目录
- 理论知识
- 模型结构
- 结构分解
- 黑盒
- 两大模块
- 块级结构
- 编码器的组成
- 解码器的组成
- 模型实现
- 多头自注意力块
- 前馈网络块
- 位置编码
- 编码器
- 解码器
- 组合模型
- 最后附上引用部分
- 模型效果
- 总结与心得体会
理论知识
Transformer是可以用于Seq2Seq任务的一种模型,和Seq2Seq不冲突。
模型结构

结构分解
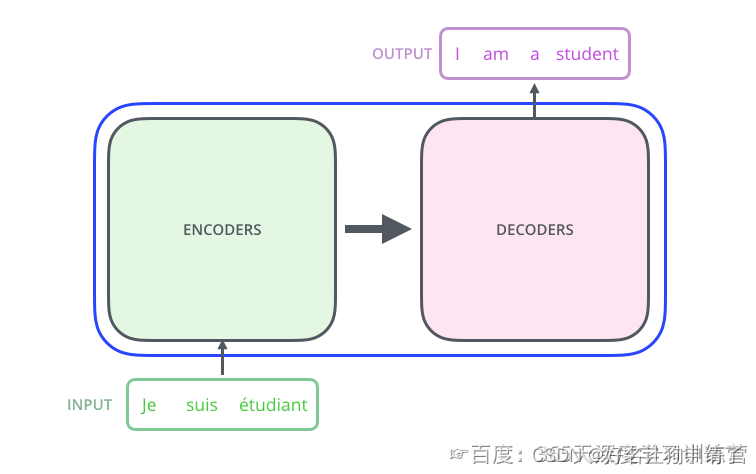
黑盒
以机器翻译任务为例

两大模块
在Transformer内部,可以分成Encoder编码器和和Decoder解码器两部分,这也是Seq2Seq的标准结构。
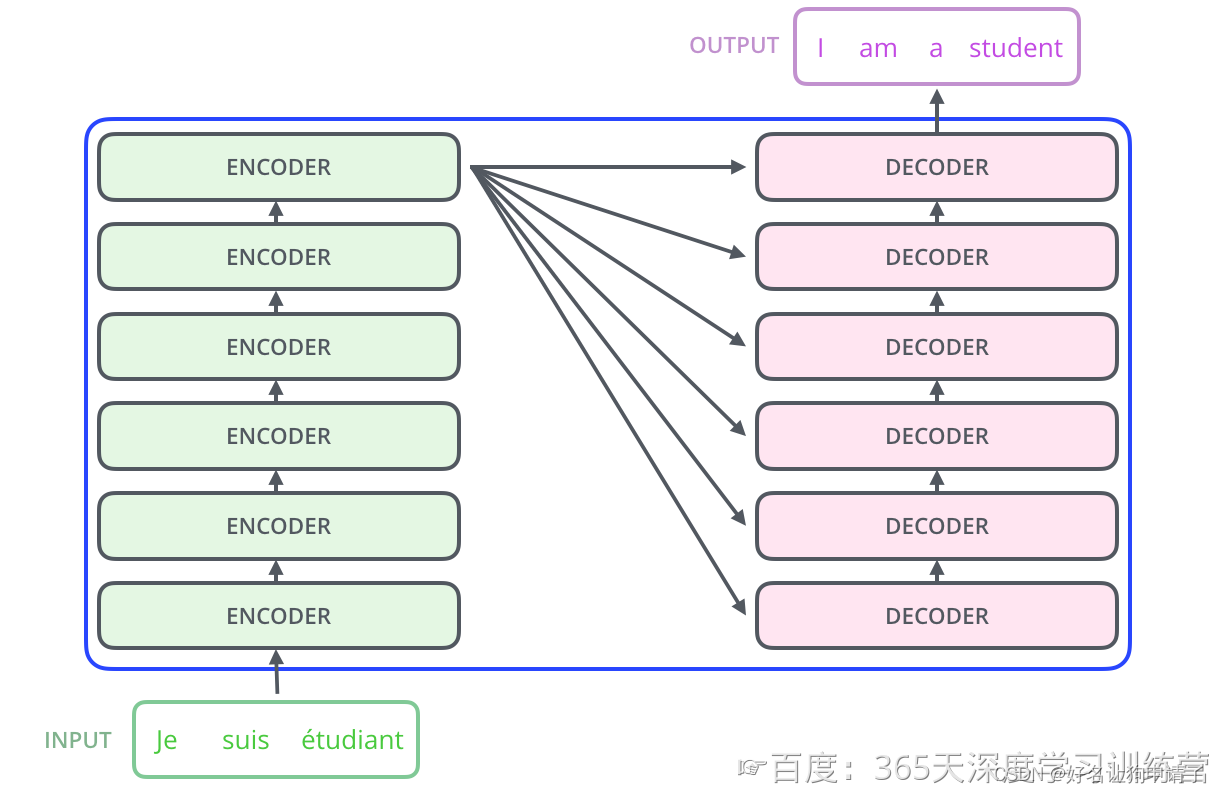
块级结构
继续拆解,可以发现模型的由许多的编码器块和解码器块组成并且每个解码器都可以获取到最后一层编码器的输出以及上一层解码器的输出(第一个当然是例外的)。
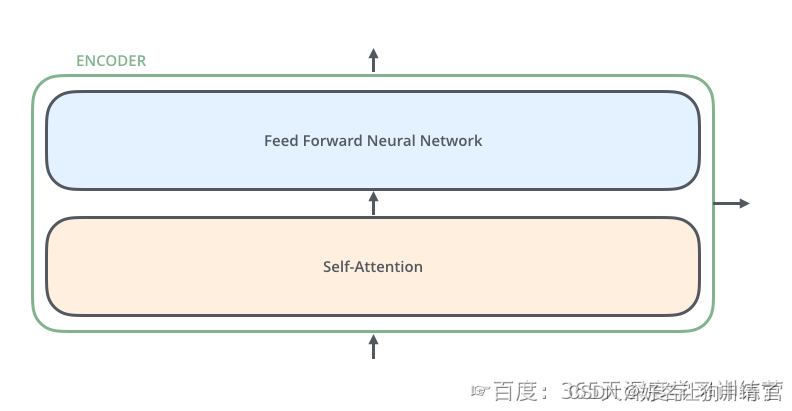
编码器的组成
继续拆解,一个编码器是由一个自注意力块和一个前馈网络组成。
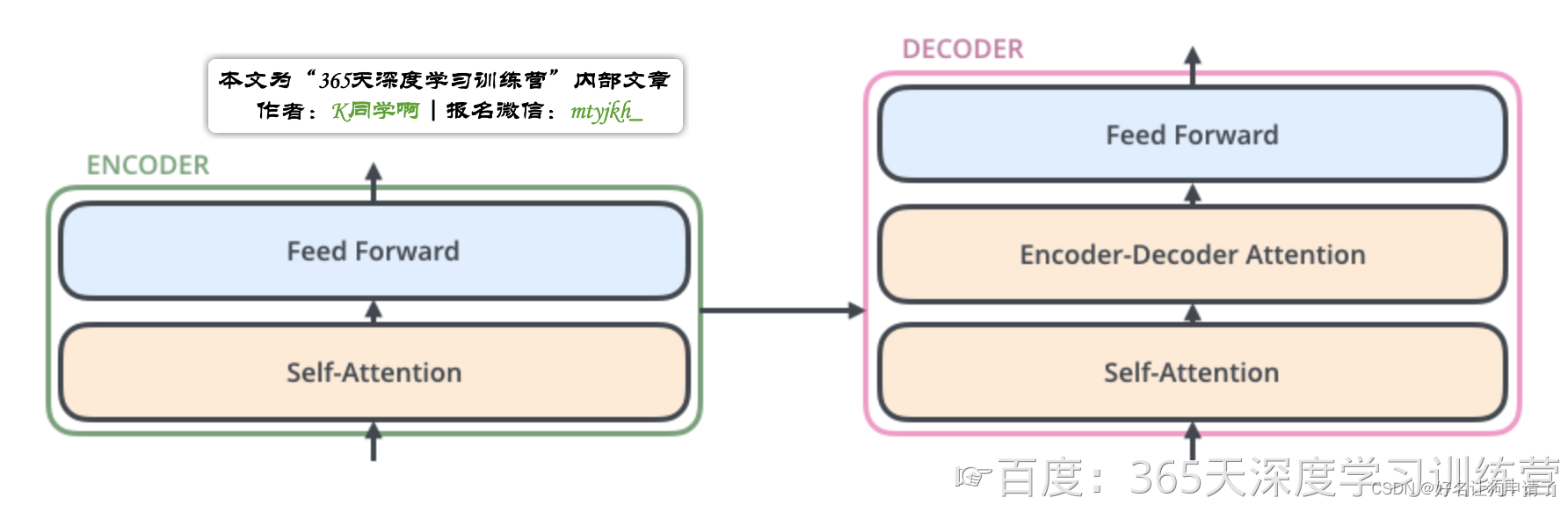
解码器的组成
而解码器,是在编码器的结构中间又插入了一个Encoder-Decoder Attention层。
模型实现
通过前面自顶向下的拆解,已经基本掌握了模型的总体结构。接下来自底向上的复现Transformer模型。
多头自注意力块
class MultiHeadAttention(nn.Module):"""多头注意力模块"""def __init__(self, dims, n_heads):"""dims: 每个词向量维度n_heads: 注意力头数"""super().__init__()self.dims = dimsself.n_heads = n_heads# 维度必需整除注意力头数assert dims % n_heads == 0# 定义Q矩阵self.w_Q = nn.Linear(dims, dims)# 定义K矩阵self.w_K = nn.Linear(dims, dims)# 定义V矩阵self.w_V = nn.Linear(dims, dims)self.fc = nn.Linear(dims, dims)# 缩放self.scale = torch.sqrt(torch.FloatTensor([dims//n_heads])).to(device)def forward(self, query, key, value, mask=None):batch_size = query.shape[0]# 例如: [32, 1024, 300] 计算10头注意力Q = self.w_Q(query)K = self.w_K(key)V = self.w_V(value)# [32, 1024, 300] -> [32, 1024, 10, 30] 把向量重新分组Q = Q.view(batch_size, -1, self.n_heads, self.dims//self.n_heads).permute(0, 2, 1, 3)K = K.view(batch_size, -1, self.n_heads, self.dims//self.n_heads).permute(0, 2, 1, 3)V = V.view(batch_size, -1, self.n_heads, self.dims//self.n_heads).permute(0, 2, 1, 3)# 1. 计算QK/根dk# [32, 1024, 10, 30] * [32, 1024, 30, 10] -> [32, 1024, 10, 10] 交换最后两维实现乘法attention = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scaleif mask is not None:# 将需要mask掉的部分设置为很小的值attention = attention.masked_fill(mask==0, -1e10)# 2. softmaxattention = torch.softmax(attention, dim=-1)# 3. 与V相乘# [32, 1024, 10, 10] * [32, 1024, 10, 30] -> [32, 1024, 10, 30]x = torch.matmul(attention, V)# 恢复结构# 0 2 1 3 把 第2,3维交换回去x = x.permute(0, 2, 1, 3).contiguous()# [32, 1024, 10, 30] -> [32, 1024, 300]x = x.view(batch_size, -1, self.n_heads*(self.dims//self.n_heads))# 走一个全连接层x = self.fc(x)return x
前馈网络块
class FeedForward(nn.Module):"""前馈传播"""def __init__(self, d_model, d_ff, dropout=0.1):super().__init__()self.linear1 = nn.Linear(d_model, d_ff)self.dropout = nn.Dropout(dropout)self.linear2 = nn.Linear(d_ff, d_model)def forward(self, x):x = F.relu(self.linear1(x))x = self.dropout(x)x = self.linear2(x)return x
位置编码
class PositionalEncoding(nn.Module):"""位置编码"""def __init__(self, d_model, dropout=0.1, max_len=5000):super().__init__()self.dropout = nn.Dropout(dropout)# 用来存位置编码的向量pe = torch.zeros(max_len, d_model).to(device)# 准备位置信息position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2)* -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)# 注册一个不参数梯度下降的模型参数self.register_buffer('pe', pe)def forward(self, x):x = x + self.pe[:, :x.size(1)].requires_grad_(False)return self.dropout(x)
编码器
class EncoderLayer(nn.Module):def __init__(self, d_model, n_heads, d_ff, dropout=0.1):super().__init__()self.self_attn = MultiHeadAttention(d_model, n_heads)self.feedforward = FeedForward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, mask):attn_output = self.self_attn(x, x, x, mask)x = x + self.dropout(attn_output)x = self.norm1(x)ff_output = self.feedforward(x)x = x + self.dropout(ff_output)x = self.norm2(x)return x
解码器
class DecoderLayer(nn.Module):def __init__(self, d_model, n_heads, d_ff, dropout=0.1):super().__init__()self.self_attn = MultiHeadAttention(d_model, n_heads)self.enc_attn = MultiHeadAttention(d_model, n_heads)self.feedforward = FeedForward(d_model, d_ff, dropout)self.norm1 = nn.LayerNorm(d_model)self.norm2 = nn.LayerNorm(d_model)self.norm3 = nn.LayerNorm(d_model)self.dropout = nn.Dropout(dropout)def forward(self, x, enc_output, mask, enc_mask):# 自注意力attn_output = self.self_attn(x, x, x, mask)x = x + self.dropout(attn_output)x = self.norm1(x)# 编码器-解码器注意力attn_output = self.enc_attn(x, enc_output, enc_output, enc_mask)x = x + self.dropout(attn_output)x = self.norm2(x)# 前馈网络ff_output = self.feedforward(x)x = x + self.dropout(ff_output)x = self.norm3(x)return x
组合模型
class Transformer(nn.Module):def __init__(self, vocab_size, d_model, n_heads, n_encoder_layers, n_decoder_layers, d_ff, dropout=0.1):super().__init__()self.embedding = nn.Embedding(vocab_size, d_model)self.positional_encoding = PositionalEncoding(d_model)self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_encoder_layers)])self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(n_decoder_layers)])self.fc_out = nn.Linear(d_model, vocab_size)self.dropout = nn.Dropout(dropout)def forward(self, src, trg, src_mask, trg_mask):# 词嵌入src = self.embedding(src)src = self.positional_encoding(src)trg = self.embedding(trg)trg = self.positional_encoding(trg)# 编码器for layer in self.encoder_layers:src = layer(src, src_mask)# 解码器for layer in self.decoder_layers:trg = layer(trg, src, trg_mask, src_mask)output = self.fc_out(trg)return output
最后附上引用部分
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
模型效果
编写代码测试模型的复现是否正确(没有跑任务)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')vocab_size = 10000
d_model = 512
n_heads = 8
n_encoder_layers = 6
n_decoder_layers = 6
d_ff = 2048
dropout = 0.1transformer_model = Transformer(vocab_size, d_model, n_heads, n_encoder_layers, n_decoder_layers, d_ff, dropout).to(device)src = torch.randint(0, vocab_size, (32, 10)).to(device) # 源语言
trg = torch.randint(0, vocab_size, (32, 20)).to(device) # 目标语言src_mask = (src != 0).unsqueeze(1).unsqueeze(2).to(device)
trg_mask = (trg != 0).unsqueeze(1).unsqueeze(2).to(device)output = transformer_model(src, trg, src_mask, trg_mask)
print(output.shape)
打印结果
torch.Size([32, 20, 10000])
说明模型正常运行了
总结与心得体会
我是从CV模型学到Transfromer来的,通过对Transformer模型的复现我发现:
- 类似于残差的连接在Transformer中也十分常见,还有先缩小再放大的Bottleneck结构。
- 整个Transformer模型的核心处理对特征的维度没有变化,这一点和CV模型完全不同。
- Transformer的核心是多头自注意机制。



![[Python GUI PyQt] PyQt5快速入门](https://img-blog.csdnimg.cn/direct/dfab37ca62e24f6ea4a0eb9dde8626c6.png#pic_center)