一、类加载阶段
一个类型从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期将会经历加载
(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化
(Initialization)、使用(Using)和卸载(Unloading)七个阶段,其中验证、准备、解析三个部分统称
为连接(Linking)。
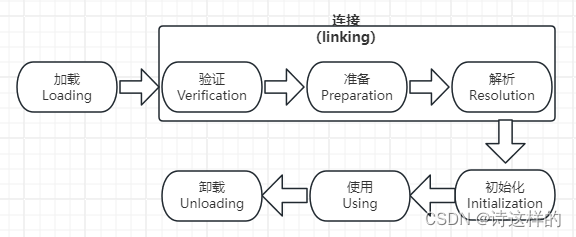
加载、验证、准备、初始化和卸载阶段的加载顺序是确定的,而解析阶段不一定:它在某些情况下可以在初始化阶段之后再开始。这是为了支持Java语言的运行时绑定特性(也称为动态绑定或晚期绑定)。
1)加载
“加载”(Loading)阶段是整个“类加载”(Class Loading)过程中的一个阶段。
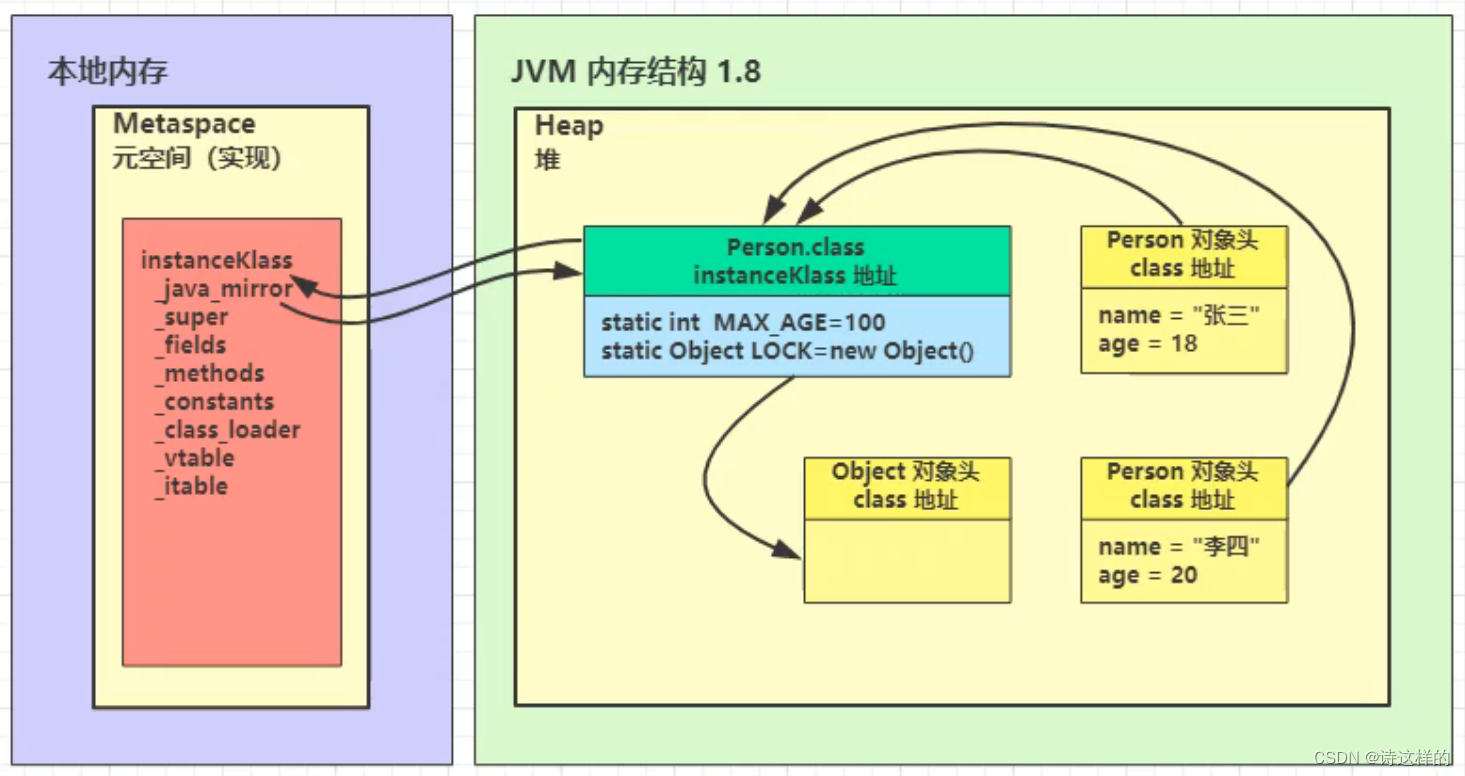
- 将类的字节码载入方法区中,内部采用 C++ 的 instanceKlass 描述 java 类,它的重要 field 有:
- _java_mirror 即 java 的类镜像,例如对 String 来说,就是 String.class,作用是把 klass 暴
- 露给 java 使用
- _super 即父类
- _fields 即成员变量
- _methods 即方法
- _constants 即常量池
- _class_loader 即类加载器
- _vtable 虚方法表
- _itable 接口方法表
注意:
- instanceKlass 这样的【元数据】是存储在方法区(1.8 后的元空间内),但 _java_mirror是存储在堆中的
- 可以通过前面介绍的 HSDB 工具查看
2)连接
2.1 验证
验证类是否符合 JVM 规范,安全性检查。
2.2 准备
准备阶段是正式为类中定义的变量(即静态变量,被static修饰的变量)分配内存并设置类变量初始值的阶段(默认值)。这里仅包括类变量,而不包括实例变量。
- 设置默认值static 变量在 JDK 7 之前存储于 instanceKlass 末尾,从 JDK 7 开始,存储于 _java_mirror 末尾
- static 变量分配空间和赋值是两个步骤,分配空间在准备阶段完成,真正的赋值在初始化阶段完成
- 如果 static 变量是 final 的基本类型,以及字符串常量,那么编译阶段值就确定了,赋值在准备阶
段完成 - 如果 static 变量被 final 修饰,但属于引用类型,那么赋值也会在初始化阶段完成
2.3 解析
将常量池中的符号引用解析为直接引用
package cn.itcast.jvm.t3.load;
/**
* 解析的含义
*/
public class Load2 {public static void main(String[] args) throws ClassNotFoundException, IOException {ClassLoader classloader = Load2.class.getClassLoader();// loadClass 方法不会导致类的解析和初始化 创建了C的对象,但不会创建 D的对象Class<?> c = classloader.loadClass("cn.itcast.jvm.t3.load.C");// 创建了 C 和 D的对象// new C(); System.in.read();}
}
class C {D d = new D();
}
class D {
}
3)初始化阶段
<clinit>()V 方法
初始化即调用 <clinit>()V ,虚拟机会保证这个类的『构造方法』的线程安全
发生的时机
类初始化是【懒惰的】
- main 方法所在的类,总会被首先初始化
- 首次访问这个类的静态变量或静态方法时
- 子类初始化,如果父类还没初始化,会引发
- 子类访问父类的静态变量,只会触发父类的初始化
- Class.forName
- new 会导致初始化
不会导致类初始化的情况
- 访问类的 static final 静态常量(基本类型和字符串)不会触发初始化
- 类对象.class 不会触发初始化
- 创建该类的数组不会触发初始化
- 类加载器的 loadClass 方法
- Class.forName 的参数 2 为 false 时
二、类加载器
以 JDK 8 为例:
| 名称 | 加载哪的类 | 说明 |
|---|---|---|
| Bootstrap ClassLoader | JAVA_HOME/jre/lib | 无法直接访问 |
| Extension ClassLoader | JAVA_HOME/jre/lib/ext | 上级为 Bootstrap, 显示 null |
| Application ClassLoader | classpath | 上级为 Extension |
| 自定义类加载 | 自定义 | 上级为 Application |
一般情况下 获取的 classloader 默认是 AppClassLoader 应用程序类加载器
1)启动类加载器
E:\git\jvm\out\production\jvm>java -Xbootclasspath/a:. cn.itcast.jvm.t3.load.Load5
bootstrap F init
null
- -Xbootclasspath 表示设置 bootclasspath (Bootstrap ClassLoader)
- 其中
/a:.表示将当前目录追加至 bootclasspath 之后
2)扩展类加载器
将A类打包成 jar包,放在 JAVA_HOME/jre/ext目录下,获取A类的类加载器为 sun.misc.Launcher$ExtClassLoader$@23232。
通过双亲委派机制,往上找类加载器,委派上级优先查找加载,如果上级没有,最后由本级加载(应用程序类加载器)
3)双亲委派模式
所谓的双亲委派,就是指调用类加载器的 loadClass 方法时,查找类的规则
注意
这里的双亲,翻译为上级似乎更为合适,因为它们并没有继承关系
protected Class<?> loadClass(String name, boolean resolve)throws ClassNotFoundException {synchronized (getClassLoadingLock(name)) {// 1. 检查该类是否已经加载Class<?> c = findLoadedClass(name);if (c == null) {long t0 = System.nanoTime();try {if (parent != null) {// 2. 有上级的话,委派上级 loadClassc = parent.loadClass(name, false);} else {// 3. 如果没有上级了(ExtClassLoader),则委派 BootstrapClassLoaderc = findBootstrapClassOrNull(name);}} catch (ClassNotFoundException e) {}if (c == null) {long t1 = System.nanoTime();// 4. 每一层找不到,调用 findClass 方法(每个类加载器自己扩展)来加载c = findClass(name);// 5. 记录耗时sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);sun.misc.PerfCounter.getFindClasses().increment();}}if (resolve) {resolveClass(c);}return c;}
}
4)线程上下文类加载器
我们在使用 JDBC 时,都需要加载 Driver 驱动,但是实际上我们不写Class.forName("com.mysql.jdbc.Driver"),也可以让com.mysql.jdbc.Driver正确加载。底层是
public class DriverManager {// 注册驱动的集合private final static CopyOnWriteArrayList<DriverInfo> registeredDrivers = new CopyOnWriteArrayList<>();// 初始化驱动static {loadInitialDrivers();println("JDBC DriverManager initialized");}
进入loadInitialDrivers() 方法
private static void loadInitialDrivers() {...// 1)使用 ServiceLoader 机制加载驱动,即 SPIAccessController.doPrivileged(new PrivilegedAction<Void>() {publicVoid run() {ServiceLoader<Driver> loadedDrivers =ServiceLoader.load(Driver.class);Iterator<Driver> driversIterator = loadedDrivers.iterator();try{while(driversIterator.hasNext()) {driversIterator.next();}} catch(Throwable t) {// Do nothing}return null;}});println("DriverManager.initialize: jdbc.drivers = " + drivers);// 2)使用 jdbc.drivers 定义的驱动名加载驱动if (drivers == null || drivers.equals("")) {return;}String[] driversList = drivers.split(":");println("number of Drivers:" + driversList.length);for (String aDriver : driversList) {try {println("DriverManager.Initialize: loading " + aDriver);// 这里的 ClassLoader.getSystemClassLoader() 就是应用程序类加载器Class.forName(aDriver, true, ClassLoader.getSystemClassLoader());} catch (Exception ex) {println("DriverManager.Initialize: load failed: " + ex);}}
}底层实际上是 spi(Service Provider Interface)机制。
最后是使用 Class.forName 完成类的加载和初始化,关联的是应用程序类加载器,因此可以顺利完成类加载
约定如下,在 jar 包的 META-INF/services 包下,以接口全限定名名为文件,文件内容是实现类名称
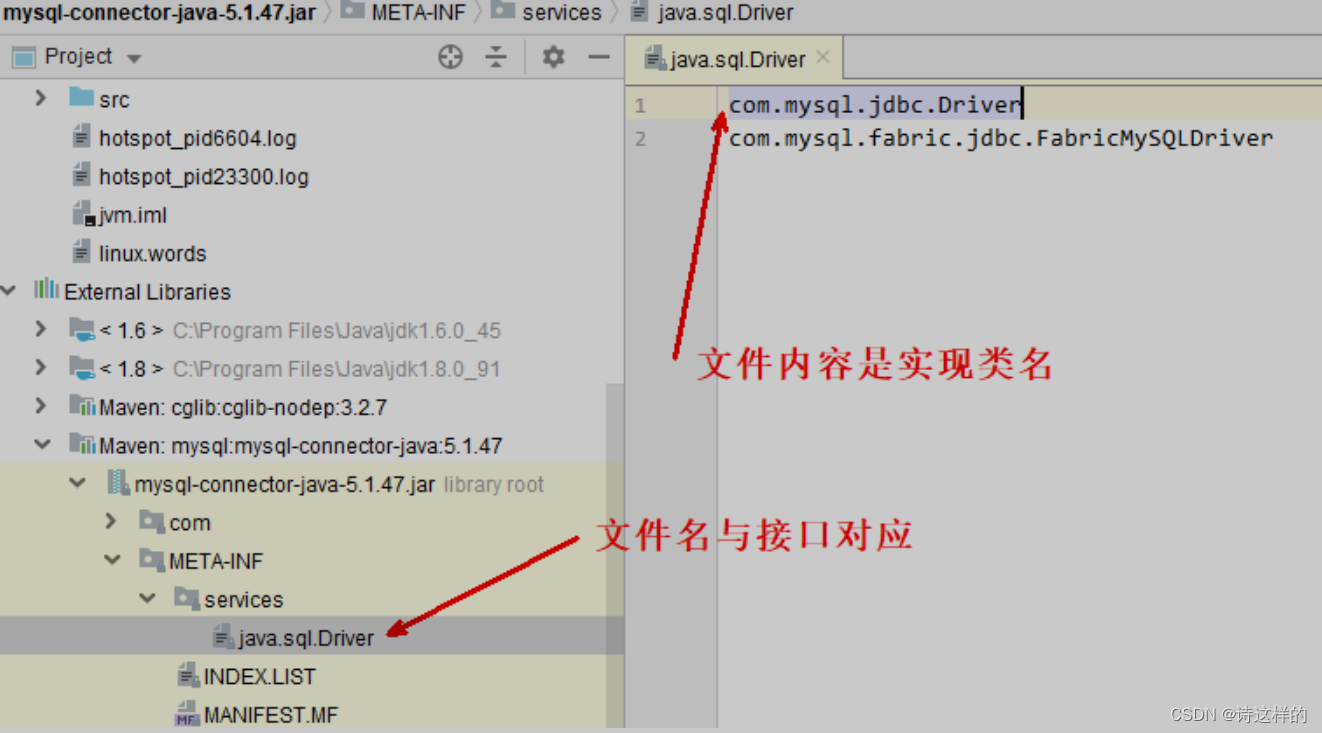
体现的是【面向接口编程+解耦】的思想,在下面一些框架中都运用了此思想:
- JDBC
- Servlet 初始化器
- Spring 容器
- Dubbo(对 SPI 进行了扩展)
5)自定义类加载器

在自定义类加载器时,使用不同的类加载器对象获取的类不是相同的。
例如:
public class Load7 {public static void main(String[] args) throws Exception {MyClassLoader classLoader = new MyClassLoader();Class<?> c1 = classLoader.loadClass("MapImpl1");Class<?> c2 = classLoader.loadClass("MapImpl1"); // 都是 classLoader1 对象System.out.println(c1 == c2); // trueMyClassLoader classLoader2 = new MyClassLoader();Class<?> c3 = classLoader2.loadClass("MapImpl1"); // 创建了 classLoader2 System.out.println(c1 == c3); // false}
}
三、运行期优化
1)即时编译
分层编译
JVM 将执行状态分成了 5 个层次:
- 0 层,解释执行(Interpreter)
- 1 层,使用 C1 即时编译器编译执行(不带 profiling)
- 2 层,使用 C1 即时编译器编译执行(带基本的 profiling)
- 3 层,使用 C1 即时编译器编译执行(带完全的 profiling)
- 4 层,使用 C2 即时编译器编译执行
即时编译器:c1 客户端编译器(Client Compiler) c2 服务端编译器 (Server Compiler)
profiling 是指在运行过程中收集一些程序执行状态的数据,例如【方法的调用次数】,【循环的
回边次数】等
即时编译器(JIT)与解释器的区别
- 解释器是将字节码解释为机器码,下次即使遇到相同的字节码,仍会执行重复的解释
- JIT 是将一些字节码编译为机器码,并存入 Code Cache,下次遇到相同的代码,直接执行,无需再编译
- 解释器是将字节码解释为针对所有平台都通用的机器码
- JIT 会根据平台类型,生成平台特定的机器码
对于占据大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,以达到理想的运行速度。 执行效率上简单比较一下 Interpreter < C1 < C2,总的目标是发现热点代码(hotspot名称的由来),优化之
优化手段称之为【逃逸分析】,发现新建的对象是否逃逸。可以使用 -XX:-DoEscapeAnalysis 关闭逃逸分析,再运行刚才的示例观察结果,未使用 C2 即时编译执行。
方法内联
对热点方法(经常调用的方法),且代码长度较短,会进行内联,即将方法内的代码拷贝、粘贴到方法调用者的位置。
-XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining (解锁隐藏参数)打印 inlining(内联) 信息
-XX:CompileCommand=dontinline,*JIT2.square 禁止某个方法 inlining
-XX:+PrintCompilation 打印编译信息