研究挑战:基于Transformer的架构在图像分割领域取得了显著的成果,但这些架构通常需要大量的计算资源,特别是在边缘设备上。
研究挑战:基于Transformer的架构在图像分割领域取得了显著的成果,但这些架构通常需要大量的计算资源,特别是在边缘设备上。
为了解决这个问题,作者提出了 PEM(prototype-based efficient MaskFormer),可以理解为是 MaskFormer方法的改进,主要包括两个创新点:
- 设计了基于原型的交叉注意力机制,利用视觉特征的冗余性来限制计算量,提高效率,同时保持性能。
- 设计了高效的多尺度FPN(特征金字塔网络),通过结合可变形卷积和基于上下文的自调节,以高效的方式提取具有高语义内容的特征。
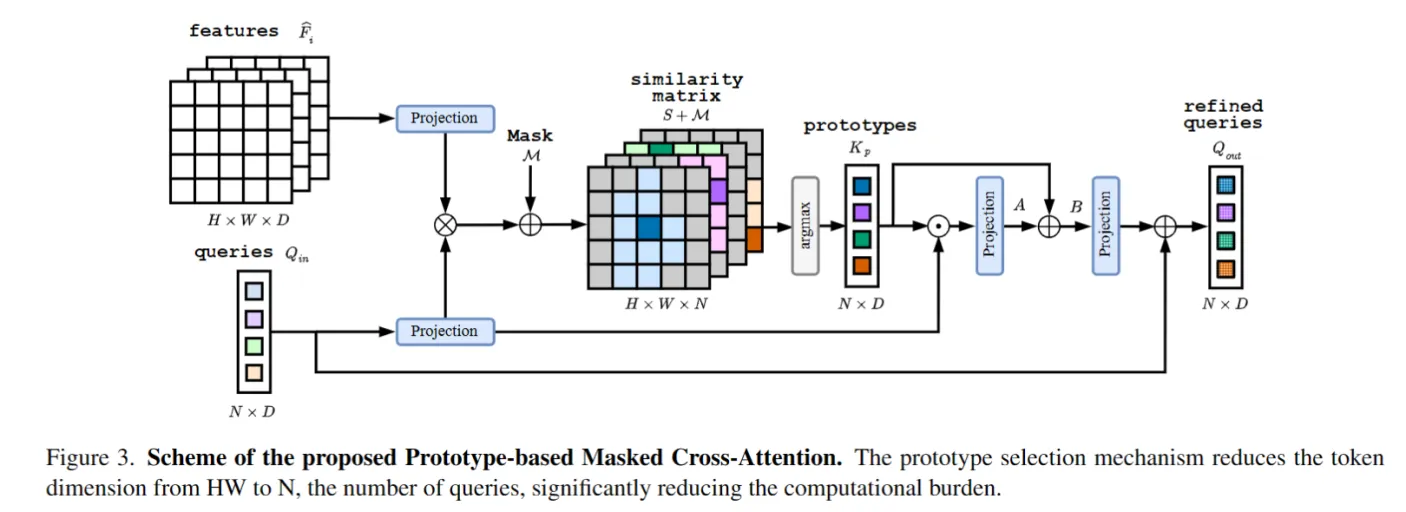
论文总体架构如下图所示,和MaskFormer等方法类似,不同的地方在于 pixel decoder 和 Transformer decoder。Pixel decoder里的蓝色的CSM(上下文调制) 是通道注意力,紫色的Def Conv是 Deformable conv。这个高效的 pixel decoder 被做为副创新点了。
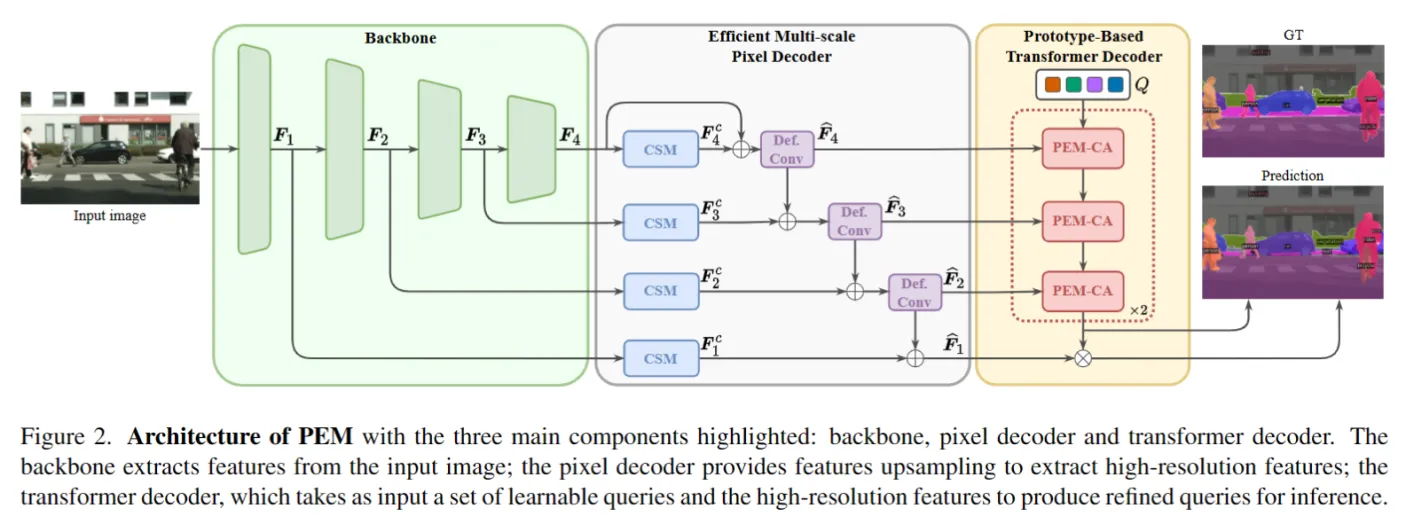
论文的主要创新点是下面这个 Prototype-based Masked Cross-Attention (PEM-CA)。作者也说,是受了SwiftFormer的启发,只保留Q和K计算注意力。中间三次的特征交互。需要注意的是,有一个 argmax 操作,正常会有不能反向传播的问题,不清楚实现的细节是如何的。