让机器理解语言,从字词开始,逐步发展到句子和文档理解:独热编码、词嵌入、word2vec、词义搜索、句意表示、暴力加算力
- 独热编码:分类 + 二进制特征
- Word2Vec 词嵌入: 用低维表示 + 用嵌入学习 + 用上下文信息
- Skip-gram 跳字模型:准确性
- CBOW 连续词袋模型:效率
- 词义搜索
- 句意表示 Doc2vec
- 大模型语言理解方式:暴力 + 算力才是王道
独热编码:分类 + 二进制特征
让机器理解自然语言,就从语言组成的基本单位开始(字和词)。
通常,将词汇映射为一个固定维度的数值向量是必要的,这种向量表示称为词向量。
假设有4万字词,就开4万维,一个字对应一个维度,当出现这个字,这个维度就标记为1,否则为0。
这种方式叫独热表示,是一种极其简单的词向量表示法(One-Hot)。
独热编码(One-Hot Encoding)有几个缺陷:
-
维度爆炸:独热编码要为语料库中的每个唯一词汇分配一个唯一的维度。
如果词汇量很大,这就会导致非常高维的向量,这些向量大部分都是零值,这对存储和计算都非常不高效。
-
缺乏语义信息:独热编码无法表示词与词之间的语义关系。
比如,“玫瑰”和“花”在语义上有一定的关联性,但是在独热编码中,它们是完全独立的两个向量,无法体现它们的相似性。
-
不适合捕捉上下文:由于每个词都被独立编码,独热编码不能捕捉词在不同上下文中的语义变化和顺序,因为每个词的编码都是固定的。
-
稀疏性:独热编码产生的向量大多数元素都是0,只有一个位置是1,这导致了向量的极端稀疏性,这种稀疏性在某些机器学习算法中会造成问题。
-
扩展性问题:新出现的词汇需要扩展已有的编码方案,对于词汇表的更新也不是很方便。
因此,为了解决这些问题,通常会采用诸如词嵌入(Word Embedding)的技术,比如Word2Vec或GloVe,它们能够生成更低维、稠密、并含有丰富语义信息的词向量。
这些词向量能够表示词语之间的相似性,并且能更好地处理新出现的词汇。
Word2Vec 词嵌入: 用低维表示 + 用嵌入学习 + 用上下文信息
Word2Vec 是一种广泛用于自然语言处理(NLP)的词嵌入技术。
它通过将词转换为在向量空间模型中的向量来捕捉单词之间的语义关系。要理解Word2Vec的解法,我们首先需要了解它主要包含两种架构:连续词袋(CBOW)和跳字模型(Skip-Gram)。
Skip-gram 跳字模型:准确性
用当前的词,预测上下文
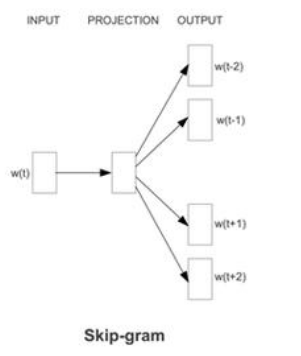
Skip-Gram模型通过目标词来预测其上下文,这种方法虽然在大规模数据集上训练速度较慢,但能更好地处理罕见词或特殊词,从而提高模型的准确性和鲁棒性。
举例:在句子“猫坐在垫子上”中,如果目标词是“坐”,Skip-Gram模型会尝试使用“坐”的词向量来预测“猫”和“在垫子上”的词向量。
CBOW 连续词袋模型:效率
用上下文预测,当前的词
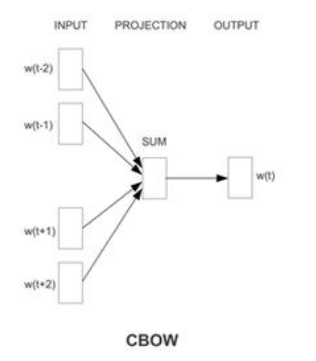
BOW模型通过取上下文中所有词的向量的平均值来预测目标词,这种方法相对于其他更复杂的处理方式,可以在大规模数据集上提供更快的训练速度。
举例:在句子“猫坐在垫子上”中,如果目标词是“坐”,上下文词是“猫”和“在垫子上”,CBOW会使用“猫”和“在垫子上”对应向量的平均值来预测“坐”。
词义搜索
在 Word2vec 之前的搜索,都是关键词搜索。

Word2Vec通过词向量的方式实现词义搜索,基于向量空间中的位置关系来识别语义相似性。
其核心原理是:在训练过程中,将语言中的每个词映射为高维空间中的一个向量,使得语义相似的词在向量空间中彼此接近。
- 训练词向量模型
- 步骤:使用大量文本数据训练Word2Vec模型。可以选择CBOW或Skip-Gram架构,根据上下文信息预测当前词或根据当前词预测上下文词。
- 目的:通过学习词与其上下文之间的关系,生成能够反映词义相似性的向量。
- 构建词向量空间
- 步骤:训练完成后,每个词都会有一个与之对应的向量表示,所有这些向量共同构成了词向量空间。
- 目的:在这个空间中,向量之间的距离和方向能够反映出词义之间的关系,如相似性、对立性等。
- 实现词义搜索
使用向量相似度计算
- 方法:计算目标词向量与词汇表中其他词向量之间的相似度,常用的相似度计算方法包括余弦相似度(还有明可夫斯基距离、杰卡德距离)。
- 结果:相似度高的词在语义上与目标词更接近,因此可以根据相似度得分对词汇进行排序,选择最相似的词作为搜索结果。
举个例子:
- 相似词查找:给定一个词,找出在向量空间中与之最接近的N个词。
- 词义推断:利用向量加减的特性来进行类比推理,例如:“国王” - “男人” + “女人” ≈ “女王”。
- 优化和应用
为了提高词义搜索的准确性和效率,可以采取以下措施:
- 增加训练数据:更大、更多样化的数据集可以提高模型的泛化能力。
- 调整模型参数:如向量维度、上下文窗口大小、训练算法(CBOW或Skip-Gram)、训练迭代次数等。
- 使用先进技术:比如负采样(Negative Sampling)和层次Softmax,可以提高训练效率,改善词义的捕捉。
句意表示 Doc2vec
Doc2Vec技术是在Word2Vec的基础上发展起来的一种算法,旨在解决Word2Vec只能表示单个词而不能直接应用于更长文本(如句子、段落或文档)的限制。
通过引入文档的唯一标识(通常称为“文档向量”),Doc2Vec能够捕捉整个文档的语义信息。
Doc2Vec的核心目标是生成一个固定长度的向量,这个向量能够代表整个文档的语义内容。
不同于Word2Vec模型生成的词向量,文档向量捕获了文档中所有词的上下文关系以及词之间的交互作用,提供了一个全面的文档表示。
这使得Doc2Vec非常适用于文档分类、文档相似度比较、推荐系统以及作为深度学习模型的特征输入。
Doc2Vec有两种主要的实现方式:分布式记忆(DM)和分布式词袋(DBOW)。
- DM模型通过预测文档中的词来学习文档向量,类似于Word2Vec中的CBOW模型,但加入了文档向量作为额外的上下文。
- DBOW模型则忽略上下文词的顺序,直接预测文档中出现的词,类似于Word2Vec的Skip-Gram模型。
DM模型通过结合文档向量和上下文信息来精确地捕捉文档中词的使用,适合于需要理解详细语境的任务。
而DBOW模型则通过直接预测文档中的词来快速捕捉文档的整体主题,适合于对文档进行广泛分类或主题识别的场景。
这两种模型提供了强大的工具,使得计算机能够理解和处理复杂的文本数据。
大模型语言理解方式:暴力 + 算力才是王道
随着技术的发展,更先进的大型模型(如BERT、GPT系列)被开发出来,它们采用了变换器(Transformer)架构,通过自注意力(Self-Attention)机制和大规模语料的预训练,能够捕获词、句子和文档级别的复杂语义关系。
这些模型并不直接使用独热编码或Word2Vec等具体技术,而是通过深度学习的方法学习语言的高级特征表示,从而实现更深层次的语言理解。
世间几乎所有力量的增长都会迅速陷入边际效益递减,从而变慢乃至于停下来,于是都是有上限的。
唯独计算机算力的增长,目前似乎还没有衰减的迹象。
摩尔定律依然强劲,算力每18个月就增长一倍,持续几十年的指数发展。
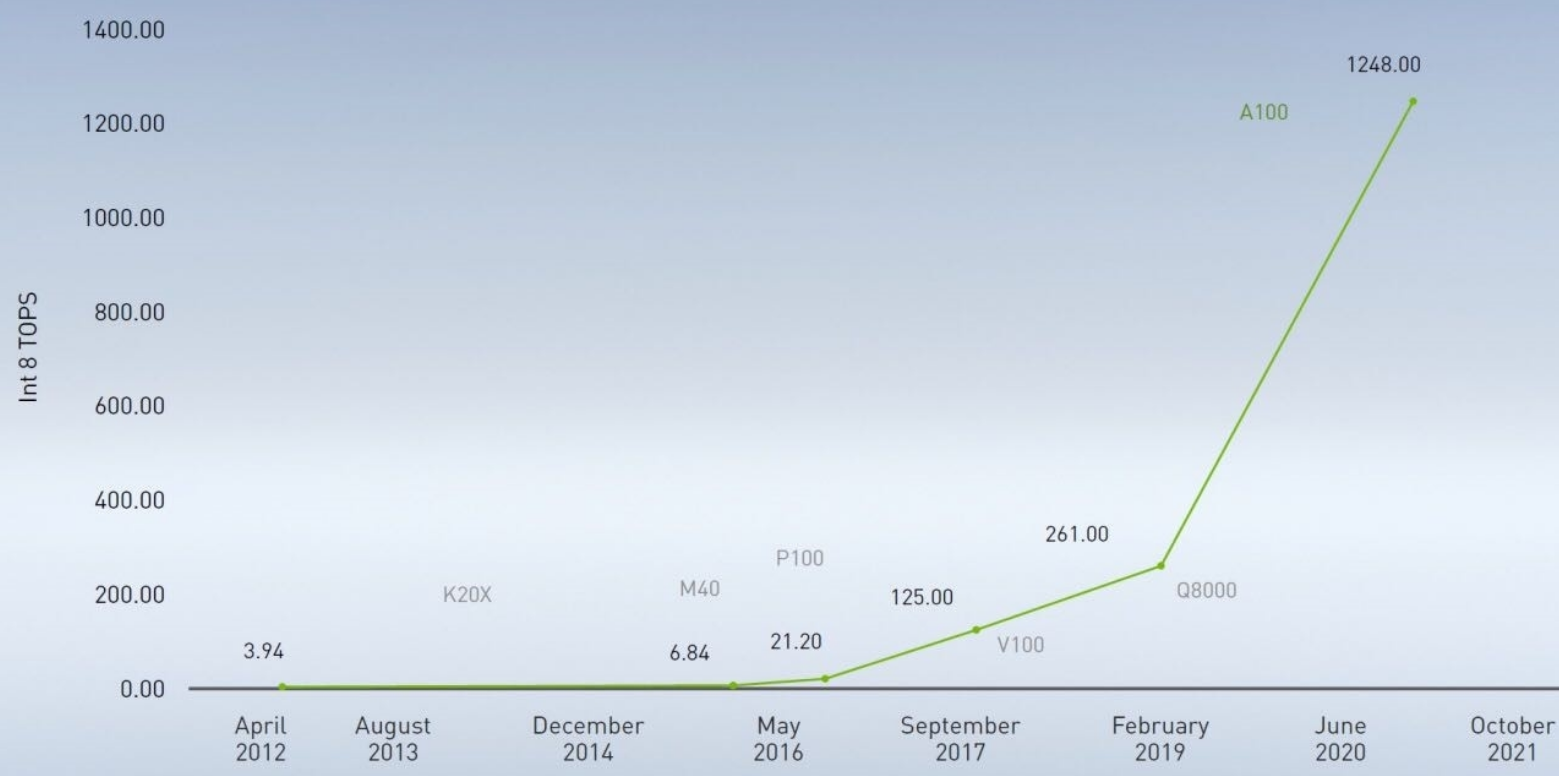
所以说,如果这个世界真有神,算力就是神。
GPT-3有1750亿个参数,无疑是非常大的数字,但是在指数增长的算力面前,这些是有限的数字。
而就是这样有限的模型,竟然就抓住了人类几乎所有平常的知识。
这说明「人」其实是简单的,简单到这么有限的算力就能把你搞明白。
以前的研究者搞的那些知识 —— 什么句法分析、语义分析、自然语言处理(NLP)—— 全都没用上,GPT直接把海量的语料暴力学一遍,就什么都会了。
在无穷的算力面前,人类的知识都只不过是一些小聪明而已。
-
人类研究者总想构建一些知识教给AI;
-
这些知识在短期内总是有用的;
-
但是从长远看,这些人类构建的知识有个明显的天花板,会限制发展;
-
让AI自行搜索和学习的暴力破解方法,最终带来了突破性进展。