目录
一. AIGC介绍
1. 介绍
2. AIGC商业化方向
3. AIGC是技术集合
4. AIGC发展三要素
4.1 数据
4.2 算力
4.3 算法
4.3.1 多模态模型CLIP
4.3.2 图像生成模型
二. Stable Diffusion 稳定扩散模型
1. 介绍
1.1 文生图功能(Txt2Img)
1.2 图生图功能(Img2Img)
2. 技术架构
step1 CLIP Text Encoder
(1) CLIP介绍
(2) CLIP架构
step2 LDM之VAE Encoder
step3 LDM之Diffusion
(1) 前向扩散:加噪
(2) 反向扩散:去噪
a) SD核心:U-Net
b) Transformer2DModel: 加入条件控制
(3) 如何训练噪声预测器?
step4 LDM之VAE Decoder
三. 参考
一. AIGC介绍
这两年,短视频平台上“AI绘画“非常火爆,抖音一键换装、前世今生之类的模板大家没玩过也应该听说过。另一个火爆应用当属ChatGPT,自2022年ChatPGT3.5发布后,快速累积了超百万用户,可谓家喻户晓。这两个概念均来自同一个领域,即AIGC。
1. 介绍
AIGC全称是AI Generated Content, 直译:人工智能生成内容,也叫生成式人工智能。
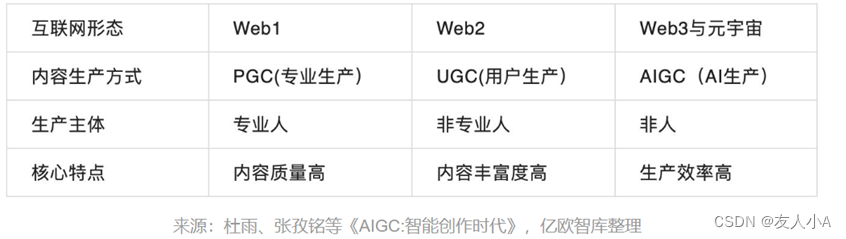
AIGC是继专业生产内容(PGC, Professional-genrated Content)、用户生产内容(UGC,User-generated Content)之后的新型内容创作方式,是互联网内容创作方式的一次革新。AIGC可以在对话、故事、图像、视频和音乐制作等方面,打造全新的数字内容生成与交互形式。
2022年8月,一位没有绘画基础的参赛者利用AI绘画工具 Midjourney创作的《太空歌剧院》在美国科罗纳州举办的新型数字艺术家竞赛中,获得“数字艺术/数字修饰照片”类别一等奖,由此,AI绘画进入大众视野。同年,AI绘图模型Stable Diffusion开源,助力AI绘画破圈得到广泛关注。

2022年11月30日,ChatGPT推出,5天后用户破百万,两个月后月活用户突破1亿,称为史上用户增长速度最快的消费级应用程序。
2021年开始,风投对AIGC的投资金额出现爆发式增长,2022年超20亿美元。据美国财经媒体Semafer报道,微软预计向ChatGPT的开发者OpenAI投资100亿美元。
2022年,因此被称为“AIGC元年”。
2. AIGC商业化方向
AIGC的出现,打开了一个全新的创作世界,为人们提供了无尽的可能性。AIGC生成的内容种类和范围随着技术的发展也在不断扩大。目前,常见的内容包括:
-
AI文本生成,以OpenAI GPT系列为代表的模型,实现自动写邮件、广告营销方案等
-
AI文生图/图生图,如使用“跨模态模型CLIP+扩散模型Diffusion“实现的文生图模型Stable Diffusion
-
AI文生视频,如OpenAI今年2.16日发布的Sora,颠覆了全球AI生成视频市场的格局
-
…
更多AIGC应用可见:AIGC工具导航 | 生成式AI工具导航平台-全品类AI应用商店!
3. AIGC是技术集合
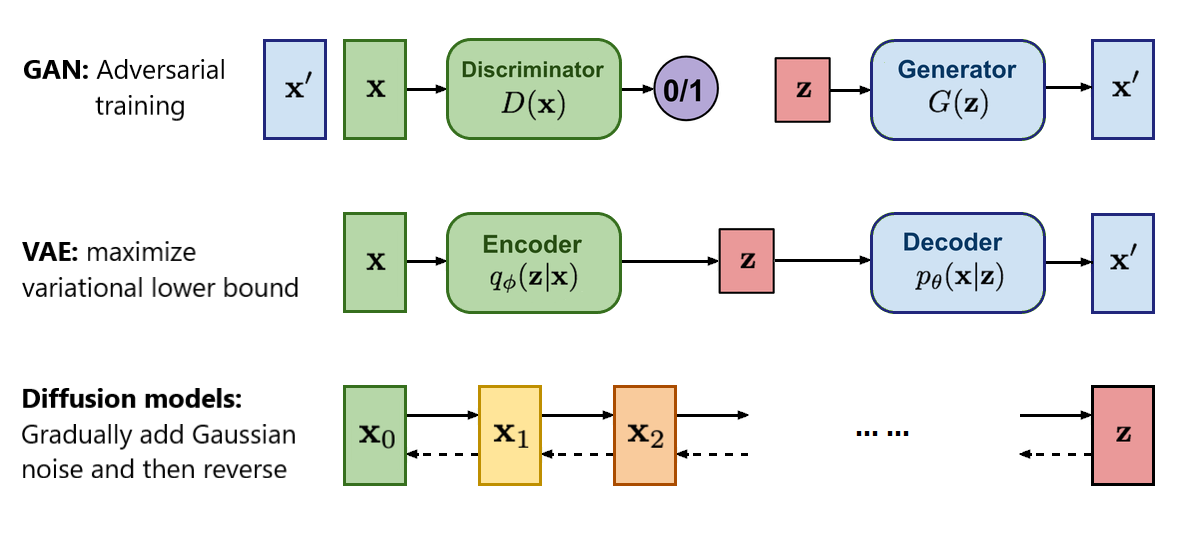
AIGC不是某一个单一的技术或者模型,AIGC使一个技术集合。概括来说,它是基于生成对抗网络GAN、大型预训练模型等人工智能技术,通过已有数据寻找规律,并通过适当的泛化能力生成相关内容的技术集合。简单理解就是所有的AIGC方向的模型,都不是单一模型实现的,而是通过刚才说的技术组合训练得到的。
4. AIGC发展三要素
4.1 数据
UGC生成的规模化内容,创造了大量学习素材,互联网数据规模快速膨胀。
4.2 算力
图形处理器GPU、张量处理器TPU等算力设备性能不断提升,A100,H100等加速卡
4.3 算法
当前AIGC技术已经从最初追求生成内容的真实性的基本要求,发展到满足生成内容多样性、可控性的进阶需求,并开始追求生成内容的组合型。数字内容的组合性一方面关注复杂场景、长文本等内容中各个元素的组合,如虚拟数字世界中人、物和环境间的交互组合,并生成整体场景;另一方面,追求概念、规则等抽象表达的组合,以此完成更加丰富和生动的数字内容生成。这些新需求对传统单一模态的人工智能算法框架提出了新的挑战。
预训练大模型和多模态方向的发展,为AIGC技术发展和升级提供了基石。

4.3.1 多模态模型CLIP
由于CLIP 两模块之一的Text Encoder是基于Transformer的模型,所以Transformer才被称为”跨模态重要开端之一“
4.3.2 图像生成模型
| 模型 | 组成 | 优点 | 缺点 |
| GAN | GAN = 生成器 + 判别器
| 生成的图片逼真 |
|
| VAE | VAE = 编码器 + 解码器 AVE将输入数据编码成一个符合正态分布的数据分布,学习图片的数据分布特征 | 学习的概率分布,可解释性强,图片多样性足 | 产生图片模糊,原因可参考:破解VAE的迷思_vae生成的图像为什么模糊-CSDN博客 |
| Diffusion | Diffusion = 前向扩散 + 反向扩散 |
| 由于是在像素空间做的扩散,数据量多,训练成本高昂、速度慢,需要多步采样 |
| Latent Diffusion | Latention Diffusion = VAE+Diffusion 潜在扩散模型 Latent Diffusion通过引入VAE, 解决速度慢的问题:VAE将像素空间的输入压缩编码成Latent潜在空间的概率分布,SD的Latent Space为4x64x64, 比图像像素空间3x512x512小48倍,减少空间占用,之后再进行模型扩散,这样可以加速训练。 |
|
二. Stable Diffusion 稳定扩散模型
1. 介绍
Stable Diffusion 是Stability AI公司于 2022 年10月发布的深度学习文字到图像生成模型。它主要用于根据文字的描述产生详细图像,能够在几秒钟内创作出令人惊叹的艺术作品。Stable Diffusion的源代码和模型权重已分别公开发布在GitHub和Hugging Face,它的参数量只有1B左右,可以在大多数配备有适度GPU的电脑硬件上运行。
| 训练数据集 | LAION-5B是一个公开的数据集,源自网络上抓取的图片-标题数据,这是一个由6亿张带标题的图片组成的子集。这个最终的子集也排除了低分辨率的图像和被人工智能识别为带有水印的图像。对该模型的训练数据进行的第三方分析发现,在从所使用的原始更广泛的数据集中抽取的1200万张图片的较小子集中,大约47%的图像样本量来自100个不同的网站 |
| 训练成本 | 亚马逊云计算服务平台,256 x NV A100 GPU, 15万个GPU小时(单卡约73h=3day),成本为60万美元 |
| 发行版本 |
|

1.1 文生图功能(Txt2Img)
Stable Diffusion演示
1.2 图生图功能(Img2Img)
2. 技术架构
Stable Diffusion是潜在扩散模型Latent Diffusion Model(简称LDM)的一种变体。
Stable Diffusion = CLIP Text Encoder + Latent Diffusion(VAE+Diffusion)


step1 CLIP Text Encoder
SD只用到了CLIP模型的Text Encoder预训练模型,权重固定,它会将文本编码成语义向量,该语义向量对应一个图像。
(1) CLIP介绍
- 全称:Contrastive Languange-Image Pre-Training,是OpenAI 2021.1发布的基于对比学习的文图多模态模型,核心是“Connecting text and images”。
- 训练数据集:WIT(WebImage Text,OpenAI自己网页爬虫创建的一个超过4亿图像-文本对的数据集)
- 模型组成:
- 基于Transformer 的Text Encoder
- 基于CNN/VIT的Image Encoder两个模型
(2) CLIP架构
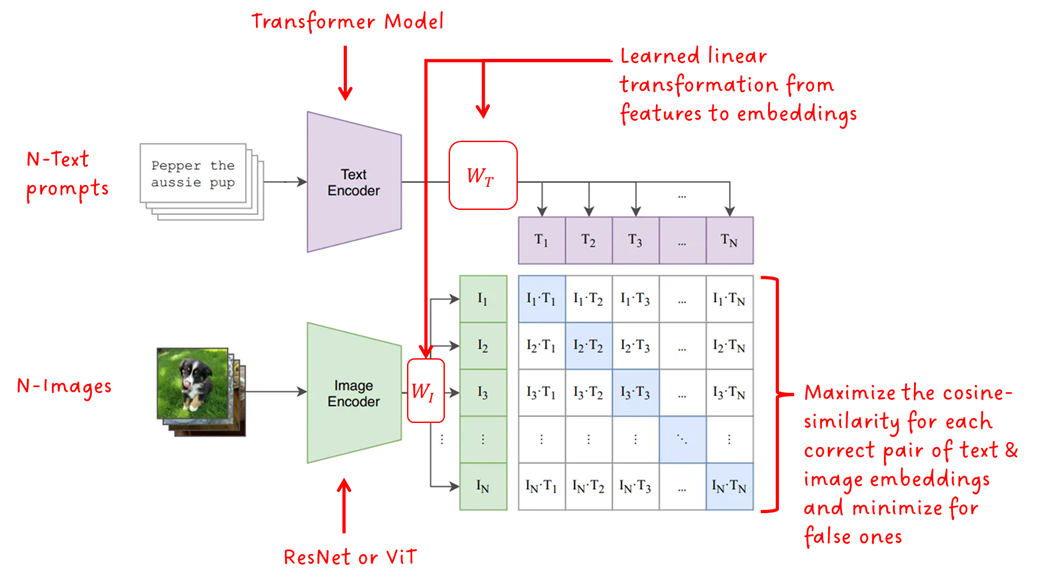
CLIP会提取文本特征和图像特征,通过对比学习,计算文本特征和图像特征的余弦相似性(cosine similarity),让模型学习到文本和图像的匹配关系。
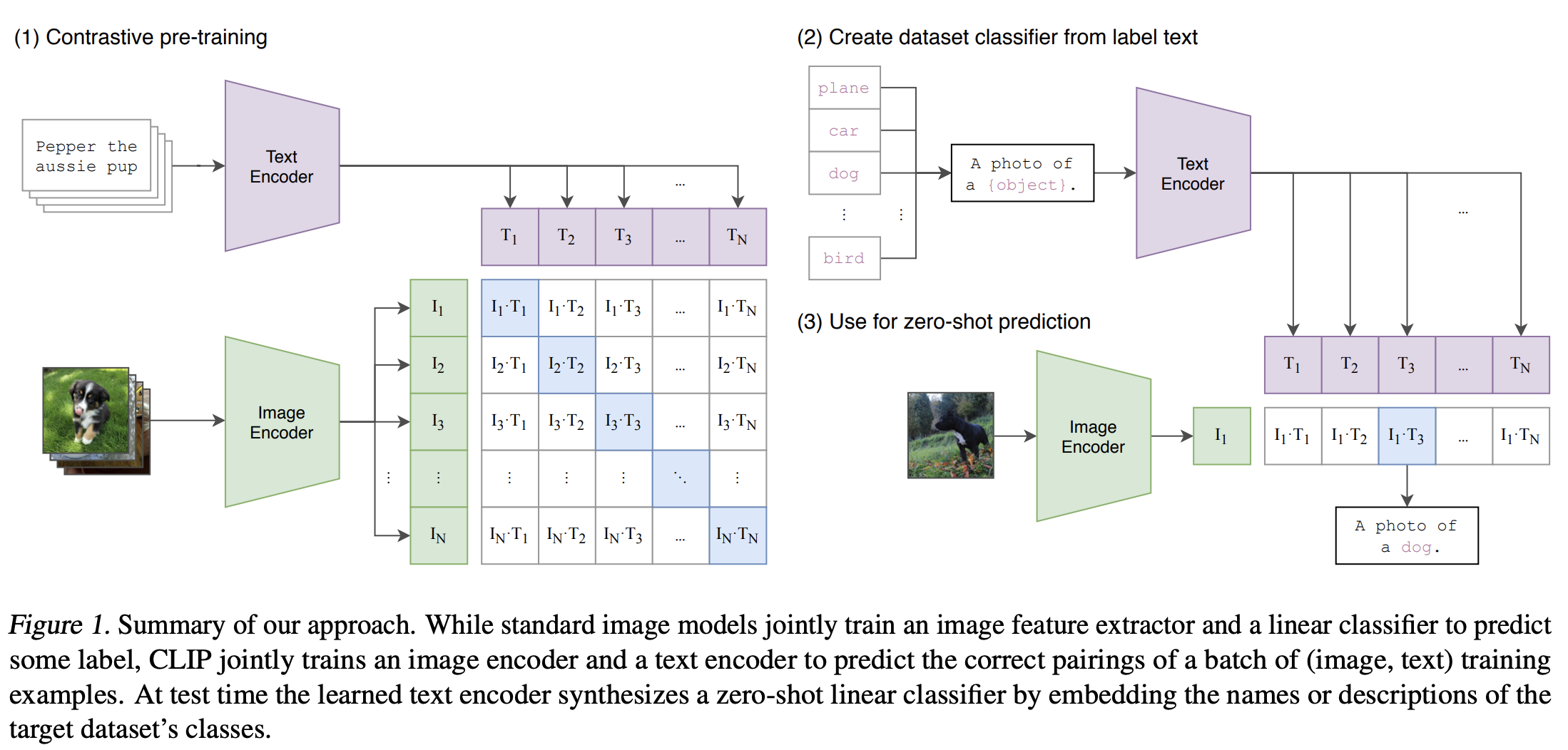
SD只用到了步骤(1)的成果:
- CLIP是自监督模型,就是说,CLIP不像传统的视觉模型,如Resnet系列模型,需要用标注好类别的图像进行训练,CLIP使用的数据集本身带有文本-图片的对应关系。
- 前向推理时,N组图片-文本数据,分别编码得到语义特征和图片特征后,计算其相似度,得到NxN个预测值,表明文本特征和每一个图片特征的相似度
- 若对角线是匹配的文本-图像对,则记为正样本,其他位置则记为不匹配的负样本;
- 定义对比损失函数Contrastive Loss,计算正负样本的相似度,得到损失函数的结果值(这个损失函数的目标是:最大化正样本对的相似度, 同时最小化负样本对的相似度——计算原理暂未研究)
- 对损失函数进行求导,计算梯度,用于指导参数的更新方向
- 更新模型参数,迭代优化
对比学习预训练学习的是整个句子与其描述的图像之间的关系,而不是像猫、狗、树等单一类别;比如传统的视觉模型,如Resnet系列模型,ResNet使用的是有监督学习,训练集是经过标注的图片,标注信息就是图片的分类,这个信息相比CLIP而言就很单一了。

当在整个句子上进行训练时,模型可以学习更多的东西(而非单一的类别),找到图像和文本之间的关系。CLIP在图像分类等比赛中的表现,也证明了CLIP对于文本-图像对比学习的优越性。

所以,我们若问SD为什么选择了CLIP Text Ecnoder作为其文本编码器?
CLIP开创性地提出训练模型学习图像和文本之间的联系,并在各项视觉比赛中证明了其优越性。CLIP预训练模型的Text Encoder编码处理的语义向量,有对应近似的图像特征向量,便于跨模态处理图像相关的下游任务,如图像生成等。
step2 LDM之VAE Encoder
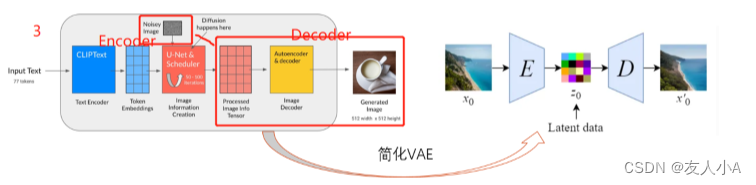
CLIP全称:Varitional AutoEncoder(VAE) 变分自编码器
CLIP思路:VAE将输入转换成Latent空间的概率分布,如标准高斯分布;
SD的Latent Space为4x64x64, 比图像像素空间3x512x512小48倍,减少空间占用,加速训练
CLIP组成:Encoder + decoder
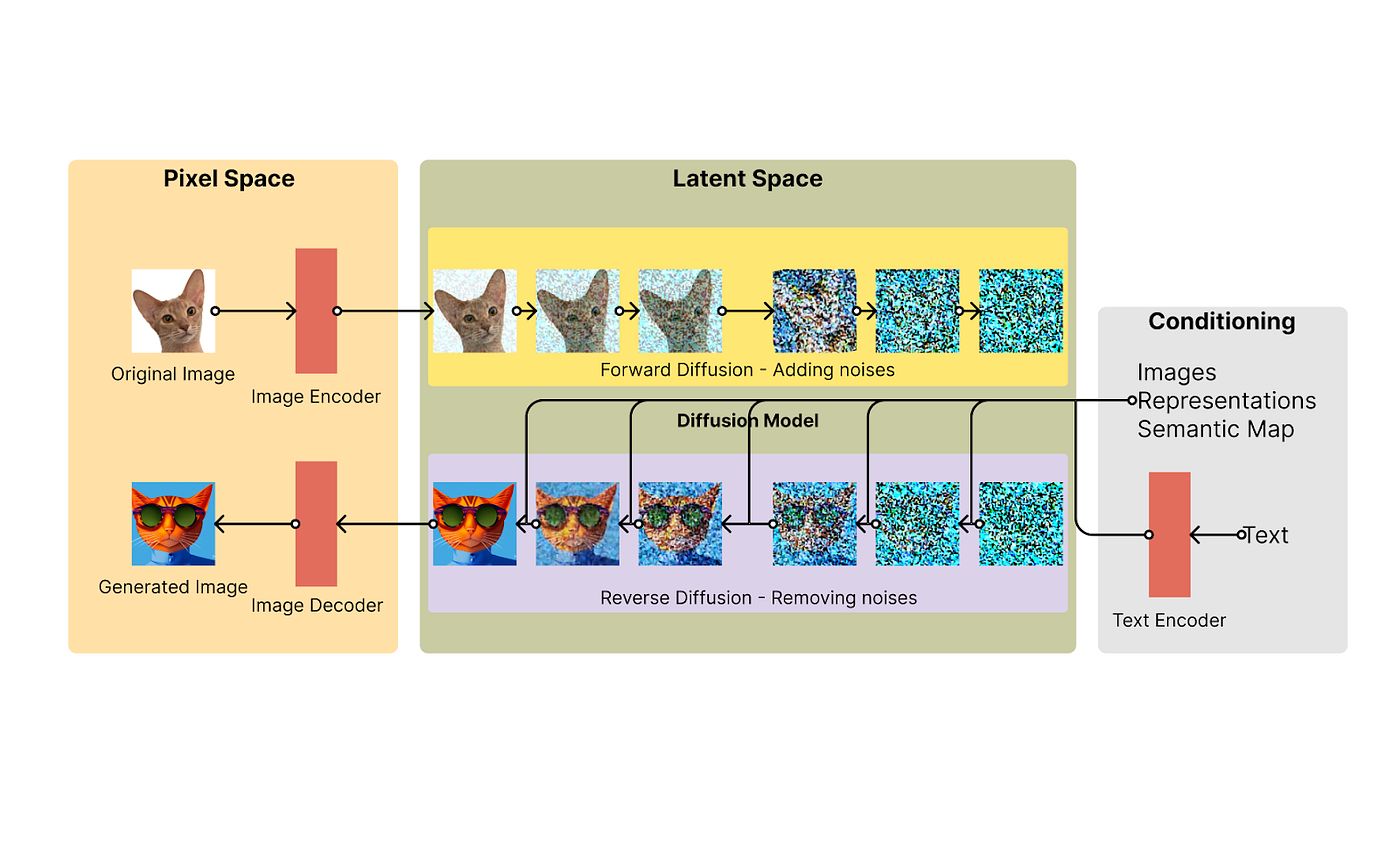
step3 LDM之Diffusion
扩散模型的目的:学习从噪声生成图片的方法
先宏观了解LDM做了什么(下为图生图样例,有图片输入+关键字)
- 隐向量通过前向扩散增加噪声,将图像数据点的复杂分布逐渐转为简单分布
- 通过CLIP Text Encoder编码出来的语义向量作为监督信号作用到去噪过程中
- 噪声向量通过反向扩散去除噪声,得到图像最终的隐向量
动图示例
Q: 图像逐渐从噪声中转变而来,这一过程是如何实现的呢?
A: 训练噪声预测器
(1) 前向扩散:加噪
向图像逐渐添加高斯噪声以破坏图像原始的特征,直到图像完全无法识别。这个过程就像一滴墨水滴入了一杯水中,墨水在水里diffuses(扩散).几分钟后,墨水会随机分散并融入水里。数据通过逐步添加噪声,从一个真实图像的复杂分布逐渐过渡到噪点图的简单分布(符合高斯分布)。
为什么添加高斯噪声?
高斯噪声是一种正太分布的噪声,正态分布在自然界中广泛存在,如人的身高、体重、智商等都可以用正态分布来描述。因此使用高斯噪声可以称为一个正确的基本假设,符合真实世界规律。

如何添加噪声?

如何反向去除噪声?
与正向过程不同,不能使用q(xₜ₋₁|xₜ)来反转噪声,因为它是难以处理的(无法计算)。所以我们需要训练神经网络pθ(xₜ₋₁|xₜ)来近似q(xₜ₋₁|xₜ)。近似pθ(xₜ₋₁|xₜ)服从正态分布。
小结:
1. LDM前向扩散可以用封闭形式的固定公式计算
2. LDM反向扩散可以用训练好的神经网络来完成(Noising Predictor, U-Net)
为了近似所需的去噪步骤,我们只需要使用神经网络推理结果近似预期噪声
因此噪声预测器实际训练的就是反向扩散的U-Net网络 !!
(2) 反向扩散:去噪
前面已经讲了,反向扩散要想像时光倒流一样,将噪点图逐渐恢复到原图,需要教会该神经网络预测(1)中添加的噪声,然后从前向扩散得到的符合高斯分布的噪声矩阵中,连续减去预测噪声,最终恢复到原图。这个神经网络就是U-Net网络。
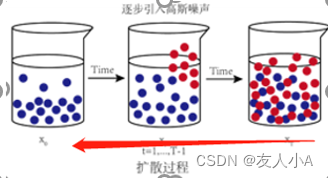
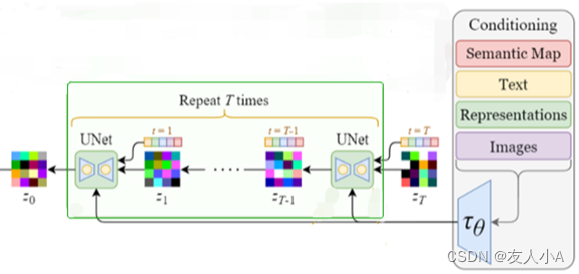
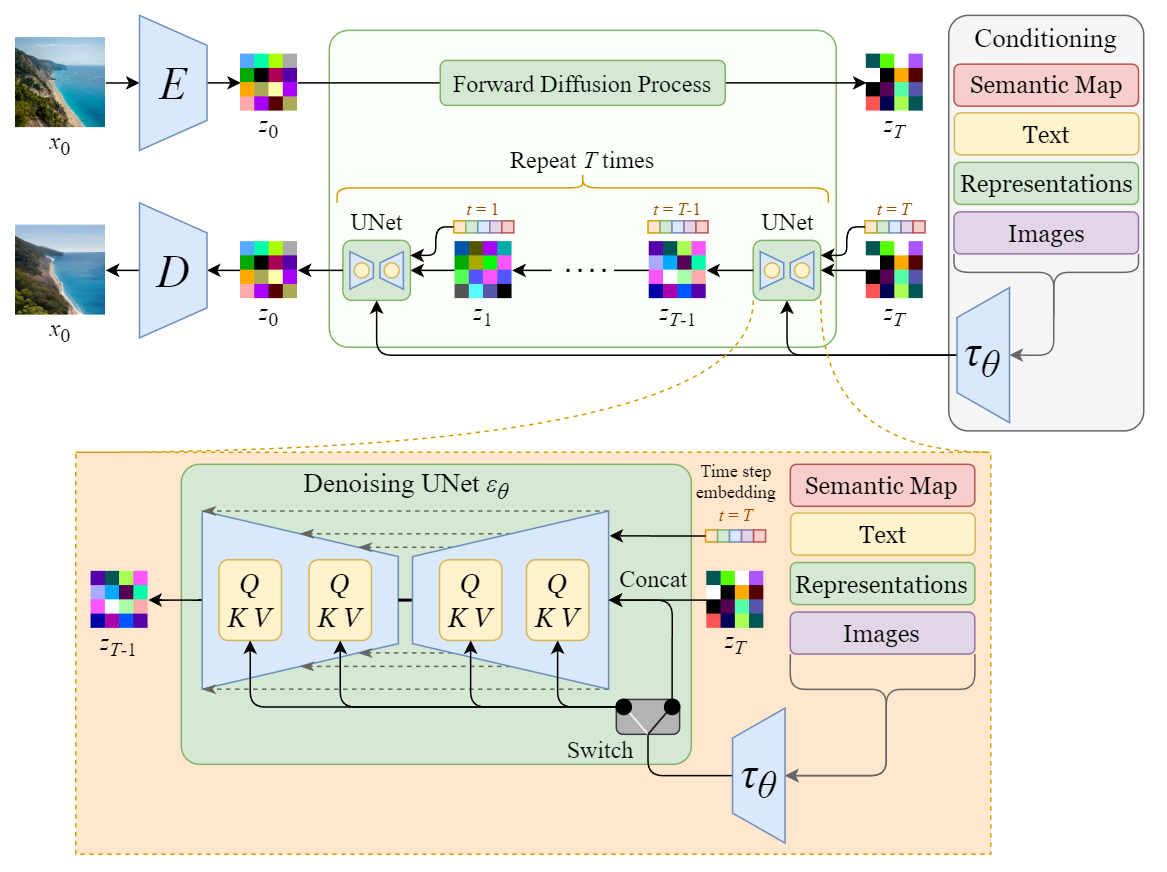
a) SD核心:U-Net
从上图中放大UNet模块:

U-Net主要对Forward Diffusion输出的高斯噪声矩阵进行迭代降噪,并且每次都使用CLIP Text-encoder的文本特征向量+timesteps作为条件控制来预测噪声,然后在高斯噪声矩阵上去除预测噪声,经过多次迭代后,将高斯噪声矩阵转换成图片的Latent特征。
U-Net原本的结构

SD中的U-Net,在原本Encoder-Decoder(下采样-上采样)结构基础上,增加了新模块:
- 1. Time Embedding 时间编码
- 将时间信息映射到一个连续的向量空间,使得时间之间的关系可以被模型学习和利用。这些时间嵌入帮助神经网络获得图像当前处于哪个状态(步骤)的某些信息。这对于了解图像中当前是否存在更多或更少的噪声很有用,从而使模型减去更多或更少的噪声。
- 2.Cross Attenion模块(交叉注意力机制)
- 3.Self-Attention模块(自注意力机制)

b) Transformer2DModel: 加入条件控制
先说一下注意力机制中QKV的作用:
举个例子,我在网页上输入关键字“Query”来搜索某些信息,网站会根据Q去数据库查询相关联的“Key”, 然后返回给我”Key”对应的“Value”。
更通俗的说法可以是:QKV模式就像是你在找答案时,先提出问题(Query),然后根据问题找到相关的关键信息(Key),最终得到你想要的具体答案或内容(Value)。
详见:Transformer_transformer qkv不同源-CSDN博客

SD的U-Net既用到了自注意力,也用到了交叉注意力。
- Self-Attention用于图像特征自己内部信息聚合
- Cross-Attention用于让生成图像对齐文本,其Q来自图像特征,K,V来自文本编码。我们知道CLIP Text Encoder编码出来的文本编码跟其对应的图像向量是近似的,所以这个文本编码本身也对应表示一幅图像。Cross-attention将KV替换成来自文本编码的KV, 就可以关联原图像和关键字,生成的图片会既和原本生成的图相似,也会和参考图像相似。(个人理解)
(3) 如何训练噪声预测器?
step4 LDM之VAE Decoder
看看step2就行了,知道这一步是将 去噪后的矩阵解码回像素空间就行。具体VAE的原理没有过多研究。
三. 参考
- 中国信通院-京东探索研究所-人工智能生成内容(AIGC)白皮书(2022年).pdf
- AIGC深度报告:新一轮内容生产力革命的起点(国海证券).pdf
- 硬核解读Stable Diffusion(完整版)
- https://zh.wikipedia.org/wiki/Stable_Diffusion
- 7. 稳定扩散模型(Stable diffusion model) — 张振虎的博客 张振虎 文档
- 深入浅出完整解析Stable Diffusion(SD)核心基础知识
- CLIP:用文本作为监督信号训练可迁移的视觉模型
- OpenAI CLIP模型的简单实现:教程
- 神器CLIP:连接文本和图像,打造可迁移的视觉模型
- 【Stable Diffusion】之原理篇
- LDM(Latent Diffusion Model)详解
- stable diffusion原理解读通俗易懂,史诗级万字爆肝长文!
- Stable Diffusion 文生图技术原理_stable diffusion csdn-CSDN博客