注:以下讨论基于InnoDB引擎。
文章目录
- 问题引入
- 猜想1:只加了一行写锁,锁住要修改的这一行。
- 语义问题
- 数据一致性问题
- 猜想2:要修改的这一行加写锁,扫描过程中遇到其它行加读锁
- 猜想3:要修改的这一行加写锁,扫描过程中遇到其它行加读锁,行与行之间的间隙加上间隙锁。
- next-key锁
- next-key锁带来的问题
- 总结
问题引入
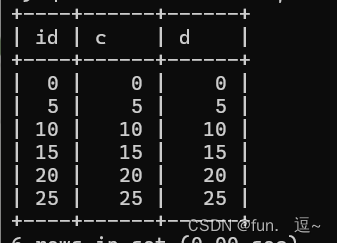
创建一张表t,并插入一些数据
CREATE TABLE `t` (`id` int(11) NOT NULL,`c` int(11) DEFAULT NULL,`d` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);
表中数据如下

执行以下sql:
select * from t where d = 5 for update;
问:这句sql是当前读,读的是d=5的这一行,我们都知道,当前读的时候会加锁。所以这句sql在读 d=5这一行时,会在该行上加写锁。现在问题来了,除了在d=5这一行上加上写锁之外,还会加其他锁吗?
猜想1:只加了一行写锁,锁住要修改的这一行。
| 时间 | 事务A | 事务B | 事务C |
|---|---|---|---|
| t0 | begin; | ||
| t1 | select * from t where d = 5 for update; (5, 5, 5) | ||
| t2 | update t set d = 5 where id = 0; | ||
| t3 | select * from t where d = 5 for update; (0, 0, 5) (5, 5, 5) | ||
| t4 | insert into t values(1,1,5); | ||
| t5 | select * from t where d = 5 for update; (0, 0, 5) (1, 1, 5) (5, 5, 5) | ||
| t6 | commit; |
如果猜想一正确,事务B和事务C不会被阻塞,事务A三次select结果显示在表中高亮部分。我们来分析以下这三条结果:
- t1时刻,表中只有一行d=5,所以返回一行
- t2时刻,事务B将id=0的一行的d值修改为5,所以查出来是两行。这里发生了不可重复读问题
- t3时刻,事务C插入了一行,所以查出来d=5有三行。这里发生了幻读问题。即前后两次查询中,后一次查询看到了前一次查询没有看到的行。
注意:t2时刻不是幻读,因为幻读只是针对插入新行。
你也许会说,for update是当前读,事务B和事务C修改了表,就应该看到最新修改的结果啊。
我们再来看看如果按猜想1这样设计,会导致什么问题果:
语义问题
| 时间 | 事务A | 事务B | 事务C |
|---|---|---|---|
| t0 | begin; | ||
| t1 | select * from t where d = 5 for update; | ||
| t2 | update t set d = 5 where id = 0; update t set c = 5 where id = 0; | ||
| t3 | select * from t where d = 5 for update; | ||
| t4 | insert into t values(1,1,5); update t set c = 5 where id = 1; | ||
| t5 | select * from t where d = 5 for update; | ||
| t6 | commit; |
t1时刻,事务A执行的语义是“我要将d=5的行加上行锁”
t2时刻,id=0这一行的d值等于5,按照猜想一,这一行是没有加锁的,所以事务B可以执行下面修改语句。
t4时刻,同理,事务C也可以修改新插入的行
事务B和事务C在执行各自第二个update语句时就破坏了事务A宣布的语义。
数据一致性问题
| 时间 | 事务A | 事务B | 事务C |
|---|---|---|---|
| t0 | begin; | ||
| t1 | select * from t where d = 5 for update; update t set d = 100 where d=5; | ||
| t2 | update t set d = 5 where id = 0; update t set c = 5 where id = 0; | ||
| t3 | select * from t where d = 5 for update; | ||
| t4 | insert into t values(1,1,5); update t set c = 5 where id = 1; | ||
| t5 | select * from t where d = 5 for update; | ||
| t6 | commit; |
此时数据库表中的d=5的行记录应该是:
| id | c | d |
|---|---|---|
| 0 | 5 | 5 |
| 1 | 5 | 5 |
底层binlog在记录时,会按照事务的提交顺序记录操作。事务的提交顺序是:B -> C -> A 所以,在binlog里面,日志是这样记录的:
// 事务B
update t set d = 5 where id = 0; // (0,0,5)
update t set c = 5 where id = 0; // (0,5,5)
// 事务C
insert into t values(1,1,5); // (1,1,5)
update t set c = 5 where id = 1; // (1,5,5)
// 事务A
select * from t where d = 5 for update; // ()
update t set d = 100 where d=5; // 所有d=5的行都把d值修改为100
select * from t where d = 5 for update;
select * from t where d = 5 for update;
如果拿这个binlog去备份备库,备库中就没有d=5的行了。而主库表中实际上是由两行d=5的记录的。这里发生了主库与备库数据不一致的问题。
综上所述吗,猜想1不正确。
猜想2:要修改的这一行加写锁,扫描过程中遇到其它行加读锁
| 时间 | 事务A | 事务B | 事务C |
|---|---|---|---|
| t0 | begin; | ||
| t1 | select * from t where d = 5 for update; update t set d = 100 where d = 5; | ||
| t2 | update t set d = 5 where id = 0; blocked update t set c = 5 where id = 0; | ||
| t3 | select * from t where d = 5 for update; | ||
| t4 | insert into t values(1,1,5); update t set c = 5 where id = 1; | ||
| t5 | select * from t where d = 5 for update; | ||
| t6 | commit; |
如果猜想2正确,t1时刻事务A执行后,会将扫描到的行都锁柱,所以t2时刻,事务B想要更新id=0的这一行记录,会被阻塞,只有A提交之后才会执行B。而t4时刻,事务C想表中插入行不会被阻塞,因为事务A在t1时刻只锁住了表中存在的行,而新插入的行在t1时刻还不存在,所以可以可以执行插入。同样地,在t5时刻,发生了幻读,即同一事务,前后两次查询,后一次查询看到了前一次查询没有看到的新行。
三个事务执行完,数据库表中的d=5的行应该是:
| id | c | d |
|---|---|---|
| 0 | 5 | 5 |
| 1 | 5 | 5 |
我们还是看看binlog日志里面是怎么记录的,由于B被阻塞,所以事务B只有等A提交之后才会执行,执行顺序应该是:C->A->B。
// 事务C
insert into t values(1,1,5); // (1,1,5)
update t set c = 5 where id = 1; // (1,5,5)
// 事务A
select * from t where d = 5 for update; // ()
update t set d = 100 where d=5; // 所有d=5的行都把d值修改为100
select * from t where d = 5 for update;
select * from t where d = 5 for update;
// 事务B
update t set d = 5 where id = 0; // (0,0,5)
update t set c = 5 where id = 0; // (0,5,5)
用binlog生成备库时,由于事务B是在事务A之后的,所以id=0这一行数据不一致问题解决了,但是id=1这一行数据还是不一致。
也就是说,即使把表中所有行都加上了锁,还是无法阻止并发事务插入新的记录。
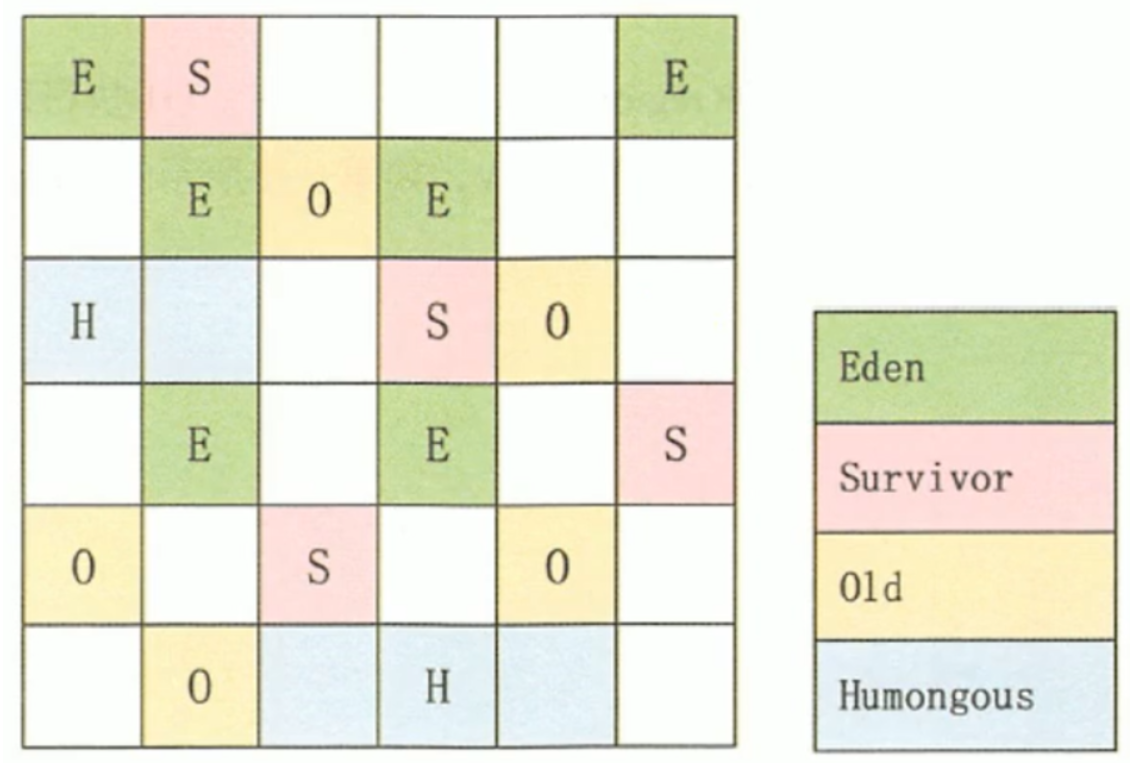
猜想3:要修改的这一行加写锁,扫描过程中遇到其它行加读锁,行与行之间的间隙加上间隙锁。
我们再来看猜想3,猜想3是加锁最多的:
- d=5的行加了行锁
- 表中所有存在的行加了行锁
- 行与行的间隙加了间隙锁
我们来看看什么是间隙锁,表t初始化插入了6条记录:
6条记录就会产生7个间隙,如图所示

所以,当执行select * from t where d = 5 for update; 语句时,不仅加了6个行锁,还加了7个间隙锁。这样就确保了事务A执行过程中无法插入新的记录。
也就是说,在一行行扫描过程中,不仅给行加上了行锁,还给行两边的间隙加上了间隙锁。读锁和读锁之间不互斥,间隙锁也一样。
| 读锁 | 写锁 | |
|---|---|---|
| 读锁 | 不互斥 | 互斥 |
| 写锁 | 互斥 | 互斥 |
间隙锁与间隙锁之间是不互斥的,也就是说执行下面这个并发事务时:
| 时间 | 事务A | 事务B |
|---|---|---|
| t0 | begin; select * from t where id = 5 for update; | |
| t1 | begin; select * from t where id = 10 for update; |
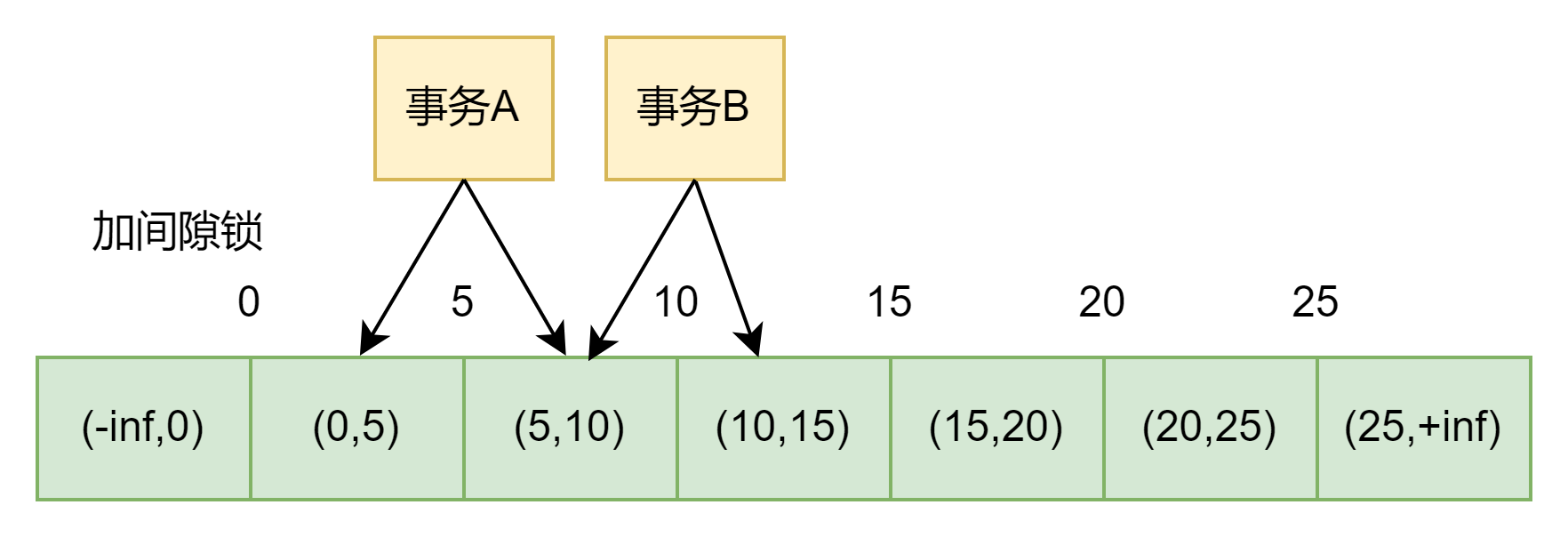
事务B是不会被阻塞的,间隙锁只对insert语句生效。
next-key锁
还用t表说明,d上没有索引:
这里图中的数字是id:
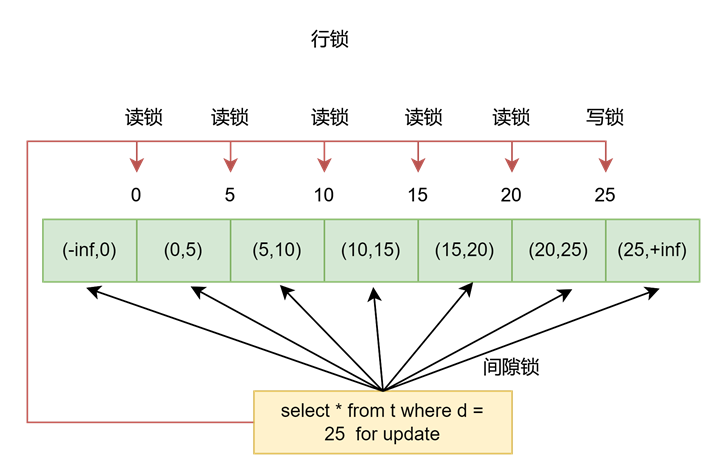
where条件是d=25,由于d上没有索引,所以要扫描所有的行,扫描到的行都加上读锁。行与行之间的间隙加了间隙锁。要修改的d=25这一行(25,25,25)加上写锁。
next-key锁就是间隙锁(开区间)加 行锁(单值),变成一个左开右闭区间
比如 (-inf, 0)的间隙锁,加上id = 0这一行的行锁 就等于 (-inf, 0] 的next-key锁
next-key锁带来的问题
间隙锁和next-key锁虽然可以解决幻读问题,但是会带来其他困扰。
比如,对于下面的sql语句:
begin;
select * from t where id=N for update;
/*如果行不存在*/
insert into t values(N,N,N);
/*如果行存在*/
update t set d=N set id=N;
commit;
如果在两个事务并发的执行,可能会造成死锁,我们用表格来说明一下:
| 时间 | 事务A | 事务B |
|---|---|---|
| t0 | begin; select * from t where id=9 for update; | |
| t1 | begin; select * from t where id=9 for update; | |
| t2 | insert into t values(9,9,9); blocked | |
| t3 | insert into t values(9,9,9); blocked dead lock |
两个事务,A和B并发地执行上面的业务sql:
-
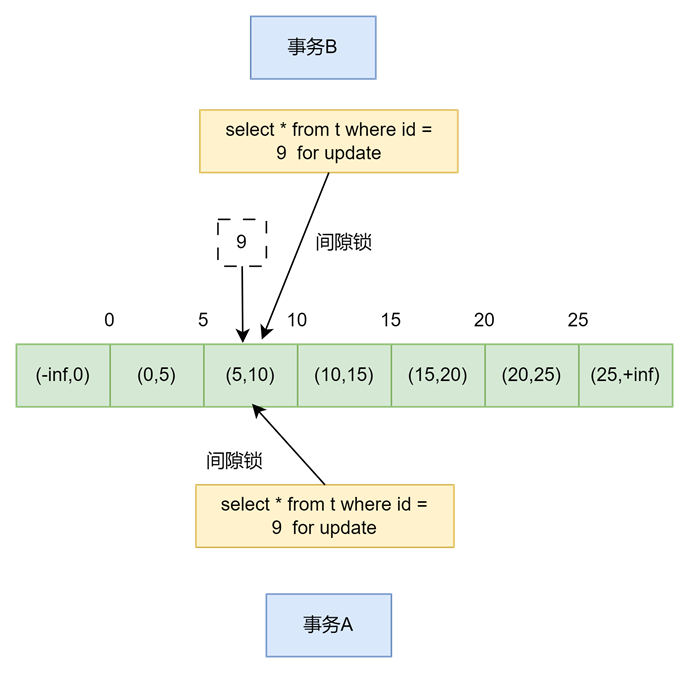
t0时刻,事务A开启事务,执行select * from t where id=9 for update; 由于id上有索引,索引只会定位到id=9这一行,不会扫描其他行,但是id=9这一行不存在,所以加不上写锁。同时,会给(5,10)这个间隙加上间隙锁。

-
t1时刻,事务B开启事务,执行select * from t where id=9 for update; 与A一样,只会给(5,10)加上间隙锁
-
t2时刻,当事务A执行inser操作,往(5,10)间隙插入行是,由于事务B也有间隙锁,所以会被阻塞,等事务B commit 释放锁之后才能执行插入操作
-
t3时刻,当事务B执行insert操作,往(5,10)间隙插入行是,由于事务A也有间隙锁,所以会被阻塞,等事务A commit 释放锁之后才能执行插入操作。事务A和事务B同时在等待对方的资源,才会释放自己占用的锁,造成死锁。
总结
在可重复读的隔离级别下,mysql的当前读加锁规则:
1、满足where条件的行加写锁
2、扫描过程中遇到的行加读锁
3、表中已存在的行会有间隙,扫描过程中遇到间隙会加间隙锁