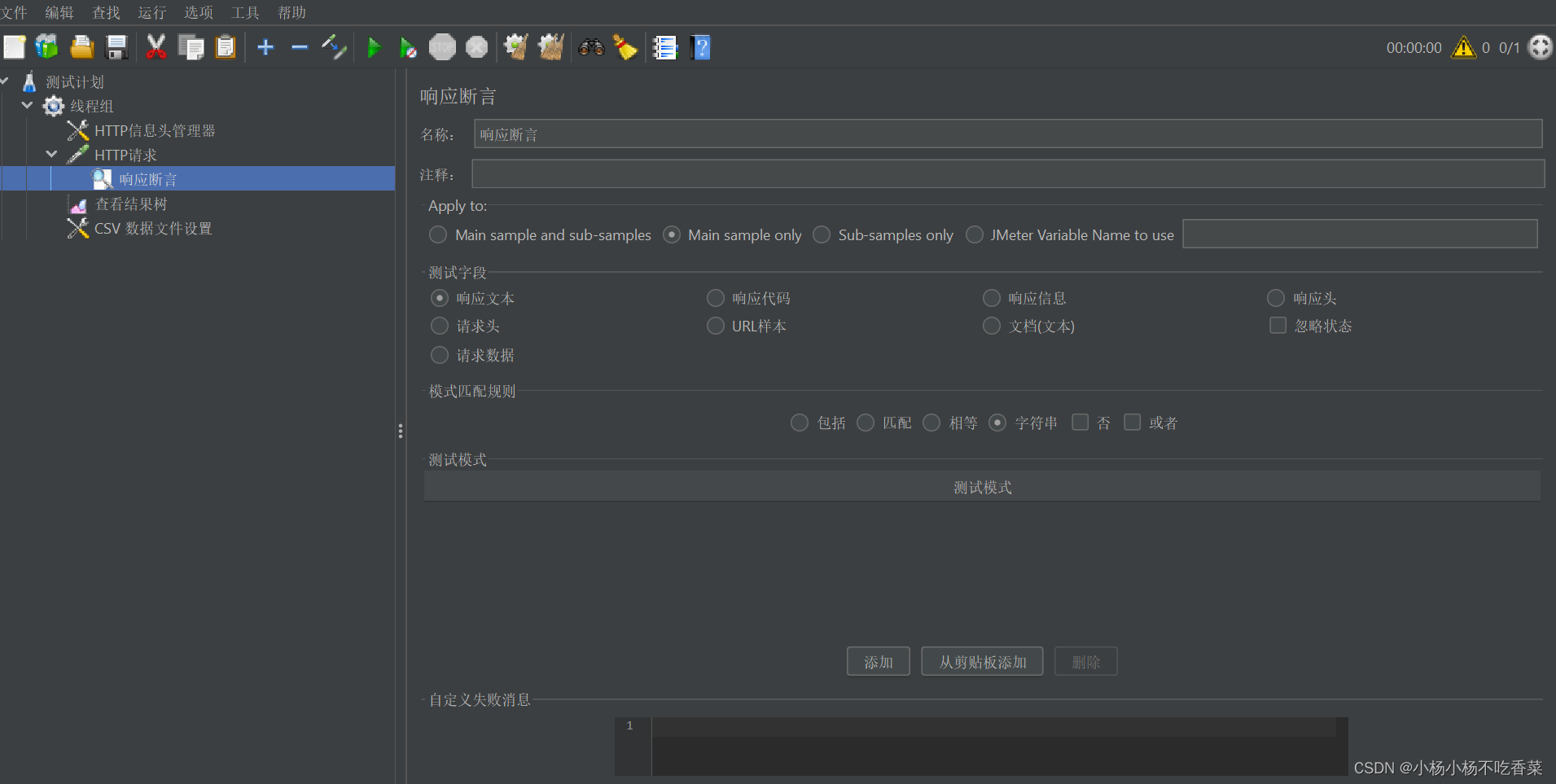
1.响应断言下方的名称和注释就是该响应断言的展示属性
2.apply to 这里我们选择默认 Main sample only 即可
3.测试字段主要是指我们是根据response的哪一部分来进行断言匹配
响应文本:来自服务器的响应文本,即主题
响应代码:响应状态码,例如200
响应信息:响应的信息,例如OK
响应头:响应头部
请求头:请求头部
URL样本:请求URL路径
文本:响应的整个文本信息
请求数据:请求数据
忽略状态:请注意这里是复选框,因为我们的断言有响应码自动判断机制,如果我们需要判断响应码为非200状态,我们需要将其勾选防止报错
4.模式匹配规则
包括:文本包含指定的正则表达式
匹配:整个文本完全匹配指定的正则表达式
相等:整个返回结果文本完全匹配指定的字符串
字符串:返回结果文本包含指定的字符串
否:当存在多个测试模式时,默认为and(当全部满足才通过断言),如果勾选这里相当于!(全部不满足才通过断言)
或者:当存在多个测试模式时,默认为and(当全部满足才通过断言),如果勾选这里相当于or(存在一个满足就通过断言)
当然否和或者你也可以一起使用,相当于!or(存在一个不满足就通过断言)
5.测试模式
我们可以添加多个测试模式
测试模式其实就是断言的判断值,与response进行比较
结果值 比较方式 预期值 --> ${测试字段} ${模式匹配规则} ${测试模式}
例如:text == “百度一下,你就知道”
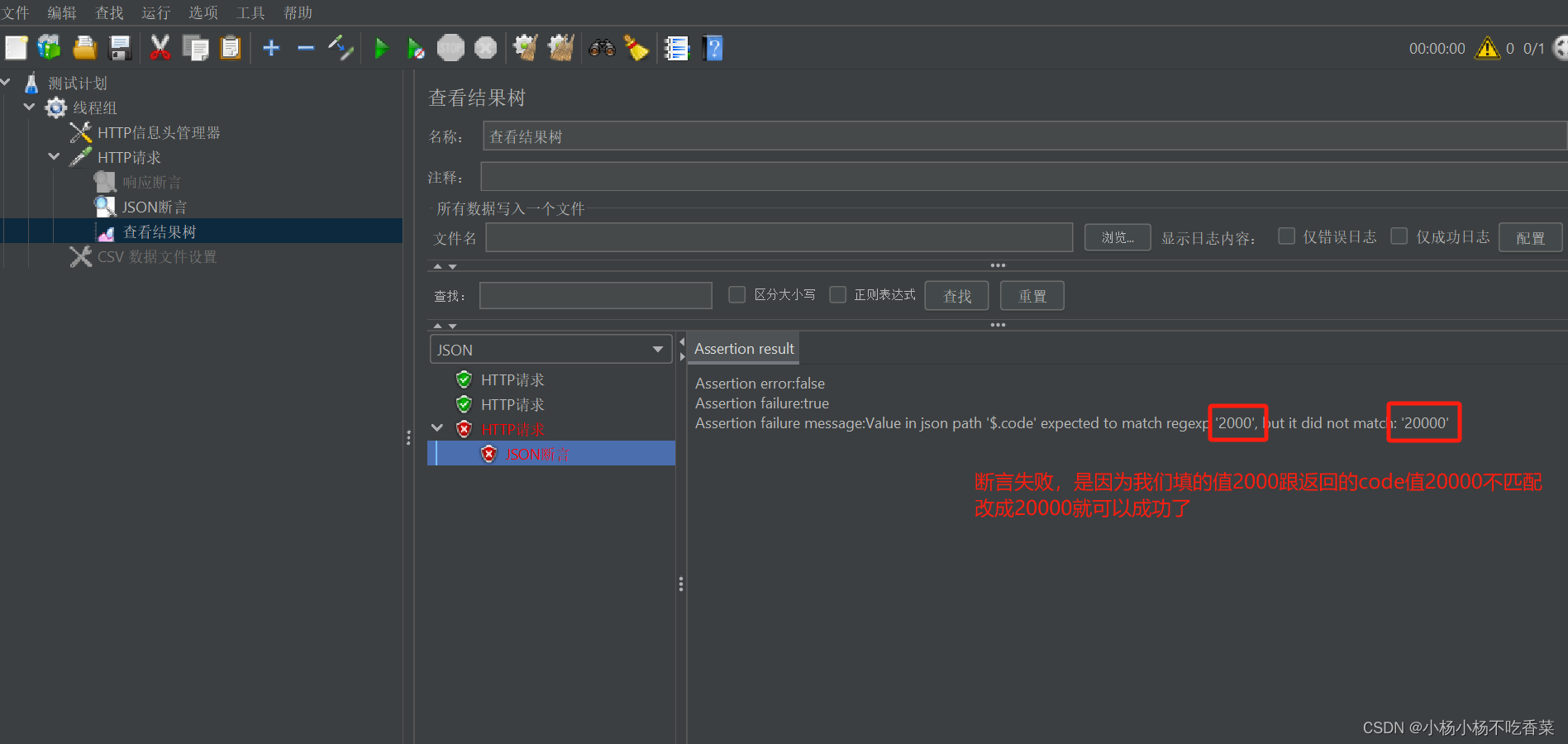
- json断言
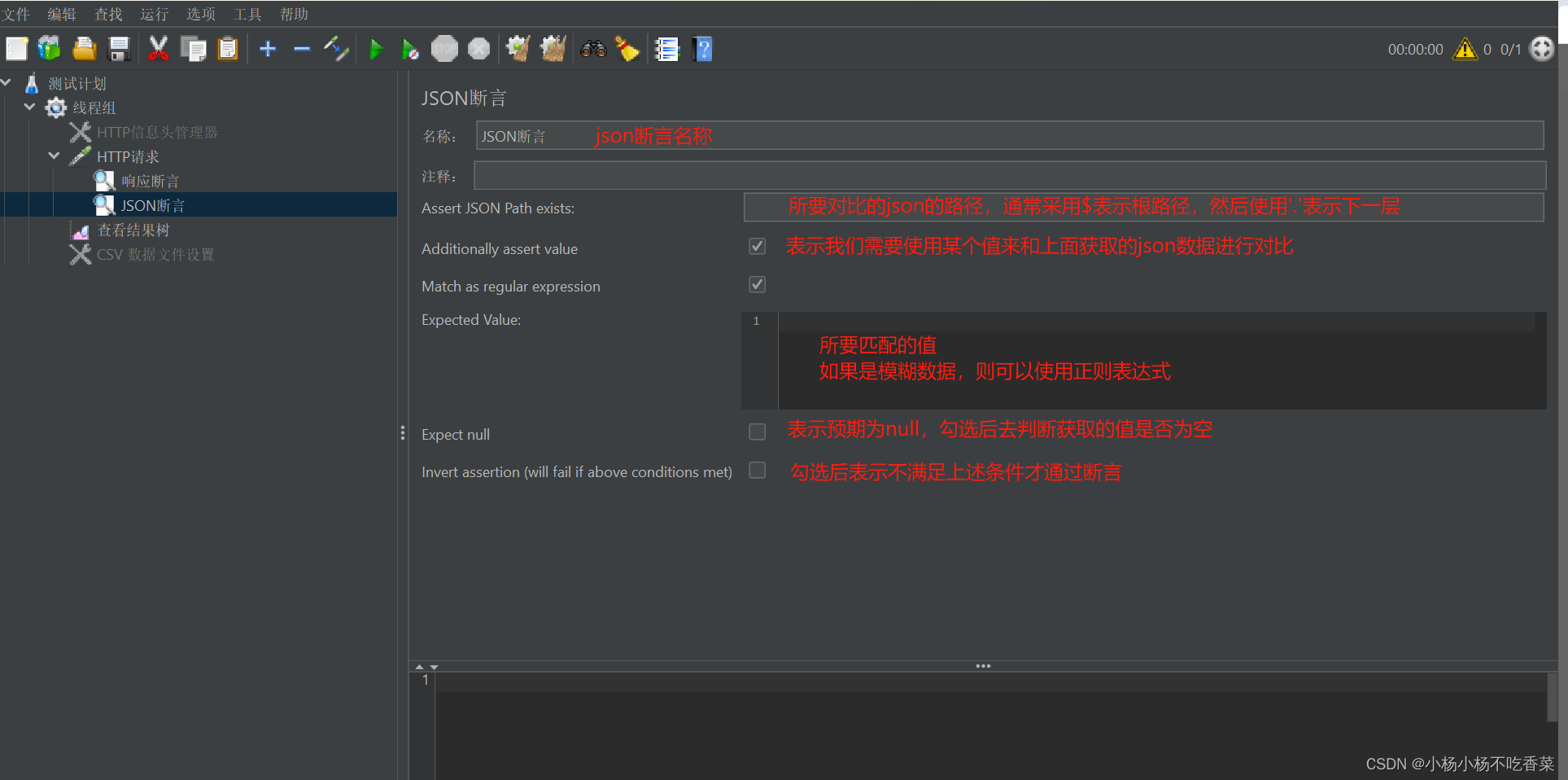
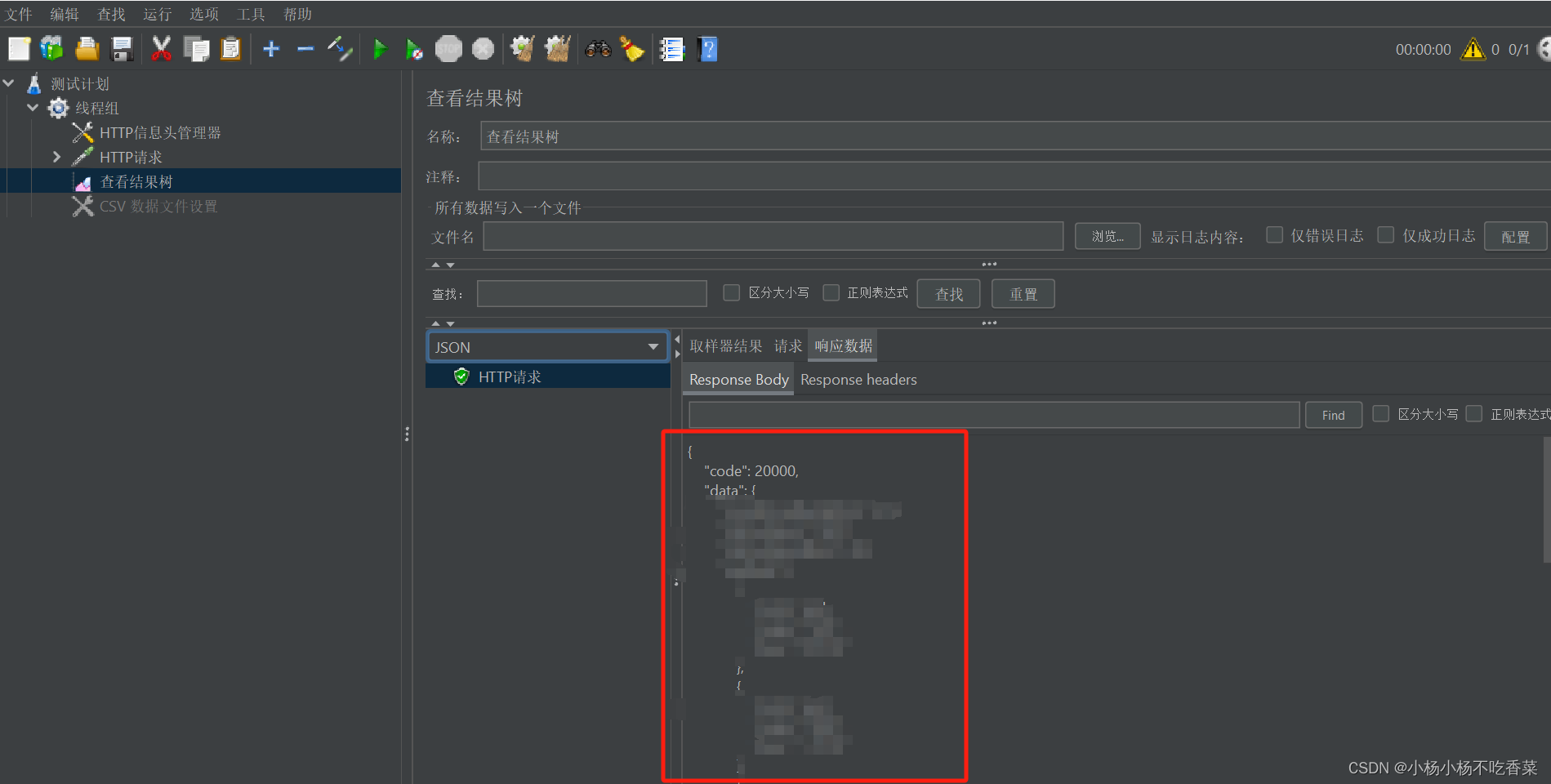
这是一个json格式的返回数据,我们来根据这个返回值进行匹配
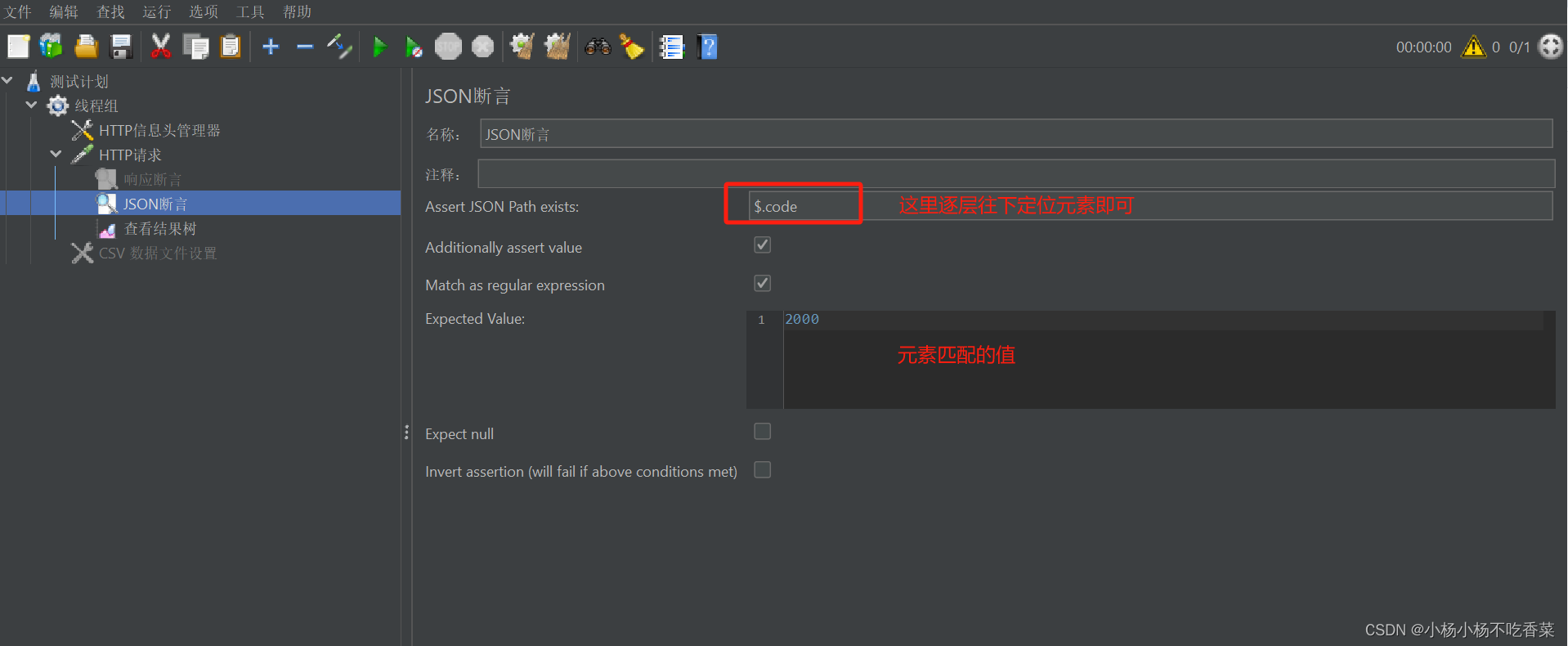
断言结果
5.正则表达式提取器
我们常用的匹配符号主要包含以下三种:
.:是通配符,可以代表任意字符(除换行回车)
*: 代表前面的字符出现0次或者多次
.*匹配规则:找到左边界值后,往右查找有边界,找到最后面的右边界,中间的所有数据都被记录下来
?: 代表非贪婪匹配,找到左边界后,往右查找匹配右边界,只要有匹配的右边界就停止继续查找;再次查找
例如我们要查找’hello world’
返回数据格式:“hello world hello world ”
我们使用(.<em>)</em> ,会一直往后寻找到最后一个标识符,匹配到的就是 hello worldhello world<br/> 我们使用<title>(.?) ,找到第一个就会停下,匹配到的就是hello world
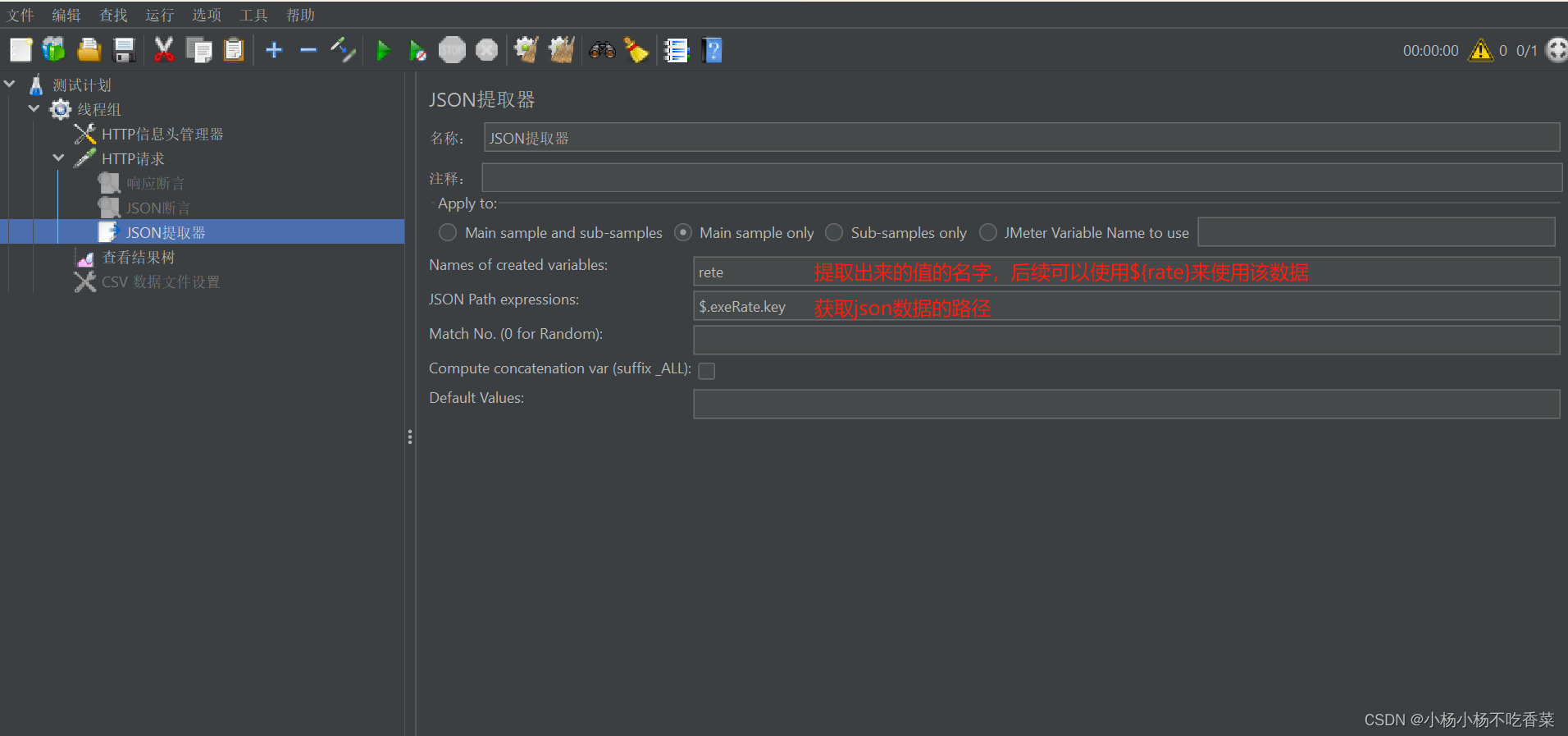
6.JSON提取器
JSON提取器主要针对返回结果是JSON的响应结果数据进行提取