1.模拟用户向指定网站发送请求
需要下载requests模块来模拟用户向网站发送请求,在终端输入如下指令:
pip install requests1> 了解网页结构
学习网页基础(一般由三部分构成,HTML(网页基本骨架),CSS(页面样式),JS(与用户进行动态交互))
2 > 了解爬虫
网络爬虫(又被称为网页蜘蛛),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据
3>了解反爬
搜索引擎可以通过爬虫抓取网页信息,进行数据分析等,但有些网站中的网页信息并不希望被爬取这里就会涉及到反爬虫技术
反爬虫技术如下所示:
1.通过user-Agent来控制访问(user-agent能够使服务器识别出用户的操作系统及版本、cpu类型、浏览器类型和版本,一些网站会设置user-agent名单范围,在范围内的可以正常访问),2.通过IP来限制,3.设置请求间隔,4.自动化测试工具,5.参数通过加密,6. 通过robots.txt来限制爬虫等。
2.解析网页数据
requests 库已经可以抓到网页源码,接下来要从源码中找到并提取数据。Beautiful Soup 是 python 的一个库,其最主要的功能是从网页中抓取数据。Beautiful Soup 目前已经被移植到 bs4 库中,也就是说在导入 Beautiful Soup 时需要先安装 bs4 库。
安装好 bs4 库以后,还需安装 lxml 库。如果我们不安装 lxml 库,就会使用 Python 默认的解析器。尽管 Beautiful Soup 既支持 Python 标准库中的 HTML 解析器又支持一些第三方解析器,但是 lxml 库具有功能更加强大、速度更快的特点,因此个人推荐安装 lxml 库。
pip install bs4
pip install lxml3.代码部分
1> 某图片网站爬取图片具体代码如下所示:
# pip install requests
import requests
#pip install bs4 用BeautifulSoup来对HTML文档进行解析
from bs4 import BeautifulSoupclass spider():def __init__(self,url):#请求网址self.url = url#设置请求头self.headers = {"user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Mobile Safari/537.36"}def get(self):# 通过请求获取响应数据(此数据是html文本格式的数据)res = requests.get(self.url,headers=self.headers)html = res.text# 解析数据info = BeautifulSoup(html, "lxml")# 使用select选择器定位数据data = info.select("#thumbs > section > ul > li > figure > img")# 在解析后的数据中通过遍历的方法提取图片的url存入列表中,得到一个urllist列表urllist = []for i in data:urllist.append(i.get("data-src"))# 通过解析后的url再次发送请求获取图片for j in urllist:pictureurl = j# 图片命名name = pictureurl.split("/")[-1]response = requests.get(url=pictureurl, headers=self.headers)# 以二进制数据流的方式写入指定目录文件with open("D:\spiderPicture\%s" % name, "wb") as f:f.write(response.content)
sp = spider("https://wallhaven.cc/search?q=id:711&sorting=random&ref=fp")
sp.get()2> 代码详解
对代码进行了封装方便批量爬取,首先导入两个包requests和BeautifulSoup,requests是为了模拟用户向浏览器发送请求,BeautifulSoup是为了在网页中抓取数据
url是目标网址:

设置请求头:
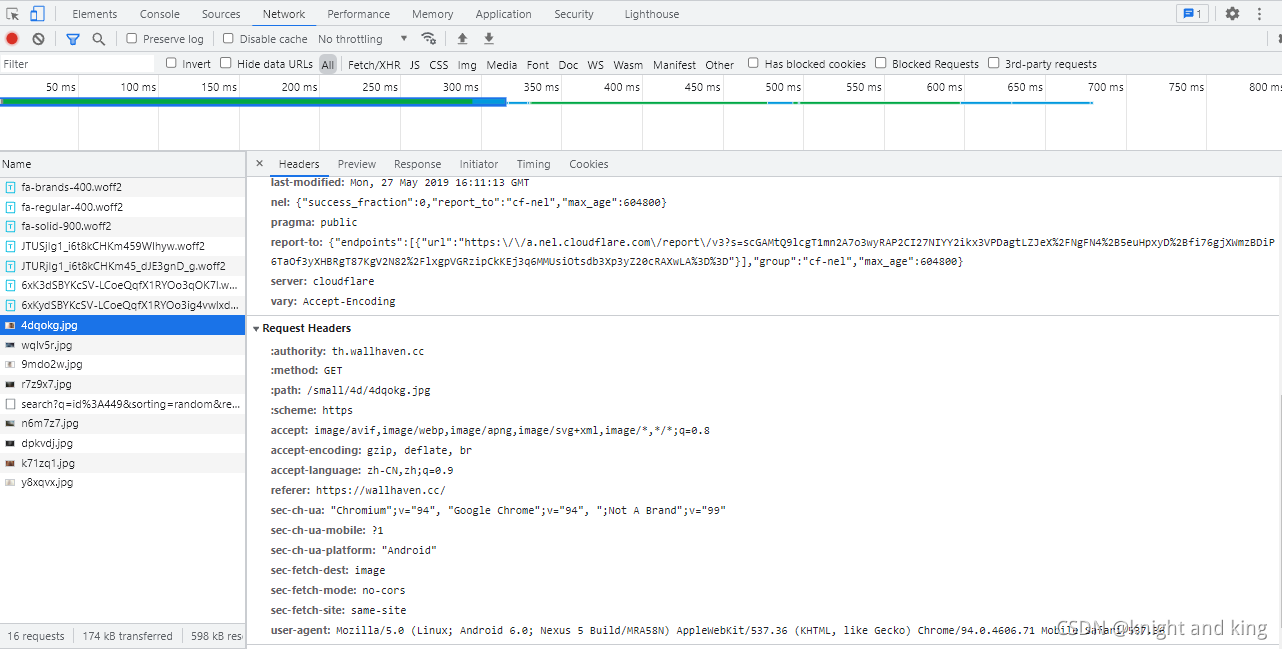
找到Request Headers中的user-agent复制粘贴
#设置请求头
self.headers = {"user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Mobile Safari/537.36"}发送请求得到响应数据:(这里的html就是HTML文本数据)
# 通过请求获取响应数据(此数据是html文本格式的数据)res = requests.get(self.url,headers=self.headers)html = res.text通过BeautifulSoup解析数据:(BeautifulSoup第一个参数是要解析的数据,第二个参数是解析方方式)
# 解析数据info = BeautifulSoup(html, "lxml")使用select选择器定位数据(我们爬取图片需要图片的url,所以需要定位url)

复制选择器得到定位的位置:
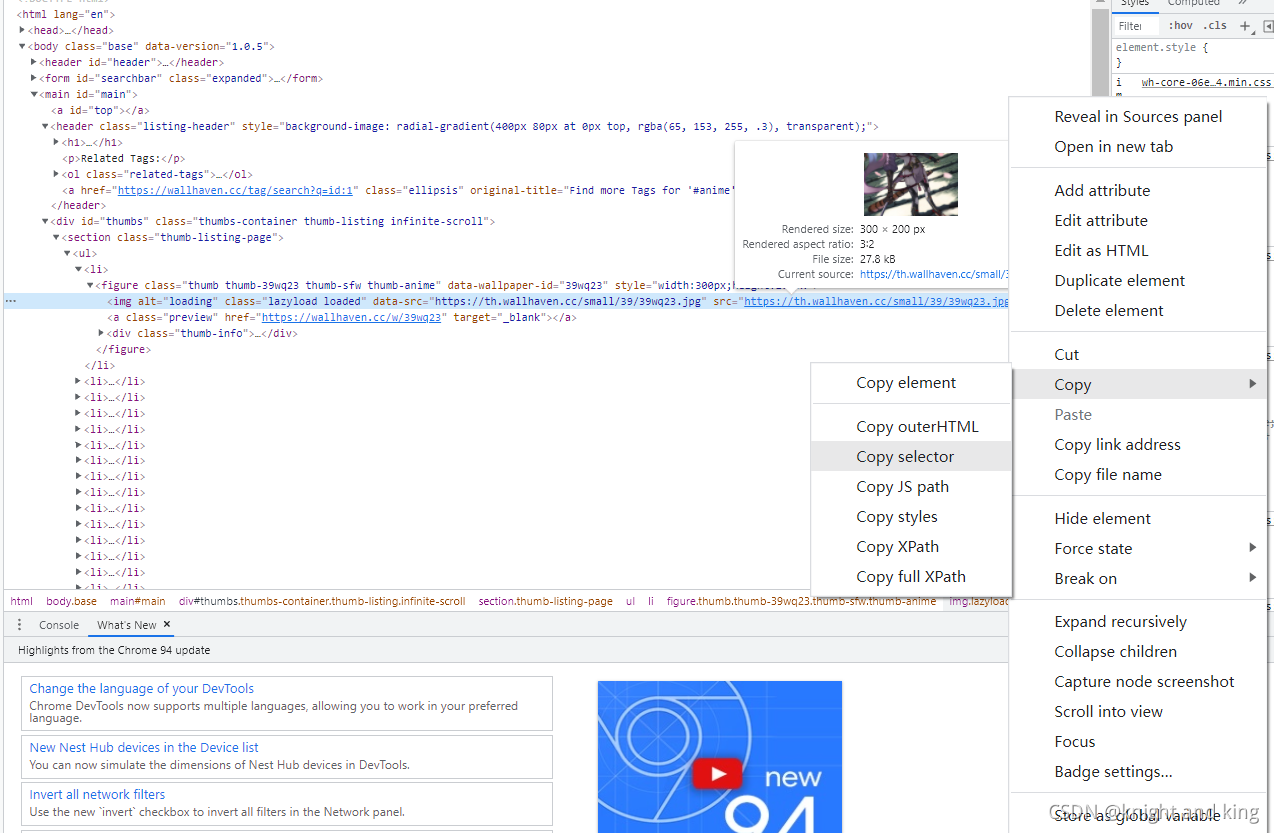
Copy selector 得到:
#thumbs > section > ul > li:nth-child(1) > figure > img但这样只是一张图片,我们要的是当页的全部图片所以这里需要改成(删掉li:后面的nth-child(1)):
#thumbs > section > ul > li > figure > img# 使用select选择器定位数据data = info.select("#thumbs > section > ul > li > figure > img")data输出的结构如下:

得到图片的地址后:新建一个列表将所有的url加入列表
# 在解析后的数据中通过遍历的方法提取图片的url存入列表中,得到一个urllist列表print(data)urllist = []for i in data:urllist.append(i.get("data-src"))列表如下:

通过解析后的url再次发送请求获取图片,图片名称我们采用将url地址字符串拆分切片的方式赋值给name,最后以二进制的方式写入指定目录
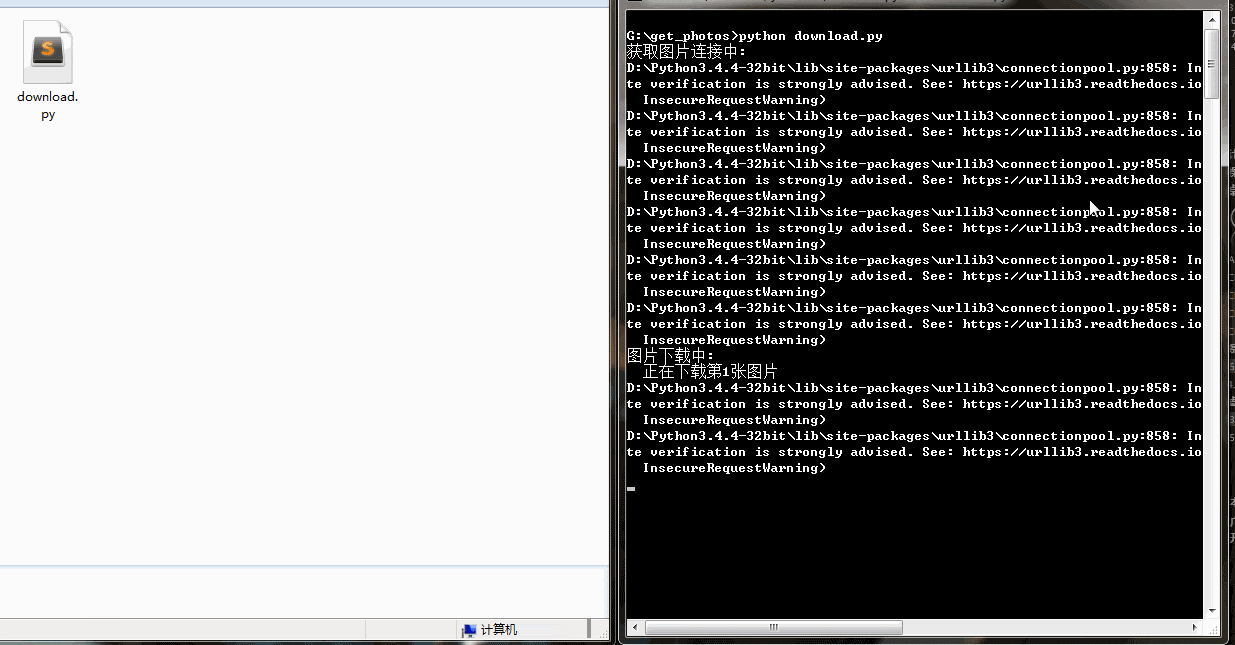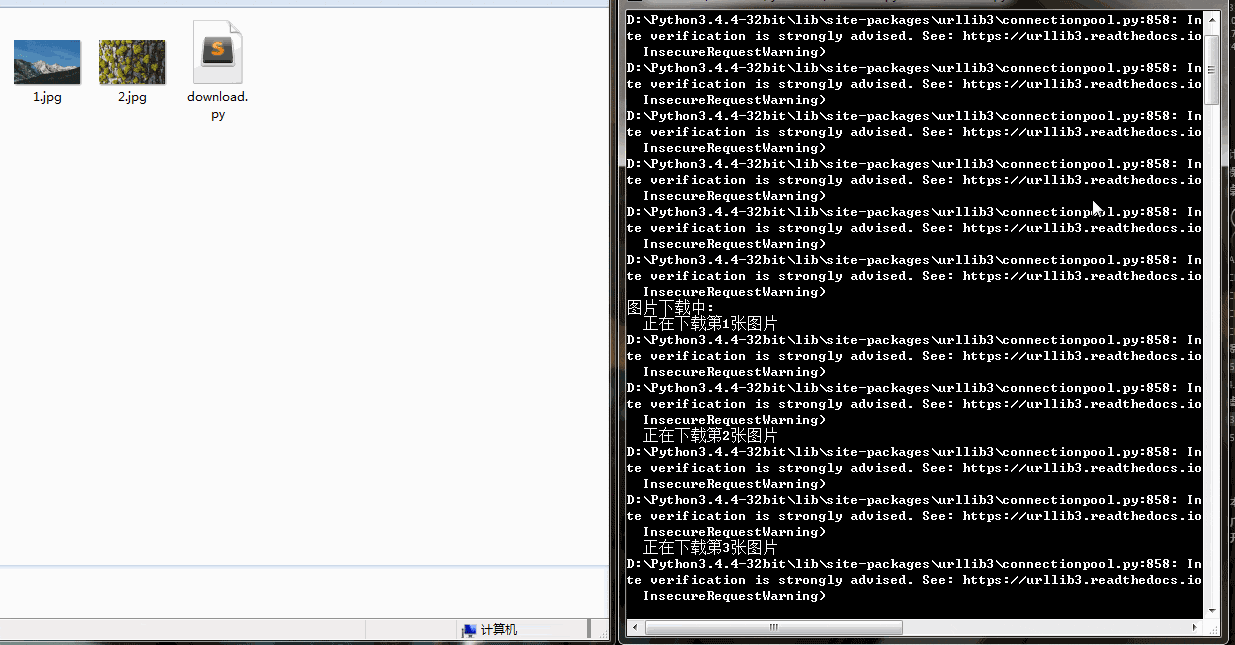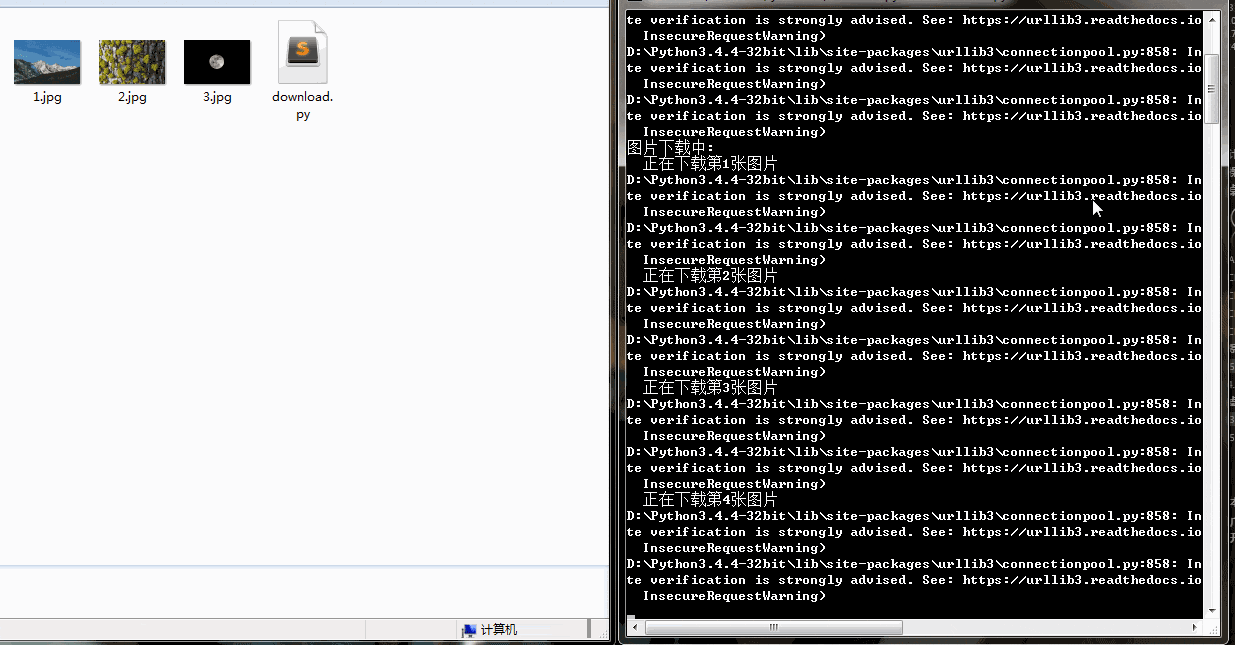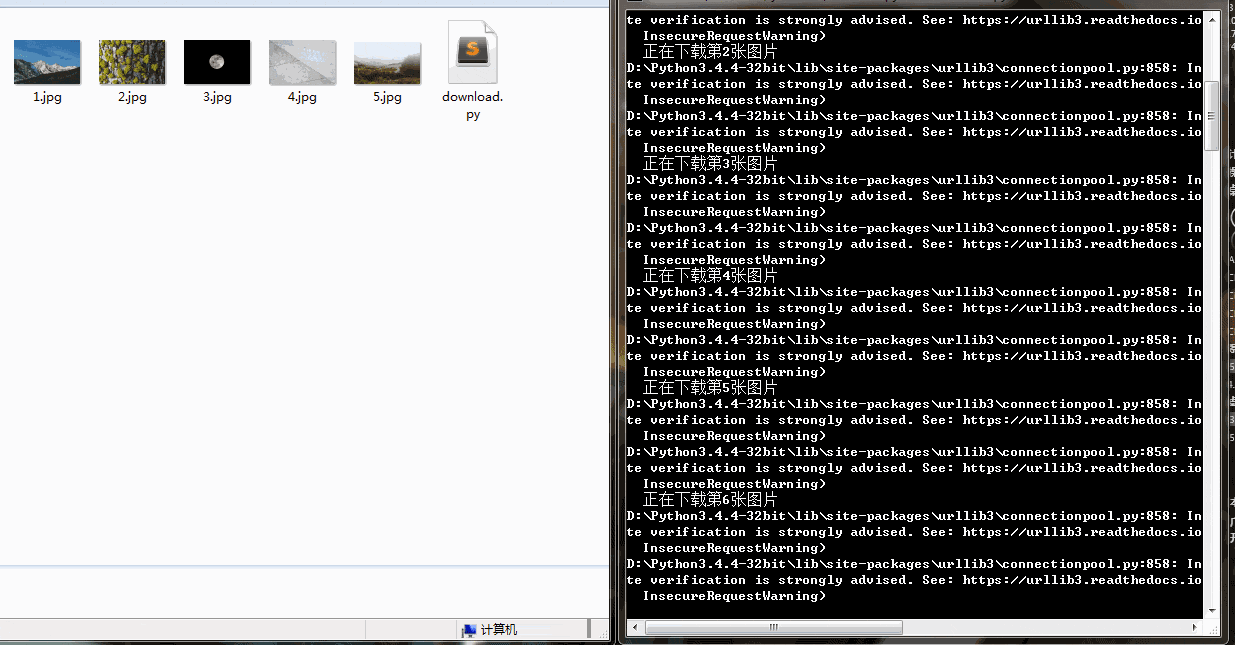
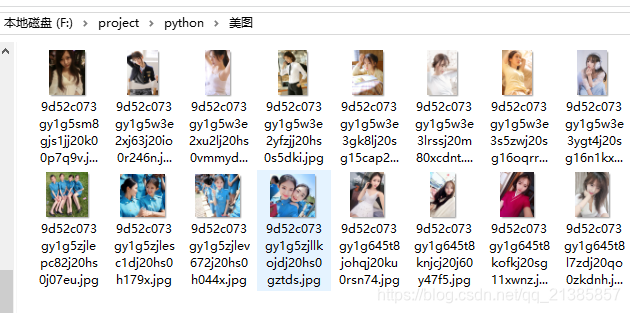
# 通过解析后的url再次发送请求获取图片for j in urllist:pictureurl = j# 图片命名name = pictureurl.split("/")[-1]response = requests.get(url=pictureurl, headers=self.headers)# 以二进制数据流的方式写入指定目录文件with open("D:\spiderPicture\%s" % name, "wb") as f:f.write(response.content)查看结果:

对另一个网站的图片批量爬取源码如下:
# pip install requests
import requests
#pip install bs4 用BeautifulSoup来对HTML文档进行解析
from bs4 import BeautifulSoupclass spider():def __init__(self,url):#请求网址self.url = url#设置请求头self.headers = {"user-agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Mobile Safari/537.36"}def get(self):# 通过请求获取响应数据(此数据是html文本格式的数据)res = requests.get(self.url,headers=self.headers)html = res.text# 解析数据info = BeautifulSoup(html, "lxml")# 使用select选择器定位数据data = info.select("#main > div.slist > ul > li > a > img")# 在解析后的数据中通过遍历的方法提取图片的url存入列表中,得到一个urllist列表print(data)urllist = []for i in data:urllist.append(i.get("src"))print(urllist)# 通过解析后的url再次发送请求获取图片for j in urllist:pictureurl = j# 图片命名# name = pictureurl.split("/")[-1]response = requests.get(url="https://pic.netbian.com"+pictureurl, headers=self.headers)# 以二进制数据流的方式写入指定目录文件global numberwith open("D:\spiderPicture\pic\%d.jpg" % number, "wb") as f:f.write(response.content)number += 1
i = 3
number = 1
while 1:url = "https://pic.netbian.com/4kmeinv/index_%d.html"%isp = spider(url)sp.get()i += 1