文件的管理
最开始说到过, 一个进程是可以打开多个文件的并且可以对这些文件做出不同的操作, 也就是说加载到内存中的文件可能存在多个.
操作系统要不要管理这些打开的文件呢?
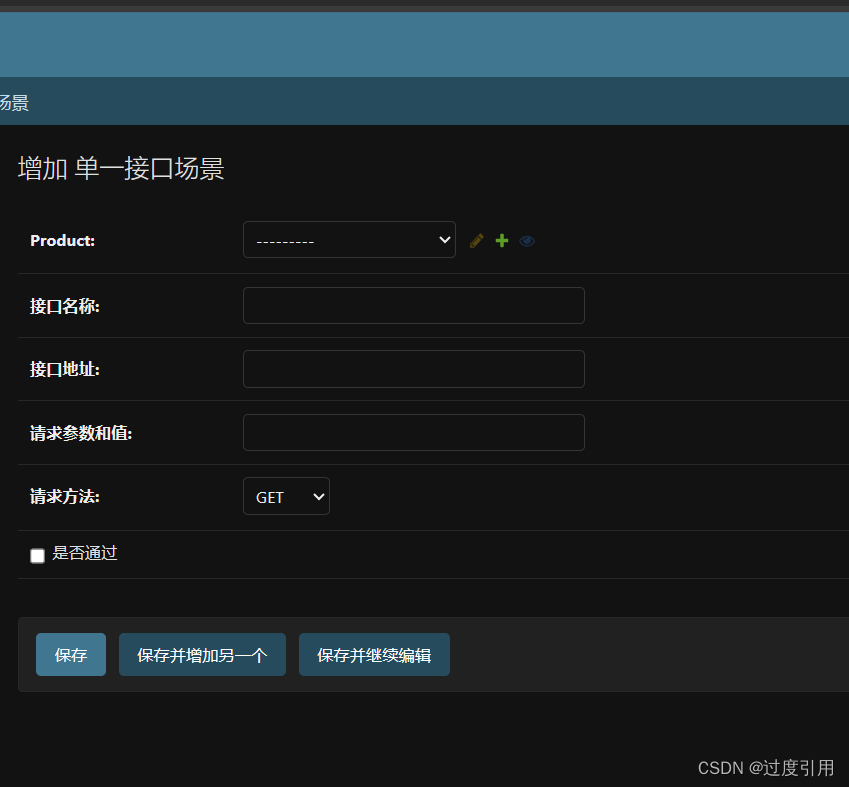
当我们在程序里面打开多个文件时, 操作系统肯定是得对这些文件进行管理的, 而管理的本质就是对数据进行管理, 管理的方法就是先描述再组织, 所以操作系统为了管理被打开的文件就会创建内核数据结构来描述这些文件, 在操作系统中这个结构体就叫做struct file, 在这个结构体里面包含了文件的大部分属性, 进程可以通过这些属性来找到文件并访问文件的内容, 每打开一个文件操作系统就会创建一个file结构体, 然后采用链式结构将这些文件的结构体连接起来, 这样操作系统只要找到一个文件结构体的起始地址就能找到所有被该进程打开的文件的file结构体, 对文件的管理就变为对file结构体的增删查改.
那这里就存在一个问题, 我们之前说文件操作的本质是: 进程和被打开文件的关系, 可是的进程和被打开的文件好像没有任何联系啊, 这就和之前的open函数的返回值文件描述符fd有关了!
fd是什么?
我们通常把fd称为文件描述符,对于fd大家最熟悉的一点就是:通常使用fd来记录open函数的返回值,比如:


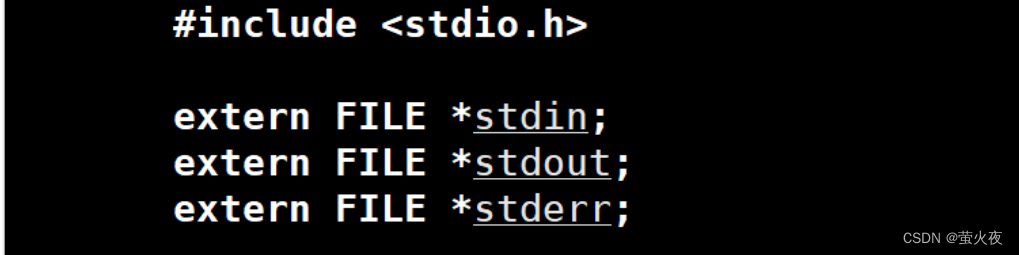
通过代码的运行结果我们可以看到open函数的返回值都是整数, 而且随着打开文件的数目增加open函数的返回值也在有规律的增加从3开始依次往后加1.
为什么这里的文件描述符是从3开始的呢?文件描述符是从0开始递增的, 那么0,1,2都去哪了?
当我们运行一个程序的时候操作系统会帮自动帮我们打开三个输入输出流:
标准输入流(stdin)对应键盘、标准输出流(stdout)对应显示器、标准错误流(stderr)也对应显示器,在Linux下它们也是文件, 分别占据了0, 1, 2的位置.
我们在学习C语言文件操作的时候, 我们曾经学过一个文件指针(FILE* pf), 它和文件描述符又有什么联系呢?
c语言的文件函数中通过FILE*指针来访问具体的文件, 操作系统的文件函数中是通过fd文件描述符来访问具体的文件,:
而c语言的文件函数是基于操作系统的文件函数实现的, FILE是一个结构体, fd是一个整型变量, 所以这里我们就可以推测出结构体FILE中一定存在着一个字段记录着fd的数值, 这三个流分别占用着文件描述符的0 1 2, 所以我们在程序中打开文件的描述符是从3开始, 这里可以通过下面的代码来验证上述的内容:

但是还存在一个问题为什么文件描述符是一个串连续的整数呢?
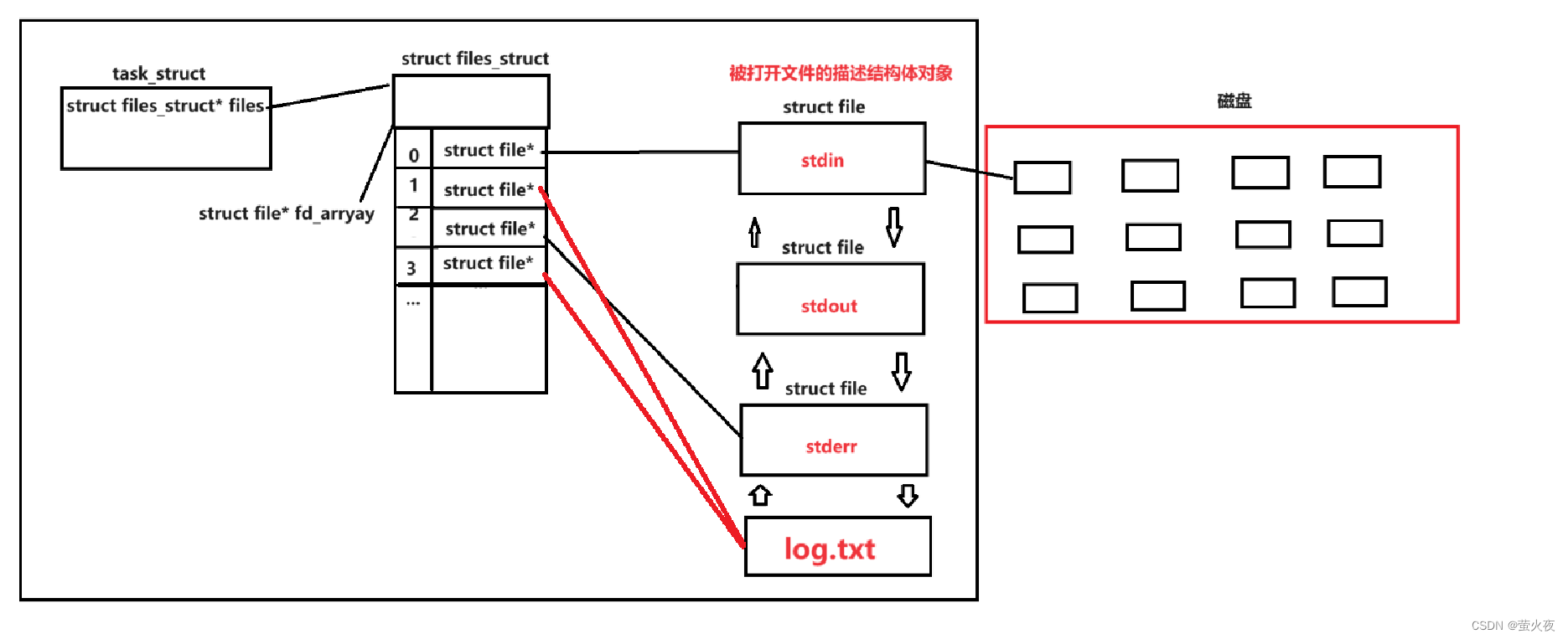
在操作系统里面不止一个进程要打开文件, 还有很多的进程也要打开各种各样的文件, 所以操作系统中存在着很多被打开的文件, 进程是没有办法从这么多被打开的文件中找到属于本进程的文件, 所以在task_struct里面就会存在一个名为files的指针, 这个指针指向的对象是一个名为files_struct的结构体:

在files_struct结构体里面存在一个数组这个数组fd_array, 数组的元素类型为struct file*, 也就是说这个数组的每个元素都是一个指针, 指针指向的对象是描述文件属性的file结构体, 当我们打开文件时操作系统就会在fd_arry数组里面从上往下查找没有被用到的元素, 找到之后就会就会将file结构体的地址填入该元素里面.
当操作系统将地址填入数组之后就会将该文件的file在数组中对应的下标返回给用户, 所以当我们使用完open函数时就可以得到一个返回值, 我们把这个返回值称为文件描述符也可以叫fd, fd的本质就是数组下标.
所以当我们通过fd对文件执行操作时, 实际上就是进程的PCB通过struct files_struct找到结构体files_struct中的数组fd_array, 再把fd的值作为数组的下标找到记录文件属性的struct file的地址, 然后再根据file结构体找到具体的文件最后执行对应的操作, fd的本质就是一个数组的下标, 所以他是一个连续的整数.
此外, struct file里面也应该有能获得文件缓冲区(在内存上)的成员, 而struct file结构体是在内核中创建的, 专门用来管理被打开的文件, 所以无论读写数据, 都要把数据加载到文件缓冲区中, 而磁盘上的文件加载到内存这一工作是由OS来进行的, 用户不需要担心文件是否被加载到内存中.
所以我们在应用层进行数据的读写, 本质是将内核缓冲区中的数据进行来回的拷贝!

此外struct file中还应该有文件的操作方法集, 通过这些方法集, 就可以实现底层不同的调用方法(多态), 后面会详细说.

再来看一段代码:


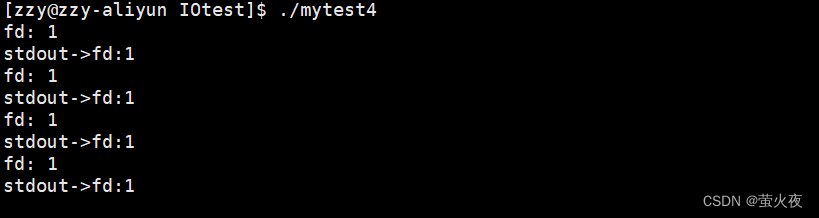
这段代码调用了read函数, 从0号文件也就是stdin中读取字符并打印出来. 这也侧面证明了我们并不需要打开0号文件, 通过0文件标识符即可访问文件, 所以c语言默认打开标准输入其实本质是系统默认打开了0号文件标识符, 打开了标准输入对应的设备文件.


同样的, 1号文件也在进程启动时直接被打开了.
fd的分配规则
我们在上面提到fd的分配规则是从数组fd_array中从上往下依次寻找没有被用到的元素, 因为每运行一个进程操作系统会自动打开三个文件, 所以我们再打开文件时得到的fd就是从3开始依次往后增加.
那既然操作系统会自动给我们打开三个文件而且这三个文件的fd分别是0 1 2, 那我们是不是能够通过 close函数 + 这三个fd 将这三个文件关闭呢?
可以, 并且将这几个文件关闭之后这些文件对应在fd_array上的地址是会被清空的, 也就是说这些fd又可以被新的文件占用.
所以按照fd的分配规则, 当我们关闭其中一个文件再打开一个新的文件时, 新文件会按顺序占用已经关闭文件的下标.
比如说将stdin文件关闭再打开一个文件, 我们就可以发现打开文件的fd为0:


关闭2号也是同理:


那关闭1号是不是呢:


这里好像就出问题屏幕上没有显示打印结果,要想明白这个问题我们就得聊聊重定向是什么.
重定向
输出重定向
FILE是一个结构体在这个结构体里面有一个字段记录着文件描述符的值, 所以在stdout的结构体里面就会存在一个字段来专门记录stdout的文件描述符(fd = 1), 当我们在程序里面使用printf函数向屏幕上打印内容时, 实际上就是向stdout文件里面打印内容.
printf("fd1:%d\n",fd1);//两者一样
fprintf(stdout,"fd1:%d",fd1);
printf函数是默认向stdout里面打印内容, fprintf函数可以向指定的文件里面打印内容, 当fprintf函数第一个File*类型的参数填入stdout时这两个函数的功能是一样的, 向stdout里面输出内容实际上就是向stdout内部的fd所指向的文件里面打印内容, stdout内部的fd永远都是1, 所以每次使用printf函数向屏幕上打印数据时, 操作系统都会在fd_array中寻找下标为1的元素得到元素里面的地址, 然后往该地址指向的文件里面输出对应的数据, 最后这些数据就会显示在屏幕上面.


此时依然什么都没有输出, 但是cat log.txt就会发现:

printf要输出的内容被打印在了log.txt文件中, 我们本来是要向显示器里打印新打开的文件的fd, 现在却输出在了文件里, 这就叫做输出重定向.
为什么呢?
一开始我们将文件描述符为1的文件关闭了, 然后我们又使用open函数打开了一个新文件, 按照fd的分配规则这时新打开的文件log.txt的文件描述符就是1, 也就是fd_array数组中1号下标位置对应的struct file*是log.txt文件的struct file的地址.

之后我们使用printf函数打印一些内容, printf函数默认向stdout文件里面输出数据, 而stdout是一个结构体, 其中保存的文件描述符一直是1, 与其说printf只认显示器/stdout, 不如说printf函数只认文件描述符1, 此时的fd_array[1]不再指向stdout文件, 而指向log.txt, 所以printf输出的数据就不会显示在屏幕上而是log.txt里, 所以要完成输出重定向其实只需要修改fd_array[1]的内容即可.
换成fprintf效果是一样的:


为什么需要fflush刷新缓冲区呢? 后面再说.
追加重定向


把O_TRUNC改为O_APPEND 即追加重定向.
输入重定向

本来默认要从键盘stdin中读取内容, 但是现在直接从打开的log.txt中读取, 这就完成了输入重定向.
dup2函数
上面的代码都是通过人为的使用close函数关闭指定文件描述符来实现重定向, 但是这种方法使用起来还是很麻烦, 所以操作系统提供了一个函数接口来专门实现重定向, 这个函数叫做dup2.
该函数的参数如下;
调用接口:int dup2(int oldfd, int newfd);
头文件:unistd.h
参数:oldfd为需要转移位置的文件描述符, newfd表示oldfd需要转移到的文件描述符的位置.
功能:将oldfd的内容覆盖到newfd处(不是交换)
所以重定向的原理就是文件描述符表中数组下标里的内容进行拷贝.
如果执行dup2(3,1):
执行完dup2函数之后就会将下标为oldfd的数据拷贝到下标为newfd的元素里面去, 也就是将fd_array[3]赋值给 fd_array[1], 此时有两个指针指向log.txt, 如果close(3), 但是log.txt还需要需用, log.txt结构体会不会直接被释放了呢? 这里用到了引用计数, 有几个指针指向这个文件, 引用计数就是几, close的时候会先--引用计数, 如果引用计数为0文件才会被释放.
所以上面的重定向可以用dup2再简化一遍:
输出重定向:

追加重定向, 只需要把O_TRUNC改成O_APPEND:

输入重定向:

指令和输入/出重定向( > <)有什么关系呢?(myshell的修改)
对于这几个重定向, 我们以前是怎么用的?

首先大部分的指令在执行的时候本质都是bash的子进程, 对于这行命令行字符串, 首先会去做识别, 检查>,>>,<, 然后判断出这个指令需要有重定向功能, 前半部分是指令, 后半部分是要重定向的目标文件, 所以进程在替换之前可以先进行重定向操作, 未来echo指令在执行时就可以把本应该打印在显示器的内容写入文件中,
所以可以对之前的myshell进行修改:
先添加几个宏用于标识重定向:

再定义两个全局变量表示重定向状态和重定向的文件名:

要判断重定向是需要对指令进行处理, 所以在获取命令字符串后进行重定向判断.
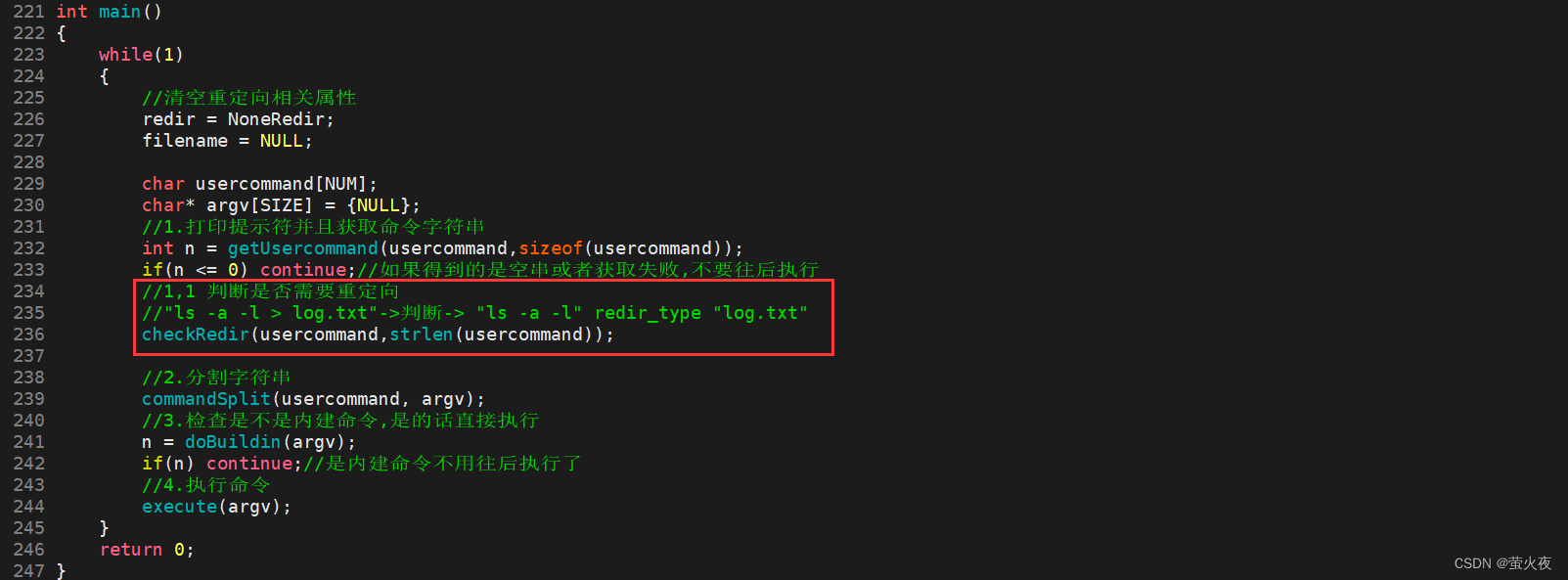

从后向前开始寻找>或<, 找到的是<输入重定向的话, 当前位置替换为'\0', filename指向下一个位置,这样就将usercommand和filename分割开, 但是filename此时指向的可能是空格, 需要跳过空格, 可以写一个宏来实现.
程序替换部分也需要进行修改, 在程序替换前先用dup2进行重定向:

可以看到 输出重定向 追加重定向 输入重定向都可以实现了


问题: 我们的重定向是在程序替换之前进行的, 程序替换后的进程会不会影响曾经进行的重定向呢? 为什么?
不会, 从运行结果也可以看出并没有影响,因为程序替换只是在内存中替换了代码和数据以及修改了对应的页表映射, 而重定向是修改了进程PCB中对应的数据, 而程序替换不会创建新进程, 也不会对当前PCB有影响, 所以并没有影响.
标准错误流
上面的一系列操作都是与标准输出(stdout)和标准输入(stdin)有关, 那标准错误(stderr)呢?
先看一段代码:


可以看到输出重定向后hello stdout重定向到了log.txt文件中, 而hello stderr打印在了屏幕上, 因为这里输出重定向是把1号文件(stdout)替换为log.txt, 和 (stderr)没有关系, 那如果我想把两行内容全都输出到log.txt中呢?
另一种重定向方式:
在之前的命令后加一个 2>&1 ,意思是把文件标识符表中fd=1中的内容放入fd=2中(理解成把2重定向为1):
![]()

所以./mytest4 > log.txt的完整写法应该是 ./mytest4 1 > log.txt:

程序运行时往往会产生一些常规消息和错误消息, 如果我们想把常规消息和错误消息分别输出到不同的文件中, 就可以这样:

这也就是标准错误存在的意义.
之前用过的printf就是向标准输出打印, perror就是向标准错误打印, 将正常消息和错误消息分开存储, 排查错误时只需查看错误日志即可.
如何理解linux下一切皆文件 ?
Linux下一切皆文件是指, Linux系统中的一切东西全都可以通过文件的方式进行访问或者管理. 反过来说, 任何被挂在系统中的东西, 即使它们的本质并不是文件, 也会被OS以文件的眼光来呈现.
比如: 我们经常谈到的进程, 磁盘, 显示器等, 实际上都不是文件, 但是用户可以以文件系统的规范去访问它, 修改属性.
一个文件站在方法的角度上, 最重要的是读写方法, 键盘,显示器,磁盘,网卡等硬件的读写方法肯定是不一样的, 键盘只有读没有写, 显示器只有写没有读, 磁盘读写方法都有, 那如何把不一样的东西看成一样的呢?
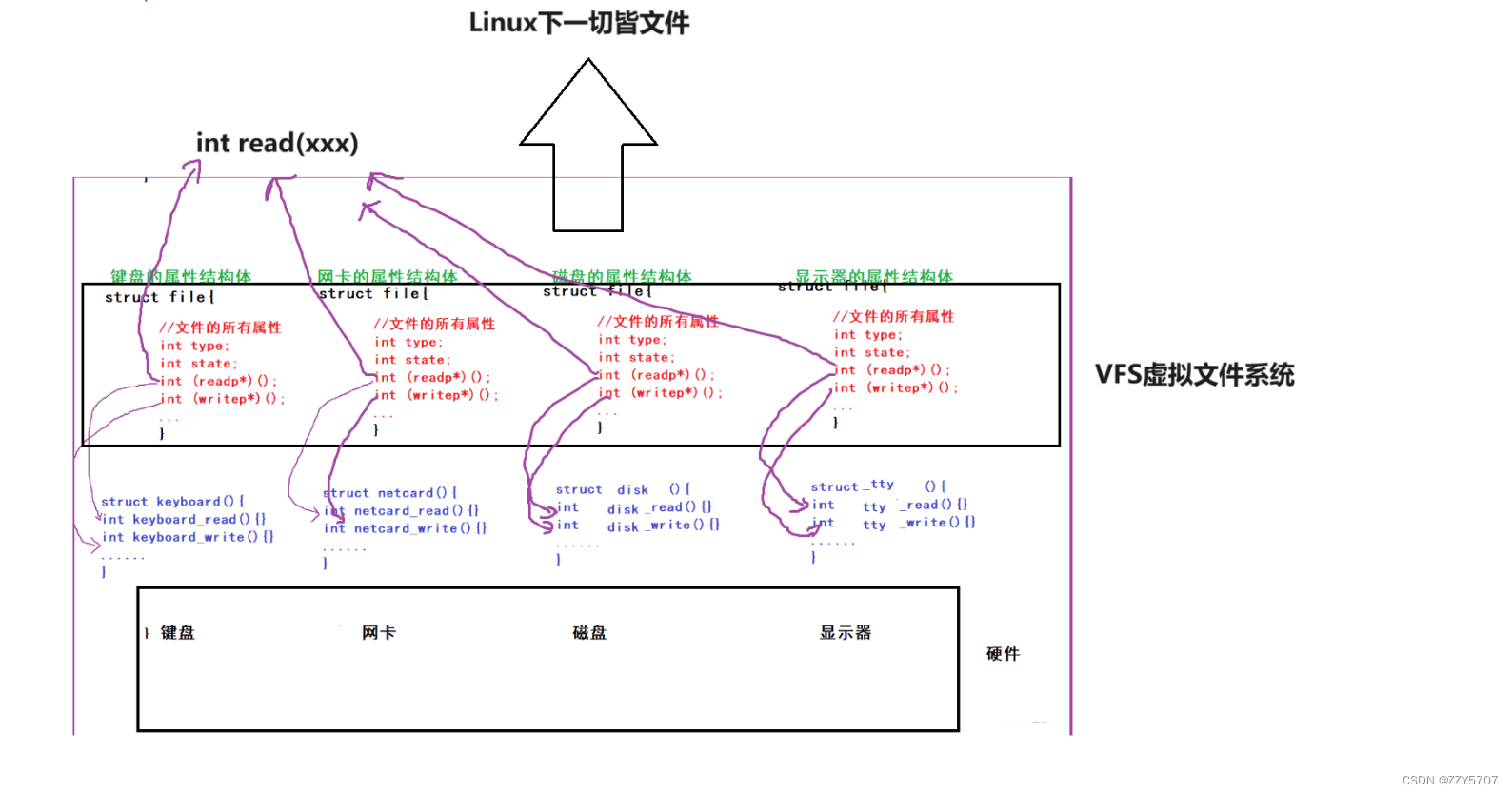
在软件层往上来看, 我们不需要关注底层硬件层的差异, 而只需要关注文件就可以了, 他们的读写方法都是一样的. 操作系统给我们虚拟化的一层软件层叫做VFS虚拟文件系统, 正是因为有这层的存在, 所以再往上看认为一切皆文件.
所以不管我们打开什么设备, 进程只需要和对应的struct file关联起来, 就可以用上层的指向底层读写方法的函数指针, 直接完成读写操作, 这也就是多态.