AlexNet示例代码与解析
- 1、前言
- 2、模型tips
- 3、模型架构
- 4、模型代码
- backbone
- train
- predict
- 5、模型训练
- 6、导出onnx模型
1、前言
AlexNet由Hinton和他的学生Alex Krizhevsky设计,模型名字来源于论文第一作者的姓名Alex。该模型以很大的优势获得了2012年ISLVRC竞赛的冠军网络,分类准确率由传统的 70%+提升到 80%+,自那年之后,深度学习开始迅速发展。
ImageNet是一个在2009年创建的图像数据集,从2010年开始到2017年举办了七届的ImageNet 挑战赛——ImageNet Large Scale Visual Recognition ChallengeI (LSVRC),在这个挑战赛上诞生了AlexNet、ZFNet、OverFeat、VGG、Inception、ResNet、WideResNet、FractalNet、DenseNet、ResNeXt、DPN、SENet 等经典模型。
摘录:CNN经典网络模型(二):AlexNet简介及代码实现(PyTorch超详细注释版)
2、模型tips
- 使用了多GPU训练,当时的硬件资源有限,一块显卡的显存并不能满足AlexNet的训练,因此作者将其分成了两部分,每一块显卡负责一部分的特征图,最后在全连接层的时候,将每块显卡提取的特征拼接成一个,当时使用了分组卷积来完成这个需求,后来证实了分组卷积能够达到普通卷积的精度。
- 使用了ReLu作为激活函数来训练模型。
- 使用了局部响应归一化来对网络层进行归一化,目的是抑制反馈较小的神经元的值,增大反馈明显的神经元的值。(在VGG的论文中指出,LRN并灭有什么明显的效果,新的深度学习网络中已使用其他归一化方法来代替LRN)。
- 使用了覆盖池化,覆盖池化的意思即当池化的步长小于池化核时,相邻的池化核之间会互相重叠。论文中指出这种池化方式可以缓解过拟合。
- 使用了dropout来缓解过拟合。dropout即在训练的过程中随机的让一些隐层中的节点置为0(在本轮训练中不参与前向传播与反向传播),因此,在每一轮训练的时候,模型都会随机的得到一个与上一论训练中不太一样的网络架构,这样的做法可以降低神经元之间的依赖性(耦合性),使每个神经元能够在一次次的训练中学习到更为可靠的特征。尽管dropout会降低训练收敛的速度,但是可以有效的缓解过拟合程度。
3、模型架构
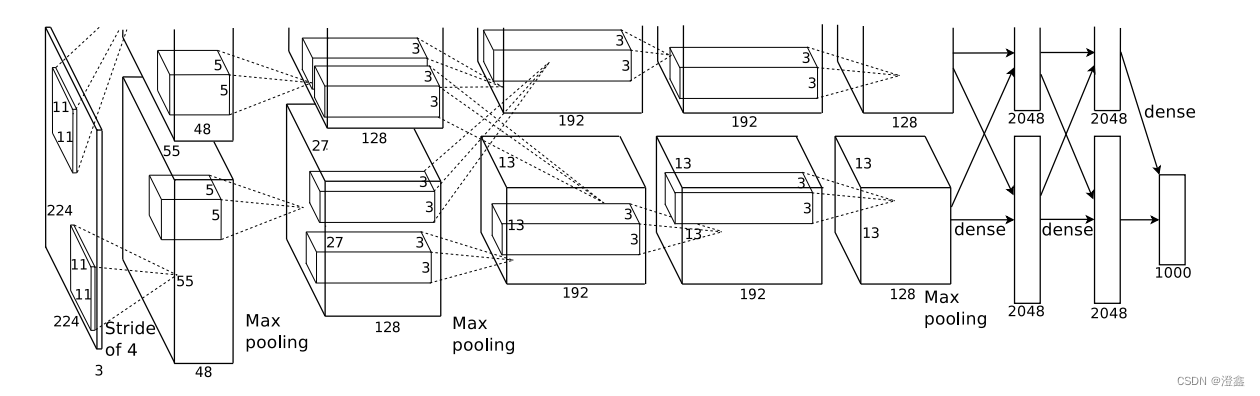
4、模型代码
我们将使用开源的深度学习框架PyTorch来搭建并训练我们的模型
backbone
import torch
import torchvision
from torch import nnclass AlexNet(nn.Module):def __init__(self):super(AlexNet, self).__init__()#特征提取层self.CONV = nn.Sequential(nn.Conv2d(3, 96, 11, 4, 2), # 1 * 224 * 224 * 3 ---> 1 * 55 * 55 * 96nn.ReLU(),nn.MaxPool2d(3, 2), # 1 * 55 * 55 * 96 ---> 1 * 27 * 27 * 96nn.Conv2d(96, 256, 5, 1, 2), # 1 * 27 * 27 * 96 ---> 1 * 27 * 27 * 256nn.ReLU(),nn.MaxPool2d(3, 2), # 1 * 27 * 27 * 256 ---> 1 * 13 * 13 * 256nn.Conv2d(256, 384, 3, 1, 1), # 1 * 13 * 13 * 256 ---> 1 * 13 * 13 * 384nn.ReLU(),nn.Conv2d(384, 384, 3, 1, 1), # 1 * 13 * 13 * 384---> 1 * 13 * 13 * 384nn.ReLU(),nn.Conv2d(384, 256, 3, 1, 1), # 1 * 13 * 13 * 384 ---> 1 * 13 * 13 * 256nn.ReLU(),nn.MaxPool2d(3, 2), # 1 * 13 * 13 * 256 ---> 1 * 6 * 6 * 256)#将多维的张量进行平坦化处理#默认从第一个维度到最后一个维度拼接self.flatten = nn.Flatten() # 1 * 6 * 6 * 256 ---> 1 * 9216#全连接层self.FC = nn.Sequential(# 全连接层1nn.Linear(in_features=6 * 6 * 256, out_features=4096),nn.ReLU(),nn.Dropout(0.5),# 全连接层2nn.Linear(in_features=4096, out_features=4096),nn.ReLU(),nn.Dropout(0.5),# 全连接层3nn.Linear(in_features=4096, out_features=1000),nn.Dropout(0.5),# 全连接层4 分类层,几分类就是降维到几nn.Linear(in_features=1000, out_features=10),)def forward(self, x):x = self.CONV(x)x = self.flatten(x)x = self.FC(x)return xif __name__ == "__main__":x = torch.randn([1,3,224,224])model = AlexNet()y = model(x)print(x)
注意这里的输入是224 * 224的宽高,有的输入是227 * 227的宽高,可以根据不同的输入来计算对应的卷积与池化的参数,对最终的结果几乎没有影响。
搭建模型时用到的torch库的api:
nn.Sequential(): 可以允许将整个容器视为单个模块(即相当于把多个模块封装成一个模块),forward()方法接收输入之后,nn.Sequential()按照内部模块的顺序自动依次计算并输出结果。
nn.Conv2d():in_channel,out_channel,kernel_size,stride,padding。
nn.ReLu():ReLu激活函数。
nn.MaxPool2dkernel_size,stride。
nn.Flatten():将张量扁平化处理,默认从第一个维度到最后一个维度的所有信息进行一维处理。start_dim=1,end_dim=-1。
nn.Linear():线性层,或者叫全连接层。in_features,out_features,is_bias(bool)。
nn.Dropout():dropout方法,随机失活神经元节点。p(失活节点的占比),in_place(是否改变输入数据),dropout只在训练阶段开启,在推理阶段不开启。
train
import torch
import torch.nn as nn
from AlexNet import AlexNet
from torch.optim import lr_scheduler
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import os
import matplotlib.pyplot as plt# 解决中文显示问题
# 运行配置参数中的字体(font)为黑体(SimHei)
plt.rcParams['font.sans-serif'] = ['simHei']
# 运行配置参数总的轴(axes)正常显示正负号(minus)
plt.rcParams['axes.unicode_minus'] = Falsedevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')ROOT_TRAIN = 'dataset'
ROOT_TEST = 'dataset'normalize = transforms.Normalize([0.5, 0.5, 0.5],[0.5, 0.5, 0.5]
)train_transform = transforms.Compose([transforms.Resize((224, 224)),#以0.5的概率来竖直翻转给定的PIL图像transforms.RandomVerticalFlip(),transforms.ToTensor(),normalize,
])val_transform = transforms.Compose([transforms.Resize((224,224)),transforms.ToTensor(),normalize,
])#加载训练数据集
train_datasets = datasets.ImageFolder(ROOT_TRAIN, transform=train_transform)
train_dataloader = DataLoader(train_datasets, batch_size=32, shuffle=True)val_datasets = datasets.ImageFolder(ROOT_TEST, transform=val_transform)
val_dataloader = DataLoader(val_datasets, batch_size=32, shuffle=True)#实例化模型对象
model = AlexNet().to(device)#定义交叉熵损失函数
loss_fn = nn.CrossEntropyLoss()#定义优化器
optimizer_ = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)#学习率每十轮降低为之前的0.5
lr_scheduler = lr_scheduler.StepLR(optimizer_, step_size=10, gamma=0.5)#定义训练函数
def train(dataloader, model, loss_fn, optimizer):loss, current, n = 0.0, 0.0, 0.0#batch为索引, x和y分别是图片和类别for batch, (x, y) in enumerate(dataloader):#前向传播image, y = x.to(device), y.to(device)output = model(image)curr_loss = loss_fn(output, y)_, pred = torch.max(output, dim=1)#计算每个批次的准确率curr_acc = torch.sum(y == pred)/output.shape[0]#反向传播#清空之前的梯度optimizer.zero_grad()#计算当前的梯度curr_loss.backward()#根据梯度更新网络参数optimizer.step()#损失叠加loss += curr_loss.item()#精度叠加current += curr_acc.item()n = n + 1#训练的平均损失和平均精度train_loss = loss / ntrain_acc = current / nprint('train loss = ' + str(train_loss))print('train accuracy = ' + str(train_acc))return train_loss, train_acc#定义验证函数
def val(dataloader, model, loss_fn):loss, current, n = 0.0, 0.0, 0.0#eval():如果模型中存在BN和dropout则不启用,以防改变权值model.eval()with torch.no_grad():for batch, (x, y) in enumerate(dataloader):#前向传播image, y = x.to(device), y.to(device)output = model(image)curr_loss = loss_fn(output, y)_, pred = torch.max(output, dim=1)curr_acc = torch.sum(y == pred) / output.shape[0]loss += curr_loss.item()current += curr_acc.item()n = n + 1val_loss = loss / nval_acc = current / nprint('val loss = ' + str(val_loss))print('val accuracy = ' + str(val_acc))return val_loss, val_acc#定义画图函数
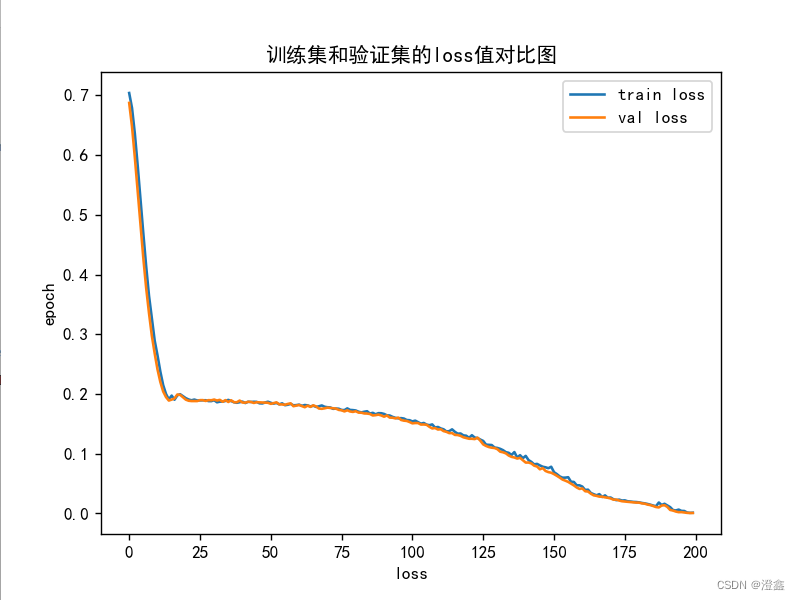
def plot_loss(train_loss, val_loss):plt.plot(train_loss, label='train loss')plt.plot(val_loss, label='val loss')plt.legend(loc='best')plt.xlabel('loss')plt.ylabel('epoch')plt.title("训练集和验证集的loss值对比图")plt.show()def plot_acc(train_acc, val_acc):plt.plot(train_acc, label='train acc')plt.plot(val_acc, label='val acc')plt.legend(loc='best')plt.xlabel('acc')plt.ylabel('epoch')plt.title("训练集和验证集的acc值对比图")plt.show()#开始训练
loss_train = []
acc_train = []
loss_val = []
acc_val = []#训练次数
epoch = 200
#用于判断什么时候保存模型
min_acc = 0
for t in range(epoch):# lr_scheduler.step()print(f"epoch{t+1}-------------------------------")#训练模型train_loss, train_acc = train(train_dataloader, model, loss_fn, optimizer_)#验证模型val_loss, val_acc = val(val_dataloader, model, loss_fn)print("\n")loss_train.append(train_loss)acc_train.append(train_acc)loss_val.append(val_loss)acc_val.append(val_acc)folder = 'save_model'# 保存最好的模型权重if val_acc > min_acc:if not os.path.exists(folder):os.mkdir(folder)min_acc = val_acctorch.save(model.state_dict(), f"{folder}/model_best.pth")if t == epoch - 1:torch.save(model.state_dict(), f"{folder}/model_last.pth")print("=============训练完毕==============\n" + f"best pth saved as {folder}/model_best.pth\n" + f"last pth saved as {folder}/model_last.pth\n")plot_loss(loss_train, loss_val)
plot_acc(acc_train, acc_val)
predict
import torch
from AlexNet import AlexNet
from torch.autograd import Variable
from torchvision import transforms
from torchvision.transforms import ToPILImage
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader# ROOT_TRAIN = 'D:/pycharm/AlexNet/data/train'
ROOT_TEST = 'dataset'# 将图像的像素值归一化到[-1,1]之间
normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])val_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),normalize
])# 加载训练数据集
val_dataset = ImageFolder(ROOT_TEST, transform=val_transform)# 如果有NVIDA显卡,转到GPU训练,否则用CPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'# 模型实例化,将模型转到device
model = AlexNet().to(device)# 加载train.py里训练好的模型
model.load_state_dict(torch.load(r'save_model/model_best.pth'))# 结果类型
classes = ["cat","dog"
]# 把Tensor转化为图片,方便可视化
show = ToPILImage()# 进入验证阶段
model.eval()
for i in range(10):x, y = val_dataset[i][0], val_dataset[i][1]# show():显示图片show(x).show()# torch.unsqueeze(input, dim),input(Tensor):输入张量,dim (int):插入维度的索引,最终扩展张量维度为4维x = Variable(torch.unsqueeze(x, dim=0).float(), requires_grad=False).to(device)with torch.no_grad():pred = model(x)# argmax(input):返回指定维度最大值的序号# 得到预测类别中最高的那一类,再把最高的这一类对应classes中的那一类predicted, actual = classes[torch.argmax(pred[0])], classes[y]# 输出预测值与真实值print(f'predicted:"{predicted}", actual:"{actual}"')5、模型训练
猫狗训练集训练二分类模型,生成pth模型。
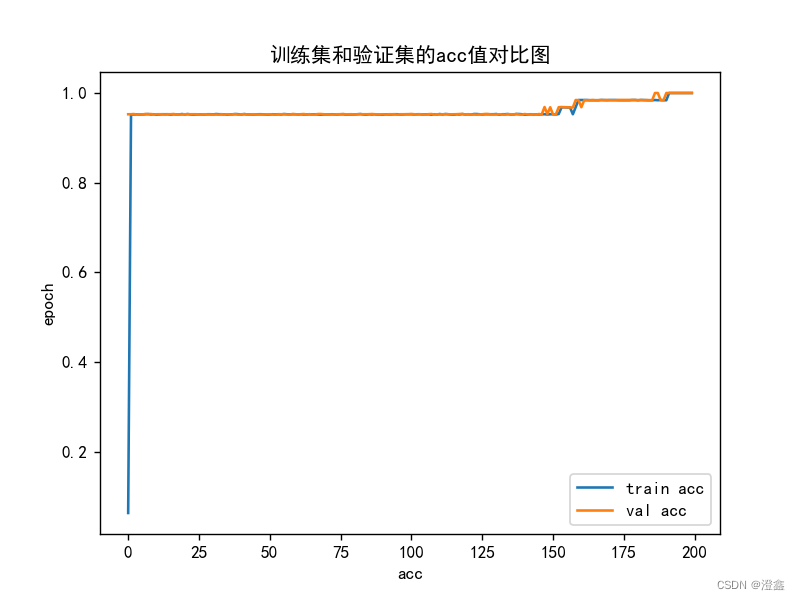
6、导出onnx模型
from AlexNet import AlexNet
import torch
import onnx
import osdef export_onnx(pt_path:str, onnx_path:str):model = AlexNet()model.load_state_dict(torch.load(pt_path))dummy_inputs = {"input": torch.randn(1, 3, 224, 224, dtype=torch.float),}output_names = {"classes"}if not os.path.exists(os.path.dirname(onnx_path)):os.makedirs(os.path.dirname(onnx_path))with open(onnx_path, "wb") as f:print(f"Exporting onnx model to {onnx_path}...")torch.onnx.export(model,tuple(dummy_inputs.values()),f,export_params=True,verbose=False,opset_version=17,do_constant_folding=True,input_names=list(dummy_inputs.keys()),output_names=output_names,# dynamic_axes=dynamic_axes,)if __name__ == "__main__":pt_path = "save_model/model_best.pth"onnx_path = "save_model/model_best.onnx"export_onnx(pt_path, onnx_path)
onnx模型可视化架构图:

![每日一题 --- 链表相交[力扣][Go]](https://img-blog.csdnimg.cn/img_convert/d2e08e393f3f732a79a950c1e70b27d4.png)