目录
B树:B-Tree
B+树
字典树:Trie Tree
哈夫曼树
博弈树
B树:B-Tree
多路平衡搜索树
1.M阶B树,就是M叉(M个指针)。
2.每个节点内记录个数<=M-1。
3.根节点记录个数>=1。
4.其余节点内记录个数>=ceil(m/2)-1(向上取整)。
5.每个节点内的记录从左至右从大到小有序。
6.当前记录的左子树的值均小于当前记录,右子树的值均大于当前记录。
插入:
(1)新记录插入叶子节点。
(2)叶子节点记录个数:1.<=m-1结束。2.>m-1裂变,中间记录上移至父亲层,左半部分变成左子树,右半部分变成右子树,讨论父亲层同(2)。
这里是m=5,来演示一下。
这里添加个23


这里添加个88


删除:
(1)查找是否是叶子节点是的话直接删除,不是的话,找到左子树最大值/右子树最小值,进行替换,删除替换记录。
(2)讨论发生删除的叶子节点内记录个数:
1.>=ceil(m/2)-1,结束。
2.<ceil(m/2)-1,看兄弟节点记录的个数:<1> >ceil(m/2)-1,兄弟节点上移一个记录至父亲层,父亲记录下移至当前节点,结束。<2>=ceil(m/2)-1,父亲记录下移,与当前兄弟节点合并成一个新节点,讨论父亲层记录个数同(2)。

这里删除个34是情况(1)叶子节点

这里删个17,是情况(1)非叶子节点,找到他左子树最大值替换

发现删除节点个数不满足ceil(m/2)-1,发现兄弟是第二种情况,父亲记录下移,和当前兄弟节点合并成一个新的节点。

这里删除25,替换后,兄弟节点是第一种情况,兄弟节点上移一个记录至父亲层,父亲记录下移至当前节点,结束。
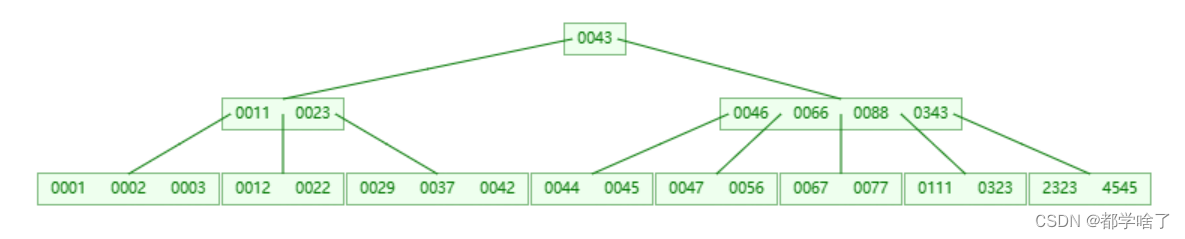
这里删43,别忘了讨论父亲层。


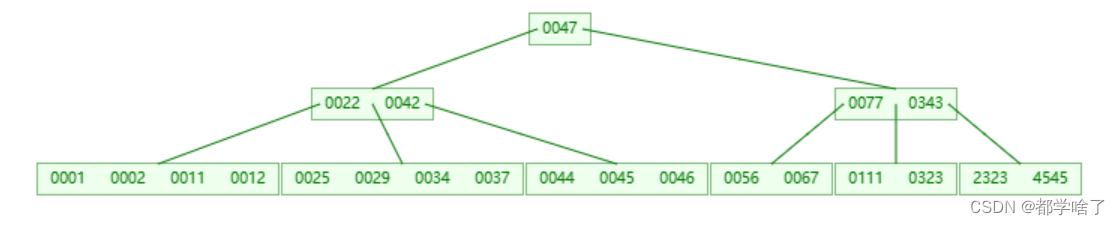
B+树
(1)叶子节点(记录),索引/内部节点。
(2)M阶B+树就是M叉。
(3)根节点既可以是索引节点,也可以是叶子节点。
(4)索引或记录个数<=m-1
(5)根节点内索引或记录个数>=1。
(6)其他节点内索引或记录个数>=ceil(m/2)-1。
(7)每个节点内记录或索引从小到大,从左到右有序。
(8)当前记录或索引的左子树值均小于它,右子树值均大于它。
(9)相邻叶子节点之间有指针从左到右指向。
插入:
(1)记录添加至叶子节点。
(2)讨论叶子节点记录个数:
1.<=m-1结束。
2.>m-1裂变,前m/2个成为左子树,剩余的记录成为右子树,指针从左侧叶子节点指向右侧叶子节点,第m/2+1个记录的索引复制一份至父亲层。
(3)讨论父亲层索引个数:
1.<=m-1,结束。
2.>m-1,裂变,中间索引上移至父亲层,左半部分成为其左子树,右半部分成为其右子树,讨论父亲层索引个数同(3)。
例:五阶
添加了13,<=m-1结束。
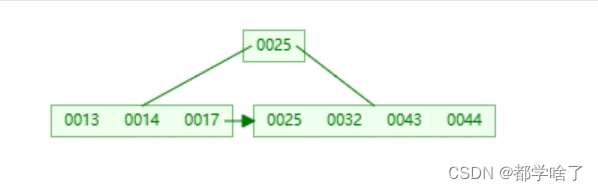
添加50,裂变了。
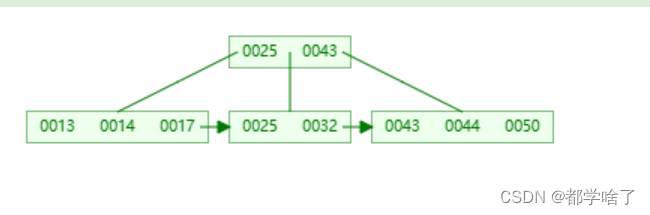
再添加一些数

然后我们添加46,父层是第二种情况。
删除:
(1)在叶子节点中删除对应记录。
(2)看叶子节点内记录个数。
1.>=ceil(m/2)-1结束。
2.<ceil(m/2)-1,看兄弟节点记录个数。
<1> >ceil(m/2)-1,兄弟记录移动一个至当前节点,更新父亲索引,结束。
<2> =ceil(m/2)-1,删除父亲索引,当前节点与兄弟节点合并成一个新节点。
(3)讨论父亲层索引个数:
1.>=ceil(m/2)-1结束。
2.<ceil(m/2)-1,看兄弟节点索引个数。
<1> >ceil(m/2)-1,兄弟节点上移一个索引至父亲层,父亲索引下移至当前节点,结束。
<2> =ceil(m/2)-1,父亲索引下移,与当前节点和兄弟节点合并成一个新节点,讨论父亲层索引个数,同(3)。
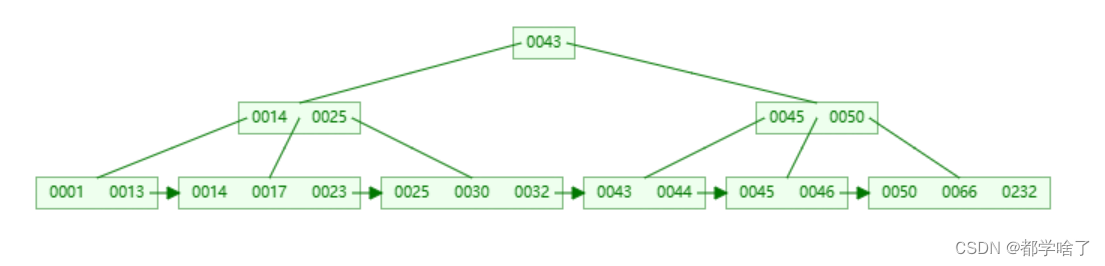
例:
删除1,兄弟记录移动一个至当前节点,更新父亲索引为6。


删除45,兄弟节点索引个数不够,父亲下移,与当前节点和兄弟节点合并成一个新节点。


B树和B+树之间除了刚刚写的增删,还有结构上,B树每个节点都有记录,B+有叶子节点和索引,指针(叶子),查:B树1~,B+树
,B+树更适合范围搜索。
字典树:Trie Tree
用于多个串搜索某个串。
字典树要完成对其计数查找排序。
创建字典树:
(1)不能为空树。
(2)每个节点内不包含字符,结构体:指针数组,标记:兼具计数功能。
1.root初始化。
2.单词添加:<1>遍历单词:字符对应分组,若不存在则创建节点,处理下一个字符,若存在,就处理下一个字符。<2>末尾标记。
查找:遍历单词,字符对应分组是否存在,不在则失败,末尾标记检测一下。
#include<iostream>
#include<stdio.h>
#include<string.h>
using namespace std;
typedef struct node
{int Count;struct node* p[26];char* str;
}TrieTree;
TrieTree* chuang()
{TrieTree* ptemp = (TrieTree*)malloc(sizeof(TrieTree));memset(ptemp, 0, sizeof(TrieTree));return ptemp;
}
void Per(TrieTree* pTree)
{if (pTree == NULL)return;if (pTree->Count != 0)cout << pTree->str << endl;for (int i = 0; i < 26; i++){Per(pTree->p[i]);}
}
void Add(TrieTree* pTree, char* ss)
{for (int i = 0; i < strlen(ss);i++){//创建节点if (pTree->p[ss[i] - 97] == NULL){pTree->p[ss[i] - 97] = chuang();}//下一个pTree = pTree->p[ss[i] - 97];}pTree->Count++;pTree->str = ss;
}
TrieTree* Create(char* s[], int len)
{if (s == NULL || len <= 0)return NULL;//root初始化TrieTree* pRoot = chuang();//单词添加for (int i = 0; i < len; i++){Add(pRoot, s[i]);}return pRoot;
}
//查找
void Serach(TrieTree* pTree,char* ss)
{if (pTree == NULL || ss == NULL)return;for (int i = 0; i < strlen(ss); i++){if (pTree->p[ss[i] - 97]==NULL) {cout << "fail 1" << endl;return;}pTree = pTree->p[ss[i] - 97];}if (pTree->Count != 0)cout << "scuess" << pTree->str << endl;else {cout << "fail 2" << endl; return;}
}
int main()
{char *s[] = {"oh","my","god"};TrieTree* pTree=Create(s, 3);Per(pTree);Serach(pTree, "god");return 0;
}哈夫曼树
度为0或2,带权路径长度WL:权值*边数,总带权路径长度最小是最优二叉树也就是哈夫曼树。
哈夫曼编码:实现无损压缩和恢复。
例如:A:10 B:15 C:40 D:30 E:5
(1)先排序:E:5 A:10 B:15 D:30 C:40
(2)找出两个最小值
(3)放回
(按同一规则放)

按左是0,右是1,A为1101,我们这棵树里每个都是叶子节点,所以这个树里哈夫曼编码都是无前缀码。
博弈树
1.全信息2.非偶然3.零和(无双赢)
极大极小搜索树,减枝。
感兴趣可以去了解一下。