垃圾回收&运行机制
- 垃圾回收
- 计算机组成
- 解释与编译
- JavaScript引擎
- V8引擎
- 垃圾回收
- 引用计数法
- 标记清除(mark-sweep)算法
- 内存管理
- 新生代
- 运行机制
- 浏览器进程分类:
- 浏览器事件循环
- 宏任务
- 微任务
- 整体流程
- 浏览器事件循环
- 案例一
- 案例二
垃圾回收
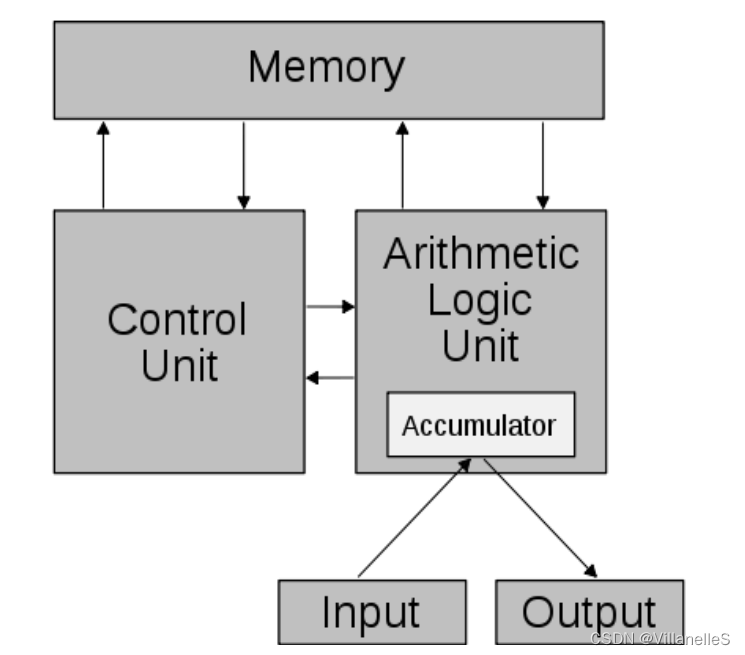
计算机组成
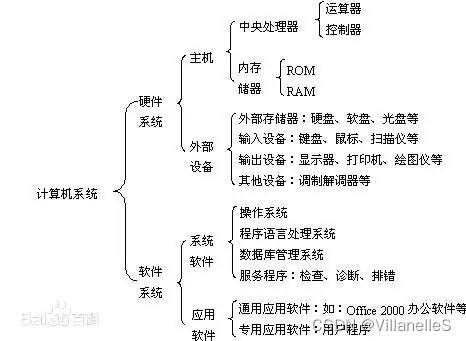
我们编写的软件首先读取到内存,用于提供给 CPU 进行运算处理。
内存的读取和释放,决定了程序性能。
Windows电脑启动程序是在rom的。
冯诺依曼模型
解释与编译
编译相当于做好了一桌子菜,可以直接开吃了。而解释就相当于吃火锅,需要一边煮一边吃。
JavaScript 属于解释型语言,它需要在代码执行时,将代码编译为机器语言。
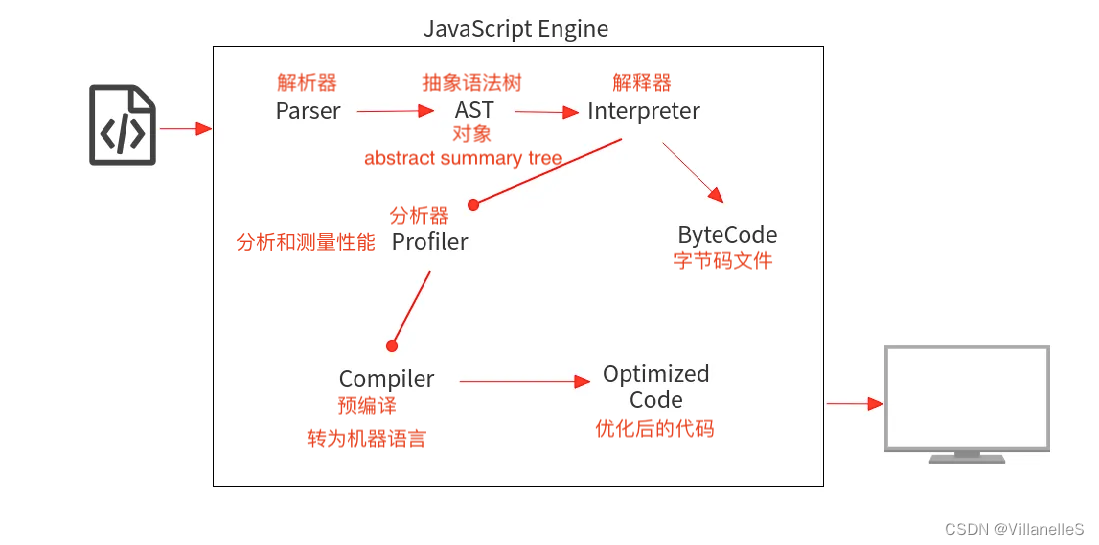
- Interpreter 逐行读取代码并立即执行。
- Compiler 读取您的整个代码,进行一些优化,然后生成优化后的代码。

从上图中可以看出,ByteCode 只是中间码,计算机仍需要对其进行翻译才能执行。 但是 Interpreter 和 Compiler 都将源代码转换为机器语言,它们唯一的区别在于转换的过程不尽相同。 - Interpreter 逐行将源代码转换为等效的机器代码。
- Compiler 在一开始就将所有源代码转换为机器代码
JavaScript引擎
JavaScript 其实有众多引擎,只不过 v8 是我们最为熟知的。
- V8 (Google),用 C++编写,开放源代码,由 Google 丹麦开发,是 Google Chrome 的一部分,也用于 Node.js。
- JavaScriptCore (Apple),开放源代码,用于 webkit 型浏览器,如 Safari ,2008 年实现了编译器和字节码解释器,升级为了 SquirrelFish。苹果内部代号为“Nitro”的 JavaScript 引擎也是基于 JavaScriptCore 引擎的。
- Rhino,由 Mozilla 基金会管理,开放源代码,完全以 Java 编写,用于 HTMLUnit
- SpiderMonkey (Mozilla),第一款 JavaScript 引擎,早期用于 Netscape Navigator,现时用于 Mozilla Firefox。
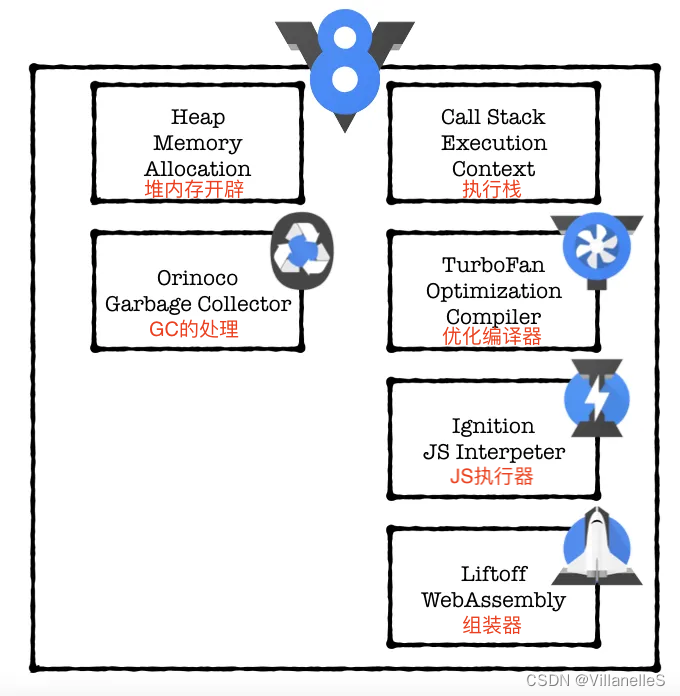
V8引擎
在node.js整个架构中:
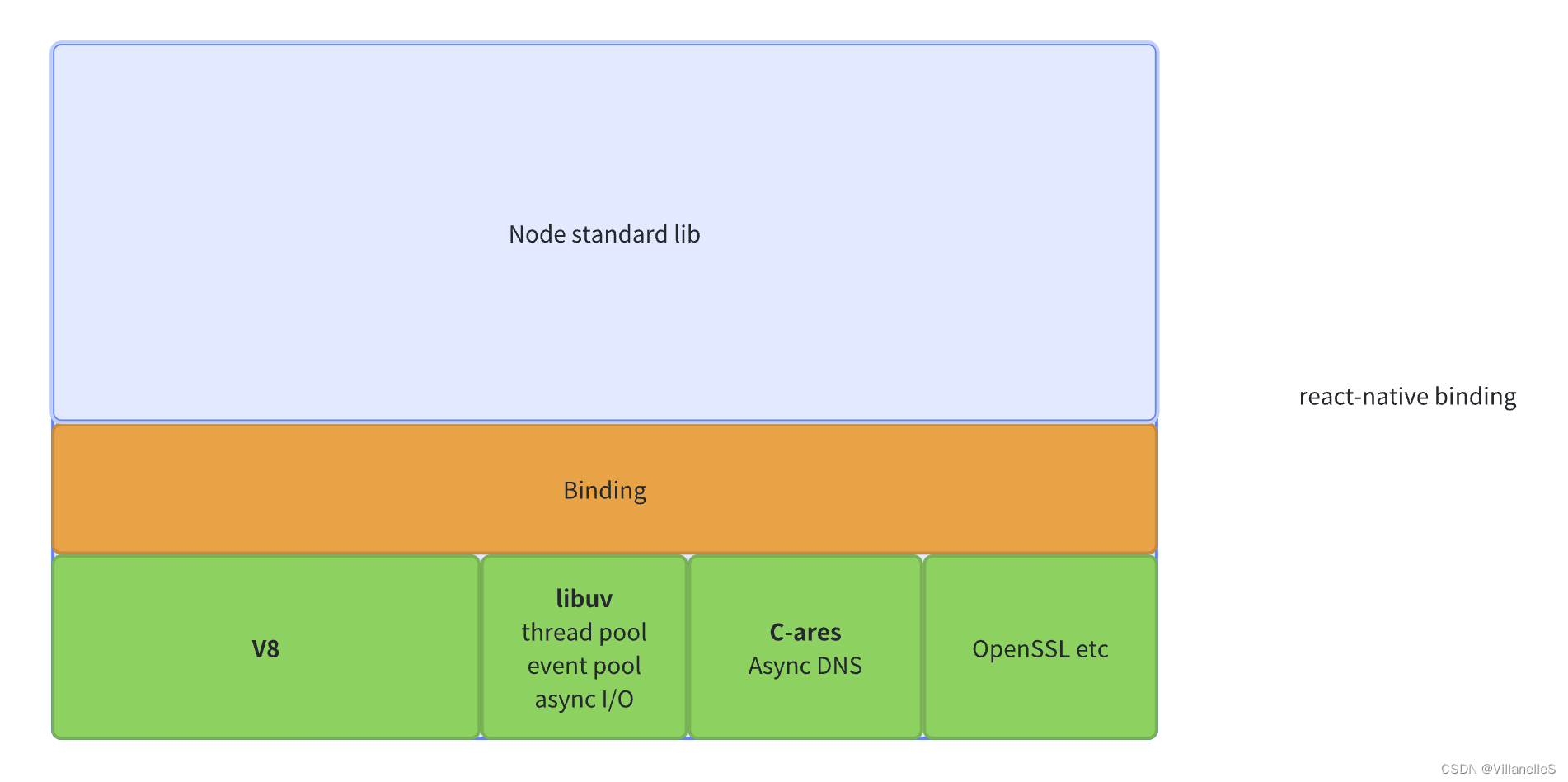
谷歌的 Chrome 使用 V8,Safari 使用 JavaScriptCore,Firefox 使用 SpiderMonkey
V8处理过程
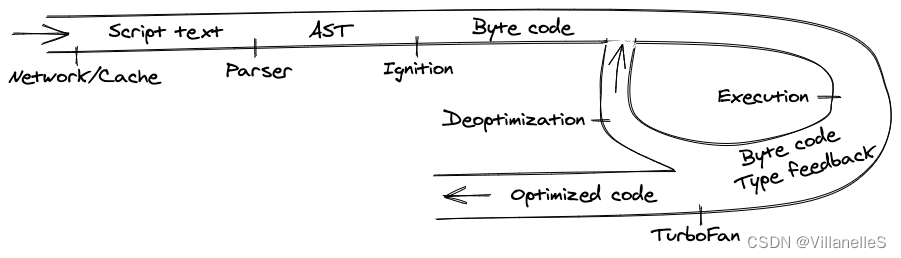
- 始于从网络中获取 JavaScript 代码。
- V8 解析源代码并将其转化为抽象语法树(AST)。
- 基于该 AST,Ignition 解释器可以开始做它的事情,并产生字节码。
- 在这一点上,引擎开始运行代码并收集类型反馈。
- 为了使它运行得更快,字节码可以和反馈数据一起被发送到优化编译器。优化编译器在此基础上做出某些假设,然后产生高度优化的机器代码。
- 如果在某些时候,其中一个假设被证明是不正确的,优化编译器就会取消优化,并回到解释器中。
垃圾回收
垃圾回收,又称为:GC(garbage collection)。
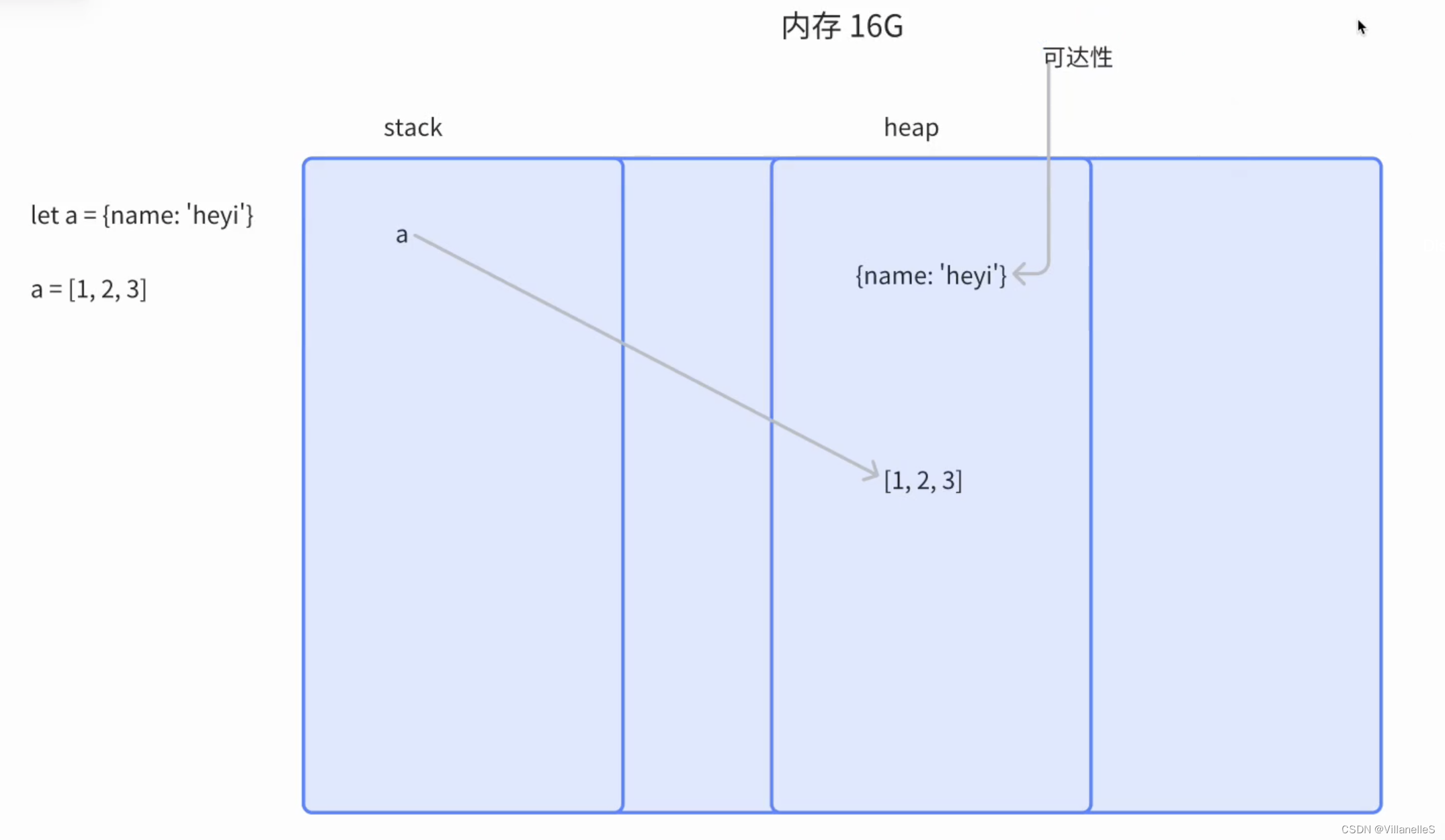
let a = {name: 'heyi'};
a = [1, 2, 3, 4, 5];
引用计数法
- 当声明了一个变量并且将一个引用类型赋值给该变量的时候这个值的引用次数就为 1
- 如果同一个值又被赋给另一个变量,那么引用数加 1
- 如果该变量的值被其他的值覆盖了,则引用次数减 1
- 当这个值的引用次数变为 0 的时候,说明没有变量在使用,这个值没法被访问了,回收空间,垃圾回收器会在运行的时候清理掉引用次数为 0 的值占用的内存
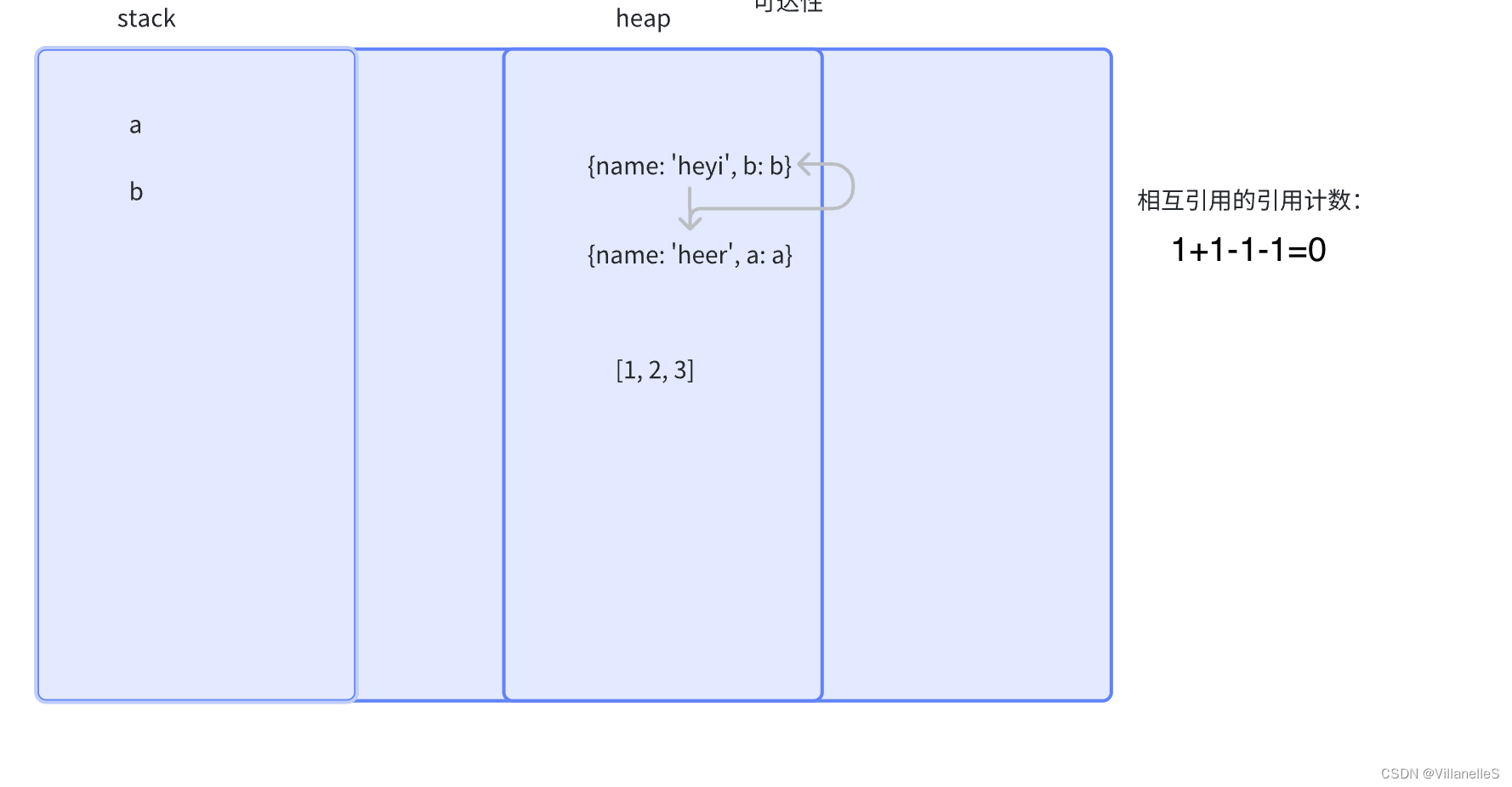
let a={name:"heyi",b:b}
let b={name:"heer",a:a}
a=null
b=null
优点
引用计数算法的优点我们对比标记清除来看就会清晰很多,首先引用计数在引用值为 0 时,也就是在变成垃圾的那一刻就会被回收,所以它可以立即回收垃圾
而标记清除算法需要每隔一段时间进行一次,那在应用程序(JS脚本)运行过程中线程就必须要暂停去执行一段时间的 GC,另外,标记清除算法需要遍历堆里的活动以及非活动对象来清除,而引用计数则只需要在引用时计数就可以了
缺点
引用计数的缺点想必大家也都很明朗了,首先它需要一个计数器,而此计数器需要占很大的位置,因为我们也不知道被引用数量的上限,还有就是无法解决循环引用无法回收的问题,这也是最严重的
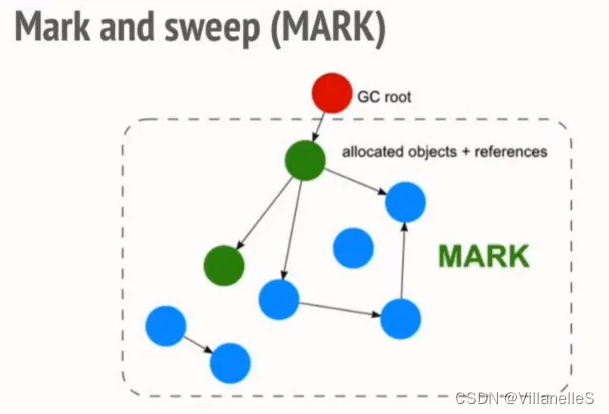
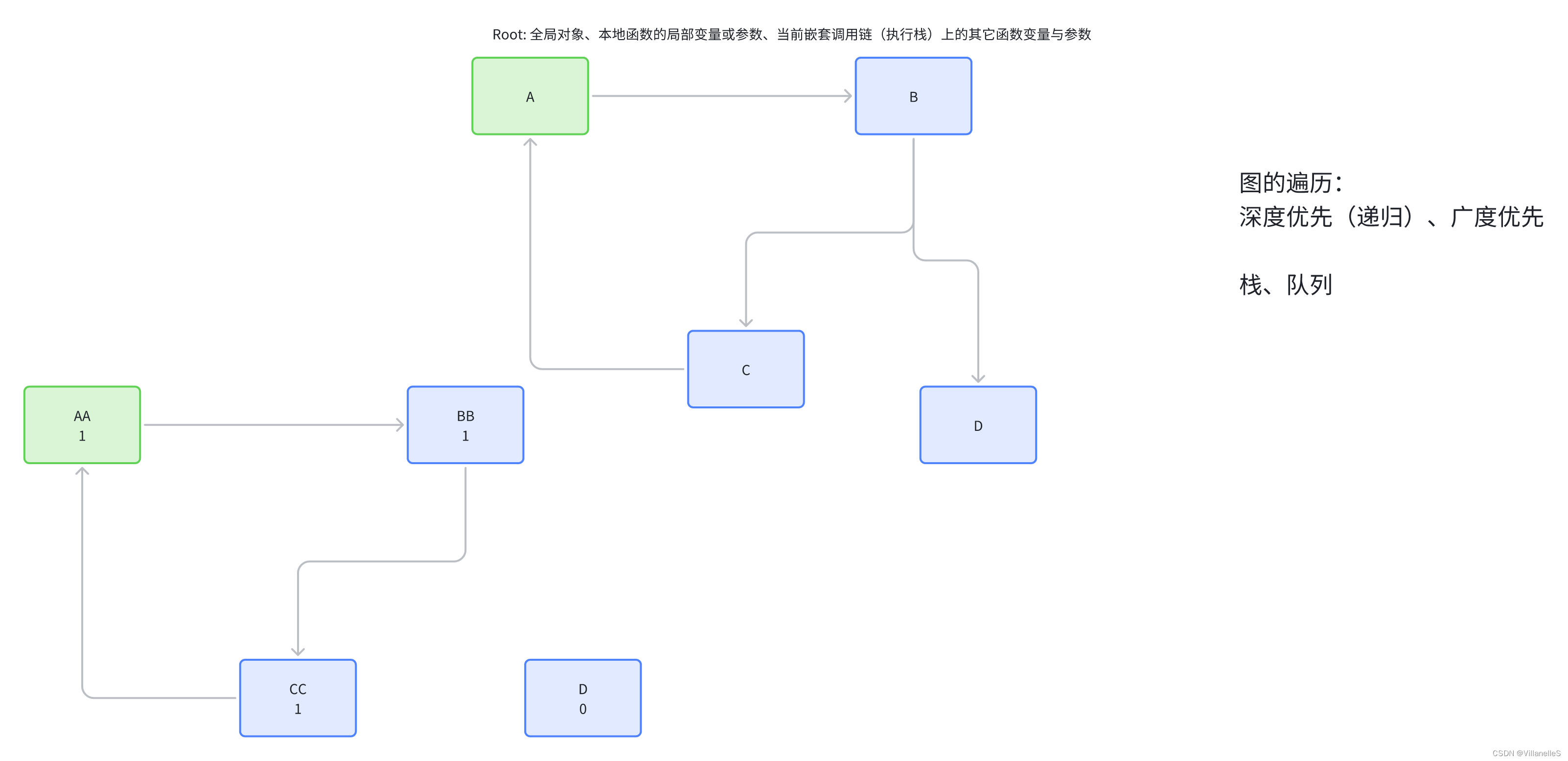
标记清除(mark-sweep)算法
标记清除(Mark-Sweep),目前在 JavaScript引擎 里这种算法是最常用的,到目前为止的大多数浏览器的 JavaScript引擎 都在采用标记清除算法,各大浏览器厂商还对此算法进行了优化加工,且不同浏览器的 JavaScript引擎 在运行垃圾回收的频率上有所差异。
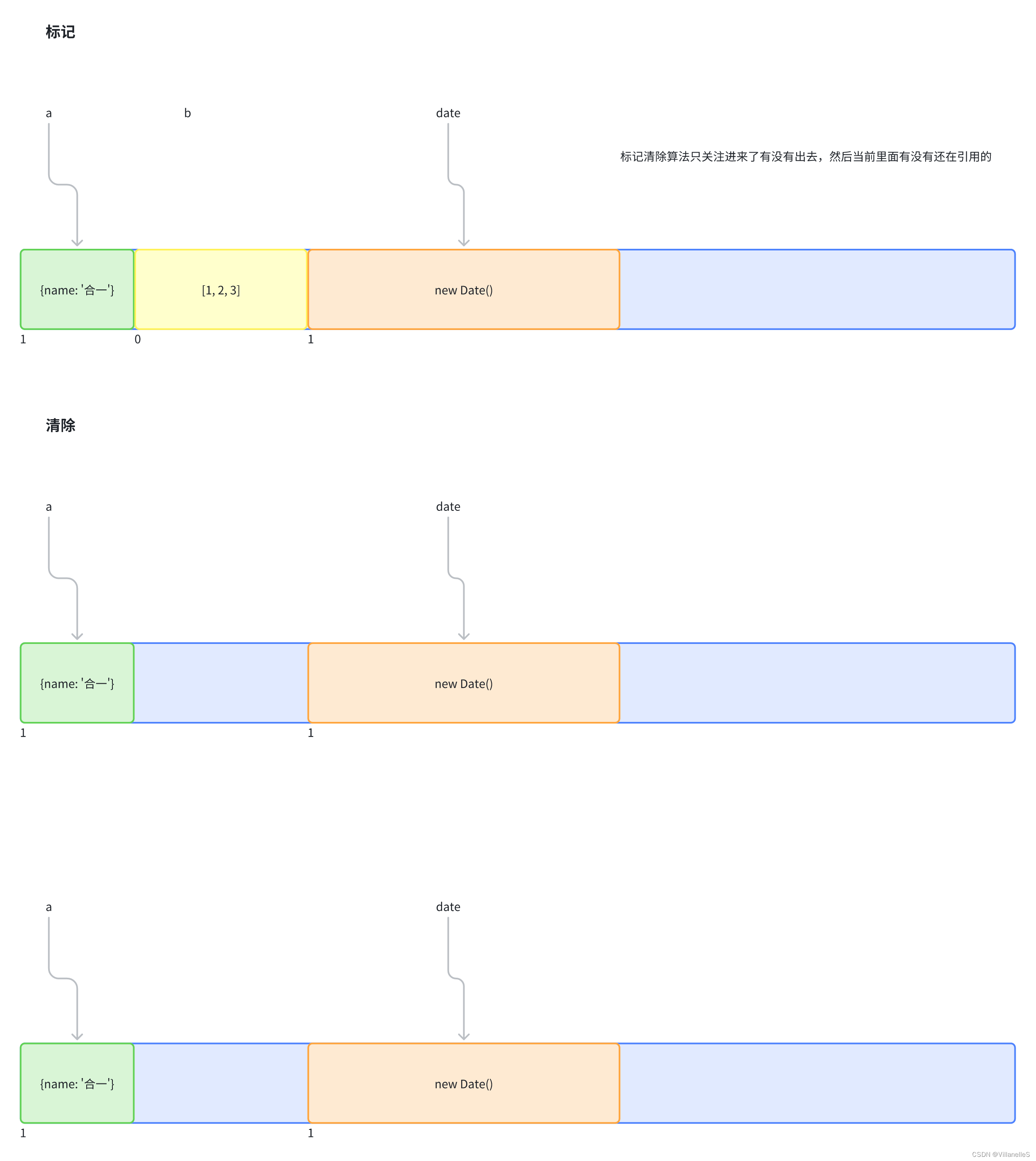
整个标记清除算法大致过程就像下面这样
- 垃圾收集器在运行时会给内存中的所有变量都加上一个标记,假设内存中所有对象都是垃圾,全标记为0
- 然后从各个根对象开始遍历,把不是垃圾的节点改成1
- 清理所有标记为0的垃圾,销毁并回收它们所占用的内存空间
- 最后,把所有内存中对象标记修改为0,等待下一轮垃圾回收
优点
标记清除算法的优点只有一个,那就是实现比较简单,打标记也无非打与不打两种情况,这使得一位二进制位(0和1)就可以为其标记,非常简单
缺点
标记清除算法有一个很大的缺点,就是在清除之后,剩余的对象内存位置是不变的,也会导致空闲内存空间是不连续的,出现了 内存碎片(如下图),并且由于剩余空闲内存不是一整块,它是由不同大小内存组成的内存列表。
内存管理
V8 的垃圾回收策略主要基于分代式垃圾回收机制,V8 中将堆内存分为新生代和老生代两区域,采用不同的垃圾回收器也就是不同的策略管理垃圾回收

新生代


当新加入对象时,它们会被存储在使用区。然而,当使用区快要被写满时,垃圾清理操作就需要执行。在开始垃圾回收之前,新生代垃圾回收器会对使用区中的活动对象进行标记。标记完成后,活动对象将会被复制到空闲区并进行排序。然后,垃圾清理阶段开始,即将非活动对象占用的空间清理掉。最后,进行角色互换,将原来的使用区变成空闲区,将原来的空闲区变成使用区。
如果一个对象经过多次复制后依然存活,那么它将被认为是生命周期较长的对象,且会被移动到老生代中进行管理。除此之外,还有一种情况,如果复制一个对象到空闲区时,空闲区的空间占用超过了25%,那么这个对象会被直接晋升到老生代空间中。25%比例的设置是为了避免影响后续内存分配,因为当按照 Scavenge 算法回收完成后,空闲区将翻转成使用区,继续进行对象内存分配。
运行机制
浏览器进程分类:
- 浏览器主进程
(1)协调控制其他子进程(创建、销毁)
(2)浏览器界面显示,用户交互,前进、后退、收藏
(3)将渲染进程得到的内存中的Bitmap,绘制到用户界面上
(4)存储功能等 - 第三方插件进程
(1)每种类型的插件对应一个进程,仅当使用该插件时才创建 - GPU进程 : 用于3D绘制等
(1)渲染进程,就是我们说的浏览器内核
①排版引擎Blink和JavaScript引擎V8都是运行在该进程中,将 HTML、CSS 和 JavaScript 转换为用户可以与之交互的网页,
②负责页面渲染,脚本执行,事件处理等
③每个tab页一个渲染进程
④出于安全考虑,渲染进程都是运行在沙箱模式下 - 网络进程
(1)负责页面的网络资源加载,之前作为一个模块运行在浏览器主进程里面,最近才独立成为一个单独的进程
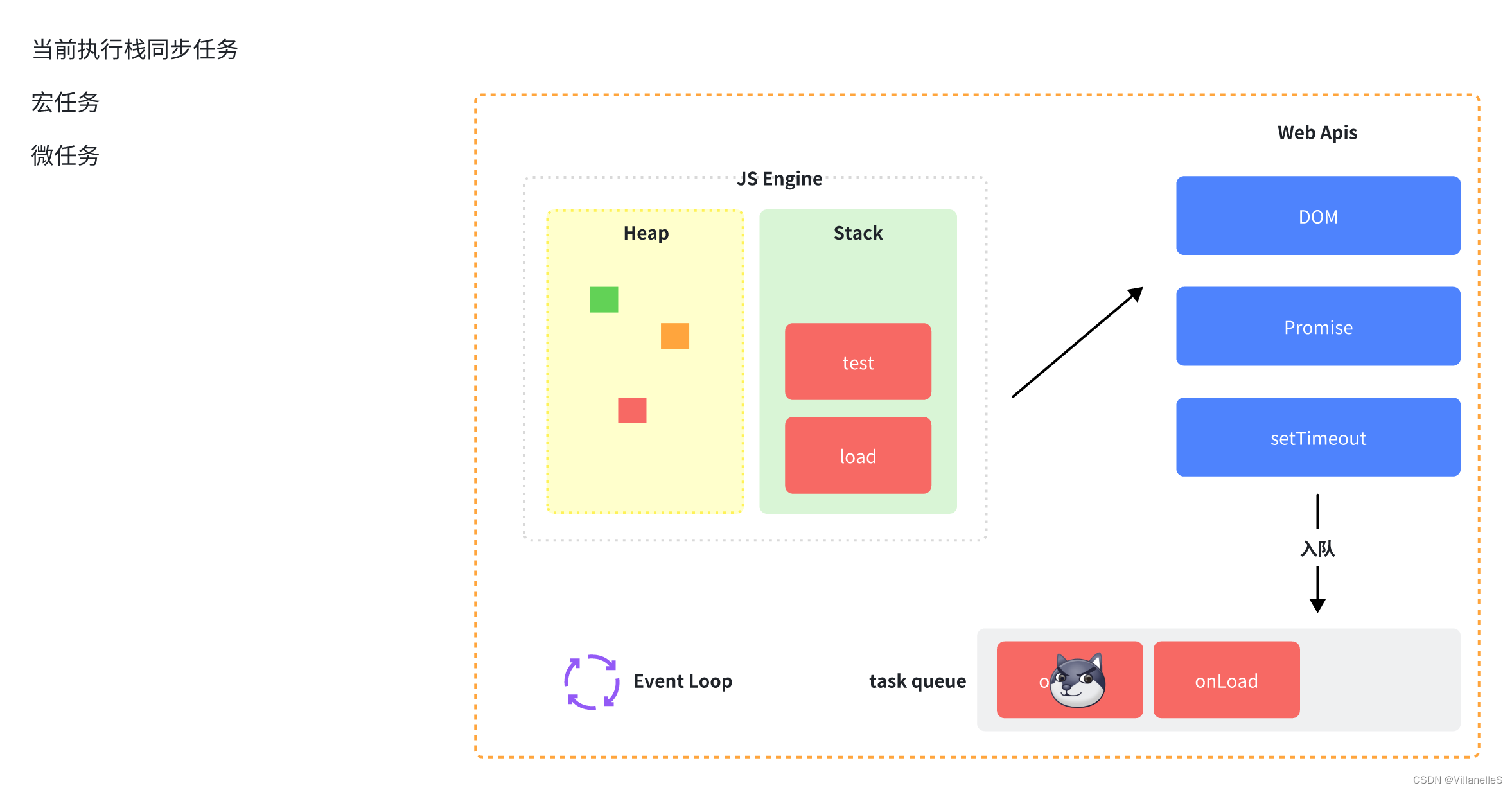
浏览器事件循环
浏览器是单线程操作的,所以执行事件要进行循环执行
宏任务
可以将每次执行栈执行的代码当做是一个宏任务
- I/O
- setTimeout
- setInterval
- setImmediate
- requestAnimationFrame
微任务
当宏任务执行完,会在渲染前,将执行期间所产生的所有微任务都执行完
- process.nextTick
- MutationObserver
- Promise.then catch finally
整体流程
- 当前执行栈内容执行
- 执行过程中如果遇到微任务,就将它添加到微任务的任务队列中
- 宏任务执行完毕后,立即执行当前微任务队列中的所有微任务(依次执行)
- 当前宏任务执行完毕,开始检查渲染,然后GUI线程接管渲染
- 渲染完毕后,JS线程继续接管,开始下一个同步任务
浏览器事件循环
案例一
console.log(1);queueMicrotask(() => {console.log(2)});Promise.resolve().then(() => console.log(3));setTimeout(() => {console.log(4)})
问:上面的打印顺序是怎么样的?
首先,任务,js 主进程的内容先执行,js 常规的代码 1, 2 为微任务,3 微任务,4 宏任务
- 执行同步代码。
- 执行一个宏任务(执行栈中没有就从任务队列中获取)。
- 执行过程中如果遇到微任务,就将它添加到微任务的任务队列中。
- 宏任务执行完毕后,立即执行当前微任务队列中的所有微任务(依次执行)。
- 当前宏任务执行完毕,开始检查渲染,然后渲染线程接管进行渲染。
- 渲染完毕后,JavaScript 线程继续接管,开始下一个循环。
queueMicrotask(() => {/* … */}):
Window 或 Worker 接口的 queueMicrotask() 方法,将微任务加入队列以在控制返回浏览器的事件循环之前的安全时间执行。
参数:function
当浏览器引擎确定可以安全调用你的代码时执行的 function。微任务(microtask)的执行顺序在所有进行中的任务(pending task)完成之后,在对浏览器的事件循环产生控制(yielding control to the browser’s event loop)之前。
执行过程:
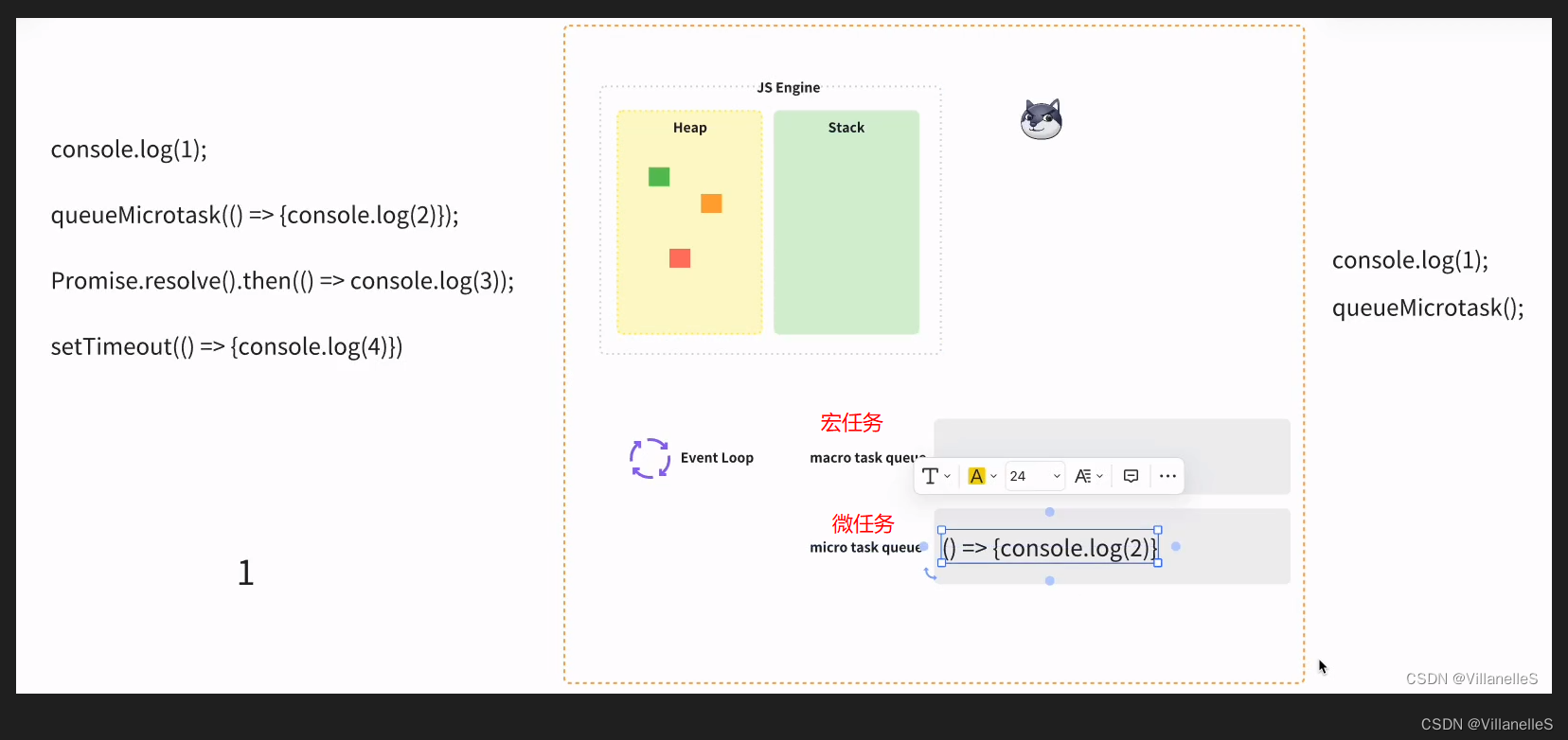
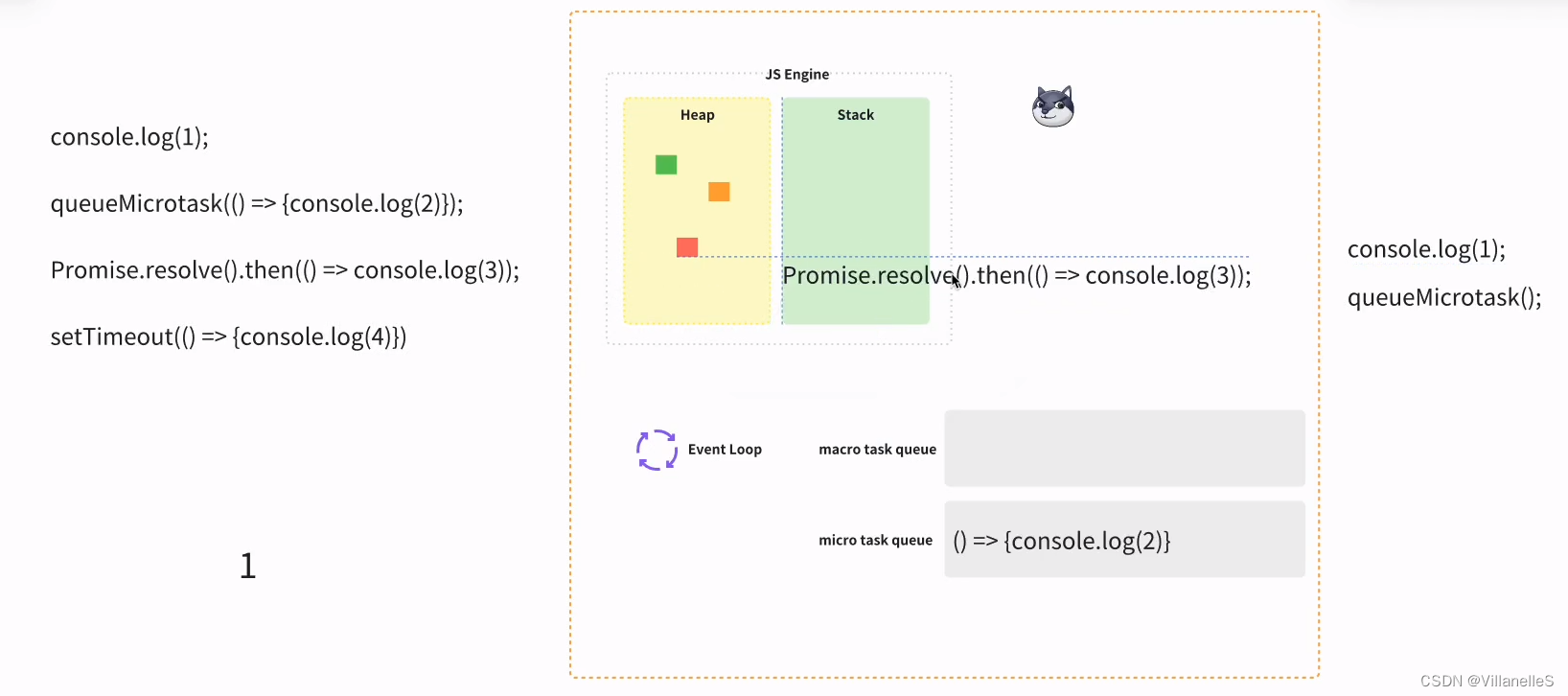
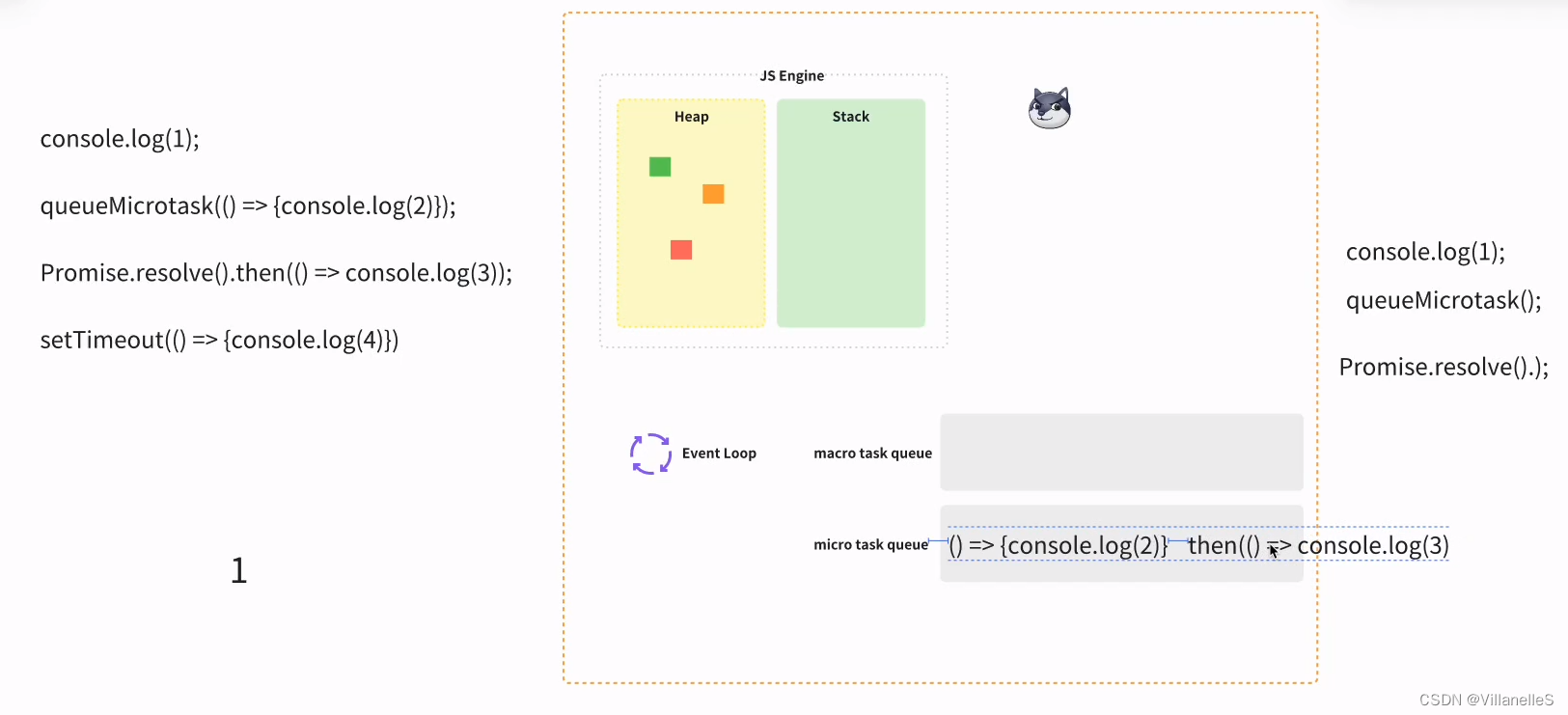
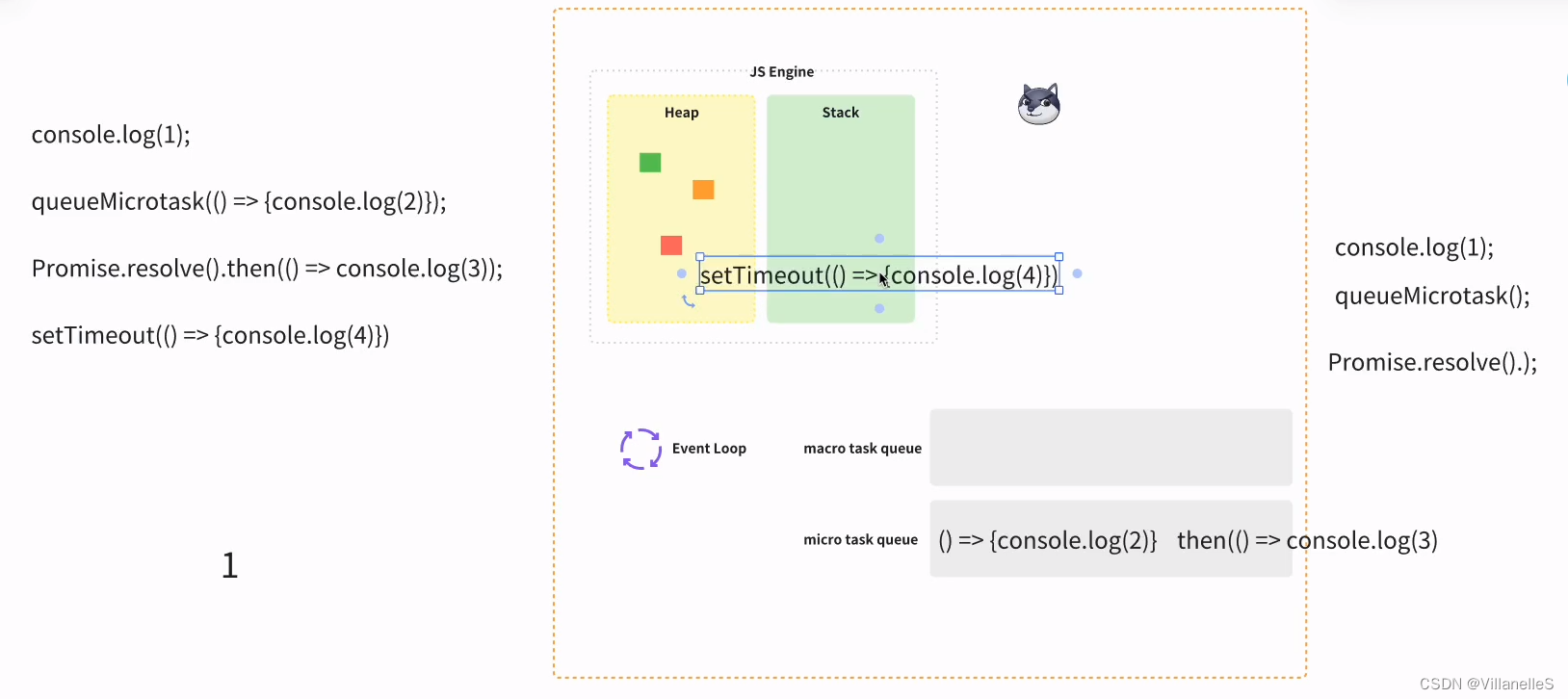
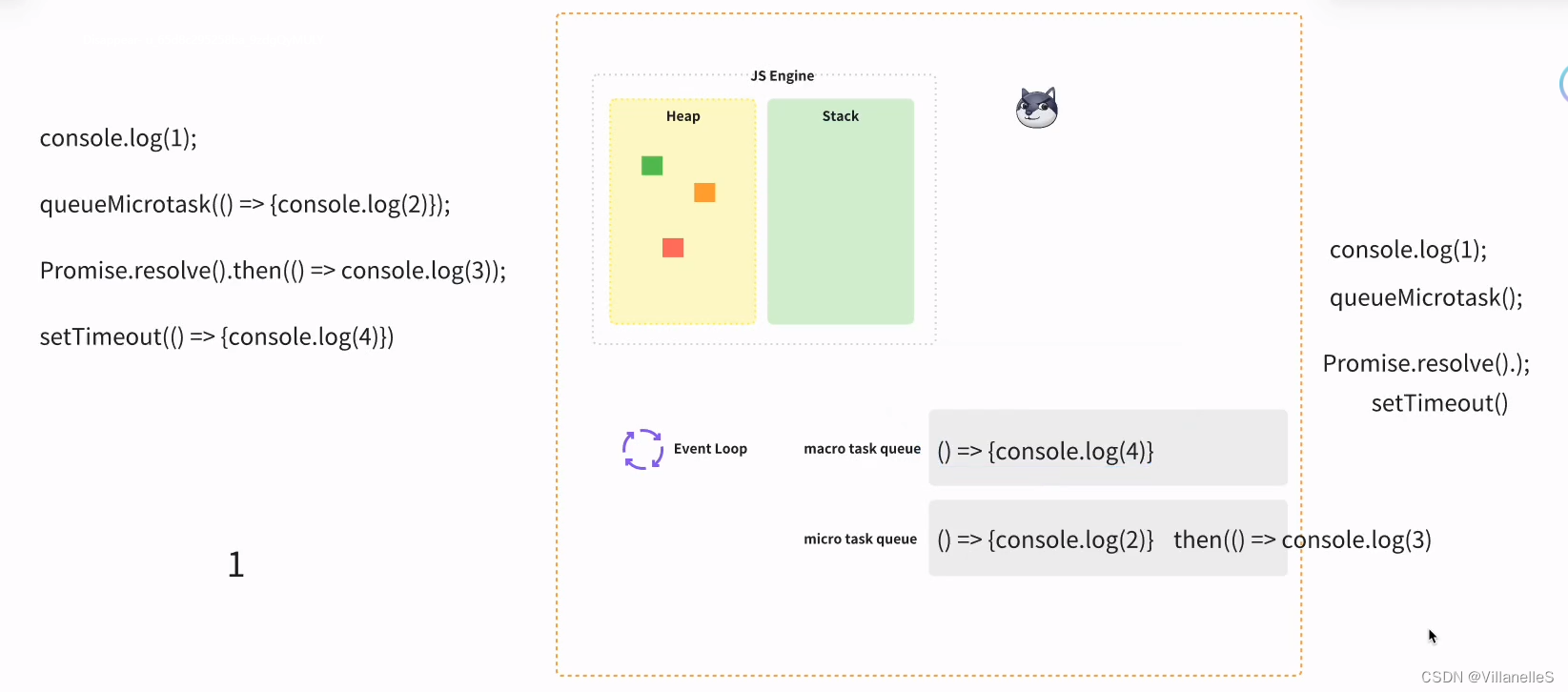
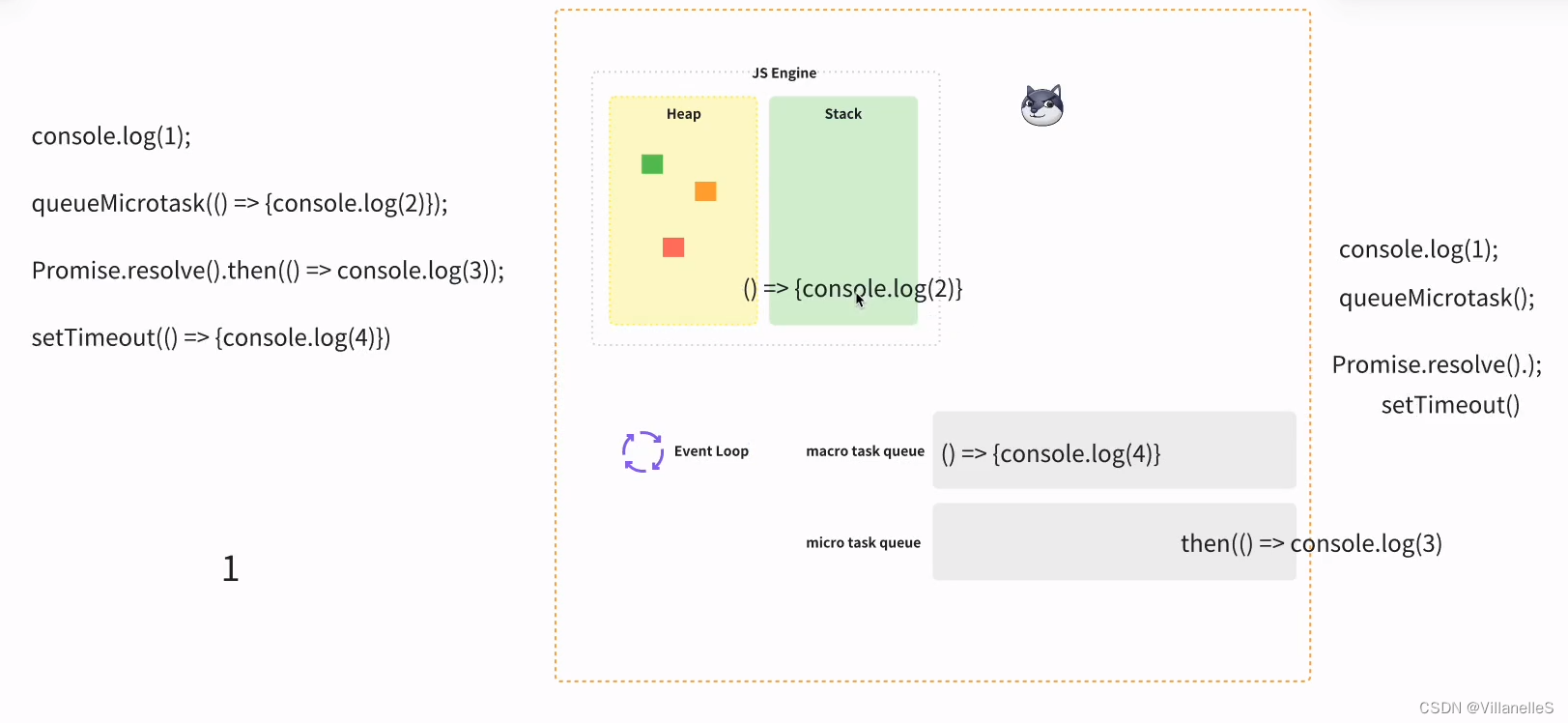
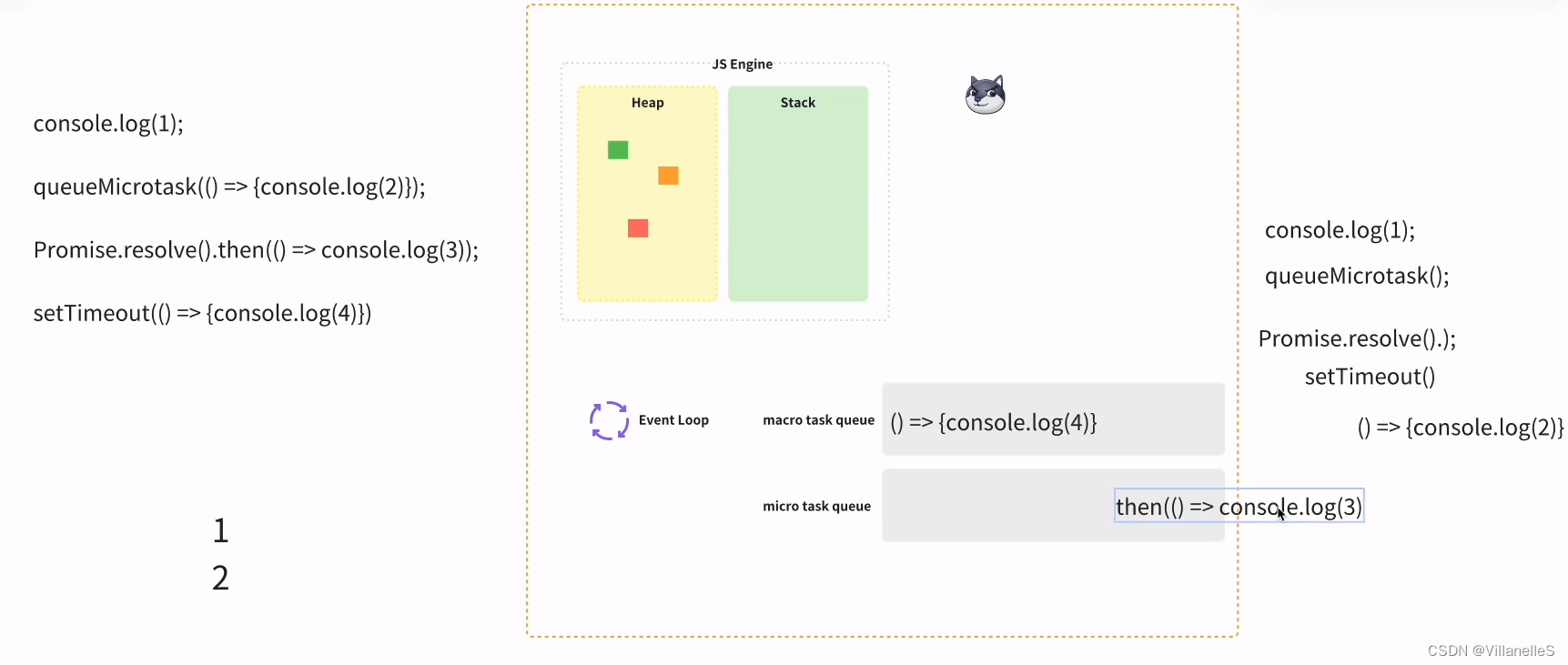
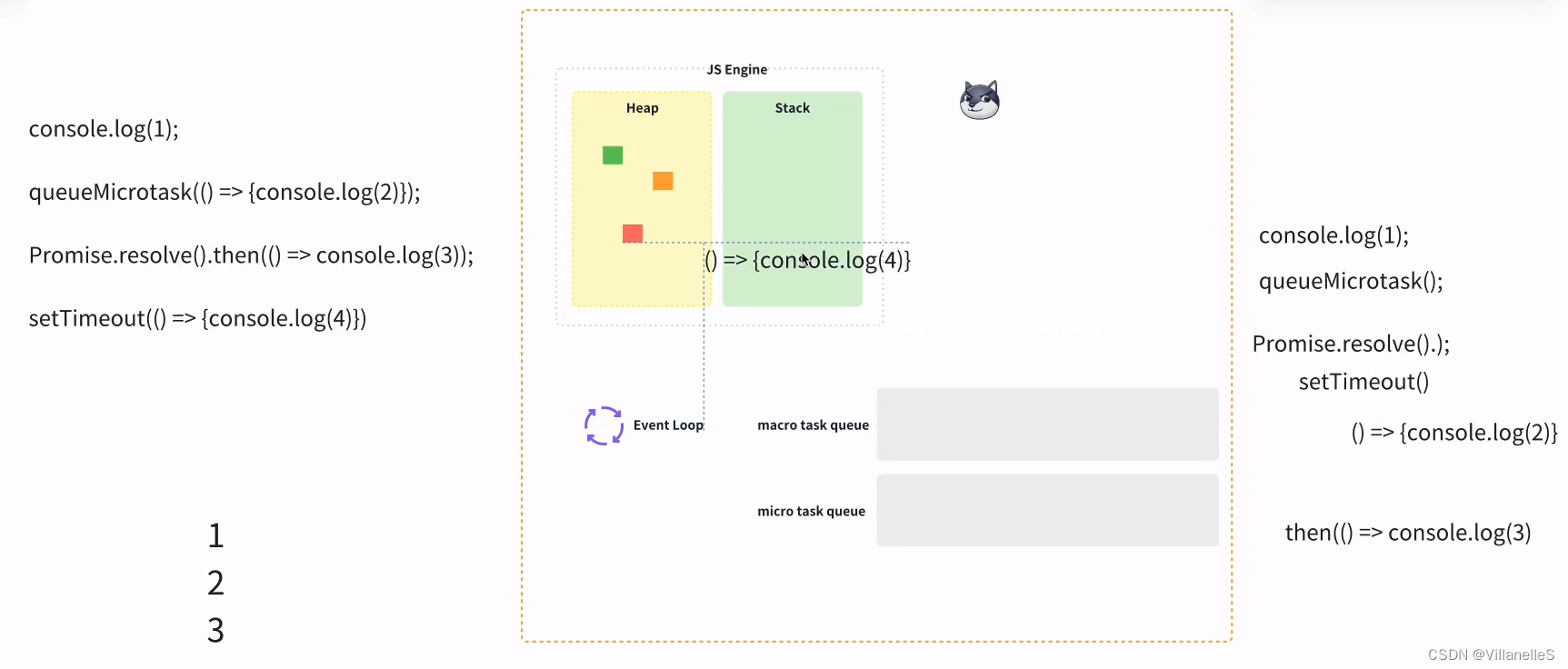
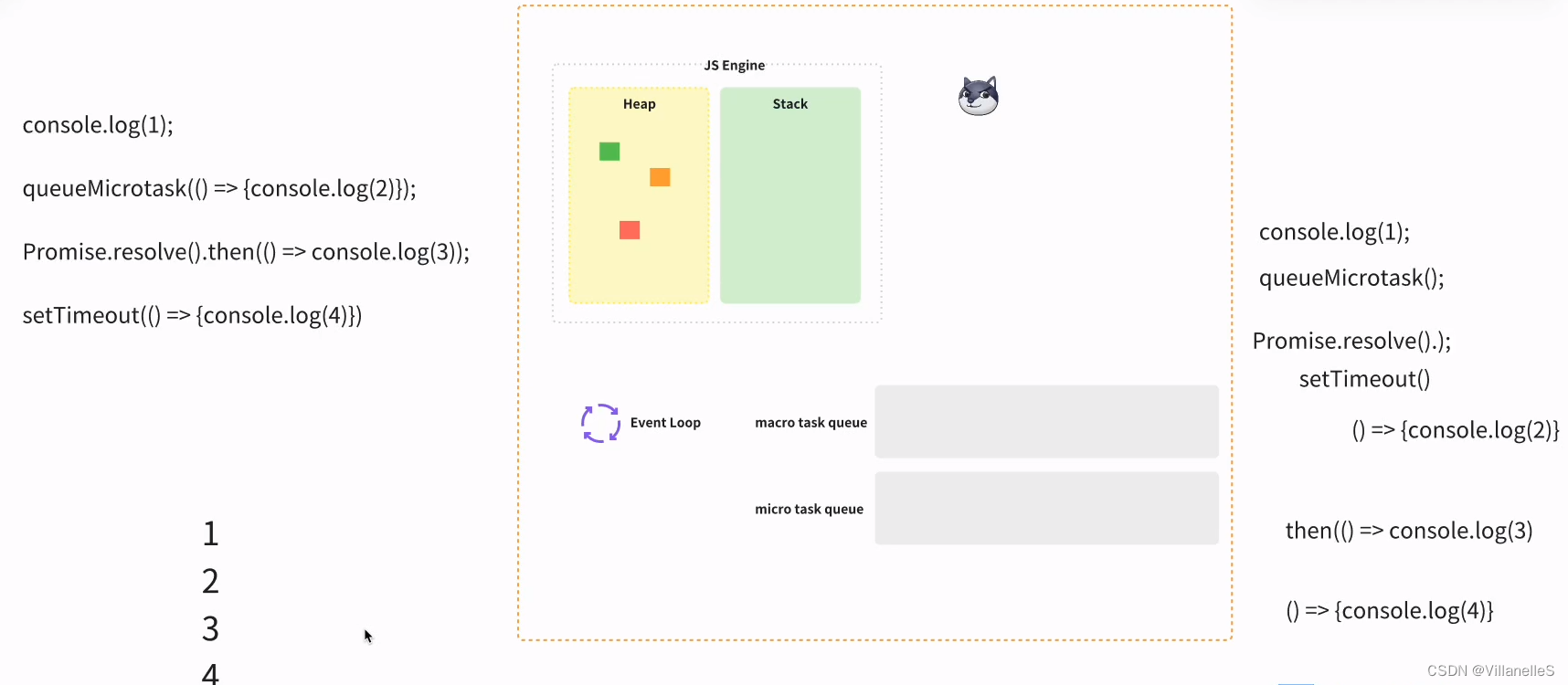
宏任务-微任务-渲染(如果需要渲染,比如到了时间,或有更改 dom),而不是又执行宏任务

案例二
console.log(1);setTimeout(() => console.log(2));Promise.resolve().then(() => console.log(3));Promise.resolve().then(() => setTimeout(() => console.log(4)));Promise.resolve().then(() => console.log(5));setTimeout(() => console.log(6));console.log(7);// 结果
/*
1 7 3 5 2 6 4
*/
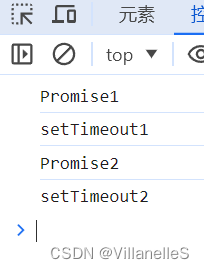
Promise.resolve().then(() => {// 微任务1console.log('Promise1')setTimeout(() => {// 宏任务2console.log('setTimeout2')}, 0)
})
setTimeout(() => {// 宏任务1console.log('setTimeout1')Promise.resolve().then(() => {// 微任务2console.log('Promise2')})
}, 0)// p1 s1 p2 s2
复杂点:
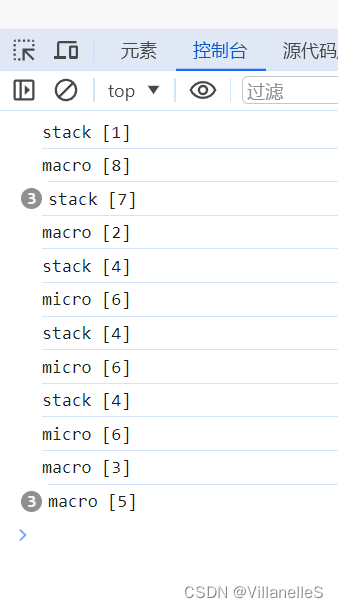
console.log('stack [1]');
setTimeout(() => console.log("macro [2]"), 0);
setTimeout(() => console.log("macro [3]"), 1);const p = Promise.resolve();
for(let i = 0; i < 3; i++) p.then(() => {setTimeout(() => {console.log('stack [4]')setTimeout(() => console.log("macro [5]"), 0);p.then(() => console.log('micro [6]'));}, 0);console.log("stack [7]");
});console.log("macro [8]");// 请说出答案
/* Result:
stack [1]
macro [8]stack [7], stack [7], stack [7]macro [2]
macro [3]stack [4]
micro [6]
stack [4]
micro [6]
stack [4]
micro [6]macro [5], macro [5], macro [5]
--------------------
but in node in versions < 11 (older versions) you will get something differentstack [1]
macro [8]stack [7], stack [7], stack [7]macro [2]
macro [3]stack [4], stack [4], stack [4]
micro [6], micro [6], micro [6]macro [5], macro [5], macro [5]more info: https://blog.insiderattack.net/new-changes-to-timers-and-microtasks-from-node-v11-0-0-and-above-68d112743eb3
*/