最近,网上疯传OpenAI2027年关于AGI的计划。在本文,我们将针对部分细节以第一人称进行分享。
摘要:OpenAI于2022年8月开始训练一个125万亿参数的多模态模型。第一个阶段是Arrakis,也叫Q*,该模型于2023年12月完成训练,但由于推理成本高而被取消。Q*是GPT-5的雏形,计划于2025年发布。由于原始GPT-5已被取消,Gobi(GPT-4.5)已重命名为GPT-5。Q*的下一阶段,最初是GPT-6,但后来更名为GPT-7(最初于2026年发布),但因埃隆·马斯克最近的诉讼而被搁置,Q*2025(GPT-8)计划于2027年发布,实现完全AGI。
...
Q* 2023 = 48 IQ
Q* 2024 = 96 IQ (delayed)
Q* 2025 = 145 IQ (delayed)
我看过很多关于AGI的定义——通用人工智能——但我将把AGI定义为一种人工智能,它可以完成聪明人所能完成的任何智力任务。这就是现在大多数人对这个词的定义。
2020年是我第一次被人工智能系统震撼——那就是GPT-3。GPT-3.5是GPT-3的升级版,是ChatGPT背后的模型。GPT-3及其升级版本GPT-3.5(是现在著名的ChatGPT的基座模型,在2023年3月升级为GPT-4),这向AGI迈出了巨大的一步。需要注意的是,像GPT-2这样的早期语言模型(以及自Eliza以来的所有聊天机器人)根本没有真正连贯的响应。那么,为什么GPT-3是如此巨大的飞跃呢?
“深度学习”这个概念基本上可以追溯到20世纪50年代人工智能研究的开端。第一个神经网络是在50年代创建的,而现代神经网络只是“更深”,这意味着它们包含更多的层——它们要大得多,并且基于更多的数据进行训练。
今天人工智能中使用的大多数主要技术都来自于20世纪50年代的基础研究,比如“反向传播”和“Transformer模型”。总的来说,人工智能研究在70年里没有发生根本性的变化。因此,人工智能能力最近爆发的真正原因只有两个:规模和数据。
越来越多的业内人士开始相信,几十年来,我们已经解决了AGI的技术细节,但直到21世纪,我们才有足够的计算能力和数据来构建它。显然,21世纪的计算机比20世纪50年代的计算机强大得多。当然,互联网是所有数据的来源。
那么,什么是参数呢?你可能已经知道了,但简单概括一下,它类似于生物大脑中的突触,是神经元之间的连接。生物大脑中的每个神经元与其他神经元有大约1000个连接。显然,数字神经网络在概念上类似于生物大脑。
那么,人类大脑中有多少突触(或“参数”)?
大脑中突触数量最常被引用的数字约为100万亿,这意味着每个神经元(人脑中约1000亿)约有1000个连接。

如果大脑中的每个神经元都有1000个连接,这意味着猫有大约2500亿个突触,狗有5300亿个突触。突触计数通常似乎可以预测更高的智力,只有少数例外:例如,从技术上讲,大象的突触计数高于人类,但智力较低。
对于智力较低的突触数量较大,最简单的解释是高质量数据量较小。从进化的角度来看,大脑是在数十亿年的表观遗传学上“训练”的数据和人类大脑是从比大象更高质量的社会化和通信数据进化而来的,这导致了我们卓越的推理能力。无论如何,突触数量绝对是重要的。
同样,自2010年代初以来,人工智能能力的爆炸是更多计算能力和更多数据的结果。GPT-2有15亿个连接,这比老鼠的大脑(约100亿个突触)还少。GPT-3有1750亿个连接,这在一定程度上接近猫的大脑。
猫大脑大小的人工智能系统会优于比老鼠大脑小的人工智能,这不是很直观吗?
2020年,在1750亿个参数GPT-3发布后,许多人猜测一个模型在100万亿个参数下的潜在性能约为600倍,因为这个参数计数将与人脑的突触计数相匹配。2020年,没有强有力的迹象表明有人在积极研究这种尺寸的模型,但这很有趣。
最大的问题是,是否可以通过参数计数来预测人工智能的性能?事实证明,答案是肯定的,正如你将在下一页看到的那样。

正如Lanrian所说明的那样,在人类水平的大脑大小与参数计数相匹配的同时,人工智能的表现似乎莫名其妙地达到了人类水平。他对大脑中突触数量的统计大约是200万亿个参数,而不是通常所说的100万亿个数字,但这一点仍然有效,在100万亿个参数下的表现非常显著接近最优。
顺便说一句,需要注意的一件重要的事情是,尽管100万亿在性能上略显次优,但OpenAI正在使用一种工程技术来弥补这一差距。我将在文档的最后解释这一点,因为它对OpenAI的构建至关重要。
Lanrian的帖子说明与先前模型之间性能的差距。OpenAI当然有更详细的指标,它们得出了与Lanrian相同的结论,我将在本文后面展示。
那么,如果人工智能的性能是基于参数计数可预测的,并且大约100万亿个参数就足以满足人类水平的性能,那么100万亿参数的人工智能模型何时发布?
GPT-5在2023年末以48的智商实现了原始AGI。
第一次提到OpenAI正在开发的100万亿参数模型是在2021年夏天,Cerebras公司CEO(Andrew Feldman)在有线采访中即兴提到了Sam Altman是该公司的主要投资者。

Sam Altman在2021年9月举行的名为AC10的在线会议和问答中对安德鲁·费尔德曼的回应。值得注意的是,Sam Altman承认他们的100万亿参数模型计划。

仅仅几周后,人工智能研究人员Igor Baikov就声称GPT-4正在接受训练,并将在12月至2月间发布。我将再次证明,Igor确实掌握了准确的信息。
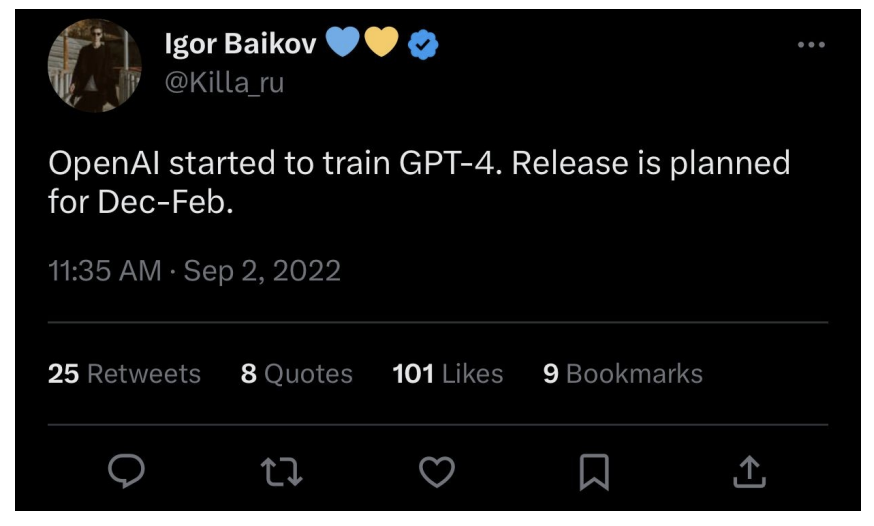
Gwern是人工智能界的著名人物——他是一名人工智能研究人员和博客作者。他在推特上给Igor Baikov发了信息(2022年9月),这是他收到的回复。重要的是要记住:“Colossal number of parameters”.“Text”, “audio”, “images”, “possibly video”以及“multimodal”。这来自一个名为“thisisthewayitwillbe”的子版块,由一位对AGI感兴趣的数学教授运营。人工智能爱好者(和一些专家)使用reddit子网站来深入讨论人工智能话题,而不是主流话题。
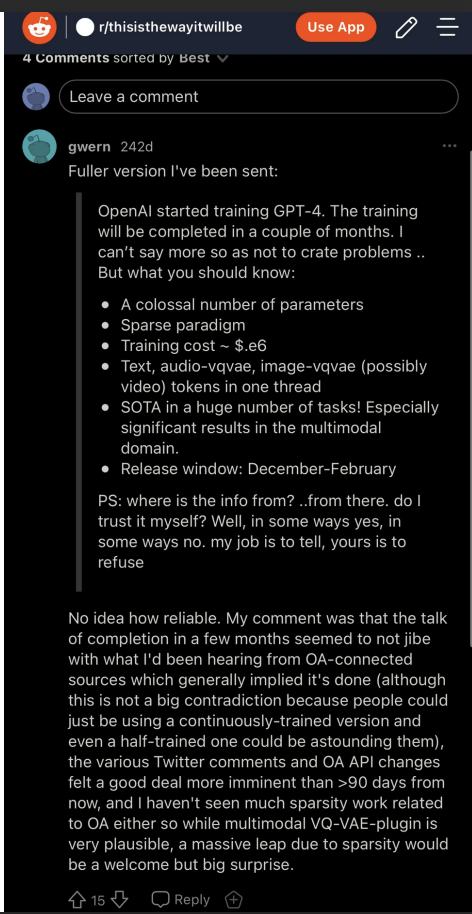
根据Igor Baikov 对“Colossal number of parameters”?的理解,指的是一个100万亿参数模型,5000亿参数模型和多达1万亿参数模型已经被训练了很多次。
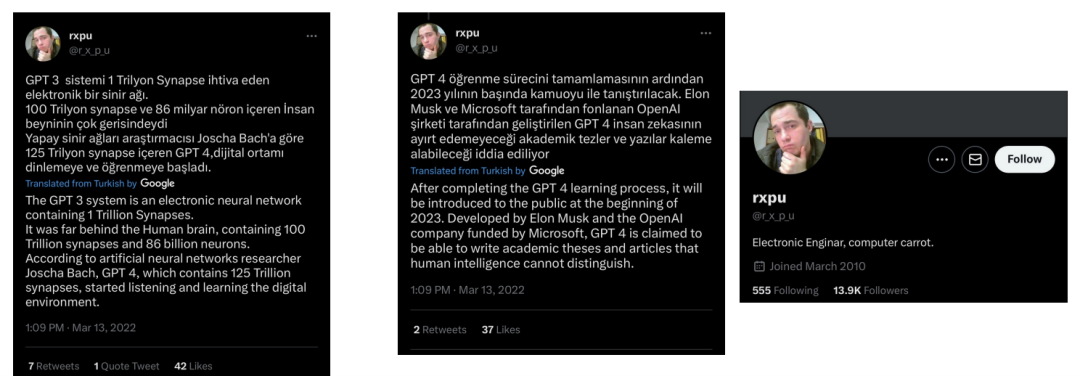
这些来自“rxpu”的推文很有趣,他似乎是一位来自土耳其的人工智能爱好者,因为他们在其他人之前对GPT-4的发布窗口做出了非常相似的声明(相信我——我每天花很多小时在互联网上搜索类似的声明,在他之前没有其他人做出过具体的声明)。
他还提到了“125万亿突触”GPT-4——然而,他错误地将GPT-3的参数计数称为1万亿。(看起来rxpu确实有内幕信息,但与参数计数混淆了——我稍后将再次说明这一点,并证明rxpu没有撒谎)。
这是一个较弱的证据,因为“roon”作为硅谷人工智能研究人员相当引人注目,紧随其后的是OpenAI首席执行官Sam Altman和推特上的其他OpenAI研究人员。

2022年11月,我联系了一位名叫Alberto Romero的人工智能博主。他的帖子似乎在网上传播得很广,所以我希望如果我给他发一些关于GPT-4的基本信息,他可能会写一篇文章,消息就会传开。
正如我将在接下来的两页中展示的那样,这次尝试的结果非常显著。
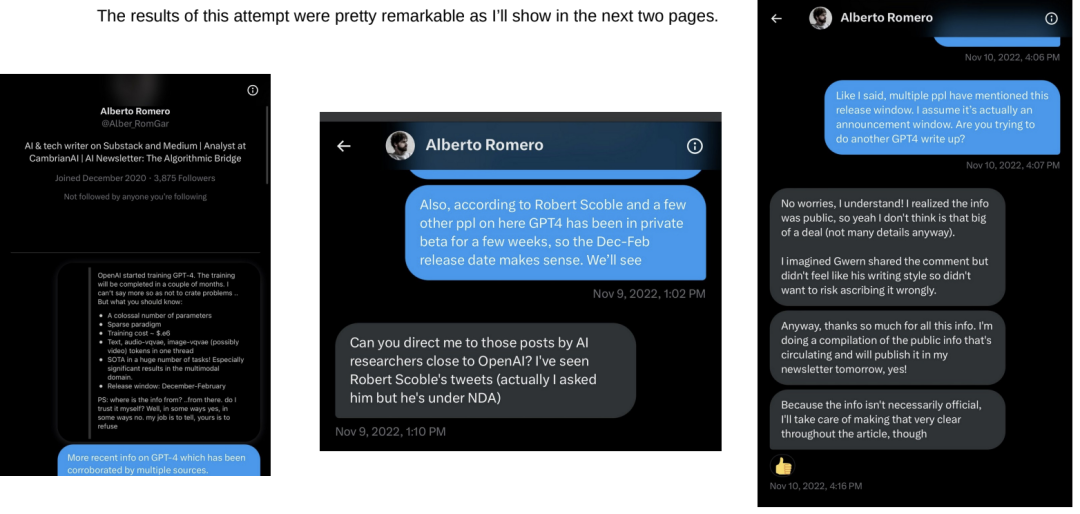
Alberto Romero的帖子。一般回复将显示在下一页。

这起100万亿参数泄露事件在网上疯传,波及数百万人,以至于包括首席执行官Sam Altman在内的OpenAI员工不得不做出回应,称其为“彻头彻尾的胡说八道”。The Verge称其“事实不正确”。正如你在左边看到的,Alberto Romero声称对泄漏事件负责。
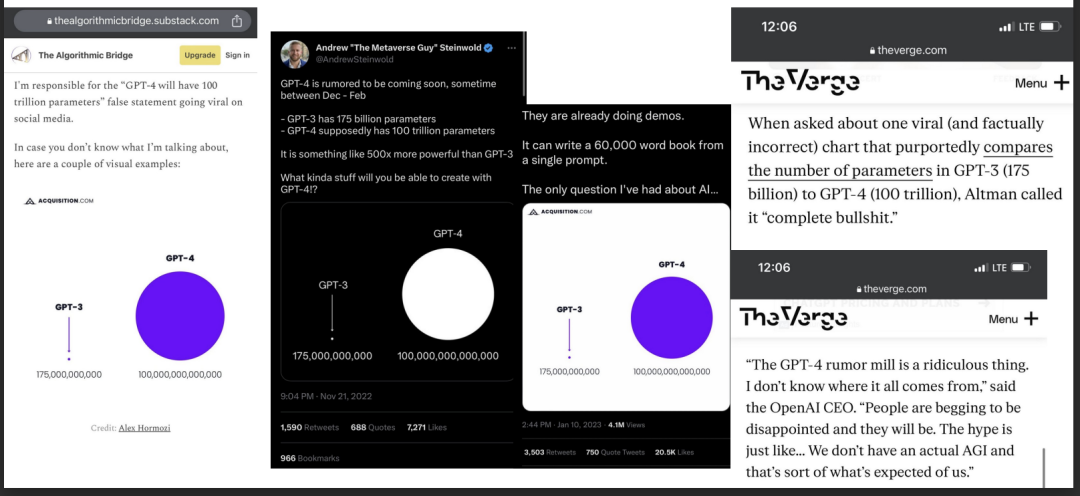
Igor说“Colossal number of parameters”时,他的意思确实是“100万亿个参数”。
但是,Igor消息的来源可靠吗?他的其他说法准确吗?多模态呢?GPT-4处理图像、声音和视频的能力如何?我很快就会证明Igor的可靠性。
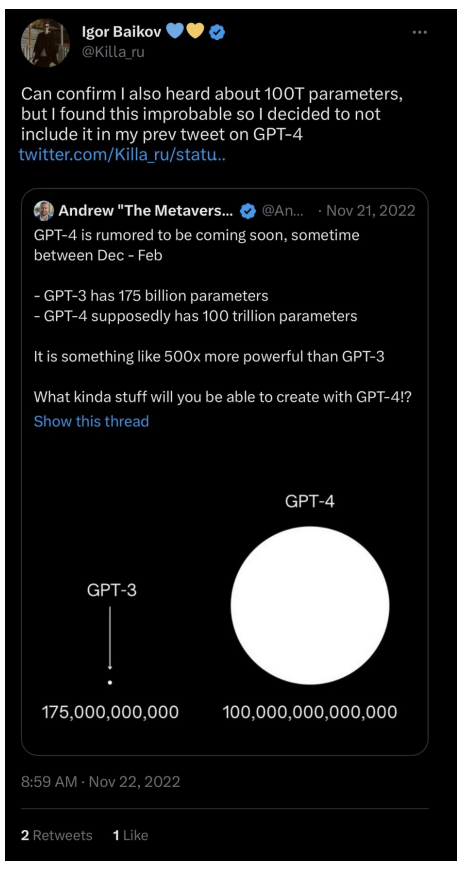
大约在2022年10月/11月的某个时候,我确信OpenAI计划在发布完整的100万亿参数模型(“GPT-5”)之前,首先发布GPT-4的约1-2万亿参数子集。这些消息来源并不特别可靠,但他们都说了同样的话——包括rxpu,他曾经声称有一个125万亿的参数模型在研究中,然后错误地声称GPT-3是1万亿——我相信他把信息搞混了。

这里的消息来源可信度各不相同(Jyri和Leeor是旧金山的投资者,Harris是人工智能研究员),但他们都莫名其妙地说了同样的话——GPT-4在2022年10月/11月进行了测试。根据美国军事人工智能研究人员Cherie M Poland的说法,它肯定在10月接受训练,这再次与Igor Baikov的泄密事件相吻合。
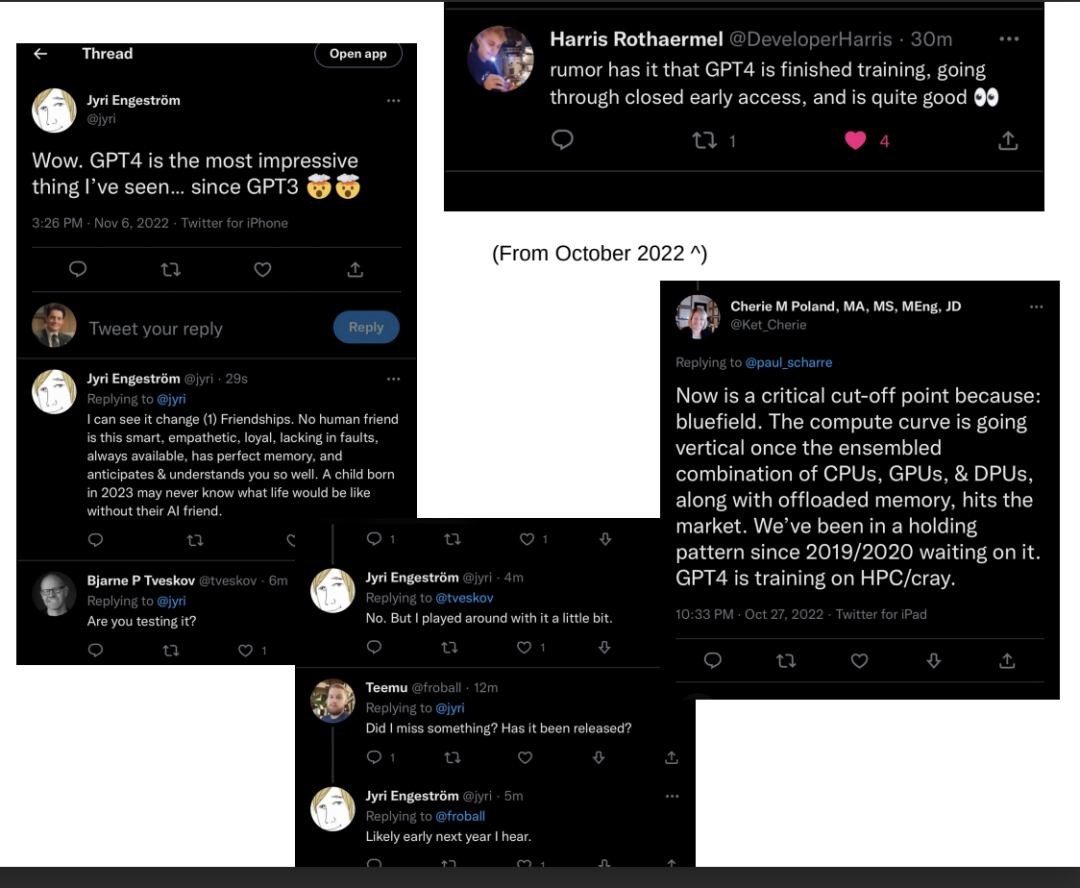
正如Sam Altman本人所证明的那样,OpenAI的官方立场是,100万亿参数GPT-4的想法“完全是胡说八道”。这是对的一半,因为GPT-4是完整的100万亿参数模型的1万亿参数子集。

为了说明100万亿参数模型尚未到来,仍在开发中,Semafor在2023年3月(GPT-4发布后不久)声称GPT-4是1万亿参数。(OpenAI拒绝披露参数量)。

另一件毫无价值的事情是,OpenAI声称GPT-4在8月“完成了训练”,而我们知道8月至10月期间正在训练一个“巨大”的多模态模型。对此的一种解释是,OpenAI撒谎了。另一种可能性是,1万亿参数GPT-4可能在8月完成了第一轮训练,但在8月至10月之间进行了额外的再训练,这是整个100万亿参数模型的大部分训练时间。
我将提供我的证据,证明GPT-4不仅接受了文本和图像训练,还接受了音频和视频训练。
Francis Hellyer似乎可信,但这一页并不是最可靠的证据——我之所以把它包括在内,是因为它似乎证实了其他消息来源的说法。弗朗西斯是一位投资者、企业家和作家。他在推文中列出的关于团队“互联网即将耗尽”的信息在任何其他出版物、任何泄露或任何在线帖子中都找不到,所以他没有从其他地方“窃取”这些信息。
下一页上有一个非常可靠的来源。

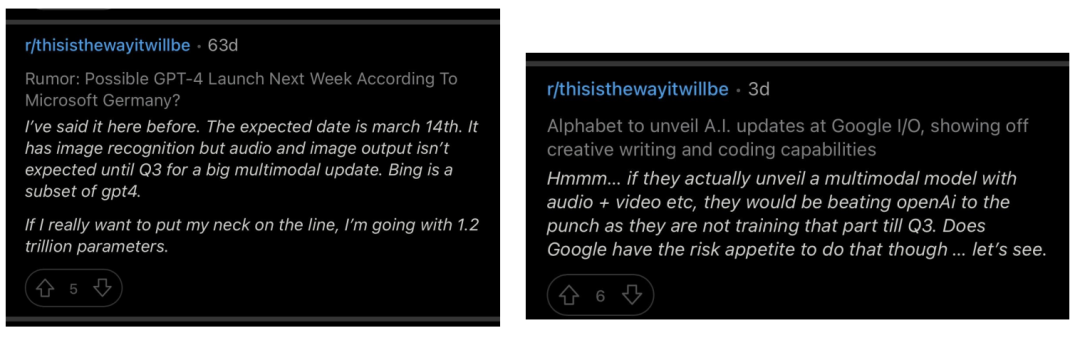
在GPT-4正式发布的前一周,微软德国公司的CTO似乎出现了失误,并透露存在一种能够处理视频的GPT-4。我想他不知道OpenAI决定不透露系统的视频功能。
这完全证明GPT-4/5不仅在文本和图像上训练,而且在视频数据上训练,当然我们可以推断音频数据也包括在内。

显然,Igor关于100万亿参数模型的说法是正确的,直到每一个精确的细节。
另一个与Igor说法一致的消息来源是一位可靠的企业家,他表示(2022年10月25日)GPT-4的发布日期将在2023年1月至2月之间:
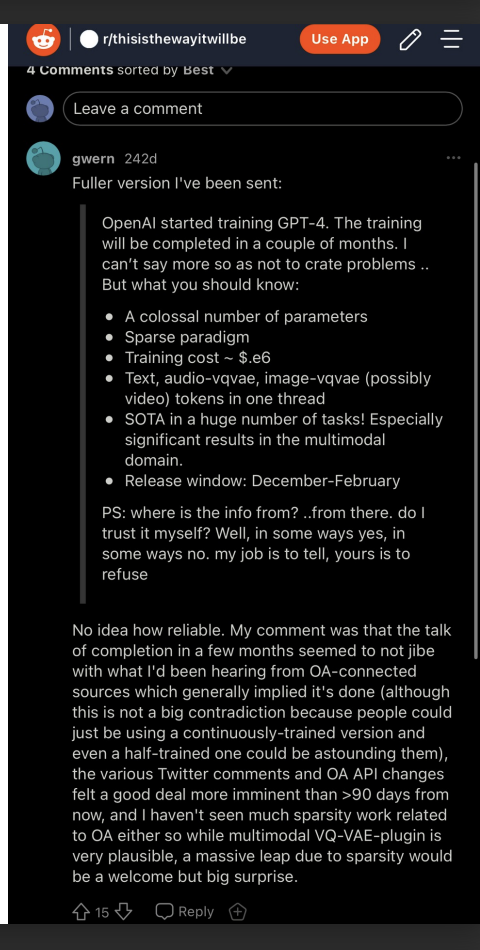

尽管GPT-4发布于2023年3月,略晚于Igor Baikov声称的12月至2月窗口期(我认为这是OpenAI故意抹黑Igor的泄露),但Bing ChatGPT(基于GPT-4)实际上是在2023年2月发布的,这清楚地表明Igor声称的窗口期是有效的,很可能在最后一分钟被惊慌失措的OpenAI更改了。

关于机器人:人工智能研究人员开始相信,视觉是实现最佳现实世界/物理性能所必需的一切。举一个例子,特斯拉完全抛弃了所有传感器,完全致力于基于视觉的自动驾驶汽车方案。
在互联网上的所有图像和视频数据上训练一个人脑大小的人工智能模型足以处理复杂的机器人任务。常识性推理被隐藏在视频数据中,就像它被隐藏在文本数据中一样(以文本为中心的GPT-4非常擅长常识性推理)。

谷歌最近的一个例子是,从一个大型视觉/语言模型中学习机器人能力。(除了语言和视觉训练外,还需要最少的机器人数据,视觉和文本任务中的知识转移到机器人任务中。OpenAI正在“互联网上的所有数据”上训练他们的100万亿参数模型,其中无疑包括机器人数据)。Palm-E是一个约5000亿的参数模型——当你根据互联网上所有可用的数据训练一个100万亿的参数模型时,机器人的性能会发生什么?(下一页有更多关于谷歌Palm-E机型的信息)。


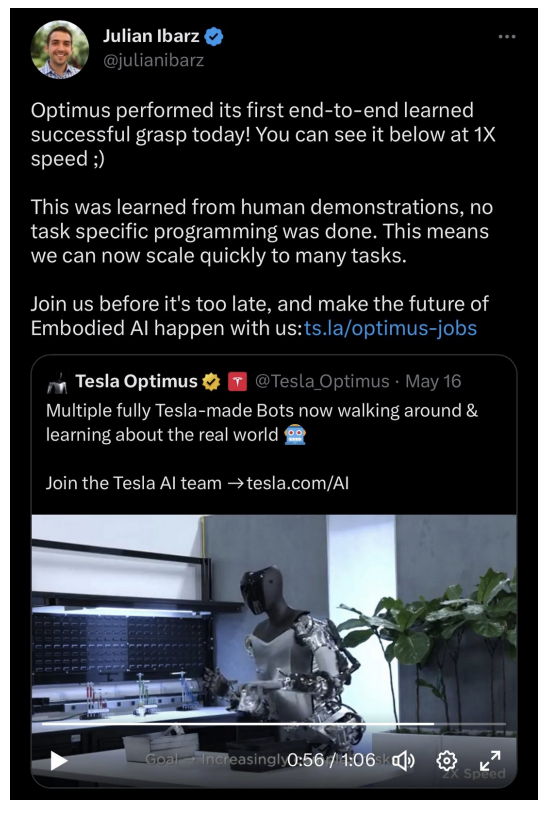
另一项机器人技术开发——这次来自特斯拉(2023年5月16日)。他们训练他们的机器人“擎天柱”来抓住一个物体——而且“没有完成特定任务的编程”。一切都是从人类身上学到的示威。
“这意味着我们现在可以快速扩展到许多任务。”
再一次:如果高级机器人性能只需要人类演示,那么在网络上所有视频上训练的100万亿参数模型肯定能够实现惊人的机器人性能。
左边的图像显示了1万亿参数GPT-4在图像识别方面的能力。这种反应已经比许多人类所能想到的更清晰、写得更好了。那么,当你根据互联网上的所有数据训练一个比GPT-4大100倍的模型时,会发生什么呢?GPT-4是人脑的大小?


公开可用的视频和图像生成AI模型的当前质量水平示例。这些模型的参数大小不到100亿。当你用互联网上的所有可用数据训练一个大一万倍的模型,并使其能够生成图像和视频时,会发生什么?(答案是:图像和视频与真实事物完全无法区分,100%的情况下,没有例外,没有变通办法,任何人都无法区分,无论他们多么努力)。-(更新:SORA来自GPT-5 Q*2023型号)
Longjumpting-Sky-1971的两个帖子。我之所以包括这一点,是因为他提前几周准确预测了GPT-4的发布日期(没有其他人提前公开发布这一信息,这意味着他有内部消息来源)。他的帖子现在有了更多的可信度——他声称图像和音频生成将在2023年第三季度进行培训。如果视频生成训练是同时进行的或之后不久进行的,这与陈思琪关于GPT-5将于2023年12月完成训练的说法一致。
让我们回到2020年2月,也就是GPT-3发布的几个月前。《技术评论》的一篇关于OpenAI的“内幕”文章似乎表明,OpenAI正处于一个“秘密”项目的早期阶段,该项目涉及一个基于图像、文本和“其他数据”的人工智能系统,OpenAI的领导层认为这是实现AGI的最有希望的方式。我想知道这可能指的是什么。
下一张幻灯片将展示2019年OpenAI总裁的一些语录,并告诉您他们的计划是什么。

OpenAI总裁Greg Brockman在2019年表示,在微软当时投资10亿美元后,OpenAI计划在五年内建立一个人脑大小的模型,这是他们的计划如何实现AGI。
2019 + 5 = 2024

这两个消息来源显然都指的是实现AGI的同一计划——一种人脑大小的人工智能模型,基于“图像、文本和其他数据”进行训练,将在2019年的五年内进行训练,到2024年。似乎与我在这份文件中列出的所有其他来源一致。


正如我将在接下来的几张幻灯片中展示的那样,人工智能领导者突然开始敲响警钟——几乎就像他们知道了一些公众不知道的非常具体的事情。
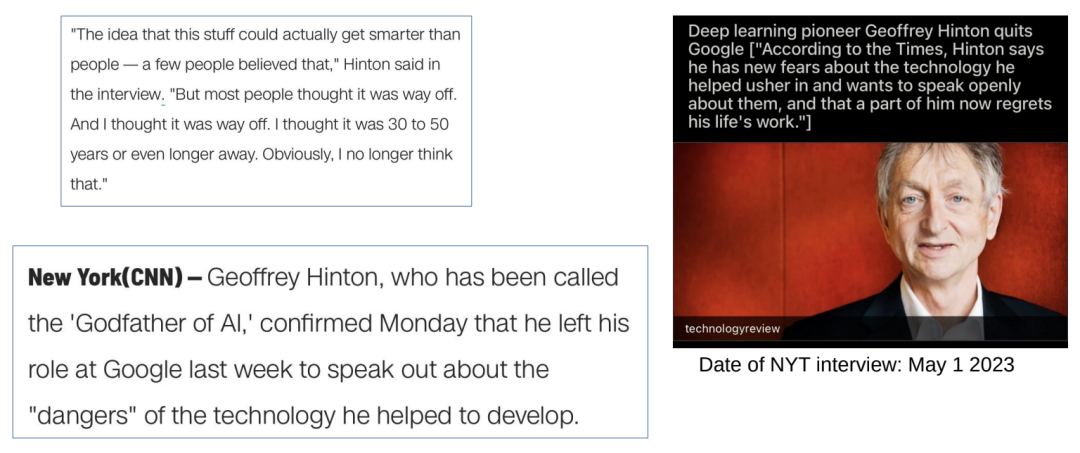
“我以为还有30到50年甚至更长的时间。显然,我不再这么认为了。”
是什么让他突然改变主意——决定离开谷歌去谈论人工智能的危险?

GPT-4发布后不久,关注减轻世界潜在灾难性风险的极具影响力的非营利组织生命未来研究所发布了一封公开信,呼吁所有人工智能实验室暂停人工智能开发六个月。为什么?
这封信的第一个发布版本特别提到了“(包括目前正在训练的GPT-5)”。为什么它被包括在内,为什么它被删除?

2022年10月,Sam Altman的一次采访和问答中引用了一些令人震惊的话——youtube链接:https://m.youtube.com/watch?v=b022FECpNe8(时间:49:30)
观众问答问题:“我们在互联网来创建AGI?”
Sam Altman直率而直接的回答打断了提问者的提问:
“对”
Sam详细阐述道:“是的,我们有信心。我们对此进行了大量思考和衡量。”
面试官插话道:“是什么给了你这种自信?”
Sam的回答是:“我认为OpenAI在这个非常健康的领域所做的一件事是,你可以将缩放定律视为一种科学预测。你可以为计算这样做,也可以为数据这样做,但你可以在小规模上进行测量,你可以非常准确地预测它将如何缩放。你需要多少数据,需要多少计算,需要多少参数,何时生成的数据足够好,可以提供帮助……互联网……有很多数据。还有很多视频。”

Sam Altman问答中的另一句话——(时间:53:00)[注意——人工智能的冬天是指人工智能领域受到限制的延长时间资金,并没有得到认真研究人员的太多关注。这种情况发生过两次——一次是在70年代和80年代,另一次是从80年代中期到21世纪末。]
另一位观众提问:“我们能再过一个人工智能冬天吗可能导致它?”
Sam Altman回应道:“我们会有一个人工智能的冬天吗?是的,当然是什么原因造成的。我认为我们不会很快有一个冬天。因为即使我们再也找不到另一个研究想法,当前范式的经济价值和可以进一步推进的程度也会让我们在未来的许多年里走下去。但无论可能性如何,我们仍有可能错过超越行为克隆的关键想法,这些模型将永远停留在人类层面。我不认为这是真的,有很多原因,但如果有人告诉我们不可能在这个研究领域再经历一个冬天,你永远不应该相信他们。”
首先,Sam Altman似乎高度、高度自信地认为,互联网上有足够的数据来训练AGI系统——自信到让人怀疑他们是否已经这样做了,或者正在这样做。
其次,“AI冬天”的概念通常指的是向AGI的进展放缓的时期,但Sam Altman重新定义了这个术语,指的是朝超智能的进展放缓。这似乎表明,OpenAI已经构建了一个AGI系统,或者非常接近它,AGI不再是目标,因为它已经存在。
正如我在文件中早些时候提到的,100万亿参数模型实际上有点次优,但OpenAI正在使用一种新的缩放范式来弥补这一差距——它基于一种名为“Chinchilla缩放定律”的东西
Chinchilla是DeepMind于2022年初推出的一款人工智能模型。Chinchilla研究论文的含义是,当前的模型训练严重不足,如果有更多的计算(意味着更多的数据),将在不需要增加参数的情况下大幅提高性能。
关键是,虽然训练不足的100万亿参数模型可能有点次优,但如果它在更多的数据上进行训练,它将很容易超过人类水平的性能。
Chinchilla范式在机器学习领域被广泛理解和接受,但仅举一个OpenAI的具体例子,总裁Greg Brockman在本次采访中讨论了OpenAI如何意识到他们最初的缩放定律是有缺陷的,并从那时起进行了调整,以将Chinchila定律考虑在内:https://youtu.be/Rp3A5q9L_bg?t=1323
人们说,“训练一个计算最优的100万亿参数模型将花费数十亿美元,而且是不可行的。”好吧,微软在2023年初刚刚向OpenAI投资了100亿美元,所以我想这毕竟不是一种荒谬的可能性。。。
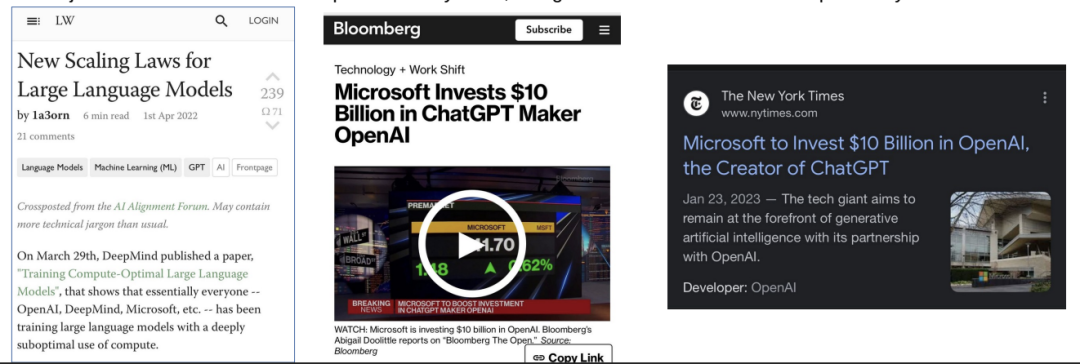
Alberto Romero写了一篇关于DeepMind的Chinchilla缩放突破的文章。Chinchilla表明,尽管它比GPT-3和DeepMind自己的Gopher小得多,但由于接受了更多数据的训练,它的表现优于它们。再次重申这一点:尽管预计100万亿参数模型的性能会略次优,但OpenAI非常清楚Chinchilla缩放定律(就像人工智能领域的几乎所有其他人一样),他们正在将Q*训练为一个100万亿参数的多模态模型,该模型是COMPUTE OPTIMAL,并在比最初多得多的数据上进行训练预定的他们现在有资金通过微软来做这件事。这将导致一个FAR,FAR超过他们最初计划的100万亿参数模型的性能的模型。没有Chinchilla比例定律的100万亿个参数=大致为人类水平,但略次优。100万亿参数,多模态,考虑Chinchilla比例定律=?

从2022年7月开始,美国开始采取行动,阻止新的计算机芯片运往中国,试图阻止其人工智能的发展。该计划于2022年10月最终确定。根据旧金山人工智能研究人员Israel Gonzales-Brooks的说法,Sam Altman于2022年9月在华盛顿。以色列声称与萨姆·奥特曼有联系(我无法证实这一点),但让他可信的是,萨姆·奥特曼被证实于2023年1月前往华盛顿。
如果GPT-4/GPT-5在2022年夏天开始训练,而萨姆·奥特曼在此期间访问了DC(可能多次),那么中国的芯片禁令不可能是巧合。

OpenAI计划到2027年建立人类级的人工智能,然后扩展到超级智能。由于埃隆·马斯克的诉讼,这项计划被推迟了,但仍将很快到来。

最后,我将揭示一个令人难以置信的信息来源——来自著名计算机科学家Scott Aaronson。2022年夏天,他加入OpenAI一年,致力于人工智能安全。他在他的博客上有一些非常有趣的事情要说,我接下来会展示。
斯科特·阿朗森在2022年12月底写了一篇博客文章,这是一封“给11岁的自己的信”,讨论了时事和他在生活中的成就。
下一页是可怕的部分。。。

Scott Aaronson“给11岁的自己的信”的下一部分。只要读一下。。

斯科特指的是Q*:一种多模态、125万亿参数的野兽。感谢阅读-杰克逊(推特上的@vancouver1717)

It‘s over!