终身学习
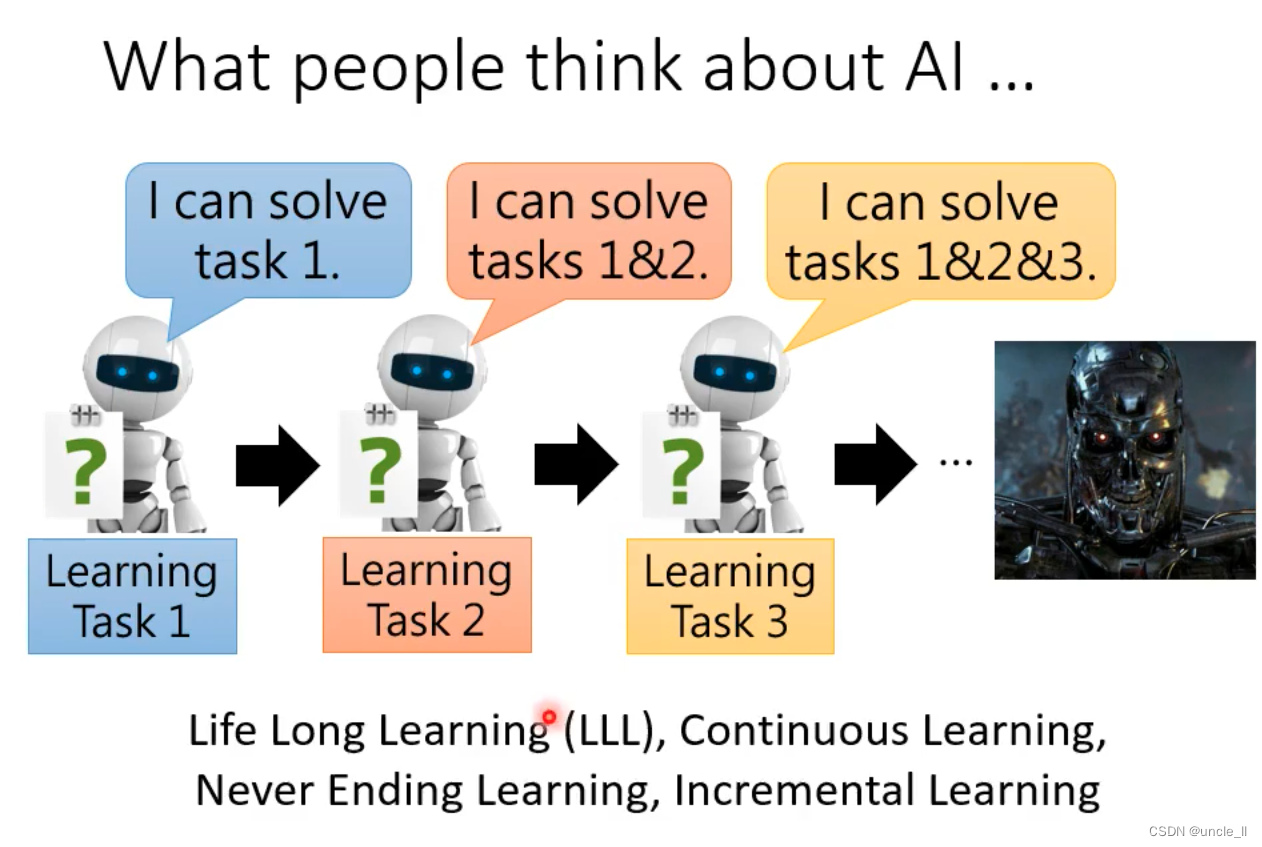
- AI不断学习新的任务,最终进化成天网控制人类
- 终身学习(LLL),持续学习,永不停止的学习,增量学习
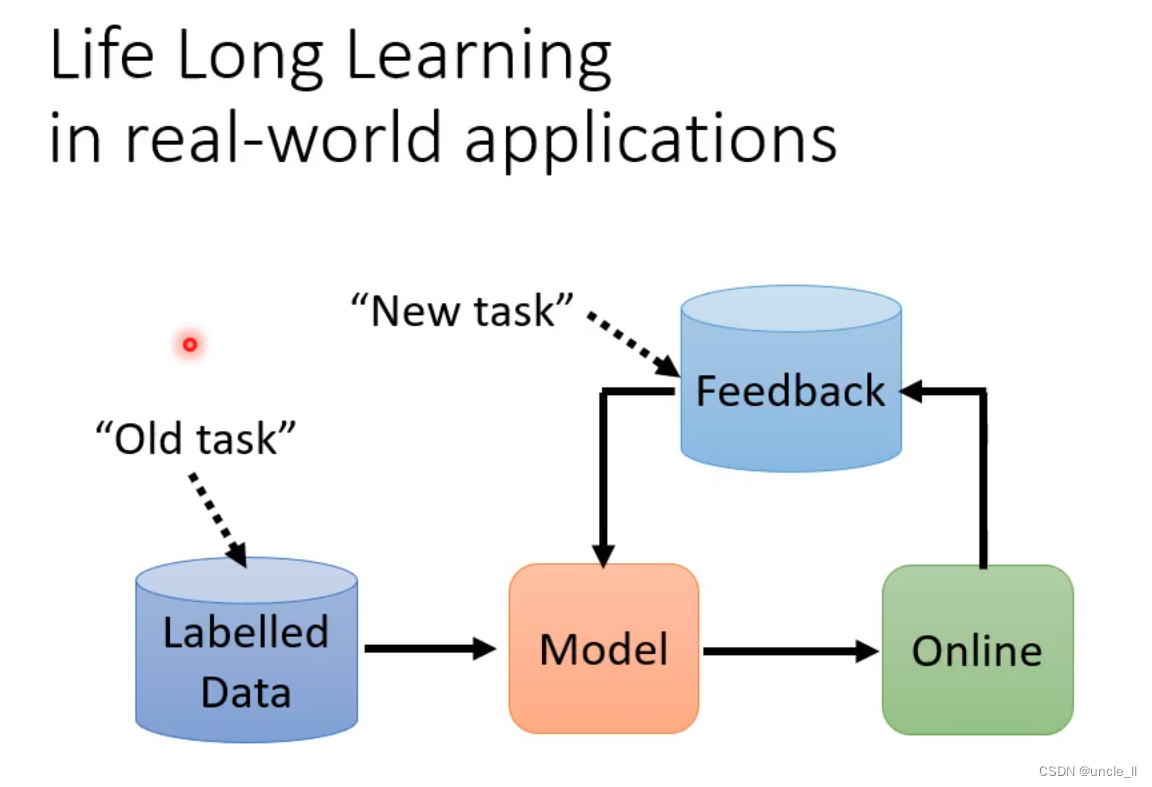
- 用线上收集的资料不断的训练模型
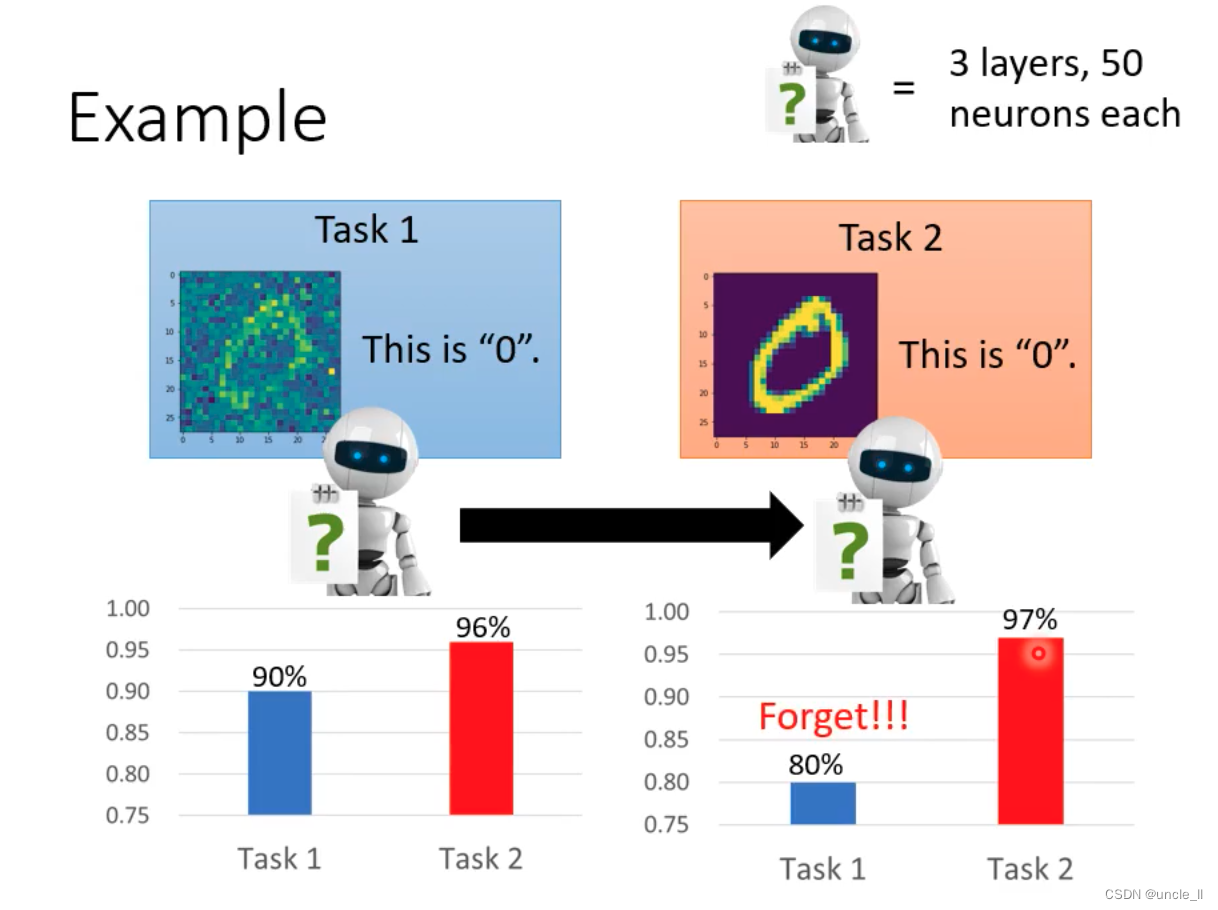
- 问题就是对之前的任务进行遗忘,在之前的任务上表现不好

- 要同时学好任务,可以将数据放一起进行学习,如果没有一起学的话,会忘记之前的一个
例子
20个QA任务

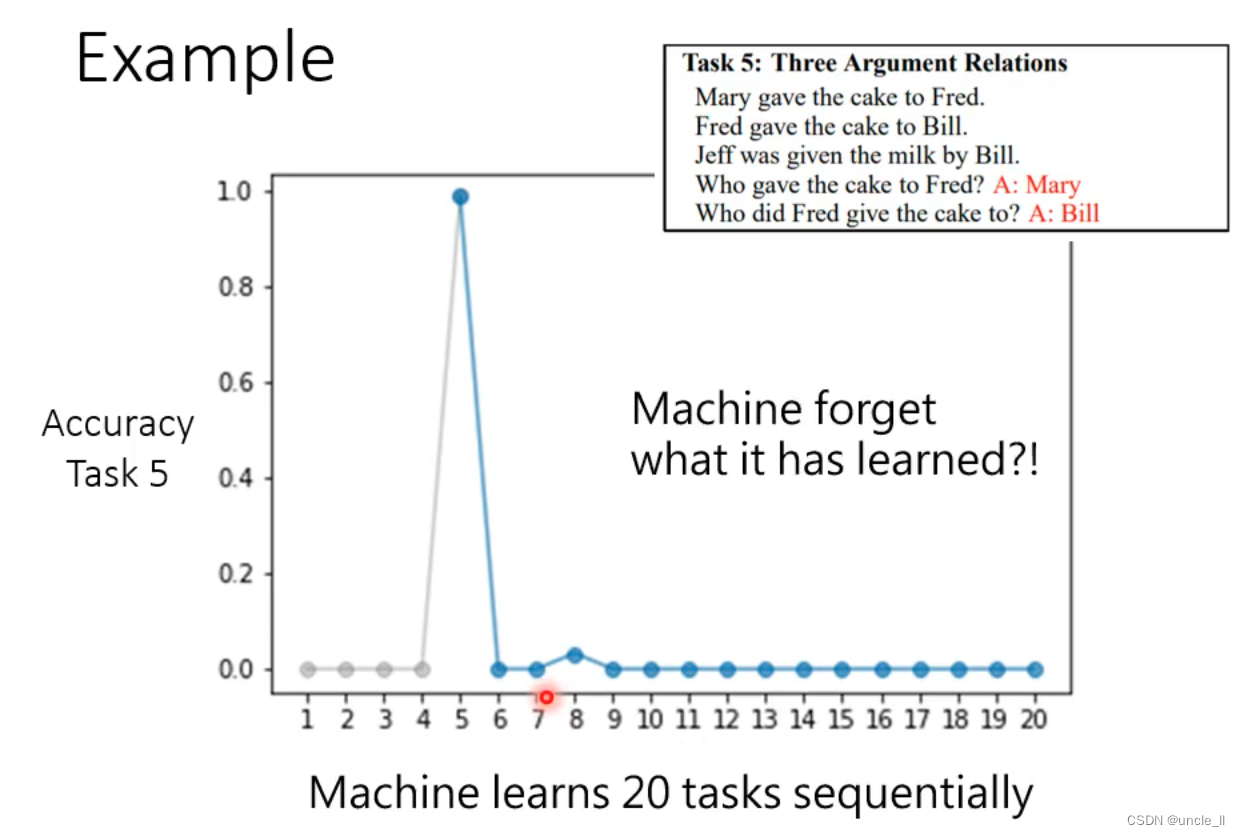
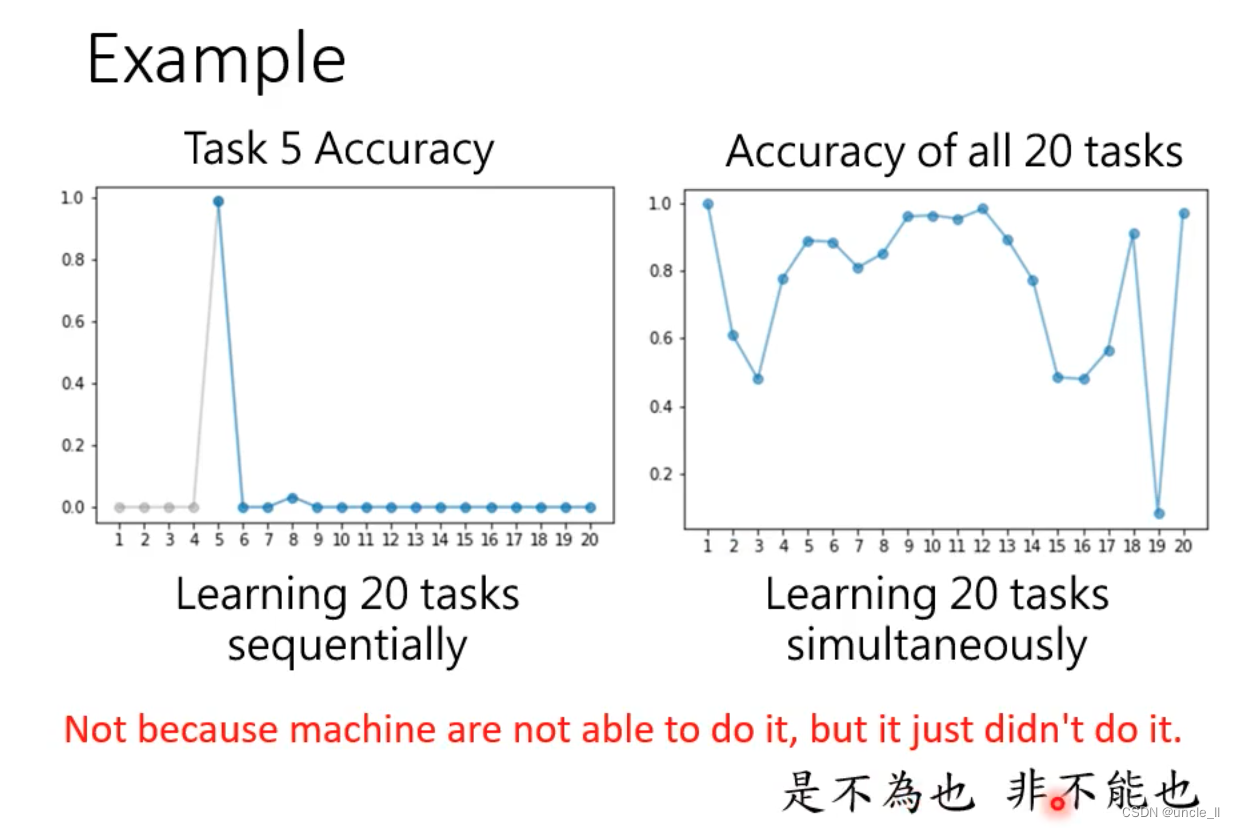
- 同时学习20个任务的时候在一些任务上是表现不错的,同时会一些技能
- 连续学的话不太可能学会所有的

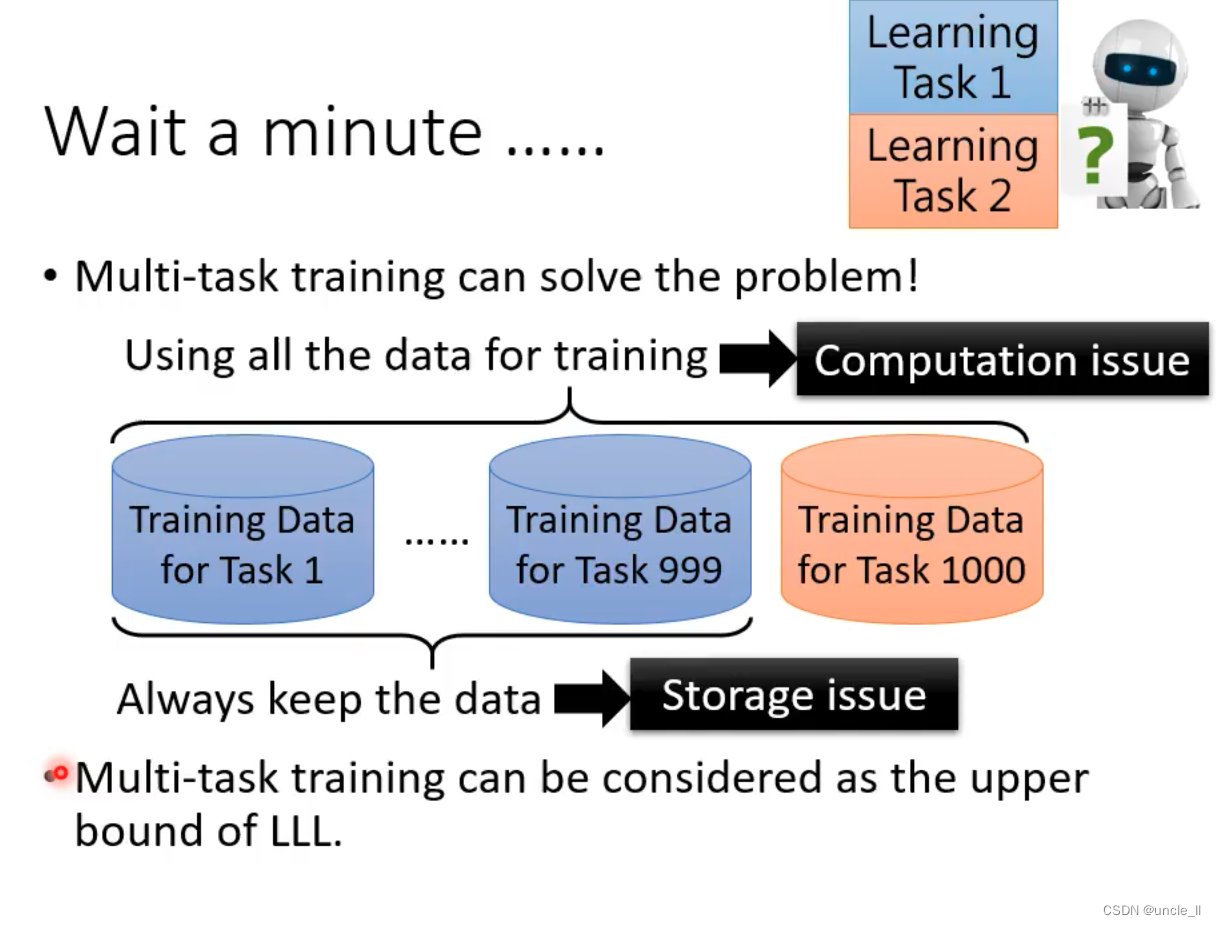
- 多任务训练可以解决问题!使用所有数据进行训练
- 存储问题
- 计算问题
- 多任务训练可以被视为LLL的上限
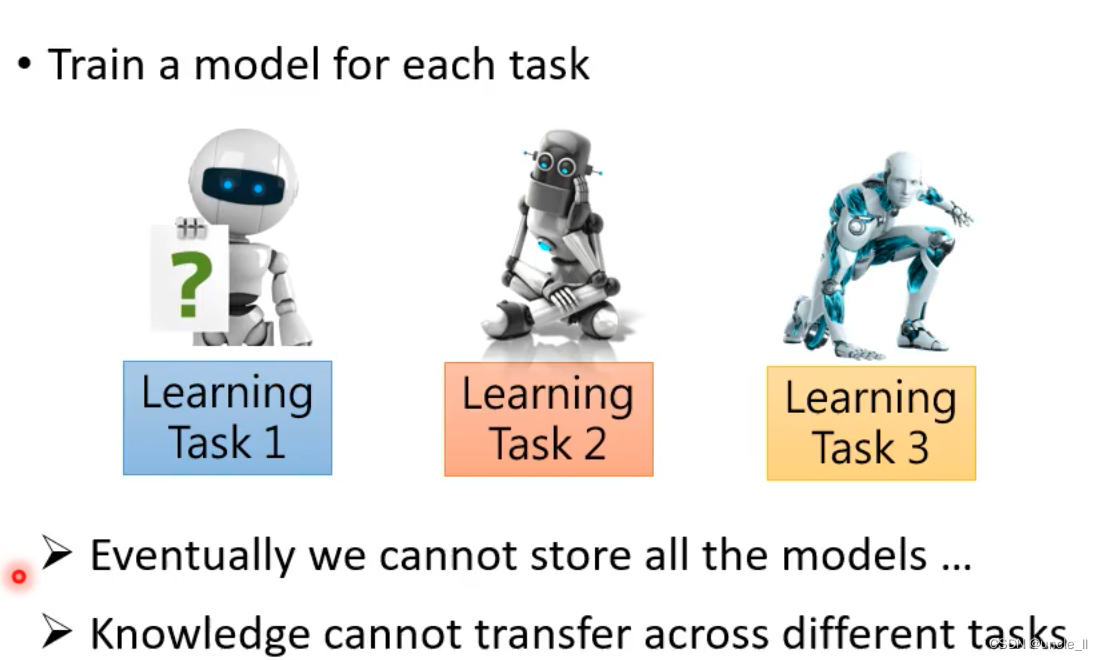
- 最终我们无法存储所有模型
- 知识无法在不同任务之间转移
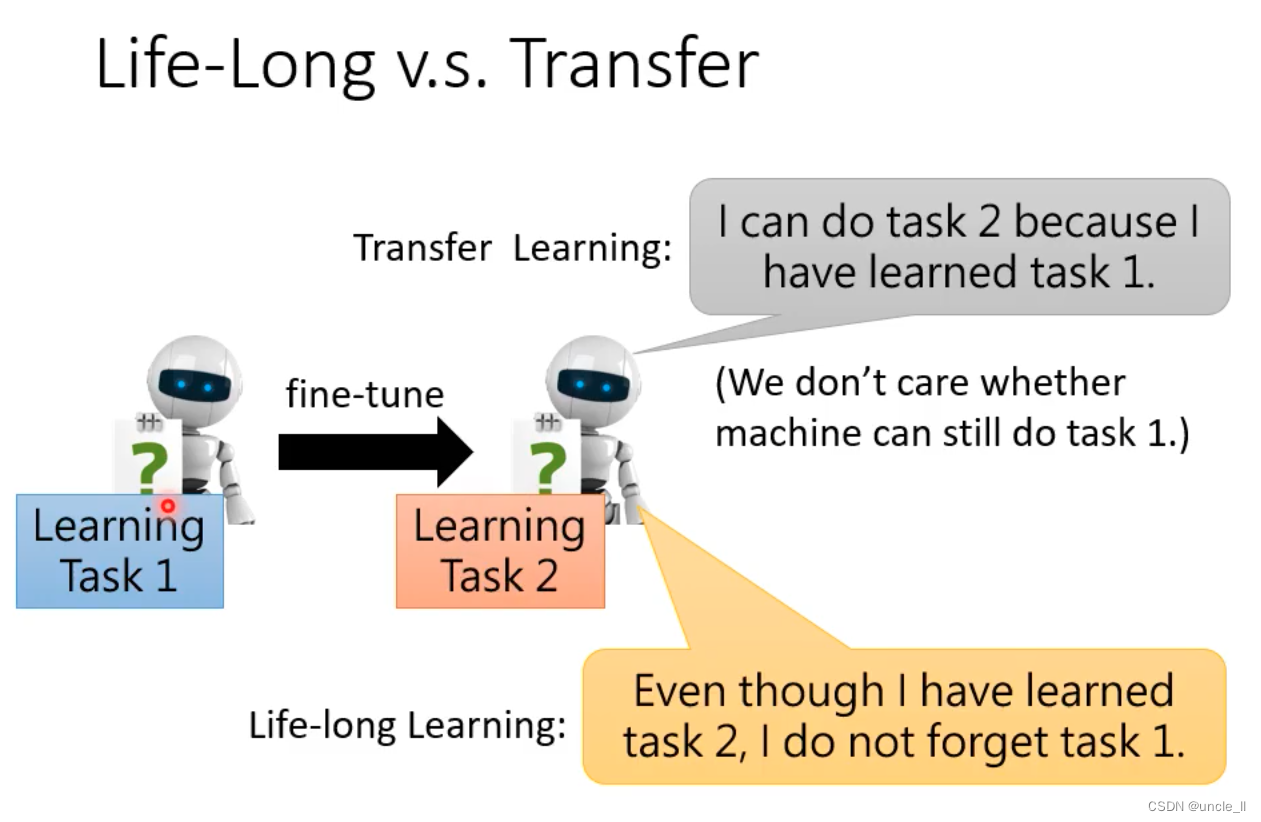
- 迁移学习:可以做任务2,因为已经学会了任务1,不关心机器是否仍然能够完成任务1
- 终身学习:即使我已经学会了任务2,我也不会忘记任务1。
- 迁移学习是指将从一个任务学到的知识或模型应用到另一个相关任务中的机器学习方法。通过利用已有任务的知识来加速新任务的学习,以解决数据稀缺或训练时间长的问题。
- 终身学习是一种机器学习范式,旨在模拟人类不断学习的能力,持续积累新知识并适应新环境。终身学习系统可以不断接收新数据、学习新任务,并保持对先前学到知识的更新和利用,以实现持续学习和适应性。
评估
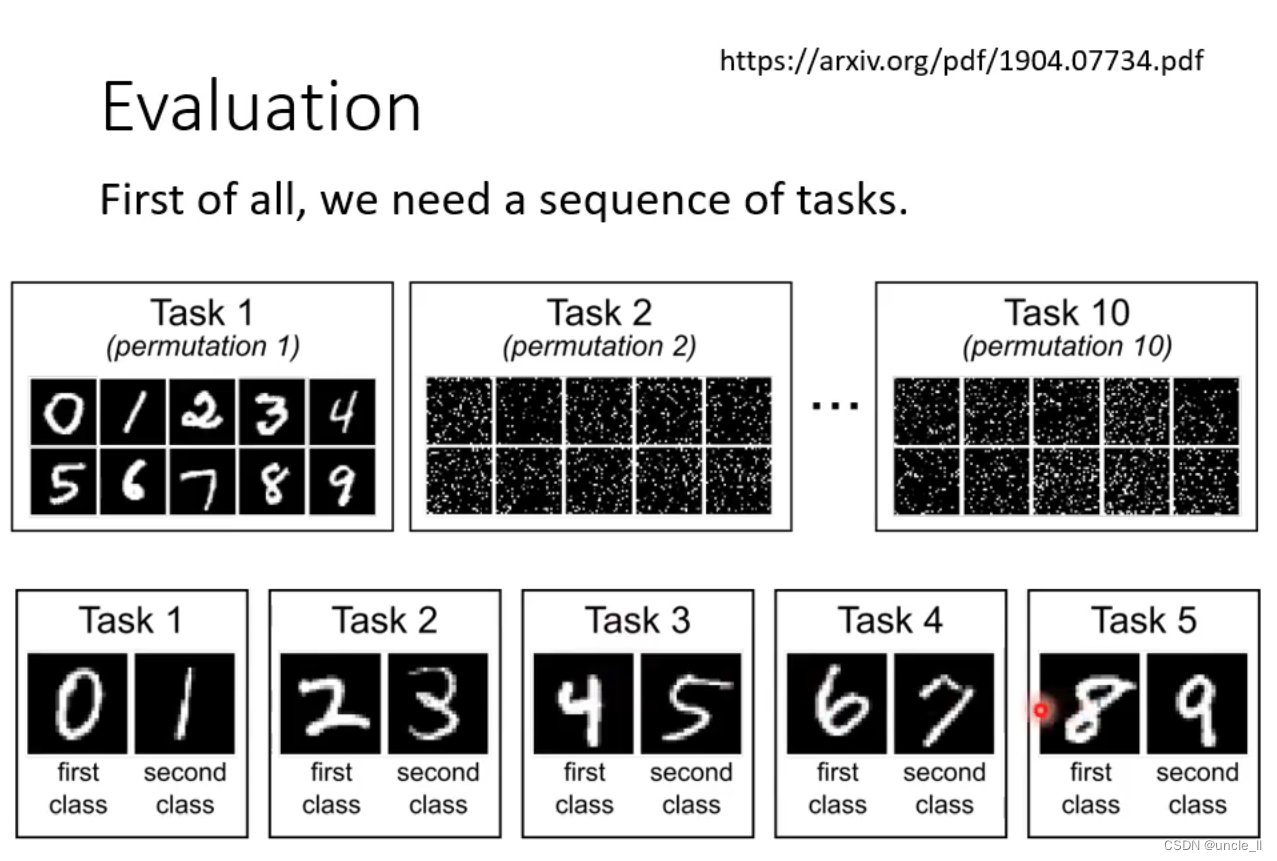
- 一些任务序列和相关内容,包括任务1到任务10的排列、时间单位以及一些类别的描述。
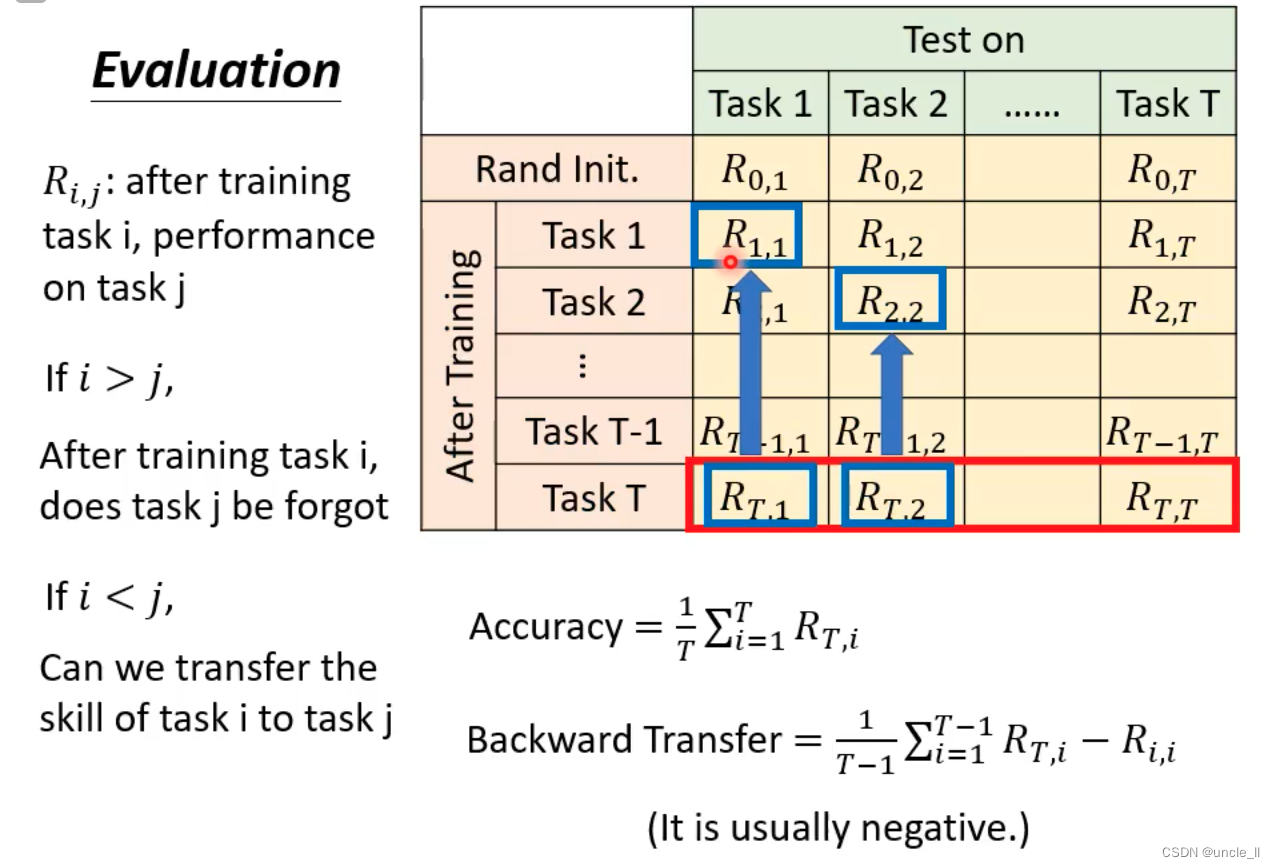
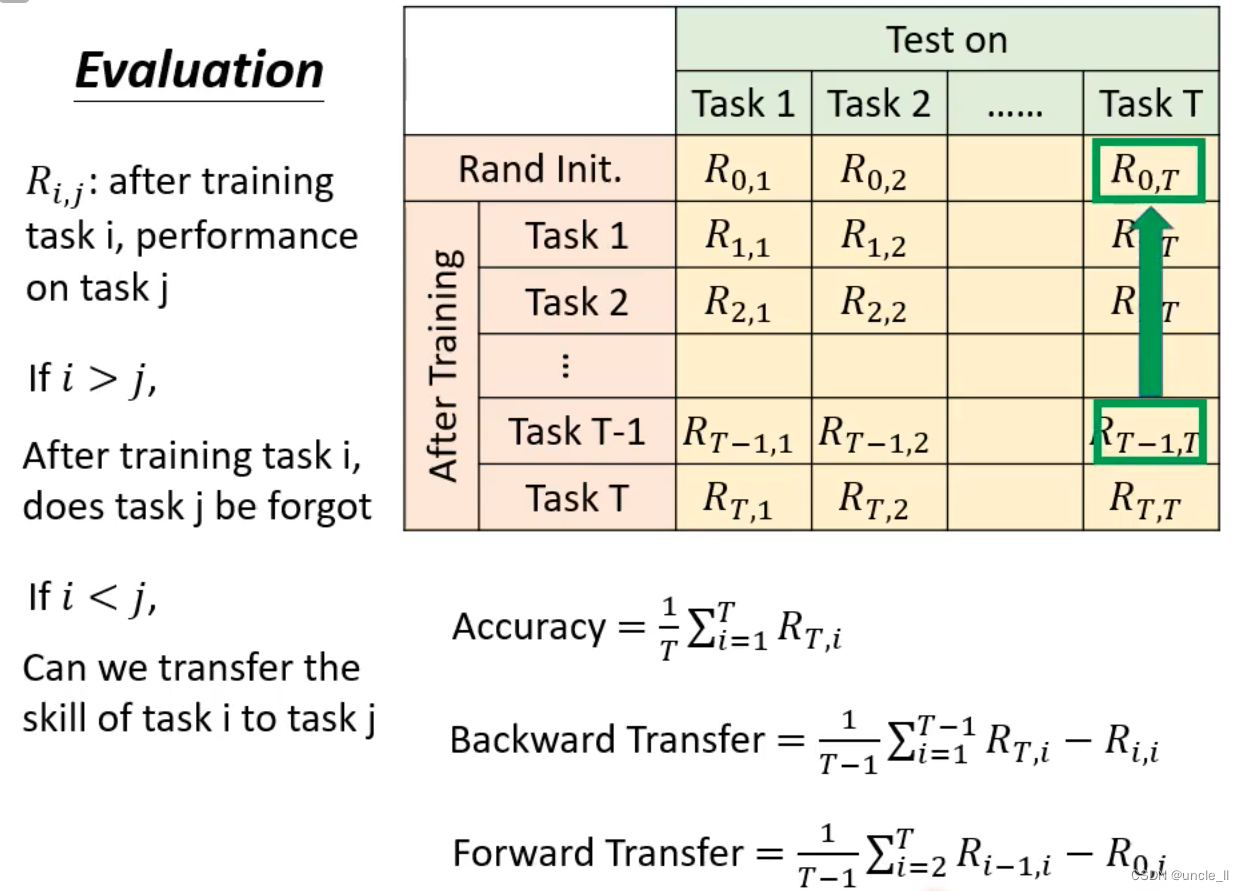
- 三种评估方式:
- 学完所有任务之后,再对每个任务计算指标并计算平均指标
- 每学完一个任务之后跟之前学完自己任务之后的指标进行求差的平均
- 在还没有看过其他任务的时候,使用此时的情况减去第一个
可能的解法
选择性的突触的可塑性
-
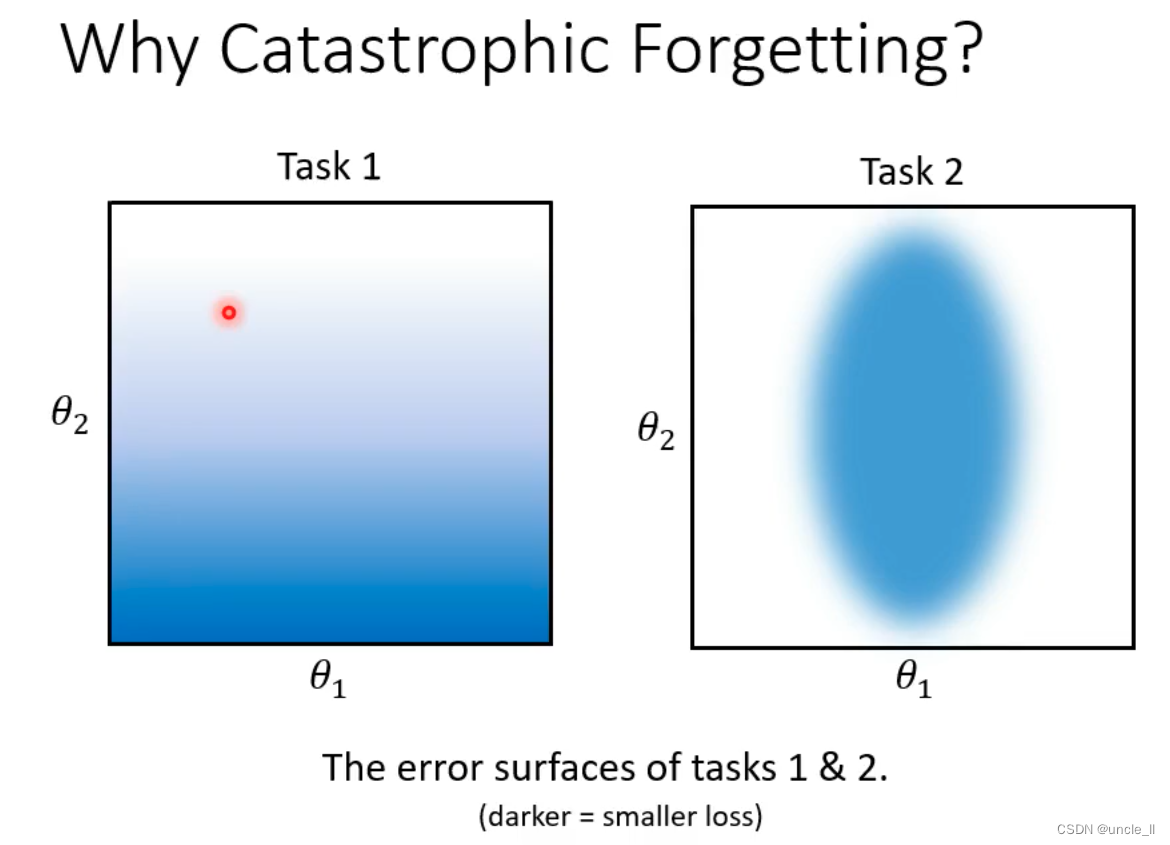
为什么会发生灾难性遗忘的内容,涉及到任务1和任务2的错误曲面,其中颜色较深的部分表示损失较小。
-
灾难性遗忘的原因在于神经网络在学习新任务时会忘记先前学习的任务,导致先前任务的信息丢失。在这种情况下,任务1和任务2的错误曲面显示了损失较小的部分,这可能表明神经网络在学习这两个任务时存在一定程度的重叠,导致出现灾难性遗忘。因为神经网络更倾向于记住新任务的信息,而忘记旧任务的信息,这可能会导致先前任务的损失加剧。

-
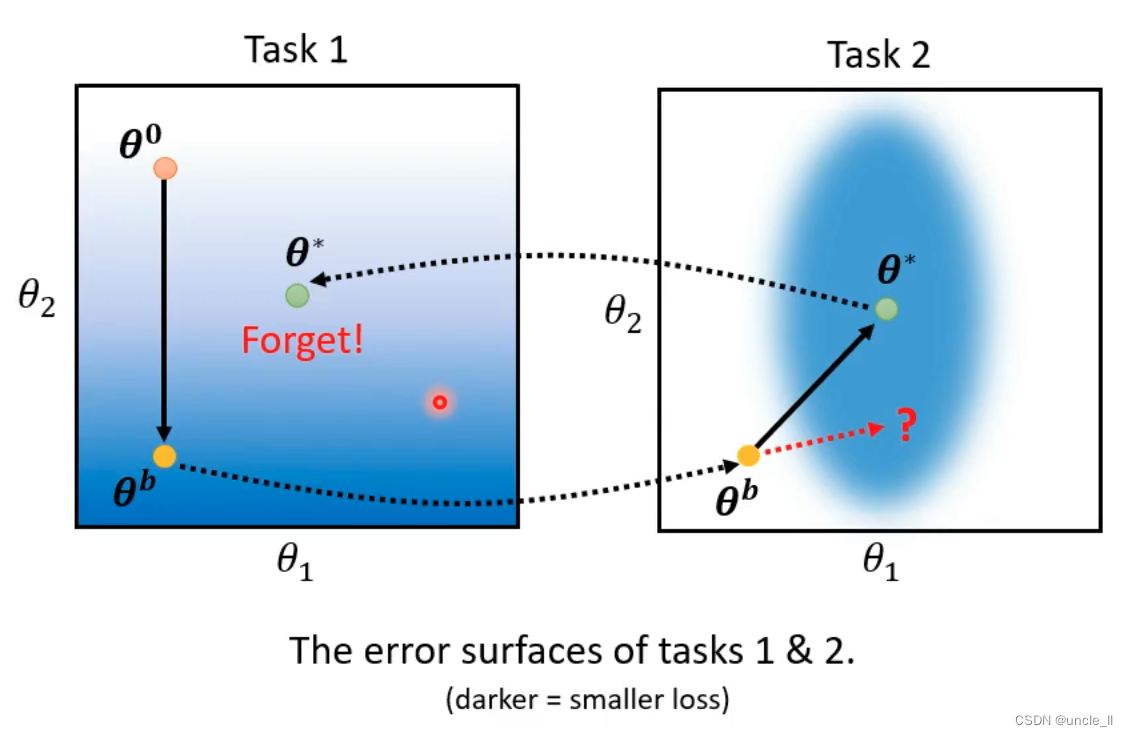
选择性突触可塑性:基本思想是模型中的一些参数对于先前的任务非常重要。只改变那些不重要的参数;每个参数 θ i θ_i θi都有一个“守卫” b i b_i bi。
-
如果bi为0,表示对应参数θi的“守卫”机制认为该参数对当前任务的重要性较低,可以被视为不重要的参数,会被重新学习。
-
如果bi为正无穷,表示对应参数θi的“守卫”机制认为该参数对当前任务的重要性非常高,是不可或缺的重要参数。在这种情况下,根据“选择性突触可塑性”的概念,这样的重要参数将被视为必须保留不变,不会被改变或调整,以确保先前任务学习到的重要知识得以保留并应用到新任务中。
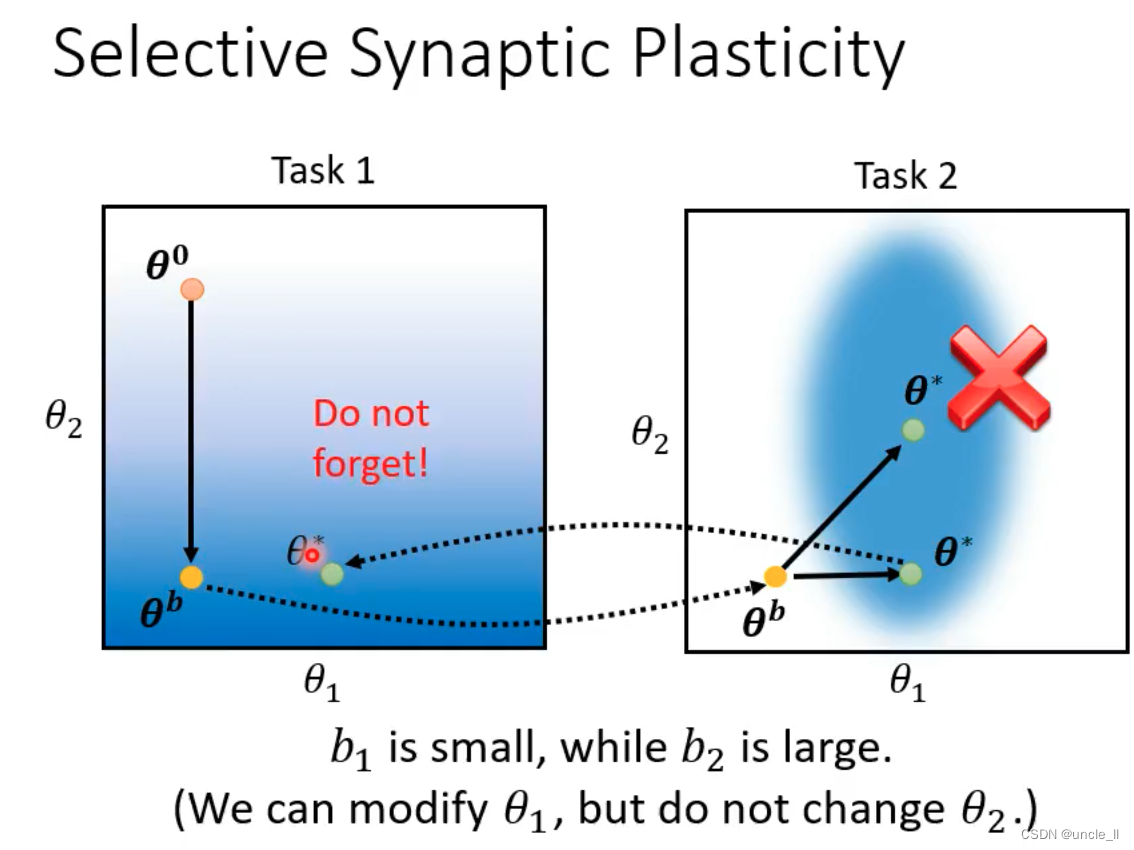
- 对于任务1和任务2,参数θ2和参数b1较小,而参数b2较大。这意味着可以修改参数θ1,但不改变参数θ2。
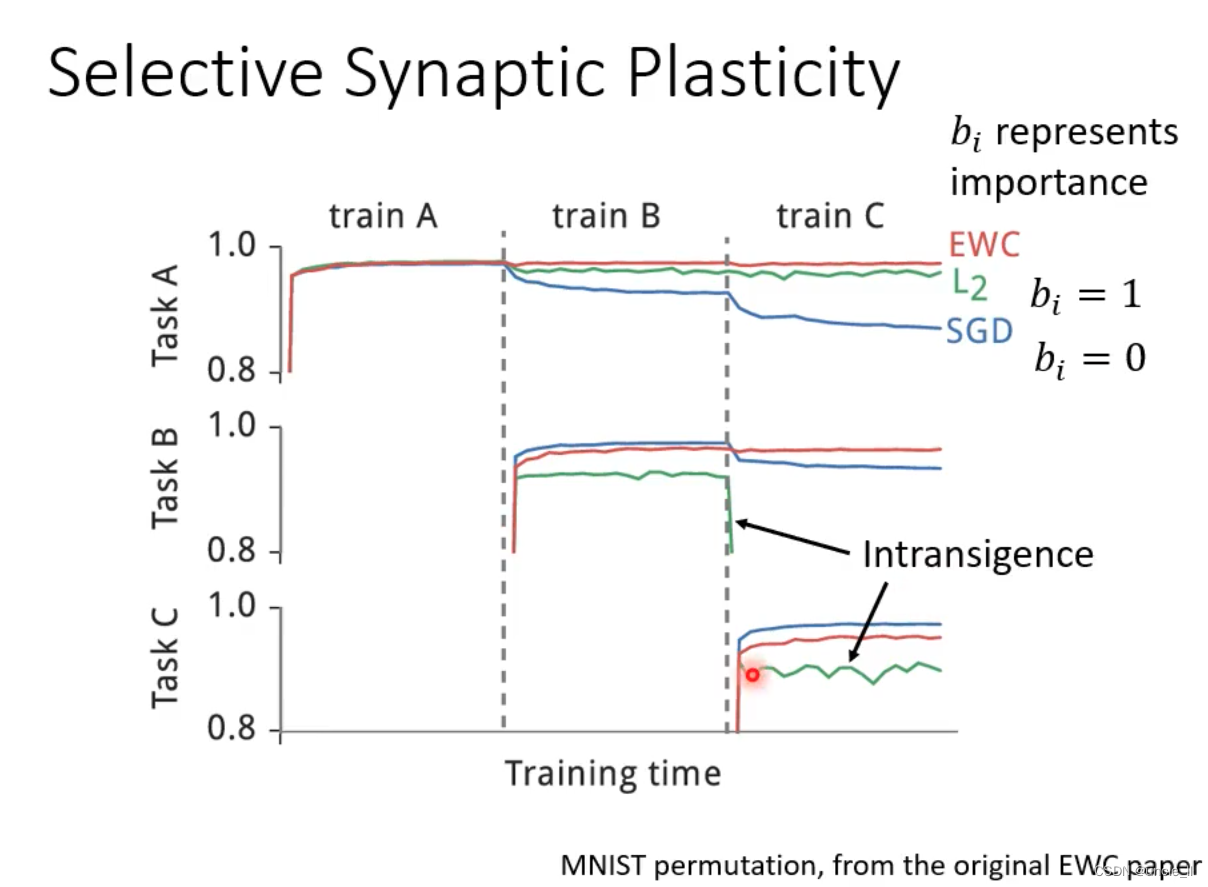
- 任务A、任务B和任务C的训练情况,以及使用的训练时间、EWC, L2、SGD等相关信息

- b i b_i bi的设置方式有多种,包括
- 弹性权重保持(Elastic Weight Consolidation,EWC)
- 突触智能(Synaptic Intelligence,SI)
- 记忆感知突触(Memory Aware Synapses,MAS)
- RWalk
- 切片Cramer保留(Sliced Cramer Preservation,SCP)
改变任务的顺序对结果会有较大的影响
GEM
对梯度方向上做选择去更新参数,需要把过去的资料存下来来修改g的方向,不需要大量的资料
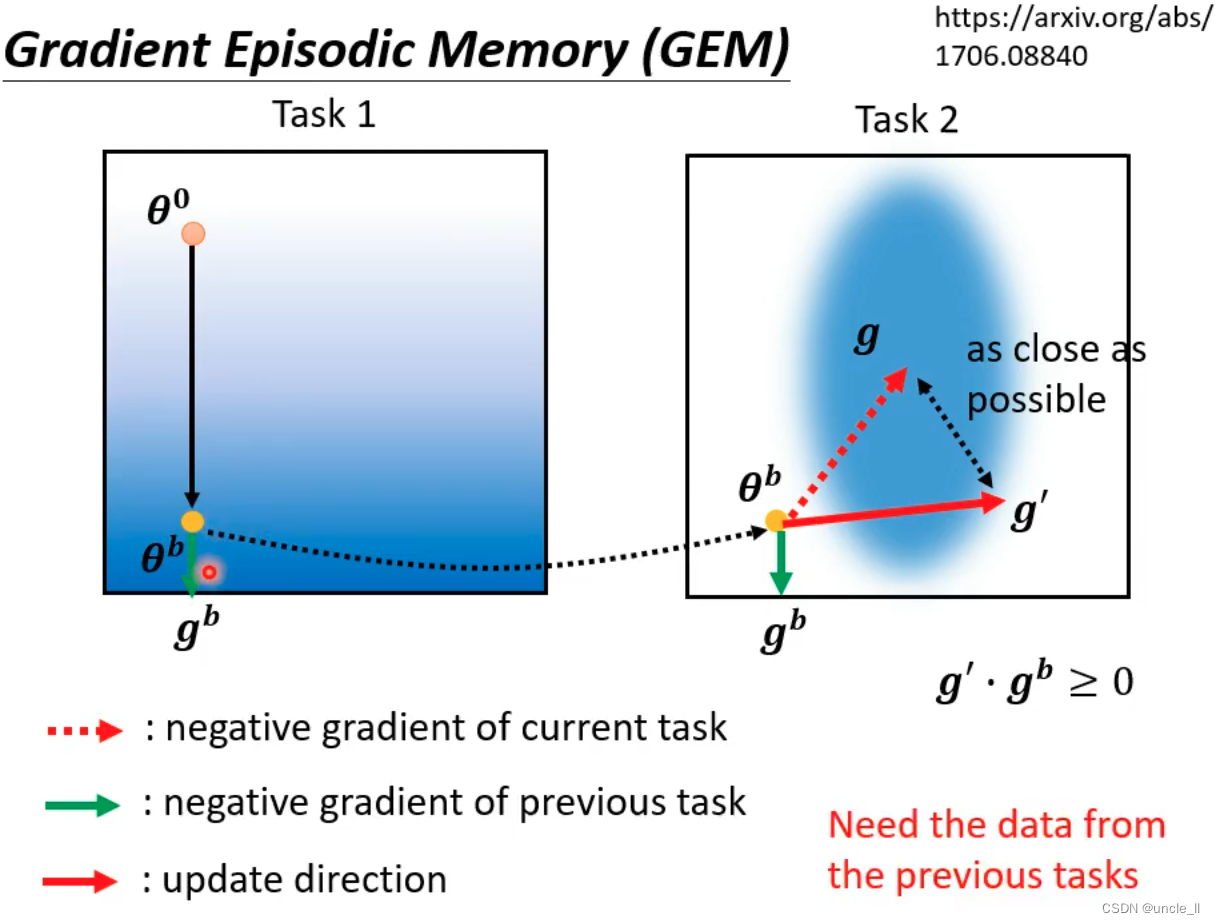
- 梯度情节记忆"(Gradient Episodic Memory,GEM)涉及到任务1和任务2,以及负责当前任务的梯度g和负责先前任务的梯度g’之间的关系。梯度g表示当前任务的负梯度,而梯度g’表示先前任务的负梯度,它们之间的乘积大于等于0。这种方法需要来自先前任务的数据以更新方向。
增加网络资源分配
渐进式神经网络
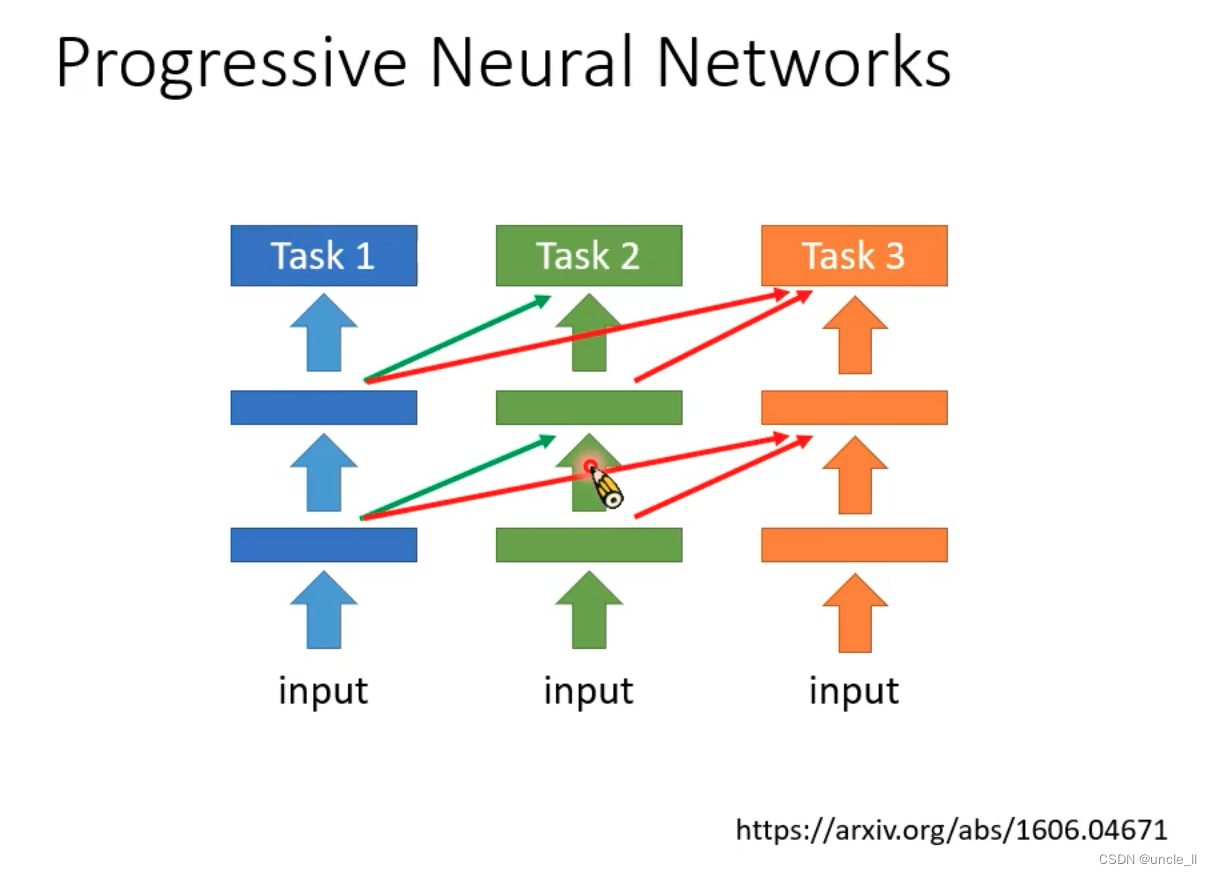
- 渐进式神经网络(Progressive Neural Networks)是一种用于处理逐步增加任务复杂性的神经网络结构。在渐进式神经网络中,每个新任务都会引入一个新的神经网络模块,而不会破坏先前任务的学习。这种方法允许神经网络在逐步学习新任务的同时保留先前任务的知识,从而实现对多任务学习的有效管理和应用。通过逐步增加模块来处理新任务,渐进式神经网络能够在不同任务之间实现知识共享和迁移,提高整体学习效率和性能。
- 渐进式神经网络的一些缺点包括:
- 网络结构复杂性增加: 随着每个新任务引入一个新的神经网络模块,网络结构会变得越来越复杂,可能导致计算资源需求增加和训练时间延长。
- 参数冗余: 每个任务都会引入新的神经网络模块,这可能导致参数冗余,使得模型变得庞大且难以管理。
- 遗忘问题: 在处理多任务学习时,可能会出现遗忘问题,即学习新任务时会影响先前任务的表现,导致灾难性遗忘。
- 知识共享限制: 每个任务有自己独立的神经网络模块,可能限制了不同任务之间的有效知识共享和迁移。
- 训练稳定性: 随着模型复杂性的增加,可能会影响训练的稳定性和收敛速度,增加了调参的难度。
在小数据集上表现还是可以的
PackNet
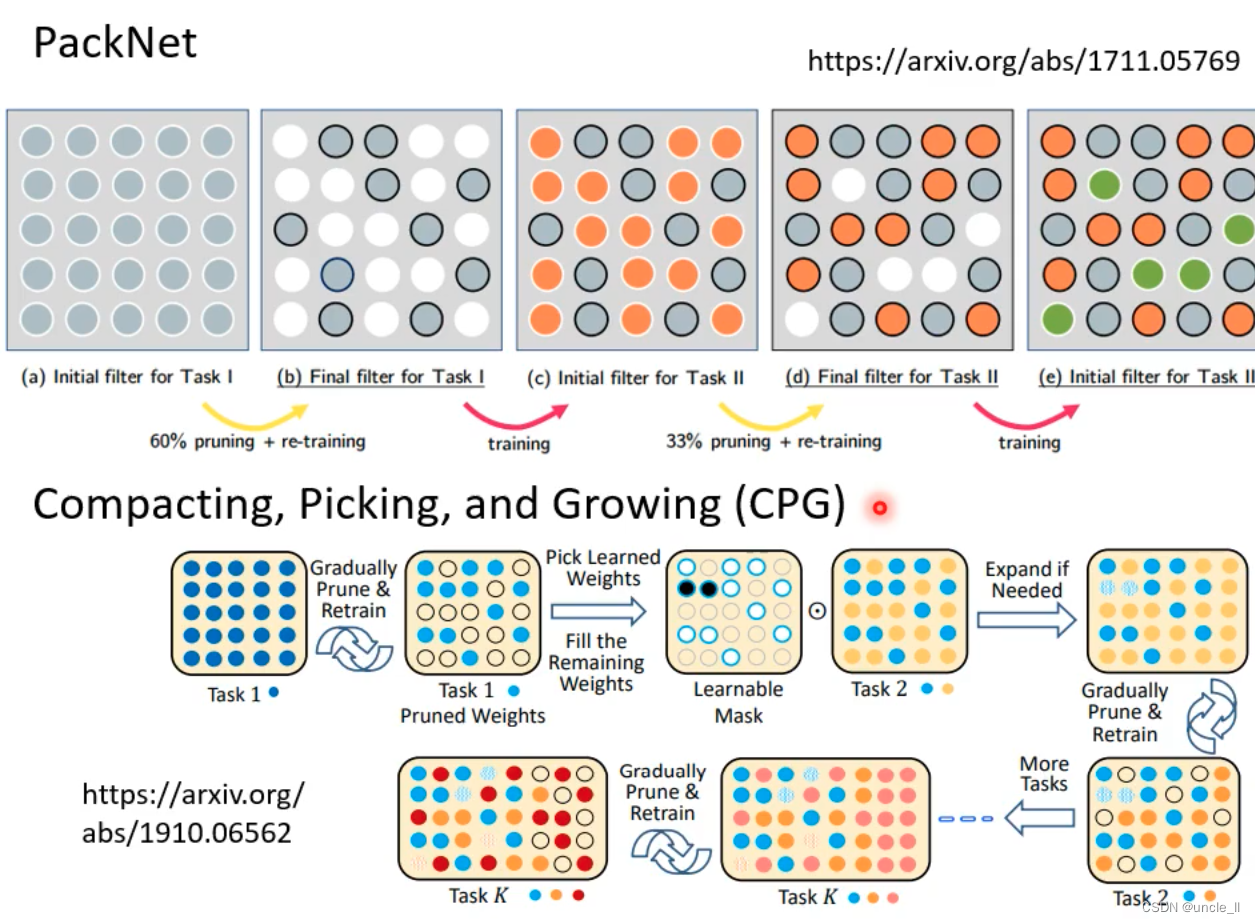
- 先训练一个大的模型,在不同的任务时只用其中的一部分
- PackNet是一种用于神经网络压缩和加速的方法。它采用了一种称为“PackNet”的结构,通过将神经网络的参数分组打包,以实现更高效的计算和存储。PackNet的主要思想是将网络参数分成多个组,每个组称为一个“包”(pack),然后对每个包应用特定的压缩技术,例如低秩近似、量化或剪枝等,以减少参数量并提高计算效率。
- 通过使用PackNet,可以在不损失太多性能的情况下大幅减少神经网络的参数量和计算复杂度,从而实现模型的轻量化和加速。这种方法在资源受限或对速度要求较高的场景下特别有用,可以帮助提高模型的推理速度和在嵌入式设备上的部署效率。
内存回复
内存回复(Memory Replay)是一种机器学习中的技术,用于增强模型的学习和泛化能力。在传统的机器学习训练中,通常使用静态的训练数据进行模型的训练和更新。然而,内存回复引入了一种记忆机制,允许模型在训练过程中保存和重播先前的经验。
内存回复的基本思想是将具有代表性的训练样本存储在一个内存缓冲区中,然后在后续的训练中周期性地从内存中提取样本,并将其与当前的训练数据一起使用。这样做的好处是可以增加训练样本的多样性和数量,从而提供更全面和丰富的训练信号,有助于模型更好地捕捉数据中的模式和结构。
生成数据
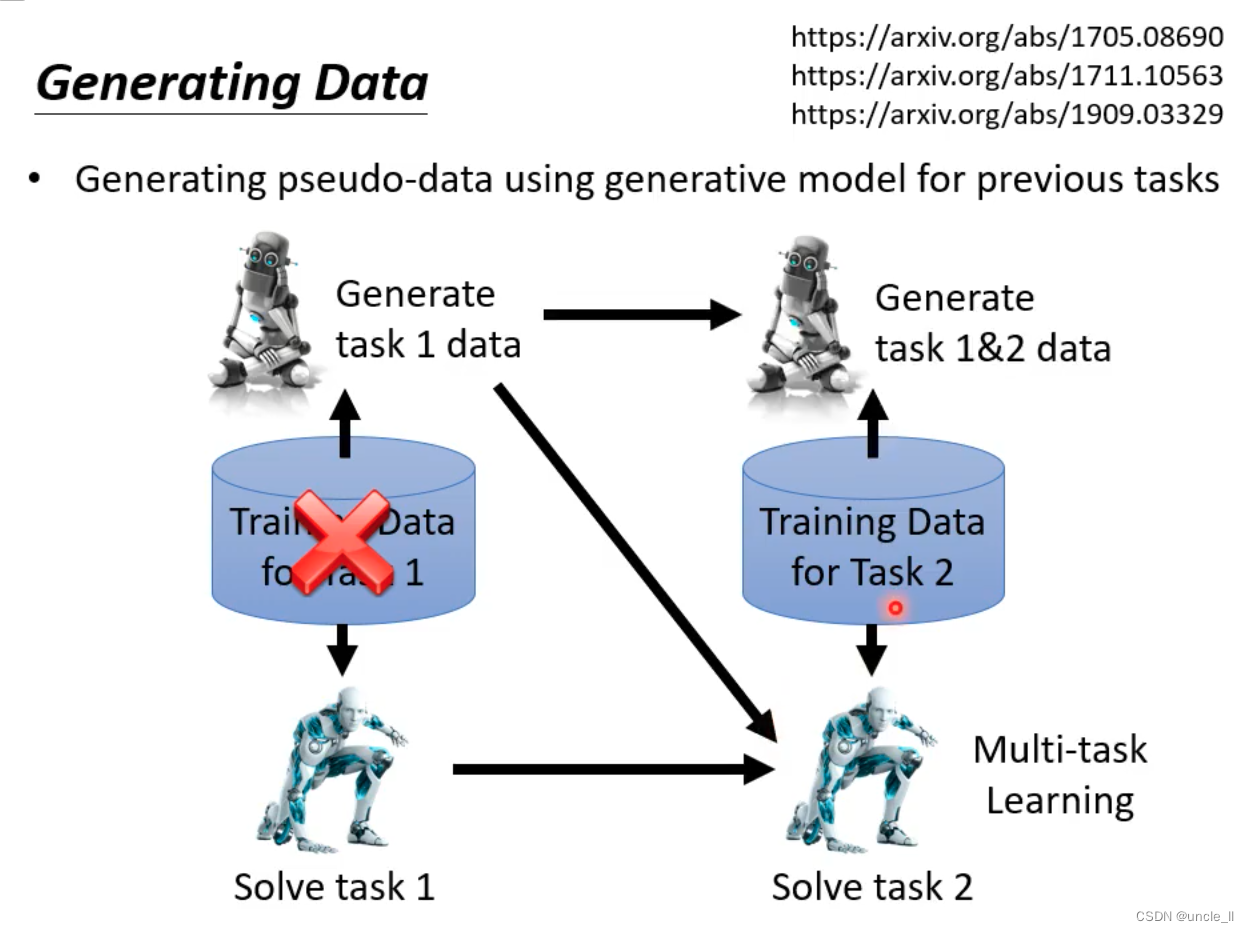
- 使用生成模型生成伪数据来处理先前任务,以及生成任务1数据、解决任务1、任务2的训练数据和解决任务2等步骤
- 旨在利用生成模型为先前任务生成数据,以帮助解决新任务
增加新类别
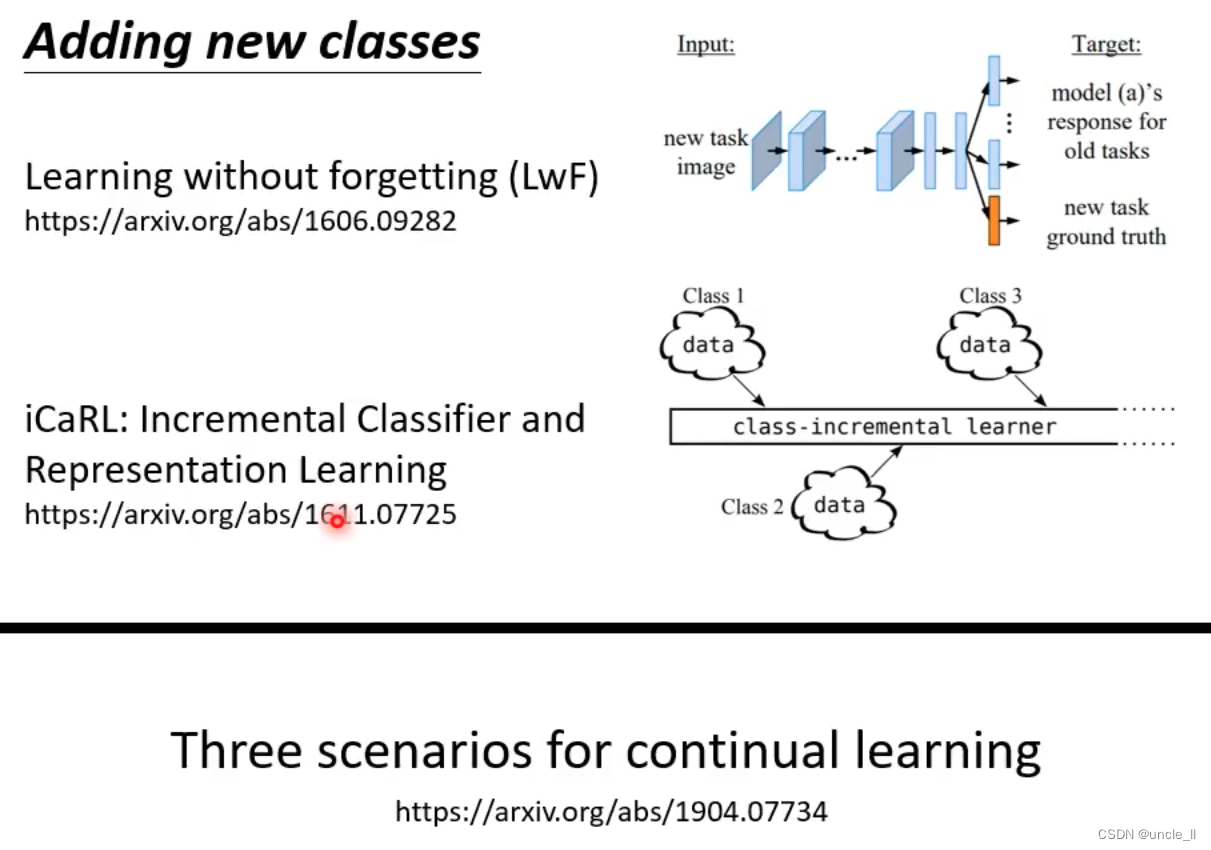
- 学习无遗忘(Learning without forgetting,LwF):旨在解决在学习新任务时导致先前任务遗忘的问题。LwF方法通过在训练过程中结合新任务数据和先前任务的知识,以确保在学习新任务时不会忘记先前任务的信息。
- iCaRL: 增量分类器和表示学习(Incremental Classifier and Representation Learning
- 连续学习的三种场景等内容
课程学习
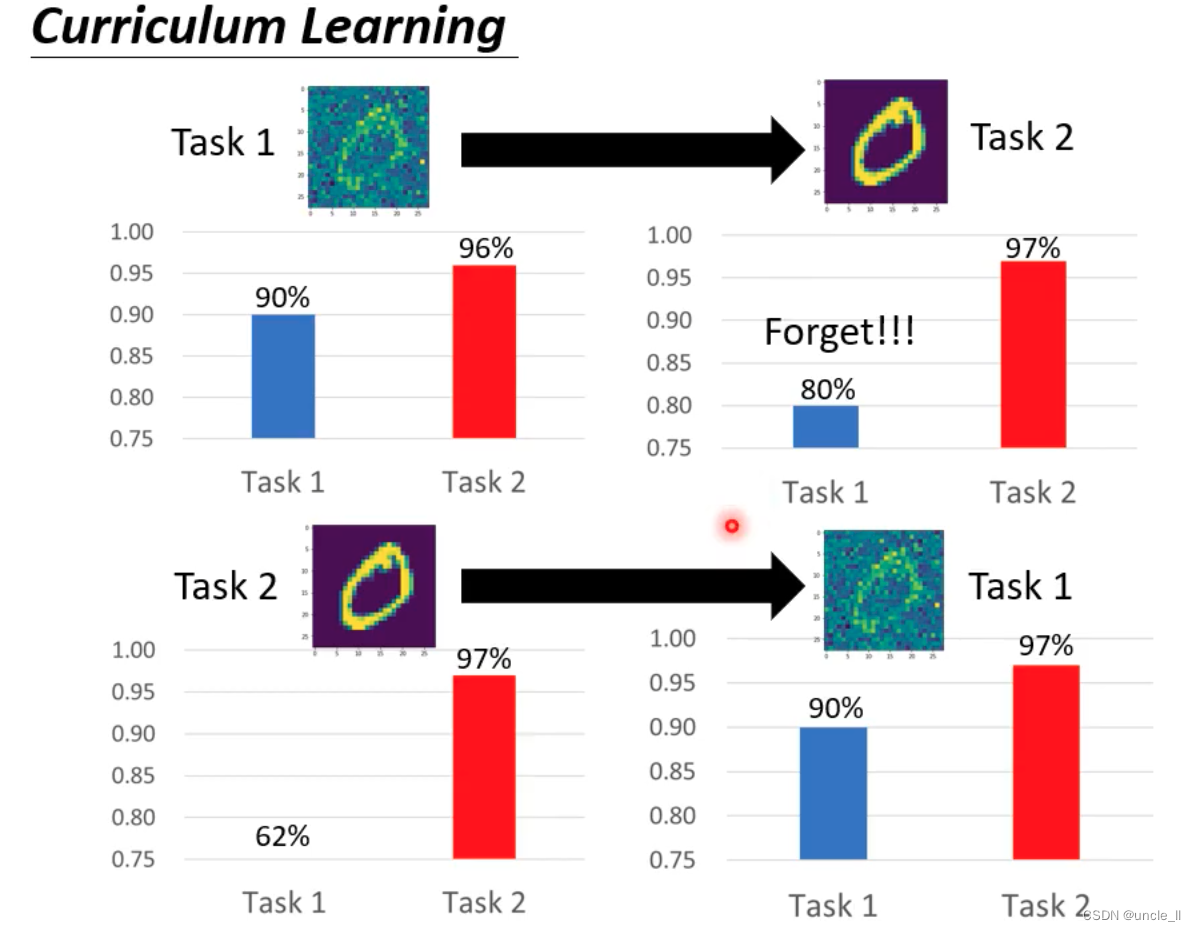
- 不同任务的顺序对最终的结果也是有影响的
- 课程学习(Curriculum Learning)是一种机器学习技术,通过按照难度或复杂性的顺序对模型进行一系列任务的训练。课程学习的思想是通过逐渐呈现越来越具有挑战性的训练样本,促进学习过程。
- 在传统的机器学习方法中,训练数据通常是随机或按照固定顺序呈现的。然而,课程学习承认在模型学习更复杂的概念之前,某些模式或概念可能更容易或更直观地学习。通过以有意义的顺序组织训练数据,课程学习旨在引导模型按照一种课程或教学大纲学习,模仿人类学习的方式。
- 课程可以根据特定问题领域和任务的要求以各种方式设计。例如,在计算机视觉任务中,课程可以从包含清晰模式的简单图像开始,逐渐引入具有遮挡或变化的更复杂图像。类似地,在自然语言处理中,课程可能涉及从简单的句子结构开始,逐渐引入更复杂的语法构造。
- 课程学习的主要动机是提高模型的学习效率和泛化性能。通过逐渐向模型展示越来越困难的示例,它可以在现有知识的基础上构建,并学习更强大的表示。课程学习已在计算机视觉、自然语言处理和强化学习等各个领域证明有效。