在微服务架构中,一次请求往往涉及到多个模块,多个中间件,多台机器的相互协作才能完成。
这一系列调用请求中,有些是串行的,有些是并行的,那么如何确定这个请求背后调用了哪些应用,哪些模块,哪些节点及调用的先后顺序?
本文将会从以下几个方面来阐述

分布式追踪系统的原理及作用
如何衡量一个接口的性能好坏,一般我们至少会关注以下三个指标
-
接口的 RT 你怎么知道?
-
是否有异常响应?
-
主要慢在哪里?
单体架构
在初期,公司刚起步的时候,可能多会采用如下单体架构,对于单体架构我们该用什么方式来计算以上三个指标呢?

最容易想到的显然是用 AOP

使用 AOP 在调用具体的业务逻辑前后分别打印一下时间即可计算出整体的调用时间,使用 AOP 来 catch 住异常也可知道是哪里的调用导致的异常。
微服务架构
在单体架构中由于所有的服务,组件都在一台机器上,所以相对来说这些监控指标比较容易实现,不过随着业务的快速发展,单体架构必然会朝微服务架构发展,如下
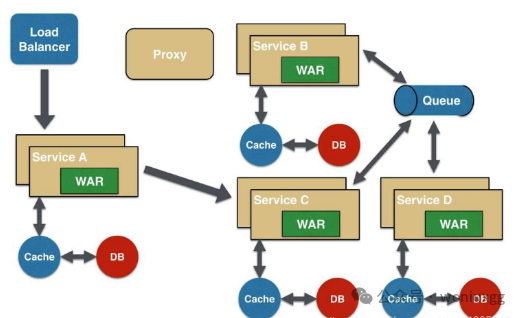
如图示:一个稍微复杂的微服务架构
如果有用户反馈某个页面很慢,我们知道这个页面的请求调用链是 A -----> C -----> B -----> D,此时如何定位可能是哪个模块引起的问题。每个服务 Service A,B,C,D 都有好几台机器。怎么知道某个请求调用了服务的具体哪台机器呢?



分布式调用链标准 - OpenTracing
知道了分布式调用链的作用,那我们来看下如何实现分布式调用链的实现及原理, 首先为了解决不同的分布式追踪系统 API 不兼容的问题,诞生了 OpenTracing 规范,OpenTracing 是一个轻量级的标准化层,它位于应用程序/类库和追踪或日志分析程序之间。


接下来我们来看 OpenTracing 的数据模型,主要有以下三个
-
Trace:一个完整请求链路
-
Span:一次调用过程(需要有开始时间和结束时间)
-
SpanContext:Trace 的全局上下文信息, 如里面有traceId
理解这三个概念非常重要,为了让大家更好地理解这三个概念,我特意画了一张图
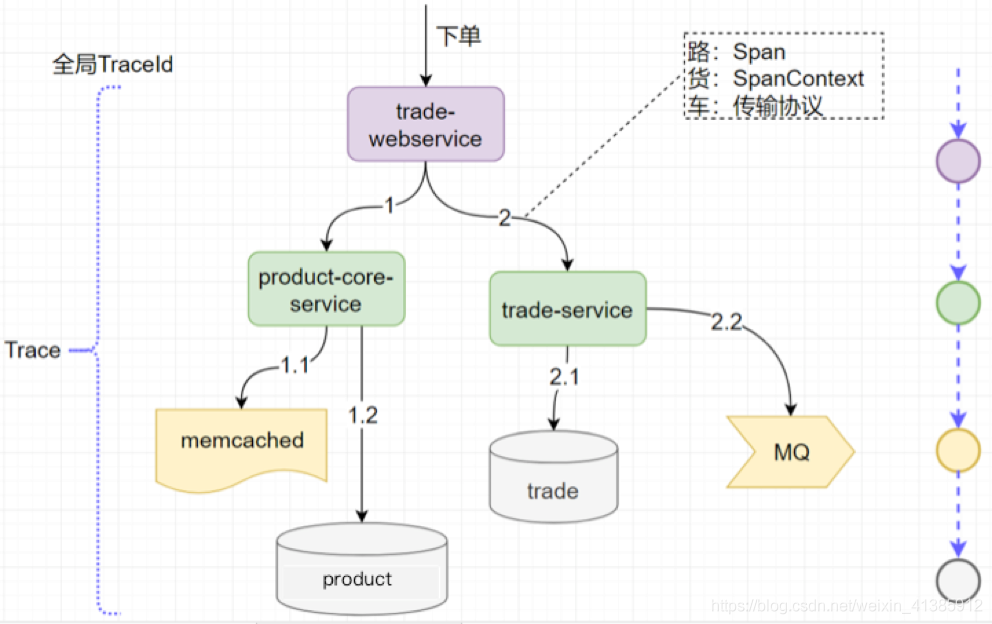




根据这些图表信息显然可以据此来画出调用链的可视化视图如下


SkyWalking的原理及架构设计
怎么自动采集 span 数据
SkyWalking 采用了插件化 + javaagent 的形式来实现了 span 数据的自动采集,这样可以做到对代码的 无侵入性,插件化意味着可插拔,扩展性好(后文会介绍如何定义自己的插件)

如何跨进程传递 context


dubbo 中的 attachment 就相当于 header ,所以我们把 context 放在 attachment 中,这样就解决了 context 的传递问题。

小提示:这里的传递 context 流程均是在 dubbo plugin 处理的,业务无感知,这个 plugin 是怎么实现的呢,下文会分析
traceId 如何保证全局唯一


图示: snowflake 算法生成的 id
不过 snowflake 算法有一个众所周知的问题:时间回拨,这个问题可能会导致生成的 id 重复。那么 SkyWalking 是如何解决时间回拨问题的呢。


请求量这么多,全部采集会不会影响性能?
如果对每个请求调用都采集,那毫无疑问数据量会非常大,但反过来想一下,是否真的有必要对每个请求都采集呢,其实没有必要,我们可以设置采样频率,只采样部分数据,SkyWalking 默认设置了 3 秒采样 3 次,其余请求不采样,如图示

这样的采样频率其实足够我们分析组件的性能了,按 3 秒采样 3 次这样的频率来采样数据会有啥问题呢。理想情况下,每个服务调用都在同一个时间点(如下图示)这样的话每次都在同一时间点采样确实没问题
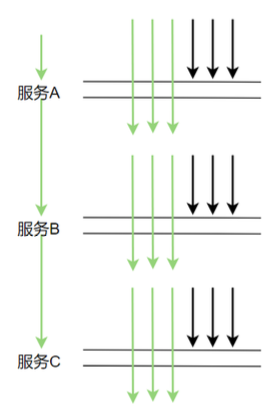
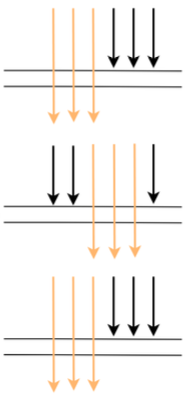
但在生产上,每次服务调用基本不可能都在同一时间点调用,因为期间有网络调用延时等,实际调用情况很可能是下图这样

SkyWalking 的基础架构
SkyWalking 的基础如下架构,可以说几乎所有的的分布式调用都是由以下几个组件组成的

首先当然是节点数据的定时采样,采样后将数据定时上报,将其存储到 ES, MySQL 等持久化层,有了数据自然而然可根据数据做可视化分析。
SkyWalking 的性能如何
接下来大家肯定比较关心 SkyWalking 的性能,那我们来看下官方的测评数据




我司在分布式调用链上的实践
SkyWalking 在我司的应用架构
由上文可知 SkyWalking 有很多优点,那么是不是我们用了它的全部组件了呢,其实不然,来看下其在我司的应用架构


我司对 SkyWalking 作了哪些改造和实践
我司主要作了以下改造和实践
-
预发环境由于调试需要强制采样
-
实现更细粒度的采样?
-
日志中嵌入traceId
-
自研实现了 SkyWalking 插件
预发环境由于调试需要强制采样


实现更细粒度的采样?
哈叫更细粒度的采样。先来看下 skywalking 默认的采样方式 ,即统一采样

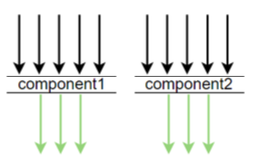
就是说 3 秒内进行 3 次 redis, dubbo, mysql 等的采样,也就避免了此问题
日志中如何嵌入traceId?


然后我们再实现一个 log4j 的插件,如下


我司自研了哪些 skywalking 插件
SkyWalking 实现了很多插件,不过未提供 memcached 和 druid 的插件,所以我们根据其规范自研了这两者的插件


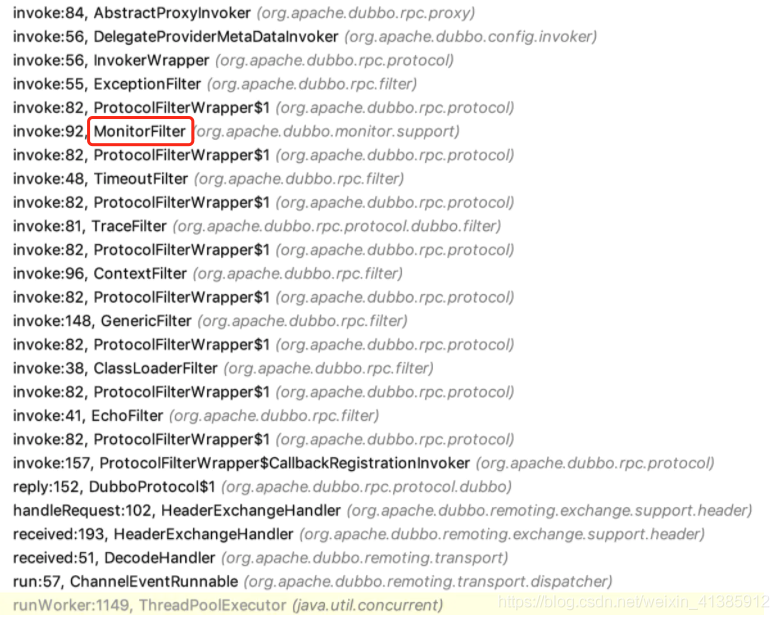


我们再看看下代码中描写的拦截器(Inteceptor)干了什么事,以下列出关键步骤


// skywalking-plugin.def 文件
dubbo=org.apache.skywalking.apm.plugin.asf.dubbo.DubboInstrumentation
这样打包出来的插件就会对 MonitorFilter 的 invoke 方法进行增强,在 invoke 方法执行前对期 attachment 作注入全局 traceId 等操作,这一切都是静默的,对代码无侵入的。
最后说一句(求关注!别白嫖!)
如果这篇文章对您有所帮助,或者有所启发的话,求一键三连:点赞、转发、在看。
关注公众号:woniuxgg,在公众号中回复:笔记 就可以获得蜗牛为你精心准备的java实战语雀笔记,回复面试、开发手册、有超赞的粉丝福利!










![[ROS 系列学习教程] rosbag Python API](https://img-blog.csdnimg.cn/direct/d90a65e3a44a446d9da741646a4070c4.png#pic_center)