一、前言
上一篇文章中,介绍了防火墙配置文件包含的基本元素和格式样式,并模拟了几组有代表性的规则内容,作为基础测试数据。在拿到基础测试数据后,关于我们最终想解析成的数据是什么样式的,其实不难看出,主要还是和IP地址组、服务端口组、规则清单这三个模块类别有关。配置文件里的数据内容是逐行从上到下,依次展示的IP地址组信息、服务端口组信息、规则清单信息;故我们可采用shell逐行读取文本内容,加上相应的过滤处理机制,分别获取到我们想要的三个模块完整信息。
二、shell处理说明
1、定义好工作处理目录,及相应参数文件,方便脚本处理时文件的统一输出和获取,例如:
#定义工作目录
dir="/mnt/hgfs/python/rule/test"
#定义工作临时目录
dirtmp="/mnt/hgfs/python/rule/test/dirtmp"
#定义防火墙配置文件目录
dirtcfg="/mnt/hgfs/python/rule/test/cfg"#定义防火墙处理结果输出目录
dirresult="/mnt/hgfs/python/rule/test/result"#定义防火墙名称
fwname="policy"
2、处理逻辑
通过整体配置文件的读循环,将每行内容输出到临时文件中,再对临时文件进行文本过滤,依次获取到 所有IP地址组信息、服务端口组信息、规则清单信息,在文本过滤过程中,需要考虑到不同文本的过滤条件,以及数量的控制(例如一个端口组下面对应多条端口信息等),示例如下:
1)定义好需要截取的数据内容和准备工作
###创建三类表的基础信息内容
echo 'fwname ipgroupname securityzone ipaddress' > $dirresult/$fwname-ipgroup
echo 'fwname servicegroupname serviceport' > $dirresult/$fwname-servicegroup
echo 'fwname rulename ruleid description action source-zone destination-zone source-ip-host destination-ip service' > $dirresult/$fwname-rule####创建三类表临时处理目录及初始文件
mkdir -p $dirtmp/$fwname/ipgrouplinshitmp
mkdir -p $dirtmp/$fwname/servicegrouplinshitmp
mkdir -p $dirtmp/$fwname/rulelinshitmpecho "#" > $dirtmp/$fwname/ipgrouplinshitmp/name
echo "#" > $dirtmp/$fwname/ipgrouplinshitmp/zone
echo "#" > $dirtmp/$fwname/ipgrouplinshitmp/ip
echo "#" > $dirtmp/$fwname/servicegrouplinshitmp/servicename
echo "#" > $dirtmp/$fwname/servicegrouplinshitmp/serviceport
echo "#" > $dirtmp/$fwname/rulelinshitmp/rule
echo "#" > $dirtmp/$fwname/rulelinshitmp/ruleid
echo "#" > $dirtmp/$fwname/rulelinshitmp/description
echo "#" > $dirtmp/$fwname/rulelinshitmp/action
echo "#" > $dirtmp/$fwname/rulelinshitmp/sourcezone
echo "#" > $dirtmp/$fwname/rulelinshitmp/destinationzone
echo "#" > $dirtmp/$fwname/rulelinshitmp/sourceip
echo "#" > $dirtmp/$fwname/rulelinshitmp/destinationiphost
echo "#" > $dirtmp/$fwname/rulelinshitmp/service
2)循环读取文本内容
####开始读取
cat $dirtcfg/$fwname > $dirtmp/datatmp
echo finalctrl >> $dirtmp/datatmp
cat $dirtmp/datatmp |while read i;
do
echo $i > $dirtmp/$fwname/linshi
####截取关键内容####
ipgroupname=`cat $dirtmp/$fwname/linshi|awk '{ $1="";$2=""; print $0}'`
ipaddress=`cat $dirtmp/$fwname/linshi|awk '{$1="";$2=""; print $0}'`
servicename=`cat $dirtmp/$fwname/linshi|awk '{print $3}'`
serviceport=`cat $dirtmp/$fwname/linshi|awk '{$1="";$2="";$3=""; print $0}'`
rulename=`cat $dirtmp/$fwname/linshi|awk '{ $1="";$2=""; print $0}'`
description=`cat $dirtmp/$fwname/linshi|awk '{ $1=""; print $0}'`
action=`cat $dirtmp/$fwname/linshi|awk '{ $1=""; print $0}'`
sourcezone=`cat $dirtmp/$fwname/linshi|awk '{ $1=""; print $0}'`
destinationzone=`cat $dirtmp/$fwname/linshi|awk '{ $1=""; print $0'}`
sourceip=`cat $dirtmp/$fwname/linshi|awk '{ $1=""; print $0}'`
destinationiphost=`cat $dirtmp/$fwname/linshi|awk '{ $1=""; print $0}'`
service=`cat $dirtmp/$fwname/linshi|grep service|awk '{ $1=""; print $0}'`
3)读取数量的控制,文本内容中,可能存在部分字段为空,同一字段多数值的情况出现,所以增加个数量统计,用以判断取值,例如(截取部分)
###记录各字段计数
ipgroupnum=`cat $dirtmp/$fwname/linshi|grep "ip address-set"|wc -l`
servicenamenum=`cat $dirtmp/$fwname/linshi|grep "ip service-set"|wc -l`
servicenum=`cat $dirtmp/$fwname/linshi|grep service|wc -l`
finalctl=`cat $dirtmp/$fwname/linshi|grep finalctrl|wc -l`###if语句用来控制记录
if [ $ipgroupnum -eq 1 ];then
name=`cat $dirtmp/$fwname/ipgrouplinshitmp/name`
zone=`cat $dirtmp/$fwname/ipgrouplinshitmp/zone`
ip=`cat $dirtmp/$fwname/ipgrouplinshitmp/ip`
echo "$fwname $name $zone $ip" >>$dirresult/$fwname-ipgroup
rm -rf $dirtmp/$fwname/ipgrouplinshitmp
mkdir $dirtmp/$fwname/ipgrouplinshitmp
echo $ipgroupname> $dirtmp/$fwname/ipgrouplinshitmp/name
echo "#" >$dirtmp/$fwname/ipgrouplinshitmp/zone
echo -n "#" > $dirtmp/$fwname/ipgrouplinshitmp/ip
touch $dirtmp/$fwname/ipgrouplinshitmp/ip
elif [ $securityzonenum -eq 1 ];then
rm -rf $dirtmp/$fwname/ipgrouplinshitmp/zone
echo "$securityzone">> $dirtmp/$fwname/ipgrouplinshitmp/zone
三、结果展示
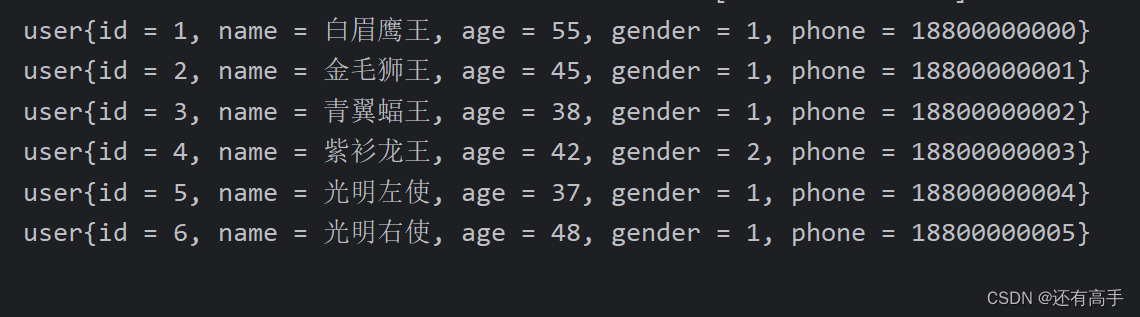
完整脚本执行完之后,可以获取到3个目标数据内容,处理后的格式以csv表格文件形式记录,如
地址组基础数据

端口组基础数据

规则基础数据

完成这一步,算是对原始数据的读取识别,输出成我们想要的基础数据格式(也就是3类数据基础表),下一步则是需要对这3类表进一步展开处理,例如三者之间的关联补充,丰富更多的字段信息等操作内容,处理完,再把最终的数据入库,用于后期的页面查询展示。
关于这一块的数据处理,也有其他程序处理的手段,例如python、java、go语言,都有文本处理的方式,大家都习惯于用哪一种呢?