目录
前言
一、按关键字排序查询
1、单字段排序
1.1 按某一字段升序排序
1.2 按某一字段降序排序
1.3 结合where进行条件进行排序
2、多字段排序
2.1 按多字段升序排序
2.2 按多字段降序排序
2.3 案例操作
3、区间判断及查询不重复记录
3.1 区间判断
3.1.1 AND/OR简单使用
3.1.2 AND/OR嵌套使用
3.2 查询不重复记录
3.3 查询取值列表中的数据
3.4 between区间操作符
二、对结果进行多列分组查询
1、聚合函数
1.1 基于聚合函数count
1.2 基于聚合函数sum
1.3 基于聚合函数avg
1.4 基于聚合函数max
1.5 基于聚合函数min
2、常用数学函数
3、字符串函数
3.1 去除字符trim
3.2 截取字符串substr
3.3 字段拼接
3.4 返回字符长度length
3.5 替换replace
4、日期时间函数
三、限制结果条目(limit)
1、查询前n行记录
2、查询前n行后m行记录
3、查询某个单独行的记录
四、设置别名alias
1、设置字段的别名
2、设置表的别名
3、as作为连接语句的操作符
五、通配符like
1、查询以某字符开头的记录
2、查询以某字符结尾的记录
3、查询只要有某字符的记录
4、查询具体到任意单个字符的记录
5、常用字符结合查询
六、子查询
1、子查询与IN操作符概述
1.1 子查询概念
1.2 IN操作符概念
2、select
2.1 单表查询
2.2 多表查询
2.3 将子语句的结果取反not
3、insert
4、update
5、delete
6、exists
7、as别名
七、视图(优化Mysql数据库)
1、视图概念与功能
2、视图与基本表的区别和联系
3、视图的基本用法
3.1 创建视图
3.1.1 单表创建
3.1.2 多表创建
3.2 修改视图数据
3.3 删除视图
八、NULL值
九、连接查询
1、内连接
2、左连接
3、右连接
十、总结
前言
MySQL数据库的高级SQL语句涵盖了一系列复杂的查询、数据操作和数据库管理功能,旨在处理复杂的数据关系、优化查询性能以及提供高级数据分析能力
一、按关键字排序查询
1、单字段排序
使用 select 语句可以将需要的数据从 mysql 数据库中查询出来,如果对查询的结果进行排序操作,可以使用 order by 语句完成排序,并且最终将排序后的结果返回给客户。这个语句的排序不光可以针对某一个字段,也可以针对多个字段
格式:select 字段1,字段2,…… from 表名 order by 字段 asc|desc;#其中asc|desc
#asc:是按照升序进行排名的,是默认的排序方式,即asc可以省略
#desc:是按照降序的方式进行排序的
#当然 order by 前也可以使用 where 子句对查询结果进一步过滤部署环境:新建表,并插入表数据,方便进行查询
#登录mysql数据库
[root@localhost ~]#mysql -uroot -p123456
#进入xgy数据库
use xgy;
#新建表
create table info (id char(3) not null,name varchar(15) not null primary key,score decimal(4,2),address varchar(50) not null,hobbid char(3) not null);
#插入点表数据,来进行查询
insert into info values (1,'cxz','66','江苏南京',5);
insert into info values (2,'ysl','97','江苏徐州',3);
insert into info values (3,'pmi','82','江苏泰州',2);
insert into info values (4,'dfy','45','江苏无锡',3);
insert into info values (5,'sii','77','江苏宿迁',2);
insert into info values (6,'lyy','92','江苏南京',1);
1.1 按某一字段升序排序
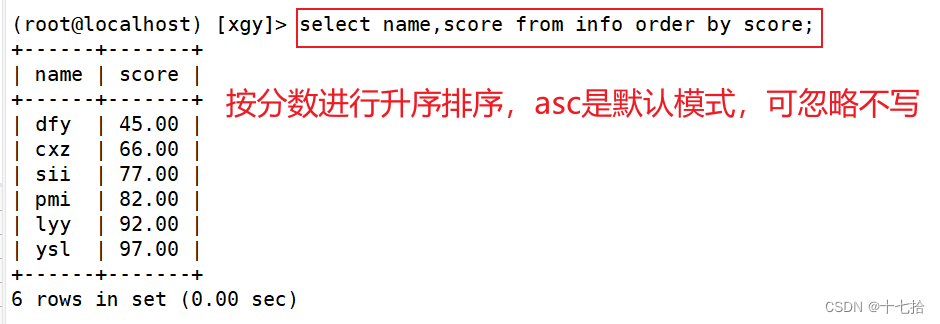
格式:select 字段1,字段2,…… from 表名 order by 字段 asc;
#asc:是按照升序进行排名的,是默认的排序方式,即asc可以省略select name,score from info order by score asc;
#按照分数升序排序,显示name和score的字段值
1.2 按某一字段降序排序
格式:select 字段1,字段2,…… from 表名 order by 字段 desc;
#desc:是按照降序的方式进行排序的select name,score from info order by score desc;
#按照分数降序排序,显示name和score的字段值
1.3 结合where进行条件进行排序
select name,score,address from info where address='江苏南京' order by score;
#筛选地址为“江苏南京”的行数据,并按成绩进行升序排序,显示name、score、address字段select name,score,hobbid from info where hobbid=3 order by score desc;
#筛选hobbid为3的行数据,并按成绩进行降序排序,显示name、score、hobbid字段
2、多字段排序
order by 语句也可以使用多个字段来进行排序,当排序的第一个字段相同的记录有多条的情况下,这些多条的记录再按照第二个字段进行排序,order by 后面跟多个字段时,字段之间使用英文逗号隔开,优先级是按先后顺序而定,但order by 之后的第一个参数只有在出现相同值时,第二个字段才有意义
2.1 按多字段升序排序
格式:select 字段1,字段2,…… from 表名 order by 字段1 asc,字段2 asc,……;
#asc:是按照升序进行排名的,是默认的排序方式,即asc可以省略
#order by之后的第一个参数只有在出现相同值时,第二个字段才有意义2.2 按多字段降序排序
格式:select 字段1,字段2,…… from 表名 order by 字段1 desc,字段2 desc,……;
#desc:是按照降序的方式进行排序的
#order by之后的第一个参数只有在出现相同值时,第二个字段才有意义2.3 案例操作
#先按第一个参数字段hobbid升序排序,如果出现第一个参数字段值相同的情况下,那么再按第二参数字段score升序排序
select name,hobbid,score from info order by hobbid asc,score asc;
#先按第一个参数字段hobbid降序排序,如果出现第一个参数字段值相同的情况下,那么再按第二参数字段score降序排序
select name,hobbid,score from info order by hobbid desc,score desc;
#先按第一个参数字段hobbid升序排序,如果出现第一个参数字段值相同的情况下,那么再按第二参数字段score降序排序
select name,hobbid,score from info order by hobbid asc,score desc;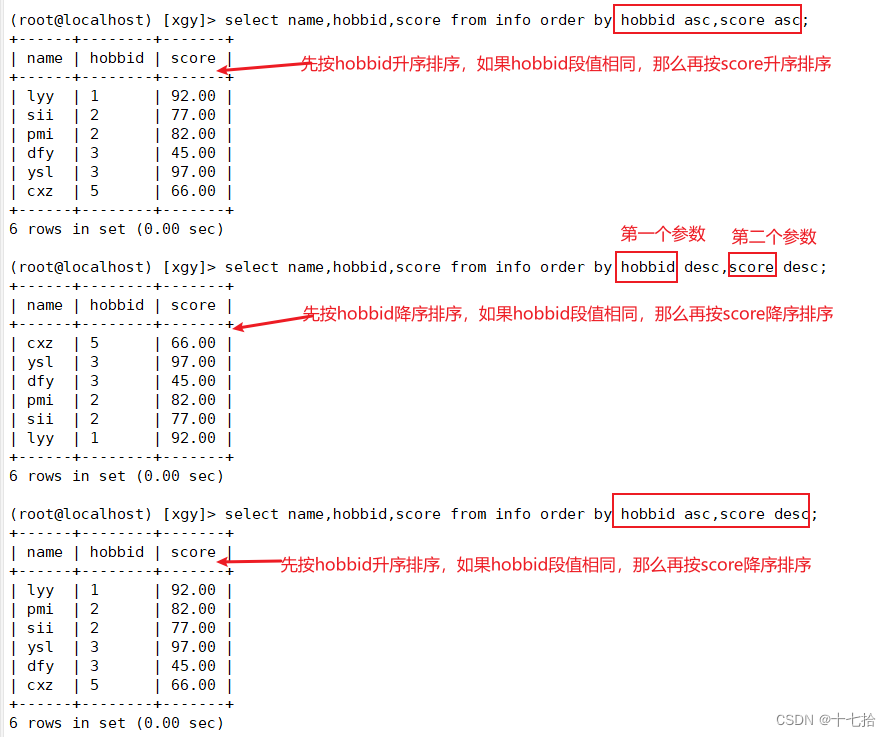
3、区间判断及查询不重复记录
3.1 区间判断
使用AND/OR操作符:
AND/OR:且/或的使用
格式:select 字段 from 表名 where 条件判断1 and/or 条件判断2
使用比较操作符:
比较操作符>、<、>=、<=可以用来定义开放区间或半开放区间的查询3.1.1 AND/OR简单使用
#筛选分数大于70且分数小于等于95的记录
select * from info where score > 70 and score <= 95;
#筛选分数小于70,或者分数大于等于95的记录
select * from info where score < 70 or score >= 95;
3.1.2 AND/OR嵌套使用
#筛选分数大于80,或者分数大于等于85且分数小于95的记录
select * from info where score > 80 or (score >= 85 and score < 95);
#筛选id大于2且(id大于等于4或者id小于等于3)的记录
select * from info where id > 2 and (id >=4 or id <= 3);

3.2 查询不重复记录
格式:select distinct 字段 from 表名﹔#distinct:必须放在最开头
#distinct:只能使用需要去重的字段进行操作
#distinct:去重多个字段时,几个字段同时重复时才能被过滤,会默认按左边第一个字段为依据#去除hobbid字段重复的值
select distinct hobbid from info;
3.3 查询取值列表中的数据
select 字段 from 表名 where 字段 in ('值1','值2',……);#in,遍历一个取值列表select * from info where id in(1,3,5,7,9);
3.4 between区间操作符
between 操作符在 MySQL 中用于选取介于两个值之间的数据范围。这两个值可以是数值、文本或者日期。between 操作符是包含性的,也就是说,开始值和结束值都包括在内
select 字段 from 表名 where 字段 between '值1' and '值2';select * from info where score between 75 and 95;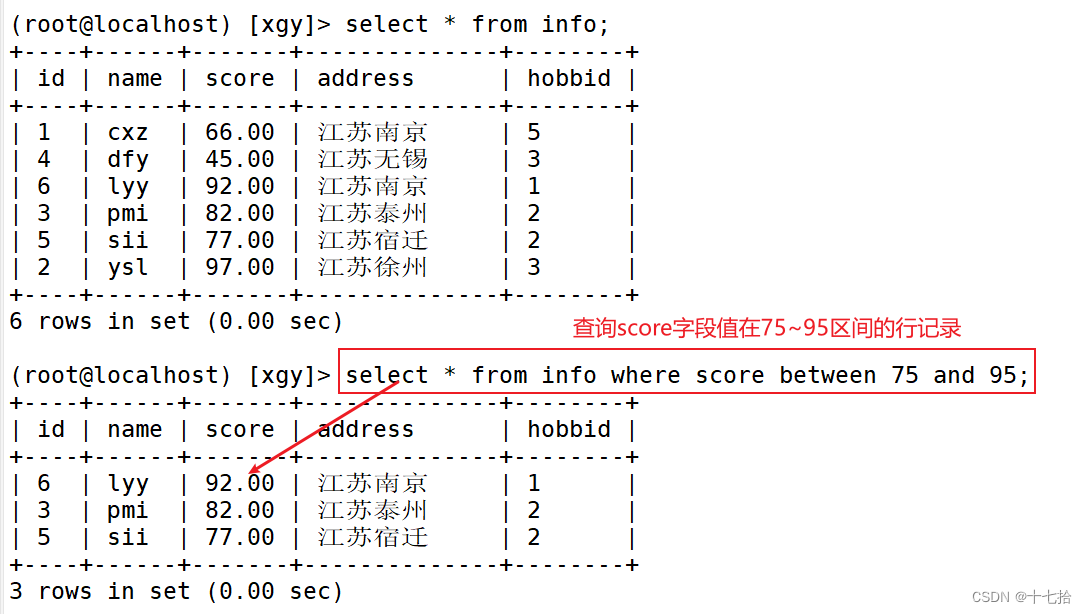
二、对结果进行多列分组查询
对结果进行分组查询是通过使用group by子句来实现的。group by子句用于将查询结果按照一个或多个列进行分组。
group by 通常都是结合聚合函数一起使用的,常用的聚合函数包括:计数(count)、 求和(sum)、求平均数(avg)、最大值(max)、最小值(min)
格式:select 字段1, 聚合函数(字段2) from 表名 (where 字段名 (匹配) 数值) group by 字段1;1、聚合函数
| 聚合函数 | 说明 |
|---|---|
| avg() | 返回指定列的平均值 |
| count() | 计数,返回指定列中非 NULL值的个数 |
| min() | 返回指定列的最小值 |
| max() | 返回指定列的最大值 |
| sum(字段) | 返回指定列的所有值之和 |
1.1 基于聚合函数count
案例一:按hobbid字段值相同的分组,计算相同分数的学生个数(基于name个数进行计数)
select count(name),hobbid from info group by hobbid;
案例二: 结合where,筛选分数大于等于80的分组,并计算各组学生的个数
#筛选分数大于等于80的记录,并显示其name和score字段
select name,score from info where score >=80;
#结合where,筛选分数大于等于80的分组,并计算各组学生的个数
select count(name),score from info where score >=80 group by score;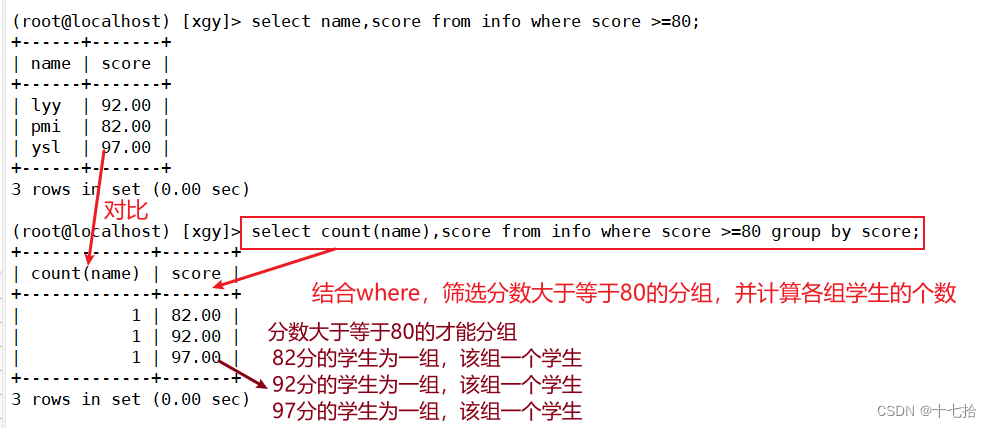
案例三:查询整个表共有多少条数据
select count(*) from info;
或者
select count(主键) from info; #主键值具有唯一性且不能为空值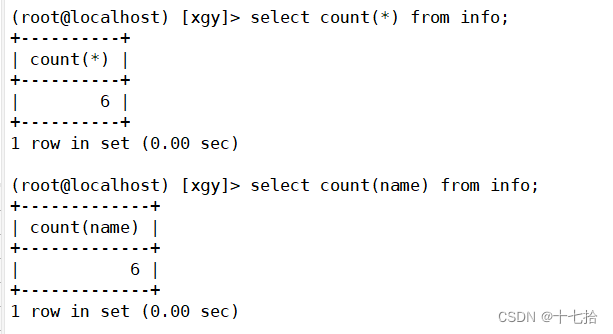
1.2 基于聚合函数sum
案例一:按hobbid字段值相同的分组,并求和每组的总成绩
#将hobbid升序排序,并显示其hobbid、name、score字段
select hobbid,name,score from info order by hobbid;
#按hobbid字段值相同的分组,并求和每组的总成绩
select sum(score),hobbid from info group by hobbid;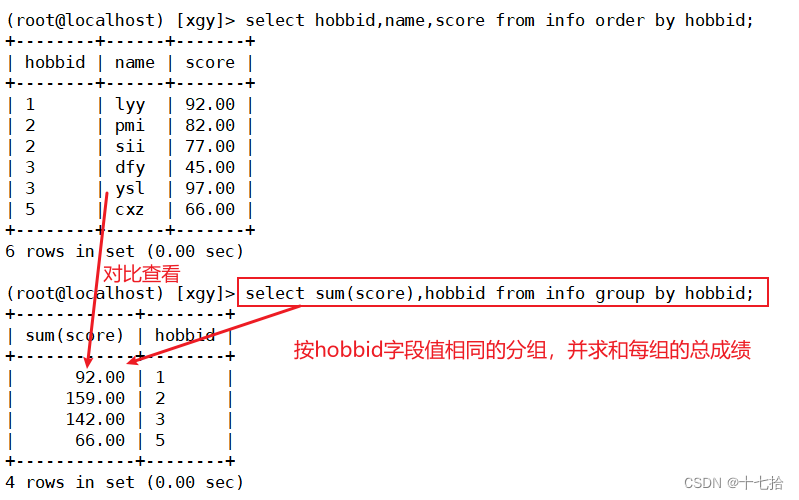
案例二:结合order by把每组的总成绩按降序排列
#按hobbid字段值相同的分组,并求和每组的总成绩,再结合order by把每组的总成绩按降序排列
select sum(score),hobbid from info group by hobbid order by sum(score) desc;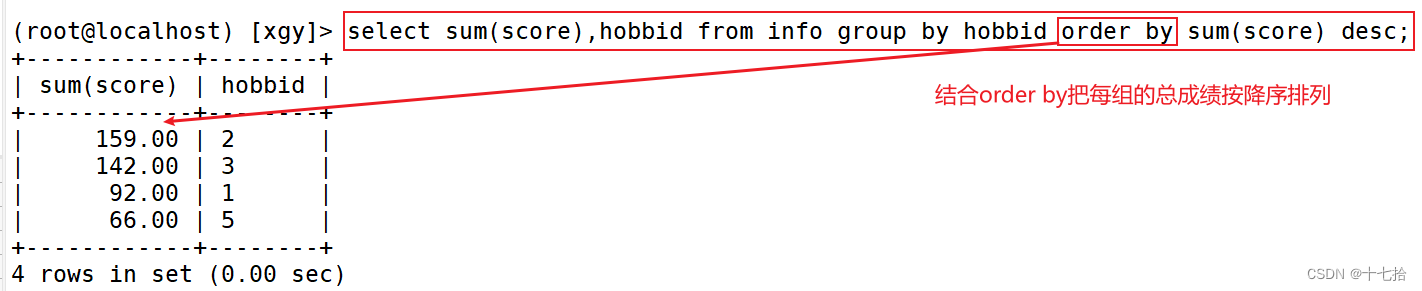
案例三:求和所有学生的总成绩
select sum(score) from info;
1.3 基于聚合函数avg
案例一:按hobbid字段值相同的分组,并对每组求平均成绩
#将hobbid升序排序,并显示其hobbid、name、score字段
select hobbid,name,score from info order by hobbid;
#按hobbid字段值相同的分组,并对每组求平均成绩
select avg(score),hobbid from info group by hobbid;
案例二:求和所有学生的平均成绩
select avg(score) from info;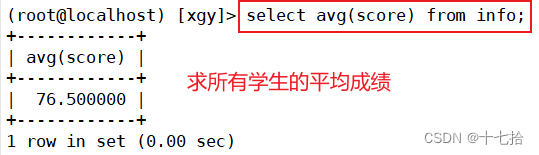
1.4 基于聚合函数max
案例一:按hobbid字段值相同的分组,并显示同一组中最大的id
#按hobbid升序排序,当hobbid字段值相同时再按id降序排序,显示id和hobbid字段
select id,hobbid from info order by hobbid,id desc;
#按hobbid字段值相同的分组,并显示同一组中最大的id
select max(id),hobbid from info group by hobbid;
案例二:查询所有学生中的最高成绩
select max(score),name from info;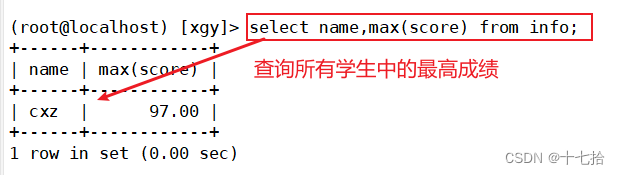
1.5 基于聚合函数min
案例一:按hobbid字段值相同的分组,并显示同一组中最小的id
#按hobbid升序排序,当hobbid字段值相同时再按id升序排序,显示id和hobbid字段
select id,hobbid from info order by hobbid,id;
#按hobbid字段值相同的分组,并显示同一组中最小的id
select min(id),hobbid from info group by hobbid;
案例二:查询所有学生中的最低成绩
select min(score),name from info;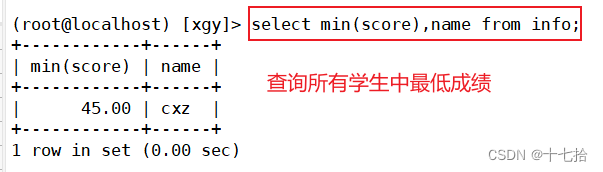
2、常用数学函数
| 数学函数 | 说明 |
|---|---|
| abs(x) | 返回x的绝对值 |
| rand() | 返回0到1的随机数 |
| mod(x, y) | 返回x除以y以后的余数 |
| power(x, y) | 返回x的y次方 |
| round(x) | 返回离x最近的整数 |
| round(x, y) | 保留x的y位小数四舍五入后的值 |
| sqrt(x) | 返回x的平方根 |
| truncate(x, y) | 返回数字x截断为y位小数的值(不四舍五入) |
| ceil(x) | 返回大于或等于x的最小整数 |
| floor(x) | 返回小于或等于x的最大整数 |
| greatest(x1,x2,...) | 返回集合中最大的值 |
| least(x1,x2,...) | 返回集合中最小的值 |
select abs(-1),rand(),mod(5,3),power(2,3);

select truncate(1.89,1);select round(1.89,1);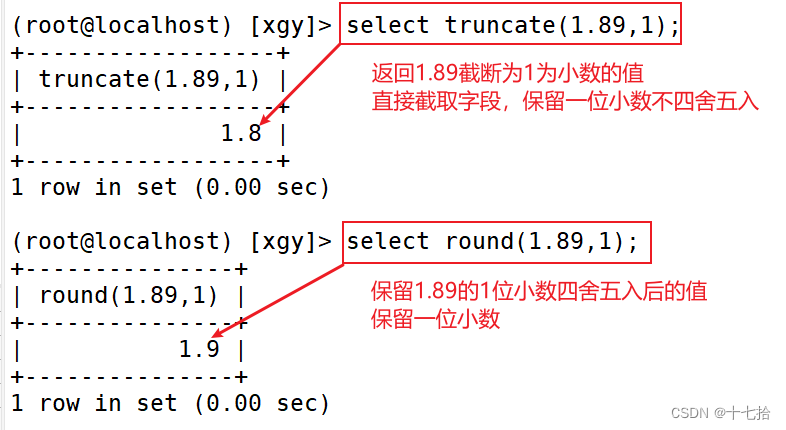
select ceil(1.76);select floor(1.76);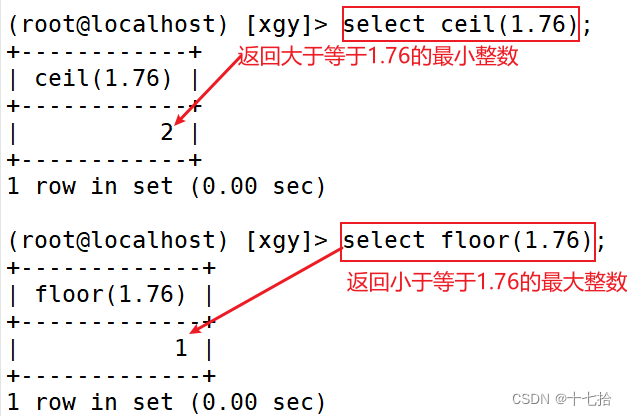
select greatest(20,10.5,30,73.2,33,21.1,66);select least(20,10.5,30,73.2,33,21.1,66);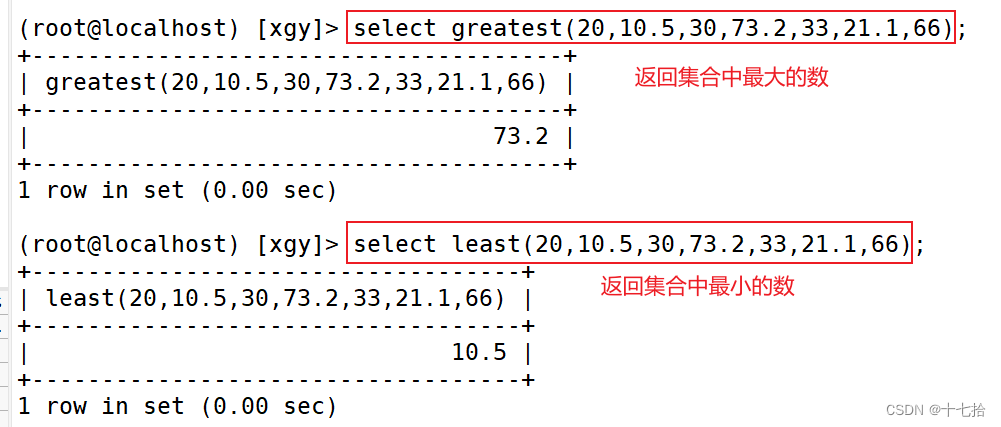
3、字符串函数
| 字符串函数 | 说明 |
|---|---|
| trim() | 返回去除指定格式的值 |
| concat(x,y) | 将提供的参数 x 和 y 拼接成一个字符串 |
| substr(x,y) | 获取从字符串 x 中的第 y 个位置开始的字符串,跟substring()函数作用相同 |
| substr(x,y,z) | 获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串 |
| length(x) | 返回字符串 x 的长度 |
| replace(x,y,z) | 将字符串 z 替代字符串 x 中的字符串 y |
| upper(x) | 将字符串 x 的所有字母变成大写字母 |
| lower(x) | 将字符串 x 的所有字母变成小写字母 |
| left(x,y) | 返回字符串 x 的前 y 个字符 |
| right(x,y) | 返回字符串 x 的后 y 个字符 |
| repeat(x,y) | 将字符串 x 重复 y 次 |
| space(x) | 返回 x 个空格 |
| strcmp(x,y) | 比较 x 和 y,返回的值可以为-1,0,1 |
| reverse(x) | 将字符串 x 反转 |
3.1 去除字符trim
格式:select trim ([ [位置] [要移除的字符串] from ] 字符串);
#[位置]:值可以为 leading (起头), trailing (结尾), both (起头及结尾)
#[要移除的字符串]:从字串的起头、结尾,或起头及结尾移除的字符串。缺省时为空格select trim(leading 'h' from 'hello');
select trim(trailing 'o' from 'hello');
select trim(both 'l' from 'laybl');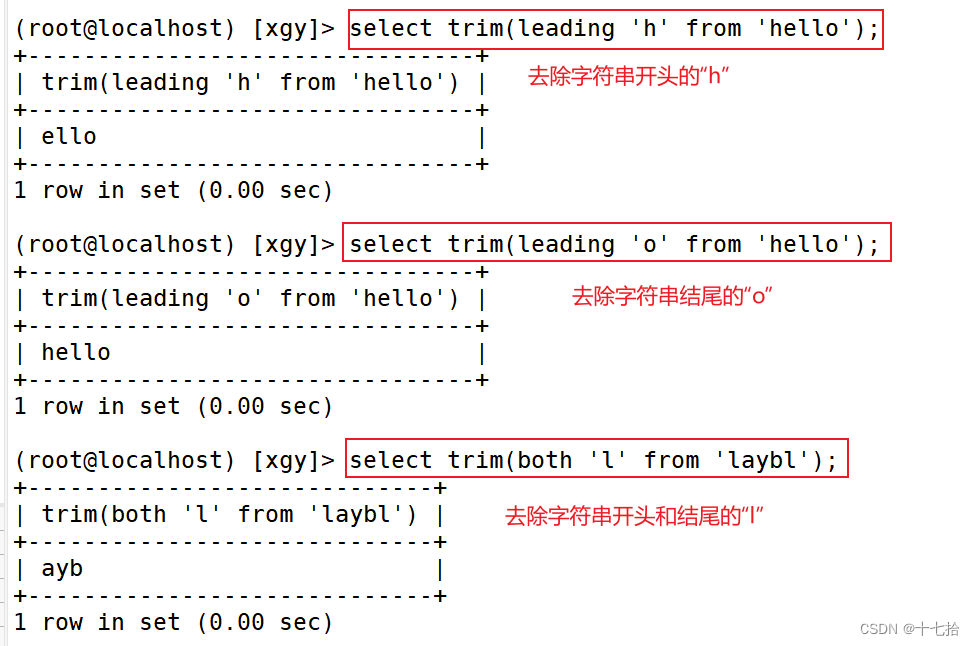
3.2 截取字符串substr
substr(x,y) #截取x字符串 从第y个开始,截取到末尾
substr(x,y,z) #截取x字符串 从第y个开始截取 ,截取长度为zselect substr(address,2) from info;
select substr(address,2,1) from info;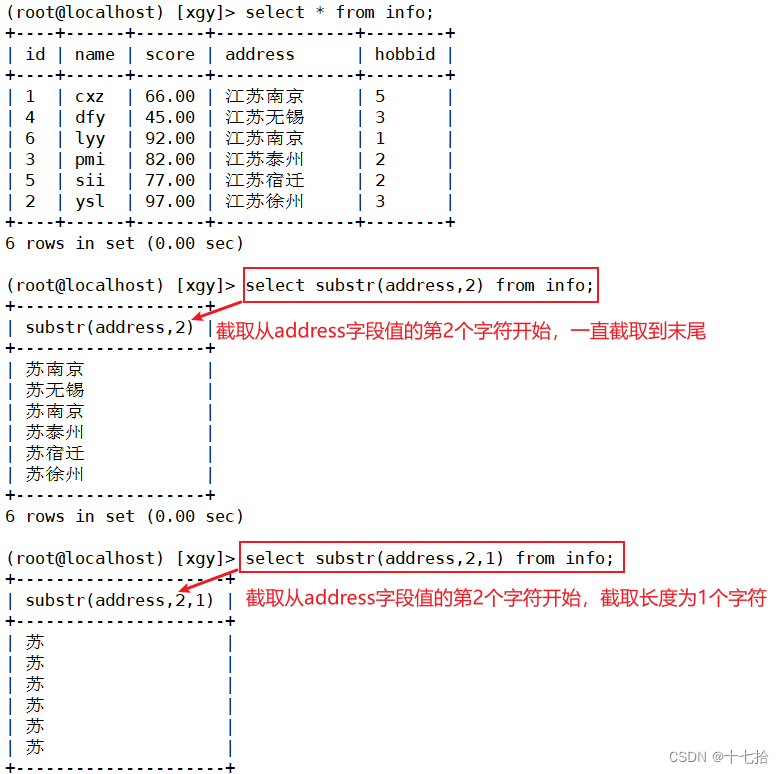
3.3 字段拼接
格式:select concat(字段名1,字段名2,……) from 表名;select concat(id,address) from info;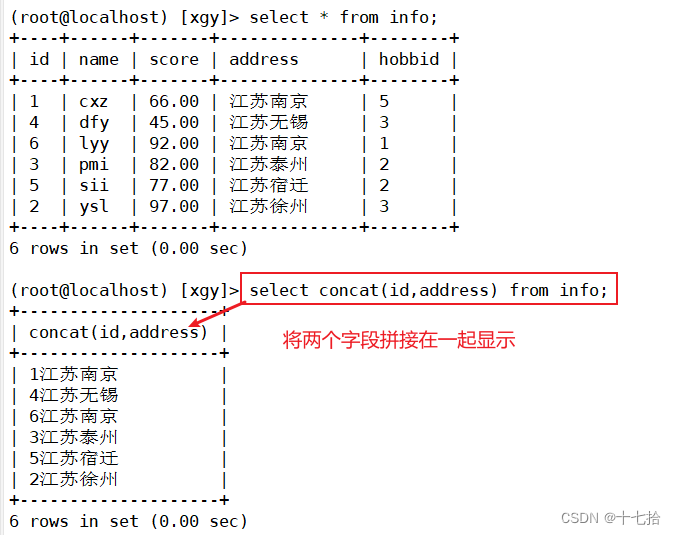
#使用 || 符号
#将info表中,id字段值和address字段值拼接在一起
select id || address from info;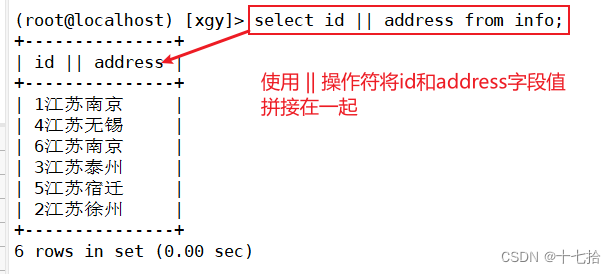
#将info表中,id字段值和address字段值拼接在一起,且中间加空格select id || ' ' || address from info;
3.4 返回字符长度length
格式:select length(字段名) from 表名;#返回info表中name字段所有行的字符长度
select length(name) from info;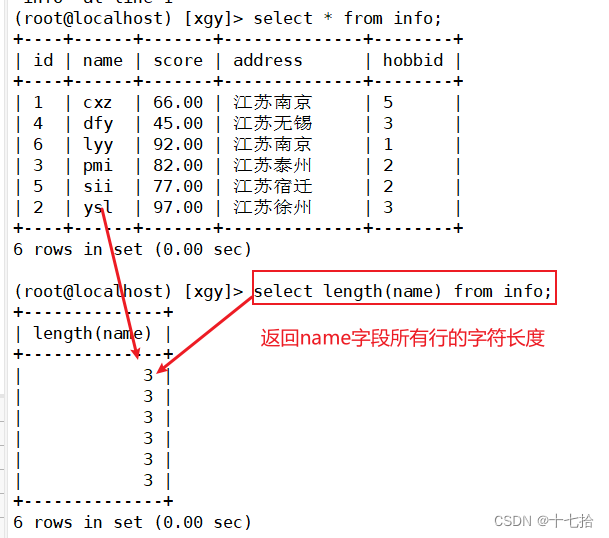
3.5 替换replace
格式:select replace(字段,'原本值','新值') from info;select replace(address,'南京','扬州') from info;
4、日期时间函数
| 字符串函数 | 说明 |
|---|---|
| curdate() | 返回当前时间的年月日 |
| curtime() | 返回当前时间的时分秒 |
| now() | 返回当前时间的日期和时间 |
| month(x) | 返回日期 x 中的月份值 |
| week(x) | 返回日期 x 是年度第几个星期 |
| hour(x) | 返回 x 中的小时值 |
| minute(x) | 返回 x 中的分钟值 |
| second(x) | 返回 x 中的秒钟值 |
| dayofweek(x) | 返回 x 是星期几,1 星期日,2 星期一 |
| dayofmonth(x) | 计算日期 x 是本月的第几天 |
| dayofyear(x) | 计算日期 x 是本年的第几天 |
三、限制结果条目(limit)
在使用 MySQL SELECT 语句进行查询时,结果集返回的是所有匹配的记录(行)。有时候仅需要返回第一行或者前几行,这时候就需要用到 limit 子句
格式:select 字段 from 表名 limit [offset,] number;#limit 的第一个参数是位置偏移量(可选参数),是设置 mysql 从哪一行开始
#如果不设定第一个参数,将会从表中的第一条记录开始显示
#offset 为索引下标,指定从哪一行开始返回结果,它是从0开始的索引,即第一行是0,第二行是1,依此类推
#number 为索引下标后的几位
1、查询前n行记录
格式:select 字段 from 表名 limit number;
案例一:查询前3行记录
select * from info limit 3;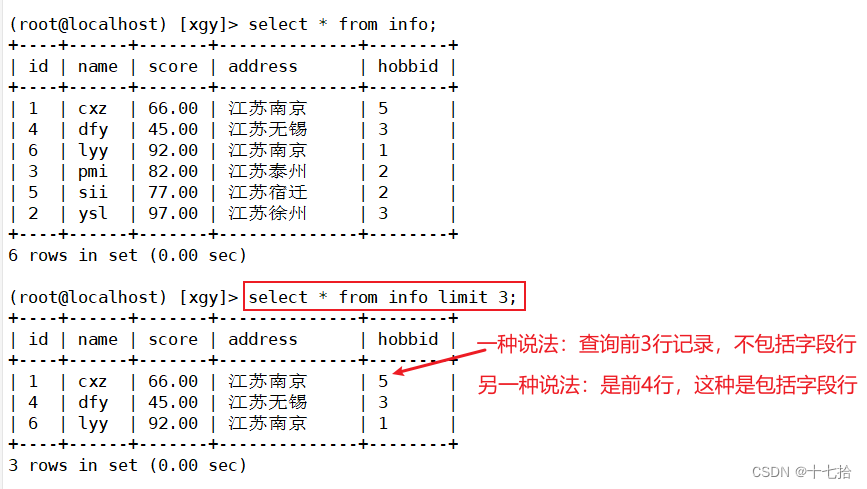
案例二:查询前5行,分数大于70的记录,显示id、name、score列
select id,name,score from info where score > 70 limit 5;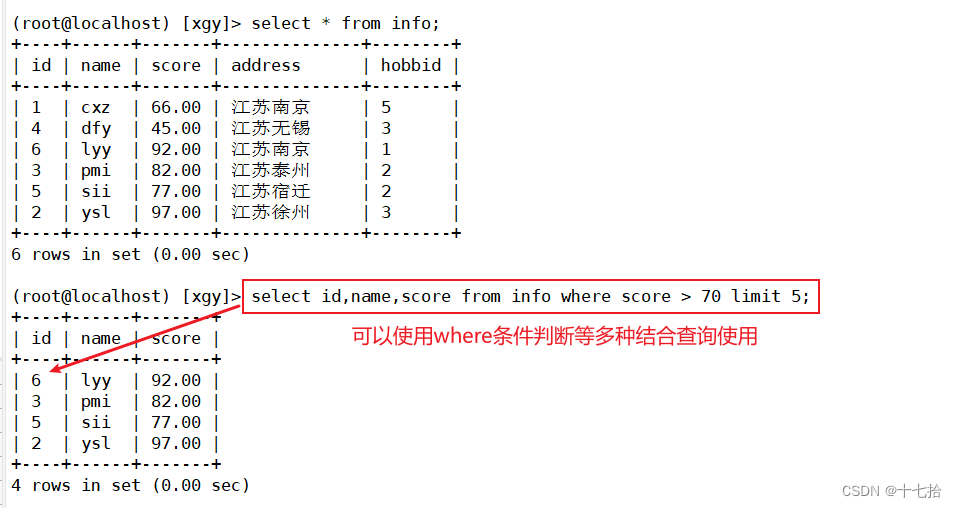
2、查询前n行后m行记录
案例一:查询前3行后的两行记录
select * from info limit 3,2;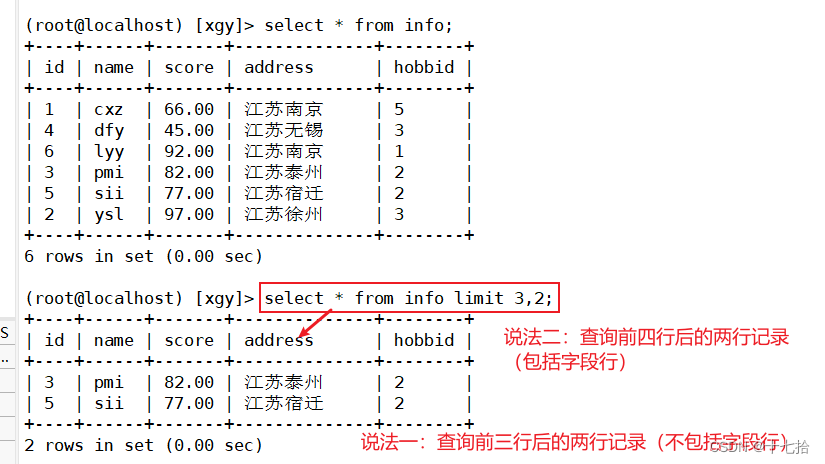
案例二:按id升序排序,查询前三行后两行记录,显示id、name、score列
select id,name,score from info order by id limit 3,2;
3、查询某个单独行的记录
#查询第一行记录
select * from info limit 1;
#查询第四行记录
select * from info limit 3,1;
#查询第五行记录
select * from info limit 4,1;

四、设置别名alias
在 MySQL 查询时,当表的名字比较长或者表内某些字段比较长时,为了方便书写或者多次使用相同的表,可以给字段列或表设置别名。使用的时候直接使用别名,简洁明了,增强可读性。
使用场景:
- 对复杂的表进行查询的时候,别名可以缩短查询语句的长度
- 多表相连查询的时候(通俗易懂、减短sql语句)
1、设置字段的别名
select 字段名 as 字段别名 from 表名;
#在使用 as 后,可以用 字段别名 代替 字段名,其中 as 语句是可选的。as 之后的别名,主要是为表内的列提供临时的名称,在查询过程中使用,库内实际的字段名是不会被改变的案例一: 查询整个表共有多少条数据,以number字段显示
select count(*) as number from info;
select count(*) number from info;
#加不加as都能设置字段别名
案例二: 按hobbid字段值相同的分组,并求和每组的总成绩,以“总成绩”字段显示
#将hobbid升序排序,并显示其hobbid、name、score字段
select hobbid,name,score from info order by hobbid;
#按hobbid字段值相同的分组,并求和每组的总成绩,以“总成绩”字段显示
select sum(score) as '总成绩',hobbid from info group by hobbid;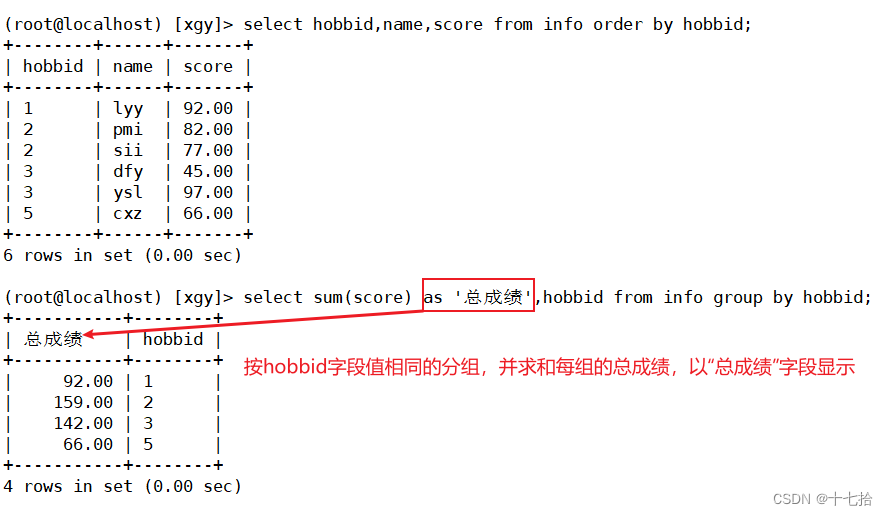
案例三:为查询结果的字段设置别名
select name 姓名,score 成绩,address 地址 from info;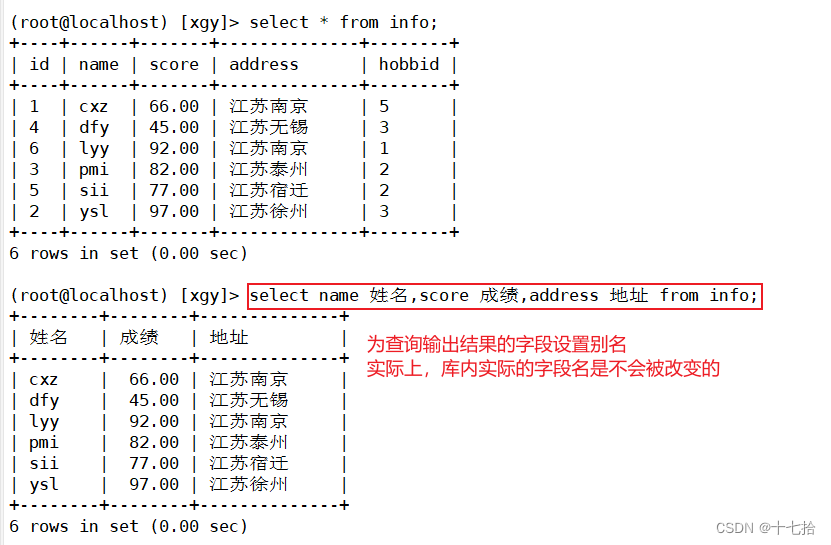
2、设置表的别名
当在查询中涉及多个表时,为表设置别名可以简化查询语句并避免歧义
select 字段 from 表名 as 表别名;
#在使用 as 后,可以用 表别名 代替 表名,其中 as 语句是可选的。as 之后的别名,主要是为表提供临时的名称,在查询过程中使用,库内实际的表名是不会被改变的select i.name 姓名,i.score 成绩,i.address 地址 from info as i;
3、as作为连接语句的操作符
create table info2 as select * from info;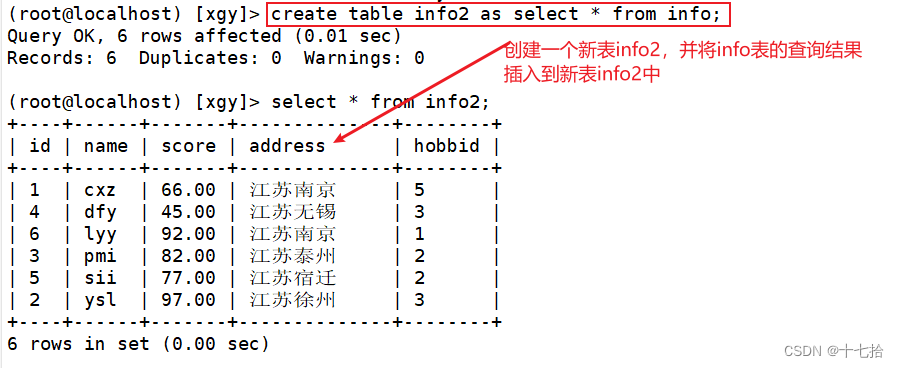
注:
此处AS起到的作用:
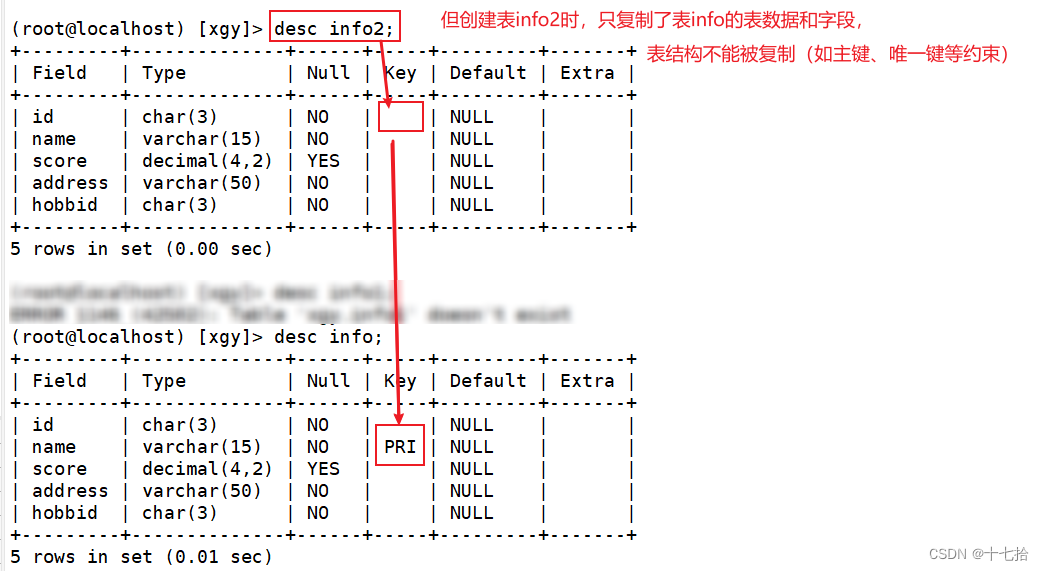
1、创建了一个新表info2并定义表结构,插入表数据(与info表相同)
2、但是”约束“没有被完全”复制“过来,但是如果原表设置了主键,那么附表的default字段会默认设置一个0
相似:和克隆、复制表结构相似 create table t1 (select * from info);
也可以加入where语句来进行判断
create table info3 as select * from info where score >=70;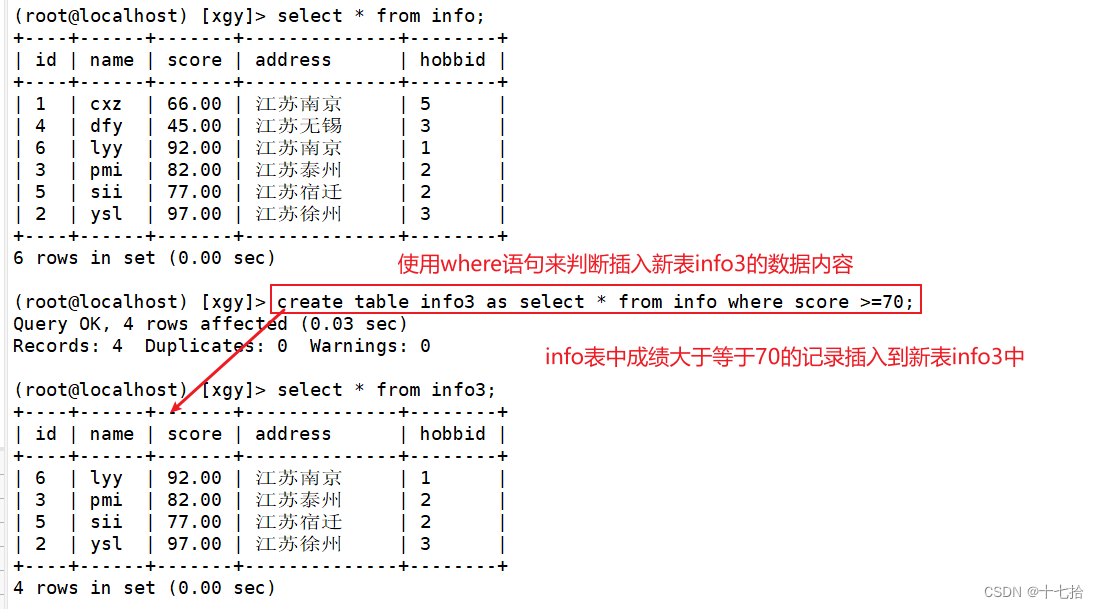
注:
在为表设置别名时,要保证别名不能与数据库中的其他表的名称冲突
列的别名是在结果中有显示的,而表的别名在结果中没有显示,只在执行查询时使用
五、通配符like
通配符主要用于替换字符串中的部分字符,通过部分字符的匹配将相关结果查询出来
通常通配符都是跟like一起使用,并协同where子句共同来完成查询任务
常用的通配符有两个:
%:代表零个、一个或多个字符
_:下划线代表单个字符| 通配符 | 含义 |
|---|---|
| % | 表示零个,一个或者多个字符 |
| _ | 下划线表示单个字符 |
| A_Z | 所有以A开头,中间任意一个字符,Z结尾的字符串 |
| ABC% | 所有以ABC开头的字符串 |
| %CBA | 所有以CBA结尾的字符串 |
| %AB% | 所有包含AB的字符串 |
| _AB% | 所有以任意一个字符开头,第二个字母为 A,第三个字母为B的字符串 |
1、查询以某字符开头的记录
select 字段 from 表名 where 字段 like ‘确定字符%’;select id,name,score from info where name like 'l%';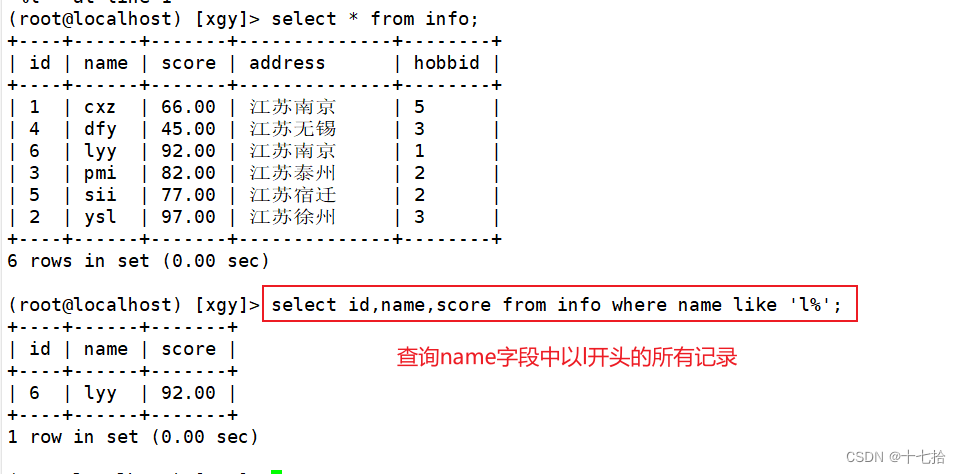
select id,name,score from info where name like 'l__';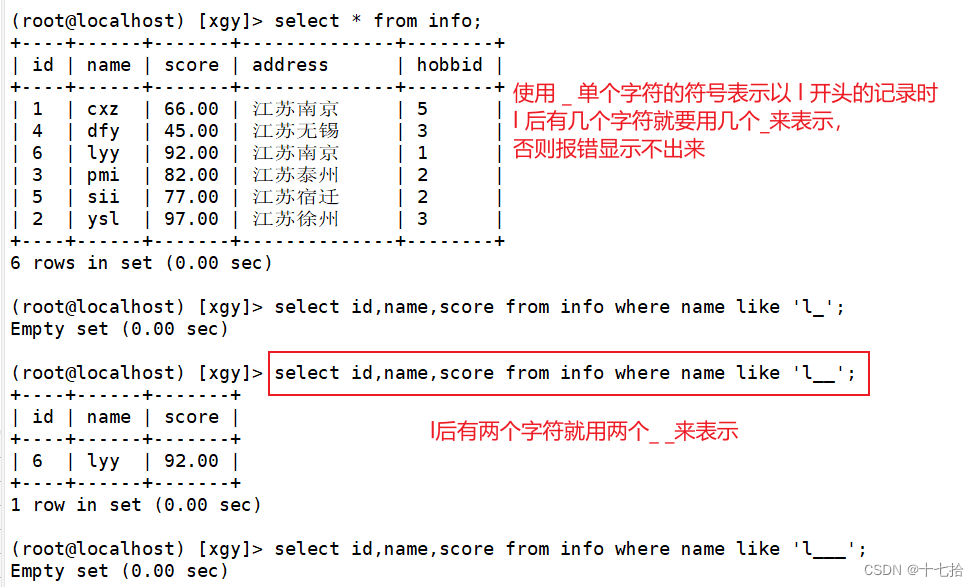
2、查询以某字符结尾的记录
select 字段 from 表名 where 字段 like ‘%确定字符’;select id,name,score from info where name like '%yy';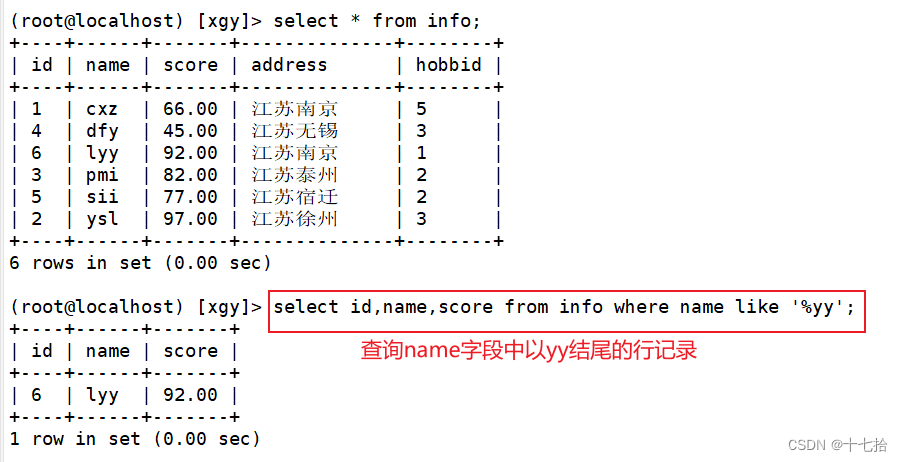
3、查询只要有某字符的记录
select 字段 from 表名 where 字段 like ‘%确定字符%’;select id,name,score from info where name like '%s%';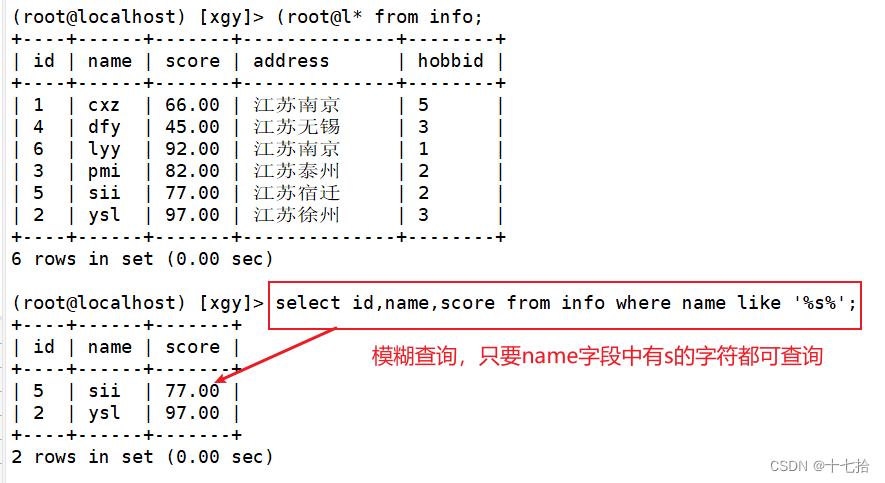
4、查询具体到任意单个字符的记录
select 字段 from 表名 where 字段 like ‘字符_字符__字符’;select id,name,score from info where name like 'p_i';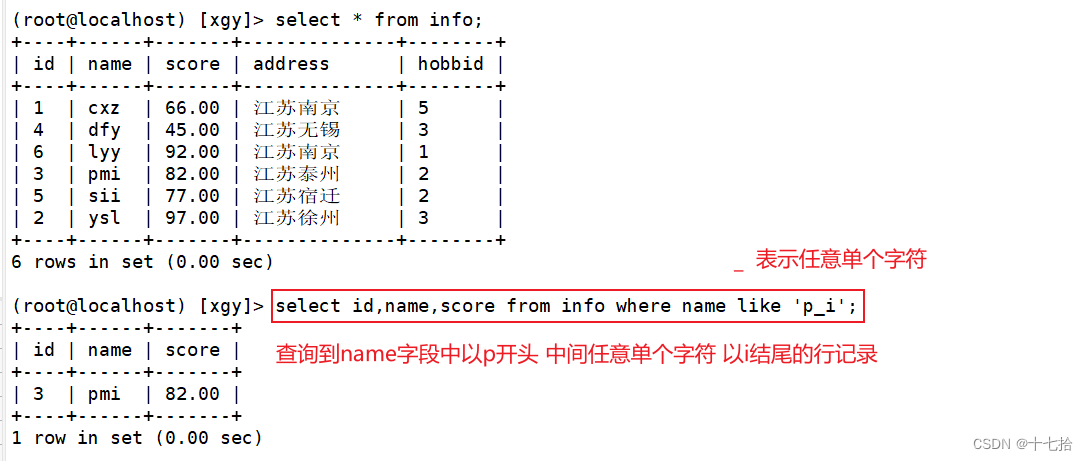
select id,name,score from info where name like '__y';
5、常用字符结合查询
select id,name,score from info where name like 'c%_%z';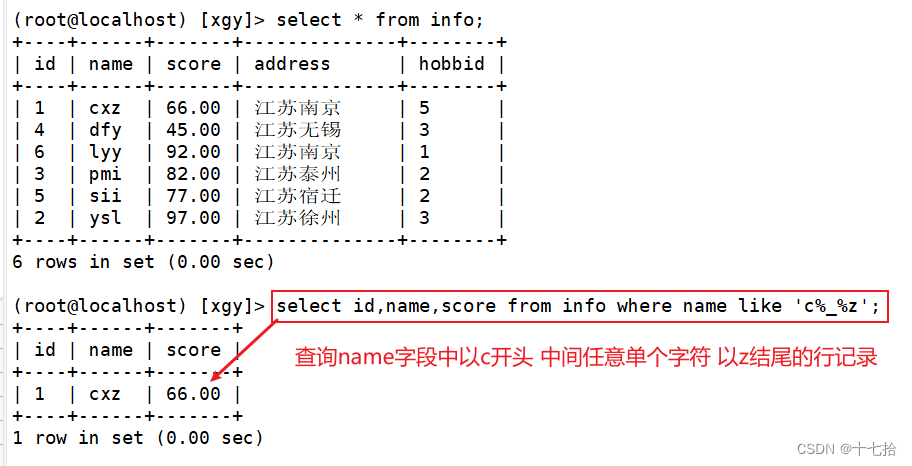
六、子查询
1、子查询与IN操作符概述
1.1 子查询概念
MySQL数据库中的子查询是一种嵌套查询,即一个查询语句内部包含另一个查询语句
子查询可以出现在select、insert、update或delete语句中,以及set或do语句中。它们通常用于比较值、计算数据或者作为条件来限制数据的选择范围
子查询语句是先于主查询语句被执行的,其结果作为外层的条件返回给主查询进行下一 步的查询过滤
子语句可以与主语句所查询的表相同,也可以是不同表
格式:select 字段1,字段2 from 表名1 where 字段 in (select 字段 from 表名 where 条件判断语句);1.2 IN操作符概念
允许在where子句中指定一个值列表,然后从表中选择列值与这个列表中任何一个值相匹配的行。简而言之,IN可以在单个查询中对多个值进行条件匹配
也用来判断某个值是否在给定的结果集中,通常结合子查询来使用
<表达式> [not] in <子查询>#当表达式与子查询返回的结果集中的某个值相等时,返回 true,否则返回 false
#若启用了 not 关键字,则返回值相反。需要注意的是,子查询只能返回一列数据,如果需求比较复杂,一列解决不了问题,可以使用多层嵌套的方式来应对
#多数情况下,子查询都是与 select 语句一起使用的2、select
2.1 单表查询
select name,score from info where id in (select id from info where score >80);
#主语句:select name,score from info where id;
#子语句(集合):select id from info where score >80;
#子语句中的sql语句是为了最后过滤出一个结果集,用于主语句的判断条件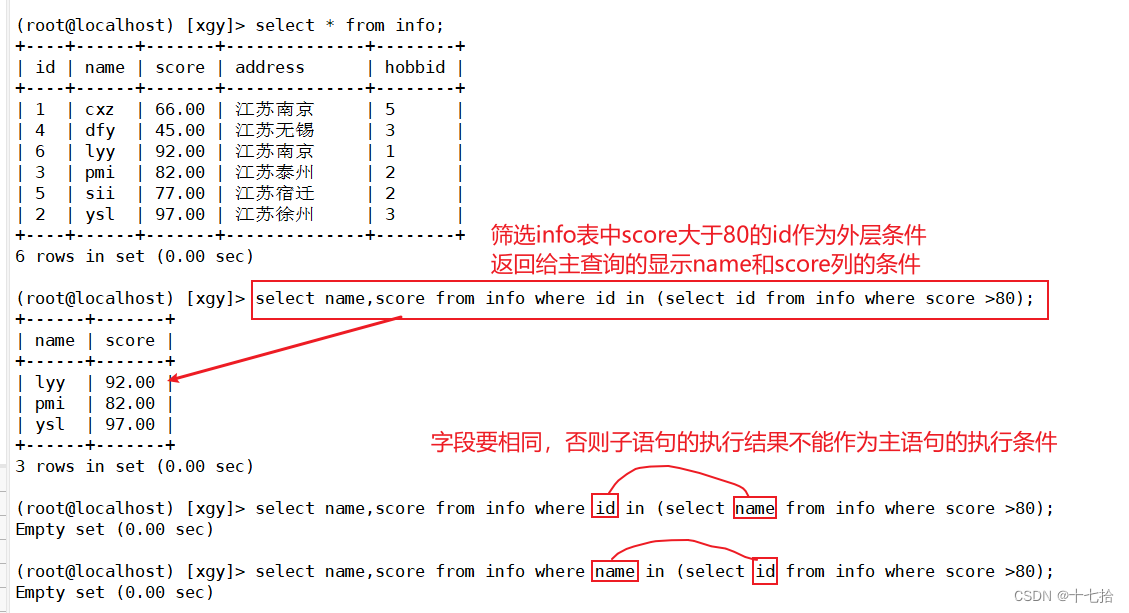
2.2 多表查询
select id,name,score from info where id in (select id from test);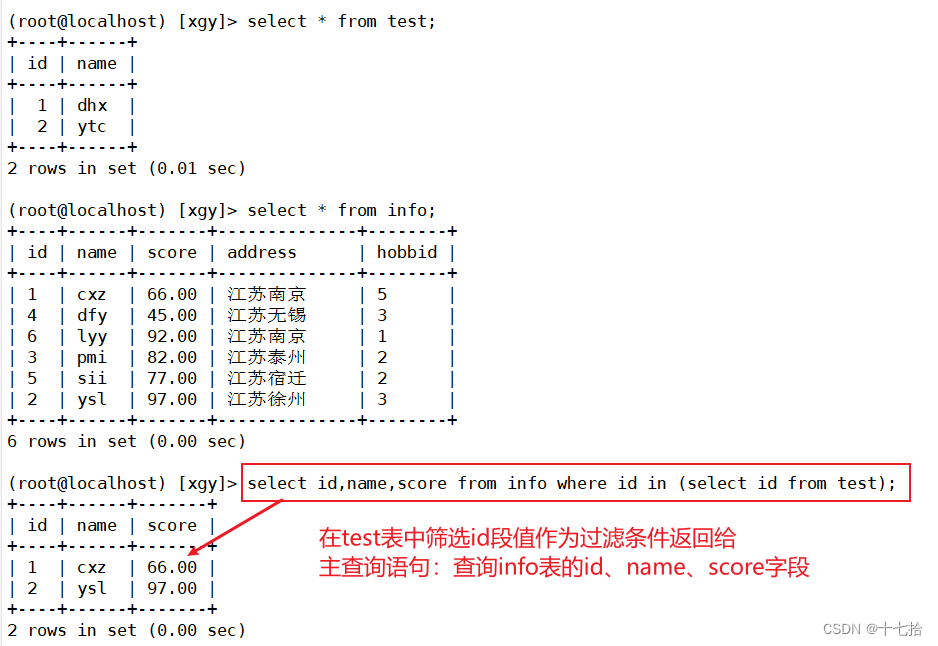
子语句可结合where,筛选info3表中分数大于85的id给主语句的info表查询
select id,name,score from info where id in (select id from info3 where score > 85);
2.3 将子语句的结果取反not
select id,name,score from info where id not in (select id from info3 where score > 85);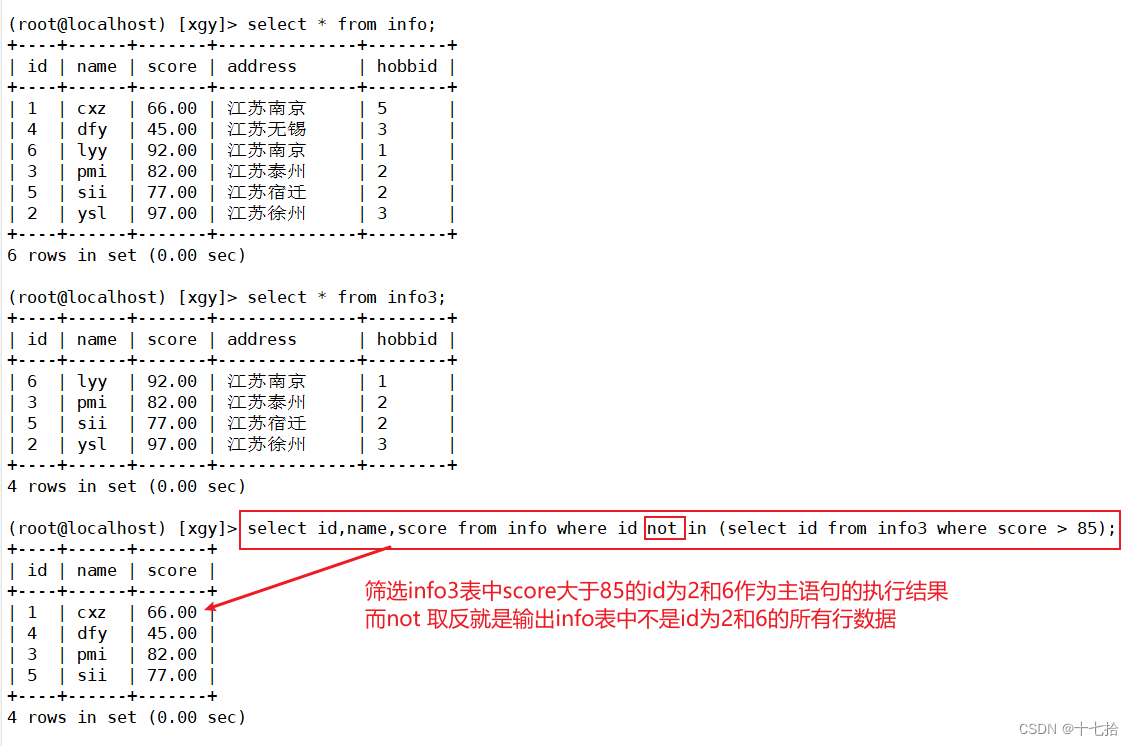
3、insert
子查询还可以用在insert语句中,子查询的结果集可以通过insert语句插入到其它表中
insert into class select * from info where id in (select id from test);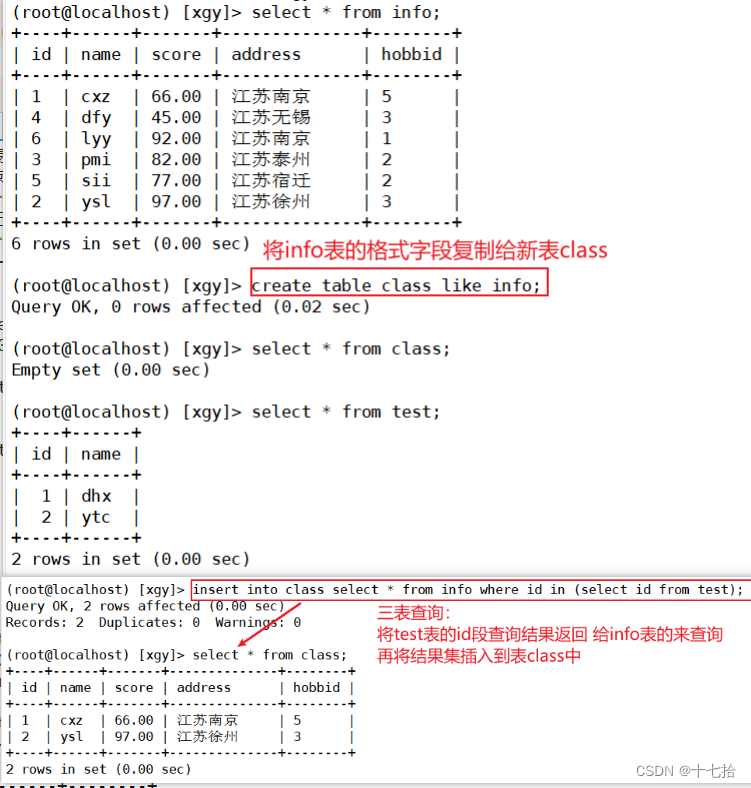
4、update
update语句也可以使用子查询,update内的子查询,在set更新内容时,可以是单独的一行一列,也可以是多行单列
#更新单行单列数据
update info set score=100 where id in (select id from test where id=2);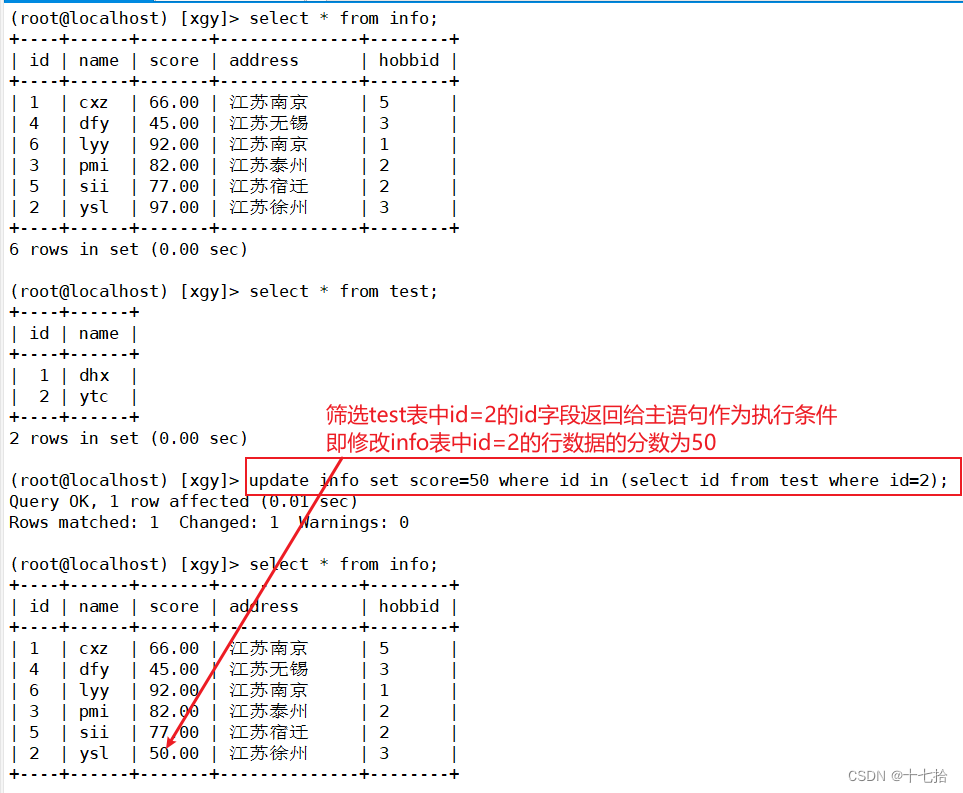

#更新多行单列数据
update info set score=99 where id in (select id from test where id<=2);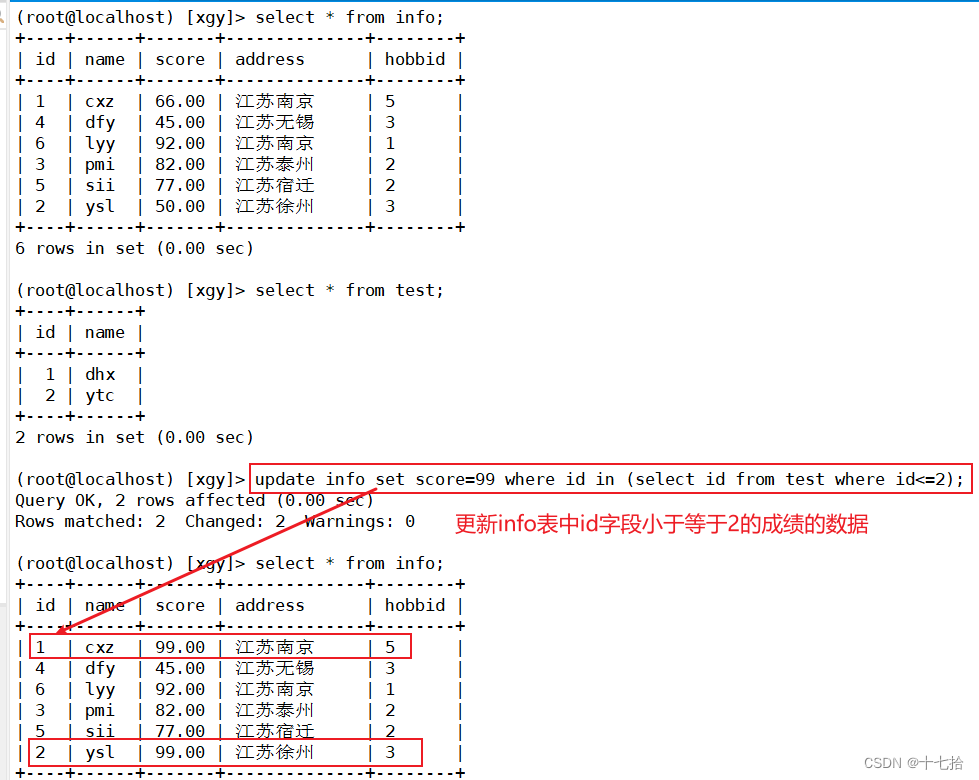
5、delete
使用子查询的delete语句允许根据另一个查询的结果来删除记录。这种方式特别有用于删除那些满足特定关联条件的行,而这些条件可能需要通过查询其他表来确定
delete from info where id in (select id from info3 where score > 85);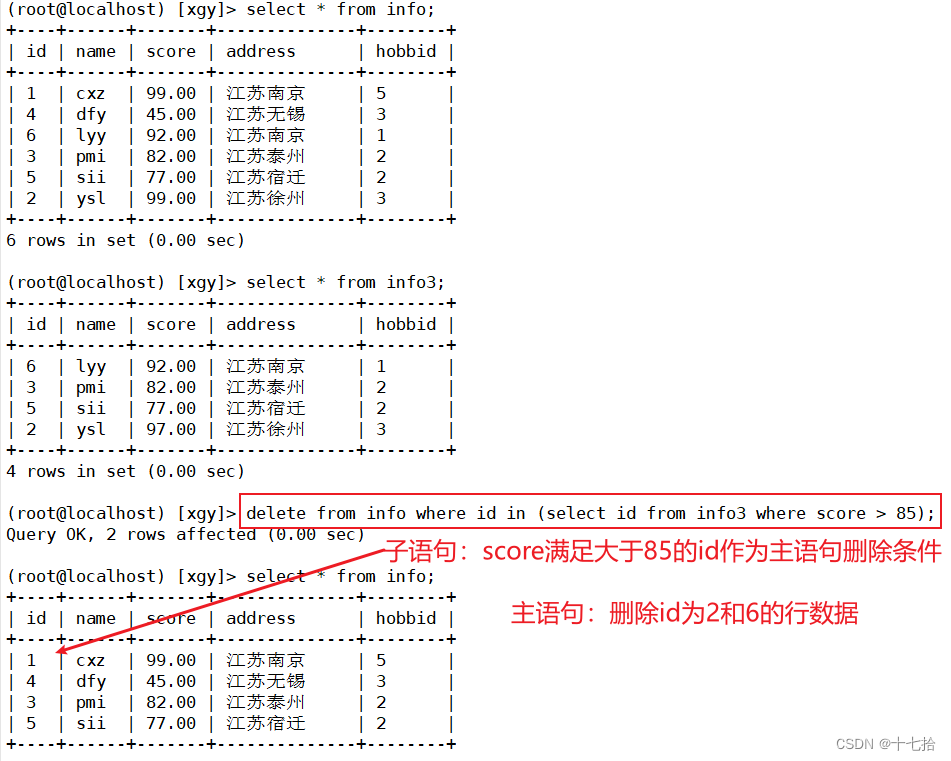
6、exists
exists这个关键字在子查询时,主要用于判断子查询的结果集是否为空,如果不为空,则返回true,反之则返回false
在使用exists时,当子查询有结果时,不关心子查询的内容,执行主查询操作;当子查询没有结果时,则不执行主查询操作
#当子语句查询结果不为空时返回true,立即执行主语句
select count(*) from info where exists(select id from info3 where score>85);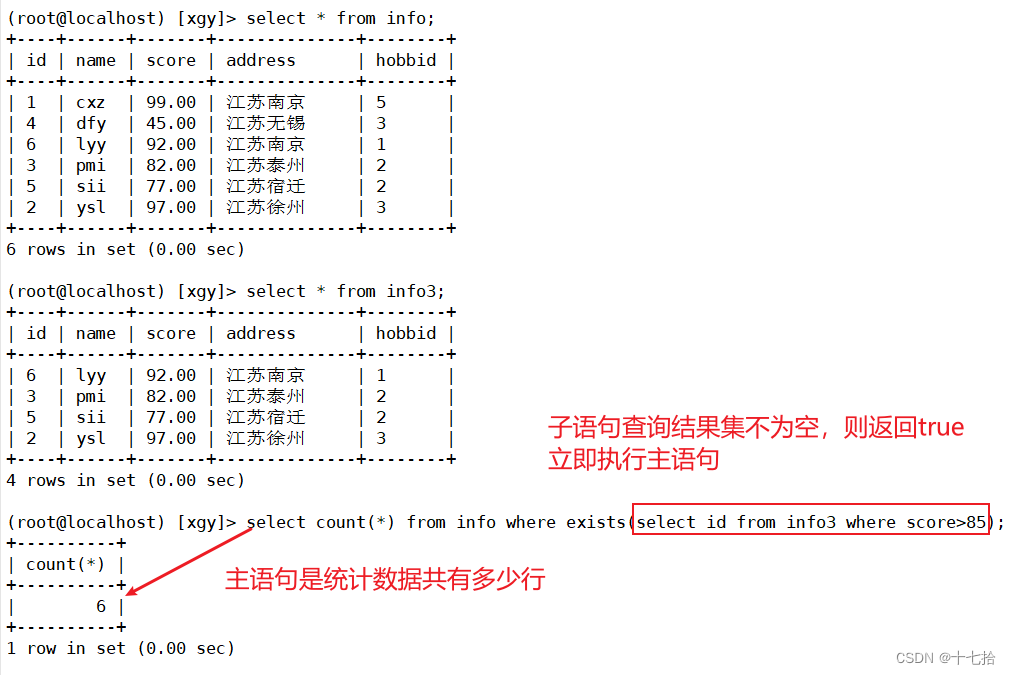
#当子语句查询结果为空时返回false,不执行主语句
select count(*) from info where exists(select id from info3 where score=80);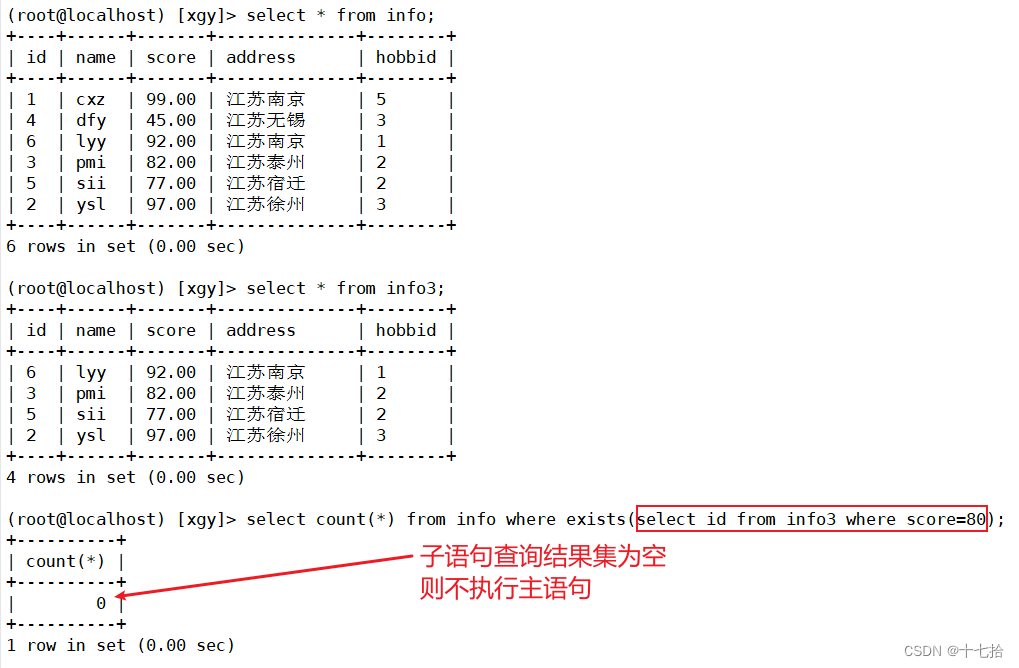
7、as别名
将结果集作为一张表进行查询的时候,需要用到别名
select a.id,a.name from (select id,name from info) a;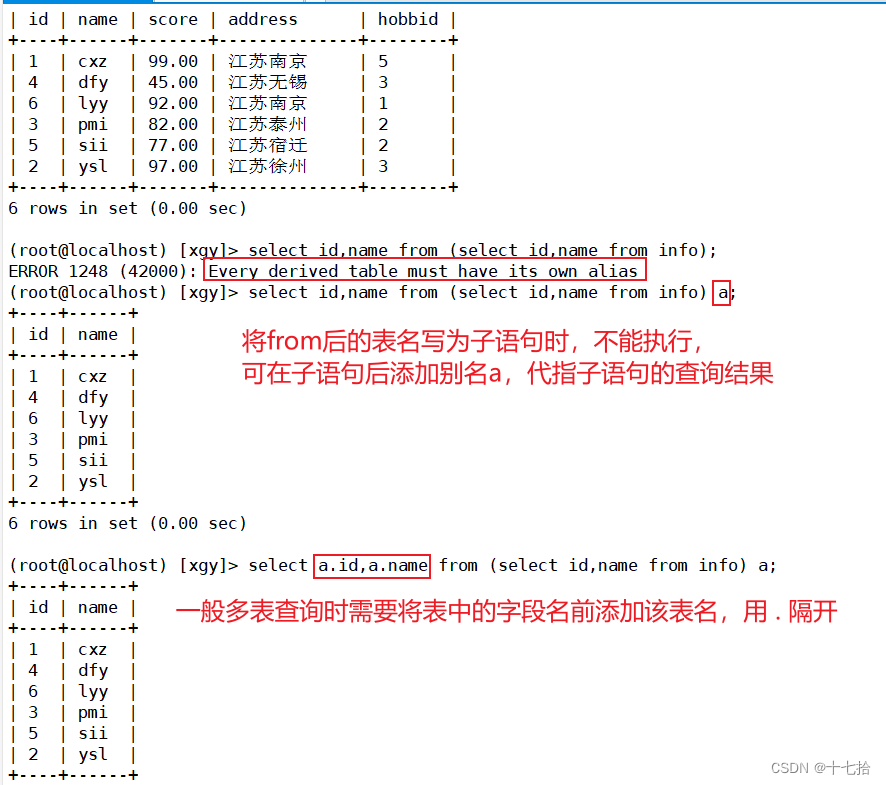
七、视图(优化Mysql数据库)
1、视图概念与功能
数据库中的虚拟表,不包含真实数据,只是映射;简化SQL语句,简化查询结果集、灵活查询,针对不同的用户呈现不同的结果集;只适合查询,不适合增删改。视图有表之后才能存在,它的内容都来自基本表,一个视图可对应一个或多个基本表。
2、视图与基本表的区别和联系
① 视图是已经编译好的sql语句,表不是
② 视图没有实际的物理记录,表有
③ 表占用物理空间,而视图不占用,视图是逻辑概念存在;表可即时修改,但视图只能由创建的语句来修改
④ 视图是查看数据表的一种方法,可以查询数据表中某些字段构成的数据,从安全角度来说,用户接触不到表结构
⑤ 表属于全局模式中的实表;视图属于局部模式的虚表
⑥ 视图的建立和删除只影响视图本身,不影响对应的基本表。当更新视图数据,会影响到基本表
3、视图的基本用法
#创建视图
create view 视图表名 as select * from 表名 where 条件;
#查看视图
select * from 视图表名;
#查看表和视图的状态信息
show table status\G;
#查看视图结构
desc 视图表名;
#修改视图
update 视图表名 set 字段=新值 where 条件判断;
#删除视图
drop view [if exists] 视图名;3.1 创建视图
#创建视图
create view 视图表名 as select * from 表名 where 条件;3.1.1 单表创建
#单表创建视图
create view v_1 as select * from info where score<85;
select * from v_1; #查看视图
show table status\G; #查看表和视图的状态信息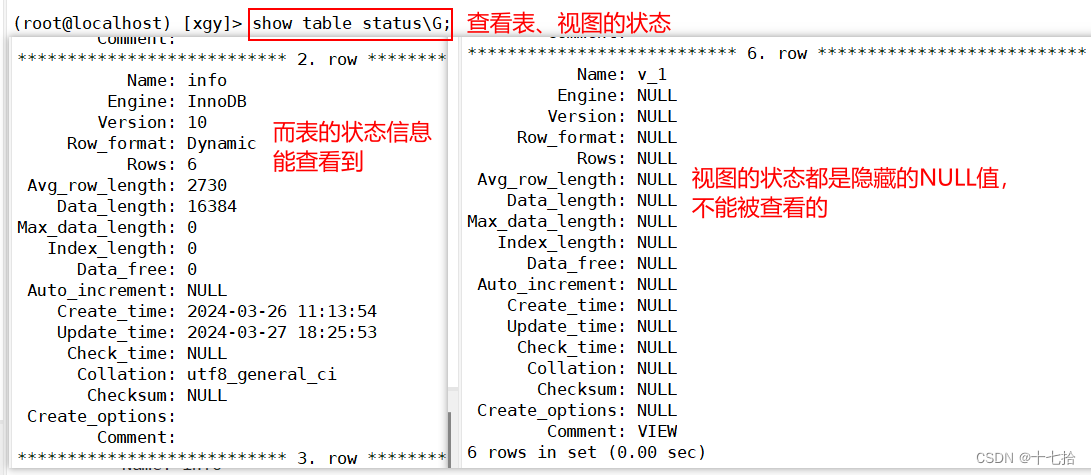
3.1.2 多表创建
create view v_2 (id,name,score,age) as select a.id,a.name,a.score,b.age from info a,web b where a.name=b.name;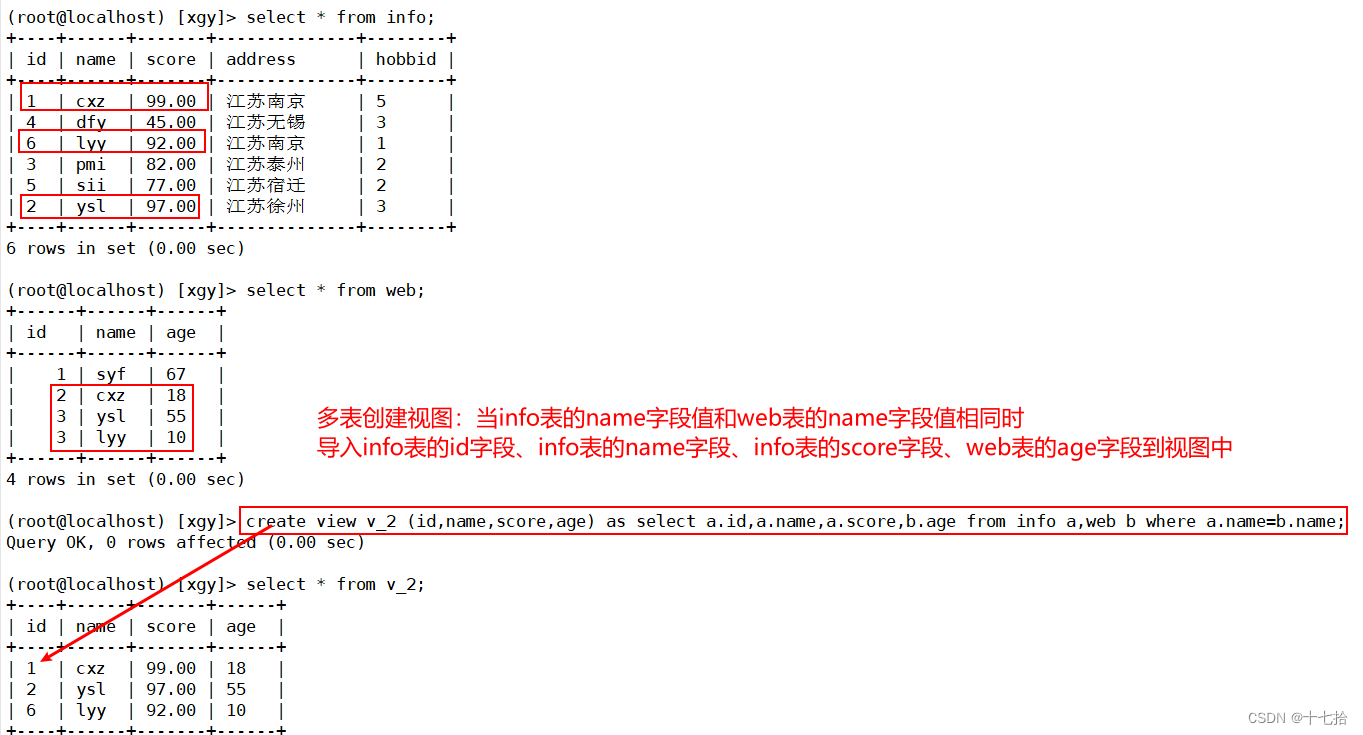
3.2 修改视图数据
格式:update 视图表名 set 字段=新值 where 条件判断;#修改视图数据
update v_2 set score=60 where name='cxz';
注:
当通过视图修改了数据,实际上是在修改视图所引用的基础表中的数据。这意味着对视图的修改会影响到基础表
#修改表数据
update info set score=20 where name='cxz';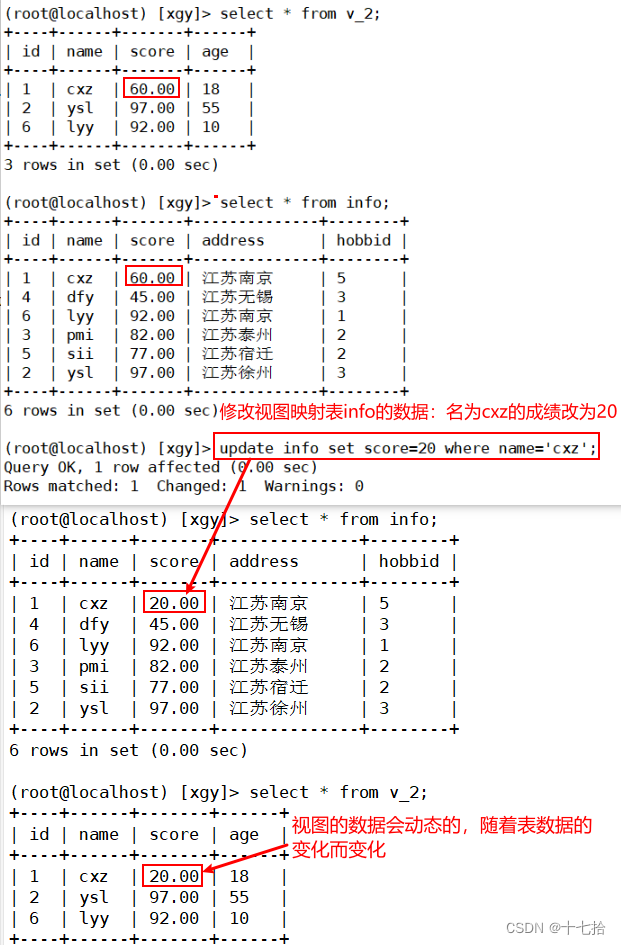
注:
当修改了表的数据,与该表相关联的视图将会反映这些变化。当查询视图时,它会动态地显示基础表的数据
3.3 删除视图
格式:drop view [if exists] 视图名;drop view v_1;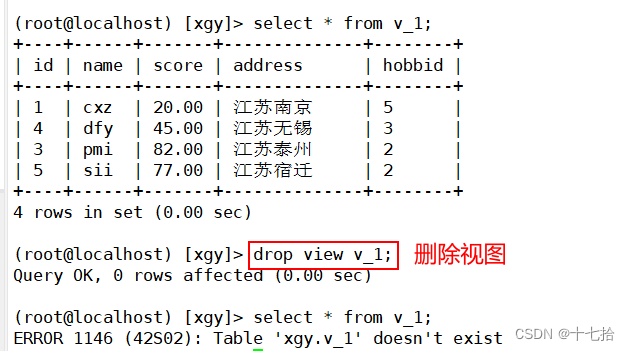
八、NULL值
在 SQL 语句使用过程中,经常会碰到 NULL 这几个字符。通常使用 NULL 来表示缺失的值,也就是在表中该字段是没有值的。
如果在创建表时,限制某些字段不为空,则可以使用 NOT NULL 关键字,不使用则默认可以为空。
如果在向表内插入记录或者更新记录时,如果该字段没有 NOT NULL 并且没有值,这时候新记录的该字段将被保存为 NULL。
NULL 值与数字 0 或者空白(spaces)的字段是不同的,值为 NULL 的字段是没有值的。在 SQL 语句中,使用 ls null 可以判断表内的某个字段是不是 NULL 值,相反的用 ls not null可以判断不是NULL值
NULL值与空值的区别:
- 空值长度为0,不占空间,NULL值的长度为null,占用空间
- ls null可判断是不是NULL值,却无法判断空值
- 空值使用"=“或者”<>"来处理(!=)
- count() 计算时,NULL会忽略,空值会加入计算
#查看null值、空值、abc字符串的字符长度
select length(null),length(''),length('abc');
alter table info add length varchar(50);
alter table info add age varchar(50) not null;
#将info表id字段值小于等于2的行数据的length字段值改为空值
update info set length='' where id<=2;
#查询指定字段是否为NULL值
select * from info where length is null; #查询length字段是NULL值的行记录
select * from info where length is not null; #查询length字段是不NULL值的行记录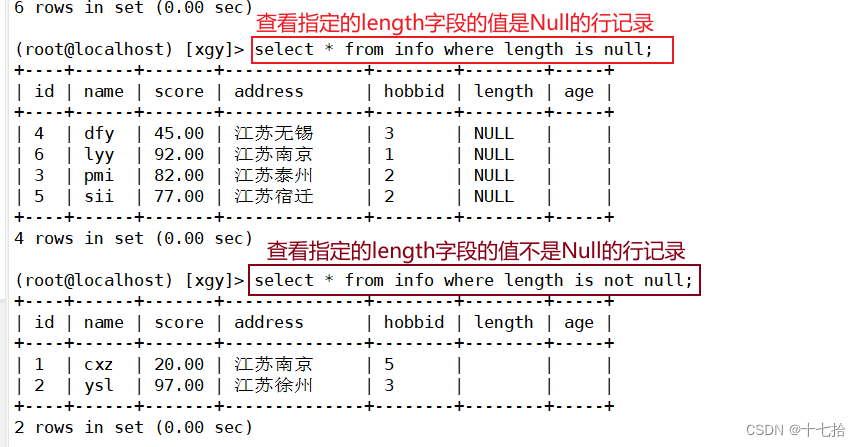
#count统计数量时,NULL值不会参与计数,但空值会参与计数
select count(length) from info;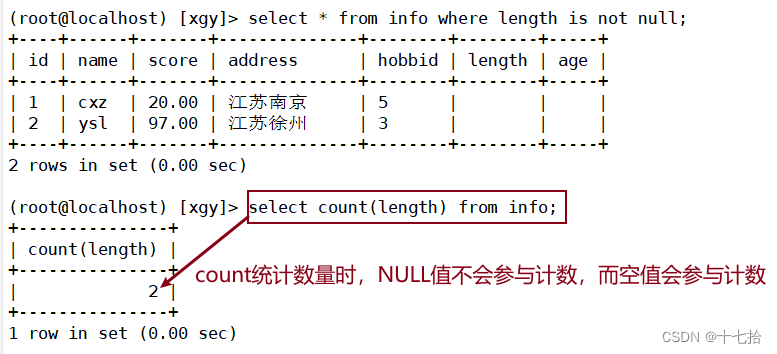
九、连接查询
在MySQL中,连接查询是一种用于检索数据的方法,它可以从一个以上的表中获取数据,并将它们关联起来。这种查询通常使用JOIN子句来实现
1、内连接
内连接就是两张或多张表中同时符合某种条件的数据记录的组合。
通常在 from 子句中使用关键字 inner join 来连接多张表,并使用 on 子句设置连接条件,内连接是系统默认的表连接,所以在 from 子句后可以省略 inner 关键字,只使用 关键字 join。同时有多个表时,也可以连续使用 inner join 来实现多表的内连接,不过为了更好的性能,建议最好不要超过三个表
格式:select 表1[2].字段1,表1[2].字段2,... from 表1 inner join 表2 on 表1.同名字段=表2.同名字段;select info.id,info.name from info inner join web on info.name=web.name;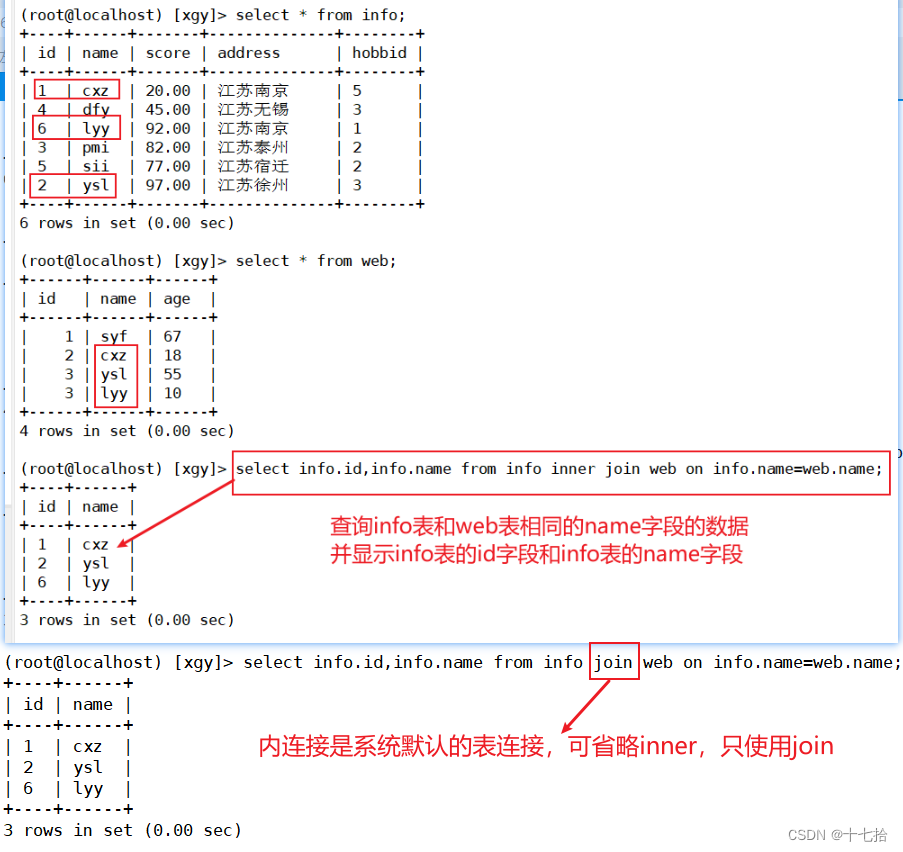
2、左连接
左连接也可以被称为左外连接,在 from 子句中使用 left join 或者 left outer join 关键字来表示。左连接以左侧表为基础表,接收左表的所有行,并用这些行与右侧参考表中的记录进行匹配,也就是说匹配左表中的所有行以及右表中符合条件的行
格式:select * from 表1 left join 表2 on 表1.同名字段=表2.同名字段;select * from info left join web on info.name=web.name;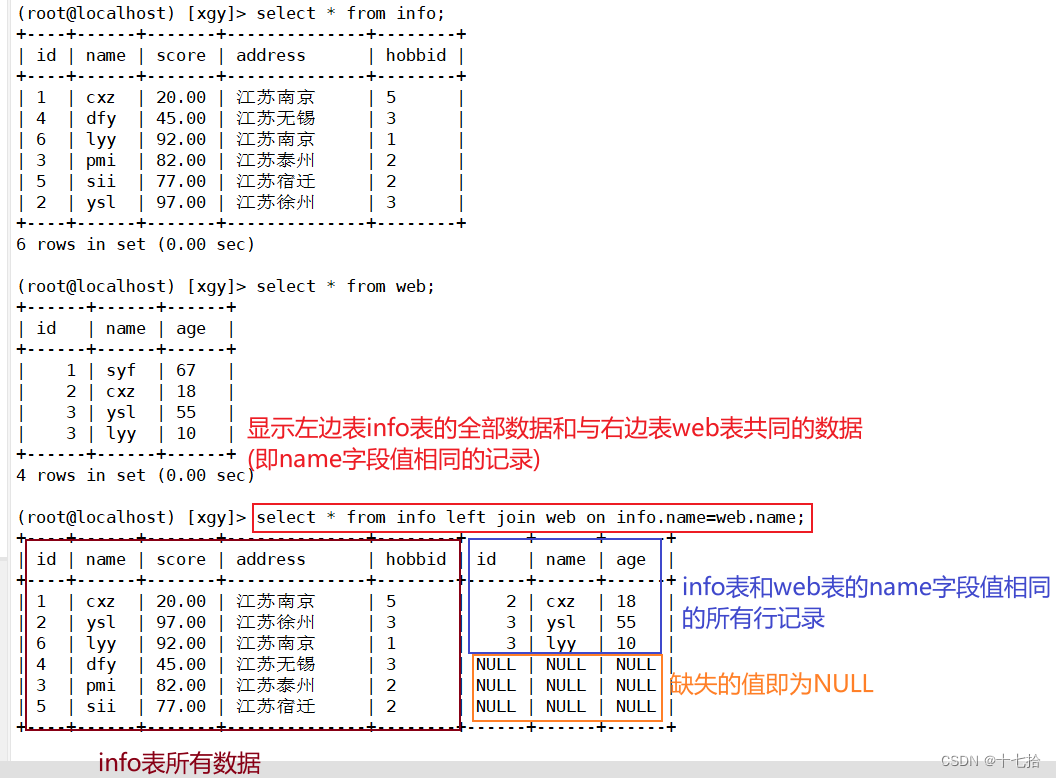 3、右连接
3、右连接
右连接也被称为右外连接,在 from子句中使用 right join 或者 right outer join 关键字来表示。右连接跟左连接正好相反,它是以右表为基础表,用于接收右表中的所有行,并用这些记录与左表中的行进行匹配

select * from 表1 right join 表2 on 表1.同名字段=表2.同名字段;select * from info right join web on info.name=web.name;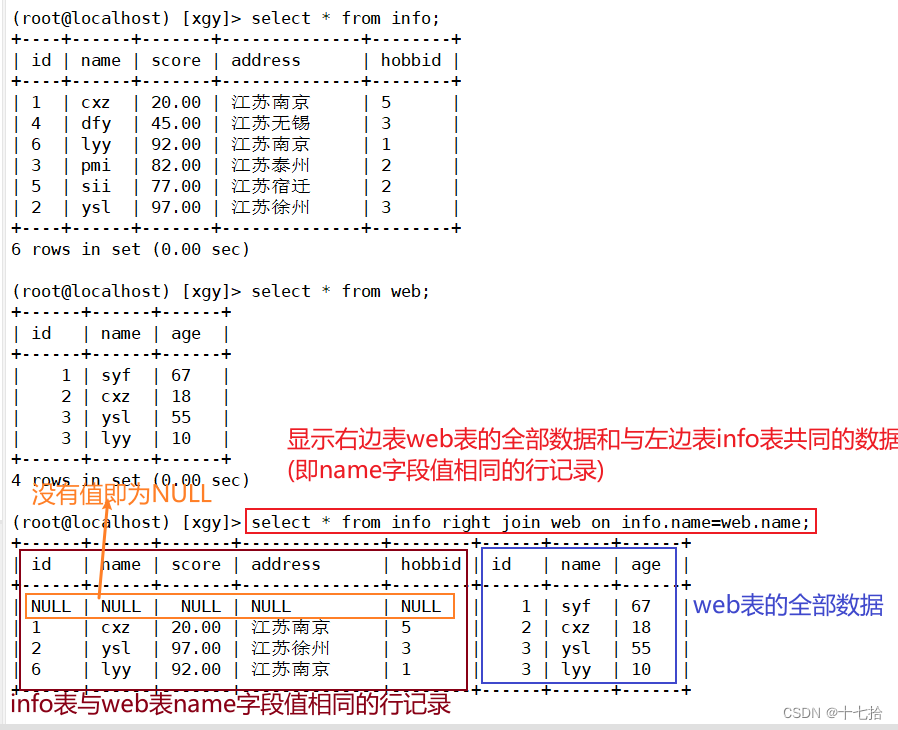
十、总结
按关键字排序:
- 使用order by子句对查询结果进行排序
- 默认按升序(asc)排序,可指定降序(desc)
格式:select 字段1,字段2,…… from 表名 order by 字段 asc|desc;区间判断:
BETWEEN操作符用于选取介于两个值之间的数据范围- 包含边界值
- AND/OR操作符:且/或的使用
- distinct 查询不重复的记录
分组查询:
group by子句用于将结果集按一个或多个列进行分组- 通常与聚合函数(如
count(), sum(), avg(),max(),min())一起使用
格式:select 字段1, 聚合函数(字段2) from 表名 (where 字段名 (匹配) 数值) group by 字段1;限制结果条目:
- limit子句用于限制查询结果的数量
- 常用于分页
格式:select 字段 from 表名 limit number;
设置别名:
- 使用as关键字给列或表设置别名,以简化查询或在join操作中解决列名冲突
select 字段 as 字段别名 from 表名 as 表别名;通配符:
LIKE操作符与%(代表任意字符序列)和_(代表单个字符)通配符一起使用,进行模糊匹配
select 字段 from 表名 where 字段 like ‘确定字符%’;子查询:
- 子查询是嵌套在其他查询中的查询
- 可以在select,from,where等子句中使用
格式:select 字段1,字段2 from 表名1 where 字段 in (select 字段 from 表名 where 条件判断语句);视图:
- 视图是基于SQL查询的虚拟表
- 可以包含一个或多个表中的数据
#创建视图
create view 视图表名 as select * from 表名 where 条件;
#查看视图
select * from 视图表名;
#查看表和视图的状态信息
show table status\G;
#查看视图结构
desc 视图表名;
#修改视图
update 视图表名 set 字段=新值 where 条件判断;
#删除视图
drop view [if exists] 视图名;连接查询:
- join操作用于结合两个或多个表的行
- inner join:返回两个表中匹配的记录
- left join:返回左表的所有记录,即使右表中没有匹配
- right join:返回右表的所有记录,即使左表中没有匹配
select 字段 from 表名1 [join/left join/right join] 表名2 on 表名1.相同字段 = 表名2.相同字段;