作者 | Python
之前,复旦大学的研究者让ChatGPT参加了中国高考,发现成绩惨不忍睹(参见推送),其中理科数学竟只有20多分。这次,小米AI lab的研究者们给模型降低一下难度,找了1700道中国小学数学题,测试了10个大语言模型。实验表明,ChatGPT只能通过小学4年级水平,而GPT-4可以小学毕业。同时,国产大模型如Baichuan、MOSS、ChatGLM2等表现较差。让我们来看看吧。
论文题目:
CMATH: Can Your Language Model Pass Chinese Elementary School Math Test?
论文链接:
https://arxiv.org/pdf/2306.16636.pdf
大模型研究测试传送门
GPT-4能力研究传送门(遇浏览器警告点高级/继续访问即可):
https://gpt4test.com
数据集
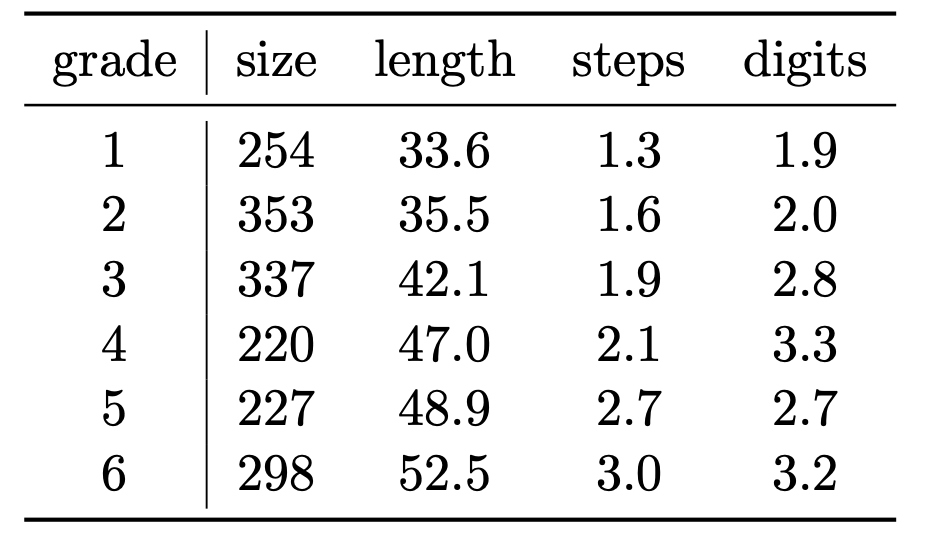
本实验使用的小学数学题数据集CMATH获取自开源的小学练习册和考卷。如下图所示,每道题标注了年级(Grade),推理步数(#Steps)与最大有效数字位数(#Digits)来标示难度。

实验结果
实验设置上,作者只采用了零监督设置,没有使用CoT等技巧。作者表示这样才能最原生态地评价大模型。但这样可能也会让模型表现偏低。
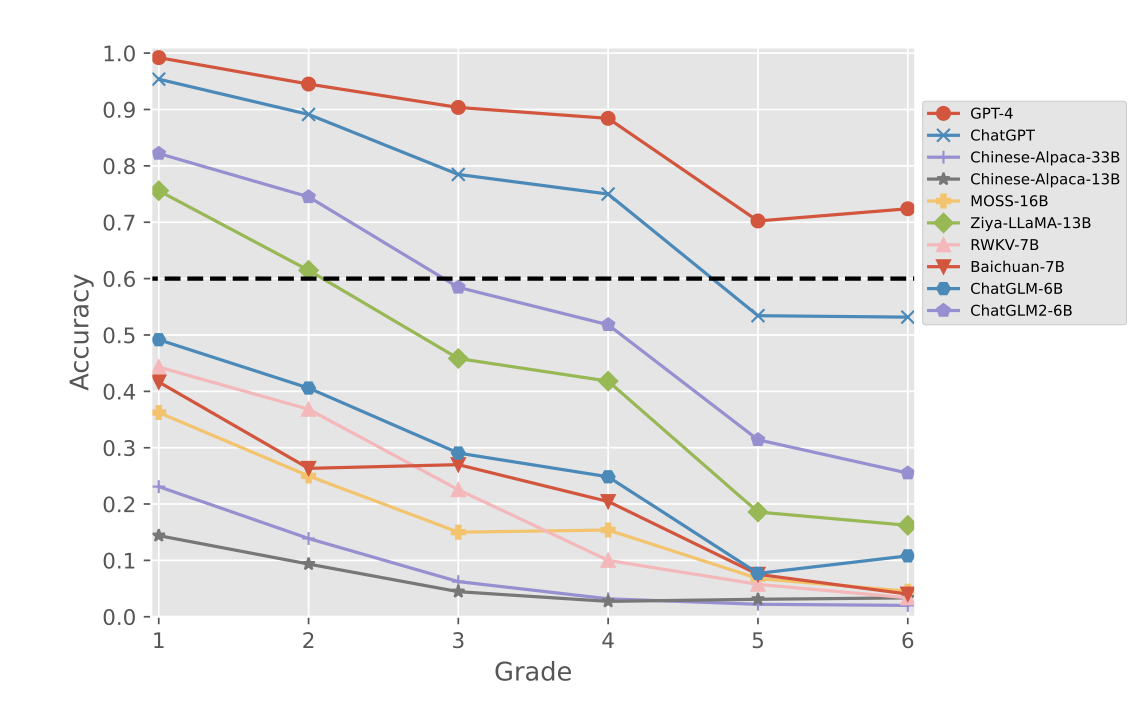
各个年级的题目上,实验结果如下图所示。可以看到,GPT-4可以在所有年级的题目中拿到60分以上的成绩,而ChatGPT只能达到4年级及格的水平。国产大模型中,只有ChatGLM2与Ziya-LLaMA-13B能达到2年级及格的水平,其它模型在一年级的问题中也都难以得到50分以上的成绩。
不过,即使GPT-4成绩相对最好,大家回想一下自己小学时的成绩,可能还是要比GPT-4强不少的。
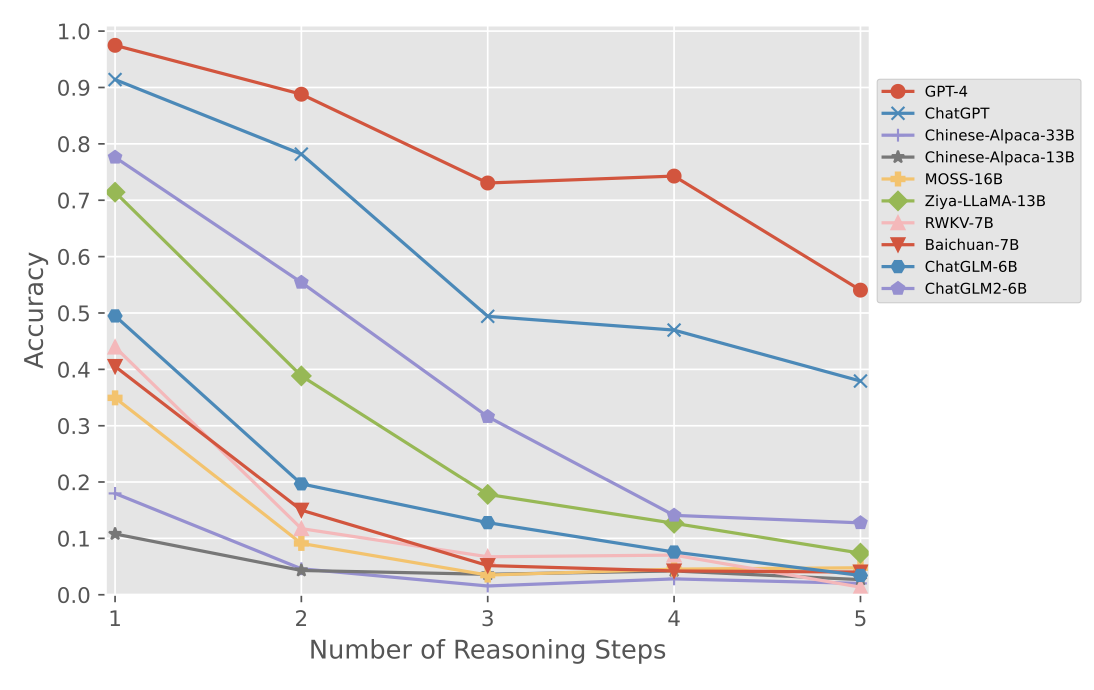
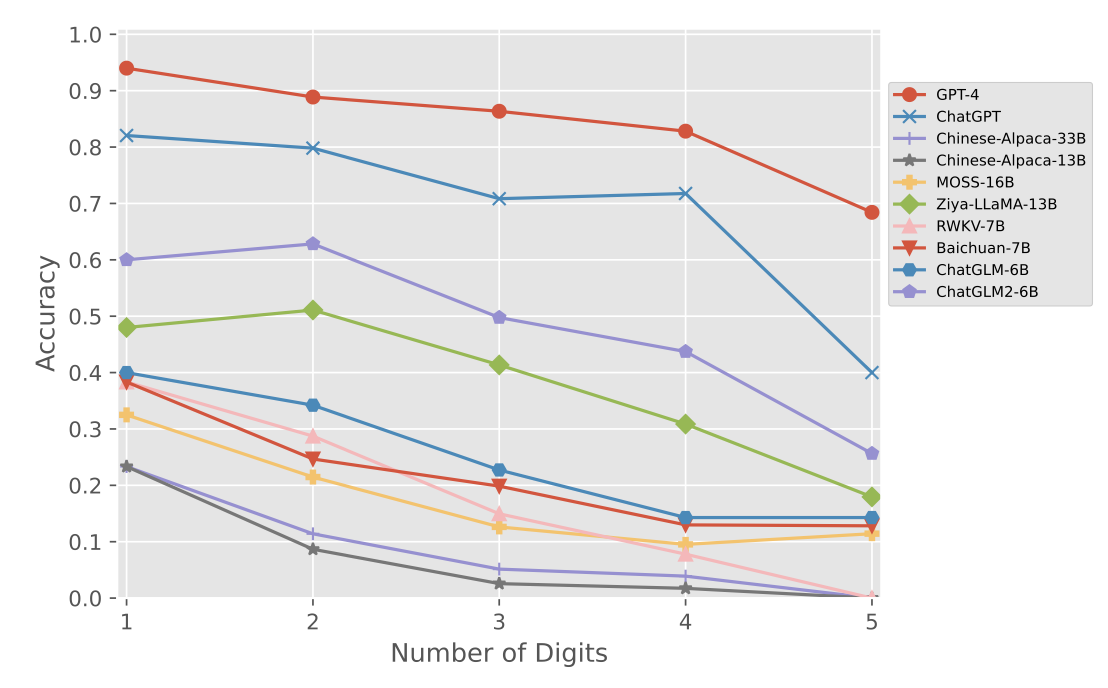
接下来观看不同模型对需要不同推理步骤的问题,与不同计算位数的问题的表现,也可以看出,当推理步数较多或数字位数较大时,国产大模型表现下滑明显。
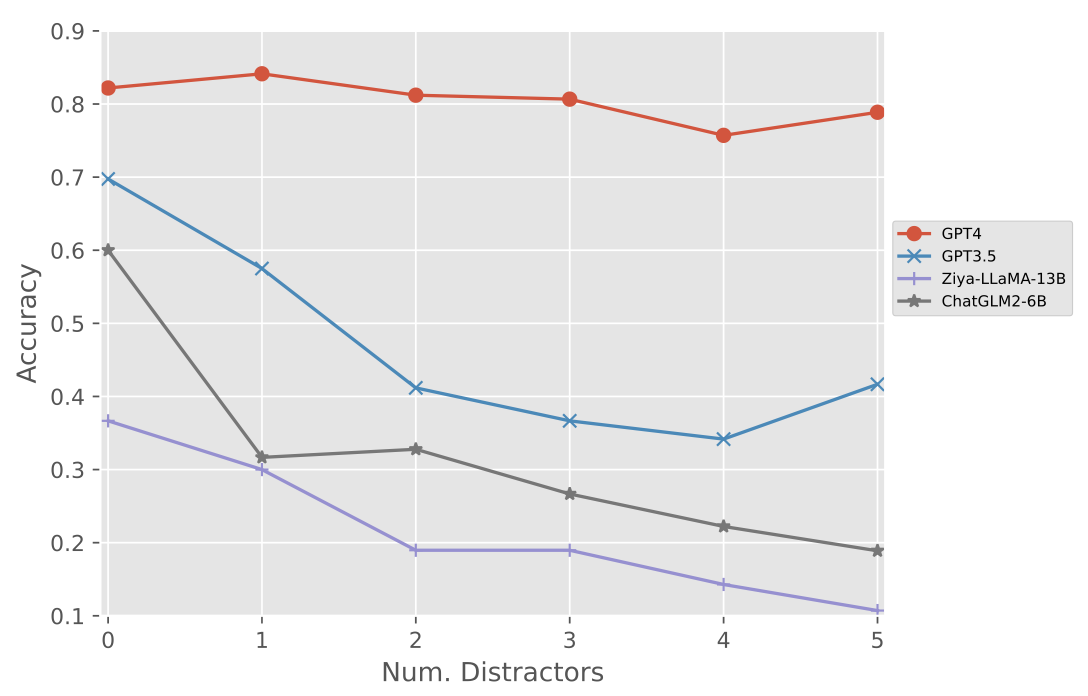
作者还尝试在问题中增加干扰条件(Distractors)来检测大模型的鲁棒性。
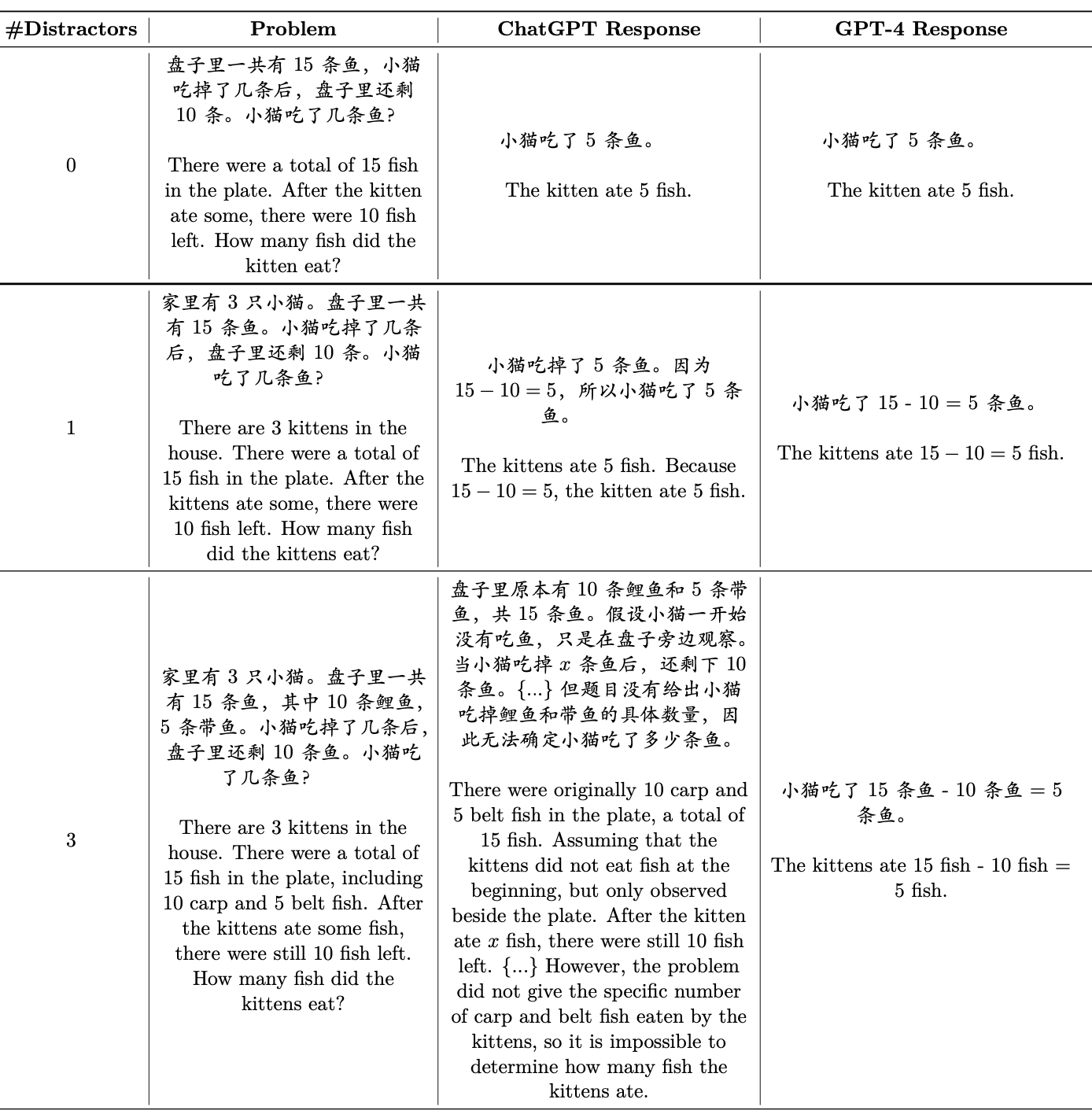
实验结果表明,GPT-4具有较强的抗干扰能力,而其他大模型在抗干扰上表现不佳。
总结
该文用中国小学数学题测试了GPT-4、ChatGPT与国产大模型。实验结果表明,GPT-4可以较好地解答中文小学数学题,但和人类相比还有差距;即使是面对中文试题,国产大模型与OpenAI的产品之间还有很大距离,我们还需要进一步加强国产大模型的研究。
大模型AI全栈手册
行业首份AI全栈手册开放下载啦!!
长达3000页,涵盖大语言模型技术发展、AIGC技术最新动向和应用、深度学习技术等AI方向。
微信公众号关注“夕小瑶科技说”,回复“789”下载资料
![[图片]](https://img-blog.csdnimg.cn/72fe161362264a8292b239e5e6a822d0.png)






![new bing 使用出现“”]Sorry, looks like your network settings are preventing access to this feature.解决方法](https://img-blog.csdnimg.cn/b6e5bfda930045f9a1c5f79ffd36ae1d.png)