十二、通过指标和增强改进训练
本章涵盖
-
定义和计算精确率、召回率以及真/假阳性/阴性
-
使用 F1 分数与其他质量指标
-
平衡和增强数据以减少过拟合
-
使用 TensorBoard 绘制质量指标图
上一章的结束让我们陷入了困境。虽然我们能够将深度学习项目的机制放置好,但实际上没有任何结果是有用的;网络只是将一切都分类为非结节!更糟糕的是,结果表面看起来很好,因为我们正在查看训练和验证集中被正确分类的整体百分比。由于我们的数据严重倾向于负样本,盲目地将一切都视为负面是我们的模型快速得分的一种简单而快速的方法。太糟糕了,这样做基本上使模型无用!
这意味着我们仍然专注于与第十一章相同的图 12.1 的同一部分。但现在我们正在努力使我们的分类模型工作良好而不是只是工作。本章重点讨论如何衡量、量化、表达,然后改进我们的模型执行工作的能力。
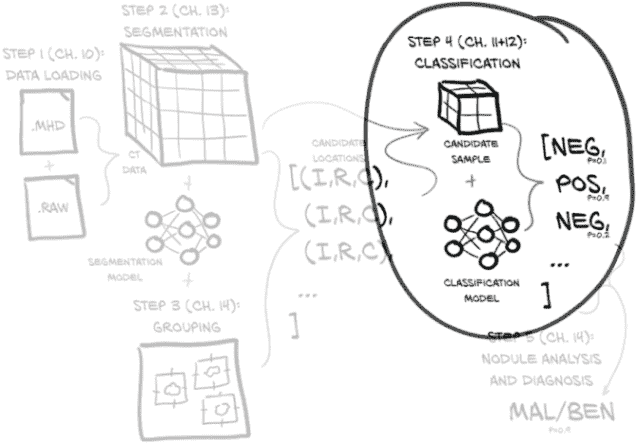
图 12.1 我们的端到端肺癌检测项目,重点放在本章的主题上:第 4 步,分类
12.1 改进的高层计划
虽然有点抽象,图 12.2 向我们展示了我们将如何处理那些广泛的主题。
让我们详细地走过本章的这张有些抽象的地图。我们将处理我们面临的问题,比如过度关注单一、狭窄的指标以及由此产生的行为在一般意义上是无用的。为了使本章的一些概念更具体化,我们将首先使用一个比喻来将我们的困境更具体化:在图 12.2 中,(1)看门狗和(2)鸟和窃贼。

图 12.2 我们将使用的比喻来修改衡量我们模型的指标,使其变得出色
之后,我们将开发一个图形语言来代表上一章实施中所需的核心概念:(3)比率:召回率和精确率。一旦我们将这些概念巩固下来,我们将涉及一些使用这些概念的数学,这将包括一种更健壮的评估我们模型性能的方式,并将其压缩为一个数字:(4)新指标:F1 分数。我们将实施这些新指标的公式,并查看在训练过程中每个时期这些结果值如何变化。最后,我们将对我们的LunaDataset实现进行一些急需的更改,以改善我们的训练结果:(5)平衡和(6)增强。然后我们将看看这些实验性的更改是否对我们的性能指标产生了预期的影响。
到本章结束时,我们训练的模型将表现得更好:(7)工作得很棒!虽然它还没有准备好立即投入临床使用,但它将能够产生明显优于随机的结果。这意味着我们已经有了可行的第 4 步实现,结节候选分类;一旦完成,我们可以开始考虑如何将第 2 步(分割)和第 3 步(分组)纳入项目中。
12.2 好狗与坏家伙:假阳性和假阴性
我们不再考虑模型和肿瘤,而是考虑图 12.3 中的两只看门狗,它们刚从服从学校毕业。它们都想警告我们有窃贼——这是一种罕见但严重的情况,需要及时处理。
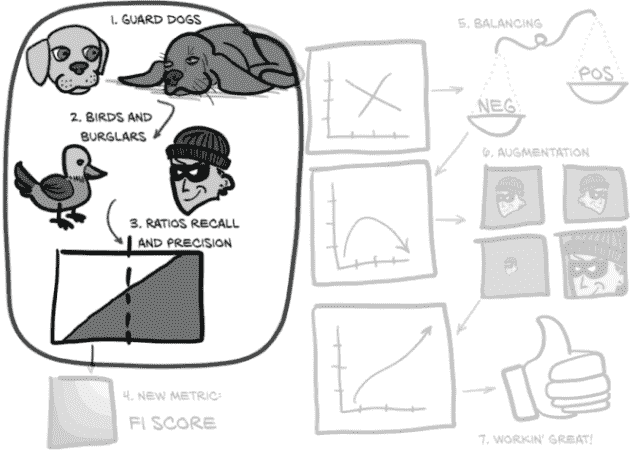
图 12.3 本章的主题集,重点放在框架比喻上
不幸的是,虽然两只狗都是好狗,但都不是好的警卫狗。我们的梗犬(Roxie)对几乎所有事情都会吠,而我们的老猎犬(Preston)几乎只会对入室者吠叫——但前提是他在他们到达时恰好醒着。
Roxie 几乎每次都会警告我们有入室者。她还会警告我们有消防车、雷暴、直升机、鸟、邮递员、松鼠、路人等。如果我们对每次吠叫进行跟进,我们几乎永远不会被抢劫(只有最狡猾的偷窃者才能溜过)。完美!… 除了那么勤奋意味着我们实际上并没有通过养警卫狗节省任何工作。相反,我们每隔几个小时就会起床,手持手电筒,因为 Roxie 闻到了猫的气味,或者听到了猫头鹰的叫声,或者看到了一辆晚点的公共汽车经过。Roxie 有一个问题性的假阳性数量。
假阳性是被分类为感兴趣或所需类别的成员(阳性表示“是的,这是我感兴趣了解的类型”)的事件,但实际上并不是真正感兴趣的。对于结节检测问题,当一个实际上无趣的候选者被标记为结节,因此需要放射科医生的关注时,就会发生假阳性。对于 Roxie 来说,这些可能是消防车、雷暴等。在接下来的章节和随后的图中,我们将使用一张猫的图片作为典型的假阳性。
将假阳性与真阳性进行对比:被正确分类的感兴趣项目。这些将在图中由一个人类强盗表示。
与此同时,如果 Preston 吠叫,请立即报警,因为这意味着几乎肯定有人闯入,房子着火了,或者哥斯拉在袭击。然而,Preston 睡得很沉,正在进行家庭入侵的声音不太可能唤醒他,所以每当有人尝试时,我们几乎总是会被抢劫。虽然比没有好,但我们并没有真正获得最初让我们养狗的平静心态。Preston 有一个问题性的假阴性数量。
假阴性是被分类为不感兴趣或不是所需类别的成员(阴性表示“不,这不是我感兴趣了解的类型”)的事件,但实际上确实是感兴趣的。对于结节检测问题,当一个结节(即潜在的癌症)未被检测到时,就会发生假阴性。对于 Preston 来说,这些将是他睡过的抢劫案。在这里我们将有点创意,使用一张啮齿强盗的图片来代表假阴性。它们很狡猾!
将假阴性与真阴性进行对比:正确识别为无趣项目的项目。我们将用一只鸟的图片来代表这些。
为了完成这个比喻,第十一章的模型基本上是一只拒绝对不是金鱼罐的任何东西发出喵声的猫(同时坚定地忽视 Roxie)。我们在上一章末尾的重点是整体训练和验证集的正确百分比。显然,这不是一个很好的评分方式,正如我们从我们每只狗对单一指标的近视关注——比如真阳性或真阴性的数量——可以看出的那样,我们需要一个更广泛关注的指标来捕捉我们的整体表现。
12.3 绘制阳性和阴性
让我们开始制定我们将用来描述真/假阳性/阴性的视觉语言。如果我们的解释变得重复,请耐心等待;我们希望确保您对我们将要讨论的比率形成坚实的心理模型。考虑图 12.4,显示了可能对我们其中一只警卫狗感兴趣的事件。

图 12.4 中的猫、鸟、啮齿动物和强盗构成了我们的四个分类象限。它们由人类标签和狗的分类阈值分隔。
在图 12.4 中,我们将使用两个阈值。第一个是人为决定的将入室盗窃犯与无害动物分开的分界线。具体来说,这是为每个训练或验证样本分配的标签。第二个是狗确定的分类阈值,它决定了狗是否会对某物吠叫。对于深度学习模型,这是在考虑样本时模型产生的预测值。
这两个阈值的组合将我们的事件分成四个象限:真/假阳性/阴性。我们将关注的事件用较深的背景色进行阴影处理(因为那些坏家伙总是在黑暗中潜行)。
当然,现实要复杂得多。并不存在一个关于入室盗窃犯的柏拉图理想,也没有一个相对于分类阈值的单一点,所有入室盗窃犯都会在那里。相反,图 12.5 向我们展示了一些入室盗窃犯会特别狡猾,一些鸟类会特别烦人。我们还将把我们的实例放在一个图中。我们的 X 轴将保持每个事件的吠声价值,由我们的一只看门狗确定。我们将让 Y 轴代表我们作为人类能够感知的一些模糊特质,但我们的狗却无法感知。
由于我们的模型产生二元分类,我们可以将预测阈值视为将单一数值输出与我们的分类阈值值进行比较。这就是为什么我们要求图 12.5 中的分类阈值线是完全垂直的。

图 12.5 每种事件都会有许多可能的实例,我们的看门狗需要评估。
每个可能的入室盗窃犯都是不同的,因此我们的看门狗将需要评估许多不同的情况,这意味着更多犯错的机会。我们可以看到明显的对角线将鸟类与入室盗窃犯分开,但普雷斯顿和洛克西只能在这里感知 X 轴:他们在我们的图中间有一组混乱、重叠的事件。他们必须选择一个垂直的吠声价值阈值,这意味着他们中的任何一个都不可能完美地做到。有时候把你的家电搬到他们的货车上的人是你雇来修理洗衣机的维修人员,有时候入室盗窃犯会开着一辆侧面写着“洗衣机维修”的货车出现。期望狗能够察觉到这些微妙之处注定会失败。
我们要使用的实际输入数据具有高维度–我们需要考虑大量 CT 体素值,以及更抽象的事物,如候选大小、在肺部的整体位置等等。我们模型的工作是将每个事件及其属性映射到这个矩形中,以便我们可以使用单一垂直线(我们的分类阈值)清晰地分离这些正面和负面事件。这是通过我们模型末端的nn.Linear层完成的。垂直线的位置与我们在第 11.6.1 节中看到的classificationThreshold_float完全对应。在那里,我们选择了硬编码值 0.5 作为我们的阈值。
请注意,实际上,所呈现的数据不是二维的;在倒数第二层之后,它变成了非常高维度,到输出时变成了一维(这里是我们的 X 轴)–每个样本只有一个标量(然后被分类阈值二分)。在这里,我们使用第二维(Y 轴)来表示我们的模型无法看到或使用的每个样本特征:例如患者的年龄或性别,结节候选在肺部的位置,甚至模型尚未利用的候选局部特征。它还为我们提供了一种方便的方式来表示非结节和结节样本之间的混淆。
图 12.5 中的象限区域和每个区域中包含的样本数将是我们用来讨论模型性能的值,因为我们可以使用这些值之间的比率来构建越来越复杂的指标,以客观地衡量我们的表现。正如他们所说,“证据在于比例。”¹ 接下来,我们将使用这些事件子集之间的比率来开始定义更好的指标。
12.3.1 召回率是罗克西的优势
召回率基本上是“确保你永远不会错过任何有趣的事件!”正式地说,召回率是真阳性与真阳性和假阴性的并集的比率。我们可以在图 12.6 中看到这一点。
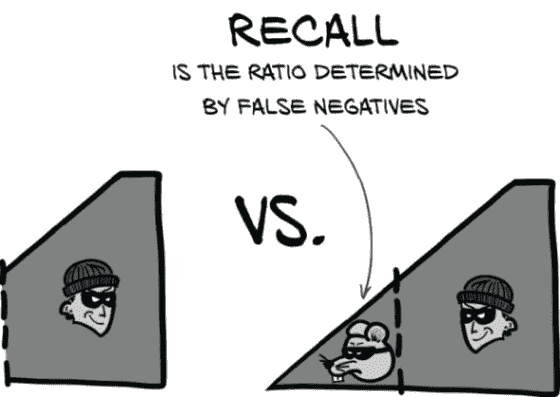
图 12.6 召回率是真阳性与真阳性和假阴性的并集的比率。高召回率可以最小化假阴性。
注 在某些情境中,召回率被称为敏感性。
为了提高召回率,要尽量减少假阴性。在看门狗的术语中,这意味着如果你不确定,就叫一声,以防万一。不要让任何啮齿动物小偷在你的监视下溜走!
罗克西通过将分类阈值推到最左边,使其包含图 12.7 中几乎所有的正面事件,从而实现了极高的召回率。请注意,这样做意味着她的召回值接近 1.0,即 99%的盗贼都会被叫唤。由于这是罗克西定义成功的方式,在她看来,她做得很好。不要在意大量的假阳性!
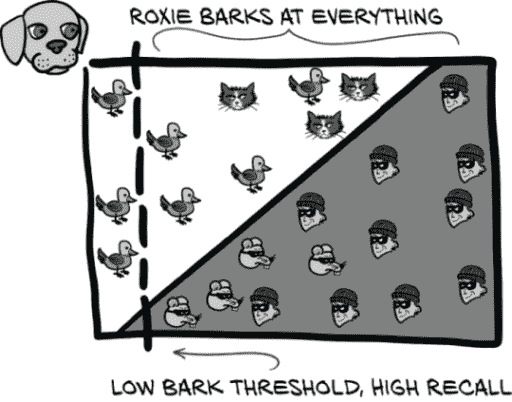
图 12.7 罗克西选择的阈值优先考虑减少假阴性。每只老鼠都会被叫唤……还有猫,大多数鸟。
12.3.2 精确性是普雷斯顿的长处
精确性基本上是“除非你确定,否则不要叫。”为了提高精确性,要尽量减少假阳性。普雷斯顿不会对某事物叫唤,除非他确定那是一个盗贼。更正式地说,精确性是真阳性与真阳性和假阳性的并集的比率,如图 12.8 所示。

图 12.8 精确性是真阳性与真阳性和假阳性的并集的比率。高精确性可以最小化假阳性。
普雷斯顿通过将分类阈值推到最右边,排除尽可能多的无趣、负面事件,从而实现了极高的精确性(见图 12.9)。这与罗克西的方法相反,意味着普雷斯顿的精确性接近 1.0:他叫的 99%的事物都是盗贼。尽管有大量事件未被检测到,但这也符合他作为一只好看门狗的定义。
虽然精确性和召回率都不能作为评估我们模型的单一指标,但它们在训练过程中是有用的数字。让我们计算并显示这些作为我们训练程序的一部分,然后我们将讨论其他可以使用的指标。
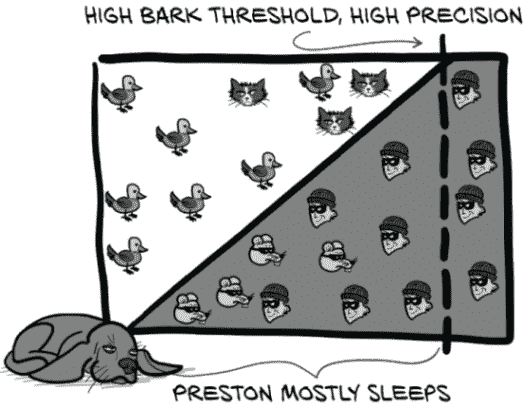
图 12.9 普雷斯顿选择的阈值优先考虑减少假阳性。猫被放过,只有盗贼会被叫唤!
12.3.3 在 logMetrics 中实现精确性和召回率
在训练过程中,精确性和召回率都是有价值的指标,因为它们提供了关于模型行为的重要见解。如果它们中的任何一个降至零(正如我们在第十一章中看到的!),那么我们的模型可能已经开始表现出退化的方式。我们可以使用行为的确切细节来指导我们在哪里进行调查和实验,以使训练重新回到正轨。我们希望更新logMetrics函数,以在每个时期的输出中添加精确性和召回率,以补充我们已经拥有的损失和正确性指标。
到目前为止,我们一直在以“真阳性”等术语定义精确度和召回率,因此我们将在代码中继续这样做。事实证明,我们已经计算了一些我们需要的值,尽管我们给它们起了不同的名称。
列表 12.1 training.py:315,LunaTrainingApp.logMetrics
neg_count = int(negLabel_mask.sum())
pos_count = int(posLabel_mask.sum())trueNeg_count = neg_correct = int((negLabel_mask & negPred_mask).sum())
truePos_count = pos_correct = int((posLabel_mask & posPred_mask).sum())falsePos_count = neg_count - neg_correct
falseNeg_count = pos_count - pos_correct
在这里,我们可以看到neg_correct与trueNeg_count是相同的!这其实是有道理的,因为非结节是我们的“负面”值(如“负面诊断”),如果分类器预测正确,那么这就是真阴性。同样,正确标记的结节样本是真阳性。
我们确实需要添加我们的假阳性和假阴性值的变量。这很简单,因为我们可以取良性标签的总数并减去正确的计数。剩下的是被误分类为阳性的非结节样本的计数。因此,它们是假阳性。同样,假阴性计算形式相同,但使用结节计数。
有了这些数值,我们可以计算precision和recall,并将它们存储在metrics_dict中。
列表 12.2 training.py:333,LunaTrainingApp.logMetrics
precision = metrics_dict['pr/precision'] = \truePos_count / np.float32(truePos_count + falsePos_count)
recall = metrics_dict['pr/recall'] = \truePos_count / np.float32(truePos_count + falseNeg_count)
注意双重赋值:虽然有单独的precision和recall变量并不是绝对必要的,但它们提高了下一节的可读性。我们还扩展了logMetrics中的日志语句以包括新值,但我们暂时跳过实现(我们将在本章稍后重新讨论日志记录)。
12.3.4 我们的终极性能指标:F1 分数
尽管有用,但精确度和召回率都无法完全捕捉我们评估模型所需的内容。正如我们在 Roxie 和 Preston 中看到的,通过操纵我们的分类阈值,可能会单独操纵其中一个,导致模型在其中一个上得分良好,但以牺牲任何实际效用为代价。我们需要一种以防止这种操纵的方式结合这两个值的东西。正如我们在图 12.10 中看到的,现在是引入我们的终极指标的时候了。
通常接受的结合精确度和召回率的方法是使用 F1 分数(en.wikipedia.org/wiki/F1_score)。与其他指标一样,F1 分数的范围在 0(没有真实世界预测能力的分类器)和 1(具有完美预测的分类器)之间。我们将更新logMetrics以包括这一点。
列表 12.3 training.py:338,LunaTrainingApp.logMetrics
metrics_dict['pr/f1_score'] = \2 * (precision * recall) / (precision + recall)
乍一看,这可能比我们需要的更复杂,当在精确度和召回率之间进行权衡时,F1 分数的行为可能不会立即显而易见。然而,这个公式有很多好的性质,并且与我们可能考虑的几种其他更简单的替代方案相比较有利。
图 12.10 本章的主题集,重点是最终的 F1 分数指标
一个立即可能的评分函数是将精确度和召回率的值平均起来。不幸的是,这使得avg(p=1.0, r=0.0)和avg(p=0.5, r=0.5)都得到相同的 0.5 分数,正如我们之前讨论的,精确度或召回率为零的分类器通常是无用的。将无用的东西与有用的东西赋予相同的非零分数,立即使平均成为一个没有意义的指标。
然而,让我们在图 12.11 中直观比较平均和 F1。有几件事引人注目。首先,我们可以看到平均值的等高线中没有曲线或拐点。这就是让我们的精确度或召回率偏向一侧的原因!永远不会出现这样的情况,即通过使召回率达到 100%(Roxie 方法)然后消除任何容易消除的假阳性来最大化分数是没有意义的。这就为添加分数至少为 0.5 设置了一个底线!拥有一个质量指标,可以轻松获得至少 50% 的分数,感觉不对劲。
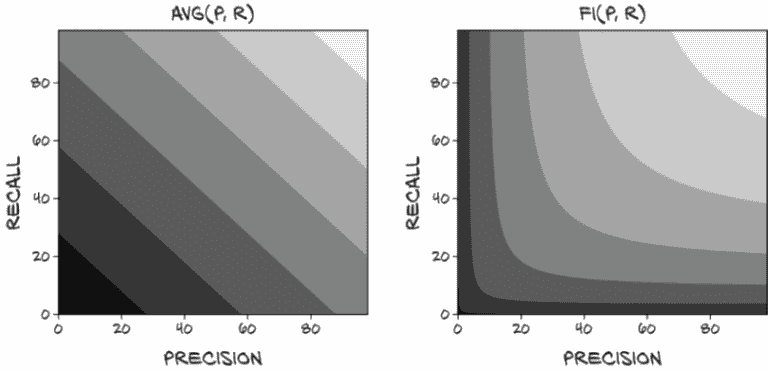
图 12.11 使用avg(p, r)计算最终分数。较浅的值接近 1.0。
注意 我们实际上在这里做的是取精确度和召回率的算术平均值(en.wikipedia.org/wiki/Arithmetic_mean),这两者都是比率而不是可计数的标量值。取比率的算术平均值通常不会给出有意义的结果。F1 分数是两个比率的调和平均值(en.wikipedia.org/wiki/Harmonic_mean)的另一个名称,这是结合这些值的更合适的方式。
与 F1 分数相比:当召回率高而精确度低时,为了将分数移动到平衡的甜蜜点,牺牲很多召回率以换取一点精确度将使分数更接近。有一个漂亮、深刻的拐点,很容易滑入其中。鼓励具有平衡精确度和召回率是我们希望从我们的评分指标中得到的。
假设我们仍然希望有一个更简单的指标,但不会奖励任何偏斜。为了纠正加法的弱点,我们可能会取精确度和召回率的最小值(图 12.12)。
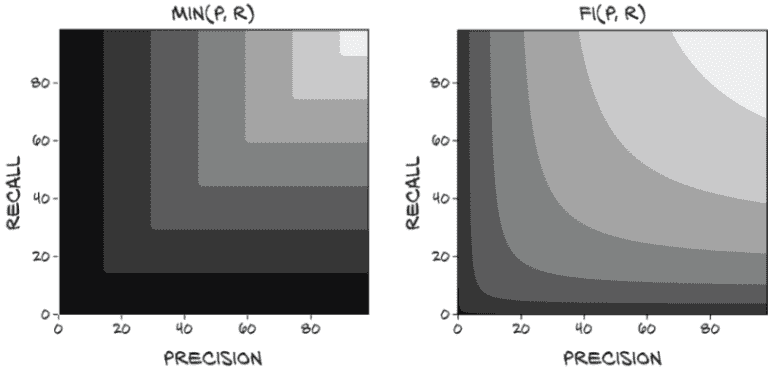
图 12.12 使用min(p, r)计算最终分数
这很好,因为如果任一值为 0,分数也为 0,而要获得 1.0 的分数的唯一方法是两个值都为 1.0。然而,它仍然有待改进,因为使召回率从 0.7 提高到 0.9 而将精确度保持在 0.5 不会改善分数,降低召回率到 0.6 也不会改善分数!尽管这个指标肯定惩罚了精确度和召回率之间的不平衡,但它并没有捕捉到关于这两个值的许多细微差别。正如我们所见,通过简单地移动分类阈值,很容易将一个值换成另一个值。我们希望我们的指标能反映这些交易。
为了更好地实现我们的目标,我们将不得不接受至少更复杂一点。我们可以将这两个值相乘,如图 12.13 所示。这种方法保持了一个很好的特性,即如果任一值为 0,分数也为 0,而分数为 1.0 意味着两个输入都完美。它还有利于在低值处精确度和召回率之间的平衡折衷,尽管当接近完美结果时,它变得更加线性。这并不好,因为我们真的需要将两者都提高才能在那一点上有意义的改进。

图 12.13 使用mult(p, r)计算最终分数
注意 在这里我们正在取两个比率的几何平均值(en.wikipedia.org/wiki/Geometric_mean),这也不会产生有意义的结果。
还有一个问题,几乎整个象限从(0, 0)到(0.5, 0.5)都非常接近于零。正如我们将看到的,拥有一个对该区域的变化敏感的指标是重要的,特别是在我们模型设计的早期阶段。
虽然将乘法作为我们的评分函数是可行的(它没有任何立即淘汰的资格,就像之前的评分函数一样),但我们将使用 F1 分数来评估我们的分类模型的性能。
更新日志输出以包括精确度、召回率和 F1 分数
现在我们有了新的指标,将它们添加到我们的日志输出中非常简单。我们将在我们的训练和验证集的主要日志声明中包括精确度、召回率和 F1。
列表 12.4 training.py:341, LunaTrainingApp.logMetrics
log.info(("E{} {:8} {loss/all:.4f} loss, "+ "{correct/all:-5.1f}% correct, "+ "{pr/precision:.4f} precision, " # ❶+ "{pr/recall:.4f} recall, " # ❶+ "{pr/f1_score:.4f} f1 score" # ❶).format(epoch_ndx,mode_str,**metrics_dict,)
)
❶ 格式字符串已更新
另外,我们将为每个负样本和正样本的正确识别计数和总样本数包括精确值。
列表 12.5 training.py:353, LunaTrainingApp.logMetrics
log.info(("E{} {:8} {loss/neg:.4f} loss, "+ "{correct/neg:-5.1f}% correct ({neg_correct:} of {neg_count:})").format(epoch_ndx,mode_str + '_neg',neg_correct=neg_correct,neg_count=neg_count,**metrics_dict,)
)
新版本的正日志声明看起来基本相同。
12.3.5 我们的模型如何使用我们的新指标?
现在我们已经实施了闪亮的新指标,让我们试试它们;我们将在展示 Bash shell 会话结果后讨论结果。在您的系统进行数字计算时,您可能想提前阅读;这可能需要大约半个小时,具体时间取决于您的系统。实际所需时间取决于您的系统的 CPU、GPU 和磁盘速度;我们的系统配备 SSD 和 GTX 1080 Ti,每个完整时期大约需要 20 分钟:
$ ../.venv/bin/python -m p2ch12.training
Starting LunaTrainingApp...
...
E1 LunaTrainingApp.../p2ch12/training.py:274: RuntimeWarning: invalid value encountered in double_scalarsmetrics_dict['pr/f1_score'] = 2 * (precision * recall) / (precision + recall) # ❶E1 trn 0.0025 loss, 99.8% correct, 0.0000 prc, 0.0000 rcl, nan f1
E1 trn_ben 0.0000 loss, 100.0% correct (494735 of 494743)
E1 trn_mal 1.0000 loss, 0.0% correct (0 of 1215).../p2ch12/training.py:269: RuntimeWarning: invalid value encountered in long_scalarsprecision = metrics_dict['pr/precision'] = truePos_count / (truePos_count + falsePos_count)E1 val 0.0025 loss, 99.8% correct, nan prc, 0.0000 rcl, nan f1
E1 val_ben 0.0000 loss, 100.0% correct (54971 of 54971)
E1 val_mal 1.0000 loss, 0.0% correct (0 of 136)
❶ 这些 RuntimeWarning 行的确切计数和行号可能会因运行而异。
糟糕。我们收到了一些警告,考虑到我们计算的一些值是nan,可能在某处发生了除零操作。让我们看看我们能找出什么。
首先,由于训练集中没有一个正样本被分类为正,这意味着精确度和召回率都为零,导致我们的 F1 分数计算除以零。其次,对于我们的验证集,由于没有任何东西被标记为正,truePos_count和falsePos_count都为零。这导致我们的precision计算的分母也为零;这是合理的,因为这就是我们看到另一个RuntimeWarning的地方。
少数负训练样本被分类为正(494743 个中有 494735 个被分类为负,因此有 8 个样本被错误分类)。虽然一开始可能看起来很奇怪,但请记住我们是在整个时期内收集我们的训练结果,而不是像我们对验证结果那样使用模型的时期末状态。这意味着第一批次实际上产生了随机结果。其中一些来自第一批次的样本被标记为正并不奇怪。
注意 由于网络权重的随机初始化和训练样本的随机排序,单独的运行可能会表现出略有不同的行为。确切可重现的行为可能是可取的,但超出了我们在本书第 2 部分中所尝试的范围。
嗯,那有点痛苦。切换到我们的新指标导致从 A+降至“零,如果你幸运的话”–如果我们不幸运,分数会很糟糕,甚至不是一个数字。哎呀。
话虽如此,在长期来看,这对我们是有利的。自第十一章以来,我们就知道我们的模型性能很差。如果我们的指标告诉我们除了那个,那将指向指标中的一个基本缺陷!
12.4 理想数据集是什么样的?
在我们为当前糟糕的情况哭泣之前,让我们想想我们实际上希望我们的模型做什么。图 12.14 说,首先我们需要平衡我们的数据,以便我们的模型能够正确训练。让我们建立起达到这个目标所需的逻辑步骤。
图 12.14 本章主题集,重点关注平衡我们的正负样本
回想一下之前的图 12.5,并讨论分类阈值。通过移动阈值来获得更好的结果具有有限的效果–正负类之间有太多重叠无法处理。
相反,我们想看到一个类似图 12.15 的图像。在这里,我们的标签阈值几乎是垂直的。这就是我们想要的,因为这意味着标签阈值和我们的分类阈值可以相当好地对齐。同样,大多数样本集中在图表的两端。这两件事都要求我们的数据易于分离,并且我们的模型具有执行该分离的能力。我们的模型目前具有足够的容量,所以问题不在于此。相反,让我们看看我们的数据。
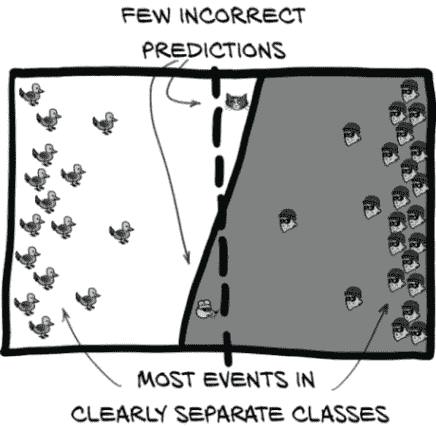
图 12.15 一个训练良好的模型可以清晰地分离数据,使得很容易选择一个具有少量折衷的分类阈值。

图 12.16 一个大致近似我们 LUNA 分类数据中不平衡的数据集
请记住,我们的数据极度不平衡。正样本与负样本的比例为 400:1。这是极端不平衡的!图 12.16 展示了这种情况。难怪我们的“实际结节”样本在人群中被忽略!
现在,让我们非常清楚:当我们完成时,我们的模型将能够很好地处理这种数据不平衡。我们甚至可以在不改变平衡的情况下训练模型到最后,假设我们愿意等待无数个纪元。但我们是忙碌的人,有很多事情要做,所以与其等到 GPU 烧毁到宇宙的热死亡,不如尝试通过改变我们训练的类平衡使我们的训练数据看起来更理想。
12.4.1 使数据看起来不那么实际,更像“理想”的方法
最好的做法是有相对更多的正样本。在训练的初始时期,当我们从随机混乱过渡到更有组织的状态时,由于正样本太少,它们会被淹没。
然而,这种情况发生的方式有些微妙。请记住,由于我们的网络权重最初是随机的,网络每个样本的输出也是随机的(但被夹在[0-1]范围内)。
注意 我们的损失函数是nn.CrossEntropyLoss,严格来说是在原始 logits 上操作,而不是类概率。在我们的讨论中,我们将忽略这一区别,假设损失和标签预测之间的差异是相同的。
预测与正确标签数值接近的结果对网络权重几乎没有影响,而与正确答案明显不同的预测结果会导致权重发生更大的变化。由于模型在随机权重初始化时输出是随机的,我们可以假设在我们约 500k 个训练样本(准确地说是 495,958 个)中,我们将有以下近似组:
-
250,000 个负样本将被预测为负面(0.0 到 0.5),并最多对网络权重产生一点朝向预测负面的变化。
-
250,000 个负样本将被预测为正面(0.5 到 1.0),并导致网络权重向预测负面的方向发生大幅变化。
-
500 个正样本将被预测为负面,并导致网络权重向预测正面的方向发生变化。
-
500 个正样本将被预测为正面,并几乎不会对网络权重产生任何变化。
注意 请记住,实际预测是介于 0.0 和 1.0 之间的实数,因此这些组没有严格的界限。
这里的关键是:1 组和 4 组可以是任意大小,它们对训练几乎没有影响。唯一重要的是 2 组和 3 组能够相互抵消,防止网络崩溃到退化的“只输出一种结果”的状态。由于 2 组比 3 组大 500 倍,我们使用的批量大小为 32,大约需要经过 500/32 = 15 批次才能看到一个正样本。这意味着 15 个训练批次中有 14 个将是 100%负面的,只会将所有模型权重拉向预测负面的方向。这种不平衡的拉力产生了我们一直看到的退化行为。
相反,我们希望正样本和负样本数量相同。因此,在训练的第一部分中,一半的标签将被错误分类,这意味着第 2 组和第 3 组的大小应该大致相等。我们还希望确保我们呈现的批次中包含负样本和正样本的混合。平衡将导致拉锯战平衡,每个批次中的类别混合将使模型有很好的机会学会区分这两个类别。由于我们的 LUNA 数据只有少量固定数量的正样本,我们将不得不接受我们拥有的正样本并在训练期间重复呈现它们。
歧视
在这里,我们将歧视定义为“将两个类别彼此分开的能力”。构建和训练一个能够将“实际结节”候选者与正常解剖结构区分开的模型是我们在第 2 部分所做的全部工作的重点。
歧视的一些其他定义更具问题性。虽然超出了我们在这里讨论工作的范围,但从真实世界数据训练的模型存在更大的问题。如果真实世界数据集是从存在真实世界歧视性偏见的来源收集的(例如,种族偏见在逮捕和定罪率中,或者从社交媒体收集的任何内容),并且在数据集准备或训练期间没有纠正这种偏见,那么生成的模型将继续表现出训练数据中存在的相同偏见。就像在人类中一样,种族主义是被学习的。
这意味着几乎任何从互联网大数据源训练的模型都会在某种程度上受到损害,除非极端小心地清除这些模型中的偏见。请注意,就像我们在第 2 部分的目标一样,这被认为是一个未解决的问题。
回想一下我们在第十一章中提到的教授,他的期末考试有 99 个错误答案和 1 个正确答案。下学期,在被告知“你应该有更平衡的真假答案”后,教授决定增加一次期中考试,其中有 99 个正确答案和 1 个错误答案。“问题解决了!”
显然,正确的方法是以一种不允许学生利用测试的更大结构来回答问题的方式交替真实和错误答案。虽然学生可能会注意到“奇数问题是真实的,偶数问题是错误的”这样的模式,但 PyTorch 使用的批处理系统不允许模型“注意到”或利用那种模式。我们的训练数据集将需要更新,以在正样本和负样本之间交替,就像图 12.17 中那样。
不平衡数据就像我们在第九章开始提到的草堆中的针。如果您必须手动执行这项分类工作,您可能会开始同情普雷斯顿。
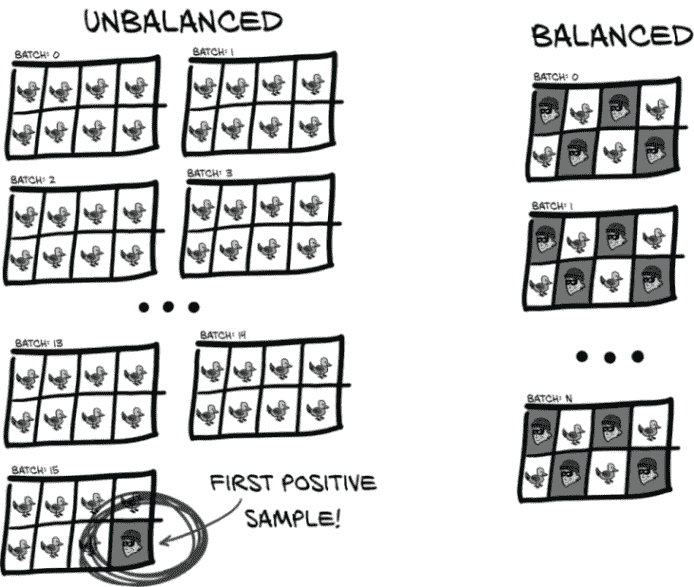
图 12.17 不平衡数据的批次将在第一个正事件之前只有负事件,而平衡数据可以每隔一个样本交替出现。
然而,我们不会为验证进行任何平衡。我们的模型需要在现实世界中表现良好,而现实世界是不平衡的(毕竟,这就是我们获取原始数据的地方!)。
我们应该如何实现这种平衡?让我们讨论我们的选择。
取样器可以重塑数据集
DataLoader 的一个可选参数是sampler=...。这允许数据加载器覆盖传入数据集的本机迭代顺序,而是根据需要塑造、限制或重新强调底层数据。当使用一个不受您控制的数据集时,这可能非常有用。将公共数据集重新塑造以满足您的需求比从头开始重新实现该数据集要少得多。
不足之处在于,我们可以通过采样器实现的许多变异需要我们打破底层数据集的封装。例如,假设我们有一个类似于 CIFAR-10(www.cs.toronto.edu/~kriz/cifar.html)的数据集,由 10 个权重相同的类组成,我们想要让 1 个类(比如“飞机”)现在占所有训练图像的 50%。我们可以决定使用WeightedRandomSampler(mng.bz/8plK)并将每个“飞机”样本索引的权重提高,但构建weights参数需要我们事先知道哪些索引是飞机。
正如我们讨论的那样,Dataset API 只规定子类提供__len__和__getitem__,但我们无法直接询问“哪些样本是飞机?”我们要么事先加载每个样本以查询该样本的类别,要么打破封装并希望我们需要的信息可以轻松从查看Dataset子类的内部实现中获得。
由于在我们可以直接控制数据集的情况下,这两种选项都不是特别理想的,因此第 2 部分的代码在Dataset子类内部实现任何所需的数据整形,而不依赖外部采样器。
在数据集中实现类平衡
我们将直接更改我们的LunaDataset,以呈现平衡的正负样本比例进行训练。我们将保留负训练样本和正训练样本的分开列表,并交替从这两个列表中返回样本。这将防止模型通过简单地回答每个呈现的样本为“false”而得分良好的退化行为。此外,正负类别将交错排列,以便权重更新被迫区分类别。
让我们在LunaDataset中添加一个ratio_int,用于控制第N个样本的标签,并跟踪我们按标签分开的样本。
列表 12.6 dsets.py:217,class LunaDataset
class LunaDataset(Dataset):def __init__(self,val_stride=0,isValSet_bool=None,ratio_int=0,):self.ratio_int = ratio_int# ... line 228self.negative_list = [nt for nt in self.candidateInfo_list if not nt.isNodule_bool]self.pos_list = [nt for nt in self.candidateInfo_list if nt.isNodule_bool]# ... line 265def shuffleSamples(self): # ❶if self.ratio_int:random.shuffle(self.negative_list)random.shuffle(self.pos_list)
❶ 我们将在每个周期的开头调用这个函数,以随机化呈现的样本顺序。
有了这个,我们现在为每个标签都有专门的列表。使用这些列表,更容易根据数据集中的索引返回我们想要的标签。为了确保我们的索引正确,我们应该勾画出我们想要的排序。假设ratio_int为 2,意味着负样本与正样本的比例为 2:1。这意味着每三个索引应该是正样本:
DS Index 0 1 2 3 4 5 6 7 8 9 ...
Label + - - + - - + - - +
Pos Index 0 1 2 3
Neg Index 0 1 2 3 4 5
数据集索引与正索引之间的关系很简单:将数据集索引除以 3 然后向下取整。负索引稍微复杂一些,因为我们必须从数据集索引中减去 1,然后再减去最近的正索引。
在我们的LunaDataset类中实现,看起来像下面这样。
列表 12.7 dsets.py:286,LunaDataset.__getitem__
def __getitem__(self, ndx):if self.ratio_int: # ❶pos_ndx = ndx // (self.ratio_int + 1)if ndx % (self.ratio_int + 1): # ❷neg_ndx = ndx - 1 - pos_ndxneg_ndx %= len(self.negative_list) # ❸candidateInfo_tup = self.negative_list[neg_ndx]else:pos_ndx %= len(self.pos_list) # ❸candidateInfo_tup = self.pos_list[pos_ndx]else:candidateInfo_tup = self.candidateInfo_list[ndx] # ❹
❶ 零的ratio_int意味着使用本地平衡。
❷ 非零余数表示这应该是一个负样本。
❸ 溢出导致环绕。
❹ 如果不平衡类别,则返回第 N 个样本
这可能有点复杂,但如果你仔细检查一下,就会明白。请记住,如果比率较低,我们会在用尽数据集之前用完正样本。我们通过在索引到self.pos_list之前取pos_ndx的模来处理这个问题。虽然由于大量负样本的存在,neg_ndx不太可能发生相同类型的索引溢出,但我们仍然执行模运算,以防以后做出可能导致溢出的更改。
我们还将对数据集的长度进行更改。虽然这并非绝对必要,但加快单个周期的速度是很好的。我们将硬编码我们的__len__为 200,000。
列表 12.8 dsets.py:280,LunaDataset.__len__
def __len__(self):if self.ratio_int:return 200000else:return len(self.candidateInfo_list)
我们不再受限于特定数量的样本,并且提供“完整的一轮”在我们必须多次重复正样本以呈现平衡的训练集时并不是很有意义。通过选择 20 万个样本,我们减少了开始训练运行并看到结果之间的时间(更快的反馈总是不错!),并且我们给自己一个漂亮、清晰的每轮样本数。随时调整一轮的长度以满足您的需求。
为了完整起见,我们还添加了一个命令行参数。
列表 12.9 training.py:31,class LunaTrainingApp
class LunaTrainingApp:def __init__(self, sys_argv=None):# ... line 52parser.add_argument('--balanced',help="Balance the training data to half positive, half negative.",action='store_true',default=False,)
然后我们将该参数传递给LunaDataset构造函数。
列表 12.10 training.py:137,LunaTrainingApp.initTrainDl
def initTrainDl(self):train_ds = LunaDataset(val_stride=10,isValSet_bool=False,ratio_int=int(self.cli_args.balanced), # ❶)
❶ 这里我们依赖于 Python 的True可转换为1。
我们已经准备就绪。让我们运行它!
12.4.2 将平衡的 LunaDataset 与之前的运行进行对比
作为提醒,我们不平衡的训练运行结果如下:
$ python -m p2ch12.training
...
E1 LunaTrainingApp
E1 trn 0.0185 loss, 99.7% correct, 0.0000 precision, 0.0000 recall, nan f1 score
E1 trn_neg 0.0026 loss, 100.0% correct (494717 of 494743)
E1 trn_pos 6.5267 loss, 0.0% correct (0 of 1215)
...
E1 val 0.0173 loss, 99.8% correct, nan precision, 0.0000 recall, nan f1 score
E1 val_neg 0.0026 loss, 100.0% correct (54971 of 54971)
E1 val_pos 5.9577 loss, 0.0% correct (0 of 136)
但是当我们使用--balanced运行时,我们看到以下情况:
$ python -m p2ch12.training --balanced
...
E1 LunaTrainingApp
E1 trn 0.1734 loss, 92.8% correct, 0.9363 precision, 0.9194 recall, 0.9277 f1 score
E1 trn_neg 0.1770 loss, 93.7% correct (93741 of 100000)
E1 trn_pos 0.1698 loss, 91.9% correct (91939 of 100000)
...
E1 val 0.0564 loss, 98.4% correct, 0.1102 precision, 0.7941 recall, 0.1935 f1 score
E1 val_neg 0.0542 loss, 98.4% correct (54099 of 54971)
E1 val_pos 0.9549 loss, 79.4% correct (108 of 136)
这看起来好多了!我们放弃了大约 5%的负样本正确答案,以获得 86%的正确正样本答案。我们又回到了一个扎实的 B 范围内!⁵
然而,就像第十一章一样,这个结果是具有欺骗性的。由于负样本比正样本多 400 倍,即使只有 1%的错误,也意味着我们会将负样本错误地分类为正样本,比实际正样本总数多四倍!
尽管如此,这显然比第十一章的完全错误行为要好得多,比随机抛硬币要好得多。事实上,我们甚至已经进入了(几乎)在实际场景中有用的领域。回想一下我们过度劳累的放射科医生仔细检查每一个 CT 上的每一个斑点:现在我们有了一些可以合理地筛除 95%的假阳性的东西。这是一个巨大的帮助,因为这意味着机器辅助人类的生产力增加了大约十倍。
当然,还有那令人讨厌的 14%被错过的正样本问题,我们可能需要处理一下。也许增加一些额外的训练轮次会有所帮助。让我们看看(再次提醒,每轮至少需要花费 10 分钟):
$ python -m p2ch12.training --balanced --epochs 20
...
E2 LunaTrainingApp
E2 trn 0.0432 loss, 98.7% correct, 0.9866 precision, 0.9879 recall, 0.9873 f1 score
E2 trn_ben 0.0545 loss, 98.7% correct (98663 of 100000)
E2 trn_mal 0.0318 loss, 98.8% correct (98790 of 100000)
E2 val 0.0603 loss, 98.5% correct, 0.1271 precision, 0.8456 recall, 0.2209 f1 score
E2 val_ben 0.0584 loss, 98.6% correct (54181 of 54971)
E2 val_mal 0.8471 loss, 84.6% correct (115 of 136)
...
E5 trn 0.0578 loss, 98.3% correct, 0.9839 precision, 0.9823 recall, 0.9831 f1 score
E5 trn_ben 0.0665 loss, 98.4% correct (98388 of 100000)
E5 trn_mal 0.0490 loss, 98.2% correct (98227 of 100000)
E5 val 0.0361 loss, 99.2% correct, 0.2129 precision, 0.8235 recall, 0.3384 f1 score
E5 val_ben 0.0336 loss, 99.2% correct (54557 of 54971)
E5 val_mal 1.0515 loss, 82.4% correct (112 of 136)...
...
E10 trn 0.0212 loss, 99.5% correct, 0.9942 precision, 0.9953 recall, 0.9948 f1 score
E10 trn_ben 0.0281 loss, 99.4% correct (99421 of 100000)
E10 trn_mal 0.0142 loss, 99.5% correct (99530 of 100000)
E10 val 0.0457 loss, 99.3% correct, 0.2171 precision, 0.7647 recall, 0.3382 f1 score
E10 val_ben 0.0407 loss, 99.3% correct (54596 of 54971)
E10 val_mal 2.0594 loss, 76.5% correct (104 of 136)
...
E20 trn 0.0132 loss, 99.7% correct, 0.9964 precision, 0.9974 recall, 0.9969 f1 score
E20 trn_ben 0.0186 loss, 99.6% correct (99642 of 100000)
E20 trn_mal 0.0079 loss, 99.7% correct (99736 of 100000)
E20 val 0.0200 loss, 99.7% correct, 0.4780 precision, 0.7206 recall, 0.5748 f1 score
E20 val_ben 0.0133 loss, 99.8% correct (54864 of 54971)
E20 val_mal 2.7101 loss, 72.1% correct (98 of 136)
哎呀。要滚动到我们感兴趣的数字,需要滚过很多文本。让我们坚持下去,专注于val_mal XX.X% correct数字(或者直接跳到下一节的 TensorBoard 图表)。第 2 轮之后,我们达到了 87.5%;第 5 轮时,我们达到了 92.6%的峰值;然后到了第 20 轮,我们下降到了 86.8%–低于我们的第二轮!
注意 正如前面提到的,由于网络权重的随机初始化和每轮训练样本的随机选择和排序,预计每次运行都会有独特的行为。
训练集的数字似乎没有同样的问题。负训练样本被正确分类的概率为 98.8%,正样本则为 99.1%。发生了什么?
12.4.3 识别过拟合的症状
我们所看到的是过拟合的明显迹象。让我们看一下我们在正样本上的损失图,见图 12.18。
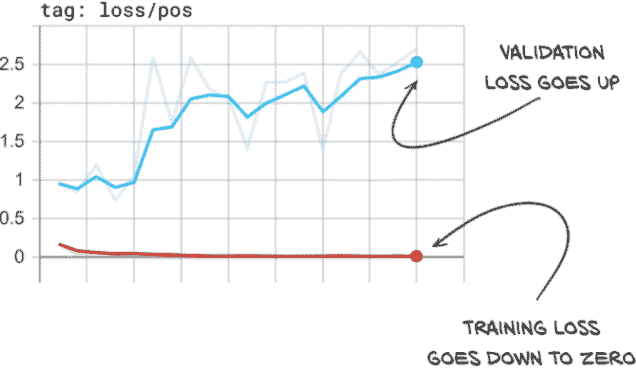
图 12.18 我们的正损失显示出明显的过拟合迹象,因为训练损失和验证损失趋势不同。
在这里,我们可以看到我们的正样本的训练损失几乎为零–每个正样本训练样本都得到了几乎完美的预测。然而,我们的正样本的验证损失却在增加,这意味着我们的实际表现可能正在变差。在这一点上,最好停止训练脚本,因为模型不再改进。
提示 通常,如果您的模型在训练集上的表现正在提高,而在验证集上表现变差,那么模型已经开始过拟合。
然而,我们必须注意检查正确的指标,因为这种趋势只发生在我们的正损失上。如果我们看一下我们的整体损失,一切似乎都很好!这是因为我们的验证集不平衡,所以整体损失被我们的负样本所主导。正如图 12.19 所示,我们在我们的负样本中没有看到相同的发散行为。相反,我们的负损失看起来很好!这是因为我们有 400 倍的负样本,所以模型要记住个别细节要困难得多。然而,我们的正训练集只有 1,215 个样本。虽然我们多次重复这些样本,但这并不会使它们更难记忆。模型正在从泛化原则转变为基本上记住这 1,215 个样本的怪癖,并声称不属于这几个样本之一的任何东西都是负样本。这包括负训练样本和我们验证集中的所有内容(正负样本都有)。
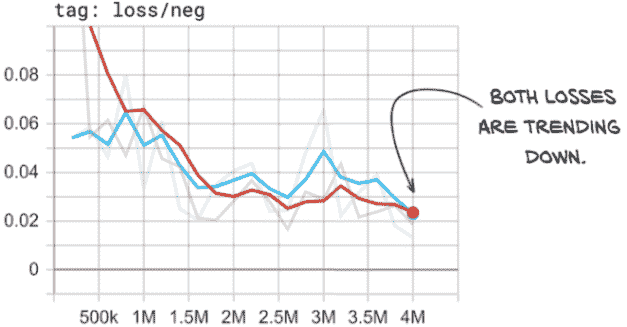
图 12.19 我们的负损失没有显示过拟合的迹象
显然,仍然存在一些泛化,因为我们大约正确分类了 70%的正验证集。我们只需要改变我们训练模型的方式,使我们的训练集和验证集都朝着正确的方向发展。
12.5 重新审视过拟合问题
我们在第五章中提到了过拟合的概念,现在是时候更仔细地看看如何解决这种常见情况了。我们训练模型的目标是教会它识别我们感兴趣的类别的一般属性,如我们数据集中所表达的那样。这些一般属性存在于该类别的一些或所有样本中,并且可以泛化并用于预测未经训练的样本。当模型开始学习训练集的特定属性时,就会发生过拟合,模型开始失去泛化的能力。如果这有点抽象,让我们使用另一个类比。
12.5.1 一个过拟合的人脸到年龄预测模型
假设我们有一个模型,它以人脸图像作为输入,并输出预测的年龄。一个好的模型会注意到年龄的特征,如皱纹、白发、发型、服装选择等,并利用这些建立不同年龄看起来的一般模型。当呈现一张新图片时,它会考虑“保守的发型”、“眼镜”和“皱纹”等因素,得出“大约 65 岁”的结论。
与之相比,过拟合模型则是通过记住识别细节来记住特定的人。“那个发型和那副眼镜意味着那是弗兰克。他 62.8 岁了”;“哦,那个伤疤意味着那是哈里。他 39.3 岁了”;等等。当展示一个新的人时,模型将无法识别这个人,也完全不知道该预测多少岁。
更糟糕的是,如果展示弗兰克的儿子的照片(看起来像他爸爸,至少戴着眼镜时是这样!),模型会说:“我认为那是弗兰克。他 62.8 岁了。”尽管小弗兰克实际上年轻了 25 岁!
过拟合通常是由于训练样本太少,与模型仅仅记住答案的能力相比。普通人可以记住自己家人的生日,但在预测比一个小村庄规模更大的群体的年龄时,就必须求助于概括。
我们的人脸到年龄模型有能力简单地记住那些看起来不完全符合其年龄的照片。正如我们在第 1 部分中讨论的,模型容量是一个有点抽象的概念,但大致是模型参数数量乘以这些参数的有效使用方式。当模型的容量相对于需要记住训练集中难样本的数据量很高时,模型很可能会开始过拟合这些更难的训练样本。
12.6 通过数据增强防止过拟合
是时候将我们的模型训练从好到优秀了。我们需要完成图 12.20 中的最后一步。
图 12.20 本章的主题集,重点是数据增强
我们通过对单个样本应用合成的改变来增强数据集,从而得到一个有效大小比原始数据集更大的新数据集。典型的目标是使改变导致合成样本仍然代表与源样本相同的一般类别,但不能与原始样本一起轻松记忆。当正确执行时,这种增强可以将训练集大小增加到模型能够记忆的范围之外,从而迫使模型越来越依赖泛化,这正是我们想要的。在处理有限数据时,这种增强尤其有用,正如我们在第 12.4.1 节中看到的。
当然,并非所有的增强都同样有用。回到我们的面部年龄预测模型的例子,我们可以轻松地将每个图像的四个角像素的红色通道更改为随机值 0-255,这将导致数据集比原始数据集大 40 亿倍。当然,这并不特别有用,因为模型可以相当轻松地学会忽略图像角落的红点,而图像的其余部分仍然像单个未经增强的原始图像一样容易记忆。将这种方法与左右翻转图像进行对比。这样做只会使数据集比原始数据集大两倍,但每个图像对于训练目的来说会更有用。年龄的一般属性与左右无关,因此镜像图像仍然具有代表性。同样,面部图片很少是完全对称的,因此镜像版本不太可能与原始版本轻松记忆。
12.6.1 具体的数据增强技术
我们将实现五种特定类型的数据增强。我们的实现将允许我们单独或合并地对任何一种或全部进行实验。这五种技术如下:
-
将图像上下、左右和/或前后镜像
-
将图像移动几个体素
-
将图像放大或缩小
-
将图像围绕头-脚轴旋转
-
添加噪声到图像
对于每种技术,我们希望确保我们的方法保持训练样本的代表性,同时又足够不同,以便样本用于训练时是有用的。
我们将定义一个函数 getCtAugmentedCandidate,负责获取我们标准的 CT 块并对其中的候选进行修改。我们的主要方法将定义一个仿射变换矩阵(mng.bz/Edxq),并将其与 PyTorch 的 affine_grid(pytorch.org/docs/stable/nn.html#affine-grid)和 grid_sample(pytorch.org/docs/stable/nn.html#torch.nn.functional.grid_sample)函数一起使用,以对我们的候选进行重新采样。
列表 12.11 dsets.py:149, def getCtAugmentedCandidate
def getCtAugmentedCandidate(augmentation_dict,series_uid, center_xyz, width_irc,use_cache=True):if use_cache:ct_chunk, center_irc = \getCtRawCandidate(series_uid, center_xyz, width_irc)else:ct = getCt(series_uid)ct_chunk, center_irc = ct.getRawCandidate(center_xyz, width_irc)ct_t = torch.tensor(ct_chunk).unsqueeze(0).unsqueeze(0).to(torch.float32)
我们首先获取 ct_chunk,可以从缓存中获取,也可以直接通过加载 CT 获取(这在我们创建自己的候选中会很方便),然后将其转换为张量。接下来是仿射网格和采样代码。
列表 12.12 dsets.py:162, def getCtAugmentedCandidate
transform_t = torch.eye(4)
# ... # ❶
# ... line 195
affine_t = F.affine_grid(transform_t[:3].unsqueeze(0).to(torch.float32),ct_t.size(),align_corners=False,)augmented_chunk = F.grid_sample(ct_t,affine_t,padding_mode='border',align_corners=False,).to('cpu')
# ... line 214
return augmented_chunk[0], center_irc
❶ 转换 transform_tensor 的修改将在这里进行。
没有任何额外的东西,这个函数不会有太多作用。让我们看看需要添加一些实际变换的步骤。
注意 重要的是要构建数据流水线,使得缓存步骤发生在增强之前!否则将导致数据被增强一次,然后保留在那种状态,这违背了初衷。
镜像
当镜像一个样本时,我们保持像素值完全相同,只改变图像的方向。由于肿瘤生长与左右或前后没有强烈的相关性,我们应该能够在不改变样本代表性质的情况下翻转它们。指数轴(在患者坐标中称为Z)对应于直立人体中的重力方向,然而,肿瘤的顶部和底部可能存在差异的可能性。我们将假设这没问题,因为快速的视觉调查并没有显示任何明显的偏差。如果我们正在进行一个临床相关的项目,我们需要向专家确认这一假设。
列表 12.13 dsets.py:165,def getCtAugmentedCandidate
for i in range(3):if 'flip' in augmentation_dict:if random.random() > 0.5:transform_t[i,i] *= -1
grid_sample 函数将范围 [-1, 1] 映射到旧张量和新张量的范围(如果大小不同,则会隐式地进行重新缩放)。这个范围映射意味着为了镜像数据,我们只需要将变换矩阵的相关元素乘以 -1。
通过随机偏移进行移动
将结节候选物体移动一下不会产生很大的影响,因为卷积是独立于平移的,尽管这会使我们的模型对不完全居中的结节更加稳健。更重要的是,偏移量可能不是整数个体素数;相反,数据将使用三线性插值重新采样,这可能会引入一些轻微的模糊。样本边缘的体素将被重复,这可以看作是沿边界的一部分呈现出模糊、条纹状的区域。
列表 12.14 dsets.py:165,def getCtAugmentedCandidate
for i in range(3):# ... line 170if 'offset' in augmentation_dict:offset_float = augmentation_dict['offset']random_float = (random.random() * 2 - 1)transform_t[i,3] = offset_float * random_float
请注意,我们的 'offset' 参数是以与网格采样函数期望的 [-1, 1] 范围相同的比例表示的最大偏移量。
缩放
稍微缩放图像与镜像和移动非常相似。这样做也会导致我们刚刚讨论的在移动样本时提到的相同重复边缘体素。
列表 12.15 dsets.py:165,def getCtAugmentedCandidate
for i in range(3):# ... line 175if 'scale' in augmentation_dict:scale_float = augmentation_dict['scale']random_float = (random.random() * 2 - 1)transform_t[i,i] *= 1.0 + scale_float * random_float
由于 random_float 被转换为在范围 [-1, 1],所以实际上无论我们将 scale_float * random_float 添加到 1.0 还是从 1.0 中减去它都没有关系。
旋转
旋转是我们将使用的第一种增强技术,我们必须仔细考虑我们的数据,以确保我们不会通过导致其不再具有代表性的转换来破坏我们的样本。请记住,我们的 CT 切片在行和列(X 和 Y 轴)上具有均匀间距,但在指数(或 Z)方向上,体素是非立方体的。这意味着我们不能将这些轴视为可互换的。
一种选择是重新采样我们的数据,使得我们沿指数轴的分辨率与其他两个轴的分辨率相同,但这并不是一个真正的解决方案,因为沿着那个轴的数据会非常模糊和模糊。即使我们插入更多的体素,数据的保真度仍然很差。相反,我们将把这个轴视为特殊轴,并将我们的旋转限制在 X-Y 平面上。
列表 12.16 dsets.py:181,def getCtAugmentedCandidate
if 'rotate' in augmentation_dict:angle_rad = random.random() * math.pi * 2s = math.sin(angle_rad)c = math.cos(angle_rad)rotation_t = torch.tensor([[c, -s, 0, 0],[s, c, 0, 0],[0, 0, 1, 0],[0, 0, 0, 1],])transform_t @= rotation_t
噪音
我们的最终增强技术与其他技术不同,因为它在某种程度上对我们的样本进行了积极破坏,而翻转或旋转样本则没有这种情况。如果我们向样本添加太多噪音,它将淹没真实数据,并使其实际上无法分类。虽然如果我们使用极端输入值,移动和缩放样本也会产生类似的效果,但我们选择的值只会影响样本的边缘。噪音将对整个图像产生影响。
列表 12.17 dsets.py:208,def getCtAugmentedCandidate
if 'noise' in augmentation_dict:noise_t = torch.randn_like(augmented_chunk)noise_t *= augmentation_dict['noise']augmented_chunk += noise_t
其他增强类型已经增加了我们数据集的有效大小。噪音使我们模型的工作更加困难。一旦我们看到一些训练结果,我们将重新审视这一点。
检查增强候选物体
我们可以在图 12.21 中看到我们努力的结果。左上角的图像显示了一个未增强的正候选样本,接下来的五个图像显示了每种增强类型的效果。最后,底部行显示了三次组合结果。
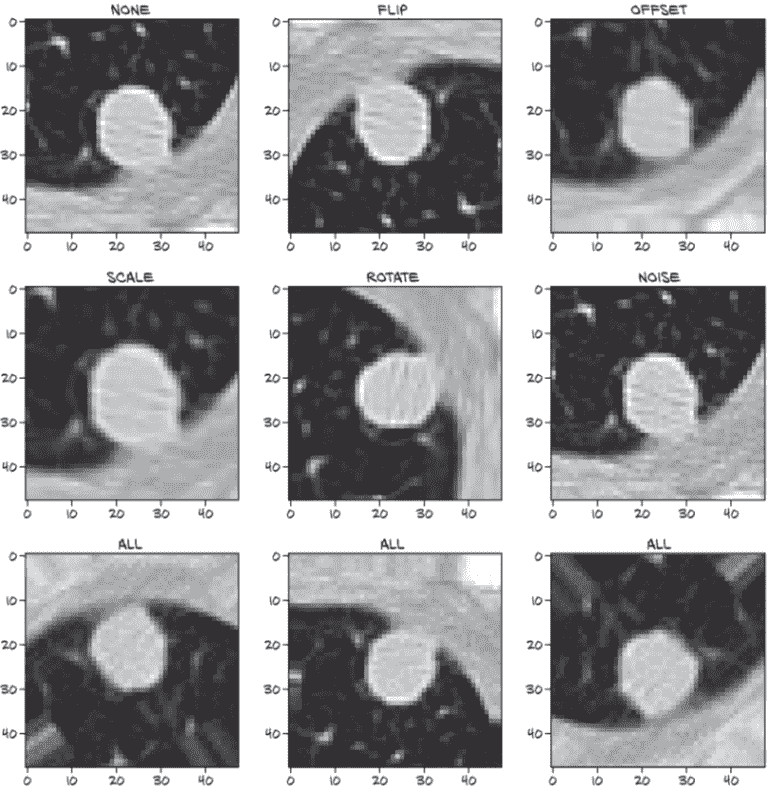
图 12.21 在正结节样本上执行的各种增强类型
由于对增强数据集的每次__getitem__调用都会随机重新应用增强,底部行的每个图像看起来都不同。这也意味着几乎不可能再次生成完全相同的图像!还要记住,有时'flip'增强会导致没有翻转。始终返回翻转图像与一开始不翻转一样限制。现在让我们看看这是否有所不同。
12.6.2 从数据增强中看到改进
我们将训练额外的模型,每种增强类型一个,还有一个将所有增强类型组合在一起的额外模型训练运行。一旦它们完成,我们将在 TensorBoard 中查看我们的数据。
为了能够打开和关闭我们的新增强类型,我们需要将augmentation_dict的构建暴露给我们的命令行界面。程序的参数将通过parser.add_argument调用添加(未显示,但类似于我们的程序已经具有的那些),然后将被馈送到实际构建augmentation_dict的代码中。
列表 12.18 training.py:105,LunaTrainingApp.__init__
self.augmentation_dict = {}
if self.cli_args.augmented or self.cli_args.augment_flip:self.augmentation_dict['flip'] = True
if self.cli_args.augmented or self.cli_args.augment_offset:self.augmentation_dict['offset'] = 0.1 # ❶
if self.cli_args.augmented or self.cli_args.augment_scale:self.augmentation_dict['scale'] = 0.2 # ❶
if self.cli_args.augmented or self.cli_args.augment_rotate:self.augmentation_dict['rotate'] = True
if self.cli_args.augmented or self.cli_args.augment_noise:self.augmentation_dict['noise'] = 25.0 # ❶
❶ 这些值是经验选择的,具有合理的影响,但可能存在更好的值。
现在我们已经准备好这些命令行参数,您可以运行以下命令,或者重新查看 p2_run_everything.ipynb 并运行第 8 到 16 个单元格。无论如何运行,都需要花费相当长的时间才能完成:
$ .venv/bin/python -m p2ch12.prepcache # ❶$ .venv/bin/python -m p2ch12.training --epochs 20 \--balanced sanity-bal # ❷$ .venv/bin/python -m p2ch12.training --epochs 10 \--balanced --augment-flip sanity-bal-flip$ .venv/bin/python -m p2ch12.training --epochs 10 \--balanced --augment-shift sanity-bal-shift$ .venv/bin/python -m p2ch12.training --epochs 10 \--balanced --augment-scale sanity-bal-scale$ .venv/bin/python -m p2ch12.training --epochs 10 \--balanced --augment-rotate sanity-bal-rotate$ .venv/bin/python -m p2ch12.training --epochs 10 \--balanced --augment-noise sanity-bal-noise$ .venv/bin/python -m p2ch12.training --epochs 20 \--balanced --augmented sanity-bal-aug
❶ 您每章只需要准备一次缓存。
❷ 您可能在本章的早些时候运行过这个;在这种情况下,无需重新运行!
在此期间,我们可以启动 TensorBoard。让我们通过更改logdir参数来指示它仅显示这些运行,如下所示:../path/to/tensorboard --logdir runs/p2ch12。
根据您手头的硬件情况,训练可能需要很长时间。如果需要加快进度,可以跳过flip、shift和scale训练任务,并将第一次和最后一次运行减少到 11 个周期。我们选择了 20 次运行,因为这有助于使它们脱颖而出,但 11 次也可以。
如果让所有内容运行到完成,您的 TensorBoard 应该有类似图 12.22 所示的数据。我们将取消选择除验证数据之外的所有内容,以减少混乱。当您实时查看数据时,还可以更改平滑值,这有助于澄清趋势线。快速查看一下图,然后我们将详细介绍它。
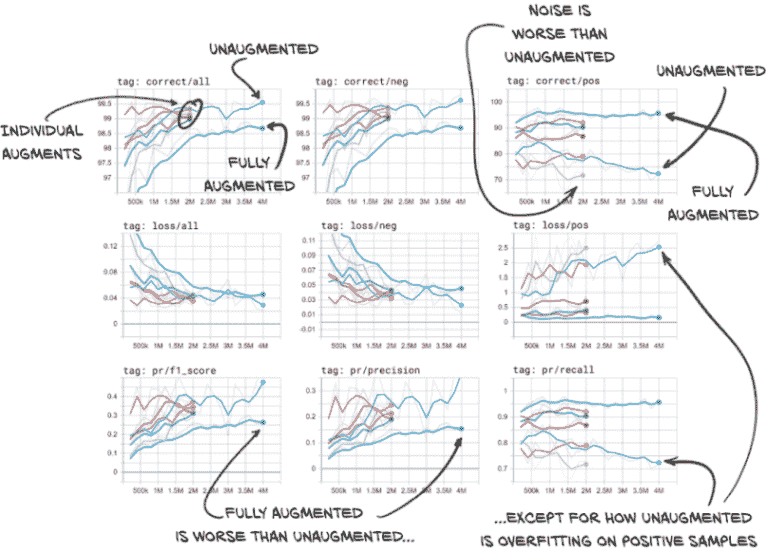
图 12.22 用各种增强方案训练的网络在验证集上正确分类的百分比、损失、F1 分数、精度和召回率
在左上角的图表中第一件要注意的事情(“标签:正确/全部”)是各个增强类型有些混乱。我们的未增强和完全增强的运行位于该混乱的两侧。这意味着当结合时,我们的增强效果超过了其各部分之和。还有一个有趣的地方是,我们的完全增强运行得到了更多错误答案。虽然这通常是不好的,但如果我们看一下右侧的图像列(重点是我们实际关心的正候选样本–那些真正的结节),我们会发现我们的完全增强模型在查找正候选样本方面要好得多。完全增强模型的召回率很高!它也更不容易过拟合。正如我们之前看到的,我们的未增强模型随着时间的推移变得更糟。
值得注意的一点是,噪声增强模型在识别结节方面比未增强模型更差。如果我们记得我们说过噪声会让模型的工作变得更困难,这就说得通了。
在实时数据中看到的另一个有趣的事情(在这里有点混乱)是,旋转增强模型在召回方面几乎与完全增强模型一样好,并且在精度上有很大提高。由于我们的 F1 分数受精度限制(由于负样本数量较高),旋转增强模型的 F1 分数也更高。
未来我们将继续使用完全增强的模型,因为我们的用例需要高召回率。F1 分数仍将用于确定哪个时期保存为最佳。在实际项目中,我们可能希望花费额外的时间来调查不同的增强类型和参数值组合是否能产生更好的结果。
12.7 结论
在本章中,我们花了很多时间和精力重新构思我们对模型性能的看法。通过糟糕的评估方法很容易被误导,而且对评估模型的因素有强烈的直觉理解至关重要。一旦这些基本原理内化,就更容易发现我们何时被误导。
我们还学习了如何处理数据源不足的情况。能够合成代表性的训练样本非常有用。确实很少有太多的训练数据的情况!
现在我们有一个表现合理的分类器,我们将把注意力转向自动查找候选结节进行分类。第十三章将从那里开始;然后,在第十四章中,我们将把这些候选者反馈到我们在这里开发的分类器中,并着手构建另一个分类器来区分恶性结节和良性结节。
12.8 练习
-
F1 分数可以推广支持除 1 以外的值。
-
阅读
en.wikipedia.org/wiki/F1_score,并实现 F2 和 F0.5 分数。 -
确定 F1、F2 和 F0.5 中哪个对这个项目最有意义。跟踪该值,并与 F1 分数进行比较和对比。⁶
-
-
实现
WeightedRandomSampler方法来平衡LunaDataset的正负训练样本,ratio_int设置为0。-
您如何获取每个样本类别的所需信息?
-
哪种方法更容易?哪种导致更易读的代码?
-
-
尝试不同的类平衡方案。
-
两个时期后哪个比例得分最高?20 个时期后呢?
-
如果比例是
epoch_ndx的函数会怎样?
-
-
尝试不同的数据增强方法。
-
是否可以使任何现有方法更具侵略性(噪声、偏移等)?
-
噪声增强的包含是否有助于或妨碍您的训练结果?
- 是否有其他值会改变这个结果?
-
研究其他项目使用的数据增强方法。这里有哪些适用的?
- 为正结节候选实现“mixup”增强。这有帮助吗?
-
-
将初始归一化从
nn.BatchNorm更改为自定义内容,并重新训练模型。-
使用固定归一化能获得更好的结果吗?
-
什么归一化偏移和比例是有意义的?
-
非线性归一化如平方根是否有帮助?
-
-
TensorBoard 除了我们在这里介绍的内容之外还可以显示哪些其他数据?
-
你能让它显示有关网络权重的信息吗?
-
在运行模型对特定样本的中间结果时有什么?
- 将模型的骨干包装在
nn.Sequential的实例中是否有助于或妨碍这一努力?
- 将模型的骨干包装在
-
12.9 总结
-
二进制标签和二进制分类阈值结合在一起,将数据集分成四个象限:真正阳性、真正阴性、假阴性和假阳性。这四个量为我们改进的性能指标提供了基础。
-
回忆是模型最大化真正阳性的能力。选择每一个项目都能保证完美的回忆——因为所有正确答案都包括在内——但也表现出较低的精度。
-
精度是模型最小化假阳性的能力。不选择任何内容保证了完美的精度——因为没有错误答案被包括在内——但也表现出较低的回忆。
-
F1 分数将精度和回忆结合成一个描述模型性能的单一指标。我们使用 F1 分数来确定对训练或模型进行的更改对我们的性能有何影响。
-
在训练过程中平衡训练集,使得正负样本数量相等,可以使模型表现更好(定义为具有正的、增加的 F1 分数)。
-
数据增强是指采用现有的有机数据样本并对其进行修改,使得生成的增强样本与原始样本有明显不同,但仍代表同一类别的样本。这样可以在数据有限的情况下进行额外的训练而不会过拟合。
-
常见的数据增强策略包括改变方向、镜像、重新缩放、偏移、添加噪音。根据项目的不同,其他更具体的策略也可能相关。
¹ 没有人实际说过这个。
² 如果花费的时间超过这个时间,请确保您已运行prepcache脚本。
³ 请记住,这些图像只是分类空间的一种表示,不代表真实情况。
⁴ 目前尚不清楚这是否属实,但这是有可能的,而且损失确实在改善中……
⁵ 请记住,这是在仅呈现了 200,000 个训练样本之后,而不是不平衡数据集的 500,000+个样本之后,所以我们用了不到一半的时间就达到了这个结果。
⁶ 是的,这是一个暗示,这不是 F1 分数!
十三、使用分割找到可疑结节
本章涵盖
-
使用像素到像素模型对数据进行分割
-
使用 U-Net 进行分割
-
使用 Dice 损失理解掩模预测
-
评估分割模型的性能
在过去的四章中,我们取得了很大的进展。我们了解了 CT 扫描和肺部肿瘤,数据集和数据加载器,以及指标和监控。我们还应用了我们在第一部分学到的许多东西,并且我们有一个可用的分类器。然而,我们仍然在一个有些人为的环境中操作,因为我们需要手动注释的结节候选信息加载到我们的分类器中。我们没有一个很好的方法可以自动创建这个输入。仅仅将整个 CT 输入到我们的模型中——也就是说,插入重叠的 32×32×32 数据块——会导致每个 CT 有 31×31×7=6,727 个数据块,大约是我们拥有的注释样本数量的 10 倍。我们需要重叠边缘;我们的分类器期望结节候选位于中心,即使如此,不一致的定位可能会带来问题。
正如我们在第九章中解释的,我们的项目使用多个步骤来解决定位可能结节、识别它们,并指示可能恶性的问题。这是从业者中常见的方法,而在深度学习研究中,有一种倾向是展示单个模型解决复杂问题的能力。我们在本书中使用的多阶段项目设计给了我们一个很好的借口,逐步介绍新概念。
13.1 向我们的项目添加第二个模型
在前两章中,我们完成了图 13.1 中显示的计划的第 4 步:分类。在本章中,我们不仅要回到上一步,而是回到上两步。我们需要找到一种方法告诉我们的分类器在哪里查找。为此,我们将对原始 CT 扫描进行处理,找出可能是结节的所有内容。这是图中突出显示的第 2 步。为了找到这些可能的结节,我们必须标记看起来可能是结节的体素,这个过程被称为分割。然后,在第十四章中,我们将处理第 3 步,并通过将这幅图像的分割掩模转换为位置注释来提供桥梁。
图 13.1 我们的端到端肺癌检测项目,重点关注本章主题:第 2 步,分割
到本章结束时,我们将创建一个新模型,其架构可以执行像素级标记,或分割。完成这项任务的代码将与上一章的代码非常相似,特别是如果我们专注于更大的结构。我们将要做出的所有更改都将更小且有针对性。正如我们在图 13.2 中看到的,我们需要更新我们的模型(图中的第 2A 步),数据集(2B),以及训练循环(2C),以适应新模型的输入、输出和其他要求。(如果你在图中右侧的步骤 2 中不认识每个组件,不要担心。我们在到达每个步骤时会详细讨论。)最后,我们将检查运行新模型时得到的结果(图中的第 3 步)。
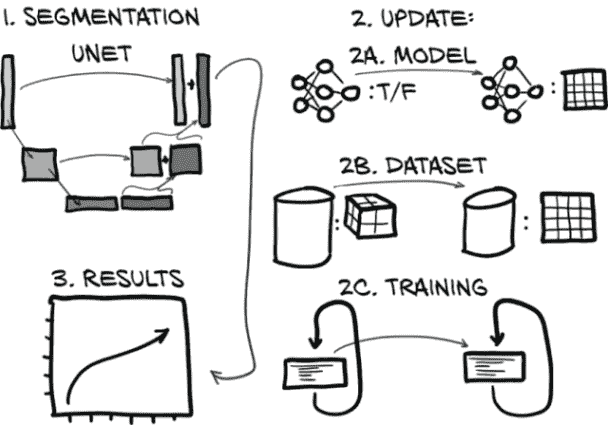
图 13.2 用于分割的新模型架构,以及我们将实施的模型、数据集和训练循环更新
将图 13.2 分解为步骤,我们本章的计划如下:
-
分割。首先,我们将学习使用 U-Net 模型进行分割的工作原理,包括新模型组件是什么,以及在我们进行分割过程中会发生什么。这是图 13.2 中的第 1 步。
-
更新。为了实现分割,我们需要在三个主要位置更改我们现有的代码库,如图 13.2 右侧的子步骤所示。代码在结构上与我们为分类开发的代码非常相似,但在细节上有所不同:
-
更新模型(步骤 2A)。我们将把一个现有的 U-Net 集成到我们的分割模型中。我们在第十二章的模型输出一个简单的真/假分类;而在本章中的模型将输出整个图像。
-
更改数据集(步骤 2B)。我们需要更改我们的数据集,不仅提供 CT 的片段,还要为结节提供掩模。分类数据集由围绕结节候选的 3D 裁剪组成,但我们需要收集完整的 CT 切片和用于分割训练和验证的 2D 裁剪。
-
调整训练循环(步骤 2C)。我们需要调整训练循环,以引入新的损失进行优化。因为我们想在 TensorBoard 中显示我们的分割结果的图像,我们还会做一些事情,比如将我们的模型权重保存到磁盘上。
-
-
结果。最后,当我们查看定量分割结果时,我们将看到我们努力的成果。
13.2 各种类型的分割
要开始,我们需要讨论不同类型的分割。对于这个项目,我们将使用语义分割,这是使用标签对图像中的每个像素进行分类的行为,就像我们在分类任务中看到的那样,例如,“熊”,“猫”,“狗”等。如果做得正确,这将导致明显的块或区域,表示诸如“所有这些像素都是猫的一部分”之类的事物。这采用标签掩模或热图的形式,用于识别感兴趣的区域。我们将有一个简单的二进制标签:真值将对应结节候选,假值表示无趣的健康组织。这部分满足了我们找到结节候选的需求,稍后我们将把它们馈送到我们的分类网络中。
在深入细节之前,我们应该简要讨论我们可以采取的其他方法来找到结节候选。例如,实例分割使用不同的标签标记感兴趣的单个对象。因此,语义分割会为两个人握手的图片使用两个标签(“人”和“背景”),而实例分割会有三个标签(“人 1”,“人 2”和“背景”),其中边界大约在握手处。虽然这对我们区分“结节 1”和“结节 2”可能有用,但我们将使用分组来识别单个结节。这种方法对我们很有效,因为结节不太可能接触或重叠。
另一种处理这类任务的方法是目标检测,它在图像中定位感兴趣的物品并在该物品周围放置一个边界框。虽然实例分割和目标检测对我们来说可能很好,但它们的实现有些复杂,我们认为它们不是你接下来学习的最好内容。此外,训练目标检测模型通常需要比我们的方法更多的计算资源。如果你感到挑战,YOLOv3 论文比大多数深度学习研究论文更有趣。² 对我们来说,语义分割就是最好的选择。
注意 当我们在本章的代码示例中进行操作时,我们将依赖您从 GitHub 检查大部分更大上下文的代码。我们将省略那些无趣或与之前章节类似的代码,以便我们可以专注于手头问题的关键。
13.3 语义分割:逐像素分类
通常,分割用于回答“这张图片中的猫在哪里?”这种问题。显然,大多数猫的图片,如图 13.3,其中有很多非猫的部分;背景中的桌子或墙壁,猫坐在上面的键盘,这种情况。能够说“这个像素是猫的一部分,这个像素是墙壁的一部分”需要基本不同的模型输出和不同的内部结构,与我们迄今为止使用的分类模型完全不同。分类可以告诉我们猫是否存在,而分割将告诉我们在哪里可以找到它。
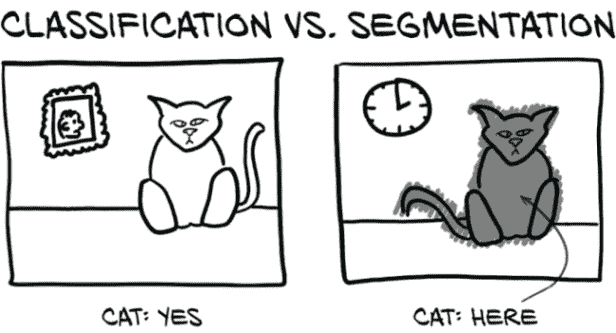
图 13.3 分类结果产生一个或多个二进制标志,而分割产生一个掩码或热图。
如果您的项目需要区分近处猫和远处猫,或者左边的猫和右边的猫,那么分割可能是正确的方法。迄今为止我们实现的图像消费分类模型可以被看作是漏斗或放大镜,将大量像素聚焦到一个“点”(或者更准确地说,一组类别预测)中,如图 13.4 所示。分类模型提供的答案形式为“是的,这一大堆像素中有一只猫”,或者“不,这里没有猫”。当您不关心猫在哪里,只关心图像中是否有猫时,这是很好的。
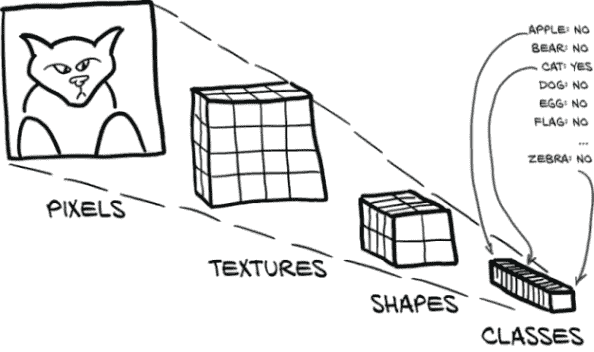
图 13.4 用于分类的放大镜模型结构
重复的卷积和下采样层意味着模型从消耗原始像素开始,产生特定的、详细的检测器,用于识别纹理和颜色等内容,然后构建出更高级的概念特征检测器,用于眼睛、耳朵、嘴巴和鼻子等部位³,最终得出“猫”与“狗”的结论。由于每个下采样层后卷积的接受域不断增加,这些更高级的检测器可以利用来自输入图像越来越大区域的信息。
不幸的是,由于分割需要产生类似图像的输出,最终得到一个类似于单一分类列表的二进制标志是行不通的。正如我们从第 11.4 节回忆的那样,下采样是增加卷积层接受域的关键,也是帮助将构成图像的像素数组减少到单一类别列表的关键。请注意图 13.5,它重复了图 11.6。

图 13.5 LunaModel块的卷积架构,由两个 3×3 卷积和一个最大池组成。最终像素具有 6×6 的接受域。
在图中,我们的输入从左到右在顶部行中流动,并在底部行中继续。为了计算出影响右下角单个像素的接受域–我们可以向后推导。最大池操作有 2×2 的输入,产生每个最终输出像素。底部行中的 3×3 卷积在每个方向(包括对角线)查看一个相邻像素,因此导致 2×2 输出的卷积的总接受域为 4×4(带有右侧的“x”字符)。顶部行中的 3×3 卷积然后在每个方向添加一个额外的像素上下文,因此右下角单个输出像素的接受域是顶部左侧输入的 6×6 区域。通过来自最大池的下采样,下一个卷积块的接受域将具有双倍宽度,每次额外的下采样将再次使其加倍,同时缩小输出的大小。
如果我们希望输出与输入大小相同,我们将需要不同的模型架构。一个用于分割的简单模型可以使用重复的卷积层而没有任何下采样。在适当的填充下,这将导致输出与输入大小相同(好),但由于基于多层小卷积的有限重叠,会导致非常有限的感受野(坏)。分类模型使用每个下采样层来使后续卷积的有效范围加倍;没有这种有效领域大小的增加,每个分割像素只能考虑一个非常局部的邻域。
注意 假设 3×3 卷积,堆叠卷积的简单模型的感受野大小为 2 * L + 1,其中L是卷积层数。
四层 3×3 卷积将每个输出像素的感受野大小为 9×9。通过在第二个和第三个卷积之间插入一个 2×2 最大池,并在最后插入另一个,我们将感受野增加到…
注意 看看你是否能自己算出数学问题;完成后,回到这里查看。
… 16×16。最终的一系列 conv-conv-pool 具有 6×6 的感受野,但这发生在第一个最大池之后,这使得原始输入分辨率中的最终有效感受野为 12×12。前两个卷积层在 12×12 周围添加了总共 2 个像素的边框,总共为 16×16。
因此问题仍然是:如何在保持输入像素与输出像素 1:1 比率的同时改善输出像素的感受野?一个常见的答案是使用一种称为上采样的技术,它将以给定分辨率的图像生成更高分辨率的图像。最简单的上采样只是用一个N×N像素块替换每个像素,每个像素的值与原始输入像素相同。从那里开始,可能性变得更加复杂,选项包括线性插值和学习反卷积。
13.3.1 U-Net 架构
在我们陷入可能的上采样算法的兔子洞之前,让我们回到本章的目标。根据图 13.6,第一步是熟悉一个名为 U-Net 的基础分割算法。

图 13.6 我们将使用的分割新模型架构
U-Net 架构是一种可以产生像素级输出的神经网络设计,专为分割而发明。从图 13.6 的突出部分可以看出,U-Net 架构的图表看起来有点像字母U,这解释了名称的起源。我们还立即看到,它比我们熟悉的大多数顺序结构的分类器要复杂得多。不久我们将在图 13.7 中看到 U-Net 架构的更详细版本,并了解每个组件的具体作用。一旦我们了解了模型架构,我们就可以开始训练一个来解决我们的分割任务。
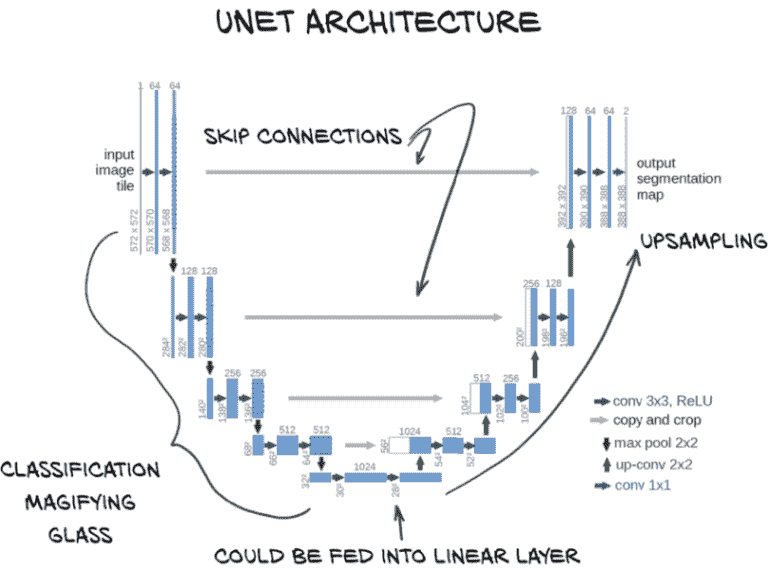
图 13.7 来自 U-Net 论文的架构,带有注释。来源:本图的基础由 Olaf Ronneberger 等人提供,来源于论文“U-Net:用于生物医学图像分割的卷积网络”,可在arxiv.org/abs/1505.04597和lmb.informatik.uni-freiburg.de/people/ronneber/u-net找到。
图 13.7 中显示的 U-Net 架构是图像分割的一个早期突破。让我们看一看,然后逐步了解架构。
在这个图表中,方框代表中间结果,箭头代表它们之间的操作。架构的 U 形状来自网络操作的多个分辨率。顶部一行是完整分辨率(对我们来说是 512×512),下面一行是其一半,依此类推。数据从左上流向底部中心,通过一系列卷积和下采样,正如我们在分类器中看到的并在第八章中详细讨论的那样。然后我们再次上升,使用上采样卷积回到完整分辨率。与原始 U-Net 不同,我们将填充物,以便不会在边缘丢失像素,因此我们左右两侧的分辨率相同。
早期的网络设计已经具有这种 U 形状,人们试图利用它来解决完全卷积网络的有限感受野大小问题。为了解决这个有限的感受野大小问题,他们使用了一种设计,复制、反转并附加图像分类网络的聚焦部分,以创建一个从精细详细到宽感受野再到精细详细的对称模型。
然而,早期的网络设计存在收敛问题,这很可能是由于在下采样过程中丢失了空间信息。一旦信息到达大量非常缩小的图像,对象边界的确切位置变得更难编码,因此更难重建。为了解决这个问题,U-Net 的作者在图中心添加了我们看到的跳跃连接。我们在第八章首次接触到跳跃连接,尽管它们在这里的应用方式与 ResNet 架构中的不同。在 U-Net 中,跳跃连接将输入沿着下采样路径短路到上采样路径中的相应层。这些层接收来自 U 较低位置的宽感受野层的上采样结果以及通过“复制和裁剪”桥接连接的早期精细详细层的输出作为输入。这是 U-Net 的关键创新(有趣的是,这比 ResNet 更早)。
所有这些意味着这些最终的细节层在最佳状态下运作。它们既具有关于周围环境的更大背景信息,又具有来自第一组全分辨率层的精细详细数据。
最右侧的“conv 1x1”层位于网络头部,将通道数从 64 改变为 2(原始论文有 2 个输出通道;我们的情况下有 1 个)。这在某种程度上类似于我们在分类网络中使用的全连接层,但是逐像素、逐通道:这是一种将最后一次上采样步骤中使用的滤波器数量转换为所需的输出类别数量的方法。
13.4 更新用于分割的模型
现在是按照图 13.8 中的步骤 2A 进行操作的时候了。我们已经对分割理论和 U-Net 的历史有了足够的了解;现在我们想要更新我们的代码,从模型开始。我们不再只输出一个给出真或假的二进制分类,而是集成一个 U-Net,以获得一个能够为每个像素输出概率的模型:也就是执行分割。我们不打算从头开始实现自定义 U-Net 分割模型,而是打算从 GitHub 上的一个开源存储库中适用一个现有的实现。
github.com/jvanvugt/pytorch-unet 上的 U-Net 实现似乎很好地满足我们的需求。它是 MIT 许可的(版权 2018 Joris),包含在一个单独的文件中,并且有许多参数选项供我们调整。该文件包含在我们的代码存储库中的 util/unet.py 中,同时附有原始存储库的链接和使用的完整许可证文本。
注意 虽然对于个人项目来说这不是太大问题,但重要的是要注意你为项目使用的开源软件附带的许可条款。MIT 许可证是最宽松的开源许可证之一,但它仍对使用 MIT 许可的代码的用户有要求!还要注意,即使作者在公共论坛上发布他们的作品,他们仍保留版权(是的,即使在 GitHub 上也是如此),如果他们没有包含许可证,这并不意味着该作品属于公共领域。恰恰相反!这意味着你没有任何使用代码的许可,就像你没有权利从图书馆借来的书中全文复制一样。
我们建议花一些时间检查代码,并根据你到目前为止建立的知识,识别体系结构中反映在代码中的构建模块。你能发现跳跃连接吗?对你来说一个特别有价值的练习是通过查看代码绘制显示模型布局的图表。
现在我们找到了一个符合要求的 U-Net 实现,我们需要调整它以使其适用于我们的需求。一般来说,留意可以使用现成解决方案的情况是一个好主意。重要的是要了解存在哪些模型,它们是如何实现和训练的,以及是否可以拆解和应用到我们当前正在进行的项目中。虽然这种更广泛的知识是随着时间和经验而来的,但现在开始建立这个工具箱是一个好主意。
13.4.1 将现成模型调整为我们的项目
现在我们将对经典 U-Net 进行一些更改,并在此过程中加以证明。对你来说一个有用的练习是比较原始模型和经过调整后的模型的结果,最好一次删除一个以查看每个更改的影响(这在研究领域也称为消融研究)。

图 13.8 本章大纲,重点关注我们分割模型所需的更改
首先,我们将通过批量归一化将输入传递。这样,我们就不必在数据集中自己归一化数据;更重要的是,我们将获得在单个批次上估计的归一化统计数据(读取均值和标准差)。这意味着当某个批次由于某种原因变得单调时–也就是说,当所有馈送到网络中的 CT 裁剪中没有什么可见时–它将被更强烈地缩放。每个时期随机选择批次中的样本将最大程度地减少单调样本最终进入全单调批次的机会,从而过度强调这些单调样本。
其次,由于输出值是不受限制的,我们将通过一个 nn.Sigmoid 层将输出传递以将输出限制在 [0, 1] 范围内。第三,我们将减少模型允许使用的总深度和滤波器数量。虽然这有点超前,但使用标准参数的模型容量远远超过我们的数据集大小。这意味着我们不太可能找到一个与我们确切需求匹配的预训练模型。最后,尽管这不是一种修改,但重要的是要注意我们的输出是单通道,输出的每个像素表示模型估计该像素是否属于结节的概率。
通过实现一个具有三个属性的模型来简单地包装 U-Net:分别是我们想要添加的两个特征和 U-Net 本身–我们可以像在这里处理任何预构建模块一样对待。我们还将把收到的任何关键字参数传递给 U-Net 构造函数。
列表 13.1 model.py:17,class UNetWrapper
class UNetWrapper(nn.Module):def __init__(self, **kwargs): # ❶super().__init__()self.input_batchnorm = nn.BatchNorm2d(kwargs['in_channels']) # ❷self.unet = UNet(**kwargs) # ❸self.final = nn.Sigmoid()self._init_weights() # ❹
❶ kwarg 是一个包含传递给构造函数的所有关键字参数的字典。
❷ BatchNorm2d 要求我们指定输入通道的数量,我们从关键字参数中获取。
❸ U-Net:这里包含的是一个小细节,但它确实在发挥作用。
❹ 就像第十一章中的分类器一样,我们使用我们自定义的权重初始化。该函数已复制,因此我们不会再次显示代码。
forward方法是一个同样简单的序列。我们可以使用nn.Sequential的实例,就像我们在第八章中看到的那样,但为了代码的清晰度和堆栈跟踪的清晰度,我们在这里明确说明。
第 13.2 节 model.py:50, UNetWrapper.forward
def forward(self, input_batch):bn_output = self.input_batchnorm(input_batch)un_output = self.unet(bn_output)fn_output = self.final(un_output)return fn_output
请注意,我们在这里使用nn.BatchNorm2d。这是因为 U-Net 基本上是一个二维分割模型。我们可以调整实现以使用 3D 卷积,以便跨切片使用信息。直接实现的内存使用量将大大增加:也就是说,我们将不得不分割 CT 扫描。此外,Z 方向的像素间距比平面方向大得多,这使得结节不太可能跨越多个切片存在。这些考虑因素使得我们的目的不太吸引人的完全 3D 方法。相反,我们将调整我们的 3D 数据,一次对一个切片进行分割,提供相邻切片的上下文(例如,随着相邻切片的出现,检测到明亮的块确实是血管变得更容易)。由于我们仍然坚持以 2D 形式呈现数据,我们将使用通道来表示相邻切片。我们对第三维的处理类似于我们在第七章中将全连接模型应用于图像的方式:模型将不得不重新学习我们沿轴向丢弃的邻接关系,但对于模型来说这并不困难,尤其是考虑到由于目标结构的小尺寸而给出的上下文切片数量有限。
13.5 更新用于分割的数据集
本章的源数据保持不变:我们正在使用 CT 扫描和有关它们的注释数据。但是我们的模型期望输入和输出的形式与以前不同。正如我们在图 13.9 的第 2B 步骤中所暗示的,我们以前的数据集生成了 3D 数据,但现在我们需要生成 2D 数据。
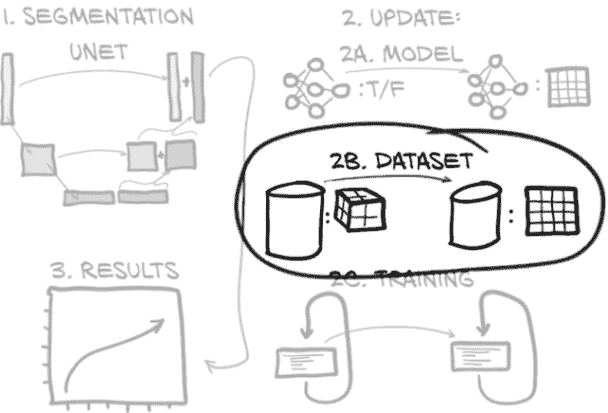
图 13.9 本章概述,重点关注我们分割数据集所需的变化
原始 U-Net 实现没有使用填充卷积,这意味着虽然输出分割地图比输入小,但输出的每个像素都具有完全填充的感受野。用于确定该输出像素的所有输入像素都没有填充、虚构或不完整。因此,原始 U-Net 的输出将完全平铺,因此它可以与任何大小的图像一起使用(除了输入图像的边缘,那里将缺少一些上下文)。
对于我们的问题采用相同的像素完美方法存在两个问题。第一个与卷积和下采样之间的交互有关,第二个与我们的数据性质是三维的有关。
13.5.1 U-Net 具有非常具体的输入尺寸要求
第一个问题是 U-Net 的输入和输出补丁的大小非常具体。为了使每个卷积线的两个像素损失在下采样之前和之后对齐(特别是考虑到在较低分辨率处进一步卷积收缩),只有某些输入尺寸才能起作用。U-Net 论文使用了 572×572 的图像补丁,导致了 388×388 的输出地图。输入图像比我们的 512×512 CT 切片大,输出则小得多!这意味着靠近 CT 扫描切片边缘的任何结节都不会被分割。尽管在处理非常大的图像时这种设置效果很好,但对于我们的用例来说并不理想。
我们将通过将 U-Net 构造函数的padding标志设置为True来解决这个问题。这意味着我们可以使用任何大小的输入图像,并且我们将得到相同大小的输出。我们可能会在图像边缘附近失去一些保真度,因为位于那里的像素的感受野将包括已被人为填充的区域,但这是我们决定接受的妥协。
13.5.2 3D 与 2D 数据的 U-Net 权衡
第二个问题是我们的 3D 数据与 U-Net 的 2D 预期输入不完全对齐。简单地将我们的 512×512×128 图像输入到转换为 3D 的 U-Net 类中是行不通的,因为我们会耗尽 GPU 内存。每个图像是 29×29×27,每个体素 22 字节。U-Net 的第一层是 64 个通道,或 26。这是 9 + 9 + 7 + 2 + 6 的指数= 33,或 8 GB 仅用于第一个卷积层。有两个卷积层(16 GB);然后每次下采样都会减半分辨率但加倍通道,这是第一个下采样后每层另外 2 GB(记住,减半分辨率会导致数据减少八分之一,因为我们处理的是 3D 数据)。因此,甚至在我们到达第二次下采样之前,我们就已经达到了 20 GB,更不用说模型上采样端或处理自动梯度的任何内容了。
注意 有许多巧妙和创新的方法可以解决这些问题,我们绝不认为这是唯一可行的方法。⁶ 我们认为这种方法是在这本书中我们项目所需的水平上完成工作的最简单方法之一。我们宁愿保持简单,这样我们就可以专注于基本概念;聪明的东西可以在你掌握基础知识后再来。
如预期的那样,我们不会尝试在 3D 中进行操作,而是将每个切片视为一个 2D 分割问题,并通过提供相邻切片作为单独的通道来绕过第三维中的上下文问题。我们的主要通道不再是我们从照片图像中熟悉的“红色”,“绿色”和“蓝色”通道,而是“上面两个切片”,“上面一个切片”,“我们实际分割的切片”,“下面一个切片”等。
然而,这种方法并非没有权衡。当表示为通道时,我们失去了切片之间的直接空间关系,因为所有通道将被卷积核线性组合,没有它们相隔一两个切片,上下的概念。我们还失去了来自真正的 3D 分割的深度维度中更广泛的感受野。由于 CT 切片通常比行和列的分辨率厚,我们获得的视野比起初看起来要宽一些,这应该足够了,考虑到结节通常跨越有限数量的切片。
要考虑的另一个方面,对于当前和完全 3D 方法都相关的是,我们现在忽略了确切的切片厚度。这是我们的模型最终将不得不学会对抗的东西,通过呈现具有不同切片间距的数据。
一般来说,没有一个简单的流程图或经验法则可以提供关于做出哪些权衡或给定一组妥协是否太多的标准答案。然而,仔细的实验至关重要,系统地测试假设之后的假设可以帮助缩小哪些变化和方法对手头问题有效的范围。虽然在等待最后一组结果计算时进行一连串的更改很诱人,但要抵制这种冲动。
这一点非常重要:不要同时测试多个修改。有很高的机会其中一个改变会与另一个产生不良互动,你将没有坚实的证据表明任何一个值得进一步调查。说了这么多,让我们开始构建我们的分割数据集。
13.5.3 构建地面真实数据
我们需要解决的第一件事是我们的人工标记的训练数据与我们希望从模型中获得的实际输出之间存在不匹配。我们有注释点,但我们想要一个逐体素掩模,指示任何给定的体素是否属于结节。我们将不得不根据我们拥有的数据构建该掩模,然后进行一些手动检查,以确保构建掩模的例程表现良好。
在规模上验证这些手动构建的启发式方法可能会很困难。当涉及确保每个结节都得到适当处理时,我们不会尝试做任何全面的工作。如果我们有更多资源,像“与(或支付)某人合作创建和/或手动验证所有内容”这样的方法可能是一个选择,但由于这不是一个资金充足的努力,我们将依靠检查少量样本并使用非常简单的“输出看起来合理吗?”方法。
为此,我们将设计我们的方法和我们的 API,以便轻松调查我们的算法正在经历的中间步骤。虽然这可能导致稍微笨重的函数调用返回大量中间值的元组,但能够轻松获取结果并在笔记本中绘制它们使得这种笨重值得。
边界框
我们将从将我们拥有的结节位置转换为覆盖整个结节的边界框开始(请注意,我们只会为实际结节这样做)。如果我们假设结节位置大致位于肿块中心,我们可以沿着所有三个维度从该点向外追踪,直到遇到低密度的体素,表明我们已经到达了主要充满空气的正常肺组织。让我们在图 13.10 中遵循这个算法。
图 13.10 围绕肺结节找到边界框的算法
我们从我们的搜索起点(图中的 O)开始在注释的结节中心的体素处。然后我们检查沿着列轴的原点相邻体素的密度,用问号(?)标记。由于两个检查的体素都包含密集组织,显示为浅色,我们继续我们的搜索。在将列搜索距离增加到 2 后,我们发现左侧的体素密度低于我们的阈值,因此我们在 2 处停止搜索。
接下来,我们在行方向上执行相同的搜索。同样,我们从原点开始,这次我们向上下搜索。当我们的搜索距离变为 3 时,在上下搜索位置都遇到了低密度的体素。我们只需要一个就可以停止我们的搜索!
我们将跳过在第三维度中显示搜索。我们最终的边界框宽度为五个体素,高度为七个体素。这是在代码中的索引方向的样子。
代码清单 13.3 dsets.py:131,Ct.buildAnnotationMask
center_irc = xyz2irc(candidateInfo_tup.center_xyz, # ❶self.origin_xyz,self.vxSize_xyz,self.direction_a,
)
ci = int(center_irc.index) # ❷
cr = int(center_irc.row)
cc = int(center_irc.col)index_radius = 2
try:while self.hu_a[ci + index_radius, cr, cc] > threshold_hu and \self.hu_a[ci - index_radius, cr, cc] > threshold_hu: # ❸index_radius += 1
except IndexError: # ❹index_radius -= 1
❶ 这里的 candidateInfo_tup 与我们之前看到的相同:由 getCandidateInfoList 返回。
❷ 获取中心体素的索引,这是我们的起点
❸ 先前描述的搜索
❹ 超出张量大小的索引的安全网
我们首先获取中心数据,然后在while循环中进行搜索。作为一个轻微的复杂性,我们的搜索可能超出张量的边界。我们对这种情况并不太担心,也很懒,所以我们只捕获索引异常。
请注意,当密度降低到阈值以下时,我们停止增加非常粗略的radius值,因此我们的边界框应包含低密度组织的一个体素边界(至少在一侧;由于结节可能与肺壁等密度较高的组织相邻,当我们在任一侧遇到空气时,我们必须停止搜索)。由于我们将center_index + index_radius和center_index - index_radius与该阈值进行比较,因此该一个体素边界仅存在于最接近结节位置的边缘。这就是为什么我们需要这些位置相对居中。由于一些结节与肺和肌肉或骨骼等密度较高的组织之间的边界相邻,我们不能独立追踪每个方向,因为一些边缘最终会远离实际结节。
然后,我们使用row_radius和col_radius重复相同的半径扩展过程(为简洁起见,此代码被省略)。完成后,我们可以将边界框掩码数组中的一个框设置为True(我们很快就会看到boundingBox_ary的定义;这并不令人惊讶)。
好的,让我们将所有这些封装在一个函数中。我们遍历所有结节。对于每个结节,我们执行之前显示的搜索(我们在代码清单 13.4 中省略了)。然后,在一个布尔张量boundingBox_a中,我们标记我们找到的边界框。
循环结束后,我们通过取边界框掩码和密度高于-700 HU(或 0.3 g/cc)的组织之间的交集来进行一些清理。这将剪裁掉我们的盒子的角(至少是那些不嵌入在肺壁中的盒子),使其更符合结节的轮廓。
代码清单 13.4 dsets.py:127,Ct.buildAnnotationMask
def buildAnnotationMask(self, positiveInfo_list, threshold_hu = -700):boundingBox_a = np.zeros_like(self.hu_a, dtype=np.bool) # ❶for candidateInfo_tup in positiveInfo_list: # ❷# ... line 169boundingBox_a[ci - index_radius: ci + index_radius + 1,cr - row_radius: cr + row_radius + 1,cc - col_radius: cc + col_radius + 1] = True # ❸mask_a = boundingBox_a & (self.hu_a > threshold_hu) # ❹return mask_a
❶ 从与 CT 相同大小的全 False 张量开始
❷ 遍历结节。作为我们只查看结节的提醒,我们称之为 positiveInfo_list。
❸ 在获取结节半径后(搜索本身被省略了),我们标记边界框。
❹ 将掩码限制为高于我们密度阈值的体素
让我们看一下图 13.11,看看这些掩码在实践中是什么样子。完整彩色图像可以在 p2ch13_explore_data.ipynb 笔记本中找到。

图 13.11 ct.positive_mask中突出显示的三个结节,白色标记
右下角的结节掩码展示了我们矩形边界框方法的局限性,包括部分肺壁。这当然是我们可以修复的问题,但由于我们还没有确信这是我们时间和注意力的最佳利用方式,所以我们暂时让它保持原样。接下来,我们将继续将此掩码添加到我们的 CT 类中。
在 CT 初始化期间调用掩码创建
现在我们可以将结节信息元组列表转换为与 CT 形状相同的二进制“这是一个结节吗?”掩码,让我们将这些掩码嵌入到我们的 CT 对象中。首先,我们将我们的候选人筛选为仅包含结节的列表,然后我们将使用该列表构建注释掩码。最后,我们将收集具有至少一个结节掩码体素的唯一数组索引集。我们将使用这些数据来塑造我们用于验证的数据。
代码清单 13.5 dsets.py:99,Ct.__init__
def __init__(self, series_uid):# ... line 116candidateInfo_list = getCandidateInfoDict()[self.series_uid]self.positiveInfo_list = [candidate_tupfor candidate_tup in candidateInfo_listif candidate_tup.isNodule_bool # ❶]self.positive_mask = self.buildAnnotationMask(self.positiveInfo_list)self.positive_indexes = (self.positive_mask.sum(axis=(1,2)) # ❷.nonzero()[0].tolist()) # ❸
❶ 用于结节的过滤器
❷ 给出一个 1D 向量(在切片上)中每个切片中标记的掩码体素数量
❸ 获取具有非零计数的掩码切片的索引,我们将其转换为列表
敏锐的眼睛可能已经注意到了getCandidateInfoDict函数。定义并不令人惊讶;它只是getCandidateInfoList函数中相同信息的重新表述,但是预先按series_uid分组。
代码清单 13.6 dsets.py:87
@functools.lru_cache(1) # ❶
def getCandidateInfoDict(requireOnDisk_bool=True):candidateInfo_list = getCandidateInfoList(requireOnDisk_bool)candidateInfo_dict = {}for candidateInfo_tup in candidateInfo_list:candidateInfo_dict.setdefault(candidateInfo_tup.series_uid,[]).append(candidateInfo_tup) # ❷return candidateInfo_dict
❶ 这对于避免 Ct init 成为性能瓶颈很有用。
❷ 获取字典中系列 UID 的候选人列表,如果找不到,则默认为一个新的空列表。然后将当前的 candidateInfo_tup 附加到其中。
缓存掩模的块以及 CT
在早期章节中,我们缓存了围绕结节候选项中心的 CT 块,因为我们不想每次想要 CT 的小块时都读取和解析整个 CT 的数据。我们希望对我们的新的 positive _mask 也做同样的处理,因此我们还需要从我们的 Ct.getRawCandidate 函数中返回它。这需要额外的一行代码和对 return 语句的编辑。
列表 13.7 dsets.py:178, Ct.getRawCandidate
def getRawCandidate(self, center_xyz, width_irc):center_irc = xyz2irc(center_xyz, self.origin_xyz, self.vxSize_xyz,self.direction_a)slice_list = []# ... line 203ct_chunk = self.hu_a[tuple(slice_list)]pos_chunk = self.positive_mask[tuple(slice_list)] # ❶return ct_chunk, pos_chunk, center_irc # ❷
❶ 新添加的
❷ 这里返回了新值
这将通过 getCtRawCandidate 函数缓存到磁盘,该函数打开 CT,获取指定的原始候选项,包括结节掩模,并在返回 CT 块、掩模和中心信息之前剪裁 CT 值。
列表 13.8 dsets.py:212
@raw_cache.memoize(typed=True)
def getCtRawCandidate(series_uid, center_xyz, width_irc):ct = getCt(series_uid)ct_chunk, pos_chunk, center_irc = ct.getRawCandidate(center_xyz,width_irc)ct_chunk.clip(-1000, 1000, ct_chunk)return ct_chunk, pos_chunk, center_irc
prepcache 脚本为我们预先计算并保存所有这些值,帮助保持训练速度。
清理我们的注释数据
我们在本章还要处理的另一件事是对我们的注释数据进行更好的筛选。事实证明,candidates.csv 中列出的几个候选项出现了多次。更有趣的是,这些条目并不是彼此的完全重复。相反,原始的人类注释在输入文件之前并没有经过充分的清理。它们可能是关于同一结节在不同切片上的注释,这甚至可能对我们的分类器有益。
在这里我们将进行一些简化,并提供一个经过清理的 annotation.csv 文件。为了完全了解这个清理文件的来源,您需要知道 LUNA 数据集源自另一个名为肺部图像数据库协会图像集(LIDC-IDRI)的数据集,并包含来自多名放射科医生的详细注释信息。我们已经完成了获取原始 LIDC 注释、提取结节、去重并将它们保存到文件 /data/part2/luna/annotations_with_malignancy.csv 的工作。
有了那个文件,我们可以更新我们的 getCandidateInfoList 函数,从我们的新注释文件中提取结节。首先,我们遍历实际结节的新注释。使用 CSV 读取器,¹⁰我们需要将数据转换为适当的类型,然后将它们放入我们的 CandidateInfoTuple 数据结构中。
列表 13.9 dsets.py:43, def getCandidateInfoList
candidateInfo_list = []
with open('data/part2/luna/annotations_with_malignancy.csv', "r") as f:for row in list(csv.reader(f))[1:]: # ❶series_uid = row[0]annotationCenter_xyz = tuple([float(x) for x in row[1:4]])annotationDiameter_mm = float(row[4])isMal_bool = {'False': False, 'True': True}[row[5]]candidateInfo_list.append( # ❷CandidateInfoTuple(True, # ❸True, # ❹isMal_bool,annotationDiameter_mm,series_uid,annotationCenter_xyz,))
❶ 对于注释文件中表示一个结节的每一行,…
❷ … 我们向我们的列表添加一条记录。
❸ isNodule_bool
❹ hasAnnotation_bool
类似地,我们像以前一样遍历 candidates.csv 中的候选项,但这次我们只使用非结节。由于这些不是结节,结节特定信息将只填充为 False 和 0。
列表 13.10 dsets.py:62, def getCandidateInfoList
with open('data/part2/luna/candidates.csv', "r") as f:for row in list(csv.reader(f))[1:]: # ❶series_uid = row[0]# ... line 72if not isNodule_bool: # ❷candidateInfo_list.append( # ❸CandidateInfoTuple(False, # ❹False, # ❺False, # ❻0.0,series_uid,candidateCenter_xyz,))
❶ 对于候选文件中的每一行…
❷ … 但只有非结节(我们之前有其他的)…
❸ … 我们添加一个候选记录。
❹ isNodule_bool
❺ hasAnnotation_bool
❻ isMal_bool
除了添加hasAnnotation_bool和isMal_bool标志(我们在本章不会使用),新的注释将插入并可像旧的一样使用。
注意 您可能会想知道为什么我们到现在才讨论 LIDC。事实证明,LIDC 已经围绕基础数据集构建了大量工具,这些工具是特定于 LIDC 的。您甚至可以从 PyLIDC 获取现成的掩模。这些工具呈现了一个有些不切实际的图像,说明了给定数据集可能具有的支持类型,因为 LIDC 的支持异常充分。我们对 LUNA 数据所做的工作更具典型性,并提供更好的学习,因为我们花时间操纵原始数据,而不是学习别人设计的 API。
13.5.4 实现 Luna2dSegmentationDataset
与之前的章节相比,我们在本章将采用不同的方法来进行训练和验证集的划分。我们将有两个类:一个作为适用于验证数据的通用基类,另一个作为基类的子类,用于训练集,具有随机化和裁剪样本。
尽管这种方法在某些方面有些复杂(例如,类并不完全封装),但实际上简化了选择随机训练样本等逻辑。它还非常清楚地显示了哪些代码路径影响训练和验证,哪些是仅与训练相关的。如果没有这一点,我们发现一些逻辑可能会以难以跟踪的方式嵌套或交织在一起。这很重要,因为我们的训练数据与验证数据看起来会有很大不同!
注意 其他类别的安排也是可行的;例如,我们考虑过完全分开两个独立的Dataset子类。标准软件工程设计原则适用,因此尽量保持结构相对简单,尽量不要复制粘贴代码,但不要发明复杂的框架来防止重复三行代码。
我们生成的数据将是具有多个通道的二维 CT 切片。额外的通道将保存相邻的 CT 切片。回想图 4.2,这里显示为图 13.12;我们可以看到每个 CT 扫描切片都可以被视为二维灰度图像。
图 13.12 CT 扫描的每个切片代表空间中的不同位置。
我们如何组合这些切片取决于我们。对于我们分类模型的输入,我们将这些切片视为数据的三维数组,并使用三维卷积来处理每个样本。对于我们的分割模型,我们将把每个切片视为单个通道,生成一个多通道的二维图像。这样做意味着我们将每个 CT 扫描切片都视为 RGB 图像的颜色通道,就像我们在图 4.1 中看到的那样,这里重复显示为图 13.13。CT 的每个输入切片将被堆叠在一起,并像任何其他二维图像一样被消耗。我们堆叠的 CT 图像的通道不会对应颜色,但是二维卷积并不要求输入通道是颜色,所以这样做没问题。
图 13.13 摄影图像的每个通道代表不同的颜色。
对于验证,我们需要为每个具有正面掩模条目的 CT 切片生成一个样本,对于我们拥有的每个验证 CT。由于不同的 CT 扫描可能具有不同的切片计数,我们将引入一个新函数,将每个 CT 扫描及其正面掩模的大小缓存到磁盘上。我们需要这样做才能快速构建完整的验证集大小,而无需在Dataset初始化时加载每个 CT。我们将继续使用与之前相同的缓存装饰器。填充这些数据也将在 prepcache.py 脚本中进行,我们必须在开始任何模型训练之前运行一次。
列表 13.11 dsets.py:220
@raw_cache.memoize(typed=True)
def getCtSampleSize(series_uid):ct = Ct(series_uid)return int(ct.hu_a.shape[0]), ct.positive_indexes
Luna2dSegmentationDataset.__init__方法的大部分处理与我们之前看到的类似。我们有一个新的contextSlices_count参数,以及类似于我们在第十二章介绍的augmentation_dict。
指示这是否应该是训练集还是验证集的标志处理需要有所改变。由于我们不再对单个结节进行训练,我们将不得不将整个系列列表作为一个整体划分为训练集和验证集。这意味着整个 CT 扫描以及其中包含的所有结节候选者将分别位于训练集或验证集中。
列表 13.12 dsets.py:242, .__init__
if isValSet_bool:assert val_stride > 0, val_strideself.series_list = self.series_list[::val_stride] # ❶assert self.series_list
elif val_stride > 0:del self.series_list[::val_stride] # ❷assert self.series_list
❶ 从包含所有系列的系列列表开始,我们仅保留每个val_stride元素,从 0 开始。
❷ 如果我们在训练中,我们会删除每个val_stride元素。
谈到验证,我们将有两种不同的模式可以验证我们的训练。首先,当fullCt_bool为True时,我们将使用 CT 中的每个切片作为我们的数据集。当我们评估端到端性能时,这将非常有用,因为我们需要假装我们对 CT 没有任何先前信息。我们将在训练期间使用第二种模式进行验证,即当我们限制自己只使用具有阳性掩模的 CT 切片时。
由于我们现在只想考虑特定的 CT 序列,我们循环遍历我们想要的序列 UID,并获取总切片数和有趣切片的列表。
列表 13.13 dsets.py:250, .__init__
self.sample_list = []
for series_uid in self.series_list:index_count, positive_indexes = getCtSampleSize(series_uid)if self.fullCt_bool:self.sample_list += [(series_uid, slice_ndx) # ❶for slice_ndx in range(index_count)]else:self.sample_list += [(series_uid, slice_ndx) # ❷for slice_ndx in positive_indexes]
❶ 在这里,我们通过使用范围扩展样本列表中的每个 CT 切片…
❷ … 而在这里我们只取有趣的切片。
以这种方式进行将保持我们的验证相对快速,并确保我们获得真阳性和假阴性的完整统计数据,但我们假设其他切片的假阳性和真阴性统计数据与我们在验证期间评估的统计数据相对类似。
一旦我们有了要使用的series_uid值集合,我们可以将我们的candidateInfo_list过滤为仅包含series_uid包含在该系列集合中的结节候选者。此外,我们将创建另一个仅包含阳性候选者的列表,以便在训练期间,我们可以将它们用作我们的训练样本。
列表 13.14 dsets.py:261, .__init__
self.candidateInfo_list = getCandidateInfoList() # ❶series_set = set(self.series_list) # ❷
self.candidateInfo_list = [cit for cit in self.candidateInfo_listif cit.series_uid in series_set] # ❸self.pos_list = [nt for nt in self.candidateInfo_listif nt.isNodule_bool] # ❹
❶ 这是缓存的。
❷ 创建一个集合以加快查找速度。
❸ 过滤掉不在我们集合中的系列的候选者
❹ 对于即将到来的数据平衡,我们需要一个实际结节的列表。
我们的__getitem__实现也会更加复杂,通过将大部分逻辑委托给一个函数,使得检索特定样本变得更容易。在其核心,我们希望以三种不同形式检索我们的数据。首先,我们有 CT 的完整切片,由series_uid和ct_ndx指定。其次,我们有围绕结节的裁剪区域,这将用于训练数据(我们稍后会解释为什么我们不使用完整切片)。最后,DataLoader将通过整数ndx请求样本,数据集将根据是训练还是验证来返回适当的类型。
基类或子类__getitem__函数将根据需要从整数ndx转换为完整切片或训练裁剪。如前所述,我们的验证集的__getitem__只是调用另一个函数来执行真正的工作。在此之前,它将索引包装到样本列表中,以便将 epoch 大小(由数据集长度给出)与实际样本数量分离。
列表 13.15 dsets.py:281, .__getitem__
def __getitem__(self, ndx):series_uid, slice_ndx = self.sample_list[ndx % len(self.sample_list)] # ❶return self.getitem_fullSlice(series_uid, slice_ndx)
❶ 模运算进行包装。
这很容易,但我们仍然需要实现getItem_fullSlice方法中的有趣功能。
列表 13.16 dsets.py:285, .getitem_fullSlice
def getitem_fullSlice(self, series_uid, slice_ndx):ct = getCt(series_uid)ct_t = torch.zeros((self.contextSlices_count * 2 + 1, 512, 512)) # ❶start_ndx = slice_ndx - self.contextSlices_countend_ndx = slice_ndx + self.contextSlices_count + 1for i, context_ndx in enumerate(range(start_ndx, end_ndx)):context_ndx = max(context_ndx, 0) # ❷context_ndx = min(context_ndx, ct.hu_a.shape[0] - 1)ct_t[i] = torch.from_numpy(ct.hu_a[context_ndx].astype(np.float32))ct_t.clamp_(-1000, 1000)pos_t = torch.from_numpy(ct.positive_mask[slice_ndx]).unsqueeze(0)return ct_t, pos_t, ct.series_uid, slice_ndx
❶ 预先分配输出
❷ 当我们超出 ct_a 的边界时,我们复制第一个或最后一个切片。
将函数分割成这样可以让我们始终向数据集询问特定切片(或裁剪的训练块,我们将在下一节中看到)通过序列 UID 和位置索引。仅对于整数索引,我们通过__getitem__进行,然后从(打乱的)列表中获取样本。
除了ct_t和pos_t之外,我们返回的元组的其余部分都是我们包含用于调试和显示的信息。我们在训练中不需要任何这些信息。
13.5.5 设计我们的训练和验证数据
在我们开始实现训练数据集之前,我们需要解释为什么我们的训练数据看起来与验证数据不同。我们将不再使用完整的 CT 切片,而是将在我们的正候选项周围(实际上是结节候选项)训练 64×64 的裁剪。这些 64×64 的补丁将随机从以结节为中心的 96×96 裁剪中取出。我们还将在两个方向上包括三个切片的上下文作为我们 2D 分割的附加“通道”。
我们这样做是为了使训练更加稳定,收敛更快。我们之所以知道这样做是因为我们尝试在整个 CT 切片上进行训练,但我们发现结果令人不满意。经过一些实验,我们发现 64×64 的半随机裁剪方法效果不错,所以我们决定在书中使用这种方法。当你在自己的项目上工作时,你需要为自己做这种实验!
我们认为整个切片训练不稳定主要是由于类平衡问题。由于每个结节与整个 CT 切片相比非常小,我们又回到了上一章中摆脱的类似于大海捞针的情况,其中我们的正样本被负样本淹没。在这种情况下,我们谈论的是像素而不是结节,但概念是相同的。通过在裁剪上进行训练,我们保持了正像素数量不变,并将负像素数量减少了几个数量级。
因为我们的分割模型是像素到像素的,并且接受任意大小的图像,所以我们可以在具有不同尺寸的样本上进行训练和验证。验证使用相同的卷积和相同的权重,只是应用于更大的像素集(因此需要填充边缘数据的像素较少)。
这种方法的一个缺点是,由于我们的验证集包含数量级更多的负像素,我们的模型在验证期间将有很高的假阳性率。我们的分割模型有很多机会被欺骗!并且我们还将追求高召回率。我们将在第 13.6.3 节中更详细地讨论这一点。
13.5.6 实现 TrainingLuna2dSegmentationDataset
有了这个,让我们回到代码。这是训练集的__getitem__。它看起来就像验证集的一个,只是现在我们从pos_list中采样,并使用候选信息元组调用getItem_trainingCrop,因为我们需要系列和确切的中心位置,而不仅仅是切片。
代码清单 13.17 dsets.py:320,.__getitem__
def __getitem__(self, ndx):candidateInfo_tup = self.pos_list[ndx % len(self.pos_list)]return self.getitem_trainingCrop(candidateInfo_tup)
要实现getItem_trainingCrop,我们将使用一个类似于分类训练中使用的getCtRawCandidate函数。在这里,我们传入一个不同尺寸的裁剪,但该函数除了现在返回一个包含ct.positive_mask裁剪的额外数组外,没有改变。
我们将我们的pos_a限制在我们实际分割的中心切片上,然后构建我们的 96×96 给定的裁剪的 64×64 随机裁剪。一旦我们有了这些,我们返回一个与我们的验证数据集相同项目的元组。
代码清单 13.18 dsets.py:324,.getitem_trainingCrop
def getitem_trainingCrop(self, candidateInfo_tup):ct_a, pos_a, center_irc = getCtRawCandidate( # ❶candidateInfo_tup.series_uid,candidateInfo_tup.center_xyz,(7, 96, 96),)pos_a = pos_a[3:4] # ❷row_offset = random.randrange(0,32) # ❸col_offset = random.randrange(0,32)ct_t = torch.from_numpy(ct_a[:, row_offset:row_offset+64,col_offset:col_offset+64]).to(torch.float32)pos_t = torch.from_numpy(pos_a[:, row_offset:row_offset+64,col_offset:col_offset+64]).to(torch.long)slice_ndx = center_irc.indexreturn ct_t, pos_t, candidateInfo_tup.series_uid, slice_ndx
❶ 获取带有一点额外周围的候选项
❷ 保留第三维度的一个元素切片,这将是(单一的)输出通道。
❸ 使用 0 到 31 之间的两个随机数,我们裁剪 CT 和掩模。
你可能已经注意到我们的数据集实现中缺少数据增强。这一次我们将以稍有不同的方式处理:我们将在 GPU 上增强我们的数据。
13.5.7 在 GPU 上进行数据增强
在训练深度学习模型时的一个关键问题是避免训练管道中的瓶颈。嗯,这并不完全正确–总会有一个瓶颈。[¹²]
一些常见的瓶颈出现在以下情况:
-
在数据加载管道中,无论是在原始 I/O 中还是在将数据解压缩后。我们使用
diskcache库来解决这个问题。 -
在加载数据的 CPU 预处理中。这通常是数据归一化或增强。
-
在 GPU 上的训练循环中。这通常是我们希望瓶颈出现的地方,因为 GPU 的总体深度学习系统成本通常高于存储或 CPU。
-
瓶颈通常不太常见,有时可能是 CPU 和 GPU 之间的内存带宽。这意味着与发送的数据大小相比,GPU 的工作量并不大。
由于 GPU 在处理适合 GPU 的任务时可以比 CPU 快 50 倍,因此在 CPU 使用率变高时,通常有意义将这些任务从 CPU 移动到 GPU。特别是如果数据在此处理过程中被扩展;通过首先将较小的输入移动到 GPU,扩展的数据保持在 GPU 本地,使用的内存带宽较少。
在我们的情况下,我们将数据增强移到 GPU 上。这将使我们的 CPU 使用率较低,GPU 将轻松地承担额外的工作量。与其让 GPU 空闲等待 CPU 努力完成增强过程,不如让 GPU 忙于少量额外工作。
我们将通过使用第二个模型来实现这一点,这个模型与本书中迄今为止看到的所有nn.Module的子类类似。主要区别在于我们不感兴趣通过模型反向传播梯度,并且forward方法将执行完全不同的操作。由于我们在本章中处理的是 2D 数据,因此实际增强例程将进行一些轻微修改,但除此之外,增强将与我们在第十二章中看到的非常相似。该模型将消耗张量并产生不同的张量,就像我们实现的其他模型一样。
我们模型的__init__接受相同的数据增强参数–flip,offset等–这些参数在上一章中使用过,并将它们分配给self。
列表 13.19 model.py:56,class SegmentationAugmentation
class SegmentationAugmentation(nn.Module):def __init__(self, flip=None, offset=None, scale=None, rotate=None, noise=None):super().__init__()self.flip = flipself.offset = offset# ... line 64
我们的增强forward方法接受输入和标签,并调用构建transform_t张量,然后驱动我们的affine_grid和grid_sample调用。这些调用应该在第十二章中感到非常熟悉。
列表 13.20 model.py:68,SegmentationAugmentation.forward
def forward(self, input_g, label_g):transform_t = self._build2dTransformMatrix()transform_t = transform_t.expand(input_g.shape[0], -1, -1) # ❶transform_t = transform_t.to(input_g.device, torch.float32)affine_t = F.affine_grid(transform_t[:,:2], # ❷input_g.size(), align_corners=False)augmented_input_g = F.grid_sample(input_g,affine_t, padding_mode='border',align_corners=False)augmented_label_g = F.grid_sample(label_g.to(torch.float32),affine_t, padding_mode='border',align_corners=False) # ❸if self.noise:noise_t = torch.randn_like(augmented_input_g)noise_t *= self.noiseaugmented_input_g += noise_treturn augmented_input_g, augmented_label_g > 0.5 # ❹
❶ 请注意,我们正在增强 2D 数据。
❷ 变换的第一个维度是批处理,但我们只想要每个批处理项的 3×3 矩阵的前两行。
❸ 我们需要将相同的变换应用于 CT 和掩码,因此我们使用相同的网格。因为 grid_sample 仅适用于浮点数,所以我们在这里进行转换。
❹ 在返回之前,我们通过与 0.5 比较将掩码转换回布尔值。grid_sample 导致插值产生分数值。
现在我们知道了如何处理transform_t以获取我们的数据,让我们来看看实际创建我们使用的变换矩阵的_build2dTransformMatrix函数。
列表 13.21 model.py:90,._build2dTransformMatrix
def _build2dTransformMatrix(self):transform_t = torch.eye(3) # ❶for i in range(2): # ❷if self.flip:if random.random() > 0.5:transform_t[i,i] *= -1# ... line 108if self.rotate:angle_rad = random.random() * math.pi * 2 # ❸s = math.sin(angle_rad)c = math.cos(angle_rad)rotation_t = torch.tensor([ # ❹[c, -s, 0],[s, c, 0],[0, 0, 1]])transform_t @= rotation_t # ❺return transform_t
❶ 创建一个 3×3 矩阵,但我们稍后会删除最后一行。
❷ 再次,我们在这里增强 2D 数据。
❸ 以弧度形式取一个随机角度,范围为 0 … 2{pi}
❹ 2D 旋转的旋转矩阵,由第一个两个维度中的随机角度确定
❺ 使用 Python 矩阵乘法运算符将旋转应用于变换矩阵
除了处理 2D 数据的轻微差异外,我们的 GPU 数据增强代码看起来与我们的 CPU 数据增强代码非常相似。这很好,因为这意味着我们能够编写不太关心运行位置的代码。主要区别不在核心实现中:而是我们如何将该实现封装到nn.Module子类中。虽然我们一直认为模型是一种专门用于深度学习的工具,但这向我们展示了在 PyTorch 中,张量可以被用得更加普遍。在开始下一个项目时请记住这一点–使用 GPU 加速张量可以实现的事情范围相当广泛!
13.6 更新用于分割的训练脚本
我们有一个模型。我们有数据。我们需要使用它们,当图 13.14 的步骤 2C 建议我们应该用新数据训练我们的新模型时,你不会感到惊讶。
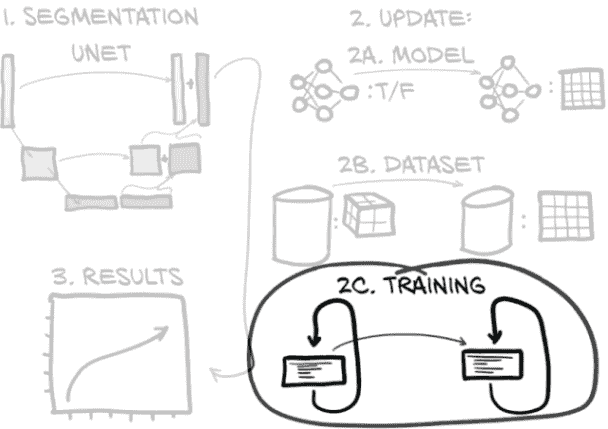
图 13.14 本章概述,重点关注我们训练循环所需的更改
为了更准确地描述训练模型的过程,我们将更新影响我们在第十二章获得的训练代码结果的三个方面:
-
我们需要实例化新模型(不足为奇)。
-
我们将引入一种新的损失函数:Dice 损失。
-
我们还将研究除了我们迄今使用的可敬的 SGD 之外的另一种优化器。我们将坚持使用一种流行的优化器,即 Adam。
但我们还将加强我们的记录工作,通过
-
将图像记录到 TensorBoard 以进行分割的可视检查
-
在 TensorBoard 中执行更多指标记录
-
根据验证结果保存我们最佳的模型
总的来说,训练脚本 p2ch13/training.py 与我们在第十二章用于分类训练的代码非常相似,比我们迄今为止看到的调整后的代码更相似。任何重大变化将在文本中介绍,但请注意一些细微调整被省略。要了解完整的故事,请查看源代码。
13.6.1 初始化我们的分割和数据增强模型
我们的initModel方法非常不足为奇。我们正在使用UNetWrapper类并为其提供我们的配置参数–我们很快将详细查看这些参数。此外,我们现在有了第二个用于数据增强的模型。就像以前一样,如果需要,我们可以将模型移动到 GPU,并可能使用DataParallel设置多 GPU 训练。我们在这里跳过这些管理任务。
列表 13.22 training.py:133, .initModel
def initModel(self):segmentation_model = UNetWrapper(in_channels=7,n_classes=1,depth=3,wf=4,padding=True,batch_norm=True,up_mode='upconv',)augmentation_model = SegmentationAugmentation(**self.augmentation_dict)# ... line 154return segmentation_model, augmentation_model
对于输入到UNet,我们有七个输入通道:3 + 3 上下文切片,以及一个是我们实际进行分割的焦点切片。我们有一个输出类指示这个体素是否是结节的一部分。depth参数控制 U 的深度;每个下采样操作将深度增加 1。使用wf=5意味着第一层将有2**wf == 32个滤波器,每个下采样都会翻倍。我们希望卷积进行填充,以便我们得到与输入相同大小的输出图像。我们还希望批量归一化在每个激活函数后面,我们的上采样函数应该是一个上卷积层,由nn.ConvTranspose2d实现(参见 util/unet.py,第 123 行)。
13.6.2 使用 Adam 优化器
Adam 优化器(arxiv.org/abs/1412.6980)是在训练模型时使用 SGD 的替代方案。Adam 为每个参数维护单独的学习率,并随着训练的进行自动更新该学习率。由于这些自动更新,通常在使用 Adam 时我们不需要指定非默认学习率,因为它会快速自行确定一个合理的学习率。
这是我们在代码中实例化Adam的方式。
列表 13.23 training.py:156, .initOptimizer
def initOptimizer(self):return Adam(self.segmentation_model.parameters())
一般认为 Adam 是开始大多数项目的合理优化器。通常有一种配置的随机梯度下降与 Nesterov 动量,可以胜过 Adam,但在为给定项目初始化 SGD 时找到正确的超参数可能会很困难且耗时。
有许多关于 Adam 的变体–AdaMax、RAdam、Ranger 等等–每种都有优点和缺点。深入研究这些细节超出了本书的范围,但我们认为了解这些替代方案的存在是重要的。我们将在第十三章中使用 Adam。
13.6.3 Dice 损失
Sørensen-Dice 系数(en.wikipedia.org/wiki/S%C3%B8rensen%E2%80%93Dice_coefficient),也称为Dice 损失,是分割任务常见的损失度量。使用 Dice 损失而不是每像素交叉熵损失的一个优点是,Dice 处理了只有整体图像的一小部分被标记为正的情况。正如我们在第十一章第 10 节中回忆的那样,当使用交叉熵损失时,不平衡的训练数据可能会有问题。这正是我们在这里的情况–大部分 CT 扫描不是结节。幸运的是,使用 Dice,这不会构成太大问题。
Sørensen-Dice 系数基于正确分割像素与预测像素和实际像素之和的比率。这些比率在图 13.15 中列出。在左侧,我们看到 Dice 分数的插图。它是两倍的联合区域(真正正例,有条纹)除以整个预测区域和整个地面实况标记区域的总和(重叠部分被计算两次)。右侧是高一致性/高 Dice 分数和低一致性/低 Dice 分数的两个典型示例。
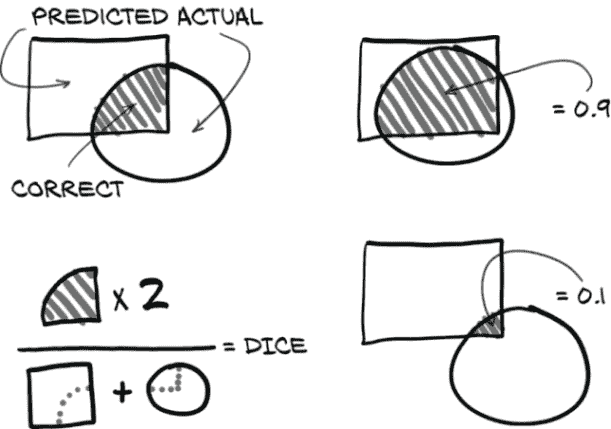
图 13.15 组成 Dice 分数的比率
这可能听起来很熟悉;这是我们在第十二章中看到的相同比率。我们基本上将使用每像素的 F1 分数!
注意 这是一个每像素的 F1 分数,其中“总体”是一个图像的像素。由于总体完全包含在一个训练样本中,我们可以直接用它进行训练。在分类情况下,F1 分数无法在单个小批量上计算,因此我们不能直接用它进行训练。
由于我们的label_g实际上是一个布尔掩码,我们可以将其与我们的预测相乘以获得我们的真正正例。请注意,我们在这里没有将prediction_devtensor视为布尔值。使用它定义的损失将不可微分。相反,我们将真正正例的数量替换为地面实况为 1 的像素的预测值之和。这收敛到与预测值接近 1 的相同结果,但有时预测值将是在 0.4 到 0.6 范围内的不确定预测。这些未决定的值将大致对我们的梯度更新产生相同的贡献,无论它们落在 0.5 的哪一侧。利用连续预测的 Dice 系数有时被称为软 Dice。
这里有一个小小的复杂性。由于我们希望最小化损失,我们将取我们的比率并从 1 中减去。这样做将反转我们损失函数的斜率,使得在高重叠情况下,我们的损失较低;而在低重叠情况下,它较高。以下是代码中的样子。
列表 13.24 training.py:315,.diceLoss
def diceLoss(self, prediction_g, label_g, epsilon=1):diceLabel_g = label_g.sum(dim=[1,2,3]) # ❶dicePrediction_g = prediction_g.sum(dim=[1,2,3])diceCorrect_g = (prediction_g * label_g).sum(dim=[1,2,3])diceRatio_g = (2 * diceCorrect_g + epsilon) \/ (dicePrediction_g + diceLabel_g + epsilon) # ❷return 1 - diceRatio_g # ❸
❶ 对除批处理维度以外的所有内容求和,以获取每个批处理项的正标记、(软)正检测和(软)正确正例
❷ Dice 比率。为了避免当我们意外地既没有预测也没有标签时出现问题,我们在分子和分母上都加 1。
❸ 为了将其转化为损失,我们取 1 - Dice 比率,因此较低的损失更好。
我们将更新我们的computeBatchLoss函数来调用self.diceLoss。两次。我们将为训练样本计算正常的 Dice 损失,以及仅计算label_g中包含的像素的 Dice 损失。通过将我们的预测(请记住,这些是浮点值)乘以标签(实际上是布尔值),我们将得到伪预测,这些预测使每个负像素“完全正确”(因为所有这些像素的值都乘以label_g中的假为零值)。唯一会产生损失的像素是假阴性像素(应该被预测为真,但实际上没有)。这将非常有帮助,因为召回率对我们的整体项目非常重要;毕竟,如果我们一开始就无法检测到肿瘤,我们就无法正确分类肿瘤!
列表 13.25 training.py:282,.computeBatchLoss
def computeBatchLoss(self, batch_ndx, batch_tup, batch_size, metrics_g,classificationThreshold=0.5):input_t, label_t, series_list, _slice_ndx_list = batch_tupinput_g = input_t.to(self.device, non_blocking=True) # ❶label_g = label_t.to(self.device, non_blocking=True)if self.segmentation_model.training and self.augmentation_dict: # ❷input_g, label_g = self.augmentation_model(input_g, label_g)prediction_g = self.segmentation_model(input_g) # ❸diceLoss_g = self.diceLoss(prediction_g, label_g) # ❹fnLoss_g = self.diceLoss(prediction_g * label_g, label_g)# ... line 313return diceLoss_g.mean() + fnLoss_g.mean() * 8 # ❺
❶ 转移到 GPU
❷ 根据需要进行数据增强,如果我们正在训练。在验证中,我们会跳过这一步。
❸ 运行分割模型…
❹ … 并应用我们精细的 Dice 损失
❺ 哎呀。这是什么?
让我们稍微谈谈我们在diceLoss_g .mean() + fnLoss_g.mean() * 8返回语句中所做的事情。
损失加权
在第十二章中,我们讨论了塑造我们的数据集,使得我们的类别不会严重失衡。这有助于训练收敛,因为每个批次中出现的正负样本能够相互抵消,模型必须学会区分它们以改进。我们通过将训练样本裁剪到包含较少非正像素的方式来近似相同的平衡;但是高召回率非常重要,我们需要确保在训练过程中提供反映这一事实的损失。
我们将使用加权损失,偏向于一类而不是另一类。通过将fnLoss_g乘以 8,我们的意思是正确预测我们的正像素总体比正确预测负像素总体重要八倍(九倍,如果计算diceLoss_g中的一个)。由于正掩模覆盖的区域远远小于整个 64 × 64 裁剪,这也意味着每个单独的正像素在反向传播时具有更大的影响力。
我们愿意在一般的 Dice 损失中放弃许多正确预测的负像素,以获得一个在假阴性损失中的正确像素。由于一般的 Dice 损失是假阴性损失的严格超集,可以进行交易的唯一正确像素是起初为真负的像素(所有真正的正像素已经包含在假阴性损失中,因此没有交易可进行)。
由于我们愿意牺牲大片真负像素以追求更好的召回率,我们通常会预期大量的假阳性。¹⁴ 我们这样做是因为召回率对我们的用例非常重要,我们宁愿有一些假阳性,也不愿有一个假阴性。
我们应该注意,这种方法仅在使用 Adam 优化器时有效。使用 SGD 时,过度预测会导致每个像素都返回为正。Adam 优化器微调学习率的能力意味着强调假阴性损失不会变得过于强大。
收集指标
由于我们将故意扭曲我们的数字以获得更好的召回率,让我们看看事情会变得多么倾斜。在我们的分类computeBatchLoss中,我们计算各种每个样本的值,用于度量等。我们还为整体分割结果计算类似的值。这些真正的正样本和其他指标以前是在logMetrics中计算的,但由于结果数据的大小(请记住,验证集中的每个单个 CT 切片是 25 万像素!),我们需要在computeBatchLoss函数中实时计算这些摘要统计信息。
列表 13.26 training.py:297, .computeBatchLoss
start_ndx = batch_ndx * batch_size
end_ndx = start_ndx + input_t.size(0)with torch.no_grad():predictionBool_g = (prediction_g[:, 0:1]> classificationThreshold).to(torch.float32) # ❶tp = ( predictionBool_g * label_g).sum(dim=[1,2,3]) # ❷fn = ((1 - predictionBool_g) * label_g).sum(dim=[1,2,3])fp = ( predictionBool_g * (~label_g)).sum(dim=[1,2,3])metrics_g[METRICS_LOSS_NDX, start_ndx:end_ndx] = diceLoss_g # ❸metrics_g[METRICS_TP_NDX, start_ndx:end_ndx] = tpmetrics_g[METRICS_FN_NDX, start_ndx:end_ndx] = fnmetrics_g[METRICS_FP_NDX, start_ndx:end_ndx] = fp
❶ 我们对预测进行阈值处理以获得“硬” Dice 但为后续乘法转换为浮点数。
❷ 计算真阳性、假阳性和假阴性与我们计算 Dice 损失时类似。
❸ 我们将我们的指标存储到一个大张量中以供将来参考。这是每个批次项目而不是批次平均值。
正如我们在本节开头讨论的,我们可以通过将我们的预测(或其否定)与我们的标签(或其否定)相乘来计算我们的真正阳性等。由于我们在这里并不太担心我们的预测的确切值(如果我们将像素标记为 0.6 或 0.9 并不重要–只要超过阈值,我们将其称为结节候选的一部分),我们将通过将其与我们的阈值 0.5 进行比较来创建predictionBool_g。
13.6.4 将图像导入 TensorBoard
在处理分割任务时的一个好处是输出可以很容易地以视觉方式表示。能够直观地看到我们的结果对于确定模型是否进展顺利(但可能需要更多训练)或者是否偏离轨道(因此我们需要停止继续浪费时间进行进一步训练)非常有帮助。我们可以将结果打包成图像的方式有很多种,也可以有很多种展示方式。TensorBoard 对这种数据有很好的支持,而且我们已经将 TensorBoard SummaryWriter 实例集成到我们的训练中,所以我们将使用 TensorBoard。让我们看看如何将所有内容连接起来。
我们将在我们的主应用程序类中添加一个logImages函数,并使用我们的训练和验证数据加载器调用它。在此过程中,我们将对我们的训练循环进行另一个更改:我们只会在第一个周期以及每第五个周期执行验证和图像记录。我们通过将周期数与一个新的常量validation_cadence进行比较来实现这一点。
在训练时,我们试图平衡几件事:
-
在不必等待太久的情况下大致了解我们的模型训练情况
-
大部分 GPU 周期用于训练,而不是验证
-
确保我们在验证集上表现良好
第一个意味着我们需要相对较短的周期,以便更频繁地调用logMetrics。然而,第二个意味着我们希望在调用doValidation之前训练相对较长的时间。第三个意味着我们需要定期调用doValidation,而不是在训练结束时或其他不可行的情况下只调用一次。通过仅在第一个周期以及每第五个周期执行验证,我们可以实现所有这些目标。我们可以及早获得训练进展的信号,大部分时间用于训练,并在进行过程中定期检查验证集。
列表 13.27 training.py:210, SegmentationTrainingApp.main
def main(self):# ... line 217self.validation_cadence = 5for epoch_ndx in range(1, self.cli_args.epochs + 1): # ❶# ... line 228trnMetrics_t = self.doTraining(epoch_ndx, train_dl) # ❷self.logMetrics(epoch_ndx, 'trn', trnMetrics_t) # ❸if epoch_ndx == 1 or epoch_ndx % self.validation_cadence == 0: # ❹# ... line 239self.logImages(epoch_ndx, 'trn', train_dl) # ❺self.logImages(epoch_ndx, 'val', val_dl)
❶ 我们最外层的循环,跨越各个周期
❷ 训练一个周期
❸ 在每个周期后记录来自训练的(标量)指标
❹ 仅在每个验证间隔的倍数时…
❺ …我们验证模型并记录图像。
我们没有一种单一正确的方式来构建我们的图像记录。我们将从训练集和验证集中各选取几个 CT 图像。对于每个 CT 图像,我们将选择 6 个均匀间隔的切片,端到端显示地面真实和我们模型的输出。我们之所以选择 6 个切片,仅仅是因为 TensorBoard 每次会显示 12 张图像,我们可以将浏览器窗口排列成一行标签图像在模型输出上方。以这种方式排列事物使得我们可以轻松地进行视觉比较,正如我们在图 13.16 中所看到的。

图 13.16 顶部行:训练的标签数据。底部行:分割模型的输出。
还请注意prediction图像上的小滑块点。该滑块将允许我们查看具有相同标签的先前版本的图像(例如 val/0_prediction_3,但在较早的时期)。当我们尝试调试某些内容或进行调整以实现特定结果时,能够查看我们的分割输出随时间变化的情况是有用的。随着训练的进行,TensorBoard 将限制从滑块中可查看的图像数量为 10,可能是为了避免用大量图像淹没浏览器。
生成此输出的代码首先从相关数据加载器中获取 12 个系列和每个系列的 6 个图像。
列表 13.28 training.py:326, .logImages
def logImages(self, epoch_ndx, mode_str, dl):self.segmentation_model.eval() # ❶images = sorted(dl.dataset.series_list)[:12] # ❷for series_ndx, series_uid in enumerate(images):ct = getCt(series_uid)for slice_ndx in range(6):ct_ndx = slice_ndx * (ct.hu_a.shape[0] - 1) // 5 # ❸sample_tup = dl.dataset.getitem_fullSlice(series_uid, ct_ndx)ct_t, label_t, series_uid, ct_ndx = sample_tup
❶ 将模型设置为评估模式
❷ 通过绕过数据加载器并直接使用数据集,获取(相同的)12 个 CT。系列列表可能已经被洗牌,所以我们进行排序。
❸ 选择 CT 中的六个等距切片
然后,我们将ct_t输入模型。这看起来非常像我们在computeBatchLoss中看到的;如果需要详情,请参阅 p2ch13/training.py。
一旦我们有了prediction_a,我们需要构建一个image_a来保存 RGB 值以供显示。我们使用np.float32值,需要在 0 到 1 的范围内。我们的方法会通过将各种图像和掩模相加,使数据在 0 到 2 的范围内,然后将整个数组乘以 0.5 将其恢复到正确的范围内。
列表 13.29 training.py:346, .logImages
ct_t[:-1,:,:] /= 2000
ct_t[:-1,:,:] += 0.5ctSlice_a = ct_t[dl.dataset.contextSlices_count].numpy()image_a = np.zeros((512, 512, 3), dtype=np.float32)
image_a[:,:,:] = ctSlice_a.reshape((512,512,1)) # ❶
image_a[:,:,0] += prediction_a & (1 - label_a)
image_a[:,:,0] += (1 - prediction_a) & label_a # ❷
image_a[:,:,1] += ((1 - prediction_a) & label_a) * 0.5 # ❸image_a[:,:,1] += prediction_a & label_a # ❹
image_a *= 0.5
image_a.clip(0, 1, image_a)
❶ 将 CT 强度分配给所有 RGB 通道,以提供灰度基础图像。
❷ 假阳性标记为红色,并叠加在图像上。
❸ 假阴性标记为橙色。
❹ 真阳性标记为绿色。
我们的目标是在半强度的灰度 CT 上叠加预测的结节(或更正确地说,结节候选)像素以各种颜色显示。我们将使用红色表示所有不正确的像素(假阳性和假阴性)。这主要是假阳性,我们不太关心(因为我们专注于召回率)。1 - label_a反转标签,乘以prediction_a给出我们只有预测像素不在候选结节中的像素。假阴性得到添加到绿色的半强度掩模,这意味着它们将显示为橙色(1.0 红和 0.5 绿在 RGB 中呈橙色)。每个正确预测的结节内像素都设置为绿色;因为我们正确预测了这些像素,不会添加红色,因此它们将呈现为纯绿色。
然后,我们将数据重新归一化到0...1范围并夹紧它(以防我们在这里开始显示增强数据,当噪声超出我们预期的 CT 范围时会导致斑点)。最后一步是将数据保存到 TensorBoard。
列表 13.30 training.py:361, .logImages
writer = getattr(self, mode_str + '_writer')
writer.add_image(f'{mode_str}/{series_ndx}_prediction_{slice_ndx}',image_a,self.totalTrainingSamples_count,dataformats='HWC',
)
这看起来与我们之前看到的writer.add_scalar调用非常相似。dataformats='HWC'参数告诉 TensorBoard 我们的图像轴的顺序将 RGB 通道作为第三个轴。请记住,我们的网络层经常指定输出为B × C × H × W,如果我们指定'CHW',我们也可以直接将数据放入 TensorBoard。
我们还想保存用于训练的地面真相,这将形成我们之前在图 13.16 中看到的 TensorBoard CT 切片的顶行。代码与我们刚刚看到的类似,我们将跳过它。如果您想了解详情,请查看 p2ch13/training.py。
13.6.5 更新我们的指标记录
为了让我们了解我们的表现如何,我们计算每个时期的指标:特别是真阳性、假阴性和假阳性。以下列表所做的事情不会特别令人惊讶。
列表 13.31 training.py:400, .logMetrics
sum_a = metrics_a.sum(axis=1)
allLabel_count = sum_a[METRICS_TP_NDX] + sum_a[METRICS_FN_NDX]
metrics_dict['percent_all/tp'] = \sum_a[METRICS_TP_NDX] / (allLabel_count or 1) * 100
metrics_dict['percent_all/fn'] = \sum_a[METRICS_FN_NDX] / (allLabel_count or 1) * 100
metrics_dict['percent_all/fp'] = \sum_a[METRICS_FP_NDX] / (allLabel_count or 1) * 100 # ❶
❶ 可能大于 100%,因为我们正在与标记为候选结节的像素总数进行比较,这是每个图像的一个微小部分
我们将开始对我们的模型进行评分,以确定特定训练运行是否是迄今为止我们见过的最佳模型。在第十二章中,我们说我们将使用 F1 得分来对我们的模型进行排名,但我们在这里的目标不同。我们需要确保我们的召回率尽可能高,因为如果我们一开始就找不到潜在的结节,我们就无法对其进行分类!
我们将使用我们的召回率来确定“最佳”模型。只要该时代的 F1 得分合理,我们只想尽可能提高召回率。筛选出任何误报阳性将是分类模型的责任。
列表 13.32 training.py:393, .logMetrics
def logMetrics(self, epoch_ndx, mode_str, metrics_t):# ... line 453score = metrics_dict['pr/recall']return score
当我们在下一章的分类训练循环中添加类似的代码时,我们将使用 F1 得分。
回到主训练循环中,我们将跟踪到目前为止在这次训练运行中见过的best_score。当我们保存我们的模型时,我们将包含一个指示这是否是迄今为止我们见过的最佳得分的标志。回想一下第 13.6.4 节,我们只对第一个和每隔五个时代调用doValidation函数。这意味着我们只会在这些时代检查最佳得分。这不应该是问题,但如果您需要调试发生在第 7 个时代的事情时,请记住这一点。我们在保存图像之前进行这个检查。
列表 13.33 training.py:210, SegmentationTrainingApp.main
def main(self):best_score = 0.0for epoch_ndx in range(1, self.cli_args.epochs + 1): # ❶# if validation is wanted# ... line 233valMetrics_t = self.doValidation(epoch_ndx, val_dl)score = self.logMetrics(epoch_ndx, 'val', valMetrics_t) # ❷best_score = max(score, best_score)self.saveModel('seg', epoch_ndx, score == best_score) # ❸
❶ 我们已经看到的时代循环
❷ 计算得分。正如我们之前看到的,我们采用召回率。
❸ 现在我们只需要编写saveModel。第三个参数是我们是否也要将其保存为最佳模型。
让我们看看如何将我们的模型持久化到磁盘。
13.6.6 保存我们的模型
PyTorch 使将模型保存到磁盘变得非常容易。在幕后,torch.save使用标准的 Python pickle库,这意味着我们可以直接传递我们的模型实例,并且它会正确保存。然而,这并不被认为是持久化我们模型的理想方式,因为我们会失去一些灵活性。
相反,我们只会保存我们模型的参数。这样做可以让我们将这些参数加载到任何期望具有相同形状参数的模型中,即使该类别与保存这些参数的模型不匹配。仅保存参数的方法使我们可以以比保存整个模型更多的方式重复使用和混合我们的模型。
我们可以使用model.state_dict()函数获取我们模型的参数。
列表 13.34 training.py:480, .saveModel
def saveModel(self, type_str, epoch_ndx, isBest=False):# ... line 496model = self.segmentation_modelif isinstance(model, torch.nn.DataParallel):model = model.module # ❶state = {'sys_argv': sys.argv,'time': str(datetime.datetime.now()),'model_state': model.state_dict(), # ❷'model_name': type(model).__name__,'optimizer_state' : self.optimizer.state_dict(), # ❸'optimizer_name': type(self.optimizer).__name__,'epoch': epoch_ndx,'totalTrainingSamples_count': self.totalTrainingSamples_count,}torch.save(state, file_path)
❶ 摆脱 DataParallel 包装器,如果存在的话
❷ 重要部分
❸ 保留动量等
我们将file_path设置为类似于data-unversioned/part2/models/p2ch13/ seg_2019-07-10_02.17.22_ch12.50000.state。.50000.部分是迄今为止我们向模型呈现的训练样本数量,而路径的其他部分是显而易见的。
提示 通过保存优化器状态,我们可以无缝恢复训练。虽然我们没有提供这方面的实现,但如果您的计算资源访问可能会中断,这可能会很有用。有关加载模型和优化器以重新开始训练的详细信息,请参阅官方文档(pytorch.org/tutorials/beginner/saving_loading_models.html)。
如果当前模型的得分是迄今为止我们见过的最好的,我们会保存第二份state的副本,文件名为.best.state。这可能会被另一个得分更高的模型版本覆盖。通过只关注这个最佳文件,我们可以让我们训练模型的客户摆脱每个训练时期的细节(当然,前提是我们的得分指标质量很高)。
列表 13.35 training.py:514, .saveModel
if isBest:best_path = os.path.join('data-unversioned', 'part2', 'models',self.cli_args.tb_prefix,f'{type_str}_{self.time_str}_{self.cli_args.comment}.best.state')shutil.copyfile(file_path, best_path)log.info("Saved model params to {}".format(best_path))with open(file_path, 'rb') as f:log.info("SHA1: " + hashlib.sha1(f.read()).hexdigest())
我们还输出了刚保存的模型的 SHA1。类似于 sys.argv 和我们放入状态字典中的时间戳,这可以帮助我们在以后出现混淆时准确调试我们正在使用的模型(例如,如果文件被错误重命名)。
我们将在下一章更新我们的分类训练脚本,使用类似的例程保存分类模型。为了诊断 CT,我们将需要这两个模型。
13.7 结果
现在我们已经做出了所有的代码更改,我们已经到达了图 13.17 步骤 3 的最后一部分。是时候运行 python -m p2ch13.training --epochs 20 --augmented final_seg。让我们看看我们的结果如何!
图 13.17 本章概述,重点关注我们从训练中看到的结果
如果我们限制自己只看我们有验证指标的时期,那么我们的训练指标看起来是这样的(接下来我们将查看这些指标,这样可以进行苹果对苹果的比较):
E1 trn 0.5235 loss, 0.2276 precision, 0.9381 recall, 0.3663 f1 score # ❶
E1 trn_all 0.5235 loss, 93.8% tp, 6.2% fn, 318.4% fp # ❶
...
E5 trn 0.2537 loss, 0.5652 precision, 0.9377 recall, 0.7053 f1 score # ❷
E5 trn_all 0.2537 loss, 93.8% tp, 6.2% fn, 72.1% fp # ❶
...
E10 trn 0.2335 loss, 0.6011 precision, 0.9459 recall, 0.7351 f1 score# ❷
E10 trn_all 0.2335 loss, 94.6% tp, 5.4% fn, 62.8% fp # ❶
...
E15 trn 0.2226 loss, 0.6234 precision, 0.9536 recall, 0.7540 f1 score# ❸
E15 trn_all 0.2226 loss, 95.4% tp, <2> 4.6% fn, 57.6% fp # ❹...
E20 trn 0.2149 loss, 0.6368 precision, 0.9584 recall, 0.7652 f1 score# ❸
E20 trn_all 0.2149 loss, 95.8% tp, <2> 4.2% fn, 54.7% fp # ❹
❶ TPs 也在上升,太好了!而 FNs 和 FPs 在下降。
❷ 在这些行中,我们特别关注 F1 分数–它在上升。很好!
❸ 在这些行中,我们特别关注 F1 分数–它在上升。很好!
❹ TPs 也在上升,太好了!而 FNs 和 FPs 在下降。
总体来看,情况看起来相当不错。真正的正例和 F1 分数在上升,假正例和假负例在下降。这正是我们想要看到的!验证指标将告诉我们这些结果是否合法。请记住,由于我们是在 64 × 64 的裁剪上进行训练,但在整个 512 × 512 的 CT 切片上进行验证,我们几乎肯定会有截然不同的 TP:FN:FP 比例。让我们看看:
E1 val 0.9441 loss, 0.0219 precision, 0.8131 recall, 0.0426 f1 score
E1 val_all 0.9441 loss, 81.3% tp, 18.7% fn, 3637.5% fpE5 val 0.9009 loss, 0.0332 precision, 0.8397 recall, 0.0639 f1 score
E5 val_all 0.9009 loss, 84.0% tp, 16.0% fn, 2443.0% fpE10 val 0.9518 loss, 0.0184 precision, 0.8423 recall, 0.0360 f1 score
E10 val_all 0.9518 loss, 84.2% tp, 15.8% fn, 4495.0% fp # ❶E15 val 0.8100 loss, 0.0610 precision, 0.7792 recall, 0.1132 f1 score
E15 val_all 0.8100 loss, 77.9% tp, 22.1% fn, 1198.7% fpE20 val 0.8602 loss, 0.0427 precision, 0.7691 recall, 0.0809 f1 score
E20 val_all 0.8602 loss, 76.9% tp, 23.1% fn, 1723.9% fp
❶ 最高的 TP 率(太好了)。请注意,TP 率与召回率相同。但 FPs 为 4495%–听起来很多。
哎呀–超过 4,000% 的假正例率?是的,实际上这是预期的。我们的验证切片面积为 218 像素(512 是 29),而我们的训练裁剪只有 212。这意味着我们在一个表面是 26 = 64 倍大的切片上进行验证!假阳性计数也增加了 64 倍是有道理的。请记住,我们的真正正例率不会有实质性变化,因为它们都已经包含在我们首次训练的 64 × 64 样本中。这种情况还导致了非常低的精确度,因此 F1 分数也很低。这是我们如何构建训练和验证的自然结果,所以不必担心。
然而,问题在于我们的召回率(因此也是真正的正例率)。我们的召回率在第 5 到 10 个时期之间趋于平稳,然后开始下降。很明显,我们很快就开始过拟合,我们可以在图 13.18 中看到更多证据–虽然训练召回率继续上升,但验证召回率在 300 万个样本后开始下降。这就是我们在第五章中识别过拟合的方式,特别是图 5.14。
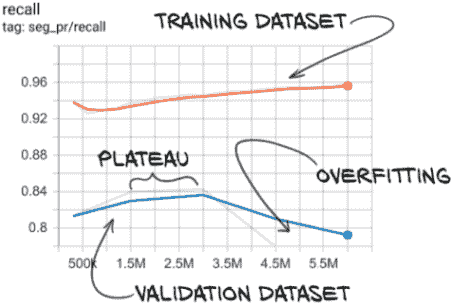
图 13.18 验证集召回率,在第 10 个时期后显示出过拟合的迹象(300 万个样本)
注意 请始终记住,TensorBoard 默认会平滑您的数据线。实色背后的浅色幽灵线显示了原始值。
U-Net 架构具有很大的容量,即使我们减少了滤波器和深度计数,它也能够很快地记住我们的训练集。一个好处是我们不需要训练模型很长时间!
回忆是我们对分割的首要任务,因为我们将让精度问题由下游的分类模型处理。减少这些假阳性是我们拥有这些分类模型的全部原因!这种倾斜的情况确实意味着我们很难评估我们的模型。我们可以使用更加重视召回率的 F2 分数(或 F5,或 F10…),但我们必须选择一个足够高的N来几乎完全忽略精度。我们将跳过中间步骤,只通过召回率评分我们的模型,并使用我们的人类判断来确保给定的训练运行不会对此产生病理性影响。由于我们是在 Dice 损失上进行训练,而不是直接在召回率上进行训练,所以应该会有所作用。
这是我们有点作弊的情况之一,因为我们(作者)已经为第十四章进行了训练和评估,我们知道所有这些将会发生什么。没有好的方法来看待这种情况,知道我们看到的结果会起作用。有教养的猜测是有帮助的,但它们不能替代实际运行实验直到有所突破。
就目前而言,我们的结果已经足够好,即使我们的度量有一些相当极端的值。我们离完成我们的端到端项目又近了一步!
13.8 结论
在本章中,我们讨论了一种为像素到像素分割构建模型的新方法;介绍了 U-Net,这是一种经过验证的用于这类任务的现成模型架构;并为我们自己的使用调整了一个实现。我们还改变了我们的数据集,以满足我们新模型的训练需求,包括用于训练的小裁剪和用于验证的有限切片集。我们的训练循环现在可以将图像保存到 TensorBoard,并且我们已经将增强从数据集移动到可以在 GPU 上运行的单独模型中。最后,我们查看了我们的训练结果,并讨论了即使假阳性率(特别是)看起来与我们所希望的不同,但考虑到我们对来自更大项目的需求,我们的结果将是可以接受的。在第十四章中,我们将把我们写的各种模型整合成一个连贯的端到端整体。
13.9 练习
-
为分类模型实现模型包装器方法来增强(就像我们用于分割训练的那样)。
-
你不得不做出什么妥协?
-
这种变化对训练速度有什么影响?
-
-
更改分割
Dataset实现,使其具有用于训练、验证和测试集的三分割。-
你用于测试集的数据占了多少比例?
-
测试集和验证集上的性能看起来一致吗?
-
较小的训练集会导致训练受到多大影响?
-
-
使模型尝试分割恶性与良性,除了结节状态。
-
你的度量报告需要如何改变?你的图像生成呢?
-
你看到了什么样的结果?分割是否足够好以跳过分类步骤?
-
-
你能训练模型同时使用 64×64 裁剪和整个 CT 切片的组合吗?¹⁶
-
除了仅使用 LUNA(或 LIDC)数据,你能找到其他数据来源吗?
13.10 总结
-
分割标记单个像素或体素属于某一类。这与分类相反,分类是在整个图像级别操作的。
-
U-Net 是用于分割任务的突破性模型架构。
-
使用分割后跟分类,我们可以用相对较少的数据和计算需求实现检测。
-
对于当前一代 GPU 来说,对 3D 分割的天真方法可能会迅速使用过多的 RAM。仔细限制呈现给模型的范围可以帮助限制 RAM 使用。
-
可以在图像裁剪上训练分割模型,同时在整个图像切片上进行验证。这种灵活性对于类别平衡可能很重要。
-
损失加权是对从训练数据的某些类别或子集计算的损失进行强调,以鼓励模型专注于期望的结果。它可以补充类平衡,并在尝试调整模型训练性能时是一个有用的工具。
-
TensorBoard 可以显示在训练过程中生成的 2D 图像,并将保存这些模型在训练运行中如何变化的历史记录。这可以用来在训练过程中直观地跟踪模型输出的变化。
-
模型参数可以保存到磁盘并重新加载,以重新构建之前保存的模型。只要旧参数和新参数之间有 1:1 的映射,确切的模型实现可以更改。
¹ 我们预计会标记很多不是结节的东西;因此,我们使用分类步骤来减少这些数量。
²Joseph Redmon 和 Ali Farhadi,“YOLOv3: An Incremental Improvement”,pjreddie.com/media/files/papers/YOLOv3.pdf。也许在你完成这本书后可以看看。
³…“头、肩膀、膝盖和脚趾、膝盖和脚趾”,就像我的(Eli 的)幼儿们会唱的那样。
⁴ 这里包含的实现与官方论文不同,使用平均池化而不是最大池化进行下采样。GitHub 上最新版本已更改为使用最大池化。
⁵ 在我们的代码抛出任何异常的不太可能的情况下–显然不会发生,对吧?
⁶ 例如,Stanislav Nikolov 等人,“Deep Learning to Achieve Clinically Applicable Segmentation of Head and Neck Anatomy for Radiotherapy”,arxiv.org/pdf/1809.04430.pdf。
⁷ 这里的错误是 0 处的环绕将不会被检测到。对我们来说并不重要。作为练习,实现适当的边界检查。
⁸ 修复这个问题对教会你关于 PyTorch 并没有太大帮助。
⁹Samuel G. Armato 第三等人,2011,“The Lung Image Database Consortium (LIDC) and Image Database Resource Initiative (IDRI): A Completed Reference Database of Lung Nodules on CT Scans”,Medical Physics 38,第 2 卷(2011 年):915-31,pubmed.ncbi.nlm.nih.gov/21452728/。另请参阅 Bruce Vendt,LIDC-IDRI,Cancer Imaging Archive,mng.bz/mBO4。
¹⁰ 如果你经常这样做,那么在 2020 年刚发布的pandas库是一个使这个过程更快的好工具。我们在这里使用标准 Python 发行版中包含的 CSV 读取器。
¹¹ 大多数 CT 扫描仪产生 512×512 的切片,我们不会担心那些做了不同处理的扫描仪。
¹² 否则,你的模型将会立即训练!
¹³ 参见cs231n.github.io/neural-networks-3。
¹⁴Roxie 会感到骄傲!
¹⁵ 是的,“合理”有点含糊。如果你想要更具体的东西,那么“非零”是一个很好的起点。
¹⁶ 提示:要一起批处理的每个样本元组必须对应张量的形状相同,但下一批可能有不同形状的不同样本。




![[保姆级教程]Windows安装MongoDB教程](https://img-blog.csdnimg.cn/direct/9ca554922b7e41a4adac42a7a114af10.png)