文章目录
- 一、简介
- 1. 数据类型
- 2. 倒排索引
- 3. Lucene
- 4. ElasticSearch
- 5. Solar VS ElasticSearch
- 二、ElasticSearch入门
- 1. 简介
- 2. 分词器
- 3. 索引操作
- 4. 文档操作
- 5. ES文档批量操作
- 二、ElasticSearch的DSL
- 1. 文档映射Mapping
- 2. Index Template
- 3. DSL
一、简介
1. 数据类型
- 结构化数据:
结构化数据是指具有固定格式和结构的数据,其存储方式是以表格形式组织,每个数据项都有固定的字段和数据类型。结构化数据通常是按照预先定义的模式进行组织和存储的,因此具有良好的组织结构和易于查询的特点。
- 非结构化数据
非结构化数据是指没有固定格式和结构的数据,其存储方式不遵循任何预定义的模式,通常以文本或二进制形式存在。由于缺乏固定的结构,非结构化数据通常难以直接用于传统的关系型数据库管理系统进行存储和查询。
非结构化数据的搜索方式通常有两种:顺序扫描和全文检索
- 顺序扫描:即按照顺序扫描的方式查询特定的关键字,例如给你一张报纸,让你找到该报纸中“平安”的文字在哪些地方出现过。你肯定需要从头到尾把报纸阅读扫描一遍然后标记出关键字在哪些版块出现过以及它的出现位置,这种扫描方式是十分耗费时间的。
- 全文检索:通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置以及出现的次数。用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体内容读取出来了。
2. 倒排索引
倒排索引(Inverted Index)是一种用于快速检索文档的数据结构,常用于搜索引擎等系统中。相比于传统的索引结构,倒排索引将文档中的每个词作为关键词,将关键词指向包含该关键词的文档列表,从而实现了从关键词到文档的快速检索。
简单理解,正向索引是通过key找value,反向索引则是通过value找key。ES底层在检索时 底层使用的就是倒排索引。
假设现在有3份文档数据:
Java is the best programming language.
PHP is the best programming language.
Javascript is the best programming language.
建立的倒排索引的形式如下:
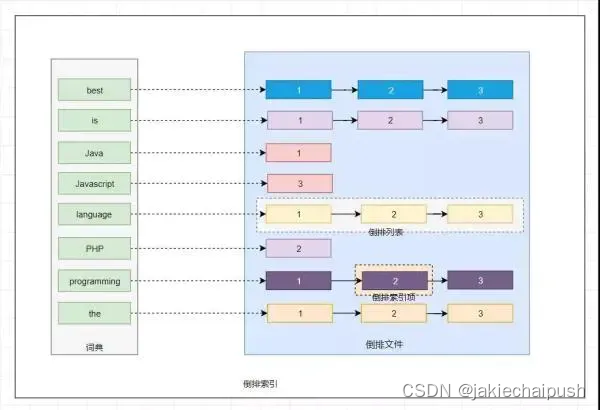
关于倒排索引有几个关键的概念需要了解:
- 词条(Term):索引里面最小的存储和查询单元,对于英文来说是一个单词,对于中文来说一般指分词后的一个词。
- 词典(Term Dictionary):或字典,是词条 Term 的集合。搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
- 倒排表(Post list):一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过以及出现的位置。
每条记录称为一个倒排项(Posting)。倒排表记录的不单是文档编号,还存储了词频等信息。
- 倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
3. Lucene
我们知道这种非结构化数据的处理需要依赖全文搜索,而目前市场上开放源代码的最好全文检索引擎工具包就属于 Apache 的 Lucene了,它是一个基于Java开发的搜索引擎库类,但是 Lucene 只是一个工具包,它不是一个完整的全文检索引擎。Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
4. ElasticSearch
Elasticsearch是构建在Apache Lucene之上的开源分布式搜索引擎,它提供了强大的全文搜索和分析功能,被广泛应用于各种场景,如日志分析、实时搜索、数据分析等,以下是 Elasticsearch 的一些特点和功能:
- 分布式架构:Elasticsearch 是基于分布式架构设计的,可以将数据分布存储在多个节点上,实现数据的水平扩展和高可用性。
- 全文搜索:Elasticsearch 提供了强大的全文搜索功能,支持复杂的查询语法和高效的搜索算法,可以快速检索海量数据,并返回相关性排名的结果。
- 实时性:Elasticsearch 支持实时索引和查询,可以快速响应用户的搜索请求,适用于需要实时分析和搜索的场景。
- 多种数据类型:除了文本数据,Elasticsearch 还支持多种数据类型的索引和搜索,包括数字、日期、地理位置等,可以满足不同类型数据的检索需求。
- 分析和聚合:Elasticsearch 提供了丰富的分析和聚合功能,可以对搜索结果进行统计、分组、排序等操作,支持各种聚合函数和数据分析工具。
- 实时监控和管理:Elasticsearch 提供了直观的监控和管理界面,可以实时查看集群状态、节点性能指标、索引状态等信息,方便运维管理和故障排查。
- 开放性和灵活性:Elasticsearch 是一个开放的系统,支持各种数据源的集成和扩展,可以通过插件和 API 扩展功能,满足不同场景下的需求。
5. Solar VS ElasticSearch
Solr 是第一个基于 Lucene 核心库功能完备的搜索引擎产品,诞生远早于 Elasticsearch。 当单纯的对已有数据进行搜索时,Solr更快。当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势。
- Solr 利用 Zookeeper 进行分布式管理,而Elasticsearch 自身带有分布式协调管理功能。
- Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持 json文件格式。
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch。
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch更适用于新兴的实时搜索应用。
二、ElasticSearch入门
1. 简介
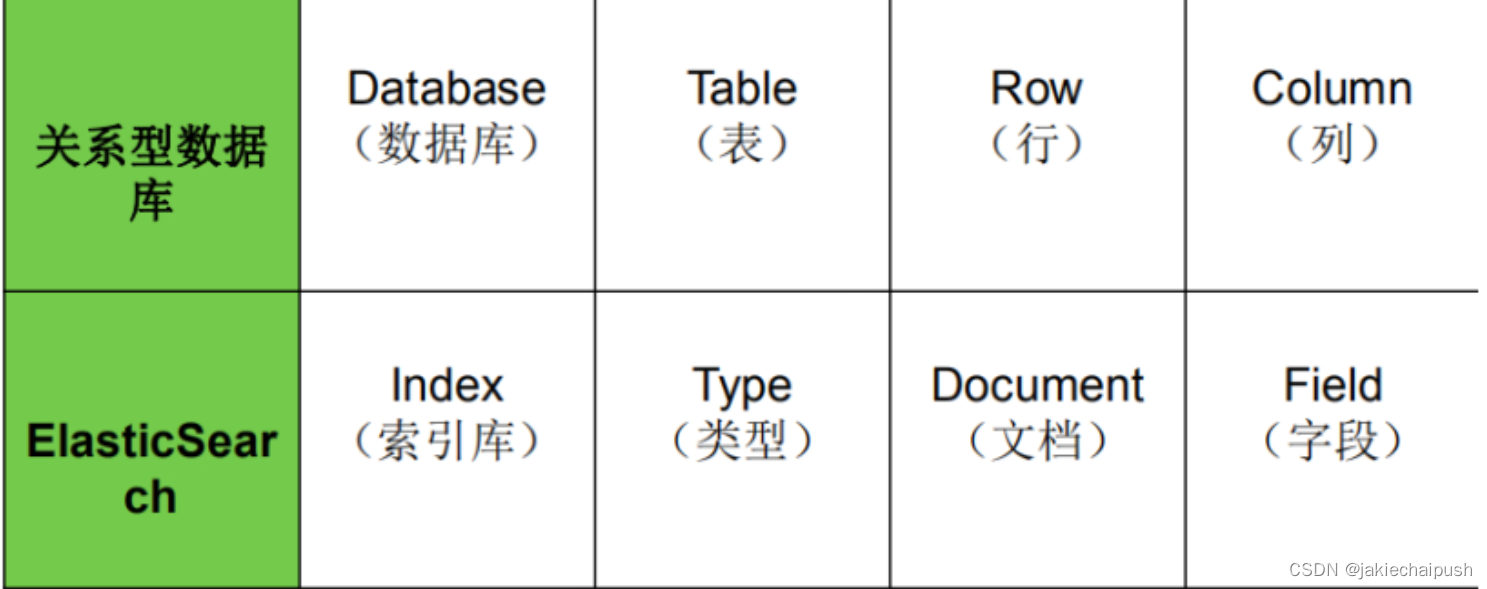
ElasticSearch有一些关键的概念,这里介绍一下:
- 节点
它指的是Elasticsearch的单个运行实例。单个物理和虚拟服务器可容纳多个节点,这取决于它们的物理资源(如RAM、存储和处理能力)的能力。
- 索引
它是不同类型的文档及其属性的集合。索引还使用分片的概念来提高性能。例如,一组文档包含社交网络应用程序的数据。
- 文档
它是以JSON格式定义的特定方式的字段集合。每个文档都属于一种类型,并且位于索引内。每个文档都与一个称为UID的唯一标识符相关联。Elasticsearch是面向文档的,文档是所有可搜索数据的最小单位。
2. 分词器
参考文章:https://blog.csdn.net/bxg_kyjgs/article/details/130561856
分词器的主要作用将用户输入的一段文本,按照一定逻辑,分析成多个词语的一种工具。顾名思义,文本分析就是把全文本转换成一系列单词(term/token)的过程,也叫分词。在 ES 中,Analysis 是通过分词器(Analyzer) 来实现的,可使用 ES 内置的分析器或者按需定制化分析器。分词器是专门处理分词的组件,分词器由以下三部分组成:
- character filter
接收原字符流,通过添加、删除或者替换操作改变原字符流
- tokenizer
简单的说就是将一整段文本拆分成一个个的词,例如拆分英文,通过空格能将句子拆分成一个个的词,但是对于中文来说,无法使用这种方式来实现。在一个分词器中,有且只有一个tokenizeer
- token filters
将切分的单词添加、删除或者改变,例如将所有英文单词小写,或者将英文中的停词a删除等,在token filters中,不允许将token(分出的词)的position或者offset改变。同时,在一个分词器中,可以有零个或者多个token filters
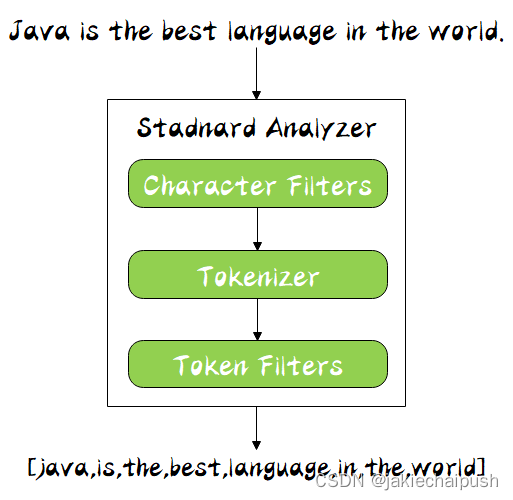
同时 Analyzer 三个部分也是有顺序的,从图中可以看出,从上到下依次经过 Character Filters,Tokenizer 以及 Token Filters,这个顺序比较好理解,一个文本进来肯定要先对文本数据进行处理,再去分词,最后对分词的结果进行过滤。
当我们使用ElasticSearch时,主要是两个地方会使用到分词器,首先是创建索引的时候,当索引文档字符类型为text时,在建立索引时将会对该字段进行分词。第二是搜索的时候,当对一个text类型的字段进行全文检索时,会对用户输入的文本进行分词。
3. 索引操作
- 创建索引
POST books/_doc
{"name": "Snow Crash","author": "Neal Stephenson","release_date": "1992-06-01","page_count": 470
}
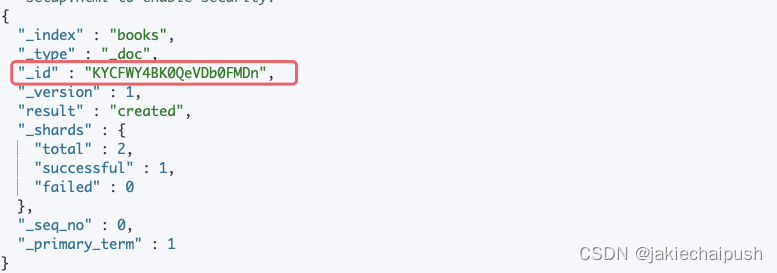
首先上面代码我们插入了一个文档,没有制定文档id,elasticsearch会帮我们自动创建一个唯一的文档id。其次当请求将JSON对象添加到特定索引时,如果该索引不存在,则此API会自动创建该索引以及该特定JSON对象的基础映射。
当然我们也可以自己手动创建索引
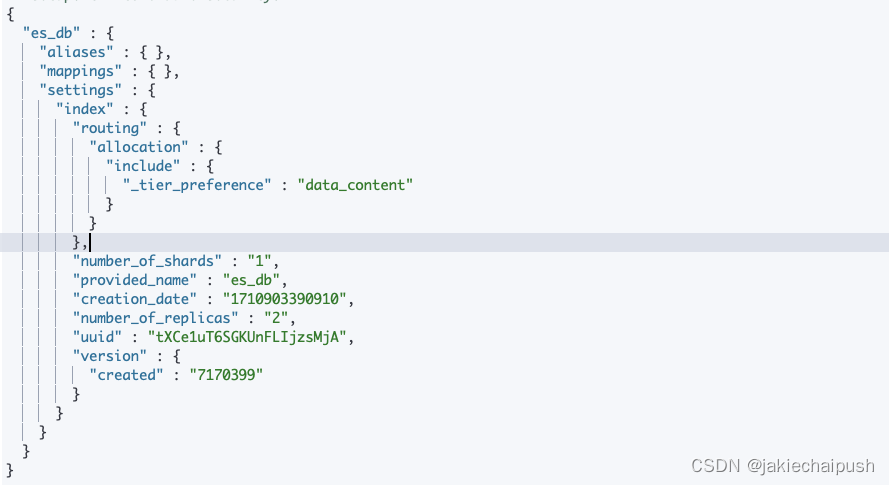
//创建索引,并使用系统默认值
PUT /es_db//创建索引指定一些默认值
PUT /es_db
{"settings": {"number_of_replicas": 1,"number_of_shards": 1}
}

- 修改索引
例如我们修改es_db的索引的设置,设置副本数为2
PUT /es_db/_settings
{"index":{"number_of_replicas": 2 }
}
- 查询索引
GET /es_db
我们可以使用下面明朗判断某个索引是否存在:
HEAD /es_db
运行上面代码后,如果HTTP响应是200,则存在,如果是404,则不存在
- 删除索引
DELETE /es-db
4. 文档操作
- 添加文档
当对具有特定映射的相应索引进行请求时,它有助于在索引中添加或更新JSON文档。例如,以下请求会将JSON对象添加到索引学校
PUT schools/_doc/5
{"name":"City School", "description":"ICSE", "street":"West End","city":"Meerut","state":"UP", "zip":"250002", "location":[28.9926174, 77.692485],"fees":3500,"tags":["fully computerized"], "rating":"4.5"
}

| 字段 | 含义 |
|---|---|
| _index | 文档所属的索引名 |
| _type | 文档所属的类型名 |
| _id | 文档唯一id |
| _source | 文档原始的json数据 |
| _version | 文档的版本号,修改删除操作_version都会自增1 |
| _seq_no | 和_version一样,一旦数据发生更改,数据也一直是累计的 |
| _primary_term | _primary_term主要是用来恢复数据时处理当多个文档的 _seq_no一样时的冲突,避免Primary Shard上的写入被覆盖。每当Primary Shard 发生重新分配时,比如重启,Primary选举等,_primary_term会递增1 |
action.auto_create_index:false
index.mapper.dynamic:false
您还可以限制索引的自动创建,通过更改以下参数的值,只允许使用具有特定模式的索引名称
action.auto_create_index:+acc*,-bank*
PUT /es_db/_doc/1
{"name":"张三","sex":1,"age":25, "address":"广州天河公园", "remark":"javadeveloper"
}
PUT /es_db/_doc/1
{"name":"张三1","sex":11,"age":251, "address":"广州天河公园", "remark":"javadeveloper"
}
上面创建文档的过程中,我们指定了一个id为1,如果在索引库中该文档id不存在,es会直接创建新的文档,如果id重复了,es会为我们删除原来的文档,然后再创建新的文档,版本字段会增加。

当然我们如果在创建文档的时候不指定id,es会自动帮我们生成一个唯一的id。
注意:POST和PUT都能起到创建/更新的作用,PUT需要对一个具体的资源进行操作也就是 要确定id才能进行更新/创建,而POST是可以针对整个资源集合进行操作的,如果不写id就由ES生成一个唯一id进行创建新文档,如果填了id那就针对这个id的文档进行创建/更新(也就是说PUT操作必须要id,POST可以不要)
- 修改文档
Es更新的第一种方式是进行全量更新,它会先删除原来的文档,然后将更新后的文档插入。
PUT /es_db/_doc/1
{"name":"张三","sex":1,"age":25, "address":"广州天河公园", "remark":"javadeveloper"
}
GET /es_db/_doc/1
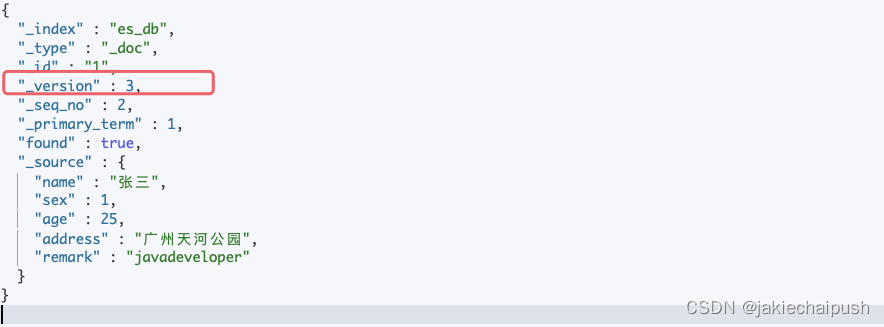
ES更新的第二种模式是使用_updata局部更新,这种模式的更新不会删除原来的文档,而是实现真正的数据更新。
POST /es_db/_update/1
{"doc": {"name": "张四","sex": 2,"age": 23}
}
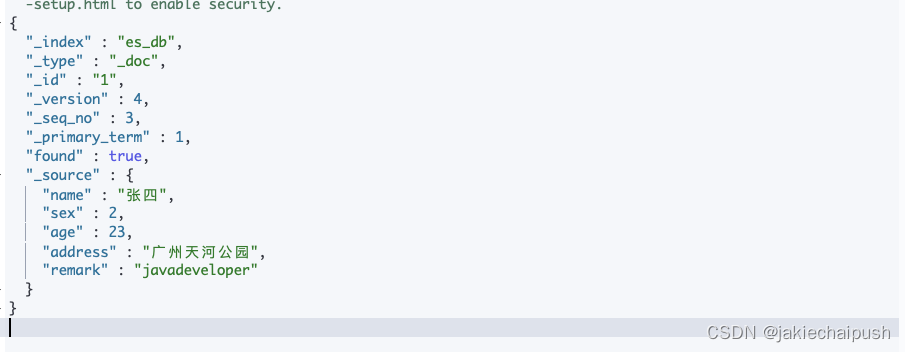
同时还可以使用_update_by_query来更新文档。_update_by_query是Elasticsearch提供的用于批量更新文档的API。通过该API,您可以基于查询条件更新符合条件的所有文档。
POST /es_db/_update_by_query
{"query": {"match": {"_id": "1"}},"script": {"source": "ctx._source.age=30"}
}
在Elasticsearch中,ctx._source是一个特殊的上下文对象,用于表示当前文档的源(即文档的原始JSON表示)。在使用Update API时,您可以使用ctx._source来访问和修改文档的源数据。具体来说,ctx._source包含当前文档的原始JSON表示,您可以通过它来读取和修改文档的字段值。例如,您可以使用ctx._source.fieldName来访问文档中某个字段的值,并且可以在需要时修改这个字段的值。在_update_by_query操作的上下文中,ctx._source用于表示正在被更新的文档。通过修改ctx._source中的字段值,您可以实现对文档的更新操作。在示例中,ctx._source.likes++表示将文档中likes字段的值增加1。
- 并发环境下修改文档
_seq_no和_primary_term是对_version的优化,7.X版本的ES默认使用这种方式控制版本,所以当在高并发环境下使用乐观锁机制修改文档时,要带上当前文 档的_seq_no和_primary_term进行更新:
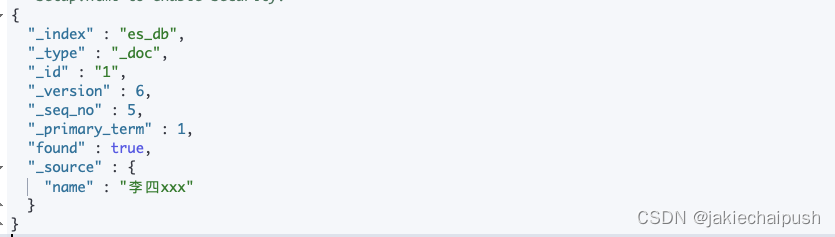
POST /es_db/_doc/1?if_seq_no=4&if_primary_term=1
{"name": "李四xxx"
}
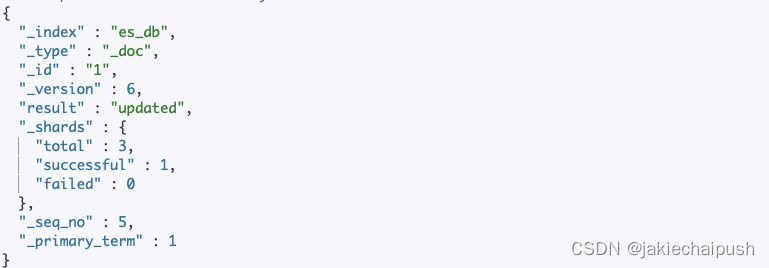
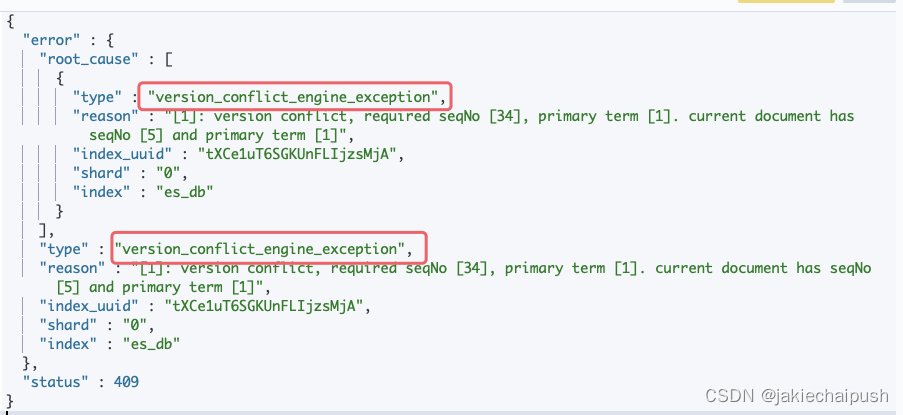
只有我们指定的if_seq_no和if_primary_term和当前的
_seq_no和primary_term相同才会进行更新,否则会报错
- 查询文档
GET /es_db/_doc/1
GET /es_db/_doc/_search

使用_search查询,会默认查询出索引库的前10个文档
ES Search API提供了两种条件查询搜索方式:
- REST风格的请求URI,直接将参数带过去
- 封装到request body中,这种方式可以定义更加易读的JSON格式
//查询年龄等于28岁的文档
GET /es_db/_doc/_search?q=age:28
//查询年龄小于等于28岁的文档
GET /es_db/_doc/_search?q=age:<=28
//查询年龄在25到26岁之间的文档
GET /es_db/_doc/_search?q=age[25 TO 26]
//查询年龄在25-26之间的0开始的前1条数据
GET /es_db/_doc/_search?q=age[25 TO 26]&from=0&size=1
//指定查询结果只输出name和age
GET /es_db/_doc/_search?_source=name,age
//对查询结果进行排序
GET/es_db/_doc/_search?sort=age:desc
- 删除文档
DELETE/es_db/_doc/1
5. ES文档批量操作
批量操作可以减少网络连接所产生的开销,提升性能,ES的批量操作有下面几个特点:
- ES支持在一次API调用中,对不同的索引进行操作
- 可以在URI中指定Index,也可以在请求的Payload中指定
- 操作中单条文档操作失败,并不会影响其他操作
- 返回结果包括了每一条操作执行的结果
批量对文档进行写操作是通过_bulk的API来实现的,请求方式需要是POST,该API需要两个参数,第一个是指定操作的类型及操作的对象(index,type和id),第二个为操作的数据。

actionName:表示操作类型,主要有create,index,delete和update
POST _bulk
{"create":{"_index":"article","_type":"_doc","_id":3}}
{"id":3,"title":"老师1","content":"老师1666","tags":["java","面向对象"],"create_time":1554015482530}
{"create":{"_index":"article","_type":"_doc","_id":4}}
{"id":4,"title":"老师2","content":"老师2NB","tags":["java","面向对象"],"create_time":1554015482530}
虽然上面语句说是批量创建文档,但也可以说是全量更新文档,如果要创建的文档存在那么就会删除原来的文档,然后插入更新过的文档。
批量删除只需要将actionName属性修改为delete
POST _bulk
{"delete":{"_index":"article","_type":"_doc","_id":3}}
{"delete":{"_index":"article","_type":"_doc","_id":4}}
批量更新,如下
POST _bulk
{"update":{"_index":"article","_type":"_doc","_id":3}}
{"doc":{"title":"ES大法必修内功"}}
{"update":{"_index":"article","_type":"_doc","_id":4}}
{"doc":{"create_time":1554018421008}}
我们甚至把上面几种类型组合在一起使用:
POST _bulk
{"create":{"_index":"article","_type":"_doc","_id":3}}
{"id":3,"title":"fox老师","content":"fox老师666","tags":["java","面向对 象"],"create_time":1554015482530}
{"delete":{"_index":"article","_type":"_doc","_id":3}} 5 {"update":{"_index":"article","_type":"_doc","_id":4}} 6 {"doc":{"create_time":1554018421008}}
es的批量查询可以使用mget和msearch两种。其中mget是需要我们知道它的id,可以指定不同的index,也可以指定返回值source。msearch可以通过字段查询来进行一个批量的查找。
#可以通过ID批量获取不同index和type的数据
GET _mget
{"docs":[{"_index":"es_db","_id":1},{"_index":"article","_id":4}]
}

#可以通过ID批量获取es_db的数据
GET /es_db/_mget
{"docs":[{"_id":1},{"_id":2}]
}
#缩减为
GET /es_db/_mget
{"ids":["1","2"]
}
在_msearch中,请求格式和bulk类似。查询一条数据需要两个对象,第一个设置index和 type,第二个设置查询语句。查询语句和search相同。如果只是查询一个index,我们可以 在url中带上index,这样,如果查该index可以直接用空对象表示。
GET /es_db/_msearch
{}
{"query":{"match_all":{}},"from":0,"size":2}
{"index":"article"}
{"query":{"match_all":{}}}

二、ElasticSearch的DSL
Elasticsearch中提供了一种强大的检索数据方式,这种检索方式称之为Query DSL(Domain Specified Language) 。Query DSL是利用 Rest API传递 JSON格式的请求体(RequestBody)数据与 ES进行交互,这种方式的丰富查询语法让 ES检索变得更强大,更简洁。其基本语法如下:
GET /es_db/_doc/_search {json请求体数据}
#可以简化为下面写法
GET /es_db/_search {json请求体数据}
1. 文档映射Mapping
ElasticSearch中的映射(Mapping)用来定义一个文档,可以定义所包含的字段以及字段的类型、分词器及属性等等。Mapping类似数据库中的schema的定义。ES中Mapping映射可以分为动态映射和静态映射。
- 动态映射
在关系数据库中,需要事先创建数据库,然后在该数据库下创建数据表,并创建表字段、类 型、长度、主键等,最后才能基于表插入数据。而Elasticsearch中不需要定义Mapping映射(即关系型数据库的表、字段等),在文档写入Elasticsearch时,会根据文档字段自动识 别类型,这种机制称之为动态映射。
- 静态映射
静态映射是在Elasticsearch中也可以事先定义好映射,包含文档的各字段类型、分词器 等,这种方式称之为静态映射
注意:动态映射(Dynamic Mapping)的机制,使得我们无需手动定义Mappings, Elasticsearch会自动根据文档信息,推算出字段的类型。但是有时候会推算的不对,例如地理位置信息。当类型如果设置不对时,会导致一些功能无法正常运行。
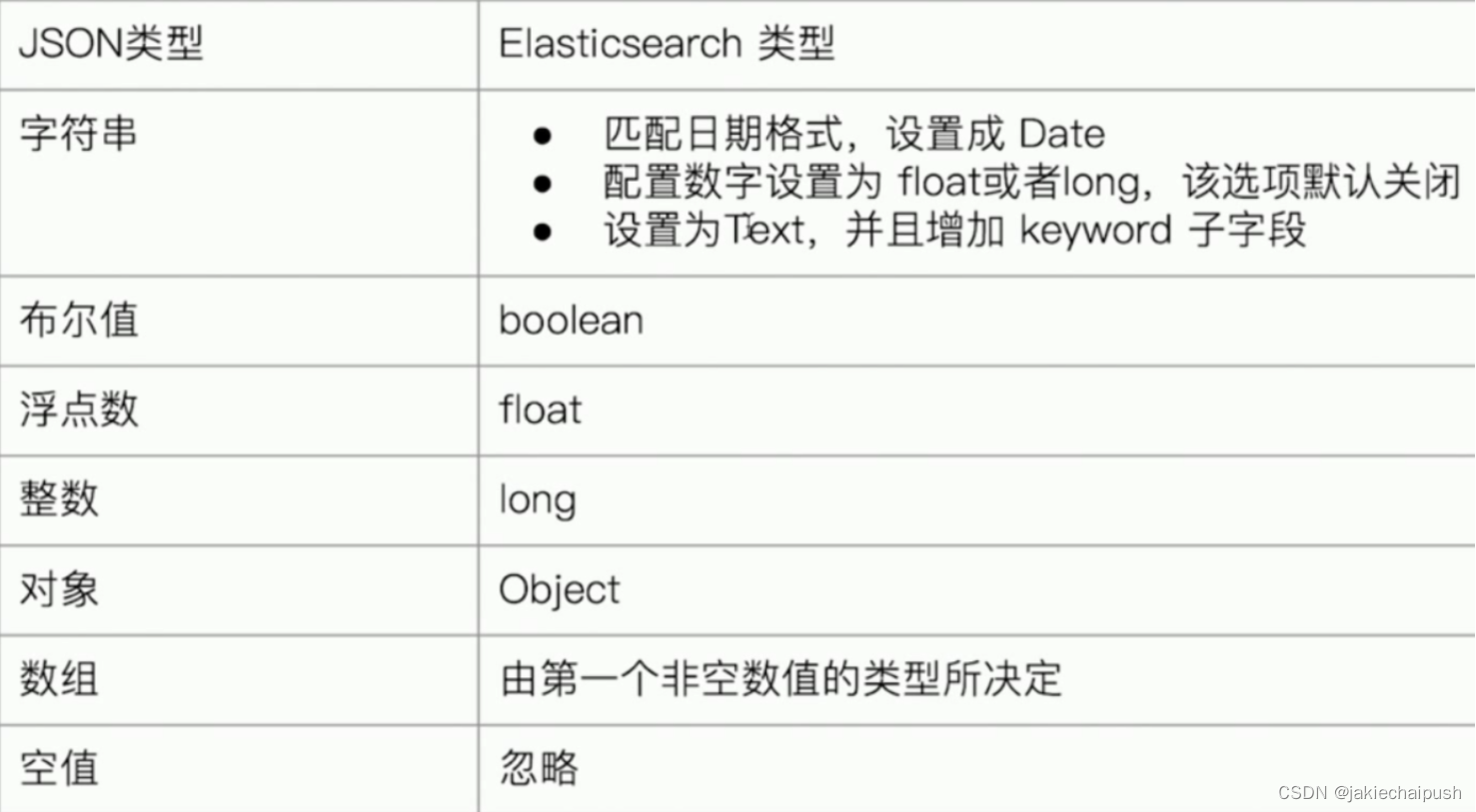
PUT /user/_doc/1
{"name":"jack","age":32,"address":"武汉马房山"
}
上面我们向es中插入了一条文档,我们现在看看es是怎么样帮我们映射mappins的
GET /user/_mapping

- address:帮我们映射成了text类型
- age:帮我们映射成了long类型
- name:帮我映射成了text类型
那么现在我们思考一下,mapping能否修改?这要分两种情况:
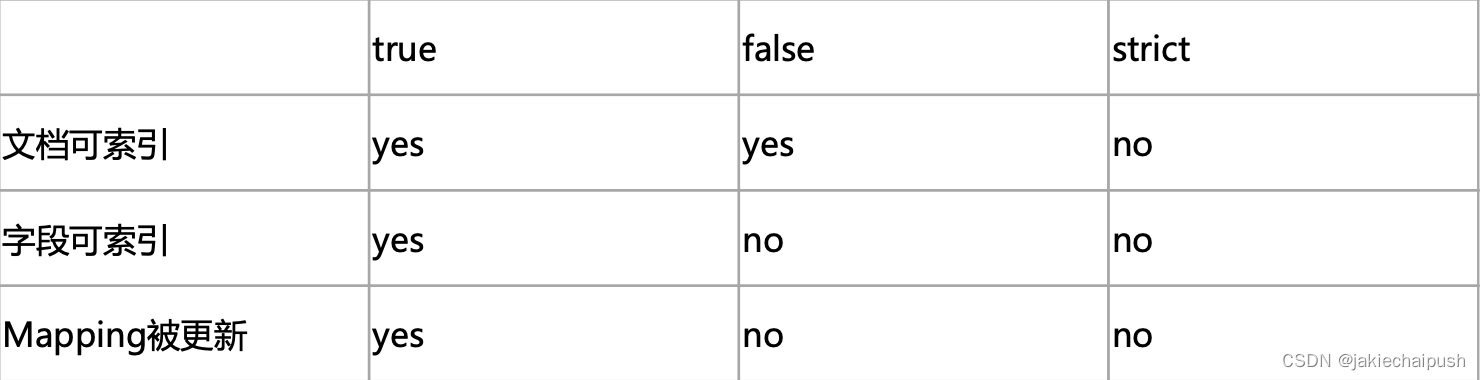
- 新增加字段
dynamic设为true时,一旦有新增字段的文档写入,Mapping 也同时被更新。dynamic设为false,Mapping 不会被更新,新增字段的数据 无法被索引,但是信息会出现在_source中。dynamic设置成strict(严格控制策略),文档写入失败,抛出异常。所以dynamic配置不同我们的es也同样会做出不同的处理。
2. 对已有字段,一旦已经有数据写入,就不再支持修改字段定义
Lucene 实现的倒排索引,一旦生成后,就不允许修改。如果希望改变字段类型,可以利用 reindex API,重建索引,reindex的作用是将数据从一个索引复制到另一个索引(一种数据迁移)。
如果我们修改了原有的字段的数据类型,会导致已经索引的数据无法被检索
PUT /user1
{"mappings": {"dynamic":"strict","properties": {"name":{"type": "text"},"address":{"type": "object","dynamic":"true"}}}
}
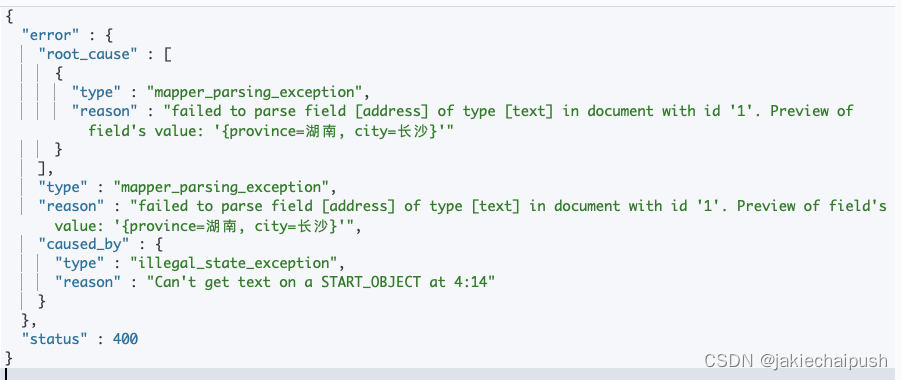
上面我们使用到了静态映射,自己定义了字段的类型,注意dynamic为strict,现在我们插入一条不合法数据。
PUT /user1/_doc/1
{"name": "fox","age": 32,"address": {"province": "湖南","city": "长沙"}
}
可以发现报了mapping解析异常
现在我们修改dynamic为true,再次执行插入就插入成功了
PUT /user1/_mapping
{"dynamic":true }

对已有字段的mapping修改,具体方法是:
- 如果要推倒现有的映射, 你得重新建立一个静态索引
- 然后把之前索引里的数据导入到新的索引里
- 删除原创建的索引
- 为新索引起个别名, 为原索引名
首先我们新建立一个索引,并设置静态映射
PUT /user3
{"mappings": {"properties": {"name":{"type": "text"},"address":{"type": "text","analyzer": "standard"}}}
}
然后将之前索引的数据迁移到新的索引中
POST _reindex
{"source": {"index":"user1"},"dest": {"index": "user3"}
}
删除原来的索引
DELETE user1
给新建立的索引取个别名,名称和原来删除的索引一样
PUT /user3/_alias/user1
//或使用下面语法
PUT /_aliases
{"actions": [{"add": {"index": "user3","alias": "user1"}}]
}
通过这几个步骤就实现了索引的平滑过渡,并且是零停机
- 常见的mapping参数配置
index: 控制当前字段是否能被索引,如果设置为false,es不会为该字段设置倒排索引 |
index_options:有四种不同基本的index options配置,控制倒排索引记录的内容
docs: 记录doc id
freqs:记录doc id 和term frequencies(词频)
positions: 记录doc id / term frequencies / term position
ffsets: doc id / term frequencies / term posistion /character offsets|
对于index_options,text类型默认记录postions,其他默认为 docs。记录内容越多,占用存储空间越大。
如果我们现在想要插入检索空值,注意只有type类型为keyword才能设置空值

copy_to设置:将字段的数值拷贝到目标字段,满足一些特定的搜索需求。 copy_to的目标字段不出现在_source中。
PUT /address
{"mappings": {"properties": {"province":{"type": "keyword","copy_to": "{full_address}"},"city":{"type": "text","copy_to": "{full_address}"}}},"settings": {"index":{"analysis.analyzer.default.type":"ik_max_word"}}
}
映射定义了索引中的字段属性。在这个例子中,定义了两个字段 “province” 和 “city”。“province” 字段的类型是 “keyword”,而 “city” 字段的类型是 “text”。此外,对于两个字段,都定义了 “copy_to” 参数,用于将字段值复制到 “full_address” 字段中。这样做的目的是为了能够在搜索时统一匹配这两个字段的内容。例如,当搜索某个地址时,可以在 “full_address” 字段中查找匹配的内容,而不用分别搜索 “province” 和 “city” 字段。设置定义了索引的配置信息。在这个例子中,设置了 “index” 下的 “analysis.analyzer.default.type” 参数为 “ik_max_word”,表示默认的分析器类型为 IK 中文分词器的 “ik_max_word”。这样配置后,当索引文档时,Elasticsearch 会使用 IK 分词器对文本进行分词处理,以便更好地支持中文搜索。
现在我们插入数据
PUT /address/_bulk
{"index":{"_id":"1"}}
{"province":"湖南","city":"长沙"}
{"index":{"_id":"2"}}
{"province":"湖南","city":"常德"}
{"index":{"_id":"3"}}
{"province":"广东","city":"广州"}
{"index":{"_id":"4"}}
{"province":"湖南","city":"邵阳"}
然后我们现在查询湖南常德:
GET /address/_search
{"query": {"match": {"{full_address}": {"query":"湖南常德","operator":"and"}}}
}
上面代码表示查询的字段就是full_address,然后operator表示操作类型,可以是and或or,ik分词器会将湖南常德分词为湖南和常德,and就表示既要有湖南,又要有常德。所以结果只有id2这一条。
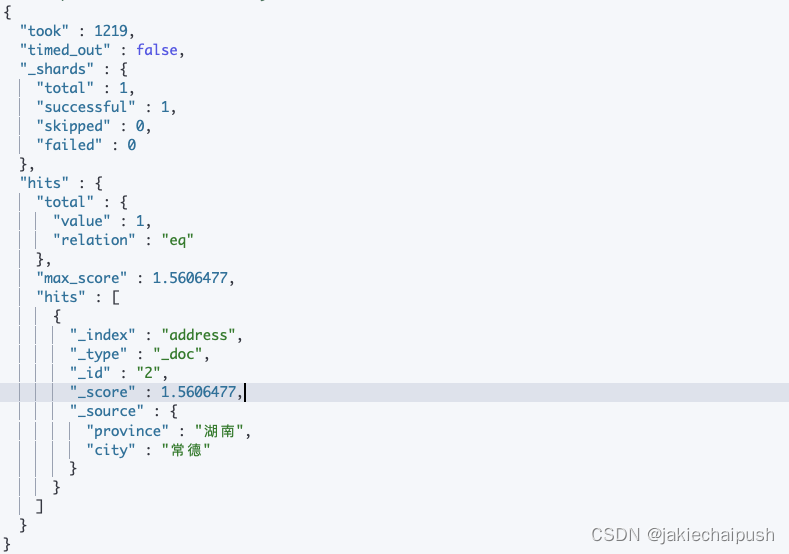
如果是or就会有多条:

2. Index Template
顾名思义,它就是一种索引建立的模版,Index Templates可以帮助你设定Mappings和Settings,并按照一定的规则,自动匹配到新创建的索引之上。Index template定义在创建新index时可以自动应用的settings和mappings。 Elasticsearch根据与index名称匹配的index模式将模板应用于新索引。这个对于我们想创建的一系列的Index具有同样的settings及mappings。比如我们希望每一天/月的日志的index都具有同样的设置。
- 模版仅在一个索引被新创建时,才会产生作用。修改模版不会影响已创建的索引
- 你可以设定多个索引模版,这些设置会被“merge”在一起
- 你可以指定“order”的数值,控制“merging”的过程
PUT /_template/template_default
{"index_patterns": ["*"],"order": 0,"version": 1,"settings": {"number_of_shards": 1,"number_of_replicas": 1}
}
上面就创建了一个Index Template,匹配所有的索引,然后匹配这个模版的索引的分片和副本数量都是1。当一个索引被新创建时,会应用Elasticsearch 默认的settings 和mappings,应用order数值低的lndex Template 中的设定,应用order高的 Index Template 中的设定,之前的设定会被覆盖,应用创建索引时,用户所指定的Settings和 Mappings,并覆盖之前模版中的设
定。
即settings和mappings设置的优先级是:用户设定>Template中Order高的>Template中Order低的>系统默认的
GET /_template/tem*
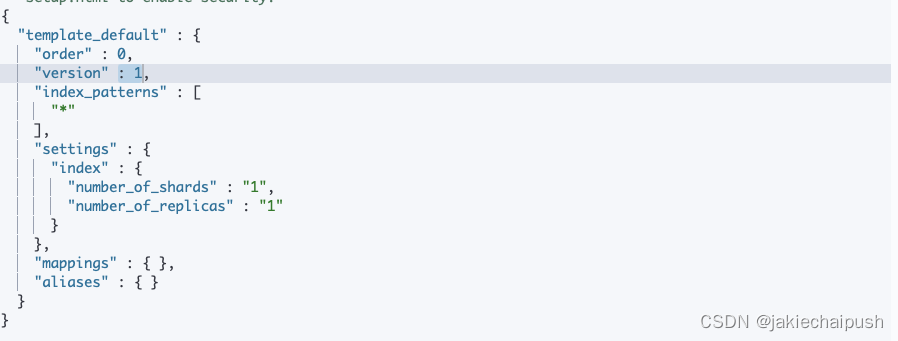
使用GET命令可以查看我们设定的模版的信息
3. DSL
ES中提供了一种强大的检索数据方式,这种检索方式称之为Query DSL(Domain Specified Language) , Query DSL是利用Rest API传递JSON格式的请求体(RequestBody)数据与ES进行交互,这种方式的丰富查询语法让ES检索变得更强大,更简洁。它的基本语法如下:
GET/es_db/_doc/_search{json请求体数据}
GET/es_db/_search{json请求体数据}
下面使用无条件查询语句:
GET /address/_search

_search默认会返回10条数据
PUT /es_db
{"settings": {"index":{"analysis.analyzer.default.type":"ik_max_word"}}
}
上面代码中对es_db文档设定了默认的分词器为ik分词器
PUT /es_db/_doc/1
{"name":"张三","sex":1,"age":25,"address":"广州天河公园","remark":"javadeveloper"
}PUT /es_db/_doc/2
{"name":"李四","sex":1,"age":28,"address":"广州荔湾大厦","remark":"javaassistant"
}
PUT /es_db/_doc/3
{"name":"王五","sex":0,"age":26,"address":"广州白云山公园","remark":"phpdeveloper"
}
PUT /es_db/_doc/4
{"name":"王五","sex":0,"age":26,"address":"广州白云山公园","remark":"phpdeveloper"
}PUT /es_db/_doc/5
{"name":"张龙","sex":0,"age":19,"address":"长沙麓谷企业广场","remark":"javaarchitectassistant"
}
PUT /es_db/_doc/6
{"name":"赵虎","sex":1,"age":32,"address":"长沙麓谷兴工国际产业园","remark":"javaarchitect"
}
上面向es_db索引库中插入了多条文档,_search查询默认采用的是分页查询,每页记录数size的默认值为10,如果想显示更多数据,可以指定size。match_all默认只会返回10条数据。
GET/es_db/_search
#等同于
GET /es_db/_search
{"query": {"match_all": {}}
}
##返回指定条数size,
GET /es_db/_search
{"query": {"match_all": {}},"size": 20
}
我们现在思考一个问题,size可以无限增加吗?我们测试一下:
GET /es_db/_search
{"query": {"match_all": {}},"size": 20000
}
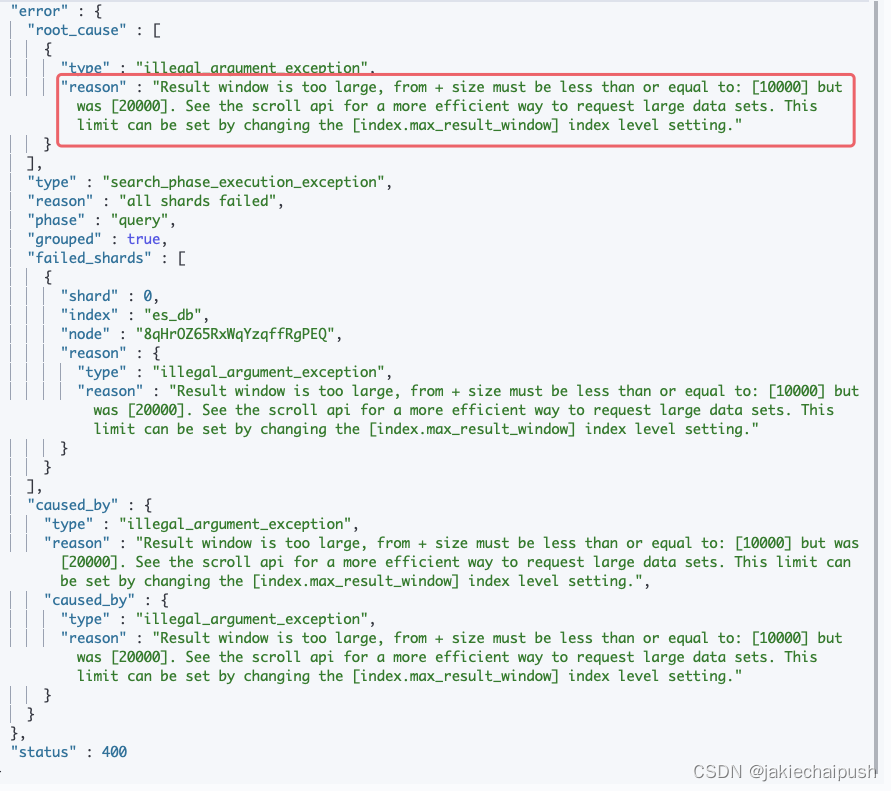
可以发现出现了异常,从错误信息可以看出来,查询结果的窗口太大,from + size的结果必须小于或等于10000,而当前查询结果的窗口为20000,我们可以采用scroll api更高效的请求大量数据集,查询结果的窗口的限制可以通过参数index.max_result_window进行设置。
PUT /es_db/_settings
{"index.max_result_window" :"20000"
}
//修改现有所有的索引,但新增的索引,还是默认的10000
PUT /_all/_settings
{"index.max_result_window" :"20000"
}
参数index.max_result_window主要用来限制单次查询满足查询条件的结果窗口的大小,窗口大小由from + size共同决定。不能简单理解成查询返回给调用方的数据量。这样做主要是为了限制内存的消耗。
比如:from为1000000,size为10,逻辑意义是从满足条件的数据中取1000000到 (1000000 + 10)的记录。这时ES一定要先将(1000000 + 10)的记录(即 result_window)加载到内存中,再进行分页取值的操作。尽管最后我们只取了10条数据返 回给客户端,但ES进程执行查询操作的过程中确需要将(1000000 + 10)的记录都加载到内存中,可想而知对内存的消耗有多大。这也是ES中不推荐采用(from + size)方式进行深度分页的原因。同理,from为0,size为1000000时,ES进程执行查询操作的过程中确需要将1000000 条记录都加载到内存中再返回给调用方,也会对ES内存造成很大压力。
- 分页查询from
from 关键字: 用来指定起始返回位置,和size关键字连用可实现分页效果
GET /es_db/_search
{"query": {"match_all": {}},"size": 5,"from": 0
}
- 深分页查询Scroll
改动index.max_result_window参数值的大小,只能解决一时的问题,当索引的数据量持续增长时,在查询全量数据时还是会出现问题。而且会增加ES服务器内存大结果集消耗完 的风险。最佳实践还是根据异常提示中的采用scroll api更高效的请求大量数据集。
es的分页查询看这条博客:https://zhuanlan.zhihu.com/p/624297206?utm_id=0
GET /es_db/_search?scroll=1m
{"query": {"match_all": {}},"size": 2
}
查询命令中新增scroll=1m,说明采用游标查询,保持游标查询窗口一分钟,实际使用中为了减少游标查询的次数,可以将值适当增大,比如设置为1000。

可以发现返回了一条scroll_id,下一次查询就可以从这个游标开始接着查询。
多次根据scroll_id游标查询,直到没有数据返回则结束查询。采用游标查询索引全量数据, 更安全高效,限制了单次对内存的消耗
- 对字段进行排序
这里注意一点使用排序的时候会让评分失效
#根据年龄将降序查询
GET /es_db/_search
{"query": {"match_all": {}},"sort": [{"age": {"order": "desc"}}]
}
//在排序的基础上加入了分页查询
GET /es_db/_search
{"query": {"match_all": {}},"sort": [{"age": {"order": "desc"}}],"from": 0,"size": 2
}
- 返回指定字段_source
GET /es_db/_search
{"query": {"match_all": {}},"_source": ["name","address"]
}

从结果看一看出返回的文档原生信息中只有address和name两个字段
- Match
match在匹配时会对所查找的关键词进行分词,然后按分词匹配查找,match支持以下参数:
- query : 指定匹配的值
- operator : 匹配条件类型,and : 条件分词后都要匹配,or : 条件分词后有一个匹配即可(默认)
- minmum_should_match : 最低匹配度,即条件在倒排索引中最低的匹配度
GET /es_db/_search
{"query": {"match": {"address": "广州白云山公园"}}
}

由结果可以知道对
广州白云山公园进行了分词,并查询结果为or类型,即只要匹配到一个分词就可以返回结果
GET /es_db/_search
{"query": {"match": {"address": {"query": "广州白云山公园","operator": "AND"}}}
}

可以看到此时只有匹配
广州白云山公园分词的所有的各个分词才会返回结果。在match中的应用: 当operator参数设置为or时,minnum_should_match参数用来控制匹配的分词的最少数量。
GET /es_db/_search
{"query": {"match": {"address": {"query": "广州公园","minimum_should_match": 2}}}
}

可以发现匹配到2个分词就可以返回结果了
- 短语查询match_phrase
match_phrase查询分析文本并根据分析的文本创建一个短语查询。match_phrase 将会检索关键词分词。match_phrase的分词结果必须在被检索字段的分词中都包含,而且顺序必须相同,而且默认必须都是连续的。
GET /es_db/_search
{"query": {"match_phrase": {"address": "广州白云山"}}
}

我们可以看看ik分词器的分词结果为下:

我们看看其它词的分词效果:
POST /_analyze
{"analyzer": "ik_max_word","text": "广州白云山公园"
}
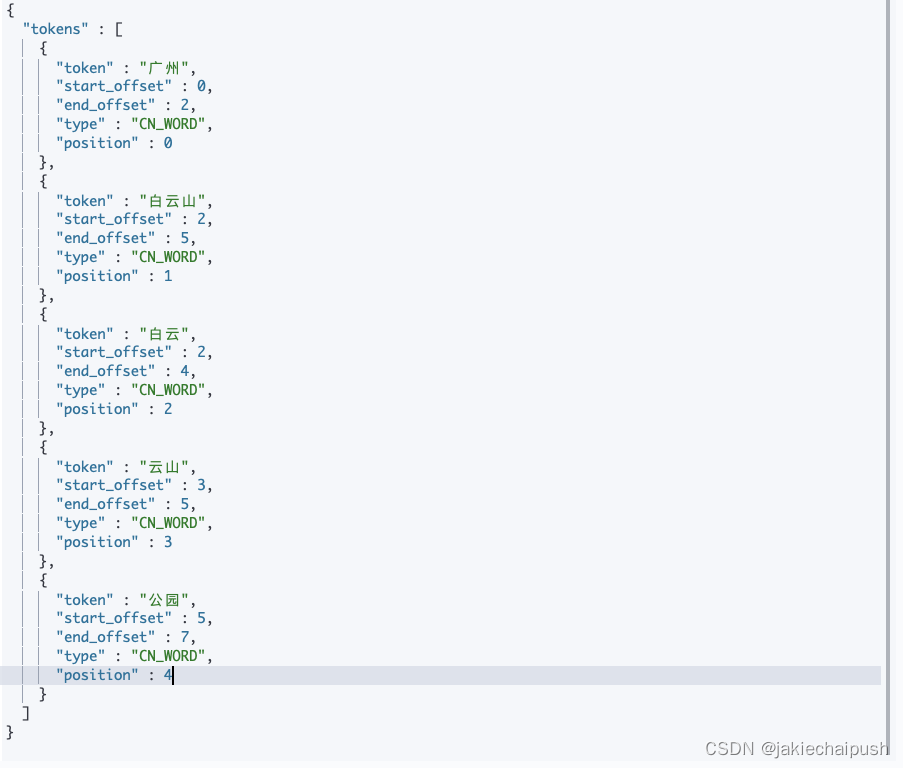
可以看出广州白云山和广州白云山公园的分词,后者的分词结果包含前者的分词结果,并且顺序一样。现在我们的需求是,如果顺序不是一样的,多个分词之间还隔有其它分析,我们可以借助slop参数,slop参数告诉match_phrase查询词条能够 相隔多远时仍然将文档视为匹配。
GET /es_db/_search
{"query": {"match_phrase": {"address": {"query": "广州云山"}}}
}

我们现在设置一下slop
GET /es_db/_search
{"query": {"match_phrase": {"address": {"query": "广州云山","slop": 2}}}
}

先查看广州白云山公园分词结果,可以知道广州和白云不是相邻的词条,中间会隔一个白云山,而match_phrase匹配的是相邻的词条,所以查询广州白云山有结果,但查询广州白云没有结果。
- 多字段查询multi_match
可以根据字段类型,决定是否使用分词查询,得分最高的在前面
GET /es_db/_search
{"query": {"multi_match": {"query": "长沙张龙","fields": ["address","name"]}}
}
字段类型分词,将查询条件分词之后进行查询,如果该字段不分词就会将查询条件作为整体进行查询。

“query"字段中指定了要搜索的关键词,这里是"长沙张龙”。"fields"字段中指定了要在哪些字段中搜索,这里是"address"和"name"两个字段。这个查询的意思是:在"address"和"name"字段中搜索包含"长沙张龙"这个词语的文档。本质上就是对
长沙张龙进行分词,然后分词到我们指定的字段中进行匹配。
- query_string
允许我们在单个查询字符串中指定AND | OR | NOT条件,同时也和 multi_match query一样,支持多字段搜索。和match类似,但是match需要指定字段名,query_string是在所有字段中搜索,范围更广泛。
首先我们可以不指定字段查询:
GET /es_db/_search
{"query": {"query_string": {"query": "张三 OR 橘子洲"}}
}
我们没有指定字段查询,它会到所有字段进行查询,我们同时还可以指定一个字段或多个字段进行查询:
GET /es_db/_search
{"query": {"query_string": {"default_field": "address","query": "白云山 OR 橘子洲"}}
}GET /es_db/_search
{"query": {"query_string": {"default_field": ["name","address"],"query": "白云山 OR 橘子洲"}}
}
- simple_query_string
类似Query String,但是会忽略错误的语法,同时只支持部分查询语法,不支持AND OR NOT,会当作字符串处理。支持部分逻辑:
+ 替代AND | 替代OR
- 替代NOT
GET /es_db/_search
{"query": {"simple_query_string": {"query": "广州+公园","fields": ["name","address"]}}
}
- 关键词查询Term
Term用来使用关键词查询(精确匹配),还可以用来查询没有被进行分词的数据类型。Term是表达语意的最小单位,搜索和利用统计语言模型进行自然语言处理都需要处理Term。 match在匹配时会对所查找的关键词进行分词,然后按分词匹配查找,而term会直接对关 键词进行查找。一般模糊查找的时候,多用match,而精确查找时可以使用term。
ES中默认使用分词器为标准分词器(StandardAnalyzer),标准分词器对于英文单词分词,对于中文单字分词。
在ES的Mapping Type 中 keyword , date ,integer, long , double , boolean or ip 这些类型不分词,只有text类型分词。
//广州白云在倒排索引中匹配
GET /es_db/_search
{"query": {"term": {"address": {"value": "广州白云"}}}
}
//精确匹配
GET /es_db/_search
{"query": {"term": {"address.keyword": {"value": "广州白云山公园"}}}
}
在ES中,Term查询,对输入不做分词。会将输入作为一个整体,在倒排索引中查找准确的 词项,并且使用相关度算分公式为每个包含该词项的文档进行相关度算分。
创建新的索引库:
PUT /product/_bulk
{"index":{"_id":1}}
{"productId":"xxx123","productName":"iPhone"}
{"index":{"_id":2}}
{"productId":"xxx111","productName":"iPad"}
我们进行查询:
GET /product/_search
{"query": {"term": {"productName": {"value": "iPhone"}}}
}

可以发现查询结果为空,这是为什么呢,我们查询是term,然后关键词是iPhone,然后到倒排索引中查询,发现没有发现iPhone,这是因为iPhone在倒排索引中会被转化为小写iphone,所以查询不到。所以对于英文,我们可以设置忽略大小写:
PUT /product
{"settings": {"analysis": {"normalizer": {"es_normalizer": {"filter": ["lowercase","asciifolding"],"type": "custom"}}}},"mappings": {"properties": {"productId": {"type": "text"},"productName": {"type": "keyword","normalizer": "es_normalizer","index": "true"}}}
}
现在就可以忽略大小写了,我仔细看看上面的查询结果,发现有max_socre,说明在使用Trem的时候,es还是会对结果进行算分,但有时我们需要的是精确查询,算分可能会影响性能,我们可以通过 Constant Score 将查询转换成一个 Filtering,避免算分,并利用缓存,提高性能。
将Query 转成 Filter,忽略TF-IDF计算,避免相关性算分的开销 Filter可以有效利用缓存,Filter可以有效利用缓存
GET /es_db/_search
{"query": {"constant_score": {"filter": {"term": {"address.keyword": "广州白云山公园"}}}}
}

- ES中的结构化搜索
结构化搜索(Structured search)是指对结构化数据的搜索,应用场景:对bool,日期,数字,结构化的文本可以利用term做精确匹配。
应用场景:对bool,日期,数字,结构化的文本可以利用term做精确匹配
GET /es_db/_search
{"query": {"term": {"age": {"value": "23"}}}
}
- 前缀查询
它会对分词后的term进行前缀搜索。它不会分析要搜索字符串,传入的前缀就是想要查找的前缀,默认状态下,前缀查询不做相关度分数计算,它只是将所有匹配的文档返回,然 后赋予所有相关分数值为1。它的行为更像是一个过滤器而不是查询。两者实际的 别就是过滤器是可以被缓存的,而前缀查询不行。
prefix的原理:需要遍历所有倒排索引,并比较每个term是否已所指定的前缀开头。
GET /es_db/_search
{"query": {"prefix": {"address": {"value": "广州"}}}
}

- 通配符查询wildcard
通配符查询:工作原理和prefix相同,只不过它不是只比较开头,它能支持更为复杂的匹配模式。
GET /es_db/_search
{"query": {"wildcard": {"address": {"value": "*白*"}}}
}

- 范围查询
gte 大于等于,lte 小于等于,gt 大于,lt 小于,now 当前时间
POST /es_db/_search
{"query": {"range": {"age": {"gte": 25,"lte": 28}}}
}

- 多id查询
ids 关键字 : 值为数组类型,用来根据一组id获取多个对应的文档
GET /es_db/_search
{"query": {"ids": {"values": [1,2]}}
}

- 模糊查询
在实际的搜索中,我们有时候会打错字,从而导致搜索不到。在Elasticsearch中,我们可以使用fuzziness属性来进行模糊查询,从而达到搜索有错别字的情形。fuzzy 查询会用到两个很重要的参数,fuzziness,prefix_length:
- fuzziness:表示输入的关键字通过几次操作可以转变成为ES库里面的对应field的字段,操作是指:新增一个字符,删除一个字符,修改一个字符,每 次操作可以记做编辑距离为1,如中文集团到中威集团编辑距离就是1,只需要修改一个字符;如果fuzziness值在这里设置成2,会把编辑距离为2的东东集团也查出来。该参数默认值为0,即不开启模糊查询。
- prefix_length:表示限制输入关键字和ES对应查询field的内容开头的第n个字符必须完全匹配,不允许错别字匹配,如这里等于1,则表示开头的字必须匹配,不匹配则不返回,加大prefix_length的值可以提高效率和准确率,默认值也是0。
GET /es_db/_search
{"query": {"fuzzy": {"address": {"value": "白运山","fuzziness": 1}}}
}

注意: fuzzy 模糊查询最大模糊错误 必须在0-2之间
- 搜索关键词长度为 2,不允许存在模糊
- 搜索关键词长度为3-5,允许1次模糊
- 搜索关键词长度大于5,允许最大2次模糊
- 高亮
highlight 关键字: 可以让符合条件的文档中的关键词高亮。highlight相关属性如下:
pre_tags 前缀标签
post_tags 后缀标签
tags_schema 设置为styled可以使用内置高亮样式
require_field_match 多字段高亮需要设置为false
GET /es_db/_search
{"query": {"term": {"address": {"value": "广州"}}},"highlight": {"post_tags": ["</span>"],"pre_tags": ["<span style='color:red'>"],"fields": {"*":{}}}
}