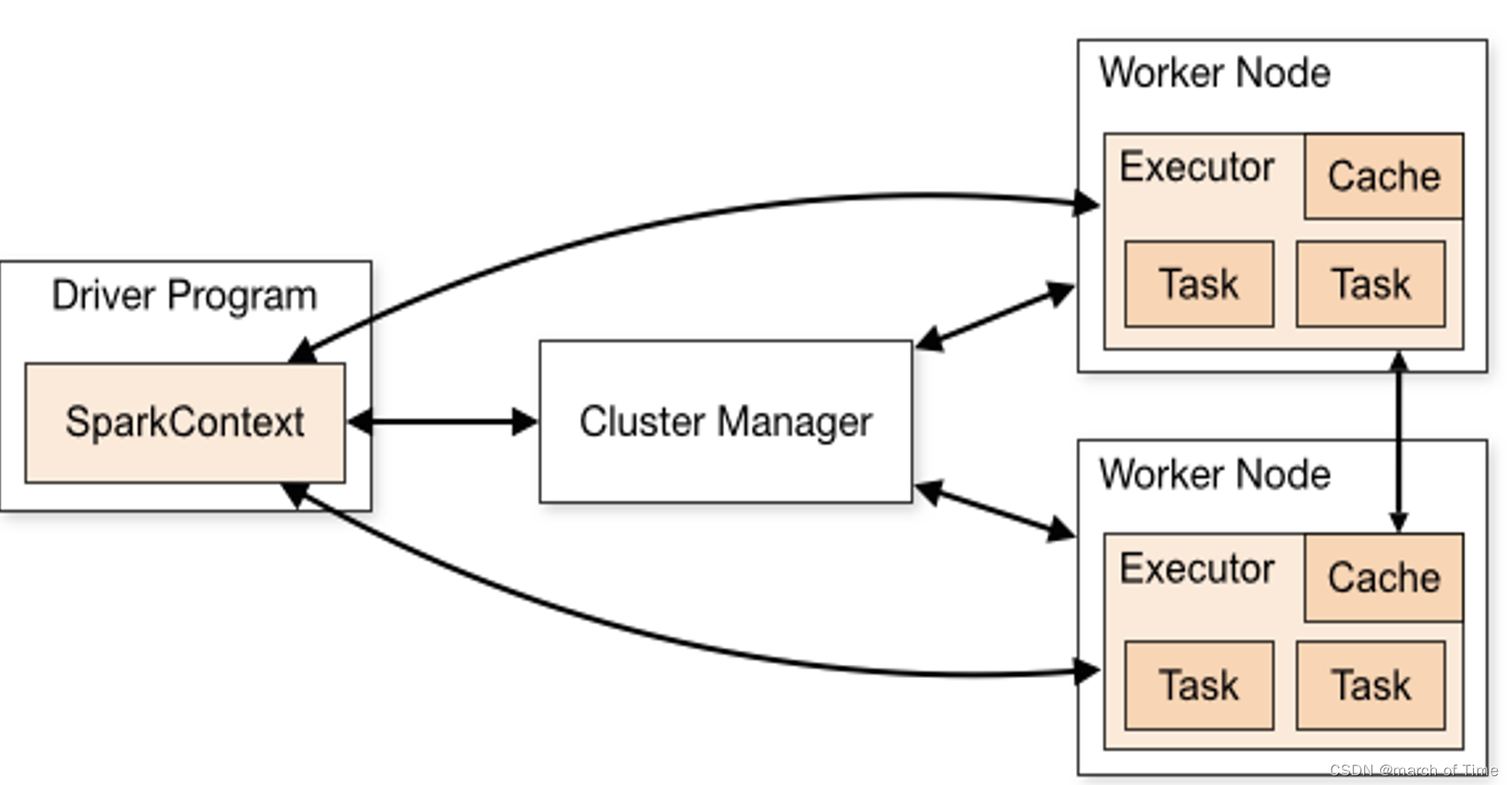
概要
本篇文章利用了Python爬虫技术对空气质量网站的数据进行获取,获取之后把数据生成CSV格式的文件,然后再存入数据库方便保存。再从之前24小时的AQI(空气质量指数)的平均值中进行分析,把数据取出来后,对数据进行数据清洗,最后将数据提取出来做可视化的分析。
在对数据的获取的过程中,使用了Python的request去获取html的一个文本,然后利用正则表达式re库和beautifulSoup这两个库去对数据进行筛选,拿到自己需要的一些空气质量的数据,并且同时写入CSV文件。
在对数据进行存储、分类时,利用了Python的sqlalchemy这个库,对写入CSV的数据去存进数据库,更简单直接的保存大群数据,然后再使用pandas这个库去读取数据库里面的数据,并且读取的数据可以直接去清洗、分类。
在数据可视化的步骤中,则用matplotlib和pyecharts这两个库去将想要分析的数据进行可视化,绘制成条形图,方便比较各个城市的空气质量差异,将当天空气最好的前十五个城市可视化出来,并且通过K-means聚类算法等去分析城市的一些空气质量受到影响的原因,以及对应的治理措施。
关键词: Python;爬虫;数据分析;数据库;数据可视化
一、研究背景与意义
随着经济的高速发展,空气质量这一生存的大问题显得越来越重要,我们以前发展太多重工业的时候,已经牺牲了很多的空气环境,到现在由于空气质量引发的一系列问题比比皆是,所以我们现在要注重空气的质量去保护环境。特别是现在网络飞速发展的时代,我们可以随时随地就能获取到各地的空气质量的信息,方便我们去了解各地的空气质量以及对空气质量进行及时的控制,让空气质量保持在一个比较良好的范围。大气污染状况是与我们每一个人的健康情况息息相关的,我们每一个人都有责任去保护我们的地球,因此普及一些空气污染的后果以及如何遏制这种提高空气质量具有重大意义。通过空气质量分析,可以使更多人了解大气污染重的地区以及原因,使大家增强环境保护意识,提高公众的科学素养,便于公众在线阅读及参与。收集全省各地市空气自动监测点位的实时发布数据,储存进空气质量搜集的数据库。这些数据不但可以呈现给用户们每个城市实时的一些空气质量信息,也可以把获取到的数据储存起来,方便以后去收集利用,还可以把这些数据给有关的保护环境的部门,作为整治空气环境的理由。所以对空气质量的关注是很有必要的。
二、功能性需求分析
(1)空气质量数据的获取。这个功能部分主要是使用Python的requests库去获取pm25.in这个网站首页的整个网页代码,提取出首页的城市名字以及对应的子链接,子链接里面就是城市的详细AQI空气质量信息,通过爬虫再次爬取每个城市的链接,得到空气质量的数据,由于这个网站公布的是实时数据,所以需要爬取前24小时空气质量的AQI折线图,然后得到平均值就是这一天的空气质量的值。
(2)数据存储。这个功能是利用SQLAlchemy去把从网页获取到的空气质量数据存进数据库中,方便保存,相比于写进CSV文件,存进数据库能更加的方便利用,而且也不会因为操作失误使数据丢失。
(3)数据分析的结果。该功能主要是列出前十五个当天的空气质量好的城市排名以及空气质量差的城市,并结合一些地理分布的情况与算法分析的结果去总结规律。
数据处理工具与算法介绍
第4章 数据处理工具与算法介绍
Pandas 模块介绍
Pandas是Python当中的一个拓展的库,Pandas里面包含了大量的标准数据类型并且提供了高效操作大型数据的工具,对于数据的处理,pandas可以做到非常的高效,并且可以与多种类库共同使用,对编程者非常友好。同时Pandas也提供了集中数据结构供使用者使用:
1. Series: 一维数组,类似于List列表的一种数据结构,但是Series与List有一些不同之处,就是Series只允许储存相同数据类型的数据,这样有利于内存分配同时提高运算效率。数据库中相同列的数据也是起着同样作用。
2. DataFrame: 二维数组,是一种表格型的数据结构,简单来说就是行与列都有一层的Series的数组,这样组成新的二维数组。当用户将所需要的数据写进Excel表格文件时,DataFrame这种数据结构可以很方便地利用CSV文件格式创建Excel表格,做到了与Excel表格基本没有任何的录入障碍。
3. Panel: 三维数组,同理可以理解为DataFrame之间的嵌套。
利用爬虫获取到空气质量的数据之后,可以同时将其写入已存在的CSV表格。同时还可以使用sqlalchemy去把CVS文件写入数据库,方便保存并且以防丢失。
SQLAlchemy模块简介及应用
SQLAlchemy是Python的一种SQL工具包和对象关系映射器,是Python的一种ORM(Object Relationship Mapping)框架,而ORM是一种为了面向对象编程开发方法而产生的一种对象关系映射的工具,它的关系是指关系数据库,也就是数据可以保存在数据库当中。当生成一个对象时,对象可以从数据库当中获取持久化的数据,不像是我们运行一个程序,里面的变量参数只存在程序运行的时候,数据存储在数据库里是持久的,反过来,数据也可以存储在数据库当中。使用SQLAlchemy的时候,可以简化开发时候需要使用SQL语句这一步操作,可以直接思考他的代码逻辑,从而简化一些步骤,提高开发中的效率。SQLAlchemy提供了一种非常持久性的模式,用于数据库访问的时候,就显得非常的高效率。使用SQLAlchemy的优势是即使开发人员不熟悉数据库操作的语句,SQLAlchemy可以让开发人员直接使用对象操作,从而跳过数据库语句的操作,不用开发人员去查找数据库语句,提高了开发的效率。而其中也有它的缺点,使用SQLAlchemy的缺点是跳过了数据库语句操作之后,不容易进行数据库查询的优化,从而可能带来一些性能上、运行方面的损失。下面是SQLAlchemy的一些常用的参数:
1.create_engine:可以当作作为一个桥梁架起数据库与Python之间的沟通,使Python可以对数据库进行连接,里面的数据类型为字符串,用来表示连接的信息:’数据库类型+数据库驱动名称://用户名:密码@需要连接主机的ip(如果是本机则是localhost或者127.0.0.1):端口号/数据库名’
2.sessionmaker:生成一个数据库的会话类。这个类相当于一个数据库连接的session,向数据库申请一个会话,同时这个类还会记录一些查询的数据,并且可以控制执行SQL语句的时间。当用这个类拿到一个数据库返回的session之后,就可以用这个session对数据库进行增删改查。
关于Pyecharts
Pyecharts是Python与Echarts交接而成,用于生成Echarts图表的一个类库。而Echarts是由百度研发,一个可以生成生动,直观,可以交互并且可以高度个性化定制的web数据可视化图表的可视化库。简单来说Echarts有着超越许多同行的一些优势,可视化出来的数据图十分的美观且炫酷。Pyecharts就是在Echarts的基础上的一个Python类库。值得注意的是,Pyecharts分为两个版本,一个v0.5x,另一个为v1,两个版本并不兼容,而且v0.5x仅仅支持Python2.7,Python3.4+,而v1的版本仅支持3.6+的版本,导入模块的方式也不完全相同,所以Python版本限制了Pyecharts的版本。Pyecharts的强大之处在于可以导入全国甚至全球的地图包,然后对其进行数据可视化,清楚的了解地区的特点。顺带一提,Pyecharts是Python的一个拓展库,需要用pip去自行下载。
K-means算法介绍
K-means算法是一种基于坐标与距离的一种聚类算法,聚类算法就是将数据中分散的样本分类,将每个特征相似的样本都分为一组,在K-means算法中,这种组称为“簇”。算法原理是先在样本中做k个随机点,作为“簇”的中心点,然后计算样本到这些“簇”的距离,对于样本点,距离哪个“簇”最近,就归类在这个“簇”内,分完样本点后。继续在这些“簇”中重新选一个中心点,继续计算离中心点的距离,继续划分“簇”,直到中心点的变化很小为止。
三、项目的实现
数据可视化是指利用图形、动画等更加形象的一些表达方式对数据进行体现,在如今的大数据时代,每秒钟就有无数条数据,而一条条的去看这些数据,不但枯燥,而且又难以记住,当使用了数据可视化,就能将数据以图形或者动画的方式呈现出来,到时候我们可以使用图形记忆去记住这些数据,而不是将数字去背下来,这样的数据更容易去使用和理解。
现在数据可视化应用到许多方面,在新闻传播的行业中,数据可视化不但是一种非常合理的呈现方式,节省大家的理解,只需几秒钟就可以看懂图中的数据所想表达的意思,还是带有更强的互动性的一张信息图表,这就说明了数据可视化的化繁为简的一个优点,并且增加信息的可读性和趣味性。信息的表达形式和手中阅读信息时候的受欢迎度、记忆度和参与度存在一定的关系,可视化的叙事方式不仅降低了受众的获知知识的成本,而且提高了一些用户对于这些信息的记忆效率和给其他人分享的欲望,这就为数据的传播提供了非常良好的途径。有科学研究表明,注视记录长度与喜爱度之间存在非常正相关的关系。用视觉元素去快速抓住观众们的眼球,营造不同的兴趣点,这样来实现自己所喜欢的“悦读”方式,进而延长信息消费的过程,已然成为当下各类媒体争取受众的制胜之策。
一般地,在人们对空气质量查看的过程中,会着重关注一些空气质量好的城市所处的位置、空气质量差的城市污染物的排放量、以及空气质量好的城市的排行。而且有些人们打算去某些城市旅游的,自己又不幸带有过敏性鼻炎,这些空气质量对他们来说影响更加的大,使他们不得不关注自己意向去到的城市的空气质量情况,以防患上更严重的呼吸类疾病。
对于数据的可视化,本着浅显易懂的原则,本文对于以下若干问题做出了图标化处理,即进一步对所获取的数据进行可视化处理。
1.列出空气质量最好的前十五个城市
2.列出空气质量最坏的前十五个城市
3.以地区分析空气质量好的城市的一些分布特点
4.以地区分析空气质量差的城市的一些分布特点
5.将污染物占比进行可视化
6.使用K-means算法分析污染情况相似的城市
5.1 空气质量最好的前15个城市排名展示
根据从网上获取到24小时的空气质量数据的平均值,空气质量最好的前十五个城市如图5.1所示:
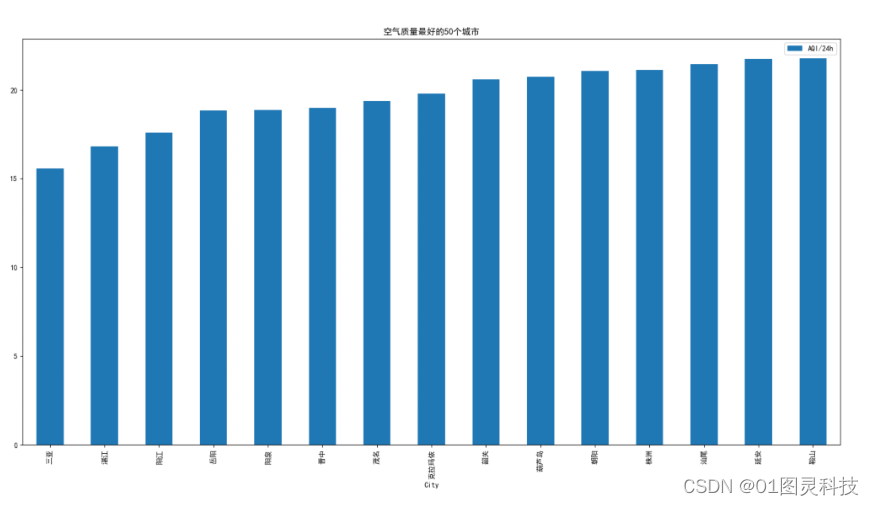
图5.1 空气质量最好的前十五个城市
图5.1中显示全国空气质量最好的前十五个城市,其中旅游胜地三亚高踞榜首,紧随其后的湛江、阳江两个城市也是旅游的大城市,有着非常丰富的水资源,绿化方面做得非常好,从整张图的角度看来,这15个城市都处于AQI值35以下,在空气质量的判断条件当中属于非常优秀的水平。从省份分析,在空气质量最好的前十五个城市当中,广东省所占据的城市比例最多,有湛江、阳江、茂名、汕尾、韶关五个城市,共占这十五个城市的三分之一,由地理环境所知,广东的水资源非常丰富,降雨量也非常多,表明空气质量受到水的影响非常大。从城市的发达程度看来,以上十五个城市全部位列三线城市及以下,空气好的原因可能为经济发展比不上一二线城市的水平,所以工业污染较少,在城市街道的出行车比较少,排放的废气少,使得空气维持在了一个较好的水平,在一定程度上说明了经济与环境的关系。
5.2 空气质量最差的前15个城市展示
根据从网上获取到24小时的空气质量数据的平均值,空气质量最差的前十五个城市如图5.2所示:
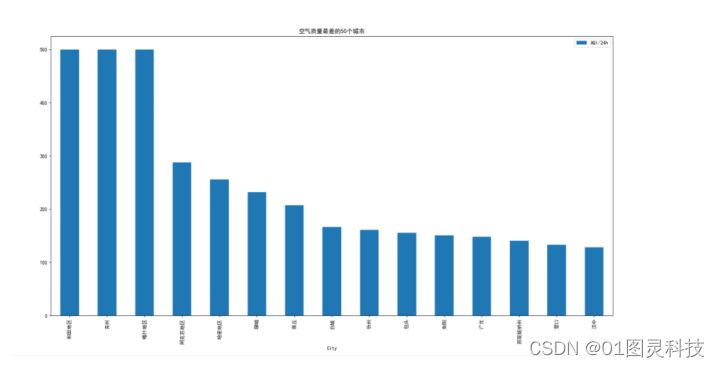
图5.2 空气质量差的前十五个城市
从区域角度分析,前五名空气差的城市都属于新疆维吾尔自治区,具体原因为沙尘暴的影响,因为新疆降雨量太少,导致沙尘容易扬起,到处都是颗粒物,并且在新疆有许多热电厂、煤化工厂、硅铁、石油化工厂、水泥厂等重污染的工厂,还有很多附属厂;加上其它燃煤锅炉、家里的燃煤炉子、在街边饭店的烤肉炉。数量惊人,外界环境的条件加上自己使用重污染的一些物资,导致了这些城市空气质量这么差。由数据可以知道,有三个属于新疆的城市达到了惊人的500AQI值,这个属于严重污染的范围,后面的几个城市污染程度也在150以上,都属于中度污染以上的级别。
5.3 以地区分析城市空气质量好的特点
由图5.3可知,空气质量好的地区大多数分布在空气湿度较高的地方比如:长江以南的城市和四川盆地,其中还有西部和东北部的丰水区。在长江以南的地方尤为密集。长江以南的地区主要以亚热带季风气候为主,降水量较多,空气湿润。主要发展轻工业,相对于重工业,轻工业的污染比较小。降水能够有效吸收、淋洗空气中的污染物。因此这些地区的空气的自我净化能力较强。
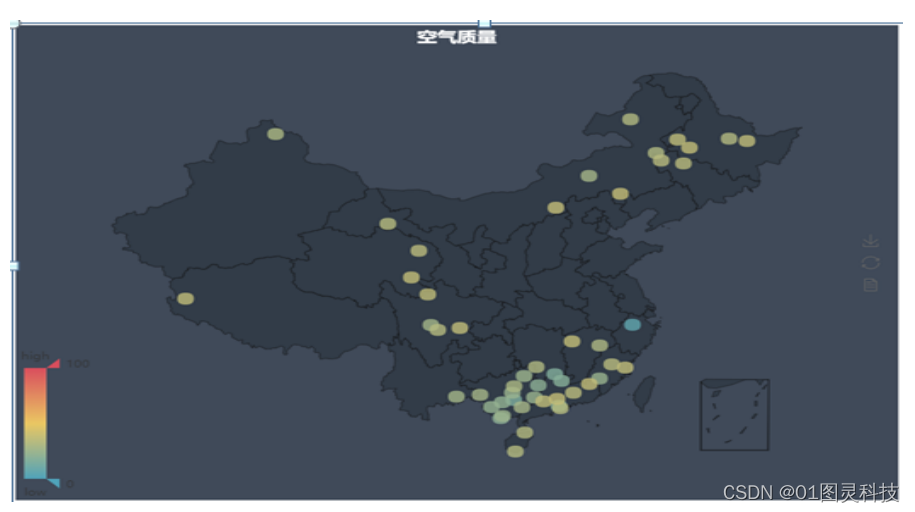
图5.3 空气质量最好的城市分布图
5.4 以地区分析城市空气质量差的特点
如图5.4所示,空气质量不好的地方多数分布在华北地区和新疆的荒漠地区。这些地区的主要特点是降水少,气候干燥。这些地区的气候是温带季风性气候和温带大陆性气候,降水少空气干燥,风沙比较多。因此这些地区的空气自我净化能力弱。由图所见,空气质量差的密集区在黄河中下游地区。这部分地区在冬天的时候燃煤供暖,会产生有害气体和粉尘,其次该地区是工业密集区,石油,煤化,冶金工业发达,人类活动和工业生产对空气质量影响大。
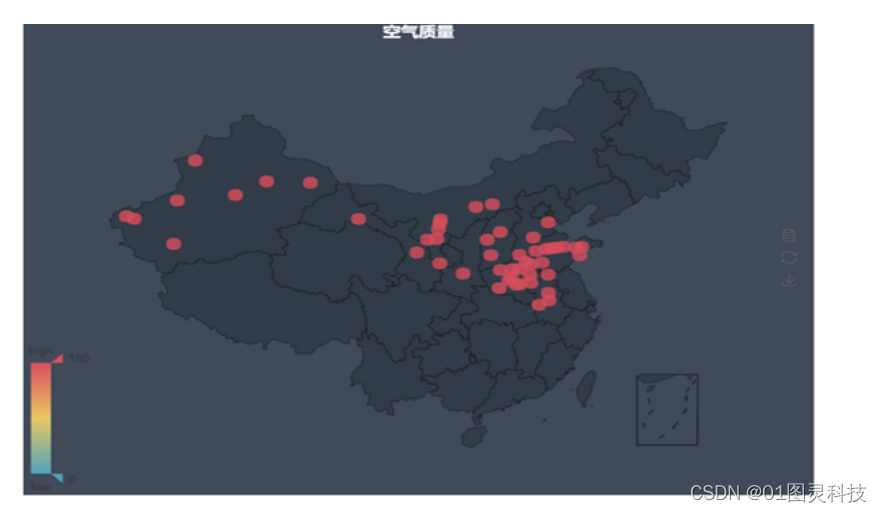
图5.4 空气质量差的城市分布图
5.5 污染物占比的可视化
图5.5是对存在污染物的城市进行归纳,然后将这些污染物的占比可视化出来。由图中我们可以看到,存在污染物的城市中,收到PM10影响的城市是最多的,其次是PM2.5,这两种颗粒物加起来占污染物的90%以上,说明当前要对空气质量的提高,仍需首要解决的还是颗粒物的问题。
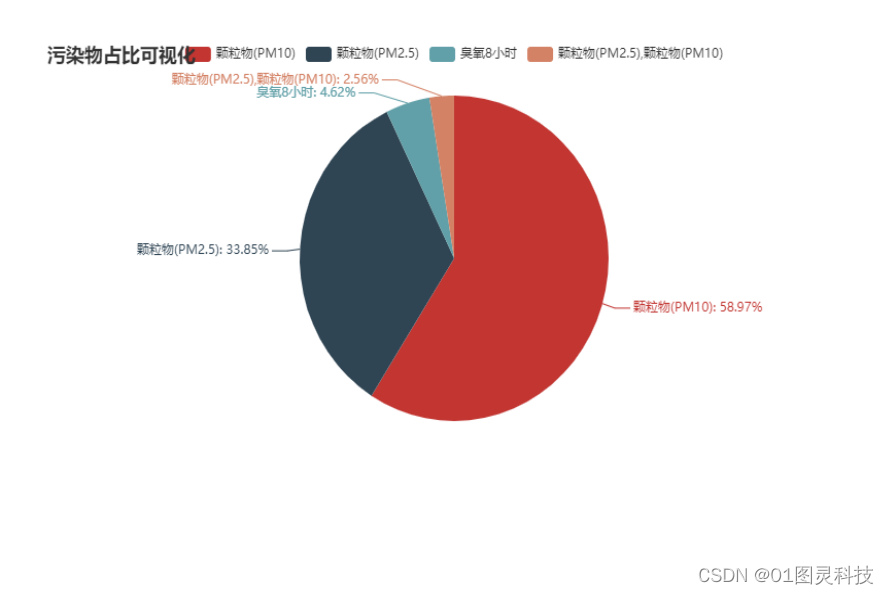
图5.5 空气质量与污染物图
5.6 通过K-means聚类算法的分析结果
要使用K-means算法分析,首先要对爬取到的数据进行标准化,同比例缩小,使得特征相似的城市落入一个小的特定区间内,消除奇异样本的影响。标准化之后,就是将这些数据进行聚类算法计算,是它们特点相似的归为一类。具体流程图如5.6所示
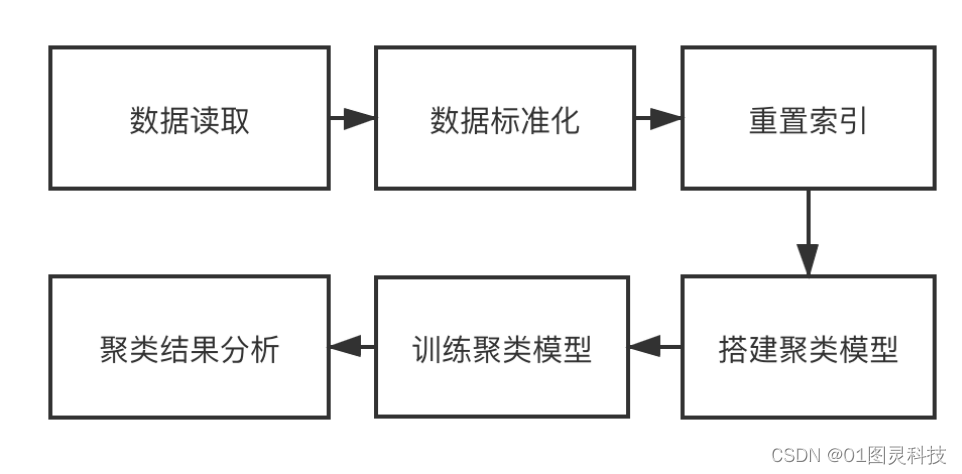
图5.6 K-means计算的流程图
下面将着重分析受到污染的城市的“簇”。根据样本的标准,我把这些城市分为5个“簇”,如图5.7所示,右边是每个簇包含的城市数量。

图5.7 “簇”内城市的数量
四、总结
主要实现了对pm25.in的城市空气质量和其污染物的搜集,并将其获取到的数据存储进入数据库。并且使用pandas模块去将这些数据从数据库中读取出来,然后使用matplolib和pyecharts进行可视化。在获取数据过程中,用了比较多的时间花在了获取整个网站的全部城市空气质量以及首要污染物的实时数据,并且在该网站的24小时的空气质量数据比较难以获取,难点主要在于对全天AQI的获取。我在这次项目中完成了以下的工作:
(1) 对空气质量网站的全部城市的空气质量进行了数据爬取,并且配置了数据库与Python进行连接,在这个过程中遇到了一些配置上的错误,后来发现需要下载pymysql的类库去制造一个依赖环境。
(2) 对获取到的城市空气质量数据存放进数据库并使用pandas取出来,方便可视化处理。对于存放到数据库的数据可视化,本篇文章使用了数据可视化工具matplolib和pyecharts进行数据排名展示和对数据的空间分布展示,并结合各城市的一些气候情况,污染物排放量,对这些城市的空气质量进行一些可视化分析和数据上的分析。
本次数据分析对多个城市进行分析后,在几个角度得到一些结论:
(1) 在展示的空气质量最好的15个城市中,广东的城市占了最大的一部分,而且这些城市大部分是水资源多的地区,有的沿海地区空气环境更好,而且这15个城市都是三线城市及以下的城市,说明水资源同样丰富的情况下,经济不太发达的城市要比发达的城市空气质量好。
(2) 在展示的空气质量最差的15个城市中,前五名空气差的城市都属于新疆维吾尔自治区,具体原因为沙尘暴的影响,因为新疆降雨量太少,导致沙尘容易扬起,到处都是颗粒物,并且根据一些地方的资料介绍,在新疆有许多热电厂、煤化工厂、硅铁、石油化工厂、水泥厂等重污染的工厂,还有很多其他污染严重的附属厂;加上其他家里用户所使用的燃煤锅炉、家里的燃煤炉子、在街边饭店的烤肉炉,这样的排放加上自然环境就导致了空气质量的恶劣。
(3) 从地理位置分布规律看,空气质量好的地区大多数分布在空气湿度较高的地方比如:长江以南的城市和四川盆地,其中还有西部和东北部的丰水区。在长江以南的地方尤为密集。长江以南的地区主要以亚热带季风气候为主,降水量较多,空气湿润。主要发展轻工业,相对于重工业,轻工业的污染比较小。降水能够有效吸收、淋洗空气中的污染物。因此这些地区的空气的自我净化能力较强。
(4) 从地里位置分布规律看,空气质量不好的地方多数分布在华北地区和新疆的荒漠地区。这些地区的主要特点是降水少,气候干燥。这些地区的气候是温带季风性气候和温带大陆性气候,降水少空气干燥,风沙比较多。因此这些地区的空气自我净化能力弱。由图所见,空气质量差的密集区在黄河中下游地区。这部分地区在冬天的时候燃煤供暖,会产生有害气体和粉尘,其次该地区是工业密集区,石油,煤化,冶金工业发达,人类活动和工业生产对空气质量影响大。
(5) 在首要污染物占比角度看,存在污染物的城市中,收到PM10影响的城市是最多的,其次是PM2.5,这两种颗粒物加起来占污染物的90%以上,说明当前要对空气质量的提高,仍需首要解决的还是颗粒物的问题。
(6)通过聚类分析算法的结果看,分成的五个聚类中,有三个聚类的空气质量是偏差的,而且这些聚类的污染物排放规律也不一样,可以通过聚类中存在的问题,对情况相似的城市进行污染物治理,增加治理的效率。
六、 目录
目 录
第1章 绪 论 1
1.1 课题的研究背景及意义 1
1.2 互联网数据及其分析的研究现状 1
1.3 论文主要研究内容及框架结构 2
第2章 需求分析 3
2.1 功能性需求分析 3
2.2 非功能性需求分析 3
第3章 介绍BeautifulSoup与爬虫的一些事项 4
3.1 BeautifulSoup简介 4
3.2 关于爬虫的一些注意事项以及对空气质量数据的搜集 4
3.2.1 区分恶意爬虫和普通爬虫 4
3.2.2 关于反爬虫的一些介绍 5
3.2.3 对空气质量以及对应城市数据的爬取 6
第4章 数据处理工具与算法介绍 9
4.1 Pandas 模块介绍 9
4.2 SQLAlchemy模块简介及应用 9
4.3 关于Pyecharts 10
4.4 K-means算法介绍 10
第5章 数据的可视化介绍及数据分析 11
5.1 空气质量最好的前15个城市排名展示 12
5.2 空气质量最差的前15个城市展示 12
5.3 以地区分析城市空气质量好的特点 13
5.4 以地区分析城市空气质量差的特点 14
5.5 污染物占比的可视化 15
5.6 通过K-means聚类算法的分析结果 15
第6章 总结与展望 19
6.1 总结 19
6.2 展望 20
参 考 文 献 21
致 谢 22
附 录 23