目录
es 写入数据流程
es 删除数据流程
es 读数据流程
es 部署的服务有哪些角色
es 的实现原理
es 和lucence 关系
如何提高写入效率
提高搜索效率
es doc value指的啥
分片指的啥,定义后可不可义再修改
深分页如何优化
对于聚合操作是如何优化的
元数据有哪些,保存在哪里的
是否支持sql查询
mapping指的是啥
常用的分词器
别名通常会用在哪些场景
es是否支持向量检索
能不能支持join操作
副分片是如何复制的
keyword和text有啥区别
字典树体现在es的哪些应用上
使用es自带的唯一id还是自己生成
并发场景下数据一致性如何保证
es 更新mapping 字段如何操作
es 为啥称为近实时
es 可能会丢数据嘛
es 写入数据流程
-
客户端发送索引请求: 客户端应用通过 REST API 或者官方提供的客户端库发送索引请求到 Elasticsearch 集群中的任意节点。索引请求包括待索引的文档数据以及目标索引的名称、类型等信息。
-
文档解析和映射: Elasticsearch 接收到索引请求后,会对文档数据进行解析,将其转换成内部数据结构,并根据文档中的字段映射信息进行处理。如果目标索引不存在,Elasticsearch 会根据映射信息创建新的索引。
-
分片路由: 根据索引请求中指定的文档 ID 或者根据文档内容,Elasticsearch 确定文档应该被索引到哪个分片上。分片路由算法通常基于文档 ID 的哈希值或者基于文档字段值的哈希值计算结果。
-
文档分片: 一旦确定了文档应该被索引到哪个分片上,Elasticsearch 就会将文档数据分配到相应的分片中。如果需要,文档数据会在分片之间进行复制,以确保数据的高可用性和容错性。
-
文档存储和索引构建: 文档数据被存储到分片中,并且根据文档的字段信息构建倒排索引和其他索引结构。倒排索引是 Elasticsearch 的核心数据结构之一,用于快速定位包含特定词条的文档。
-
主分片确认: 文档数据成功存储到主分片后,Elasticsearch 返回确认响应给客户端,表示文档索引操作已经成功完成。在确认响应返回之前,主分片需要确保数据已经持久化到本地磁盘。
-
复制分片同步: 如果配置了复制(replica)分片,主分片会将索引的变更信息发送给相应的复制分片。复制分片负责同步主分片上的数据变更,以确保数据的冗余备份和高可用性。
-
索引刷新: 为了使新索引的文档对搜索可见,Elasticsearch 需要执行索引刷新操作。索引刷新操作将内存中的倒排索引数据刷新到磁盘,并更新索引元数据信息。默认情况下,索引刷新操作会定期执行,也可以通过客户端的请求强制执行。
es 删除数据流程
-
客户端发送删除请求: 客户端通过 REST API 或者官方提供的客户端库发送删除请求到 Elasticsearch 集群中的任意节点。删除请求包括待删除文档的索引、类型和 ID 信息。
-
分片路由: Elasticsearch 接收到删除请求后,会根据文档 ID 或者文档内容确定待删除文档所在的分片。分片路由算法通常与数据写入时的路由算法相同。
-
文档删除: 一旦确定了待删除文档所在的分片,Elasticsearch 就会在相应的分片上执行文档删除操作。删除操作涉及从倒排索引中移除文档的引用,并更新其他相关的索引数据结构。
-
主分片确认: 删除操作完成后,主分片会返回确认响应给客户端,表示文档删除成功。在确认响应返回之前,主分片需要确保删除操作已经持久化到本地磁盘。
-
复制分片同步: 如果配置了复制(replica)分片,主分片会将删除操作的变更信息发送给相应的复制分片。复制分片负责同步主分片上的删除操作,以确保数据的一致性。
-
索引刷新: 删除操作也会影响到倒排索引等索引数据结构,因此需要执行索引刷新操作来更新索引状态。索引刷新操作会将索引的变更信息刷新到磁盘,并更新索引元数据信息。
需要注意的是,删除操作并不会立即释放磁盘空间,而是标记文档为已删除状态。Elasticsearch 会定期执行段合并(segment merging)等后台任务,以清理已删除文档并释放磁盘空间。因此,即使执行了删除操作,索引的磁盘使用量不会立即减少,而是随着后台任务的执行逐渐减少
es 读数据流程
-
客户端发送搜索请求: 客户端应用通过 REST API 或者官方提供的客户端库发送搜索请求到 Elasticsearch 集群中的任意节点。搜索请求包括查询条件、索引名称、类型等信息。
-
查询解析: Elasticsearch 接收到搜索请求后,会解析查询条件,并将其转换成内部的查询结构。查询可以包括全文搜索、精确匹配、范围查询、布尔逻辑等多种类型。
-
查询路由: Elasticsearch 根据搜索请求中指定的索引名称和查询条件,确定哪些分片包含符合查询条件的文档数据。分片路由算法通常基于查询条件的哈希值或者根据文档分布情况进行优化。
-
分片并行搜索: Elasticsearch 并行地向分片发送搜索请求,并在每个分片上执行相应的查询操作。这意味着搜索请求可以同时在集群中的多个分片上进行处理,从而加快搜索速度。
-
结果汇总和排序: 每个分片都会返回符合查询条件的部分文档结果,然后 Elasticsearch 将这些部分结果汇总起来,并根据查询要求对结果进行排序。通常情况下,排序操作是在每个分片返回的结果上进行的。
-
结果返回给客户端: 最终,Elasticsearch 将搜索结果返回给客户端应用。搜索结果通常包括符合查询条件的文档数据、文档 ID、得分等信息。客户端应用可以根据需要对搜索结果进行进一步处理和展示
es 部署的服务有哪些角色
在 Elasticsearch 集群中,有几种不同的角色负责不同的任务和功能。以下是主要的角色:
-
节点 (Node): 节点是 Elasticsearch 集群的基本组成单元。每个节点是一个独立的 Elasticsearch 实例,负责处理数据索引、搜索、复制、集群管理等任务。节点可以分为不同的类型,包括主节点、数据节点和客户端节点。
-
主节点 (Master Node): 主节点是 Elasticsearch 集群的控制节点,负责管理集群的整体状态、索引的创建和删除、分片分配、故障检测和故障转移等操作。主节点不存储数据,其主要任务是协调集群中的其他节点。
-
数据节点 (Data Node): 数据节点负责存储索引数据和执行搜索操作。它们负责处理文档的索引和搜索请求,并且存储集群中的数据分片。数据节点可以根据需要扩展以增加存储容量和处理能力。
-
客户端节点 (Client Node): 客户端节点是专门用于接收客户端请求并将其转发到集群中的其他节点的节点。客户端节点不存储数据,其主要作用是减轻主节点和数据节点的负载,提高集群的可用性和性能。
es 和lucence 关系
Elasticsearch 和 Lucene 之间有着密切的关系,可以将它们看作是搜索引擎的两个不同层次:
-
Lucene: Lucene 是一个开源的全文搜索引擎库,提供了用于索引和搜索文档的基本功能。它是 Apache 软件基金会的项目之一,是许多搜索引擎和信息检索系统的核心技术之一。Lucene 提供了一个高效的倒排索引数据结构,以及用于文本分析、查询解析、评分、排序等功能的实现。Lucene 可以作为一个库集成到 Java 应用中,提供搜索和索引功能。
-
Elasticsearch: Elasticsearch 是建立在 Lucene 基础之上的分布式搜索和分析引擎,它提供了更高级别的抽象和功能,使得构建和管理大规模搜索应用更加简单和高效。Elasticsearch 提供了一个 RESTful API 接口,支持分布式索引和搜索、实时数据分析、复杂查询、聚合分析、数据可视化等功能。它在 Lucene 的基础上构建了一个分布式系统,支持自动的集群管理、数据复制、故障处理等特性,使得可以横向扩展以处理海量数据和高并发请求。
Elasticsearch 实际上是 Lucene 的封装和扩展,它在 Lucene 基础上构建了一个分布式系统,提供了更丰富的功能和更容易使用的接口。通过 Elasticsearch,用户可以方便地构建和管理复杂的搜索应用,而无需直接操作 Lucene API。同时,Elasticsearch 还提供了许多其他功能,如数据分析、聚合分析、数据可视化等,使得它成为一个功能更加丰富的搜索和分析平台
es 的实现原理,主要是倒排索引
以下是倒排索引的基本原理和结构:
-
词条提取: 在构建倒排索引之前,需要对文档进行分词处理,将文档拆分成词条或者单词。分词过程通常包括词条化、标准化、词干提取等步骤,以确保搜索时能够正确匹配词条。
-
词条映射: 对于每个词条,倒排索引将其映射到包含该词条的文档列表。这意味着每个词条都有一个相关联的文档列表,其中包含了包含该词条的所有文档的标识符(如文档 ID)。
-
文档标识符: 文档标识符是倒排索引中的一个关键部分,用于标识包含特定词条的文档。文档标识符可以是文档的唯一编号、文件路径、URL 等。
-
倒排列表: 对于每个词条,倒排索引都会维护一个倒排列表,其中包含了包含该词条的所有文档的标识符。倒排列表通常按照某种顺序排列,以便进行高效的检索操作。
-
索引合并: 在实际应用中,倒排索引可能会分布在多个分片或者节点上,每个分片或节点负责维护一部分索引数据。当需要执行搜索操作时,倒排索引会合并多个分片或节点上的倒排列表,以获得完整的搜索结果。
倒排索引的优点在于它能够快速定位包含特定词条的文档,从而实现高效的搜索和检索操作。倒排索引通常被搜索引擎和信息检索系统广泛使用,如 Elasticsearch、Apache Solr 等
如何提高写入效率
-
批量写入: 将多个文档的索引请求合并成批量请求,一次性发送给 Elasticsearch。这样可以减少网络通信开销和请求处理时间,从而提高写入效率。使用 Elasticsearch 的 Bulk API 可以实现批量写入功能。
-
异步写入: 对于非实时要求较高的写入操作,可以采用异步写入的方式。将写入请求发送到消息队列或者异步任务队列,然后由后台任务异步处理,这样可以避免写入操作对客户端的响应时间造成影响。
-
分片和副本优化: 合理配置索引的分片和副本数量,以充分利用集群中的节点资源,并且确保数据的高可用性和容错性。通常情况下,增加分片数量可以提高写入并行度,从而提高写入效率,可以暂时调整副本数
-
硬件优化: 使用高性能的硬件设备,如 SSD 硬盘、高速网络等,可以提升 Elasticsearch 的写入性能。此外,确保 Elasticsearch 集群的硬件配置和网络带宽能够满足写入负载的需求。
-
索引设置优化: 根据具体的业务需求和数据特性,合理设置索引的配置参数,如刷新间隔、刷新策略、副本同步延迟等。调整这些参数可以平衡写入性能和数据一致性之间的关系
-
避免热点写入: 尽量避免将大量写入请求集中在少数几个节点上,通过自定义id,以防止出现热点写入问题。合理分布写入请求可以减轻节点的负载,并提高整个集群的写入性能
提高搜索效率
-
doc_values存储在磁盘上,可以在不加载整个文档的情况下直接访问字段值。这样可以避免加载大量文档到内存中,减少内存消耗和 I/O 操作,提高查询的性能和效率。 -
支持排序和聚合:
doc_values可以被用于排序和聚合操作,可以在大规模数据上进行快速的排序和聚合计算。Elasticsearch 使用doc_values来支持各种类型的排序和聚合操作,包括字段值、范围、统计信息等。 -
主要是按照列存储的,压缩和读取效率高
分片指的啥,定义后可不可义再修改
指的是同一个索引,会有由三个shard 来存储数据
深分页如何优化
首先来看原理,三个节点的话,如果是查一页,每页是10的话,实际上每个节点都会查10条数据出来,如果是1w页的话,每个节点都要查10w的数据出来,所以深分页带来的查询消耗是巨大的
对于聚合操作是如何优化的
这里我主要是想讲的是doc_values,列式存储,压缩,对于数值来说,聚合计算效果好,不支持字符类型,字符类型也不需要聚合运算
元数据有哪些,保存在哪里的
是否支持sql查询
开源版本不支持,可以通过自定义来实现,把sql语法转成es的查询语句
mapping指的是啥
具体来说,Mapping 定义了以下几个方面的内容:
-
字段类型(Field Type): 定义了每个字段的数据类型,例如文本(text)、关键字(keyword)、日期(date)、数值(numeric)、布尔值(boolean)等。
-
分析器(Analyzer): 对于文本类型的字段,Mapping 可以指定使用哪种分析器进行文本分析和处理。分析器用于将文本拆分成词条,并进行标准化、词干提取、停用词过滤等处理。
-
索引选项(Index Options): 定义了字段在索引中的索引行为,包括是否索引、是否存储、是否启用位置信息等。索引选项影响了字段的搜索行为和存储行为。
-
字段属性(Field Properties): 定义了字段的各种属性和设置,如是否可搜索、是否可排序、是否可聚合等。字段属性影响了字段的使用方式和行为特性。
-
嵌套字段(Nested Field): 对于复杂的数据结构,Mapping 可以定义嵌套字段,以支持多层级的文档结构。嵌套字段允许在一个字段中存储另一个文档或者文档数组
别名通常会用在哪些场景
索引按月/或者其它维度进行存储时,通过别名来查询全部的索引
es是否支持向量检索
支持
能不能支持join操作
副分片是如何复制的
在 Elasticsearch 中,副本的复制发生在主分片上发生索引操作后。当客户端发送索引请求时,请求会首先到达主分片,主分片负责处理索引操作并在本地更新索引数据。一旦主分片确认成功地将索引操作应用到本地数据后,它会将相同的操作发送给所有对应的副本分片。
副本分片在收到来自主分片的索引操作后,会执行相同的操作,将索引操作应用到本地数据中。一旦副本分片确认成功地应用了索引操作,它会向主分片发送确认请求。主分片收到来自所有副本分片的确认请求后,确认索引操作成功,并向客户端发送成功响应。
keyword和text有啥区别
keyword 为关键字不会进行分词
text会进行分词
字典树体现在es的哪些应用上
-
倒排索引(Inverted Index):ES使用倒排索引来快速查找包含特定词条的文档。在倒排索引中,每个词条都映射到包含该词条的文档列表。字典树可以用于构建这种倒排索引,其中每个节点代表一个词条的字符,从根节点开始,沿着路径可以得到包含该前缀的文档列表。
-
全文搜索(Full-Text Search):ES支持全文搜索,允许用户搜索文本中的任意词条。字典树可以用于存储文档中的单词,使得搜索引擎可以快速地定位包含特定单词的文档。
-
前缀搜索(Prefix Search):ES允许用户进行前缀搜索,即查找以特定前缀开头的词条。字典树是实现前缀搜索的理想数据结构,因为它可以有效地存储以相同前缀开头的词条,并且可以快速地找到满足特定前缀条件的所有词条。
-
自动补全(Autocomplete):基于用户输入提供自动补全建议是许多应用中常见的需求。字典树可以用于实现自动补全功能,它可以快速地查找以用户输入的前缀开头的词条,并提供相应的建议。
使用es自带的唯一id还是自己生成
使用es自带的唯一id,已经经过优化
并发场景下数据一致性如何保证
Elasticsearch 使用乐观并发控制(Optimistic Concurrency Control)来处理并发更新场景。当多个客户端同时尝试更新同一个文档时,Elasticsearch 会比较文档的版本号,并且只允许具有最新版本号的客户端执行更新操作。这样可以避免并发更新导致的数据不一致问题
// 准备更新请求UpdateRequest request = new UpdateRequest("products", "123").doc(createUpdateScript()).retryOnConflict(3) // 如果遇到版本冲突,最多重试3次.versionType(VersionType.EXTERNAL);// 发送更新请求UpdateResponse response = client.update(request, RequestOptions.DEFAULT);// 处理更新响应if (response.status() == RestStatus.OK) {System.out.println("Document updated successfully");} else {System.out.println("Failed to update document: " + response.status());}es 更新mapping 字段如何操作
可以加字段,不能删除字段
es 为啥称为近实时
Elasticsearch 支持实时刷新(Real-Time Refresh)功能,允许索引的变更立即可见。默认情况下,Elasticsearch 每秒钟会执行一次索引刷新操作,将内存中的索引数据刷新到磁盘上,从而使得新索引的文档对搜索可见
es 可能会丢数据嘛
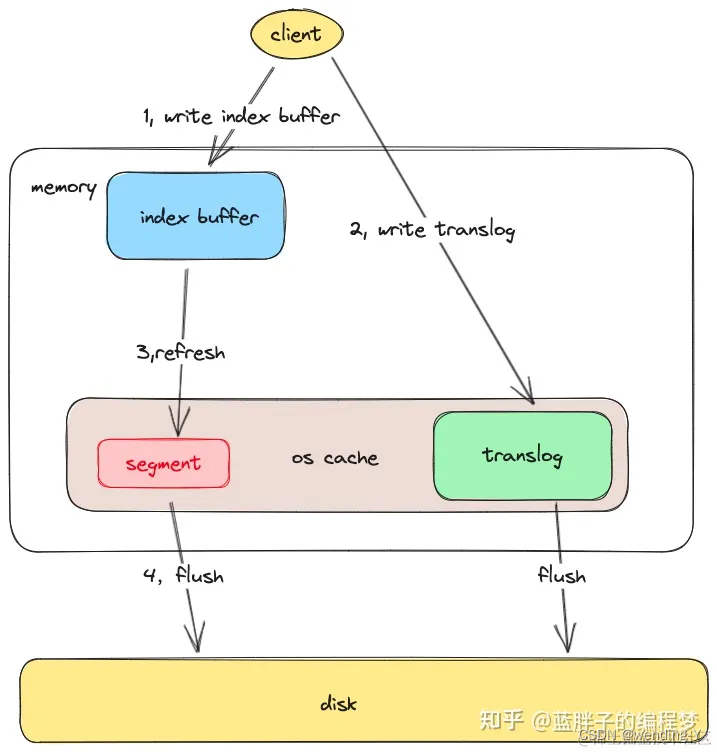
refresh 1s一次
segment flush 30分钟,或者达到指定文件大小
translog 5s一次
理论上可能会丢5s的数据
filter 和query 有啥区别
-
缓存机制:
filter查询的结果可以被缓存,这意味着相同的filter查询可以被多次重用,从而提高了性能。query查询的结果默认情况下不会被缓存,每次执行查询都会重新计算。
-
评分机制:
query查询会根据文档与查询的匹配程度计算一个评分(score),并按照评分进行排序,默认情况下,查询结果会按照评分从高到低排序。filter查询不会计算评分,它只是用来过滤文档,返回与查询匹配的文档,而不关心匹配程度。
-
语义:
query查询用于描述文档与查询的匹配程度,它会考虑到查询中的全文检索、词条匹配、相似度等因素。filter查询主要用于过滤文档,根据指定的条件来筛选文档,它主要关注于查询条件的匹配与否,而不关心匹配程度。
-
性能:
- 由于不涉及评分计算,
filter查询通常比query查询性能更好,特别是在过滤大量文档时。 query查询的性能通常会受到评分计算的影响,特别是当查询结果需要排序时,性能可能会受到更大的影响。
- 由于不涉及评分计算,