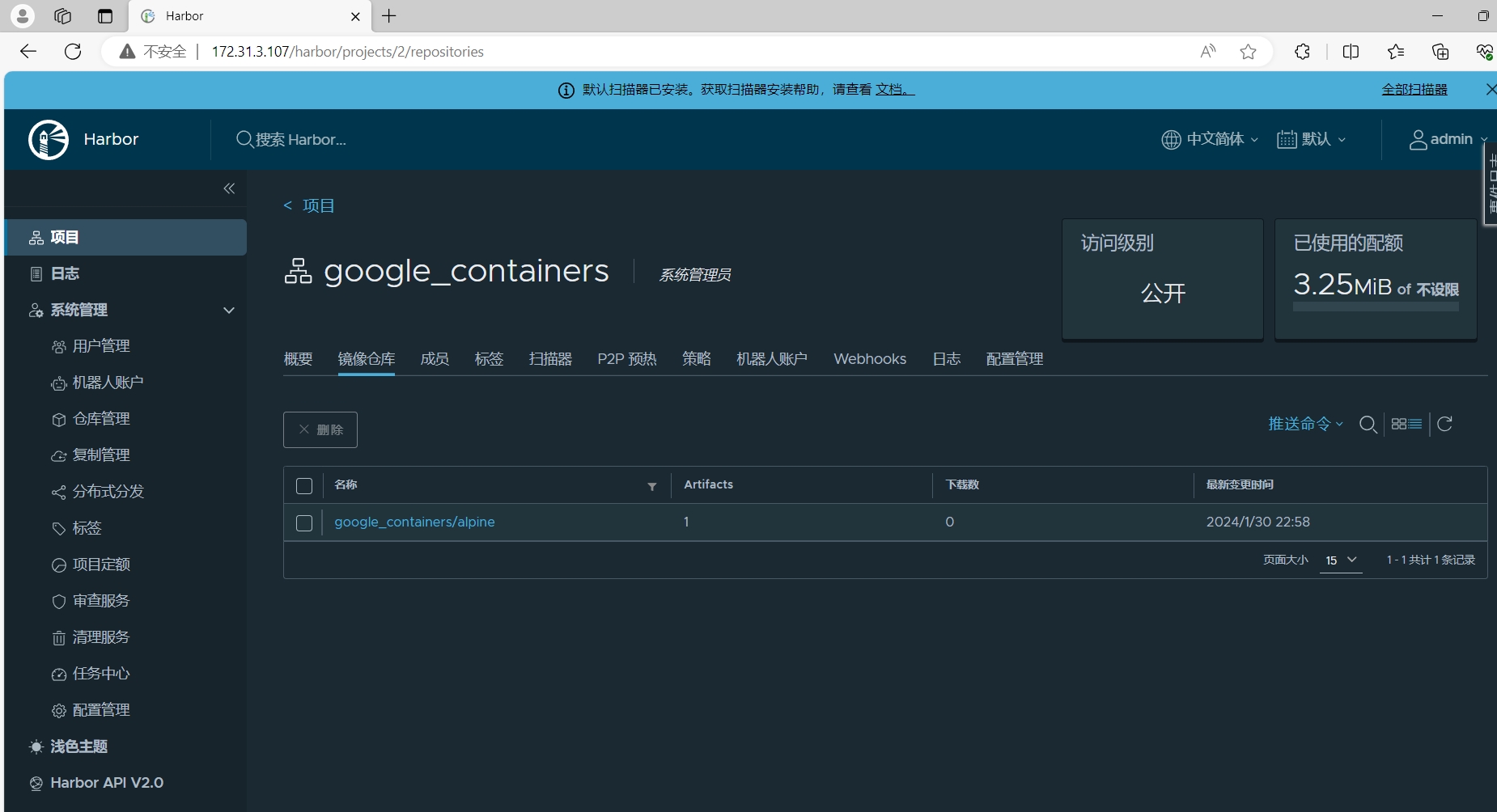
目录
一.概念浅析
1.存内计算
2.忆阻器
3.基于忆阻器的存内计算
二.忆阻器的分类
1.磁效应忆阻器
2 .相变效应忆阻器
3 .阻变效应忆阻器
三.基于忆阻器的存内计算原理
1. 利用二值忆阻器的布尔计算
3.1R-R 逻辑运算
3.2V-R 逻辑运算
3.3V-V 逻辑运算
2. 利用模拟型忆阻器的模拟计算
四.存内计算的实验研究
一.概念浅析
1.存内计算
存内计算(In-Memory Computing,简称 IMC)是一种将数据处理和存储紧密结合在一起的计算方式。它的主要思想是在存储设备中直接进行计算,而不是像传统计算那样,在处理器和内存之间频繁地传输数据。
存内计算的优势在于可以大大减少数据移动的次数,从而降低能耗和延迟。由于数据处理在存储设备内完成,不需要将数据传输到处理器进行计算,因此可以提高系统的效率和响应速度。此外,存内计算还可以通过利用存储设备的并行性,实现高效的并行计算。
在实际应用中,存内计算通常使用特定的存储器件,如闪存、相变存储器(Phase-Change Memory,PCM)或电阻式随机存取存储器(Resistive Random Access Memory,RRAM)等。这些存储器件不仅可以存储数据,还可以执行简单的计算操作,如加法、乘法或比较等。
存内计算在一些领域有着广泛的应用前景,例如人工智能、大数据处理、神经网络、数据库查询等。它可以提高这些应用的性能、能效和实时性,尤其在处理大量数据时效果更为显著。
2.忆阻器
忆阻器(Memristor),全称为记忆电阻器,是一种有记忆功能的非线性电阻,是电阻、电容、电感之外的第四种电路基本元件,具有高速、低功耗、高集成度、兼具信息存储与计算功能等特点,被认为是最有潜力的未来逻辑运算器件。
3.基于忆阻器的存内计算
忆阻器作为一种新颖的存储器技术,具有非易失性、快速切换和低操作能耗等优异特性,成为面向新型人工智能的存内计算系统的候选之一。
基于忆阻器的存内计算,是指利用忆阻器的电阻可变特性,在存储单元中直接完成计算操作,从而避免了数据在内存和处理器之间的频繁传输,提高了计算效率和能效比。这种计算方式可以应用于高维计算技术领域,例如机器学习、图像处理、模式识别等。
目前 ,人们利用能并行处理数据的 GPU (graphics processing unit)或者针对数据流设计的专用加速芯片 ,如 TPU (tensor processing unit)等硬件进行加速以满足算力需求。这类加速硬件一般有较 强的并行处理能力和较大的数据带宽,但是存储和计算单元在空间上依旧是分离的。与冯 · 诺依曼计算平台不同 ,具有大规模并行 、自适应 、自学习特征的人脑中,信息的存储和计算没有明确的分界线, 都是利用神经元和突触来完成的。人们开始研究新型的纳米器件 ,希望能够模拟神经元和突触的特性。在这类纳米器件中,忆阻器因与突触的特性十分相似且具有巨大的潜力而备受青睐。突触可 以根据前后神经元的激励来改变其权重 ,而忆阻器 则可以通过外加电压的调制来改变其电导值。新型的忆阻器包括磁效应忆阻器 、相变效应忆 阻器和阻变效应忆阻器等。其中 ,阻变效应忆阻器 包含了基于阴离子的氧空位通道型阻变忆阻器和基 于阳离子型的导电桥型忆阻器(conductive bridging RAM, CBRAM)两类。氧空位通道型阻变忆阻器也 直接被称为 RRAM。新型忆阻器有读写速度快 、 集成密度高、低功耗等优势 ,这也为存内计算带来了更多的好处。
二.忆阻器的分类
1.磁效应忆阻器
磁效应忆阻器是一种利用磁场对电阻状态进行控制的忆阻器。它通常由磁性材料和电极组成,通过改变磁场的强度或方向来改变忆阻器的电阻值。
当施加外部磁场时,磁性材料中的磁极会发生变化,从而导致电阻值的改变。这种电阻变化可以用来存储信息或实现逻辑运算。
磁效应忆阻器具有非易失性、快速响应、低能耗等优点,因此在存储器件、神经网络、模拟计算等领域具有潜在的应用前景。
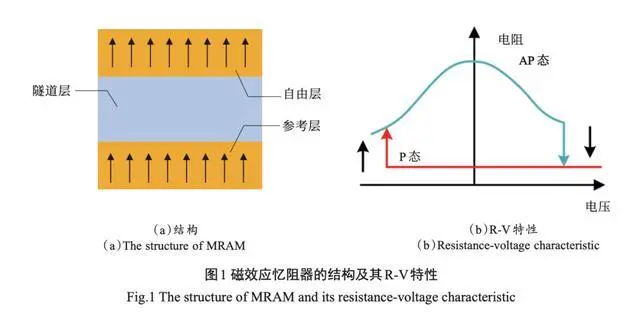
磁效应忆阻器的工作原理基于磁性材料对磁场的响应。一般来说,它由一个磁性层和一个导电层组成,两者之间通过一层绝缘层隔开。
当施加外部磁场时,磁性层中的磁极会发生对齐或反转,这会导致磁性层与导电层之间的界面电阻发生变化。具体的电阻变化取决于磁性层的材料和结构,以及磁场的强度和方向。
这种电阻变化可以用来存储信息,例如通过将不同的电阻状态与不同的逻辑值或数据位相对应。在读取信息时,可以通过检测电阻值来获取存储的信息。
此外,磁效应忆阻器的工作原理还可以与其他电子元件相结合,例如晶体管、电容器等,以实现更复杂的电路和功能。
2 .相变效应忆阻器
相变效应忆阻器是一种利用材料的相变来实现电阻变化的忆阻器。相变材料在一定的温度或电流下,会发生从一种相态到另一种相态的转变,从而导致电阻值的变化。
常见的相变材料包括硫族化合物(如 GeSbTe)、氧化物(如 VO2)等。当相变材料处于不同的相态时,其电阻值会有明显的差异。通过控制电流或温度等条件,可以使相变材料在不同的相态之间切换,从而实现电阻值的变化和信息的存储。
相变效应忆阻器具有高速、低能耗、高密度等优点,并且可以实现非易失性存储,即在断电后仍能保留存储的信息。它在存储器、神经网络、模拟计算等领域有着潜在的应用前景。
相变效应忆阻器的发展历程可以追溯到 20 世纪 60 年代,当时人们首次发现了某些材料在相变过程中电阻会发生显著变化的现象。然而,由于技术和材料限制,相变效应忆阻器的研究进展相对缓慢。
在 21 世纪初,随着纳米技术和材料科学的发展,对相变效应忆阻器的研究逐渐增多。研究人员开始探索各种相变材料,并尝试将其应用于存储器和神经网络等领域。
近年来,相变效应忆阻器的研究取得了一些重要突破。例如,在材料选择和制备方面,人们发现了一些具有更好相变性能的新材料,提高了忆阻器的性能和可靠性。同时,在器件结构和工作机制的研究上也取得了进展,使得相变效应忆阻器的应用更加多样化。
相变效应忆阻器的结构包含了顶层 、底层电极和相变材料层。在相变材料层里 ,可编程区的晶态决定了相变效应忆阻器的阻态。可编程区为非晶态时 ,相变材料的电阻率高,忆阻器的阻值也就较大;为多晶态时,相变材料的电阻率低,相应的忆阻器阻值也就较小。忆阻器从高阻态( high- resistance state ,HRS )转 变 为 低 阻 态( low- resistance state,LRS)的过程是“SET”过程;反之,从LRS 到 HRS 的过程就是“RESET”过程。
在 SET 过 程中 ,在相变效应忆阻器两端施加较小的幅度的电 压脉冲 ,产生的热量使其温度介于熔点和结晶温度 之间 ,然后进行适合时间的退火 ,对应着较缓的脉冲下降沿 ,可以引起相变材料结晶 ,转变为多晶态, 此时其阻值较小。而在 RESET 过程中 ,施加较大幅 度的电压脉冲来淬火,其电压脉冲的下降沿较陡 , 就会导致编程区局部熔化 ,转化为非晶态 ,此时其 阻值较大。通过电压脉冲来调制可编程区的多晶 态和非晶态的相对比例,可以实现相变效应忆阻器 的多级阻态。RESET 的多级阻变特性比 SET 差 ,这 是因为在 RESET 的过程中 ,准确把握淬火的程度相对困难。

3 .阻变效应忆阻器
阻变效应忆阻器是一种利用电阻变化来存储信息的器件。它的工作原理基于材料中的阻变效应,即电阻在外部刺激下(如电压、电流或光等)发生可逆的变化。
当施加特定的刺激时,阻变效应忆阻器的电阻会在高阻态和低阻态之间切换,这种切换可以用来表示二进制的“0”和“1”,从而实现信息的存储。阻变效应忆阻器的优点包括尺寸小、速度快、能耗低和可扩展性好等,因此在存储器、神经网络、模拟计算等领域具有广阔的应用前景。
要提高阻变效应忆阻器的电阻变化稳定性、可重复性和耐久性,可以考虑以下几个方面:
- 材料选择:选择具有良好阻变性能和稳定性的材料,例如具有高电阻变化对比度、快速响应和较小电阻漂移的材料。
- 优化器件结构:设计合理的器件结构,例如采用多层结构、复合结构或引入中间层等,以提高器件的稳定性和耐久性。
- 控制工作条件:精确控制施加的电压、电流、温度等工作条件,避免过度刺激或不稳定的工作环境,以减少电阻变化的波动。
- 界面工程:通过改善材料与电极之间的界面质量,减少界面电阻和电荷积累,提高电阻变化的可重复性和稳定性。
- 封装和保护:采用合适的封装技术,保护忆阻器免受外界环境的影响,如湿度、温度变化和物理冲击等。
- 可靠性测试:进行全面的可靠性测试,包括耐久性测试、温度循环测试、数据保持测试等,以评估和改进忆阻器的性能。
- 制造工艺优化:优化制造工艺流程,控制工艺参数,提高器件的一致性和重复性。
- 合作与交叉学科研究:与材料科学、物理学、电子工程等领域的专家合作,共同研究和解决相关问题。
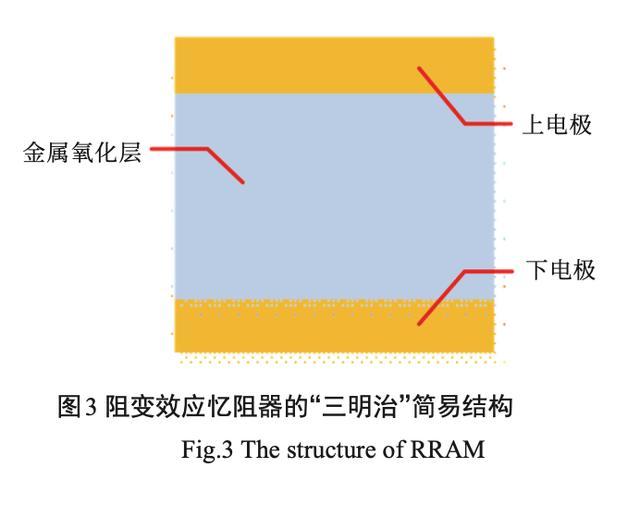
对于阻变效应忆阻器导电细丝的生长和断裂是导致阻值发生变化的关键机制之一。刚制备好的阻变效应忆阻器处于初始阻态 ,一般是高阻态 ,还没有阻变特性。为了 使其可以正常工作 ,需要在两端施加1个比较大的电压脉冲 ,这个过程称为“Forming”过程。在Forming 过程中 ,本征缺陷较少的阻变绝缘层内部因为软介 电击穿而形成了导电细丝。金属氧化物中的氧离 子在外加电场的作用下 ,往阳极迁移并被阳极存储起来.
此时 ,生成的氧空位形成导电细丝 ,阻变效应忆阻器从高态转变到低阻态。SET 过程与此相类似 ,但由于 Forming 之后阻变效应忆阻器内部缺陷较多,所以需要的电压相对较小。在RESET过程中 ,在其两端施加反向电压 ,氧原子从阴极迁移出来 并与形成导电细丝的阴极附近的氧空位复合,造 成导电细丝无法与电极相连接 ,阻变效应忆阻器从低阻态转变到高阻态。对于非导电细丝类型的阻变效应忆阻器 ,其阻变是由于缺陷在电场作用下迁移 , 使得器件界面内肖特基势垒或隧穿势垒发生均匀变 化而导致的 。
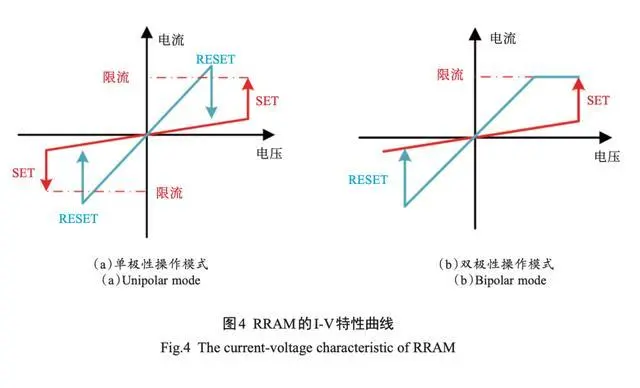
阻变效应忆阻器有单双极性两类阻变模式之分,如图 4 所示。对于双极性阻变模式而言 ,阻变现象是发生在不同极性的电压下的 ,即 SET/RESET 分别在相反的电压极性下发生。而对于单极性阻变模式 ,阻变现象与电压极性无关 ,只与电压幅度相关 。
三.基于忆阻器的存内计算原理
1. 利用二值忆阻器的布尔计算
忆阻器可以通过互连线直接访问和反复编程,这便于实现基于忆阻器的布尔运算。实质蕴涵 (material implication,IMP)逻辑和逻辑0可以构成逻辑完备集,通过级联可以实现全部 16 种逻辑运算 ,所以如何利用忆阻器实现实质蕴涵逻辑是关键。实质蕴涵逻辑的真值表如表 1 所示。基于忆阻器的布尔运算根据输入 、输出类型和操作方式的不同 ,可以分为3类 ,分别是 R-R 逻辑运算 、V-R 逻辑运算和V-V逻辑运算。

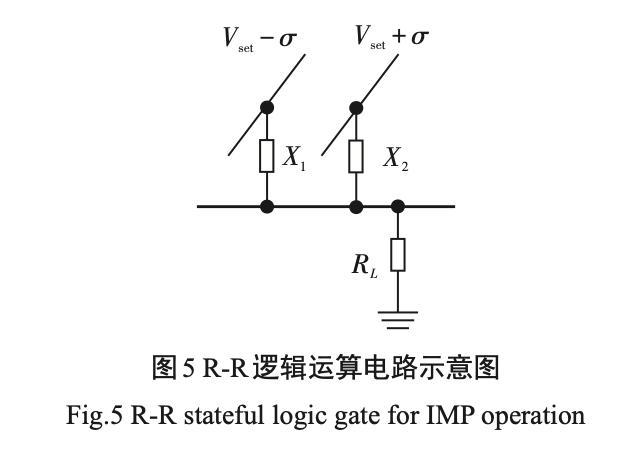
3.1R-R 逻辑运算
在R-R逻辑运算中,输入和输出都是通过忆阻器的高低阻态来分别表示逻辑 0 和 1 ,运算过程都是在忆阻器内部完成。如图 5 所示 ,计算时,根据输入 将两个忆阻器件 X1 、X2 写到对应的高低阻态 ,然后在两端分别施加电压Vsetε(Vset是器件发生SET阻变的电压,ε 是相对较小的电压),输出结果直接存储 在X2 里。根据欧姆定律和基尔霍夫电压电流定律 , 可以推出其真值表 ,如表 1 所示。当X1=0 时 ,X2 上的 压降为 Vset + ε > Vset ,无论当前X2 是哪个阻态 ,必将发 生 SET 阻变 ,X2 最终转变为低阻态 ,即输出Y=1;当X1=1时,X1和X2上的压降为2×ε<Vset ,无法发生SET 阻变 ,X2阻态没有发生改变,此时输出Y=X2。
3.2V-R 逻辑运算
在 V-R 逻辑运算中 ,输入是通过施加在单个忆阻器两端的电压幅值 X1 、X2 来表示 ,而逻辑输出Y则由高低阻态(分别表示逻辑 0 和 1)来表示。这种逻 辑运算要求忆阻器是双极性阻变模式的 ,施加正负极性的电压会使器件分别转移到高低阻态。如图 6 所示 ,在运算前把忆阻器初始化为低阻态 ,当X1=X2 时 ,器件两端的压降为零 ,阻态保持低阻态不变 ,即 输出Y=1;当X1=1 且X2=0 时 ,器件两端的压降为正 极性 ,阻态翻转为高阻态 ,即输出Y=0;当X1=0 且X2=1 时 ,器件两端的压降为负极性 ,因初始态为低阻态 ,阻态保持不变 ,即输出Y=1。其真值表如表 1 所示。 V-R 逻辑运算的默认输出Y=1,只有在X1=1 且X2=0 时输出才发生改变。由于这样的逻辑功能是完备的 ,通过适当的组合若干个 V-R 逻辑运算可以实 现 16 种布尔逻辑运算 。

3.3V-V 逻辑运算
在 V-V 逻辑运算中 ,输入和输出都是通过电压幅值低高来分别表示逻辑0和1。如图7是V-V逻辑运算的电路示意图 ,根据欧姆定律 ,作用在 Gj 上的输 入电压Vj 产生的电流为
其中,Vnode 为公共节点的电压。从而可以解出公共节点的电压Vnode
该式表明公共节点的电压Vnode 等同于输入电压 Vj 的权重累加和。一般在公共节点处放置 1 个阈值 电压为VT 的比较器 ,其输出为逻辑输出电压Voutput 。这一结构的逻辑运算与单层感知机相类似 ,公共节点的电压Vnode 和阈值电压比较器分别与神经元输入和非线性激活函数相对应起来 ,所以其逻辑功能与 单层感知机的功能一样 ,可以实现线性可分的逻辑运算 ,如与 、或 、非3类逻辑 ,如图7所 示 。与、或 、非3类逻辑可以构成逻辑完备集 ,所以这样的电路通过组合也可以实现任意逻辑运算。V-V逻辑运算可以很容易的实现级联以实现更强大的逻辑功能 ,但是和 V-R 逻辑运算一样 ,都需要额外的比较器设计。
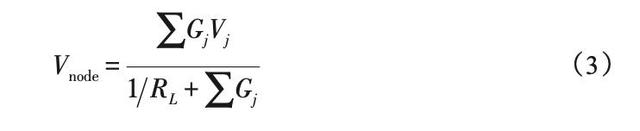

2. 利用模拟型忆阻器的模拟计算
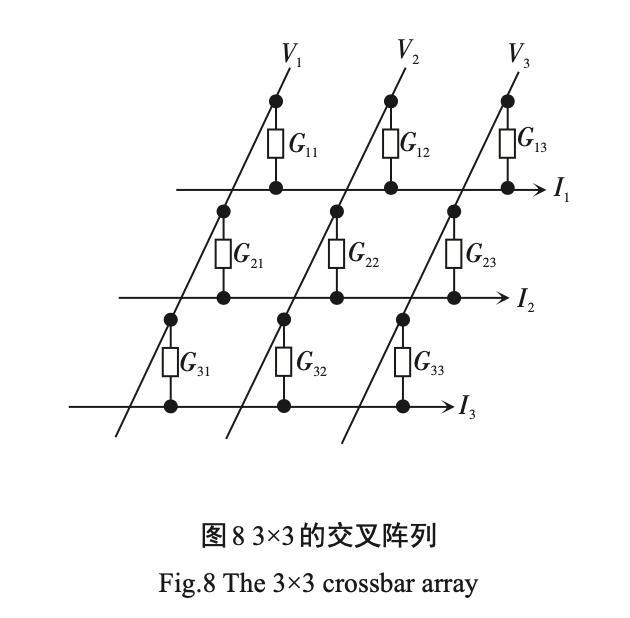
除了利用高低阻态来实现布尔运算外 ,利用具有多级阻态的模拟型忆阻器可以实现在模拟域的乘法-加法运算。如图 8 所示 ,模拟型交叉结构阵列有行列两个正交互连线 ,互连线的每个结点处夹着1个忆阻器件。电压 Vj 是施加在第j 列的电压值 ,根据欧姆定律和基尔霍夫定律 ,可以得到第i行的总电流值。

其中 Gij 为位于第j列第i行的忆阻器件的电导值。总电流值Ii是电导矩阵与电压向量的乘积结果 ,从存内计算角度来说 ,模拟型交叉阵列完成乘法-加法过程只需要一步 ,自然地可以实现矩阵向量乘的硬件加速。相比于传统的计算过程 ,这样的加速阵列更加节时 、节能。模拟型交叉阵列可以在稀疏编码 、图像压缩 、神经网络等任务中担任加速器的角色 。 在神经网络中 ,Gij 代表突触权重的大小 ,Vj 是前神经元j的输出值 ,Ii 是第i个神经元的输入值。如 图 8 所示是 3×3 的交叉阵列 ,列线与行线分别代表神 经网络中的输入神经元和输出神经元 ,忆阻器的电导值为神经元之间相互连接的突触权重值 ,利用反 向传播等学习算法可以通过 SET/RESET 操作来原位更新网络权重 。
四.存内计算的实验研究
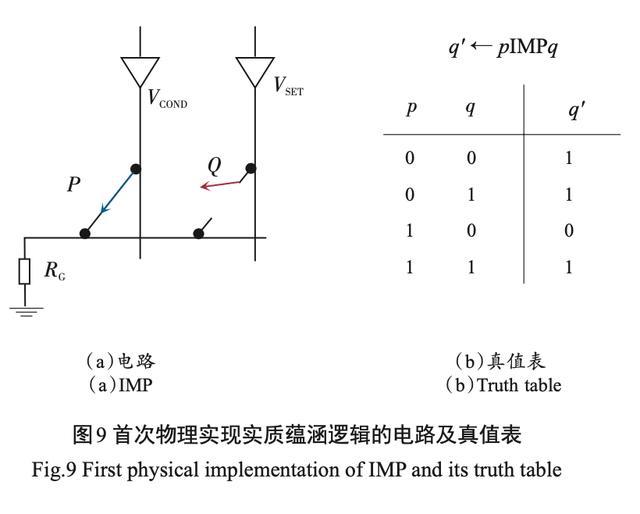
在布尔计算方面 ,忆阻器的出现为物理实现实 质蕴涵逻辑提供了很好的机会。在 2010 年 ,惠普公 司提出了一种利用 Pt/Ti/TiO2/Pt 忆阻器的电路,首 次物理实现了实质蕴涵逻辑 ,如图 9 所示。同时这样的电路只需要 3 个忆阻器件就可以实现与非逻辑运算 ,并且其存储和运算过程都由忆阻器件完成 ,可以 嵌入交叉阵列中以实现逻辑运算。这一工作展示了忆阻器件在存内计算领域的巨大潜力 ,提供了高效的存内计算的可行方案 。
进一步 ,加州大学圣巴巴拉分校 Strukov 团 队研究出了使用 4 个忆阻器件的三维状态实质 蕴涵逻辑 ,同时利用 6 个忆阻器件来重复扩展 IMP ,可以在 14 步内实现 1 个全加法器。这种三维 结构的忆阻器电路可以很容易解决内存瓶颈的问题。Waser 团队系统分析了 16 种布尔逻辑运算 , 提出了利用1个双极性阻变器件和1个互补型阻变器件的方法 ,可以在3步操 作内实现其中的14种运算 ,剩余的 2 种运算 XNOR 和 XOR 可以使用 两个器件来实现 ,其运算结果均直接存储在器件中 ,如 图 10 所 示 。

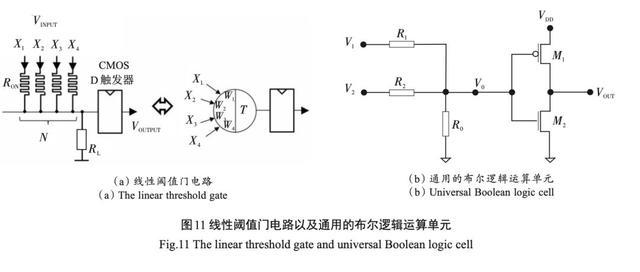
文献提出了一种CMOS和忆阻器混合电路, 实现了线性阈值门(linear threshold gate, LTG)逻辑功能。James 等报告了使用忆阻器和阈值逻辑电 路实现通用的布尔逻辑运算单元,其面积小且设计 简单即可实现类似大脑的逻辑功能,如图11所示。
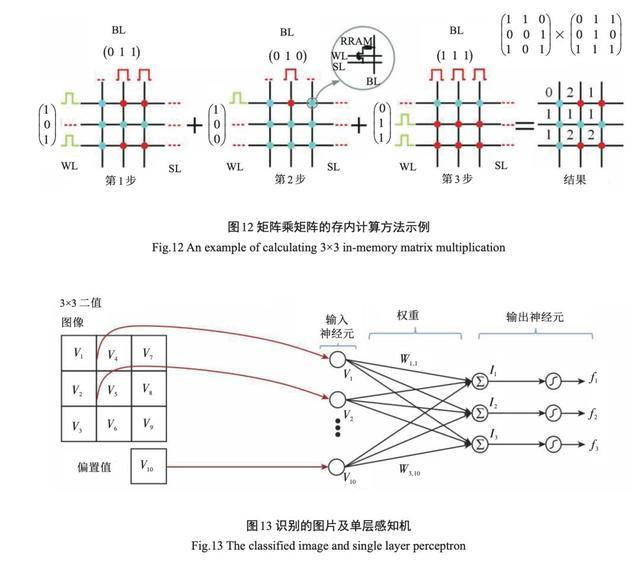
在国内,华中科技大学缪向水团队把两个忆阻器极性相反的串联起来,基于这样的三端忆阻器提出 了完备的逻辑运算方法。这种逻辑方法只需初始化 、 计算和读取共3步就可以实现16种布尔逻辑之一,计算结果存储在忆阻器的阻态中。北京大学康晋锋研究组利用忆阻器件开发并演示了存内计算的硬件处理系统 MemComp,该系统可以学习通用的逻辑运算且重复利用,极大地减小了功耗,提升了运算速度。2018年 ,清华大学钱鹤团队提出并在忆阻器阵列上演示了矩阵乘矩阵的存内计算方法 ,如图 12 所示。乘积的计算结果不需要AD转换即可存储在忆阻器阵列中,这可以高效地加速如图像处理 、数据压缩等应用的计算 。
在模拟计算方面,Strukov团队利用忆阻器阵 列实现了可以进行图像分类的感知机,并首次在实验上证明忆阻器阵列可以原位训练。权重值直接存储在忆阻器阵列上,在推理时可以充当加速器。由于阵列只有 12×12 的大小 ,所以感知机仅可以对 3 类 字母的黑白图像分类 ,如图 13 所示。这一工作验证了利用忆阻阵列完成感知机的方案 ,引起了国际的广泛关注。
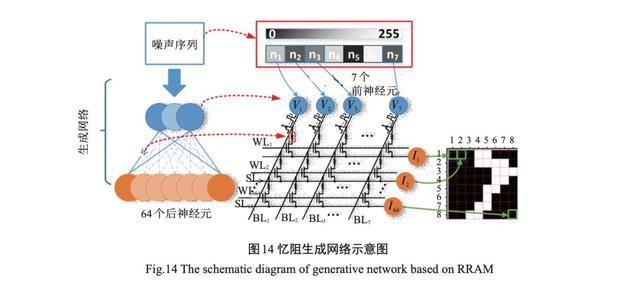
在在线训练忆阻器权重方面,斯坦福大学Wong组在PRAM阵列上利用Hebbian学习规则,可以存储给出的模式 ,并且实现了与大脑类似的恢复残缺 模式的功能。密歇根大学Lu研究组利用3232的 模拟型忆阻器阵列演示了稀疏编码算法,设计的网络可以有效地进行图像匹配和横向神经元抑制。经过训练之后的网络可以基于较少的神经元找到图像 里的关键特征。2018 年 ,IBM 的 Almaden 研究中心[51] 设计了具有高达204900个突触的软硬件混合神经网络。为了抵消器件之间的不一致性 ,提出了一种把 PRAM 的长期存储 、易失性电容器的线性更新和 可“极性反转”的权重数据传输相结合的方法。这项工作提供了一条利用硬件加速神经网络的新途径 。
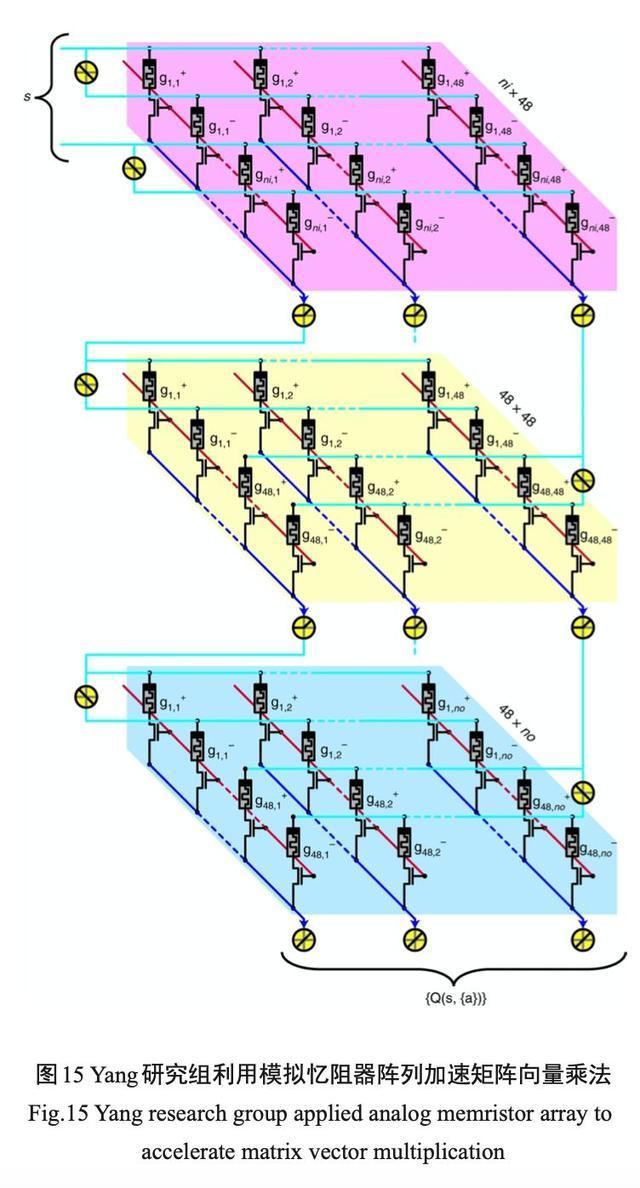
在利用忆阻器阵列直接映射来加速计算方面, Waston 工作组把训练好的卷积神经网络映射在忆阻器阵列上,利用提出的并行计算架构来提高整体的能效和数据吞吐量。与GPU方案相比,使用忆阻器阵列 加速的方法更显优势。亚利桑那州立大学 Yu 研究组提出了在忆阻器阵列上实现卷积神经网络中卷积的功能 ,把二维的核矩阵转化为了一维列向量并使用 Prewitt 核进行了概念验证。2019 年 ,Yang 研究组在 Nature Electronics 报道了利用模拟型忆阻器阵列来实现强化 学习的工作。报道中提出的模拟数字混合强化学习架构 ,把矩阵向量乘法的计算分配给了模拟型忆阻器阵列来运算 ,从而把忆阻器阵列的模拟运算优势和 CMOS 的逻辑运算优势相结合起来 ,如图 15 所示 。
参考文献:https://baijiahao.baidu.com/s?id=1659565467876650887&wfr=spider&for=pc