文章目录
- MySQL高阶SQL语句(二)
- 一、MySQL常用查询
- 1、子查询
- 1.1 语法
- 1.1.1 结合select语句查询
- 1.1.2 结合insert语句查询
- 1.1.3 结合update语句查询
- 1.1.4 结合delete语句查询
- 1.1.5 在in前面添加not
- 1.1.6 exists关键字
- 2、别名
- 二、MySQL视图
- 1、视图介绍
- 1.1 视图特点
- 1.2 作用范围
- 1.3 功能
- 2、视图和表的区别和联系
- 2.1 区别
- 2.2 联系
- 3、创建视图
- 3.1 单表创建
- 3.2 多表创建视图
- 3.3 修改表的数据
- 3.4 删除视图
- 三、NULL 值
- null值与空值的区别
- 四、连接查询
- 1、内连接
- 1.1 语法
- 1.2 内连接查询
- 2、左连接
- 左连接查询
- 3、右连接
- 右连接查询
- 4、内连接、左连接、右连接区别
- 五、存储过程
- 1、存储过程的介绍
- 2、存储过程的优点
- 3、创建存储过程
- 4、调用存储过程
- 5、查看存储过程
- 6、存储过程的参数
- 7、修改存储过程
- 8、删除存储过程
MySQL高阶SQL语句(二)
一、MySQL常用查询
1、子查询
- 子查询也被称作内查询或者嵌套查询,是指在一个查询语句里面还嵌套着另一个查询语句。
- 子查询语句是先于主查询语句被执行的,其结果作为外层的条件返回给主查询进行下一 步的查询过滤。
- 子语句可以与主语句所查询的表相同,也可以是不同表
- 子语句中的sql语句是为了最后过滤出一个结果集,用于主语句的判断条件
- in: 将主表和子表关联/连接的语法
- 子查询不仅可以在 select 语句中使用,在 insert、update、delete 中也同样适用。在嵌套的时候,子查询内部还可以再次嵌套新的子查询,也就是说可以多层嵌套。
1.1 语法
[表达式] IN [子查询]
- IN 用来判断某个值是否在给定的结果集中,通常结合子查询来使用
[表达式] [NOT] IN [子查询]
- 当表达式与子查询返回的结果集中的某个值相等时,返回 true,否则返回 false。 若启用了 NOT 关键字,则返回值相反。需要注意的是,子查询只能返回一列数据,如果需求比较复杂,一列解决不了问题,可以使用多层嵌套的方式来应对。 多数情况下,子查询都是与 select 语句一起使用的
1.1.1 结合select语句查询
use xi;
#切换数据库show tables;
#查询库中表的信息create table yy02(id int);
#创建表insert into yy02 values(1),(2),(3);
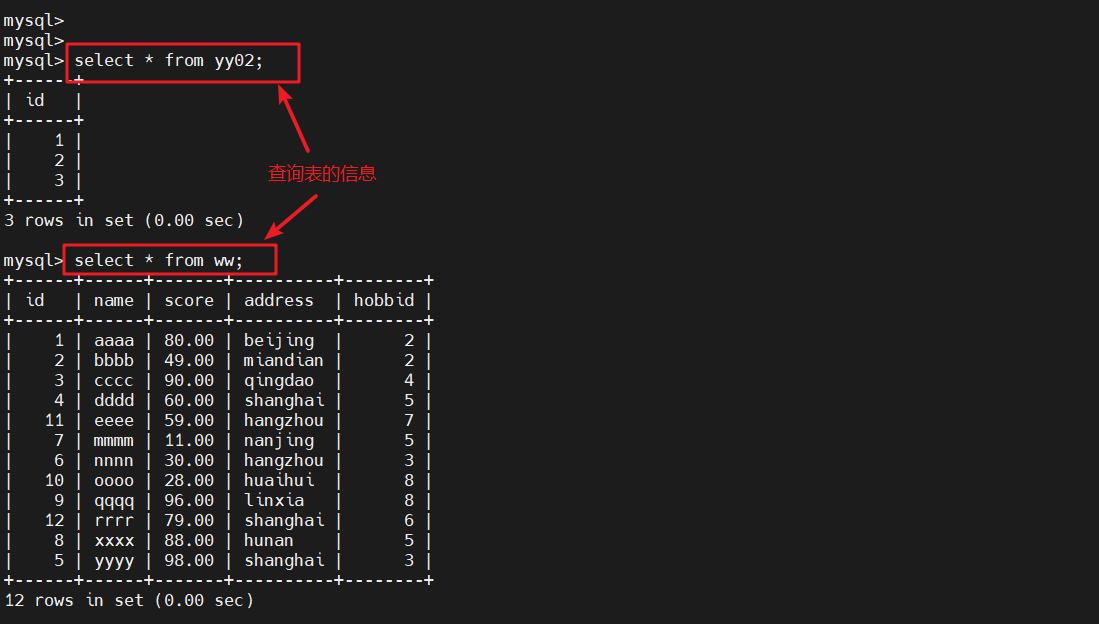
#表中插入数据select * from yy02;
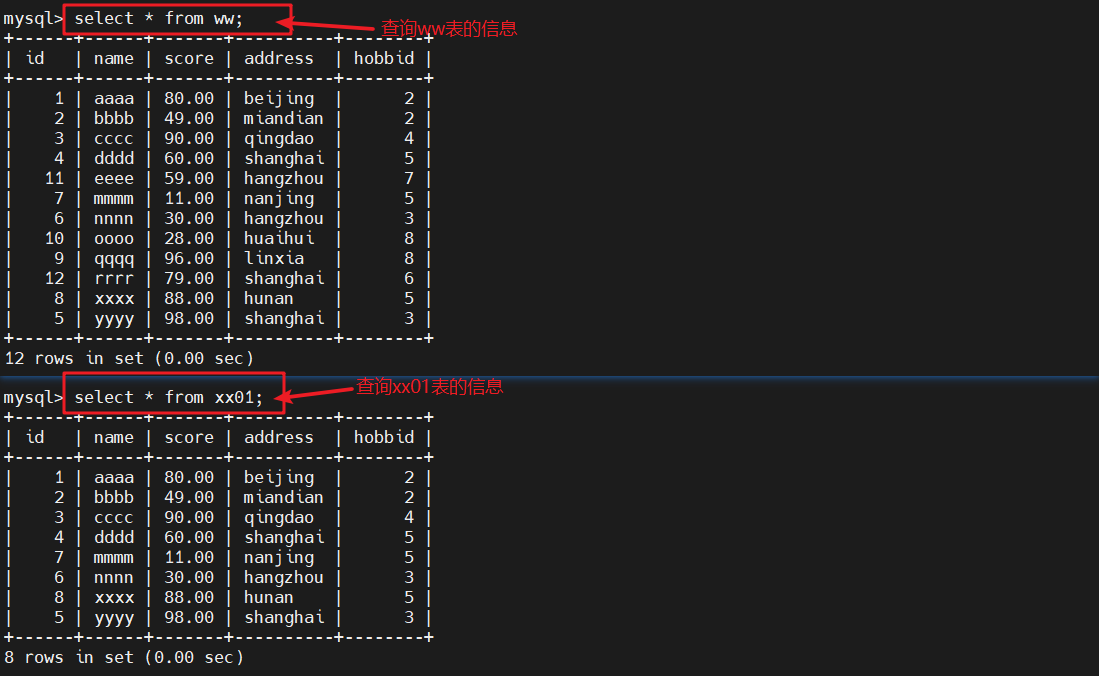
#查询表的信息select * from ww;
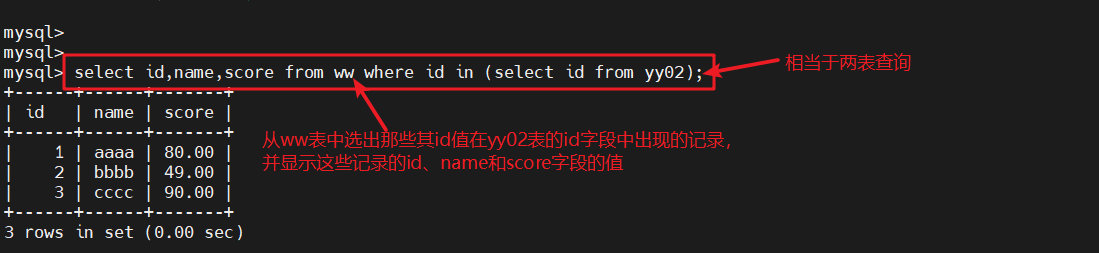
#查询表的信息select id,name,score from ww where id in (select id from yy02);
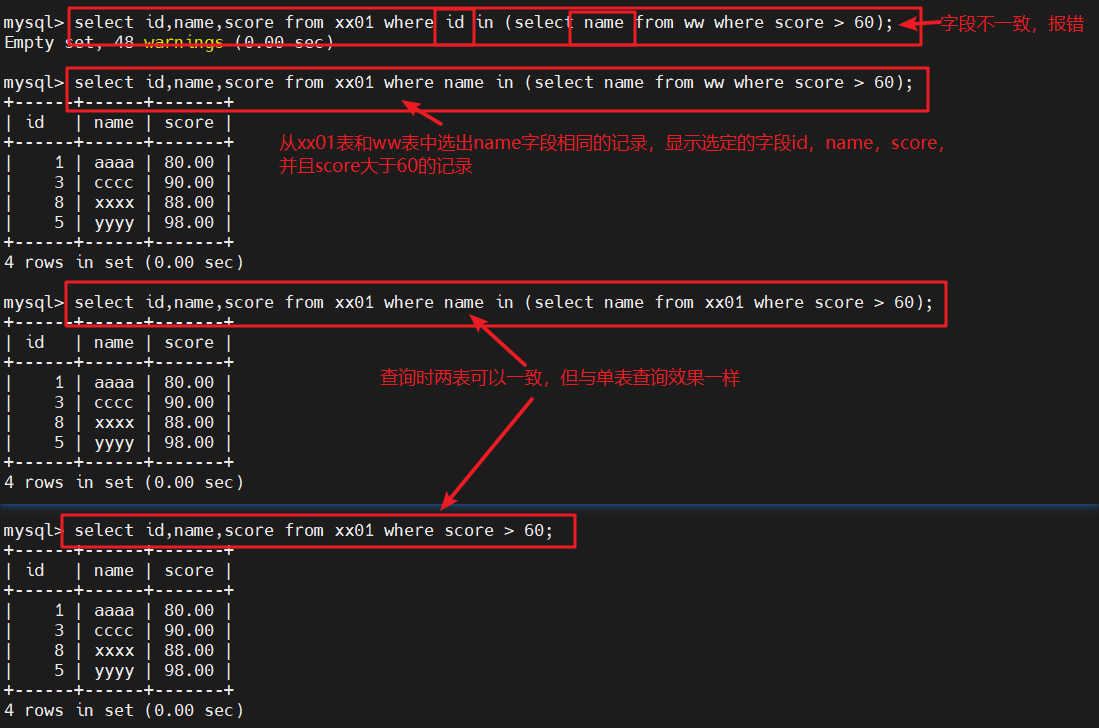
#从ww表中选出那些其id值在yy02表的id字段中出现的记录,并显示这些记录的id、name和score字段的值select id,name,score from xx01 where id in (select name from ww where score > 60);
#where语句指定的字段(id)与子查询中查询的字段(name)不一致,会报错,显示结果为空select id,name,score from xx01 where name in (select name from ww where score > 60);
#从xx01表和ww表中选出name字段相同的记录,并显示选定id,name,score字段中score大于60的记录select id,name,score from xx01 where name in (select name from xx01 where score > 60);
#同表也可以查询,但是跟单表查询结果一致
select id,name,score from xx01 where score > 60;

1.1.2 结合insert语句查询
- 子查询还可以用在 insert 语句中。子查询的结果集可以通过 insert 语句插入到其他的表中
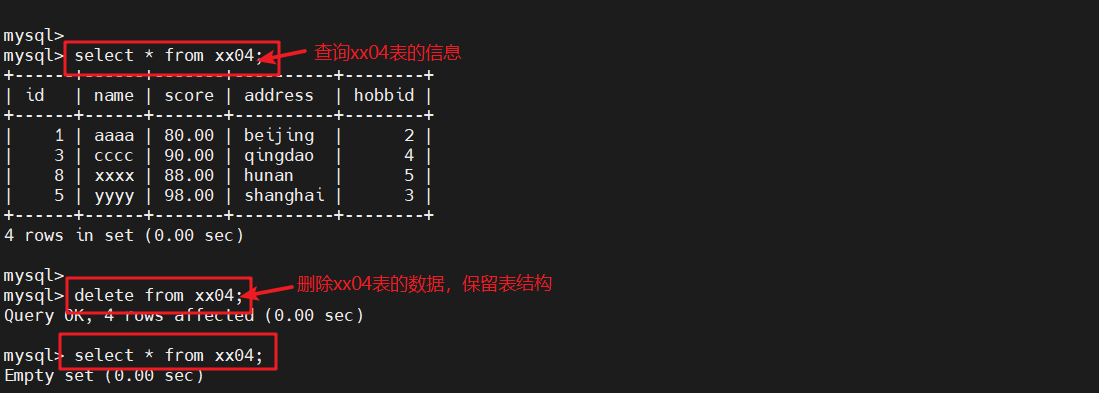
##将xx01表与ww表的相同记录行插入到xx04表中select * from xx04;
#查询xx04表信息delete from xx04;
#删除xx04表中数据,保留表结构insert into xx04 select * from xx01 where id in (select id from ww);
#查询xx01表和ww表中相同的数据,并将数据结果插入到xx04表中select * from xx04;
#查询xx04表信息
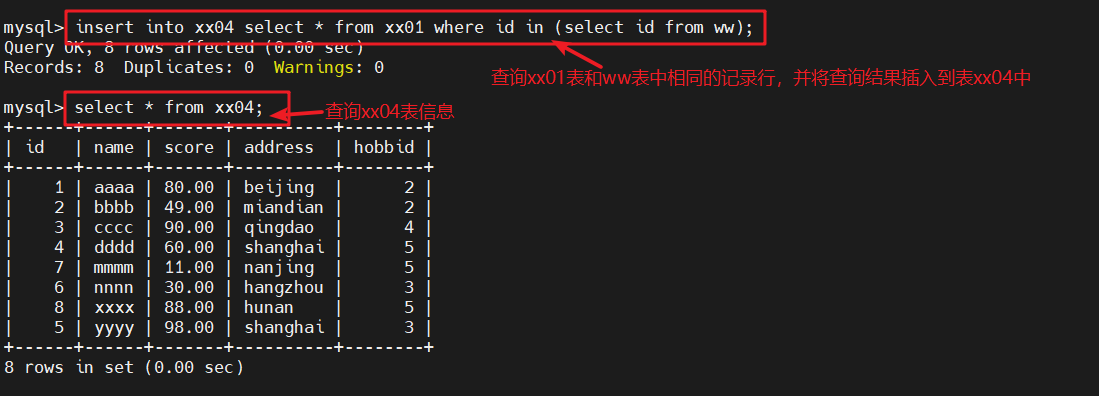
1.1.3 结合update语句查询
- update 语句也可以使用子查询。update 内的子查询,在 set 更新内容时,可以是单独的一列,也可以是多列
##将xx04表中id=6记录行的score修改为60update xx04 set score=68 where id in (select id from xx04 where id=6);
#不能对同一个表xx04既查询又修改,会报错update xx04 set score=68 where id in (select id from ww where id=6);
#查询ww表中id=6的记录行,将xx04表中此记录行的score修改为68select * from xx04;
#查看修改完后xx04表的信息
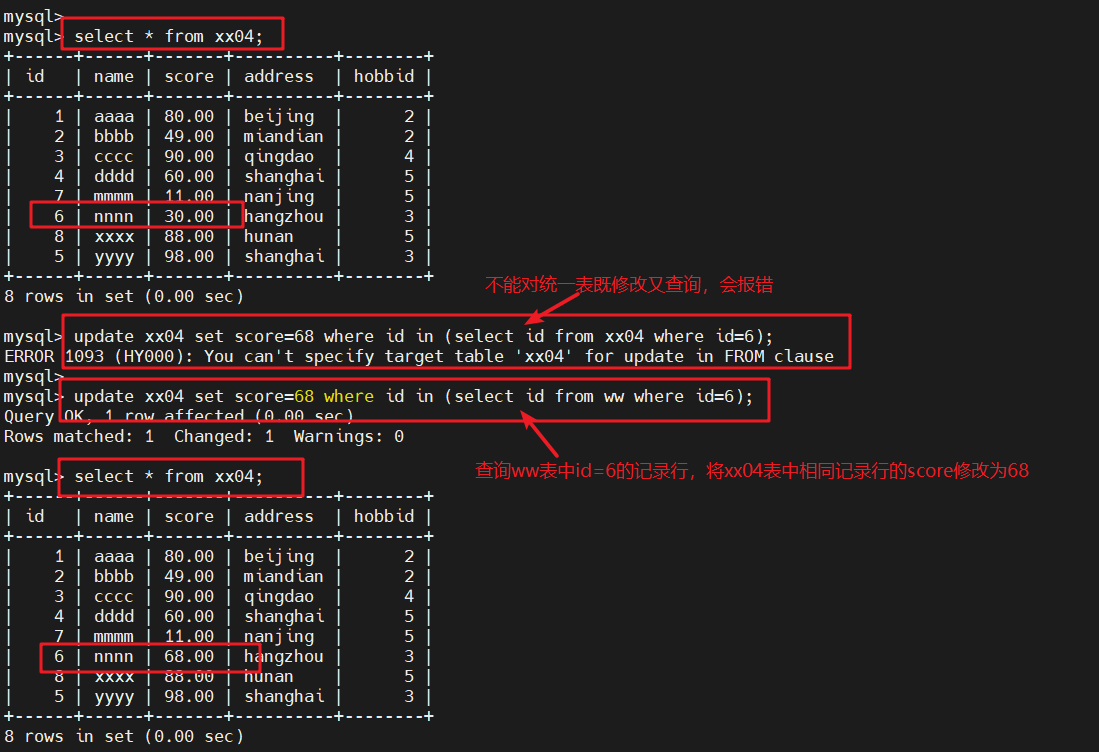
1.1.4 结合delete语句查询
- delete也适用于子查询
##删除xx04表中score小于60的记录行select * from xx04 where score < 60;
#查询xx04表中score小于60的数据delete from xx04 where id in (select id from xx04 where score < 60);
#不能对同一个表格既查询又删除,会报错delete from xx04 where id in (select id from ww where score < 60);
#查询ww表中score小于60的记录行,与xx04表对比,将xx04表中相同的记录行删除select * from xx04;
#查询xx04biao的信息
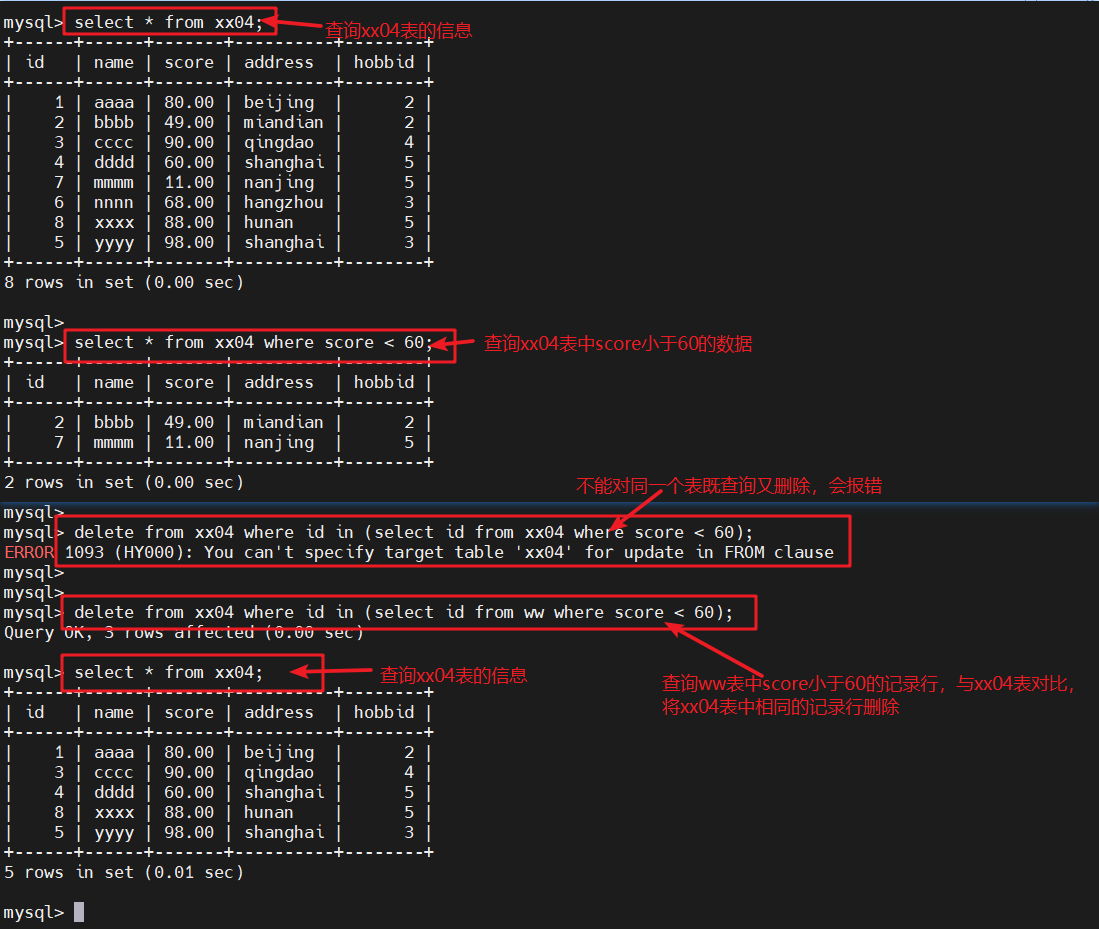
1.1.5 在in前面添加not
- not in与in作用相反,表示否定(即不在子查询的结果集里面)
select * from xx04;
#查询xx04表的信息delete from xx04 where id not in (select id from ww where score > 50);
#查询ww表中score小于50的记录行,并与xx04表做对比,将xx04表中相同的记录行删除select * from xx04;
#查询xx04表的信息
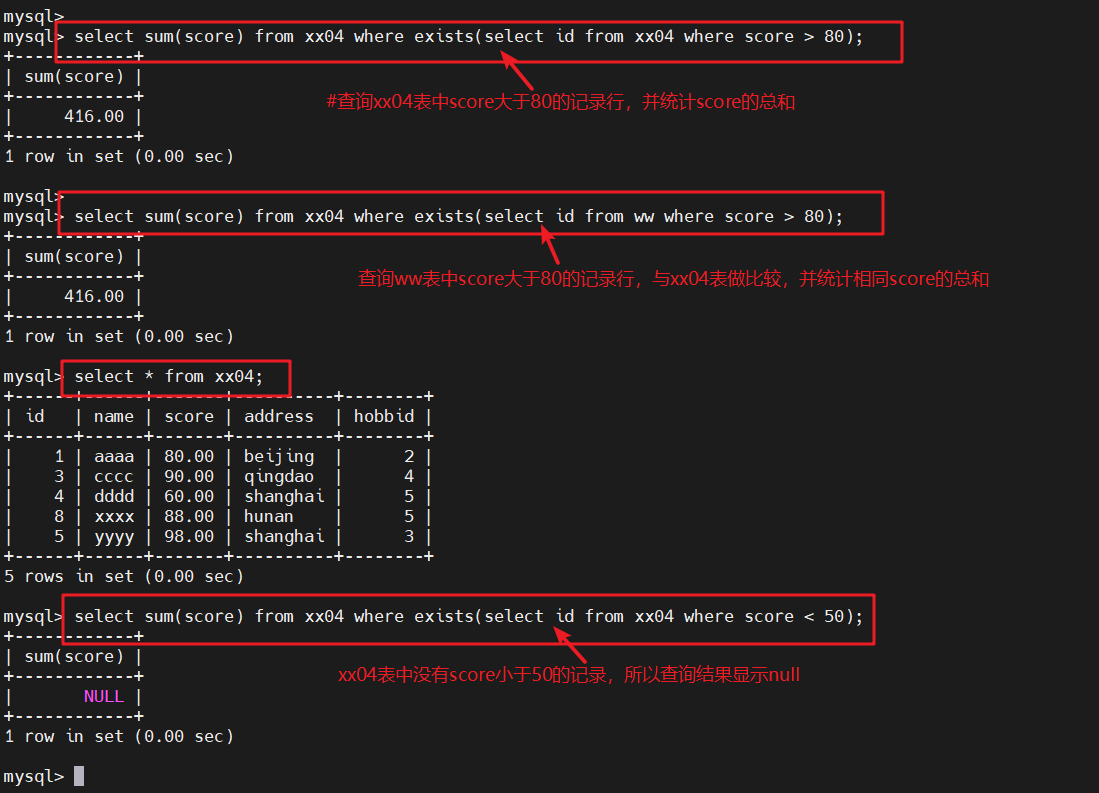
1.1.6 exists关键字
- exists 这个关键字在子查询时,主要用于判断子查询的结果集是否为空。如果不为空, 则返回 true;反之,则返回 false
select sum(score) from xx04 where exists(select id from xx04 where score > 80);
#查询xx04表中score大于80的记录行,并统计score的总和select sum(score) from xx04 where exists(select id from ww where score > 80);
#查询ww表中score大于80的记录行,与xx04表做比较,并统计相同score的总和select sum(score) from xx04 where exists(select id from xx04 where score < 50);
#xx04表中没有score小于50分的记录,所以查询结果为null
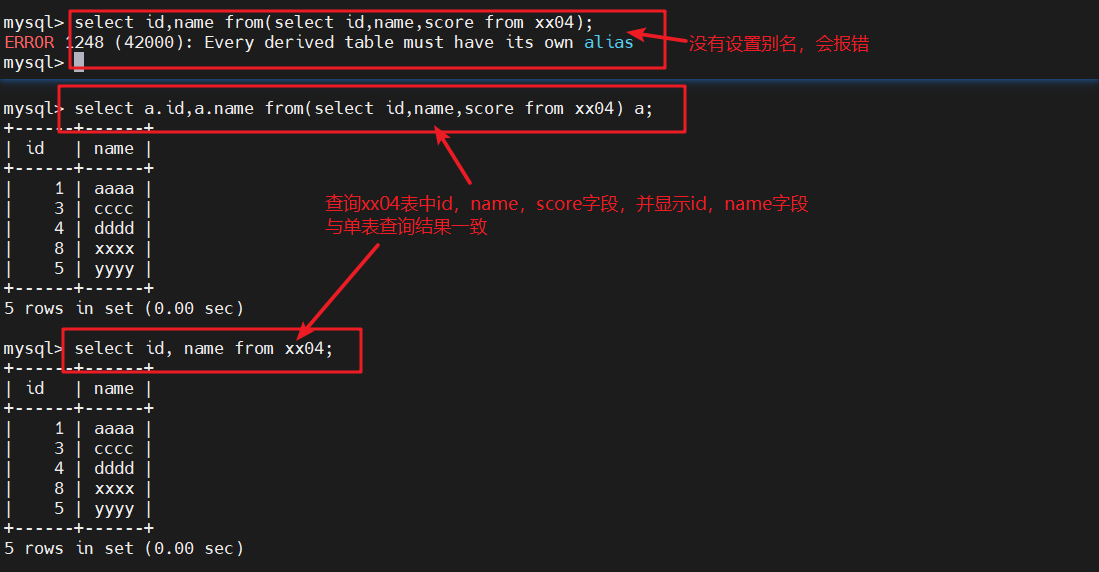
2、别名
- 将结果集做为一张表进行查询的时候,我们也需要用到别名
select id,name from(select id,name,score from xx04);
#此处没有设置别名会报错
#原因是:select * from 表名,此为标准格式,而以上的查询语句,"表名"的位置其实是一个完整结果集,mysql并不能直接识别,而此时给与结果集设置一个别名,以”select a.id from a“的方式查询将此结果集视为一张"表",就可以正常查询数据了select a.id,a.name from(select id,name,score from xx04) a;
#查询xx04表中id,name,score字段,并显示id,name字段,与单表查询结果一致select id, name from xx04;
二、MySQL视图
1、视图介绍
- 视图,可以被当作是虚拟表或存储查询
- 数据库中的虚拟表,这张虚拟表中不包含真实数据,只是做了真实数据的映射(视图可以理解为镜花水月/倒影,动态保存结果集(数据))
1.1 视图特点
- 视图不含有数据,只存储它的定义,它的用途一般可以简化复杂的查询。比如你要对净额表进行连接查询,而且还要进行统计排序等操作,写SQL语句会很麻烦的,用视图将几个表联结起来,然后对这个视图进行查询操作,就和对一个表查询一样,很方便。
1.2 作用范围
select * from 表;
#展示的部分是表select * from view_name;
#展示的一张或多张表
1.3 功能
-
简化查询结果集、灵活查询、可以针对不同用户呈现不同结果集、相对有更高的安全性
-
本质而言视图是一种select(结果集的呈现)
-
视图适合于多表连接浏览时使用,不适合增、删、改,而存储过程适合于使用较频繁的SQL语句,这样可以提高执行效率
2、视图和表的区别和联系
2.1 区别
-
视图是已经编译好的sql语句,而表不是
-
视图没有实际的物理记录,而表有
-
表只用物理空间而视图不占用物理空间,视图只是逻辑概念的存在,表可以及时对它进行修改,但视图只能用创建的语句来修改
-
视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,只是一些SQL语句的集合。从安全的角度说,视图可以不给用户接触数据表,从而不知道表结构
-
表属于全局模式中的表,是实表;视图属于局部模式的表,是虚表
-
视图的建立和删除只影响视图本身,不影响对应的基本表。(但是更新视图数据,是会影响到基本表的)
2.2 联系
- 视图(view)是在基本表之上建立的表,它的结构(即所定义的列)和内容(即所有数据行)都来自基本表,它依据基本表存在而存在。
- 一个视图可以对应一个基本表,也可以对应多个基本表。
- 视图是基本表的抽象和在逻辑意义上建立的新关系。
3、创建视图
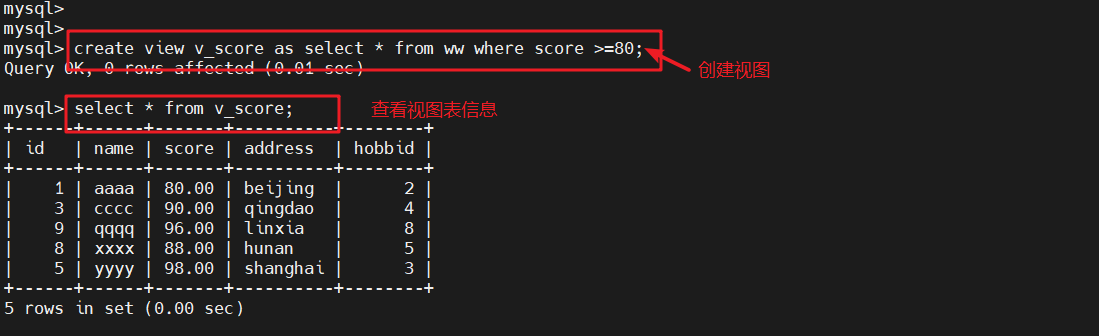
3.1 单表创建
create view v_score as select * from ww where score >=80;
#创建视图(将ww表中score大于等于80的记录导入v_score视图表中)select * from v_score;
#查看视图show table status\G
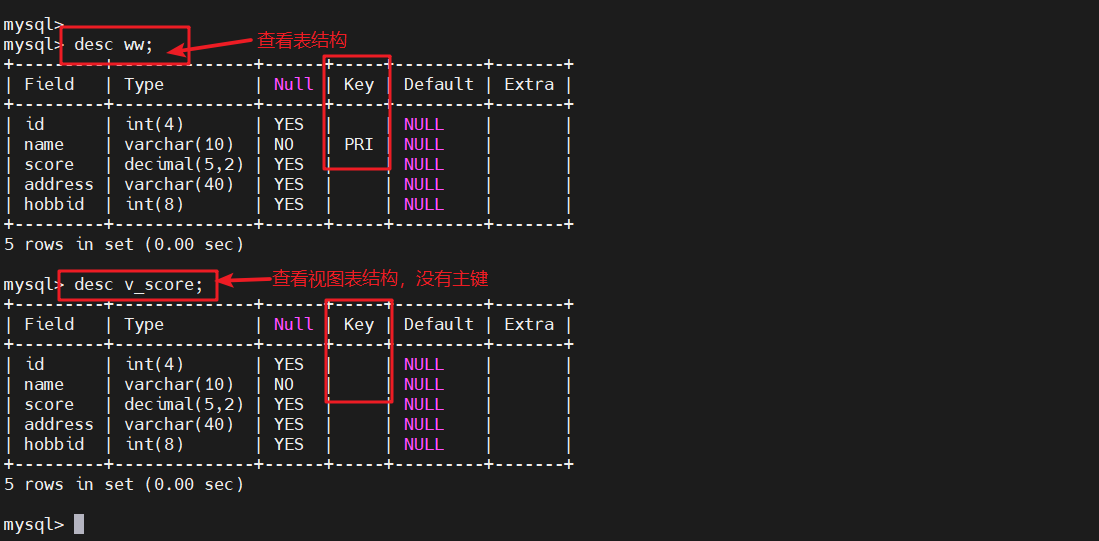
#查看表状态desc v_score;
desc ww;
#查看视图与源表结构
#区别就是视图没有主键

3.2 多表创建视图
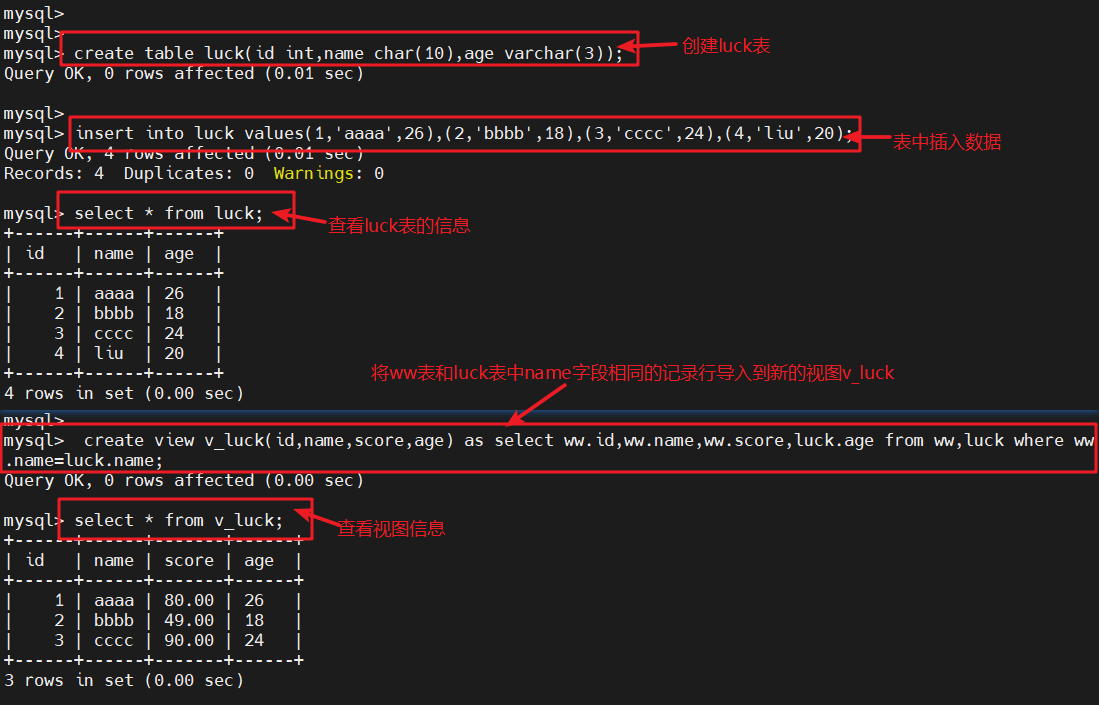
create table luck(id int,name char(10),age varchar(3));
#创建luck表insert into luck values(1,'aaaa',26),(2,'bbbb',18),(3,'cccc',24),(4,'liu',20);
#表中插入数据select * from luck;
#查看luck表的信息create view v_luck(id,name,score,age) as select ww.id,ww.name,ww.score,luck.age from ww,luck where ww.name=luck.name;
#将ww表与luck表中name字段相同的记录行导入到新的视图v_luckselect * from v_luck;
#查看视图表
3.3 修改表的数据
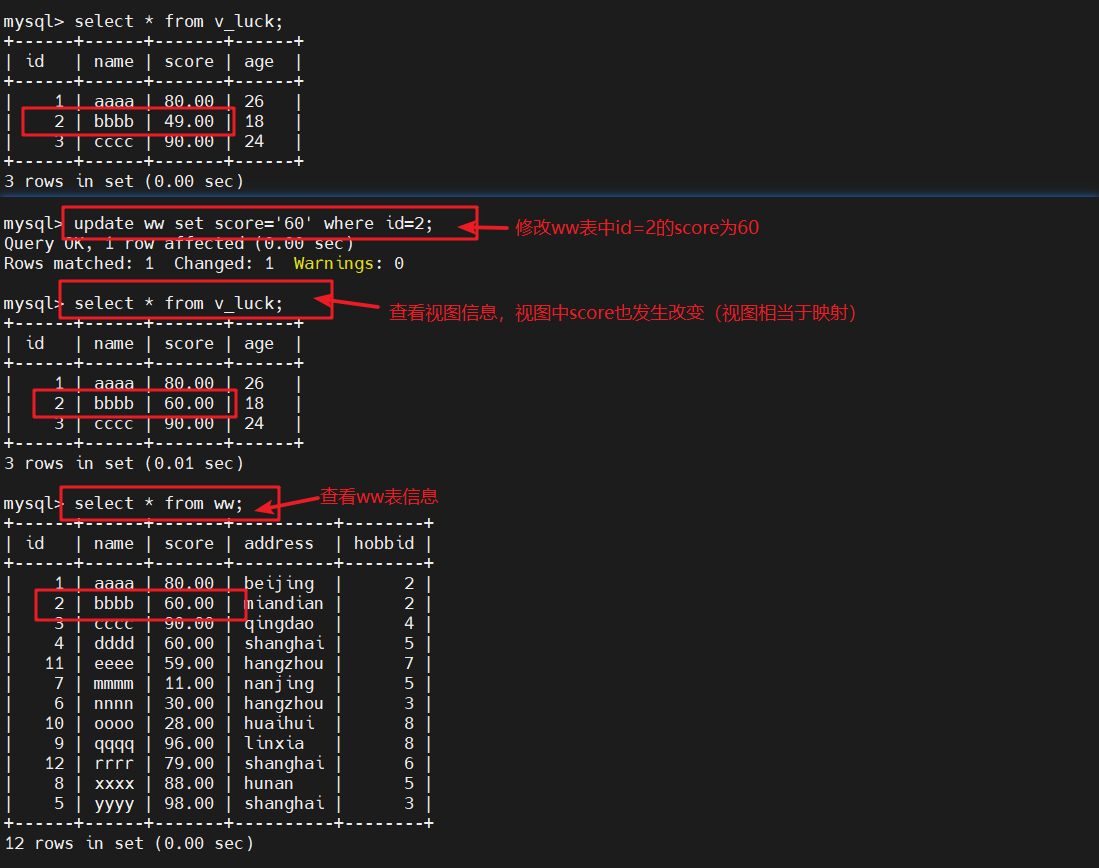
update ww set score='60' where id=2;
#修改原表ww的数据,将id=2的score修改为60select * from v_luck;
#查看视图,表中score发生变化,数据改为60,原表变化,视图也发生改变select * from ww;
#查看原表,score改为60##同时可以通过视图修改原表
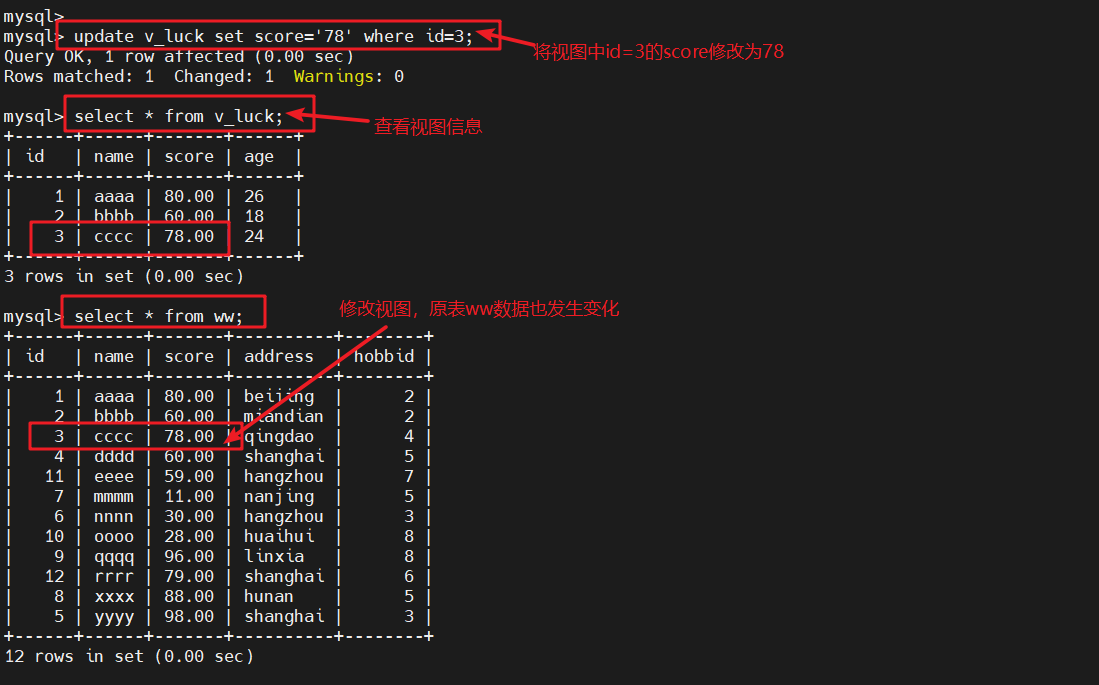
update v_luck set score='78' where id=3;
#修改视图,将id=3的score改为78select * from ww;
#查看原表ww,修改视图,原表也会发生变化select * from v_luck;
#查看视图
3.4 删除视图
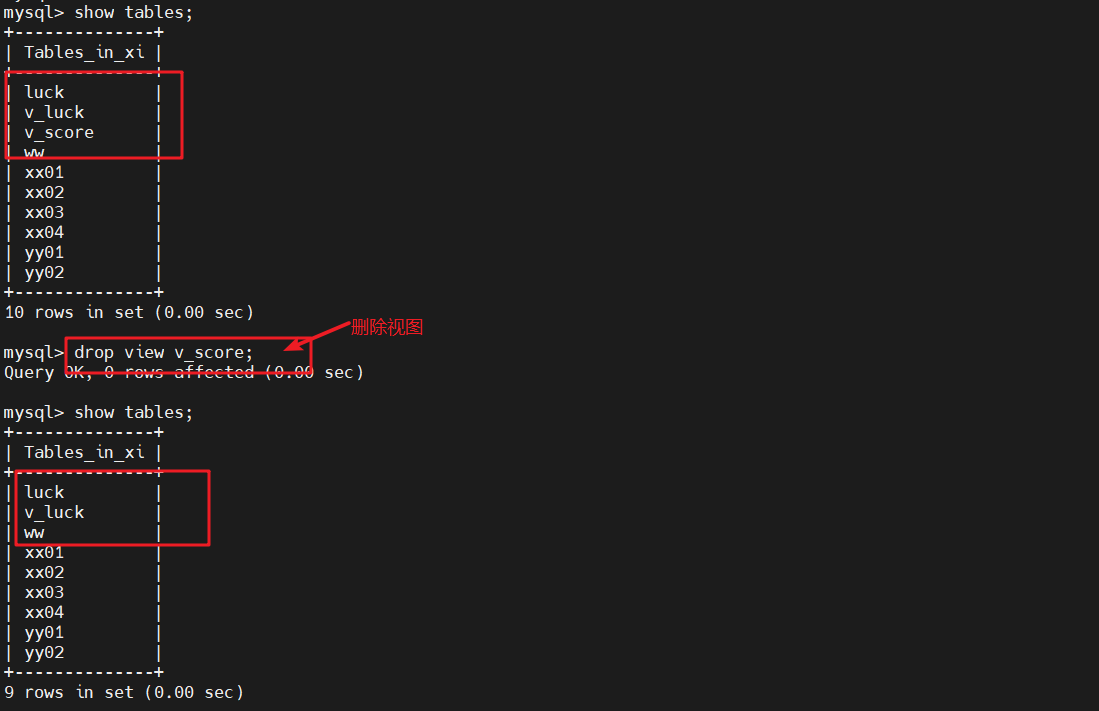
drop view v_score;
#删除视图
总结
-
修改表不能修改以函数、复合函数方式计算出来的字段
-
查询方便、安全性
- 查询方便:索引速度快、同时可以多表查询更为迅速(视图不保存真实数据,视图本质类似select)
- 安全性:我们实现登陆的账户是root ——》所拥有权限 ,视图无法显示完整的约束
三、NULL 值
- 在 SQL 语句使用过程中,经常会碰到 NULL 这几个字符。通常使用 NULL 来表示缺失 的值,也就是在表中该字段是没有值的。
- 如果在创建表时,限制某些字段不为空,则可以使用 NOT NULL 关键字,不使用则默认可以为空。
- 在向表内插入记录或者更新记录时,如果该字段没有 NOT NULL 并且没有值,这时候新记录的该字段将被保存为 NULL。需要注意的是,NULL 值与数字 0 或者空白(spaces)的字段是不同的,值为 NULL 的字段是没有值的。
- 在 SQL 语句中,使用 IS NULL 可以判断表内的某个字段是不是 NULL 值,相反的用 IS NOT NULL 可以判断不是 NULL 值。
null值与空值的区别
- 空值长度为0,不占空间,NULL值的长度为null,占用空间
select length(null),length(''),length('abc');
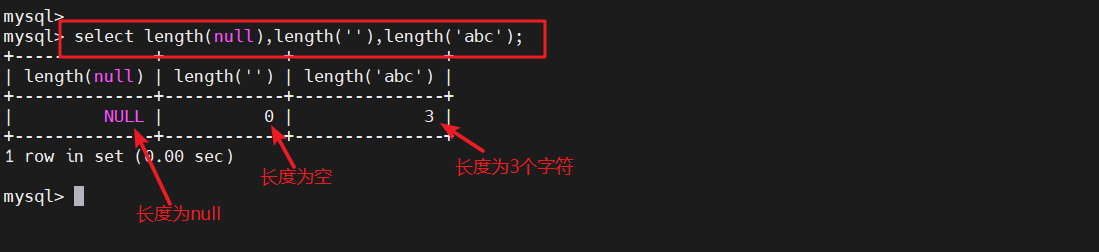
- 使用 IS NULL 可以判断表内的某个字段是不是 NULL 值,相反的用 IS NOT NULL 可以判断不是 NULL 值
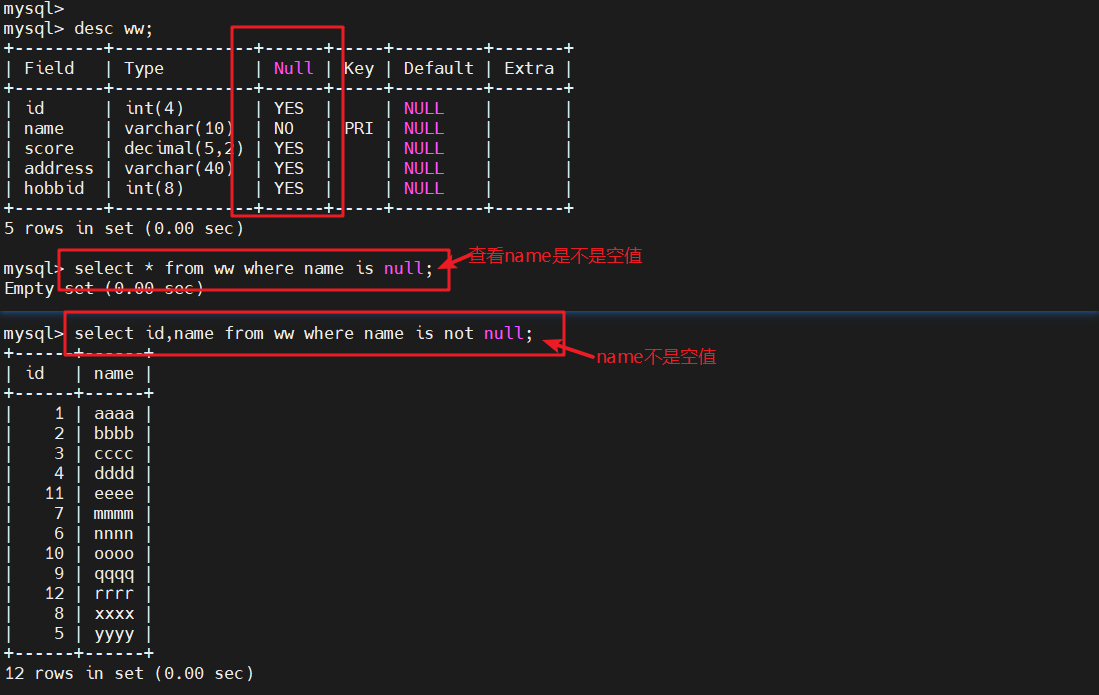
select * from ww where name is null;
#因为name不是空值,所以返回结果为空select id,name from ww where name is not null;
#返回name结果不是空值
四、连接查询
- MySQL 的连接查询,通常都是将来自两个或多个表的记录行结合起来,基于这些表之间的共同字段,进行数据的拼接。首先,要确定一个主表作为结果集,然后将其他表的行有选择 性的连接到选定的主表结果集上。
- 使用较多的连接查询包括:内连接、左连接和右连接
创建两个新表
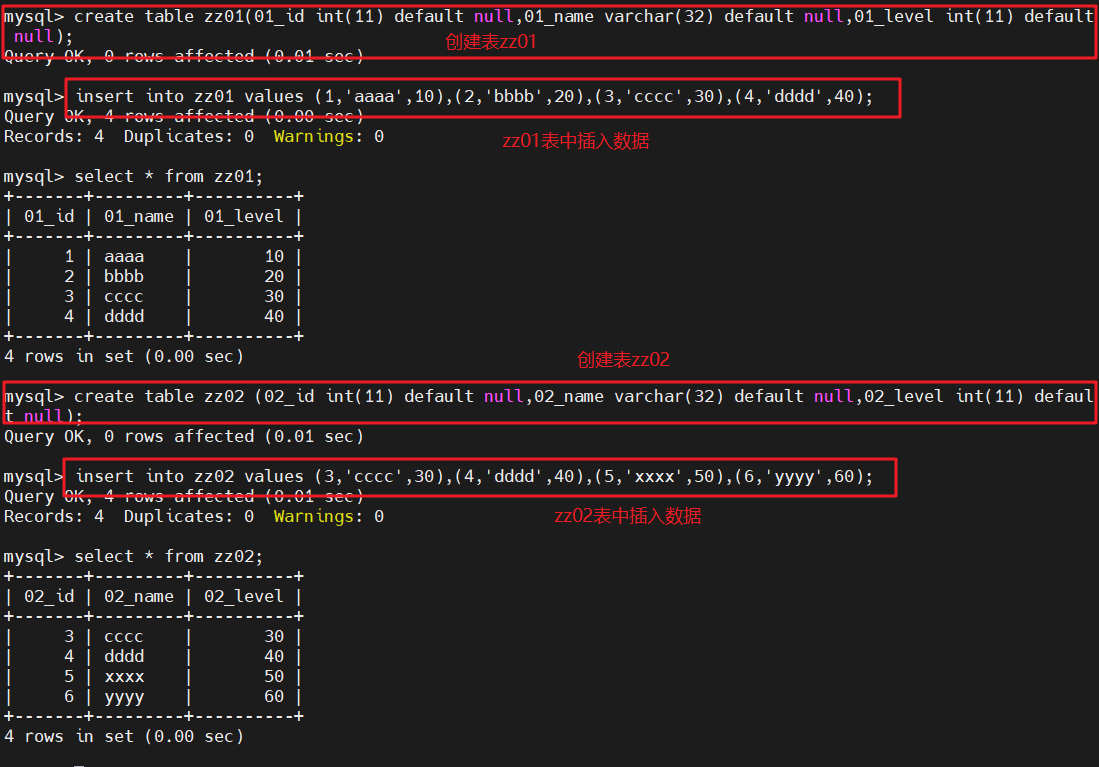
create table zz01(01_id int(11) default null,01_name varchar(32) default null,01_level int(11) default null);
#创建zz01表insert into zz01 values (1,'aaaa',10),(2,'bbbb',20),(3,'cccc',30),(4,'dddd',40);
#zz01表中插入数据select * from zz01;
#查询zz01表的信息create table zz02 (02_id int(11) default null,02_name varchar(32) default null,02_level int(11) default null);
#创建zz02表insert into zz02 values (3,'cccc',30),(4,'dddd',40),(5,'xxxx',50),(6,'yyyy',60);
#zz02表中插入数据select * from zz02;
#查询zz02表的信息
1、内连接
- MySQL中的内连接就是两张或多张表中同时符合某种条件的数据记录的组合。
- 通常在 FROM 子句中使用关键字 inner join 来连接多张表,并使用 on 字句设置连接条件,内连接是系统默认的表连接,所以在 FROM 子句后可以省略 INNER 关键字,只使用 关键字 JOIN。
- 同时有多个表时,也可以连续使用 inner join 来实现多表的内连接,不过为了更好的性能,建议最好不要超过三个表
内连查询:通过inner join 的方式将两张表指定的相同字段的记录行输出
1.1 语法
SELECT column_name(s)FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
1.2 内连接查询
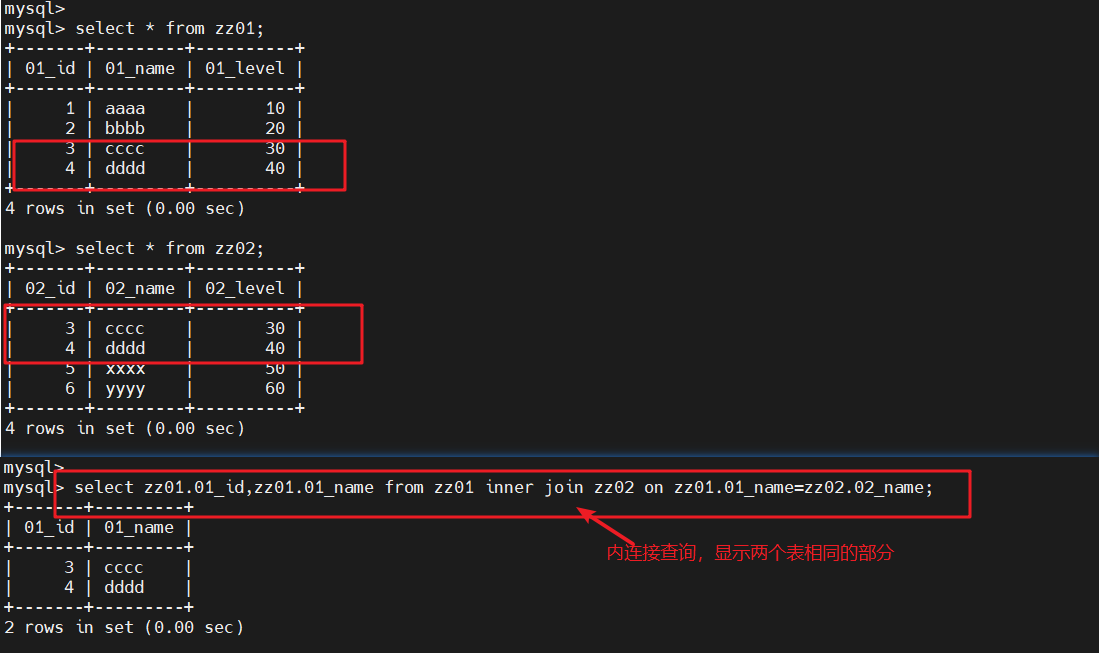
select * from zz01;
#查询zz01表的信息select * from zz02;
#查询zz02表的信息select zz01.01_id,zz01.01_name from zz01 inner join zz02 on zz01.01_name=zz02.02_name;
#内连接查询,显示两个表相同的部分
2、左连接
- 左连接也可以被称为左外连接,在 FROM 子句中使用 LEFT JOIN 或者 LEFT OUTER JOIN 关键字来表示。
- 左连接以左侧表为基础表,接收左表的所有行,并用这些行与右侧参 考表中的记录进行匹配,也就是说匹配左表中的所有行以及右表中符合条件的行。
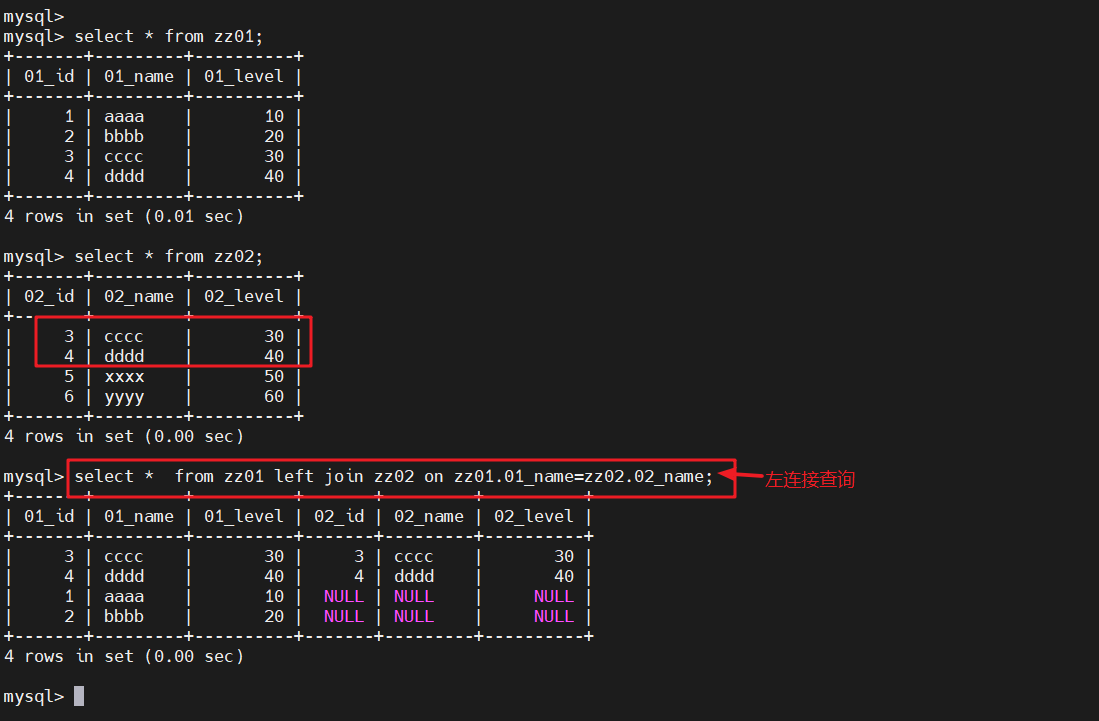
左连接查询
左连接查询:在左连接的查询结果集中,除了符合匹配规则的行外,还包括左表中有但是右表中不匹配的行,这些记录在右表中以 NULL 补足
select * from zz01;
#查询zz01表的信息select * from zz02;
#查询zz02表的信息select * from zz01 left join zz02 on zz01.01_name=zz02.02_name;
#左连接查询,左边显示左表全部信息,右边显示与左表相同的信息
3、右连接
- 右连接也被称为右外连接,在 FROM 子句中使用 RIGHT JOIN 或者 RIGHT OUTER JOIN 关键字来表示。
- 右连接跟左连接正好相反,它是以右表为基础表,用于接收右表中的所有行,并用这些记录与左表中的行进行匹配
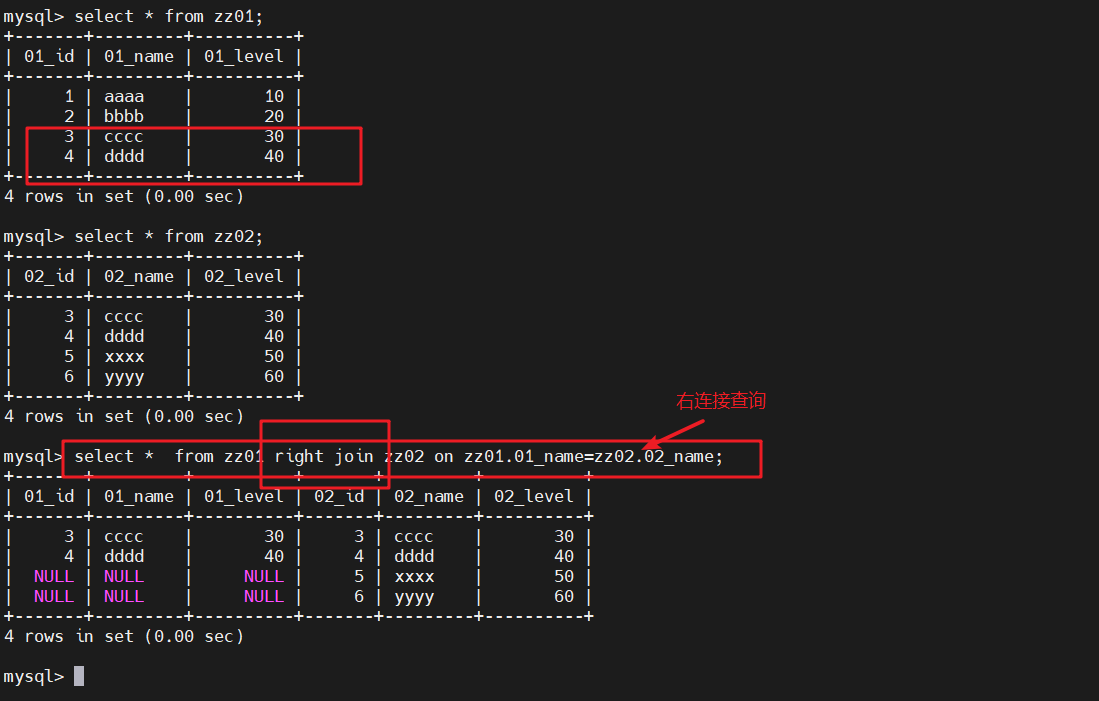
右连接查询
右连接查询:在右连接的查询结果集中,除了符合匹配规则的行外,还包括右表中有但是左表中不匹 配的行,这些记录在左表中以 NULL 补足
select * from zz01;
#查询zz01表的信息select * from zz02;
#查询zz02表的信息select * from zz01 right join zz02 on zz01.01_name=zz02.02_name;
#右连接查询,右边显示右表全部信息,左边显示与右表相同的信息
4、内连接、左连接、右连接区别
- 内连接:显示两个表相同部分内容
- 左连接:显示左表全部内容,右表仅显示与左表内容相同的部分,右表记录不足的地方均为 NULL。
- 右连接:显示右表全部内容,左表仅显示与右表内容相同的部分,左表记录不足的地方均为 NULL。
五、存储过程
1、存储过程的介绍
- 存储过程是一组为了完成特定功能的SQL语句集合,类似于shell中的函数。
- 存储过程在使用过程中是将常用或者复杂的工作预先使用SQL语句写好并用一个指定的名称存储起来,这个过程经编译和优化后存储在数据库服务器中。当需要使用该存储过程时,只需要调用它即可。存储过程在执行上比传统SQL速度更快、执行效率更高。
2、存储过程的优点
- 执行一次后,会将生成的二进制代码驻留缓冲区,提高执行效率。
- SQL语句加上控制语句的集合,灵活性高。
- 在服务器端存储,客户端调用时,降低网络负载。
- 可多次重复被调用,可随时修改,不影响客户端调用。
- 可完成所有的数据库操作,也可控制数据库的信息访问权限。
3、创建存储过程
语法
CREATE PROCEDURE <过程名> ( [过程参数[,…] ] ) <过程体>
[过程参数[,…] ] 格式
<过程名>:尽量避免与内置的函数或字段重名
<过程体>:语句
[ IN | OUT | INOUT ] <参数名><类型>
mysql> delimiter $$
#将语句的结束符号从分号;临时改为$$(可以是自定义)
mysql> create procedure dd()
#创建存储过程,过程名为dd,不带参数-> begin#过程体以关键字begin开始-> create table loo(id int,name char(10),phone varchar(20));#创建表-> insert into loo values(1,'qi',1824563),(2,'yi',1746653),(3,'yuan',1994873);#插入数据-> select * from loo;#过程体语句-> end $$#过程体以关键字end结束
Query OK, 0 rows affected (0.01 sec)mysql> delimiter ;
#将语句的结束符号恢复为分号;

4、调用存储过程
call dd;
#调用dd存储过程

5、查看存储过程
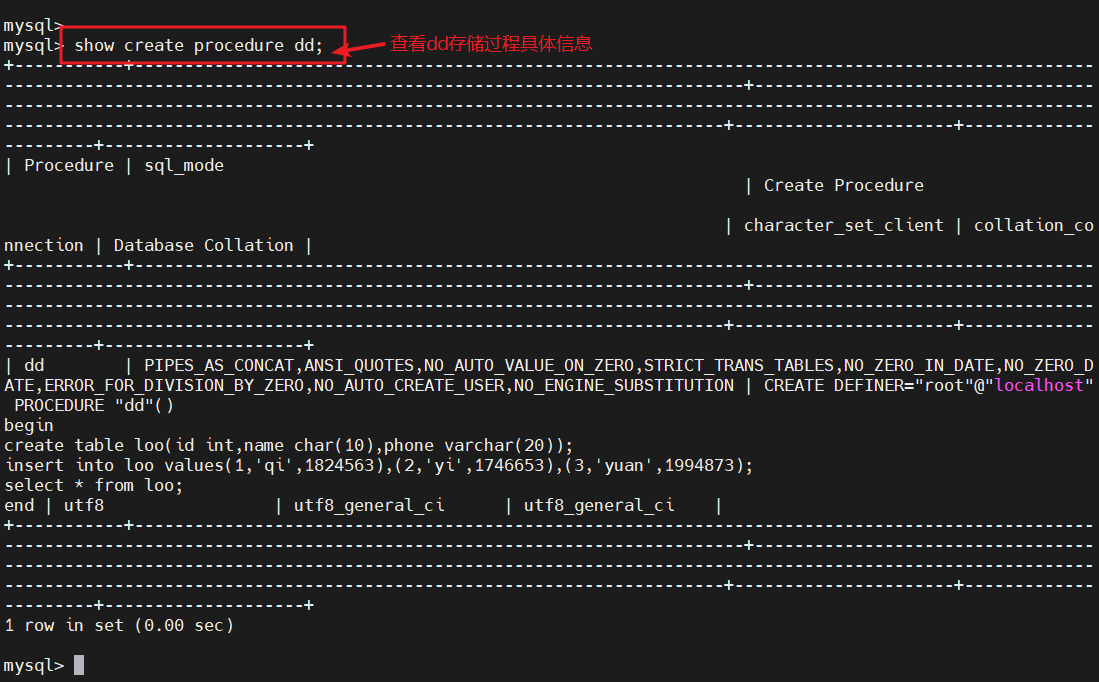
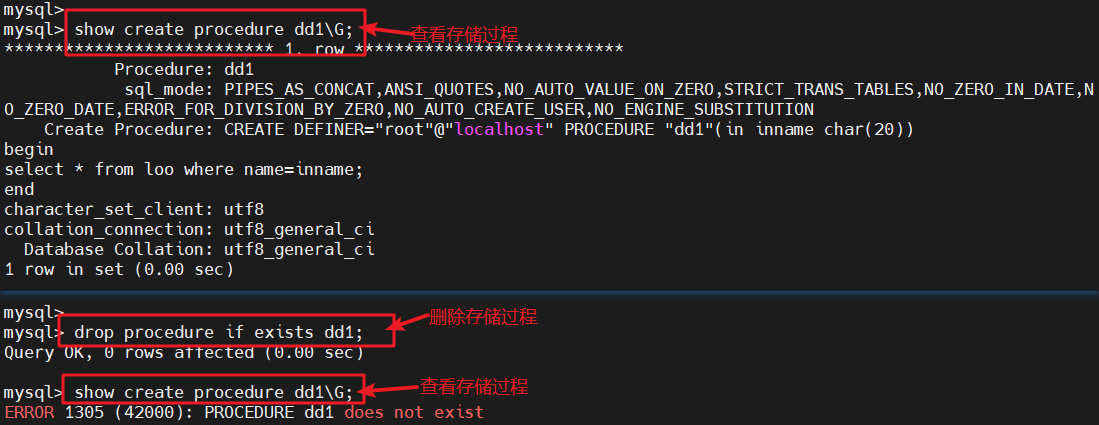
show create procedure [数据库.]存储过程名
#查看某个存储过程的具体信息
show create procedure dd;
#查看dd存储过程具体信息
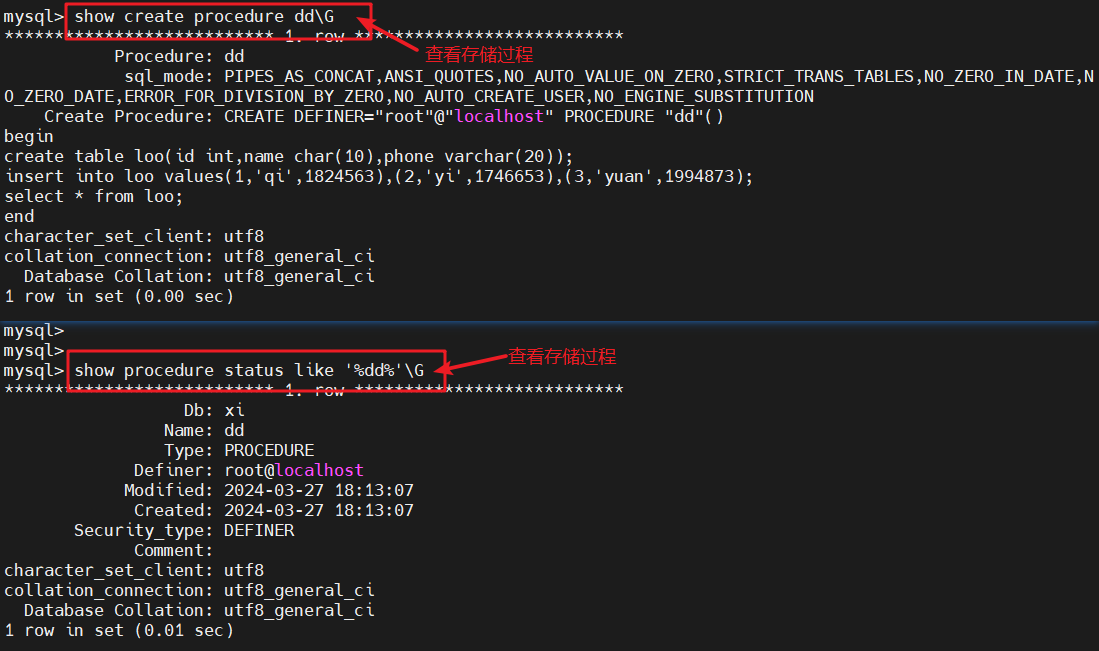
- 也可使用procedure查看存储过程
show create procedure dd\G
#查看dd存储过程show procedure status like '%dd%'\G
#查看dd存储过程信息
6、存储过程的参数
- IN 输入参数:表示调用者向过程传入值(传入值可以是字面量或变量)
- OUT 输出参数:表示过程向调用者传出值(传出值只能是变量)
- INOUT 输入输出参数:即表示调用者向过程传入值,也表示过程向调用者传出值
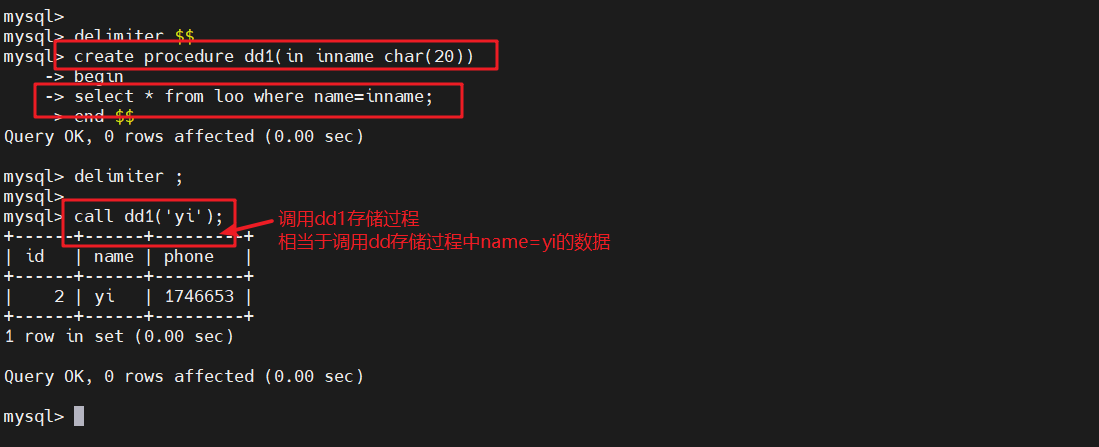
mysql> delimiter $$
mysql> create procedure dd1(in inname char(20))-> begin-> select * from loo where name=inname;-> end $$
Query OK, 0 rows affected (0.00 sec)mysql> delimiter ;call dd1('yi');
#调用dd1存储过程,相当于调用dd存储过程中name=yi的数据
7、修改存储过程
语法
ALTER PROCEDURE <过程名>[<特征>... ]
ALTER PROCEDURE dd MODIFIES SQL DATA SQL SECURITY INVOKER;
MODIFIES sQLDATA:表明存储过程是否会修改数据
SQL SECURITY INVOKER:存储过程在执行时使用的权限级别
invoker:当定义为INVOKER时,只要执行者有执行权限,就可以成功执行。
8、删除存储过程
- 存储过程内容的修改方法是通过删除原有存储过程,之后再以相同的名称创建新的存储过程。
drop procedure if exists dd1;
#删除存储过程dd1


![预期为文件结尾。json [行2,列1]](https://img-blog.csdnimg.cn/direct/ab02b88017b84684bdf9ad2d3c60934d.png)