一、前言
使用filebeat自动发现收集k8s的pod日志,这里分别收集前端的nginx日志,还有后端的服务java日志,所有格式都是用json格式,建议还是需要让开发人员去输出java的日志为json,logstash分割java日志为json格式,在日志量大的情况下非常消耗资源
二、收集日志配置
主要是配置filebeat和logstash进行日志的收集和分割,我这里的后端服务java日志不是json格式,所以需要自己去分割为json日志,有条件的也可以让开发直接输出json格式的日志,前端的只要收集nginx的access日志即可,nginx的可以直接配置为json格式输出
filebeat配置
vi filebeat-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:name: filebeat-confignamespace: elkdata:filebeat.yml: |filebeat.autodiscover: #使用filebeat自动发现模块providers:- type: kubernetes #配置为k8s类型 templates:- condition: #通过标签、命名空间筛选需要的pod日志,这里是匹配后端服务的日志and:- or:- equals:kubernetes.labels:app: foundation- equals:kubernetes.labels:app: api-gateway- equals:kubernetes.labels:app: field- equals:kubernetes.labels:app: report- equals:kubernetes.namespace: java-serviceconfig: #配置收集的pod日志路径,这里配置日志路径时要使用变量的方式定义日志路径,至于为什么使用这些变量,可以自行去看一下该日志目录下的路径名称- type: container #配置为container模式symlinks: true #使用了软链接的话需要加上该配置paths:- /var/log/containers/${data.kubernetes.pod.name}_${data.kubernetes.namespace}_${data.kubernetes.container.name}-*.logmultiline.pattern: '^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}' #使用multiline匹配以时间开头的行multiline.negate: true #反转匹配的内容,即匹配不是以时间开头的行multiline.match: after #将匹配到不是以时间开头的行就合并到上一个事件中- condition: #通过标签、命名空间筛选需要的pod日志,这里是匹配前端服务的日志,这里是因为前端的日志格式和后端的日志格式不一样,所以分开收集and:- or:- equals:kubernetes.labels:app: nodejs- equals:kubernetes.namespace: nodejsconfig:- type: containersymlinks: truepaths:- /var/log/containers/${data.kubernetes.pod.name}_${data.kubernetes.namespace}_${data.kubernetes.container.name}-*.logprocessors: #配置filebeat识别收集的日志格式为json,这里前端的日志已经配置为了json格式,所以在filebeat收集的时候需要将日志识别为json格式的日志,不配置的话收集出来的是一整串日志,和普通日志一样- decode_json_fields:fields: ["message"]target: ""overwrite_keys: trueadd_error_key: trueoutput.logstash: #将收集的日志输出到logstashhosts: ['logstash.elk:5044']logstash配置
vi logstash-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:name: logstash-configmapnamespace: elklabels:app: logstash
data:logstash.conf: |input {beats {port => 5044# codec => "json"}}filter {grok { #这里使用grok将java日志分割为json格式match => { "message" => "%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:level}\s+%{NUMBER:thread}\s+---\s+\[%{DATA:thread_name}\]\s+%{JAVACLASS:java_class}\s+:\s+%{GREEDYDATA:log_message}"}}}output {# stdout{ #该项为测试模式,将收集的日志内容输出到logstash的日志中# codec => rubydebug# }elasticsearch {hosts => "elasticsearch:9200" #这里的索引名称使用日志中包含的变量自动命名index => "%{[kubernetes][container][name]}-%{+YYYY.MM.dd}"}}这里对java日志进行一下说明,java日志都是特定的日期格式开头,基本上都是单行的,除了报错日志,报错日志会换行,因为报错栈非常多,filebeat收集日志是一行一行收集的,在收集java报错日志的时候就会出现问题,错误日志的报错栈也被分开很多行去收集了,这是有问题的,所以会在filebeat收集java日志的时候加入multiline,进行事务的一个合并,下面来看一下java的日志
正常日志
可以看到都是以特定的时间格式开头

错误日志
其实错误日志的结构和正常日志是一样的,只是后面的报错栈被分行了,所以在filebeat使用multiline将这些不是以时间开头的行合并到上一个事件中即可

可以使用kibana试验一下对java日志的分割是否能生效
%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:level}\s+%{NUMBER:thread}\s+---\s+\[%{DATA:thread_name}\]\s+%{JAVACLASS:java_class}\s+:\s+%{GREEDYDATA:log_message}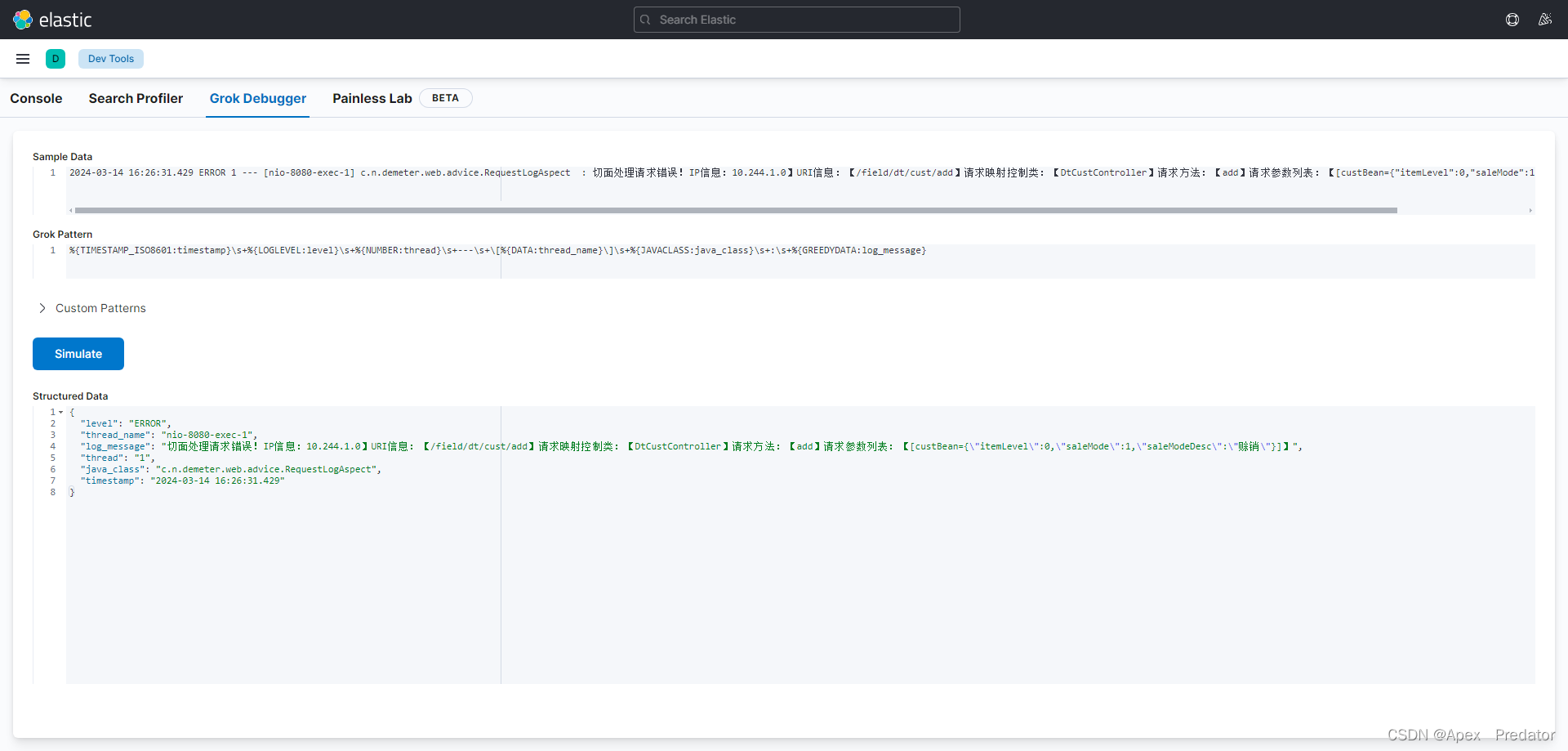
前端日志对于nginx的配置也做一下说明,需要在nginx配置文件中提前定义nginx的日志格式
vi nginx-public.yaml
apiVersion: v1
kind: ConfigMap
metadata:name: public-confignamespace: nodejs
data:nginx.conf: |user nginx;worker_processes auto;error_log /var/log/nginx/error.log notice;pid /var/run/nginx.pid;events {worker_connections 1024;}http {include /etc/nginx/mime.types;default_type application/octet-stream;log_format main '$remote_addr - $remote_user [$time_local] "$request" ''$status $body_bytes_sent "$http_referer" ''"$http_user_agent" "$http_x_forwarded_for"';log_format access '{"timestamp":"$time_iso8601",' #定义json格式的日志'"remote_addr":"$remote_addr",''"remote_user":"$remote_user",''"body_bytes_sent":$body_bytes_sent,''"request_time":$request_time,''"status": "$status",''"host":"$host",''"request":"$request",''"request_method":"$request_method",''"uri":"$uri",''"http_referer":"$http_referer",''"http_x_forwarded_for":"$http_x_forwarded_for",''"http_user_agent":"$http_user_agent"''}'; access_log /var/log/nginx/access.log access; #使用json格式的日志作为日志的输出sendfile on;#tcp_nopush on;keepalive_timeout 65;#gzip on;include /etc/nginx/conf.d/*.conf;}对于filebeat自动发现收集k8s日志的配置也可以参考elk官网,里面还有非常多的一些k8s参数可以定义 使用
参考:Autodiscover | Filebeat Reference [8.12] | Elastic








![[医学分割大模型系列] (1) SAM 分割大模型解析](https://img-blog.csdnimg.cn/direct/0d8c6c157e1742b5a524e36b41a233f8.png)