本文参考文献:
[1] Kaur N, Singh P. Conventional and contemporary approaches used in text ot speech synthesis: A review[J]. Artificial Intelligence Review, 2023, 56(7): 5837-5880.
[2] TTS | 一文了解语音合成经典论文/最新语音合成论文篇【20240111更新版】_tts原理架构图-CSDN博客
【——————目前持续更新中——————】
【可预见更新:Transformer-TTS、VITS、NaturalSpech、Flow-based、Diffusion-based】
目录
模型综述
模型分类
模型组成
评判标准
传统模型简介
Articulatory synthesis(发音合成)类语音合成技术
Formant Synthesis(共振峰语音合成)
Concatenative speech synthesis(拼接语音合成)
Statistical parametric speech synthesis(统计参数语音合成,SPSS)
深度学习模型(简述)
Restricted Boltzmann machines
Deep Belief Network
Deep Neural Network
Recurrent Neural Networks
Deep Gaussian Process
优缺点简单总结
Challenging TTS
ETTS
多语者多语言 TTS
当前先进的 TTS 模型(SOTA)
自回归模型(Autoregressive Model)
非自回归模型(Non-Autoregressive Model)
TTS 发展小总结
模型综述
模型分类
传统的合成语音模型包括:
-
发音合成:articulatory synthesis,通过模拟声道和声带的形态和动态来生成语音
-
共振峰合成:formant synthesis,通过调整声道的滤波器来模拟声音的共振峰
-
拼接语音合成:concatenative speech,使用预先录制的人类语音单元(如音素、音节或单词)的片段,并将它们连接起来以形成连续的语音
-
统计参数技术:statistical parametric techniques(基于隐马尔可夫模型),参数可以包括基频、频谱包络、共振峰频率等,用参数化模型来生成语音。
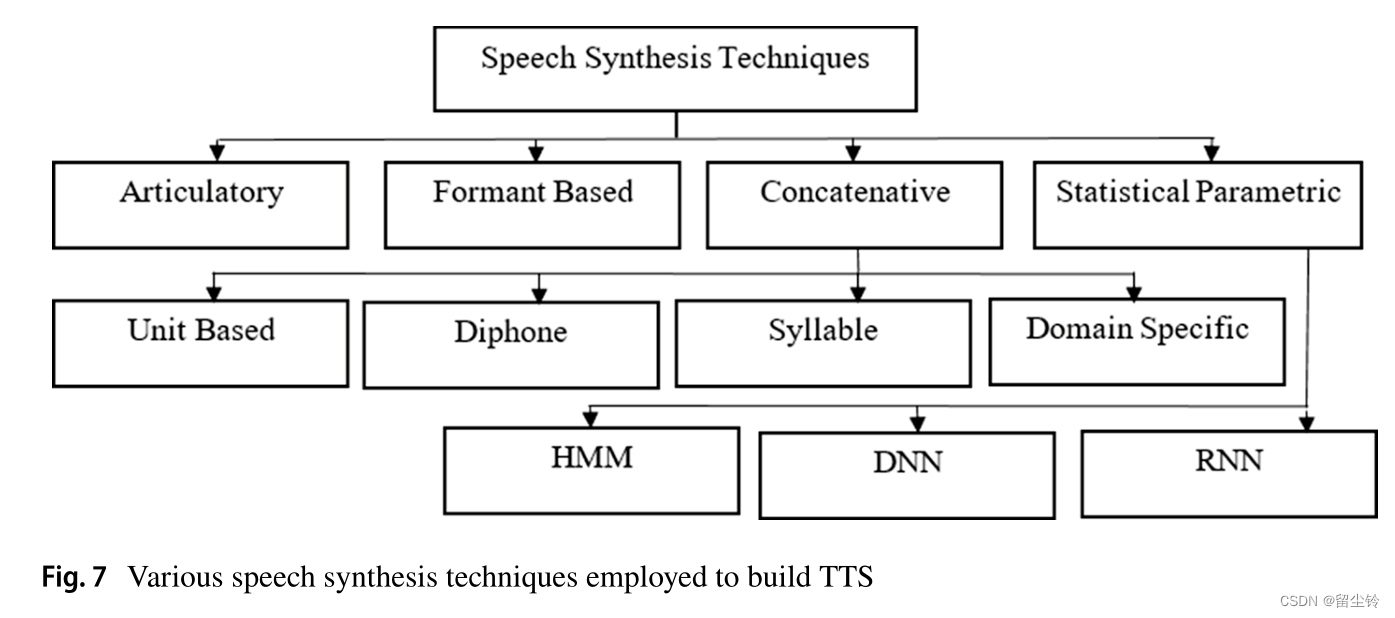
而最近的模型通常是基于深度学习方法的统计参数声学模型,以及一些端到端模型。
模型组成
通常由两个部分组成:
-
Natural Language Processing:自然语言处理,将文本转为声学表示向量。
-
Digital Signal Processing:人工合成语音波形
评判标准
通常,判断一个模型生成的语音的质量可以用两个标准来评判:
-
Intelligibility:合成难易程度和可理解性(说了什么?能不能听懂)
-
Naturalness:和人类语音的接近程度(像真人说的吗?)
传统模型简介
Articulatory synthesis(发音合成)类语音合成技术
-
通过模拟人的发声器官,进行建模,从而产生语音
-
优点:Intelligence 很不错,但是不够自然,很像机器人声音,原因是当时是通过X相片对人的声道进行建模,因此建模不够准确。这类模型并不是很流行。
Formant Synthesis(共振峰语音合成)
-
基于规则的语音合成方法,用各种参数进行规范化生成
-
避免了拼接语音合成技术中在声音单元边界常常出现的问题,但是还是很机械化发音,这类模型并不是很流行。
Concatenative speech synthesis(拼接语音合成)
-
一般分为两种,一种是基于单位(unit-based)合成,一种是基于二音节(diaphone-based)合成。
-
前者使用大量语料库,后者每个二音节只有一个copy。而且后者还需要使用PSOLA算法来调整韵律,但这需要对每个音阶周期精确标注,这会导致合成的声音不太自然。
-
后者的力量主要源自语料库。记录的声音被按照音素切割,最终选择最能匹配的音素进行链接生成语音
-
损失函数主要有两个:搜索匹配损失(target cost)和连接损失(concatenation cost)
-
它所需要的语料库是最大的限制。人们做了很多努力去压缩,去编码语料库,最终合成的语音确实只能且自然,但合成的都是正经阅读风格的语音,缺少风格的多样性、音色多样性等。而且搞到最后,不同的单元之间的边界过度还是不那么平滑。
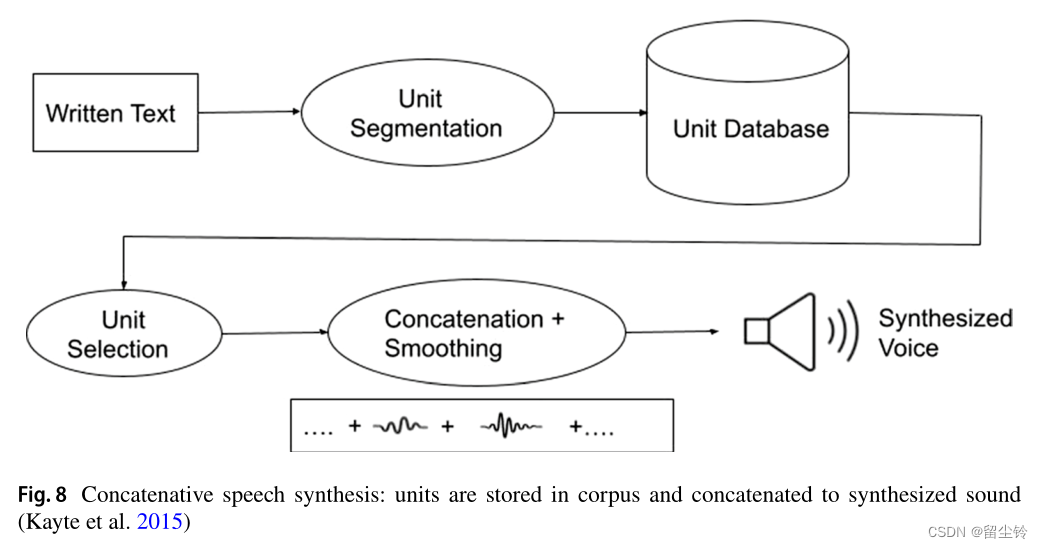
Statistical parametric speech synthesis(统计参数语音合成,SPSS)
-
主要是为了参数化语音的各个特征。通常后面需要接一个Vocoder,用于将参数转为语音波形。描述使用的参数比如基频(fundamental frequency,f0)、梅尔频率倒谱系数(MFCC)、频谱图(Spectrogram)等。
-
基于隐马尔可夫模型(HMM)的 SPPS:解决了拼接语音合成在针对不同语音风格目标导致的耗时低效,存储空间大等问题。
-
基于深度学习的 SPSS:通常为基于 DNN 和 RNN,LSTM 的表现也非常亮眼
深度学习模型(简述)
Restricted Boltzmann machines
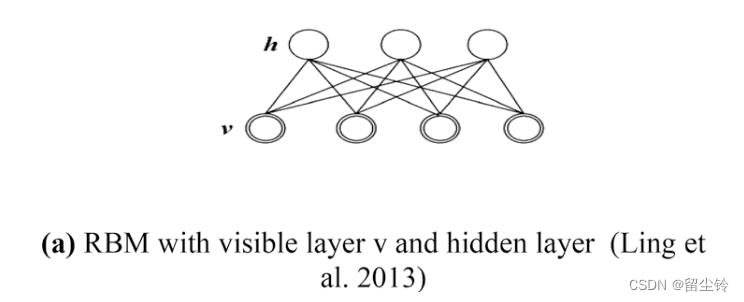
Restricted Boltzmann machines(受限玻尔兹曼机):主要用于DNN的预训练器,用来映射随机变量之间的依赖关系,一般有两层——可见层和隐藏层,同一层变量之间没有关系。
Deep Belief Network
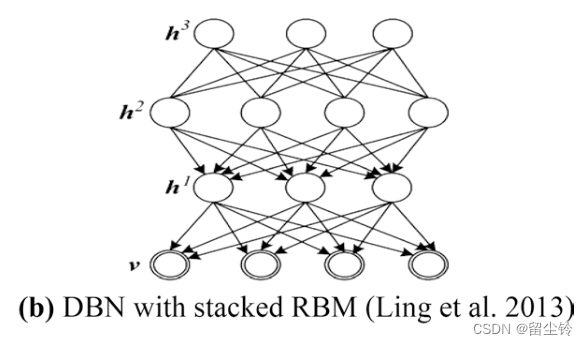
Deep Belief Network(深度置信网络):多个RBM进行堆叠。另外还有 Deep Conditional Restricted Boltzmann Machine(DCRBM,深度条件受限模型玻尔兹曼机)
Deep Neural Network
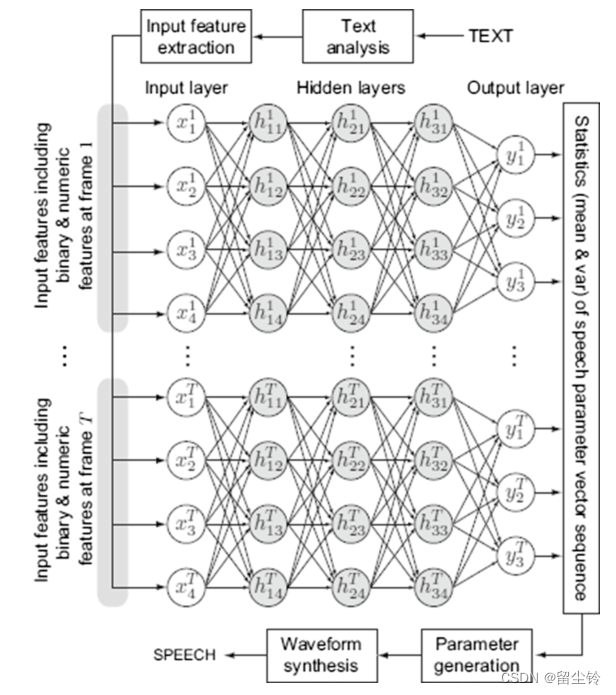
Deep Neural Network(深度神经网络):为了回归和分类问题设计,每一层都是非线性函数,因此可以去表示输入和输出之间的复杂关系。不过由于较多的层数会导致梯度的消失,因此对于较低层来说,信息的获取较为困难。
-
基本原理:文本先转为语言向量,然后通过DNN映射到输出的语音参数上,最后通过 vocoder合成语音波形。
-
分类:根据输入和输出的语音特征向量表示,深度学习方法可以分成深度生成模型、深度联合模型和深度条件模型。
-
DNN 是监督学习,不过可能会出现过拟合的情况。而且在某些主观评价中 HMM 比 DNN 好,原因在于 DNN 针对缺失的f0使用了插值算法,这就导致了合成的语音中的噪音。而针对这些问题,人们也提出了相应的解决方案:
-
针对过拟合,提出了使用 DBN 预训练的 DNN。
-
针对声学建模的准确性,使用了RBM来对频谱包络进行建模,DNN不再随机初始化权重,而是使用DBN来进行预训练。
-
-
此外,DNN 比 HMM 还优秀在能够自动表示语音的输入上下文和输出声学特征之间的依赖关系。
-
而且针对多人语料库,通过向单个隐藏层或者多个隐藏层中添加语者独热向量,DNN 也可以实现多人语音合成。
Recurrent Neural Networks
Recurrent neural networks(循环神经网络):由于 DNN 难以捕捉时间特征,因此就会导致在帧尺度上的语音参数预测的不连续性。有些算法可以缓解这种情况,但是也会导致相关的副作用。RNN 就在此提供了第二种方案。输入门决定控制当前时间步的输入信息有多少要传递给单元状态,遗忘门决定从此状态中丢弃多少旧信息,输出门基于当前的输入和先前状态决定当前的时间步的输出。
-
RNN可以轻松学习时间序列数据,因此可以针对统计语音合成中的协同发音特征(即语音单元之间的联系)进行建模,因此可以在输出层生成平滑的语音轨迹。
-
不过,由于RNN系列的声音合成模型涉及到大量的计算,因此RNN在实时语音合成任务中的应用并不比DNN要好。
Deep Gaussian Process
Deep Gaussian Process(深度高斯过程):DNN 模型主要强调训练阶段数据的拟合,虽然对语音质量有着很明显的改善,但是经常会出现过拟合的问题。而 DGP 此时就是 DNN 和 RNN 的替代。相比于 DNN 用了大量的超参数,DGP 通过级联贝叶斯核回归,可以使用更少的超参数来将语言向量映射到声学变量。由于训练过程中同时考虑了模型复杂度和数据拟合,并且在数据拟合过程中使用的是最大化边缘似然,因此模型不太容易出现过拟合的问题。
-
基于 DGP 的 TTS 模型在单语者、多语者任务上都表现出色。针对较少的训练数据、较多的训练数据都表现不错。在引入循环架构后,其表现得到了优化。其最大的问题可能在于计算量。
-
相较于 DNN 和 RNN,DGP 无论在 MOS 中还是在偏好测试分数中都比二者要高。
优缺点简单总结
-
Articulatory synthesis:发音合成,通过对发声器官进行建模
-
优点:不需要数据库,就能合成能够被理解的语音。
-
缺点:语音有点像机器人,并且非常难部署
-
-
Formant synthesis:共振峰合成,基于提供的一系列规则进行建模
-
优点:可理解语音,防止帧边界处的声学故障,对算力和存储空间有限制的平台友好,不需要数据库
-
缺点:语音不自然,生成的语音一听就是人工的,有点像机器人。
-
-
Concatenative synthesis:串联合成,串联声音单元合成语音
-
优点:比较像人类发出的声音
-
缺点:需要大量的声音数据,声音的各项特征、风格等不可以改动,在连接处的声音质量也比较差
-
-
HMM based:基于HMM合成,基于统计参数的方法,使用HMM来生成各项统计参数,并使用Vocoder来合成声音
-
优点:很方便调整语音特征,可以使用更少的语音数据去生成不同风格(比如情绪)的语音
-
缺点:语音轨迹过于平滑导致言语含糊不清,需要大量训练数据来生成听起来自然的语音。由于 HMM 中使用的决策树存在碎片问题,因此未对复杂的上下文依赖关系进行建模
-
-
HMM using RBM and DBN:使用RBM和DBN的HMM,使用相关技术对频谱包络分布进行建模,就可以在合成的时候对频谱包络进行预测了。
-
优点:对低频范围的频谱包络建模减轻了过度平滑的问题
-
缺点:准确性提高了,但是自然性没有怎么提高。
-
-
DNN:深度神经网络,对HMM的决策树进行替换,替换为DNN,用来映射输入语言变量和输出语音参数。
-
优点:既可以对输入特征之间复杂的上下文依赖关系进行建模,又不会遇到训练数据的碎片问题
-
缺点:反向传播计算量大,并且无法对多模态进行建模。
-
-
RNN:循环神经网络,使用的是双向长短期记忆和神经网络来对语音参数进行建模。
-
优点:能够捕捉到时序特征,从而改善了声音建模
-
缺点:计算复杂度较高,使其无法应用到实时语音合成任务中去
-
-
DGP:深度高斯过程,使用级联贝叶斯核回归(BKRs)来建模
-
优点:和DNN相比使用了更少的超参数,不易过拟合,在多语者语料库上表现优秀
-
缺点:没有循环结构,无法捕捉时间特征,部分参数失真仍然比DNN要高。
-
Challenging TTS
ETTS
ETTS:Expressive TTS,TTS主要需要研究说什么,谁说和怎么说三个问题,ETTS 集中解决的就是第三个问题。这其中包括韵律节奏变化、情感表达等多维度。之前可以通过总结并调整语音参数来实现,不过需要依靠大量的数据库,并且每种情感都需要一个模型。后来,从2004年开始采用单个模型去生成带情感语音。
-
当时使用的是分类代码和纬度值(categorical code and dimensional values),不过这项技术无法表达复杂的情感,并且有着注释模糊的问题存在。
-
后面又有人提出了使用 emotion exemplar,去提取情感表达后和input text一起送进语音合成模型中。如何提取则是去解析声谱,使用胶囊神经网络和残差神经网络去提取相应内容,然后通过seq2seq架构和文本一起共同生成语音
-
随后又有GST(Global Style Token)网络,核心思想就是使用一个风格标记的权重来决定语音的整体风格等等。随后人们在此基础上进行改动,并最终练出了一个可以微调心情的模型。
多语者多语言 TTS
Multi-speaker/Multi-lingual TTS:多语者、多语言语音合成
-
使用多任务学习,并复制输出层,模型很容易能够支持多语者的训练。这样的模型通过冻结隐藏层,仅仅改变回归层,可以在有限的训练数据的条件下取得不错的成绩。不过它也会随着语者的增多而线性扩展。
-
而如果是采用 IPA trainning(国际音标)训练的多语言模型,我们可以很容易将其扩展为对多语者的支持,GL vocoder 就是这样的模型产物,作者将其针对不同口音、语言等做出了改进。
-
在编码单元中引入语者嵌入向量后,多语者语音同样可以得以合成。
当前先进的 TTS 模型(SOTA)
自回归模型(Autoregressive Model)
最近,人们逐渐在使用自回归模型(AR model)来合成语音,这些模型通常先从文本生成梅尔频谱图,然后再通过vocoder来合成最终的语音。不过由于这类模型的训练和合成是串行进行的,就会导致其训练速度很慢,并且生成的语音健壮性也不足(漏读、重复等),这可能是因为自回归模型比较难捕捉长期依赖性(即上下文之间的依赖)。与此同时,非自回归模型也相继被提出,相较于对应的AR模型来说有着更高的合成率但准确性较低。不过有些技术:Knowledge distillation、word mapping、source target alignment constraints、duration prediction也可以用来提高准确性。
-
WaveNet:是全自回归概率模型,使用了深度卷积神经网络对用于训练的语音的概率分布进行建模,支持多语言、多口音,并且MOS也比较高,大幅减少了合成语音和自然语音之间的差距,也促成了端到端语音合成的发展。
-
Tacotron:也是端到端的语音合成,使用序列到序列的模型来获得语言文本到梅尔谱图的映射关系。缺失的相位信息则是由Griffin-Lim算法补充。此外,它是使用字符作为合成语音的基本单位,因此适配很多语言。并且它的生成速度要比WaveNet要更快。
-
Tacotron 2:是一代的加强版,同时结合了CNN和RNN,并使用更简单的构建块(LSTM、CNN)等来进行解码和编码。
-
Deep-voice:是百度开发的,由很多模块组成,2代可以用单个模型来合成多个语音,3代则是用了在LibriSpeechASR数据集上学习的全卷积神经网络,主要由编码器、解码器和转换器(为了和Vocoder对接)组成。
非自回归模型(Non-Autoregressive Model)
-
ParaNet:一个基于完全卷积注意力的非自回归TTS模型,在一次前馈过程中就生成语音波形。它使用自回归编码器的注意力蒸馏,反复细化文本和梅尔频谱图之间的对齐。Encoder类似DV3的编码器,解码器主要由注意力模块、全卷积模块、再一个注意力模块组成。为了提高性能,它预测对数梅尔频谱图,也预测对数线性频谱图。而作为一个非自回归模型,它的合成速度是远远胜过自回归模型的。
-
Parallel Tacotron:一个轻量级卷积非自回归TTS模型,使用VAE来捕捉语音局部上下文信息,训练合成同时进行,2代的持续时间模型基于注意力蒸馏,并使用软动态时间对齐进行迭代细化,因此在训练的时候就可以不用教师强制等方法,而是直接用可微的持续时间模型传播误差梯度,因此合成的声音就更自然。
-
FastSpeech:能够并行生成梅尔频谱图,生成速度非常快。模型主要通过预测音素持续时间来生成语音,并借用了自回归模型中的教师模型的注意力,通过均方误差进行训练。模型包括六个前馈变换模块,用来将音素序列转换成梅尔频谱图序列,并使用长度调节器来桥接序列长度不匹配的情况。不过,也正因为采用的是教师模型简化版本,其生成的梅尔频谱图信息存在缺失,也无法准确确定音素持续时间。2代通过直接训练原始真实语音数据防止了信息丢失(原来采用的是教师模型简化的数据),从目标语音中确定持续时间、音高和能量的值,并使用连续小波变换方法将音高轮廓转换为音高频谱图。最终,2代通过使用简化的训练管线和高质量的语音,使其原始版本FastSpeech的速度提高了3倍。
-
Parallel WaveNet:17年的,用的平行前馈网络,采用了概率密度蒸馏方法进行训练(将教师模型(可能是更大、更复杂的WaveNet模型)的输出概率分布作为软目标,学生模型被训练来模拟教师模型的输出分布,从而提高语音合成的质量和性能。)。它可以生成多个语者带有不同口音的声音。
TTS 发展小总结
-
以前使用的基于规则的发音和共振峰合成方法虽然产生了高度可理解的声音,但合成的语音听起来很机器人,因此并没有得到太多的欢迎。
-
之后,诸如基于单元和基于双音素的语音合成方法等串联方法,即使生成自然语音,也需要来自单个说话者的更大的语音语料库。此外,生成阅读式语音并且声音在帧边界处不连续。与这些传统的语音合成方法相比,SPSS(尤其是基于深度学习的方法)通过从参数表示合成语音来提供更准确的声学建模。这些模型最适合对输入语言特征和输出语音参数之间的复杂非线性关系进行建模。此外,在 RNN 架构中使用双向 LSTM 能够对时间特征进行建模,而 DGP 有助于在很大程度上缓解 DNN 中的过拟合问题,并利用多说话人语音语料库生成语音。
-
目前,最先进的TTS模型采用的是自回归和非自回归模型,一方面自回归 TTS 能够重新生成高质量的语音,另一方面非自回归 TTS 能够高速合成语音。