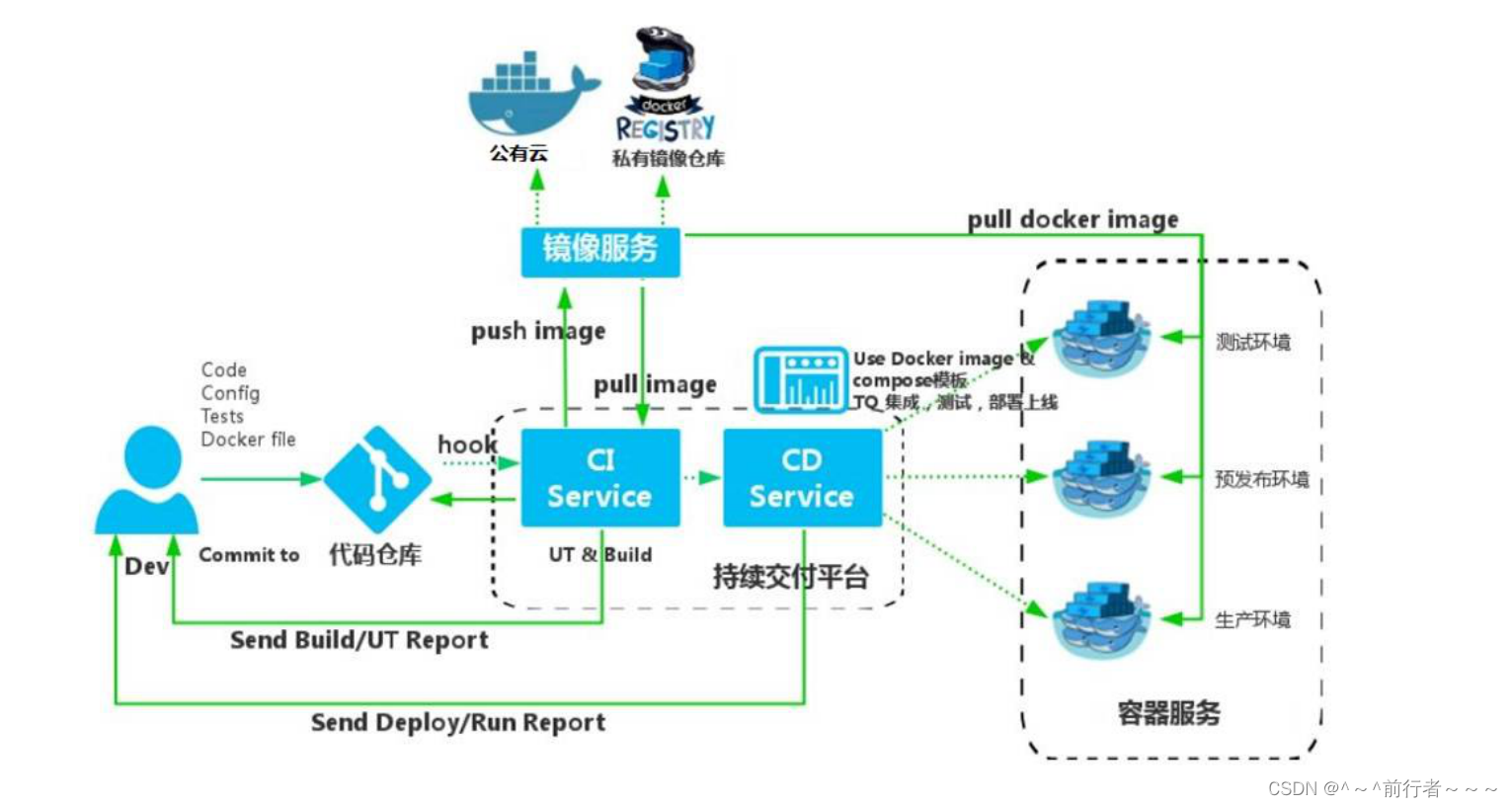
2.1 物联网的整体结构
实现物联网时,物联网服务大体上发挥着两个作用。
第一是把从设备收到的数据保存到数据库,并对采集的数据进行分析。
第二是向设备发送指令和信息。
本章将会为大家介绍如何构建物联网服务,以及用于实现物联网的重要要素。
2.1.1 整体结构
物联网大体上有3 个构成要素,如图2.1 所示。一个是设备,另一个是网关,再来就是服务器。关于设备的基本结构和使用的技术,我们会在第3 章详细说明。因此本章并不涉及设备。我们来详细看一下用怎样的机制才能实现网关和服务器。
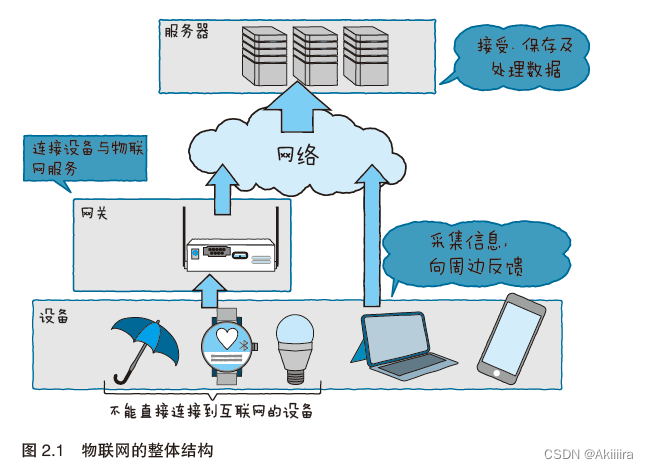
2.1.2 网关
如图2.1 左下所示,物联网使用的设备中,有3 台设备不能直接连接到互联网。网关就负责把这些设备转发到互联网。
网关指的是能连接多台设备,并具备直接连接到互联网的功能的机器和软件(图2.2)。如今,市面上有很多种网关。在多数情况下,网关凭借Linux 操作系统来运行。

选择网关时有几项重要的标准:
接口
第一重要的是用于连接网关和设备的接口。网关的接口决定了能连接的设备,因此重点在于选择一个适配设备的接口。
有线连接方式包括串行通信和USB 连接。串行通信中经常用的是一种叫作D-SUB 9 针(pin)的连接器,而USB 连接中用到的USB 连接器则种类繁多。
无线连接中用的接口是蓝牙和Wi-Fi(IEEE 802.11)。此外,还有采用920 MHz 频段的Zigbee 标准,以及各制造商们的专属协议。第3 章会详细讲解这些规格各自的特征,重点在于根据设备对应的标准来选择接口。
网络接口
我们用以太网或是Wi-Fi、4G/5G/LTE 来连接外部网络。网络接口会影响到网关的设置场所。以太网采用有线连接,通信环境稳定。然而正因为采用的是有线连接,所以必须把LAN 电缆布线到网关的设置场所。因此,在设置场所方面就会在某种程度上受到限制。
对4G/5G/LTE 连接而言,设置场所就比较自由了,但通信的质量会受信号强弱影响,所以通信不如有线连接稳定。因此,有时很难在信号不良的大楼和工厂等封闭环境中设置。不过,4G/5G/LTE 连接有个好处,即只使用网关就能完成和外部的通信,因此操作起来很简单。此外,想使用4G/5G/LTE 时,需要和电信运营商签订协议并获取SIM 卡,这点就跟使用手机一样。
硬件
相对于一般计算机而言,网关在CPU 和内存这些硬件的性能方面比较受限。我们需要确定让网关做哪些事情,也需要考虑到它的硬件性能。
软件
人们主要使用Linux 操作系统来运行网关。虽然有很多种用于服务器的Linux,不过,网关上搭载的Linux 是面向嵌入式的。
此外,还有一个叫作BusyBox 的软件,它运行起来占用内存少,集成了标准的Linux 命令工具。它用于在硬件资源匮乏的时候运行网关。除此之外,还要考虑是否有用于控制网关功能的程序库,以及与这种程序库对应的语言等。
电源
说起来,电源很容易被人们遗忘。网关基本上都是使用AC 适配器当电源的,因此需要事先在设置网关的场所准备好电源。如果网关本身搭载有电池,那么就不需要准备电源了,不过需要进行充电等维护工作。
2.1.3 服务器的结构
在功能方面,物联网服务大体上可分为3 个部分,本书分别称它们为前端部分、处理部分,以及数据库部分(图2.3)。

首先,前端部分包括数据接收服务器和数据发送服务器。数据接收服务器接收设备和网关发来的数据,转交给后续的处理部分。数据发送服务器则刚好相反,它负责把从处理服务器接收到的内容发送给设备。
通常情况下,Web 服务的前端部分只接受HTTP 协议。而物联网服务的前端部分则需要根据连接设备的不同来匹配HTTP 以外的协议。使用者需要考虑到协议的实时性和通信的轻量化,以及能否以服务器为起点发送数据。我们会在2.2 节重新讲解这些协议。
处理部分负责处理从前端部分接收到的数据。这里的“处理”指的是分解数据、存储数据、分析数据、生成发给设备的通知内容,等等。数据处理包括批处理和流处理等,批处理即把数据存入数据库之后一并进行处理,而流处理是逐次处理从前端部分收到的数据。使用者需要根据处理内容和数据特性来灵活使用这些“处理”。
最后是数据库。这里的数据库不只会用到关系数据库,还会用到NoSQL 数据库。当然,使用者需要根据想存储的数据和想使用的方法来选择数据库。
2.2 采集数据
网关的作用
就如我们前面说的那样,网关是一台用于把不能直接连接到互联网的设备转发连接到互联网的设备。再往细了说,网关是由3 种功能构成的(图2.4)。

这3 种功能分别是连接设备功能、数据处理功能和向服务器发送数据的功能。此外,实际使用网关执行应用时,还需要其他的管理应用功能。管理应用功能会在第5 章单独介绍。
接下来就来详细看看网关的3 种功能。
连接设备
设备和网关是通过各种各样的接口连接的。当通过传感器终端连接时,多数情况下是传感器单方面持续向服务器发送数据。根据设备不同,也存在设备申请从外部获取数据时,服务器向设备发送数据的情况,这时就需要通过网关申请数据。
生成要发送的数据
接下来把从设备接收到的数据转化成能发送给服务器的格式。在表示从设备发送到网关的数据时,也有把4 位二进制数(如二进制数据和BCD 码)替换成一位十进制数数据来表示的(图2.5)。这样的数据不会被直接发给服务器,而是在网关处被转化成数值数据和字符串的格式。

还存在下面这种情况:不把每台设备发来的数据直接发送给服务器,而是将大量数据整合在一起再发送给服务器。这么做有以下两个原因。
第一,通过整合数据能减少数据的附加信息,减少数据量。第二,通过一并发送数据能减轻访问物联网服务时对服务器造成的负担。
发送数据给服务器
向物联网服务发送数据。此时,需要根据服务器来决定发送数据的时间间隔和发送数据的协议。另外,为了能从物联网的服务器接收消息,还得事先准备好这种功能。
2.3 接收数据
2.3.1 数据接收服务器的作用
数据接收服务器就跟它的字面意思一样,负责接收从设备发送来的数据。它在设备和系统之间起着桥梁作用。有很多种方法可以从设备把数据发送给服务器,其中具有代表性的包括以下两种方法。
● 准备一个使用了HTTP协议的Web API来访问设备(如通常的Web系统)
● 执行语音和视频的实时通信(如WebSocket 和WebRTC)
除此之外,还出现了一种名为MQTT 的、专门针对物联网的新型通信协议。
本章将为大家介绍HTTP 协议、WebSocket、MQTT 这几个典型协议。
2.3.2 HTTP协议
HTTP 协议提供的是最大众化且最简易的方法。使用一般的Web 框架就可以制作数据接收服务器。设备用HTTP 的GET 方法和POST 方法访问服务器,把数据存入请求参数和BODY 并发送(图2.6)。
HTTP 协议是Web 的标准协议,这一点自不用说。因此HTTP 协议和Web 的兼容性非常强。此外,因为HTTP 协议有非常多的技术诀窍,所以我们必须在制作实际系统时审视服务器的结构,应用程序的架构以及安全性等。关于这点,有很多事例值得参考。另外,HTTP 协议还准备了OSS 的框架,方便人们使用。

关于GET和POST本身,可以通过这篇文章了解了解,这里不做重点来讲解。
99%的人都理解错了HTTP中GET与POST的区别
2.3.3 WebSocket
WebSocket 是一种通信协议,用于在互联网上实现套接字通信。它实现了Web 浏览器和Web 服务器间的数据双向连续传输。
就HTTP 协议而言,每次发送数据都必须生成发送数据用的通信路径及连接。此外,一般情况下,客户端没有发出申请就不能进行通信。
相对而言,WebSocket 就不同了。只要一开始根据客户端发出的连接申请确立了连接,就能持续用同一个连接传输数据。另外,只要确立了连接,就算客户端没有发出申请,服务器也能给客户端发送数据(图2.7)。

这样一来,在发送语音数据等连续的数据,以及发生与服务器的相互交换时,就能使用WebSocket 了。WebSocket 自身只提供服务器与客户端的数据交换,因此需要使用者另外决定在应用层上使用的协议。
2.3.4 MQTT
MQTT(MQ Telemetry Transport,消息队列遥测传输)是近年来出现的一种新型协议,物联网领域会将其作为标准协议。MQTT 原本是IBM 公司开发的协议,现在则开源了,被人们不断开发着。MQTT 是一种能实现一对多通信(人们称之为发布或订阅型)的协议。它由3 种功能构成,分别是中介(broker)、发布者(publisher)和订阅者(subscriber)(图2.8)。

中介承担着转发MQTT 通信的服务器的作用。相对而言,发布者和订阅者则起着客户端的作用。发布者是负责发送消息的客户端,而订阅者是负责接收消息的客户端。MQTT 交换的消息都附带“主题”地址,各个客户端把这个“主题”视为收信地址,对其执行传输消息的操作。形象地比喻一下,中介就是接收邮件的邮箱。
再来详细看一下MQTT 通信的机制(图2.9)。首先,中介在等待各个客户端对其进行连接。订阅者连接中介,把自己想订阅的主题名称告诉中介。这就叫作订阅。
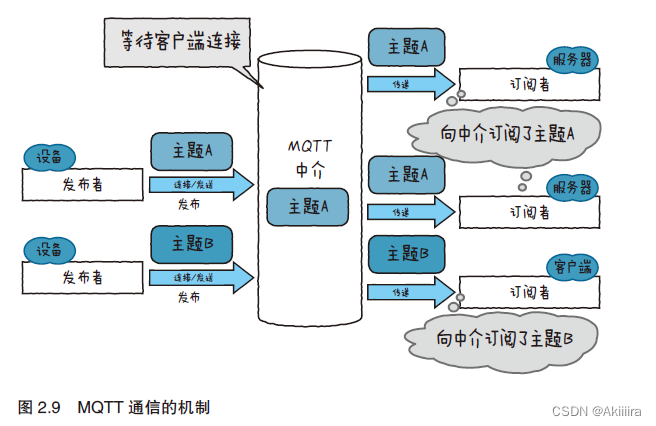
然后发布者连接中介,以主题为收信地址发送消息。这就是发布。
发布者一发布主题,中介就会把消息传递给订阅了该主题的订阅者。如图2.9 所示,如果订阅者订阅了主题A,那么只有在发布者发布了主题A 的情况下,中介才会把消息传递给订阅者。订阅者和中介总是处于连接状态,而发布者则只需在发布时建立连接,不过要在短期内数次发
布时,就需要保持连接状态了。因为中介起着转发消息的作用,所以各个客户端彼此之间没有必要知道对方的IP 地址等网络上的收信地址。
又因为多个客户端可以订阅同一个主题,所以发布者和订阅者是一对多的关系。在设备和服务器的通信中,设备相当于发布者,服务器则相当于订阅者。
主题采用的是分层结构。用“#”和“+”这样的符号能指定多个主题。如图2.10 所示,/Sensor/temperature/# 中使用了“#”符号,这样就能指定所有开头为/Sensor/temperature/ 的主题。此外,/Sensor/+/room1中使用了符号“+”,这样一来就能指定所有开头是/Sensor/、结尾是/room1 的主题。

像这样借助于中介的发布/ 订阅型通信,MQTT 就能实现物联网服务与多台设备之间的通信。另外,MQTT 还实现了轻量型协议。因此它还能在网络带宽低、可靠性低的环境下运行;又因为消息小、协议机制简单,所以在硬件资源(设备、CPU 和内存等)受限的条件下也能运行,可以说是为物联网量身定做的协议。MQTT 本身还具备特殊的机制,下面我们会对其逐一说明。
QoS
QoS 是Quality of Service(服务质量)的简称。这个词在网络领域表示的是通信线路的品质保证。MQTT 里存在3 个等级的QoS。“发布者和中介之间”以及“中介和订阅者之间”都分别定义了不同的QoS 等级,以异步的方式运行。此外,当“中介与订阅者之间”指定的QoS 小于“发布者和中介之间”交换的QoS 时,“中介与订阅者之间”的QoS会被降级到指定的QoS。QoS 0 指的是最多发送一次消息(at mostonce)(图2.11),发送要遵循TCP/IP 通信的“尽力服务”。消息分两种情况,即到达了一次中介处,或没有到达中介处。

接下来的QoS 1 是至少发送一次消息(at least once)(图2.12)。
中介一接收到消息就会向发布者发送一个叫作“PUBACK 消息”的响应,除此之外还会根据订阅者指定的QoS 发送消息。当发生故障,或经过一定时间后仍没能确认PUBACK 消息时,发布者会重新发送消息。如果中介接收了发布者发来的消息却没有返回PUBACK,那么中介会重复收到消息。
最后是QoS 2,它指的是准确发送一次消息(exactly once)。把它跟QoS 1 合在一起使用,就能避免接收到重复的消息(图2.13)。用QoS 2 发送的消息里面含有消息ID。中介收到消息后会将消息保存,然后给发布者发送PUBREC 消息。发布者再给中介发送PUBREL 消息,然后中介会给发布者发送PUBCOMP 消息。接下来中介才会依据订阅者指定的QoS,向订阅者传递接收到的消息。

此外,就QoS 2 而言,有时使用的中介会影响消息的传递时间。
人们通常使用的是QoS 0,只有要确保信息发送成功时才使用QoS 1和QoS 2,这样一来可以减少网络的负担。后文将会讲到Clean session,其中QoS 的设定也是非常重要的。
Retain
订阅者只能接收在订阅之后发布的消息,但如果发布者事先发布了带有Retain 标志的消息,那么订阅者就能在订阅后马上收到消息。
当发布者发布了带有Retain 标志的消息时,中介会把消息传递给订阅了主题的订阅者,同时保存带有Retain 标志的最新的消息。此时,若别的订阅者订阅了主题,就能马上收到带有Retain 标志的新消息(图2.14)。

Will
Will 有“遗言”的意思。由于中介的I/O 错误或网络故障等情况,发布者可能会突然从中介断开,Will 就是专门针对于这种情况的一个机构,它用于定义中介向订阅者发送的消息(图2.15)。
发布者在连接中介时会用到CONNECT(连接)消息,连接时对其指定Will 标志、要发送的消息以及QoS。这样一来,如果连接意外断开,Will 消息就会被传递给订阅者。另外,还有一个标志叫作WillRetain。通过指定这个标志,就能跟前面说的Retain 达到同样的效果,即在中介处保存消息。

当发布者使用DISCONNECT(断开连接)消息明确表明连接已断开时,Will 消息就不会被发送给订阅者。
Clean session
Clean session 用于指定中介是否保留了订阅者的已订阅状态。用CONNECT 消息连接时,订阅者把Clean session 标志设定为0 或1。0是保留session,1 是不保留session。
若指定Clean session 为0 且中介已经连接上了订阅者,则中介需要在订阅者断开连接后保留订阅的消息。另外,如果订阅者的连接已经断开,且发布者已经发布了QoS 1、QoS 2 的消息给已订阅的主题时,中介则会把消息保存,等订阅者再次连接时发送给订阅者(图2.16)。
若指定Clean session 为1 并连接,中介就会废弃以往保留的客户端信息,将其当成一次“干净”的连接来看待。此外,订阅者断开连接时,中介也会废弃所有的信息。

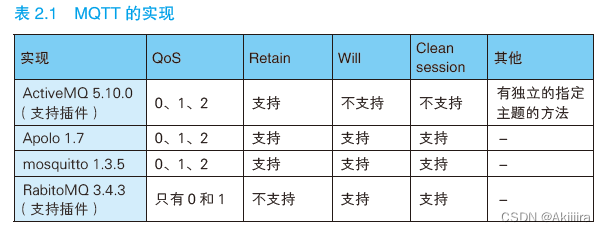
我们可以用表2.1 所示的几种产品来实现MQTT。是否支持前文介绍的功能则取决于中介的种类。
除此之外,一个叫作Paho 的库还公开了发布者和订阅者等客户端功能。不仅Java、JavaScript、Python 配备了Paho,连C 语言和C++ 都配备了Paho。因此,我们能够将其与设备结合起来并加以使用。
2.3.5 数据格式
前面我们围绕用于接收数据的通信过程,即协议进行了讲解。事实上,数据就是通过协议来进行交换的。当然,就如我们前文所说,这条规则在物联网的世界里也是不变的。数据要经过协议进行交换,而数据的格式也很重要。通过Web 协议来使用的数据格式中,具有代表性的包括XML 和JSON(图2.17)。

从物联网的角度来说,使用者也能很方便地使用XML 和JSON。举个例子,假设设备要发送传感器的值,此时除了发送传感器的值以外,还要一并发送数据接收时间、设备的机器信息以及用户信息等数据。自然,设备还会通知多个传感器的值和机器的状态。这样一来,使用者就需要好好地把从设备发送来的数据结构化。
图2.18 用XML 和JSON 分别表示了两台传感器的信息、设备的状态、获取数据的时间,以及发送数据的设备名称等。

比较二者可知,XML 的格式比JSON 更容易理解。然而XML 的字符数较多,数据量较大。相对而言,JSON 比XML 字符数少,数据量也小。
XML 和JSON 这两种数据格式都在每种语言中实现了各自的库,使用者通过程序就能很轻松地使用这些库。那么到底使用哪种才好呢?关于这点我们不能一概而论,不过JSON 数据量小,更适合使用移动线路等低速线路通信的情况。
设备传来的数据和Web 不一样,大多是传感器、图像、语音等数值数据。相较于文本而言,这样的数据更适合用二进制来处理。不过,我们前文介绍的XML 和JSON 都是用文本格式来处理数据的。
基于物联网服务处理这些格式时,要把文本数据转换成数值数据和二进制数据。因此需要进行两项工作,即解析XML 和JSON 格式,以及把解析结果从文本格式转换到二进制形式。这样一来,就需要分两步来处理。
如果能直接以二进制形式接收数据,是不是就能更迅速地处理数据了呢?由此,一种数据格式应运而生,它就是MessagePack(图2.19)。
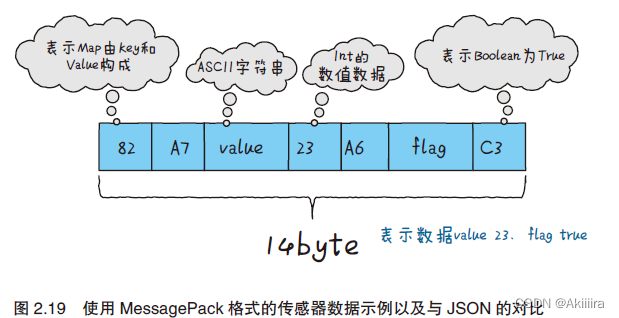
MessagePack 的数据格式虽然跟JSON 相似,其数据却保留了二进制的形式。因此,虽然这种数据格式不方便人们直接阅读,但计算机却能很容易地处理。
又因为MessagePack 发送的是二进制数据,所以比起以文本形式发送数据的JSON,数据更加紧凑。MessagePack 跟XML 和JSON 一样,都提供了面向多种编程语言的库,另外,近年来多个OSS(开源软件)也都采用了MessagePack。
我们不能一口咬定哪种格式好,哪种格式不好,请各位根据要发送的数据的特性,来选择符合目的的数据格式。
2.4 处理数据
2.4.1 处理服务器的作用
很显然,处理服务器就是处理接收到的数据的地方。“处理”是一个抽象的词语,例如保存数据,以及转换数据以使其看上去更易懂,还有从多台传感器的数据中发现新的数据,这些都是处理。使用者的目的不同,处理服务器的内容也各异。不过说到数据的处理方法,它可以归纳成以下4 种:数据分析、数据加工、数据保存以及向设备发出指令(图2.20)。
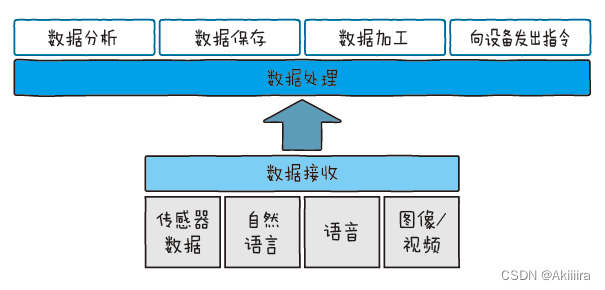
关于数据的分析和加工,有两种典型的处理方式,分别叫作“批处理”和“流处理”。首先就来说说这个“批处理”和“流处理”。
2.4.2 批处理
批处理的方法是隔一段时间就分批处理一次积攒的数据。一般情况下是先把数据存入数据库里,隔一段时间就从数据库获取数据,执行处理。批处理的重点在于要在规定时间内处理所有数据。因此,数据的数量越多,执行处理的机器性能就得越好。
今后设备的数量将会增加,这一点在第一章已经解释过了。人们需要处理从数量庞大的设备发来的传感器数据和图像等大型数据,这被称为“大数据”。不过,通过使用一种叫作分布式处理平台的平台软件,就能高效地处理数兆、数千兆这种大型数据了。具有代表性的分布式处理平台包括Hadoop 和Spark。
Apache Hadoop
Apache Hadoop 是一个对大规模数据进行分布式处理的开源框架。Hadoop 有一种叫作MapReduce 的机制,用来高效处理数据。MapReduce是一种专门用于在分布式环境下高效处理数据的机制,它基本由Map、Shuffle、Reduce 这3 种处理构成(图2.21)。

Hadoop 对于每个被称为节点的服务器执行MapReduce,并统计结果。首先是分割数据,这里的数据指的是各个服务器的处理对象。最初负责分割数据的是Map。Map 对于每条数据反复执行同一项处理,通过Map 而发生变更的数据会被移送到下一项处理,即Shuffle。Shuffle 会跨Hadoop 的节点来把同种类的数据进行分类。最后,Reduce 把分类好的数据汇总。
也就是说,MapReduce 是一种类似于收集硬币,按种类给硬币分类后再点数的方法。用Hadoop 执行处理的时候,为了能用MapReduce 实现处理内容,使用者需要下一番工夫。
另外,Hadoop 还有一种叫分布式文件系统(HDFS)的机制,用于在分布式环境下运行Hadoop。HDFS 把数据分割并存入多个磁盘里,读取数据时,就从多个磁盘里同时读取分割好的数据。这样一来,跟从一台磁盘里读出巨大的文件相比,这种方法更能高速地进行读取。如上所述,如果使用MapReduce 和HDFS 这两种机制,Hadoop 就能高速处理巨型数据。
Apache Spark
Apache Spark 也和Hadoop 一样,是一个分布式处理大规模数据的开源框架。Spark 用一种叫作RDD(Resilient Distributed Dataset,弹性分布数据集)的数据结构来处理数据(图2.22)。

RDD 能够把数据放在内存上,不经过磁盘访问也能处理数据。而且RDD 使用的内存不能被写入,所以要在新的内存上展开处理结果。通过保持内存之间的关系,就能从必要的时间点开始计算,即使再次计算也不用从头算起。根据这些条件,Spark 在反复处理同一数据时(如机器学习等),就能非常高速地运行了。
对物联网而言,传输的数据都是一些像传感器数据、语音、图像这种比较大的数据。批处理能够存储这些数据,然后导出当天的设备使用情况,以及通过图像处理从拍摄的图像来调查环境的变化。随着设备的增加,想必今后这样的大型数据会越来越多。因此,重要的是学会在批处理中使用我们介绍的分布式处理平台。
2.4.3 流处理
批处理是把数据攒起来,一次性进行处理的方法。相对而言,流处理是不保存数据,按照到达处理服务器的顺序对数据依次进行处理。
想实时对数据做出反应时,流处理是一个很有效的处理方法。因为批处理是把数据积攒之后隔一段时间进行处理,所以从数据到达之后到处理完毕为止,会出现时间延迟。因此,流处理这种把到达的数据逐次进行处理的思路就变得很重要了。此外,流处理基本上是不会保存数据的。只要是被使用过的数据,如果没必要保存,就会直接丢弃。
举个例子,假设有个系统,这个系统会对道路上行驶的车辆的当前位置和车辆雨刷的运转情况进行搜集。
仅凭搜集那些雨刷正在运转的车辆的当前位置,就能够实时确定哪片地区正在下雨。此时,使用者可能想保存下过雨的地区的数据,这时候只要保存处理结果就好,所以原来的传感器数据可以丢掉不要,流处理正适用于这种情况。用流处理平台就能实现流处理。
流处理和批处理一样,也准备了框架。在这里就给大家介绍一下Apache Spark 和Apache Storm 这两个框架。
Spark Streaming
Spark Streaming 是作为Apache Spark(在“批处理”部分介绍过)的库被公开的。通过Spark Streaming,就能够把Apache Spark 拿到流处理中来使用(图2.23)。

Spark Streaming 是用RDD 分割数据行的,它通过对分割的数据执行小批量的批处理来实现流处理。输入的数据会被转换成一种叫作DStream 的细且连续的RDD。先对一个RDD 执行Spark 的批处理,将其转换成别的RDD,然后按顺序对所有RDD 反复执行上述处理来实现流处理。
Apache Storm
Apache Storm 是用于实现流处理的框架,结构如图2.24 所示。

用Storm 处理的数据叫作Tuple,这个Tuple 的流程叫作Streams。
Storm 的处理过程由Spout 和Bolts 两项处理构成,这种结构叫作Topology。Spout 从其他处理接收到数据的时候,Storm 处理就开始了。Spout 把接收到的数据分割成Tuple,然后将其流入Topology 来生成Streams,这就形成了流处理的入口。接下来,Bolts 接收Spout 以及从其他Bolts 输出的Streams,并以Tuple 为单位处理收到的Streams,然后将其作为新的Streams 输出。可以自由组合Bolts 之间的连接,也可以根据想执行的处理自由组合Topology,还可以随意决定Tuple 使用的数据类型,以及使用JSON 等数据格式。
2.5 存储数据
2.5.1 数据库的作用
数据库的作用是保存并灵活运用数据(图2.25)。除此之外,其作用还包括从保存的数据中找出与所指定条件相符的数据。另外,数据库还能把多条数据连在一起,把它们作为一个数据取出。
打个比方,已知与特定传感器相关的ID,测量时间,以及温度传感器的值。光凭这些数据,是无法理解数据指的是哪个房间的温度的。因此就需要传感器的ID 以及跟房间名字有关的数据。把这两条数据加在一起,才能知道某房间的温度。
图2.25 展示的是一个叫作RDB(关系数据库)的数据库。最近,除了RDB 以外还出现了一种叫作NoSQL 的数据库。
RDB 用一种叫作SQL 的专门用来操作数据库的语言来保存和提取数据。另一方面,NoSQL 则是用SQL 以外的各种方法来操作数据库。本书章还会介绍键值存储(Key-Value Store,简称KVS)和文档型数据库等种类的数据库。

2.5.2 数据库的种类和特征
这里我们一并为大家说明数据库的种类和特征,以及为了实现物联网服务而处理设备数据时的要点。
关系数据库
关系数据库是人们用得最普遍的数据库。如图2.25 所示,关系数据库具备一种叫作表格的表格型数据结构,其用途在于存储数据库,使用者用SQL 语言来对其执行数据的提取、插入以及删除。
SQL 是一种非常强大的语言,它能用非常简洁的表述写出命令,来把多个表格联系到一起,搜索符合目标条件的数据。此外,使用者还能通过多种多样的编程语言来使用SQL。不过一旦确定了表格,就很难更改其结构了。因此,需要仔细考虑设备传来的数据性质再决定结构。
举个例子,假设由于传感器和设备的增加而导致一些必须保存的数据增多,此时,如果表格结构如图2.26 所示,那么就很难再追加新的数据了。

在A 表这种情况下,我们就必须变更表格的条目。而换成B 表就没必要更改表格本身。不过,这样一来就需要生成一个新的表格。
因此,如图2.27 所示,要生成一个结构来把所有传感器数据插入同一个字段里。采用这个结构时,即使来了新的传感器数据,也没有必要更改表格结构或是追加新的表格。不过传感器数据的类型必须是统一的,而且,这样一来就会在同一个表格里注册大量的数据。这种情况下,有时就得花一段时间才能从表格里检索到我们需要的数据。为了解决这个麻烦,数据库提供了一个叫作索引的机制。
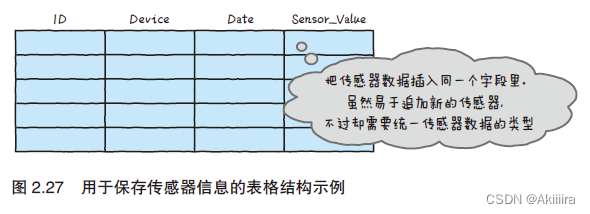
以上列举的表格就是一个例子。关于用哪种方法构成表格更好,我们不能一概而论,而是需要先考虑注册的是怎样的数据,以后又会积累多少数据,然后再下决定。
关系数据库也不擅长保存图像和语音等二进制形式的数据。虽然能够用一种叫作BLOB(Binary Large Object,二进制大对象)的数据形式来达到保存的目的,不过,这也需要另费一番工夫,因为根据用途,有时需要把图像直接保存为文件,把图像的路径单独保存在RDB 里(图2.28)。
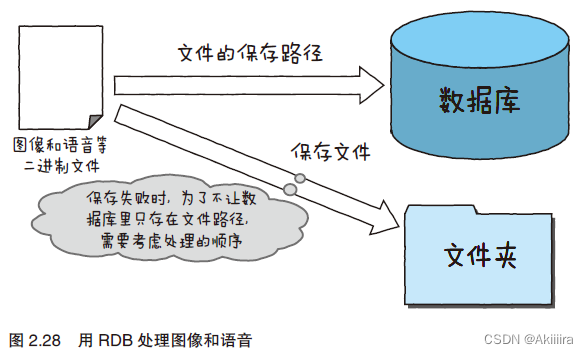
数据库把数据保存到硬盘,因此经常会发生对硬盘的访问(磁盘I/O)。这样一来,这步处理就比其他处理要慢。就系统中而言,这是处理速度方面容易产生瓶颈的一个地方。除了介绍的内容之外,还有一些需要大家注意的地方,希望大家加深对这部分内容的理解并将其灵活运用。
键值存储
键值存储属于NoSQL 数据库的一种。NoSQL 是一种不使用SQL的数据库的统称。键值存储,就是把一种叫作“值”(value)的数据值,和能够一对一特定“值”的“键”(key)的集合保存在一起。
此外,还有把数据保存在内存里的键值存储,以及把数据保存在硬盘里的键值存储。前者一方面能够高速保存数据,而另一方面,因为数据是放在内存上的,所以软件停止运行的时候,原先保存的内容就会丢失。因此前者适合作为缓存来使用。
而后者保存数据的速度虽然不及前者,但即使软件停止运行,数据也不会丢失。
有一种叫作Redis 的键值存储,它具备前后两者的性质,在通常情况下它是把数据存储在内存上的,但在任何时间都能够把数据保存到硬盘。因此,它既能够高速执行存储,也能永久保存数据。
文档型数据库
文档型数据库和键值存储一样,都属于NoSQL 数据库的一种。文档型数据库能以XML 和JSON 这种结构化文档的格式保存数据。特别是近年来,有一种叫作MongoDB 的文档型数据库很受欢迎,它以JSON 的格式保存数据(图2.29)。

MongoDB 能够直接保存JSON 格式的数据,还能用JSON 的值进行检索。这样一来,在用JSON 交换传感器的信息时,就能直接对数据进行保存和使用。即使增加了新的数据条目或是新增了设备,也能直接以JSON 格式保存数据,因此,不需要像RDB 那样考虑表格的结构。非常适合用于无法读出设备的数量和数据的种类等情况,以及保存传感器等设备的数据。
这里对数据库的讲解也是十分简略的。数据库本身也是一门作者所学专业要单独学习的一门课程,其中的知识也不是一两句能解释的清楚的。在物联网工程的开发过程中,掌握数据库的使用方法也是十分必要的一环。详细可以参考本章附件《电子书《数据库系统原理及MySQL应用教程(第2版)》》
2.6 控制设备
2.6.1 发送服务器的作用
发送服务器的目的在于向设备发送数据并控制设备。发送服务器可以使用2.3 节介绍过的HTTP、WebSocket、MQTT 协议和数据格式。
发送服务器靠在1.3.4 节提到过的两种方法来运行,一种是通过设备申请来发送数据的同步传输;另一种是由发送服务器在任意时间发送数据的异步传输。那么,就用HTTP、WebSocket、MQTT 协议来看看如何实现同步和异步传输。
2.6.2 使用HTTP发送数据
要实现数据发送,HTTP 是最简单的方法。在这个方法里,发送服务器是等待接收HTTP 请求的Web 服务器。设备向这台服务器申请发送数据,作为响应,服务器把数据发给设备(图2.30)。

使用者需要定期从设备执行轮询连接。采用此方法的原因主要有以下两个。
原因一:无法确定唯一地址,例如无法给设备设定全局IP 地址等。这种情况下,发送服务器就不知道应该把数据发送给哪台设备了。
原因二:考虑到设备频繁断电和移动线路的传输费用。此时,设备没有持续连接网络。即使设备已经连接过网络,但只要没有持续连接,那么,即使发送服务器执行了发送数据的操作,也发不到设备那里去(图2.31)。

2.6.3 使用WebSocket发送数据
使用WebSocket 时,需要用设备连接发送服务器,并确立WebSocket连接。只要建立了一次WebSocket 连接,就能实现从发送服务器和客户端发送数据。
2.6.4 使用MQTT发送数据
前文介绍了HTTP 和WebSocket,它们采用的方法都是由设备访问发送服务器。就这些方法而言,只要客户端没有发出申请,数据就不会被发送。当然使用者也可以在设备上建立HTTP 和WebSocket 协议,由服务器来连接设备。不过,一旦增加了设备,服务器想管理所有设备就相当困难了。
针对这点,我们来试着看一下这种服务器:它灵活运用MQTT,并且发挥了发布/ 订阅模型的优点。使用MQTT 时的发送服务器如图2.32所示。
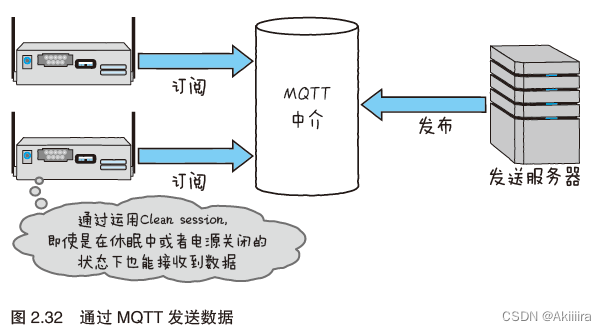
首先设备作为订阅者,向MQTT 中介进行订阅。然后,发送服务器则是发布者,同样向中介进行发布。这样一来,发送服务器只需要把确定的数据加在主题上发送就行了,发送服务器和设备都不需要知道彼此的地址。只要知道中介的地址,就能够实现通信。一旦订阅者断开,中介就会负责在断开时发送通知,并在重新连接时再次发送数据。
通过灵活运用MQTT 的功能,构建发送服务器就变得简单多了。


![[医学分割大模型系列] (1) SAM 分割大模型解析](https://img-blog.csdnimg.cn/direct/0d8c6c157e1742b5a524e36b41a233f8.png)