一、ChatGLM3-6B介绍与快速入门
ChatGLM3 是智谱AI和清华大学 KEG 实验室在2023年10月27日联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,免费下载,免费的商业化使用。
该模型在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:ChatGLM 3 GitHub
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,在44个中英文公开数据集测试中处于国内模型的第一位。ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
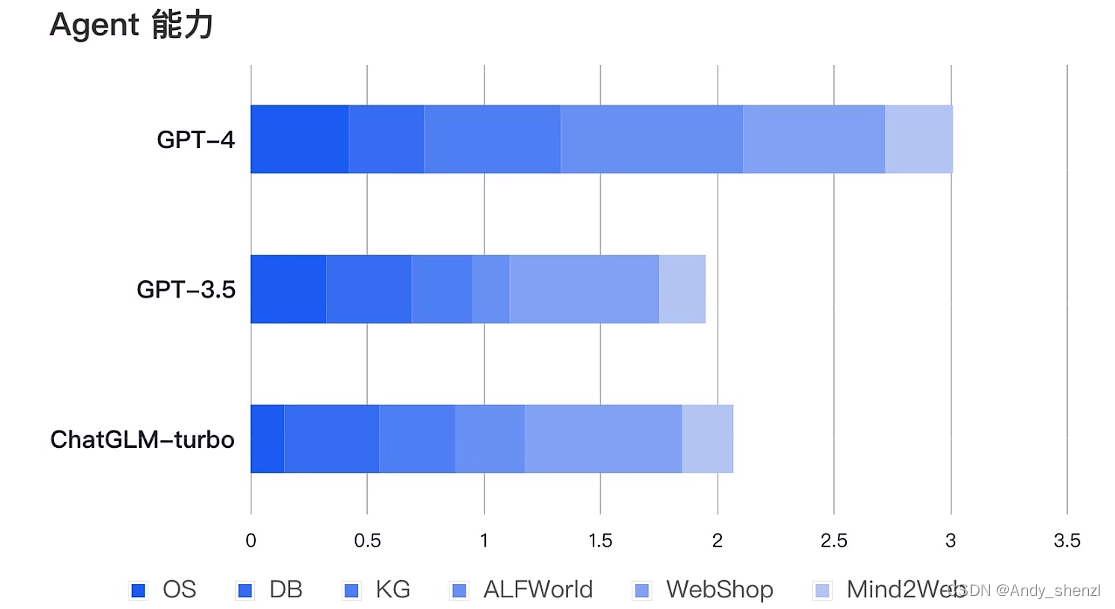
性能层面,ChatGLM3-6B在10B范围内性能最强,推理能力直逼GPT-3.5;功能层面,ChatGLM3-6B重磅更新多模态功能、代码解释器功能、联网功能以及Agent优化功能四项核心功能,全线逼近GPT-4!

AI Agent(人工智能代理)是一个能够自主执行任务或达成目标的系统或程序,能够围绕复杂问题进行任务拆解,规划多步执行步骤;能够实时围绕自动编写的代码进行debug;能够根据人类意见反馈修改答案,实时积累修改对话,并进行阶段性微调等等,具有很强的决策和执行能力。那ChatGLM3-6B模型开放的Function calling能力,是大语言模型推理能力和复杂问题处理能力的核心体现,是本次ChatGLM 3模型最为核心的功能迭代,也是ChatGLM 3模型性能提升的有力证明。
开源模型列表:
| 模型 | 介绍 | 上下文token数 | 代码链接 | 模型权重下载链接 |
|---|---|---|---|---|
| ChatGLM3-6B | 第三代 **ChatGLM 对话模型。**ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。 | 8K | Huggingface | 魔搭社区 | 始智社区 | Swanhub | 启智社区 ) | [ChatGLM3](https://github.com/THUDM/ChatGLM3 |
| ChatGLM3-6B-base | **第三代ChatGLM基座模型。**ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能。 | 8K | Huggingface | 魔搭社区 | 始智社区 | Swanhub | 启智社区 | |
| ChatGLM3-6B-32k | **第三代ChatGLM长上下文对话模型。**在ChatGLM3-6B的基础上进一步强化了对于长文本的理解能力,能够更好的处理最多32K长度的上下文。 | 32K | Huggingface | 魔搭社区 | 始智社区 | Swanhub | 启智社区 |
二、本地部署
大模型部署整体来看并不复杂,且官方一般都会提供标准的模型部署流程,但很多人在部署过程中会遇到各种各样的问题,很难成功部署,主要是因为这个过程会涉及非常多依赖库的安装和更新及根据本地的
安装情况,需要适时的调整代码逻辑。除此之外也有一定的硬件要求,总的来说还是具有一定的部署和使用门槛。
2.1 环境配置
首先看系统要求。目前开源的大模型都支持在Windows、Linux和Mac上部署运行。但在应用开发领域中,Linux 系统通常被优先选择而不是 Windows,主要原因是Linux 系统具有强大的包管理系统(如 apt, yum, pacman),允许开发者轻松安装、更新和管理软件包,这比 Windows 操作系统上的软件安装和管理更加方便快捷。同时Linux系统与多种编程语言和开发工具的兼容性较好,尤其是一些开源工具,仅支持在Linux系统上使用。整体来看,在应用运行方面对硬件的要求较低,且在处理多任务时表现出色,所以被广泛认为是一个非常稳定和可靠的系统,特别是对于服务器和长时间运行的应用。
Linux 操作系统有许多不同的发行版,每种发行版都有其特定的特点和用途,如CentOS、Ubuntu和Debian等。 CentOS 是一种企业级的 Linux 发行版,以稳定性和安全性著称。它是 RHEL(Red Hat Enterprise Linux)的免费替代品,与 RHEL 完全兼容,适用于服务器和企业环境。而Ubuntu,是最受欢迎的 Linux 发行版之一,其优势就是对用户友好和很强的易用性,其图形化界面都适合大部分人的习惯。
所以,在实践大模型时,强烈建议大家使用Ubuntu系统。同时,本教程也是针对Ubuntu 22.04 桌面版系统来进行ChatGLM3-6B模型的部署和运行的。
关于硬件的需求,ChatGLM3-6B支持GPU运行(需要英伟达显卡)、CPU运行以及Apple M系列芯片运行。其中GPU运行需要至少6GB以上显存(4Bit精度运行模式下),而CPU运行则需要至少32G的内存。而由于Apple M系列芯片是统一内存架构,因此最少需要13G内存即可运行。其中CPU运行模式下内存占用过大且运行效率较低,因此我们也强调过,GPU模式部署才能有效的进行大模型的学习实践。
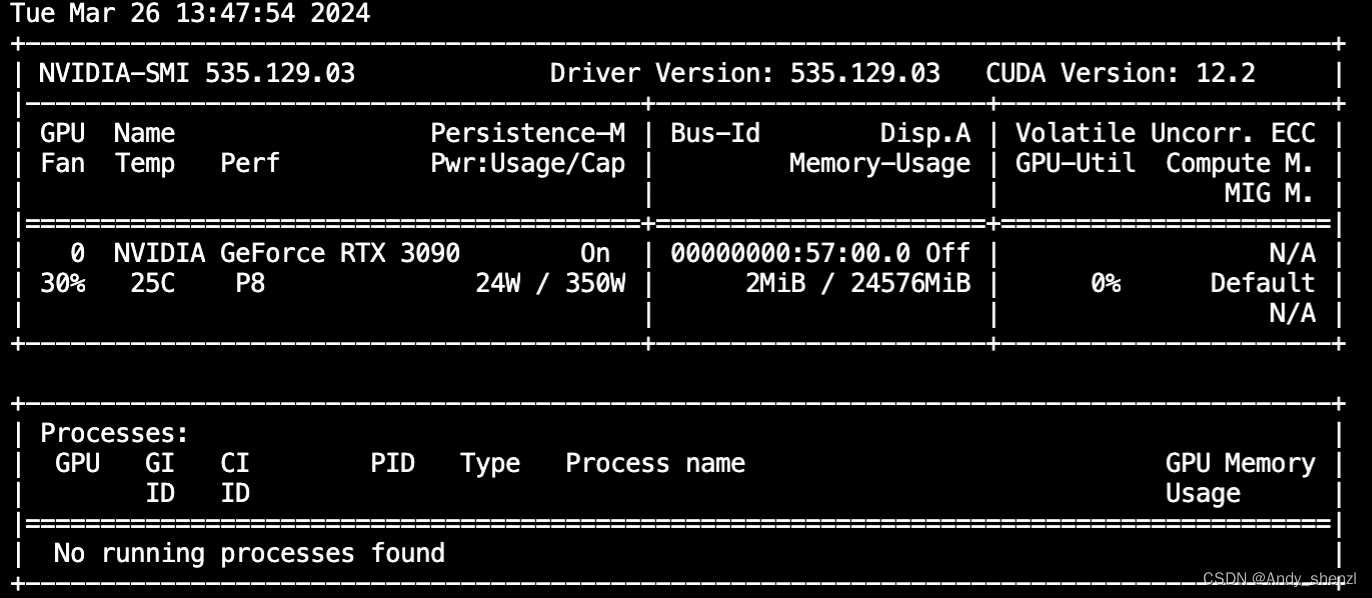
查看显卡
nvidia-smi
查看conda版本
conda --versionconda 4.10.3
conda create --name chatglm3_test python=3.11
conda activate chatglm3_test2.2 在虚拟环境中安装Pytorch
pytorch网址:
https://pytorch.org/get-started/previous-versions/
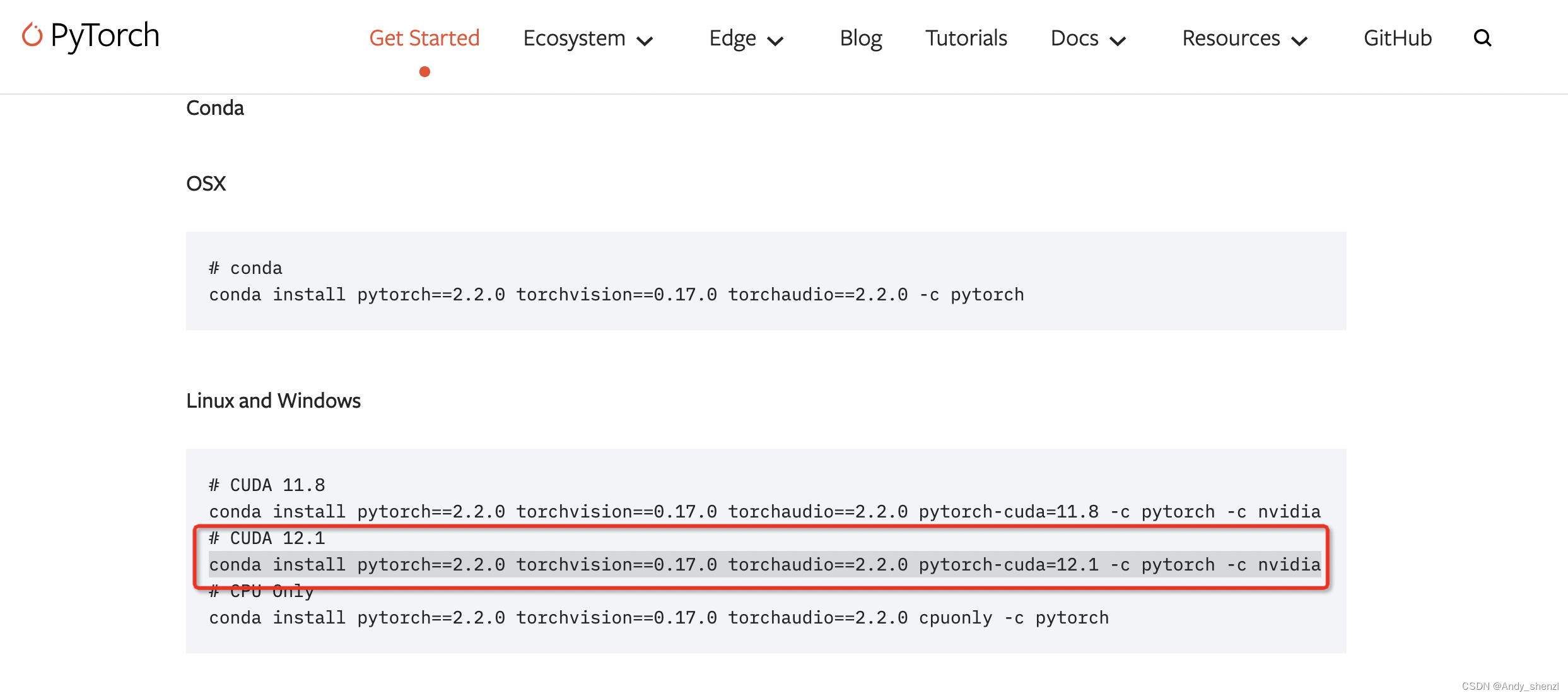
conda install pytorch==2.2.0 torchvision==0.17.0 torchaudio==2.2.0 pytorch-cuda=12.1 -c pytorch -c nvidia
import torch
print(torch.cuda.is_available())
2.3 下载ChatGLM3的项目文件
ChatGLM3的代码库和相关文档存储在 GitHub 这个在线平台上。GitHub 是一个广泛使用的代码托管平台,它提供了版本控制和协作功能。
要下载ChatGLM3-6B的项目文件,需要进入ChatGLM3的Github:https://github.com/THUDM/ChatGLM3
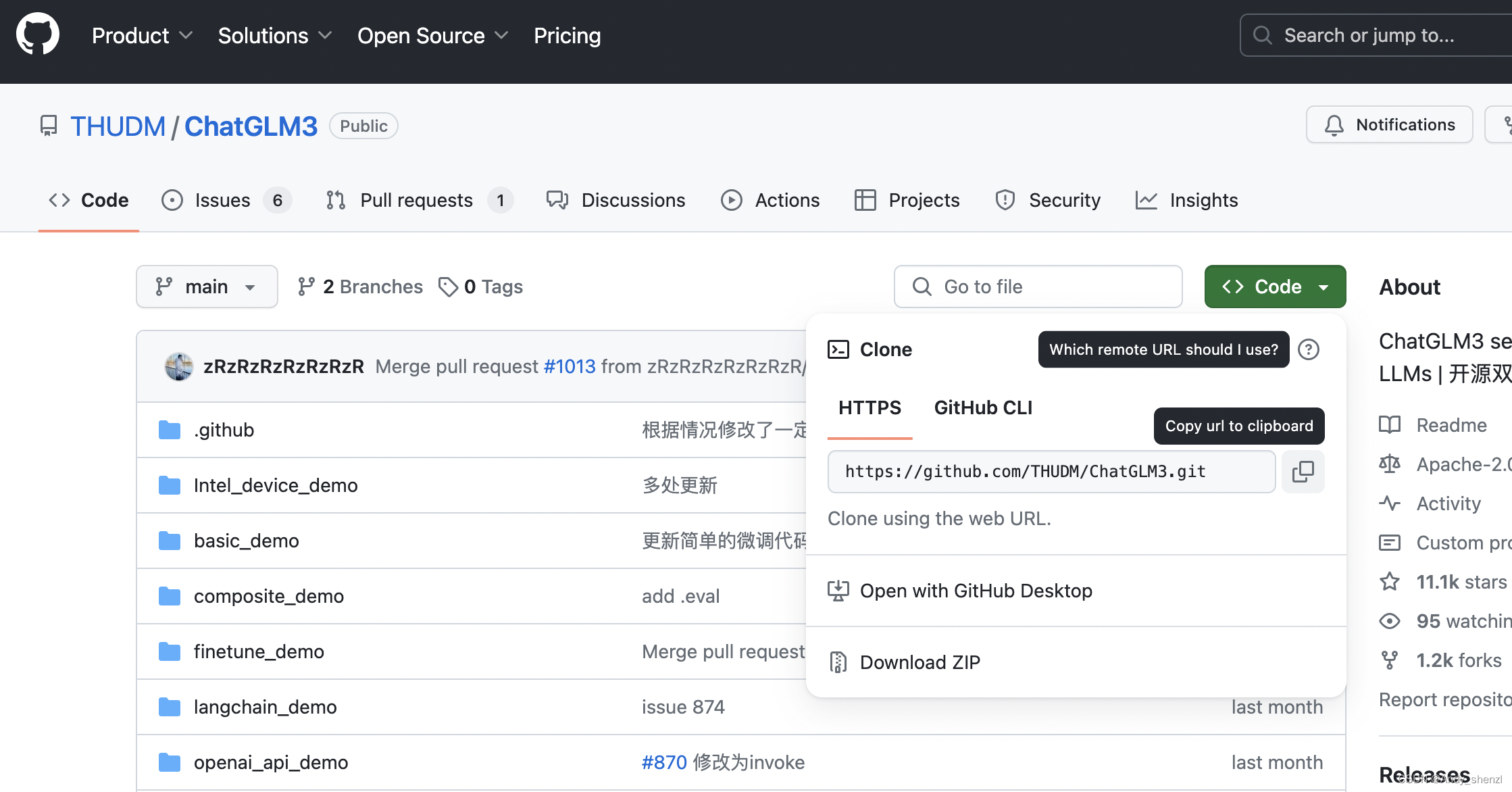
在 GitHub 上将项目下载到本地通常有两种主要方式:克隆 (Clone) 和 下载 ZIP 压缩包。
克隆 (Clone)是使用 Git 命令行的方式。我们可以克隆仓库到本地计算机,从而创建仓库的一个完整副本。这样做的好处是我们可以跟踪远程仓库的所有更改,并且可以提交自己的更改。如果要克隆某一个仓库,可以使用如下命令:
git clone <repository-url> # 其中 <repository-url> 是 GitHub 仓库的 URL。
推荐使用克隆 (Clone)的方式。对于ChatGLM3这个项目来说,我们首先在GitHub上找到其仓库的URL。
#source /etc/network_turbo
git clone https://github.com/THUDM/ChatGLM3.git
2.4 升级pip版本
pip 是 Python 的一个包管理器,用于安装和管理 Python 软件包。允许从 Python Package Index(PyPI)和其他索引中安装和管理第三方库和依赖。一般使用 pip 来安装、升级和删除 Python 软件包。除此之外,pip 自动处理 Python 软件包的依赖关系,确保所有必需的库都被安装。在Python环境中,尽管我们是使用conda来管理虚拟环境,但conda是兼容pip环境的,所以使用pip下载必要的包是完全可以的。
我们建议在执行项目的依赖安装之前升级 pip 的版本,如果使用的是旧版本的 pip,可能无法安装一些最新的包,或者可能无法正确解析依赖关系。升级 pip 很简单,只需要运行命令如下命令:
python -m pip install --upgrade pip
2.5 使用pip安装ChatGLM运行的项目依赖**
一般项目中都会提供 requirements.txt这样一个文件,该文件包含了项目运行所必需的所有 Python 包及其精确版本号。使用这个文件,可以确保在不同环境中安装相同版本的依赖,从而避免了因版本不一致导致的问题。我们可以借助这个文件,使用pip一次性安装所有必需的依赖,而不必逐个手动安装,大大提高效率。命令如下:
pip install -r requirements.txt
2.6 从Hugging Face下载ChatGLM3模型权重
经过Step 5的操作过程,我们下载到的只是ChatGLM3-6B的一些运行文件和项目代码,并不包含ChatGLM3-6B这个模型。这里我们需要进入到 Hugging Face 下载。Hugging Face 是一个丰富的模型库,开发者可以上传和共享他们训练好的机器学习模型。这些模型通常是经过大量数据训练的,并且很大,因此需要特殊的存储和托管服务。
不同于GitHub,GitHub 仅仅是一个代码托管和版本控制平台,托管的是项目的源代码、文档和其他相关文件。同时对于托管文件的大小有限制,不适合存储大型文件,如训练好的机器学习模型。相反,Hugging Face 专门为此类大型文件设计,提供了更适合大型模型的存储和传输解决方案。
Git Large File Storage(Git LFS)是一种用于处理大文件的工具,在 Hugging Face 下载大模型时,通常需要安装 Git LFS,主要的原因是:Git 本身并不擅长处理大型文件,因为在 Git 中,每次我们提交一个文件,它的完整内容都会被保存在 Git 仓库的历史记录中。但对于非常大的文件,这种方式会导致仓库变得庞大而且低效。而 Git LFS, 就不会直接将它们的内容存储在仓库中。相反,它存储了一个轻量级的“指针”文件,它本身非常小,它包含了关于大型文件的信息(如其在服务器上的位置),但不包含文件的实际内容。当我们需要访问或下载这个大型文件时,Git LFS 会根据这个指针去下载真正的文件内容。
实际的大文件存储在一个单独的服务器上,而不是在 Git 仓库的历史记录中。所以如果不安装 Git LFS 而直接从 Hugging Face 或其他支持 LFS 的仓库下载大型文件,通常只会下载到一个包含指向实际文件的指针的小文件,而不是文件本身。
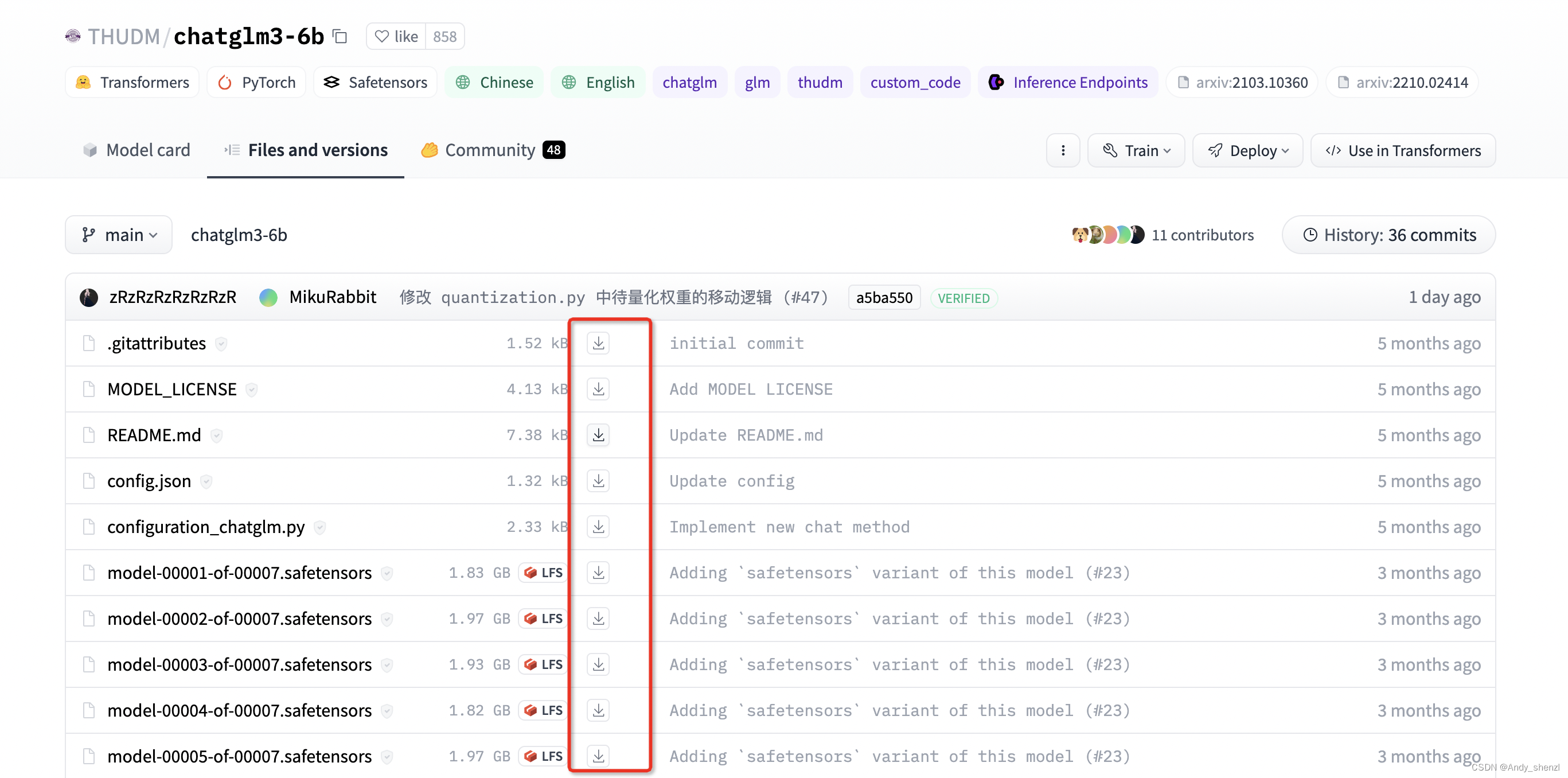
因为文件很大所以下载会很慢,建议在files页面直接点击下载单个文件,最后在整理在一起
三、运行ChatGLM3-6B模型的方式
3.1基于命令行的交互式对话
cd basic_demo/
ls
cli_batch_request_demo.py cli_demo.py cli_demo_bad_word_ids.py web_demo_gradio.py web_demo_streamlit.py
在启动前,我们仅需要进行一处简单的修改,因为我们已经把ChatGLM3-6B这个模型下载到了本地,所以需要修改一下模型的加载路径。
vim cli_demo.py
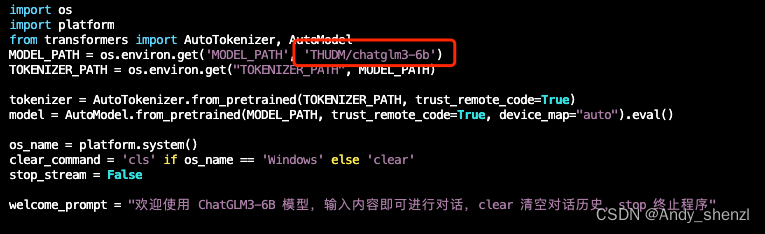
修改完成后,直接使用python cli_demp.py即可启动,如果启动成功,就会开启交互式对话,如果输入stop 可以退出该运行环境。

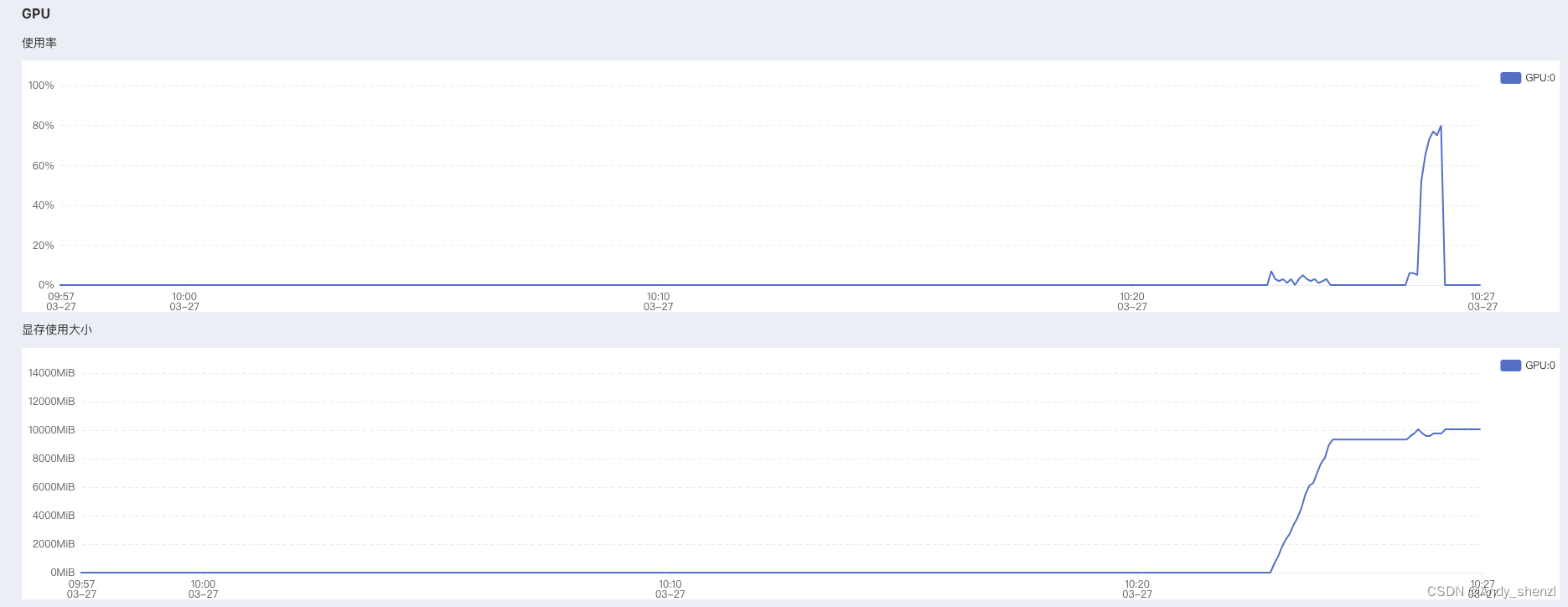
3.2 在指定虚拟环境的Jupyter Lab中运行
我们在部署Chatglm3-6B模型之前,创建了一个chatglme3_test虚拟环境来支撑该模型的运行。除了在终端中使用命令行启动,同样可以在Jupyter Lab环境中启动这个模型。具体的执行过程如下:
首先,在终端中找到需要加载的虚拟环境,使用如下命令可以查看当前系统中一共存在哪些虚拟环境:
conda env list# conda environments:
#
base * /root/miniconda3
chatglm3_test /root/miniconda3/envs/chatglm3_test
这里可以看到我们之前创建的chatglm3_test虚拟环境,需要使用如下命令进入该虚拟环境:
# 这里的`env_name`就是需要进入的虚拟环境名称
conda activate `env_name`
在该环境中安装ipykernel软件包。这个软件包将允许Jupyter Notebook使用特定环境的Python版本。运行以下命令:
conda install ipykernel
将该环境添加到Jupyter Notebook中。运行以下命令:
# 这里的env_name 替换成需要使用的虚拟环境名称
python -m ipykernel install --user --name=yenv_name --display-name="Python(env_name)"#python -m ipykernel install --user --name=llm --display-name="Python(chatglm3_test)" 执行完上述过程后,在终端输入jupyter lab 启动。
如果提示:The port 8888 is already in use, trying another port.
您可以在命令行中使用 -p 或 --port 选项,后面跟着您想要使用的端口号。例如,如果您想要使用端口 8889,您可以这样启动 JupyterLab:jupyter lab --port 8889
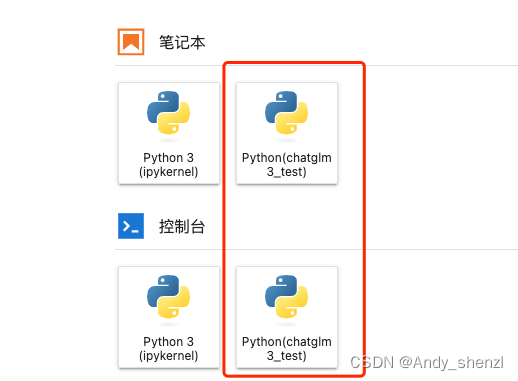
打开后就可以看到,当前环境下我们已经可以使用新的虚拟环境创建Notebook。
基本调用流程也比较简单,官方也给出了一个实例:
只需要从transformers中加载AutoTokenizer 和 AutoModel,指定好模型的路径即可。tokenizer这个词大家应该不会很陌生,可以简单理解我们在之前使用gpt系列模型的时候,使用tiktoken库帮我们把输入的自然语言,也就是prompt按照一种特定的编码方式来切分成token,从而生成API调用的成本。但在Transform中tokenizer要干的事会更多一些,它会把输入到大语言模型的文本,包在tokenizer中去做一些前置的预处理,会将自然语言文本转换为模型能够理解的格式,然后拆分为 tokens(如单词、字符或子词单位)等操作。
而对于模型的加载来说,官方的代码中指向的路径是THUDM/chatglm3-6b,表示可以直接在云端加载模型,所以如果我们没有下载chatglm3-6b模型的话,直接运行此代码也是可以的,只不过第一次加载会很慢,耐心等待即可,同时需要确保当前的网络是联通的(必要的情况下需要开梯子)。
因为我们已经将ChatGLM3-6B的模型权重下载到本地了,所以此处可以直接指向我们下载的Chatglm3-6b模型的存储路径来进行推理测试。
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)对于其他参数来说,model 有一个eval模式,就是评估的方法,模型基本就是两个阶段的事,一个是训练,一个是推理,计算的量更大,它需要把输入的值做一个推理,如果是一个有监督的模型,那必然存在一个标签值,也叫真实值,这个值会跟模型推理的值做一个比较,这个过程是正向传播。差异如果很大,就说明这个模型的能力还远远不够,既然效果不好,就要调整参数来不断地修正,通过不断地求导,链式法则等方式进行反向传播。当模型训练好了,模型的参数就不会变了,形成一个静态的文件,可以下载下来,当我们使用的时候,就不需要这个反向传播的过程,只需要做正向的推理就好了,此处设置 model.eval()就是说明这个过程。而trust_remote_code=True 表示信任远程代码(如果有), device=‘cuda’ 表示将模型加载到CUDA设备上以便使用GPU加速,这两个就很好理解了。









![【P1328】[NOIP2014 提高组] 生活大爆炸版石头剪刀布](https://img-blog.csdnimg.cn/img_convert/cb242bcc076eb19b2e006cd6118d44a3.png)