书生浦语大模型全链路开源体系
- 课程笔记
- 大模型的发展趋势
- InternLM2的主要亮点
- 模型到应用的典型流程
- 全链路的开源工具
- InternLM2技术报告笔记
- 大型语言模型的发展
- InternEvo
- Model Structure
- 训练数据
课程笔记
第一节课主要对大模型进行介绍,特别是书生浦语大模型的发展历史和目前的全链路开源体系进行总体介绍。
大模型的发展趋势
由专用模型向通用大模型发展。
通用大模型:一个模型应对多种任务,多种模态。一个模型可以应对文本,语音,图像等相关任务。
InternLM2的主要亮点
超长上下文,综合性能全面提升,优秀的对话和创作体验,工具调用能力整体升级,突出的数理能力和实用的数据分析功能
上传表格,可以根据用户的要求,进行数据的分析和画图展示,以及采用机器学习模型进行建模。
模型到应用的典型流程
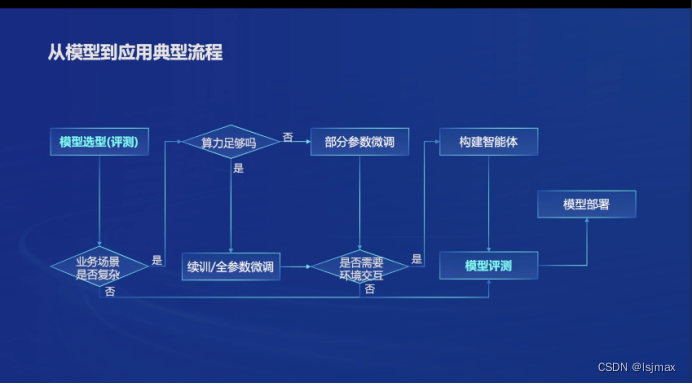
实际从模型到应用中间还间隔比较多步骤,个别步骤还是比较复杂和有难度,为此,书生浦语提供了全链路的开源体系,降低这个过程的难度。
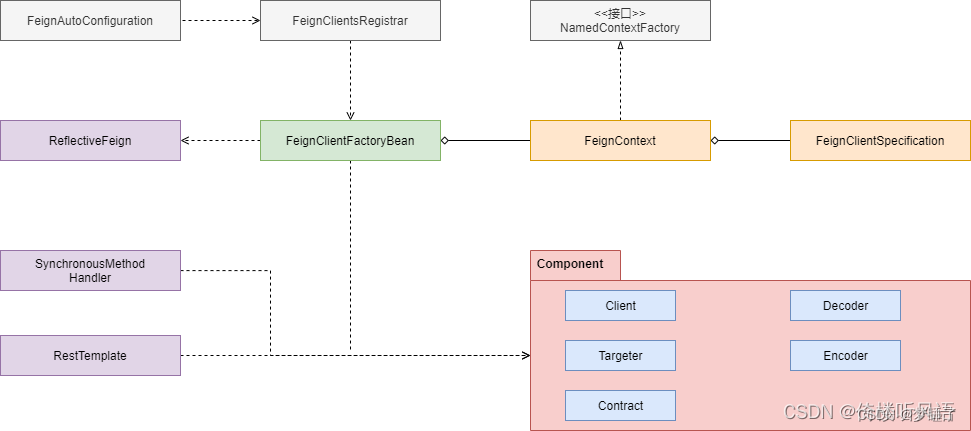
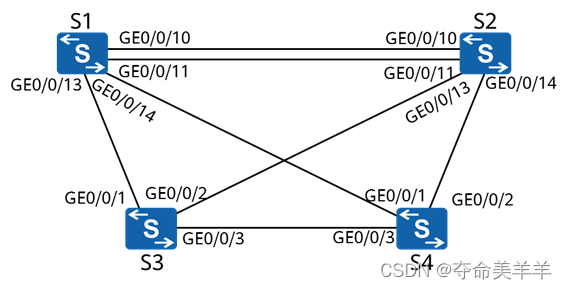
全链路的开源工具
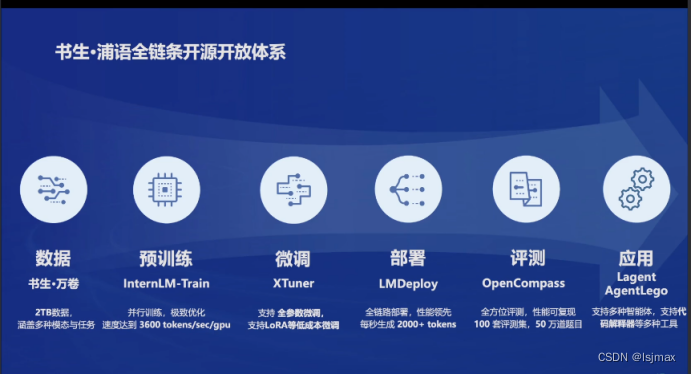
InternLM2技术报告笔记
大型语言模型的发展
预训练、监督微调(SFT)和基于人类反馈的强化学习(RLHF)等阶段
InternEvo
高效的轻量级预训练框架,在减少通信开销,通信预计算的重叠,长序列训练,容错性等方面做了很多功夫进行优化。
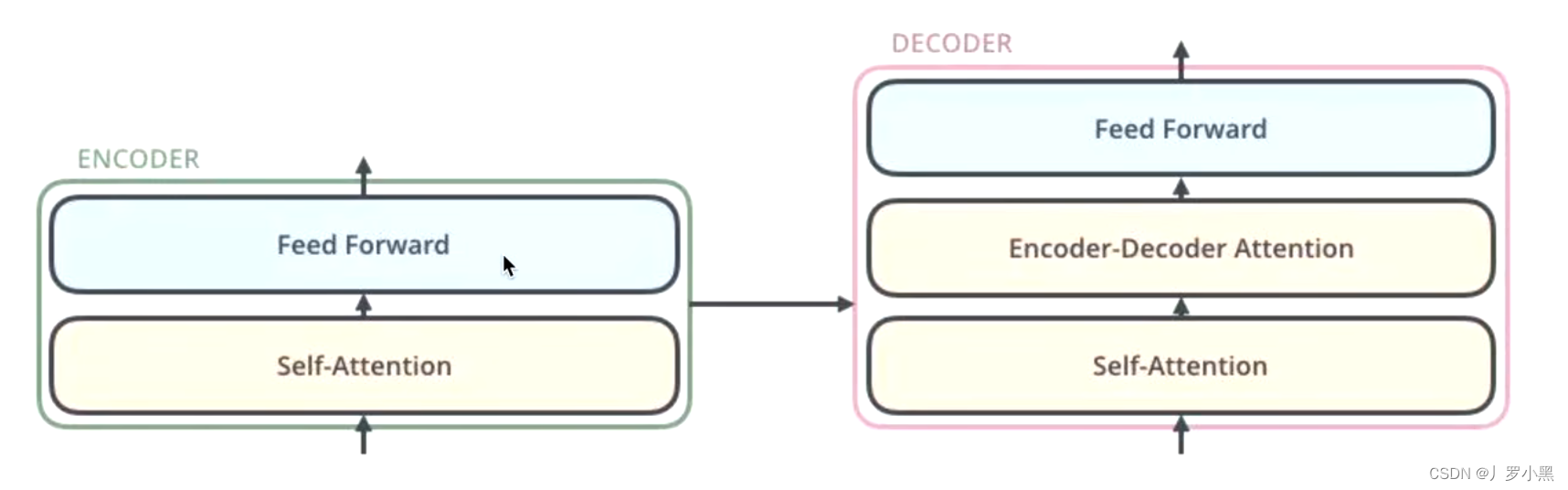
Model Structure
在Transformer架构基础上进行了改进,从而提高了训练效率和性能。
训练数据
据来源分为网页、论文、专利和书籍,并以JSON Lines (jsonl)格式存储。
低质量的数据被排除,尽管它们的比例相对较小,但我们的实证研究发现,移除它们对于优化 模型性能和保证训练稳定性至关重要。