💡💡💡本文独家改进:基于Wasserstein距离的小目标检测评估方法
Wasserstein Distance Loss | 亲测在多个数据集能够实现涨点,对小目标、遮挡物性能提升明显
💡💡💡MS COCO和PASCAL VOC数据集实现涨点
YOLOv9魔术师专栏
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、24年最新顶会改进思路、原创自研paper级创新等
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
✨✨✨ 新开专栏暂定免费限时开放,后续每月调价一次✨✨✨
🚀🚀🚀 本项目持续更新 | 更新完结保底≥80+ ,冲刺100+ 🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉
⭐⭐⭐现更新的所有改进点抢先使用私信我,目前售价68,改进点20+个⭐⭐⭐
⭐⭐⭐专栏涨价趋势 99 ->199->259->299,越早订阅越划算⭐⭐⭐

YOLOv9魔改:注意力机制、检测头、blcok魔改、自研原创等
YOLOv9魔术师
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.YOLOv9原理介绍

论文: 2402.13616.pdf (arxiv.org)
代码:GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information摘要: 如今的深度学习方法重点关注如何设计最合适的目标函数,从而使得模型的预测结果能够最接近真实情况。同时,必须设计一个适当的架构,可以帮助获取足够的信息进行预测。然而,现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。因此,YOLOv9 深入研究了数据通过深度网络传输时数据丢失的重要问题,即信息瓶颈和可逆函数。作者提出了可编程梯度信息(programmable gradient information,PGI)的概念,来应对深度网络实现多个目标所需要的各种变化。PGI 可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。此外,研究者基于梯度路径规划设计了一种新的轻量级网络架构,即通用高效层聚合网络(Generalized Efficient Layer Aggregation Network,GELAN)。该架构证实了 PGI 可以在轻量级模型上取得优异的结果。研究者在基于 MS COCO 数据集的目标检测任务上验证所提出的 GELAN 和 PGI。结果表明,与其他 SOTA 方法相比,GELAN 仅使用传统卷积算子即可实现更好的参数利用率。对于 PGI 而言,它的适用性很强,可用于从轻型到大型的各种模型。我们可以用它来获取完整的信息,从而使从头开始训练的模型能够比使用大型数据集预训练的 SOTA 模型获得更好的结果。对比结果如图1所示。

YOLOv9框架图
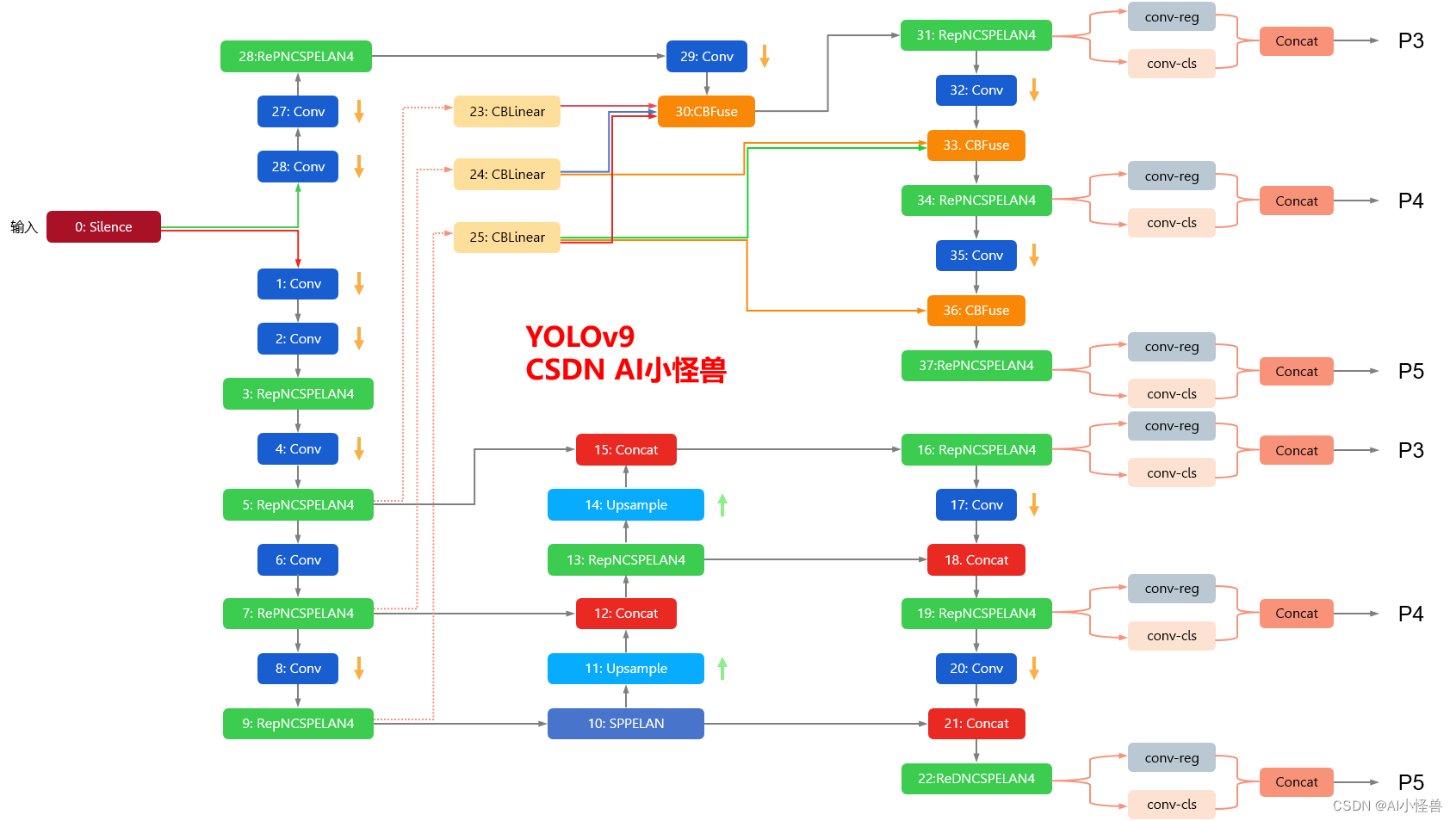
1.1 YOLOv9框架介绍
YOLOv9各个模型介绍

1.Wasserstein Distance Loss介绍
论文名称:《A Normalized Gaussian Wasserstein Distance for Tiny Object Detection》
作者:Jinwang Wang、Chang Xu、Chang Xu、Lei Yu
论文地址:https://arxiv.org/abs/2110.13389
小目标检测是一个非常具有挑战性的问题,因为小目标只包含几个像素大小。作者证明,由于缺乏外观信息,最先进的检测器也不能在小目标上得到令人满意的结果。作者的主要观察结果是,基于IoU (Intersection over Union, IoU)的指标,如IoU本身及其扩展,对小目标的位置偏差非常敏感,在基于Anchor的检测器中使用时,严重降低了检测性能。
为了解决这一问题,本文提出了一种新的基于Wasserstein距离的小目标检测评估方法。具体来说,首先将BBox建模为二维高斯分布,然后提出一种新的度量标准,称为Normalized Wasserstein Distance(NWD),通过它们对应的高斯分布计算它们之间的相似性。提出的NWD度量可以很容易地嵌入到任何基于Anchor的检测器的Assignment、非最大抑制和损失函数中,以取代常用的IoU度量。
1)分析了 IoU 对微小物体位置偏差的敏感性,并提出 NWD 作为衡量两个边界框之间相似性的更好指标;
2)通过将NWD 应用于基于锚的检测器中的标签分配、NMS 和损失函数来设计强大的微小物体检测器;
3)提出的 NWD 可以显着提高流行的基于锚的检测器的 TOD 性能,它在 AI-TOD 数据集上的 Faster R-CNN 上实现了从 11.1% 到 17.6% 的性能提升;
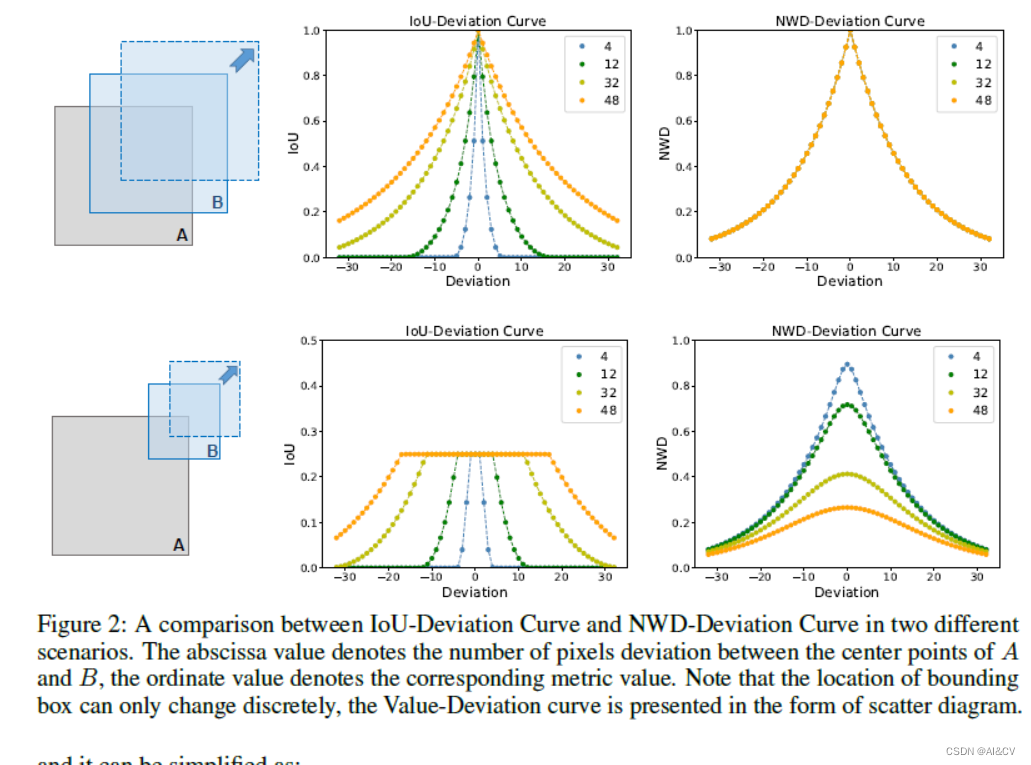
具体来说,对于6×6像素的小目标,轻微的位置偏差会导致明显的IoU下降(从0.53下降到0.06),导致标签分配不准确。然而,对于36×36像素的正常目标,IoU略有变化(从0.90到0.65),位置偏差相同。此外,图2给出了4条不同目标尺度的IoU-Deviation曲线,随着目标尺度的减小,曲线下降速度更快。值得注意的是,IoU的敏感性来自于BBox位置只能离散变化的特殊性。
Wasserstein distance的主要优点是:
- 无论小目标之间有没有重叠都可以度量分布相似性;
- NWD对不同尺度的目标不敏感,更适合测量小目标之间的相似性。
NWD可应用于One-Stage和Multi-Stage Anchor-Based检测器。此外,NWD不仅可以替代标签分配中的IoU,还可以替代非最大抑制中的IoU(NMS)和回归损失函数。在一个新的TOD数据集AI-TOD上的大量实验表明,本文提出的NWD可以持续地提高所有检测器的检测性能。
2.加入到YOLOv9
2.1实现路径为utils/metrics.py
def Wasserstein(box1, box2, xywh=True):box2 = box2.Tif xywh:b1_cx, b1_cy = (box1[0] + box1[2]) / 2, (box1[1] + box1[3]) / 2b1_w, b1_h = box1[2] - box1[0], box1[3] - box1[1]b2_cx, b2_cy = (box2[0] + box2[0]) / 2, (box2[1] + box2[3]) / 2b1_w, b1_h = box2[2] - box2[0], box2[3] - box2[1]else:b1_cx, b1_cy, b1_w, b1_h = box1[0], box1[1], box1[2], box1[3]b2_cx, b2_cy, b2_w, b2_h = box2[0], box2[1], box2[2], box2[3]cx_L2Norm = torch.pow((b1_cx - b2_cx), 2)cy_L2Norm = torch.pow((b1_cy - b2_cy), 2)p1 = cx_L2Norm + cy_L2Normw_FroNorm = torch.pow((b1_w - b2_w)/2, 2)h_FroNorm = torch.pow((b1_h - b2_h)/2, 2)p2 = w_FroNorm + h_FroNormreturn p1 + p22.2 utils/loss_tal_dual.py
训练方法为 train_dual,因此本博客以此展开
1)首先进行注册
from utils.metrics import Wasserstein1)修改class BboxLoss(nn.Module):
⭐⭐⭐现更新的所有改进点抢先使用私信我,目前售价68,改进点20+个⭐⭐⭐
⭐⭐⭐专栏涨价趋势 99 ->199->259->299,越早订阅越划算⭐⭐⭐