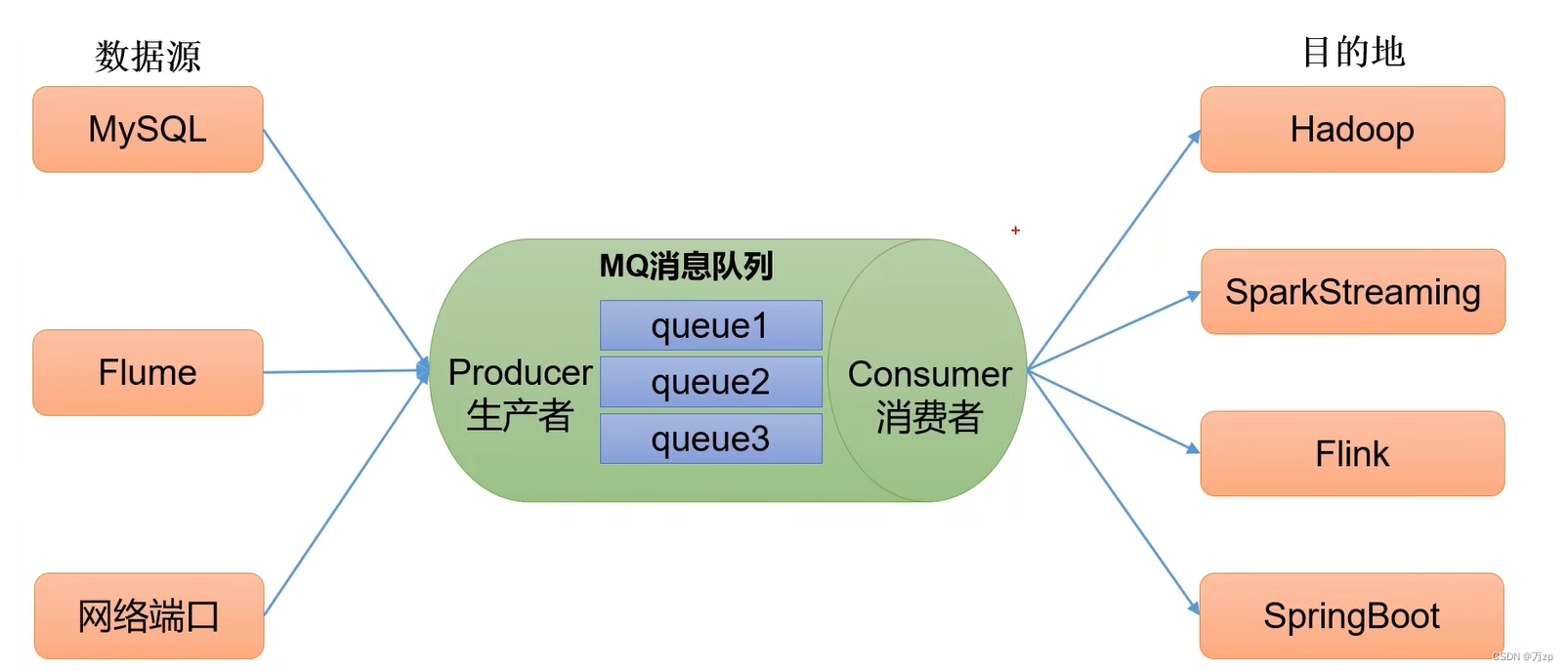
迁移类型
同时迁移表及其数据(使用import和export)
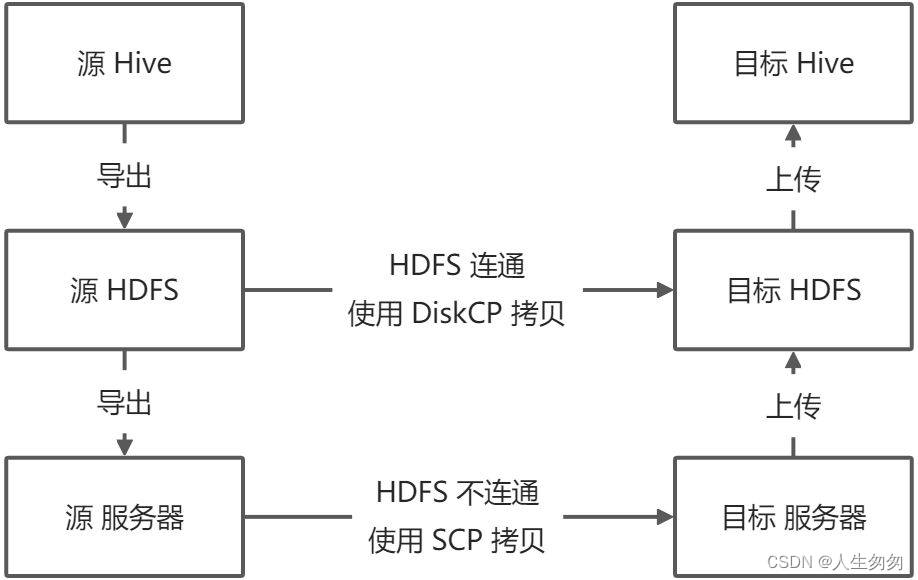
迁移步骤
- 将表和数据从 Hive 导出到 HDFS
- 将表和数据从 HDFS 导出到本地服务器
- 将表和数据从本地服务器复制到目标服务器
- 将表和数据从目标服务器上传到目标 HDFS
- 将表和数据从目标 HDFS 上传到目标 Hive 库
- 如果原始 HDFS 和目标 HDFS 集群连通,可使用 DiskCP 工具直接跨集群复制,而跳过2~4步
一、Export、Import
Export导出,将Hive表中的数据,导出到外部
Import导入,将外部数据导入Hive表中
二、Export
1、语法
EXPORT TABLE tablename TO "export_target_path";
2、用法
#把tshang表导出到hdfs上
hive (default)> EXPORT TABLE lijia.tshang TO "/tmp/hive_data/lijia";
hive (default)> exit
[root@ /opt/PE/hive_data]# hadoop fs -ls /tmp/hive_data/lijia/tshang
Found 2 items
-rw-r--r-- 3 hive hdfs 1262 2024-03-18 17:35 /tmp/hive_data/lijia/tshang/_metadata
drwxr-xr-x - hive hdfs 0 2024-03-18 17:35 /tmp/hive_data/lijia/tshang/dataHDFS 集群连通时使用 DiskCP 进行拷贝
hadoop distcp hdfs://scrNmaeNode/tmp/<db_name> hdfs://targetNmaeNode/tmp
HDFS 集群不连通
hadoop fs -get /tmp/hive_data
scp -r hive_data root@targetAP:/tmp/
上传到目标 HDFS
hadoop fs -put /tmp/hive_data /tmp/
三、Import
1、语法
IMPORT TABLE tablename FROM "source_path";
2、用法
#先创建lijia库导入数据
hive (default)> create database lijia;
OK
Time taken: 0.012 seconds#导入
hive (db_hive)> import table lijia.tshang from "/tmp/hive_data/lijia";hive (db_hive)> select * from lijia.tshang;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 1980-12-17 800.0 NULL 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.0 300.0 30
7521 WARD SALESMAN 7698 1981-2-22 1250.0 500.0 30
7566 JONES MANAGER 7839 1981-4-2 2975.0 NULL 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.0 1400.0 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.0 NULL 30
7782 CLARK MANAGER 7839 1981-6-9 2450.0 NULL 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.0 NULL 20
7839 KING PRESIDENT NULL 1981-11-17 5000.0 NULL 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.0 0.0 30
7876 ADAMS CLERK 7788 1987-5-23 1100.0 NULL 20
7900 JAMES CLERK 7698 1981-12-3 950.0 NULL 30
7902 FORD ANALYST 7566 1981-12-3 3000.0 NULL 20
7934 MILLER CLERK 7782 1982-1-23 1300.0 NULL 10
Time taken: 0.029 seconds, Fetched: 14 row(s)实施过程,迁移数据库,不在是一个表
目标集群和服务器检查
df -lh # 查看本地空间使用情况
hadoop dfsadmin -report # 查看HDFS集群使用情况
hadoop fs -find / -name warehouse # 查找Hive库位置
hadoop fs -du -h /user/hive/warehouse # 查看Hive库占用
同时迁移表及其数据(使用import和export)
- export 工具导出时会同时导出元数据和数据
- import 工具会根据元数据自行创建表并导入数据
- 如果涉及事物表需要预先开启目标库的事物机制
-- 开启事务
-- https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions#HiveTransactions-Configuration
SET hive.support.concurrency = true;
SET hive.enforce.bucketing = true;
SET hive.exec.dynamic.partition.mode = nonstrict;
SET hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
SET hive.compactor.initiator.on = true;
SET hive.compactor.worker.threads = 1;
迁移步骤
#输入需要迁移的数据库default
执行
cat <<EOF > /opt/lijia/hive_sel_tables.HQL
use default;
show tables;
EOF# 罗列要迁移的表清单
执行
beeline -u jdbc:hive2://172.24.3.183:10000 -nhive -f /opt/lijia/hive_sel_tables.HQL \
| grep -e "^|" \
| grep -v "tab_name" \
| sed "s/|//g" \
| sed "s/ //g" \
> /opt/lijia/hive_table_list.txt# 生成导出脚本
cat /opt/lijia/hive_table_list.txt \
| awk '{printf "export table <db_name>.%s to |\"/tmp/lijia/<db_name>/%s\"|;\n",$1,$1}' \
| sed "s/|//g" \
| grep -v "tab_name" \
> /opt/lijia/hive_export_table.HQL执行
cat /opt/lijia/hive_table_list.txt \
| awk '{printf "export table default.%s to |\"/tmp/lijia/default/%s\"|;\n",$1,$1}' \
| sed "s/|//g" \
| grep -v "tab_name" \
> /opt/lijia/hive_export_table.HQL# 生成导入脚本
cat /opt/lijia/hive_table_list.txt \
| awk '{printf "import table <db_name>.%s from |\"/tmp/lijia/<db_name>/%s\"|;\n",$1,$1}' \
| sed "s/|//g" \
| grep -v "tab_name" \
> /opt/lijia/hive_import_table.HQL执行
cat /opt/lijia/hive_table_list.txt \
| awk '{printf "import table default.%s from |\"/tmp/lijia/default/%s\"|;\n",$1,$1}' \
| sed "s/|//g" \
| grep -v "tab_name" \
> /opt/lijia/hive_import_table.HQL# 创建 HDFS 导出目录
hadoop fs -mkdir -p /tmp/lijia/<db_name>/
hadoop fs -mkdir -p /tmp/lijia/default/# 导出表结构到数据到 HDFS
beeline -u jdbc:hive2://172.24.3.183:10000 -nhive -f /opt/lijia/hive_export_table.HQL## HDFS 集群连通时使用 DiskCP 进行拷贝
hadoop distcp hdfs://scrNmaeNode/tmp/<db_name> hdfs://targetNmaeNode/tmp## HDFS 集群不连通
hadoop fs -get /tmp/lijia/default/
scp -r /tmp/lijia/default/ root@targetAP:/tmp/lijia/## 目标服务器# 创建 HDFS 导出目录
hadoop fs -mkdir -p /tmp/lijia/# 上传到目标 HDFS
hadoop fs -put /tmp/lijia/default /tmp/lijia/# 导入到目标 Hive
beeline -u jdbc:hive2://172.24.3.183:10000 -nhive -f /opt/lijia/hive_import_table.HQL