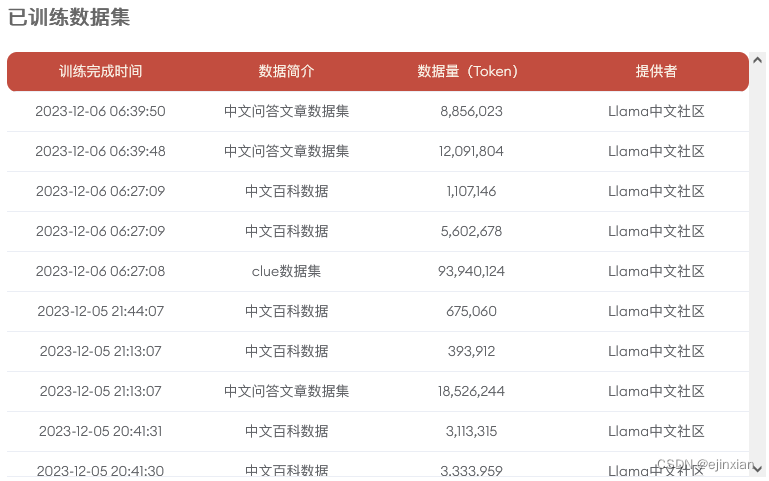
谈一谈BEV和Transformer在自动驾驶中的应用
BEV和Transformer都这么火,这次就聊一聊。

结尾有资料连接
一 BEV有什么用
首先,鸟瞰图并不能带来新的功能,对规控也没有什么额外的好处。
从鸟瞰图这个名词就可以看出来,本来摄像头等感知到的物体都是3D空间里的的,投影到2D空间,只是信息的损失,也很简单(乘一个矩阵)。甚至是变换到ST图上所需的,中间过程的必备一步。
怎么能说哪个用了鸟瞰图,哪个没用呢。
所以,BEV可以理解为,指一个端到端的感知架构。
所谓端到端,就是没有后处理,不需要作摄像头拼接和obj融合;单个摄像头内如对于道线的识别也不需要(像之前分割的方法那样)做后处理。
举一个反例,记忆泊车的感知算法,有一种做法是在AVM的图上进行SLAM,即使这是货真价实的在鸟瞰图上的算法,也没人天天宣传把这个叫BEV。
问题回到了感知本身。怎么做感知性能好。
不用作后处理当然是好事,如果没有其他缺点。只是,如果一个小球落下来,用牛顿力学一秒钟就能算准,是否需要做1万次实验,然后拟合一个网络来预测运动呢。
先说BEV优点:
-
在摄像头fov的重叠区域的物体,自动match和加权,省去了后处理的人工时;
-
跨越多个摄像头的物体,也就是fov边缘物体,可以先拼接后接入网络detection;如果不这么做,也可以再拼接一次再detection,但这样不太优雅;
-
数采同步由Lidar,且标注用Lidar做时,BEV的GT是现成的。而很多Mono3D网络的GT需要的2D框却没有现成的。
再说缺点:
-
重叠区域,双目多视角几何的距离等指标算的更准;
-
感知范围小(距离小一半),位置分表率低(投影之后分辨率为m级);
-
不透明的处理 相机内外参 和 IMU 等输入,类似上面牛顿力学的例子,交给网络去预测确定的公式;
-
暂无成熟的网络可用。
第一个优点,是使用BEV的核心诉求。
所以,一般BEV的模型还带上了如下feature:
-
时间滤波;
-
道线与地图的定位融合;
这些都是很好的探索,挖掘AI的应用潜力。
二 BEV怎么做
BEV要做的核心事情就是一件:把2D相机视角下的feature投影到2D鸟瞰图上。
但是,这个投影需要知道深度信息。当相机视角下,还没做到detection回归距离时,是只有平面的特征图的。‘
用AI,当然是假装知道了深度,投影变换用一个矩阵表示,然后靠数据去学习这个矩阵。可以理解为,把回归距离这一步在这做一遍。单帧图像当然可以做,靠近大远小,车和人的尺寸都是固定的,这个规律不难学到。
但是,细节上,想浪费时间的人且看以下:(我非常不喜欢看这些论文,但是最近看了不少):

(CVPR), 2019, https://doi.org/10.1109/cvpr.2019.00864
第一篇,先做深度估计,再做detection,能准就怪了。当你抬头看云彩,觉得一多云像草尼马后,你才会体会到距离,再之前,你是迷茫的。

FCOS3D:ICCVW, 2021
第二篇,深度估计和detection分离并行,同上,求大家灌水敬业一点。

Lift, Splat, Shoot: ECCV 2020
第三篇,非常粗爆,直接把cnn得到的features定义为深度分布和context(语义信息)。其中深度分度是一个41维的向量,且每个相机的每个像素点对应一个深度向量和语义向量。所以这是一个惊人大的需要去拟合的tensor。文章写的比较敷衍,连网络定义和图都没有,看样子也嫌浪费时间。

Simple-BEV. 2022.
第四篇,终于正常点,一个BEV点最多对应两个相机点,也就是200*200的矩阵中,每个点对应两个待拟合的小矩阵。比上一篇需要拟合的数少了1000倍。

DETR3D 2021
第五篇,用上了transformer,有网红潜力了。右下角那个decoder的query是按obj的数量来的,obj的数量在0-100之间波动,当数量少时,变成网络瓶颈,对训练效果以及推理的连续性肯定有影响。

BEVFormer ECCV 2022
第六篇,充分吸取过往经验,名字碰瓷tesla,BEVFormer,所以真红了。不过中间那个明明是decoder,为什么作者要叫encoder。
这篇和第四篇区别:1个BEV点要学习4个矩阵(4个偏置和权重),且网络深度上循环六次,比第四篇多10倍,可能第四篇太少了。
这篇和第五篇区别:那个蓝色的BEV queries大小固定,和BEV输出大小一致。比第五篇多1000-10000倍。
为什么要用Transfomer
先简单说下:
CNN 优点:
1适合并行计算
2适合视觉
3参数少(比MLP)
CNN 缺点:
1 没有全局联系 只能靠最后的全连接层(MLP) 但MLP不能太深
2 不适合做(时间)序列,不像RNN,所以滤波什么的不擅长。
RNN:我能做滤波啊,但RNN不适合并行(主要是训练),考虑到卡那么贵,还是算的快的能生存,所以被transformer淘汰了
Transformer优点:
1 适合并行计算(和CNN差不多)
2 适合做(时间)序列,所以BEV有了这个能力
3 对于大模型容易训练 (因为参数冗余多,不容易陷入局部最优),CNN也比较容易训练(自动驾驶适用大小的模型)。
4 可以建立长距离的联系 (CNN不行,MLP可以但是太臃肿)
Transformer缺点:
1 不适合视觉。所以backbone还是CNN
2 没了。
But,上面文章中的Transformer是假的。至于为啥,下次再说。
我一直认为,模型是啥,本身就不重要:
-
这几年GoogLeNet为代表的复杂模型已经被淘汰了,
-
CNN在工业界已全是最简单的残差模型,
-
GPT的胜出也证明模型越简单越好,
-
AutoML以及NAS(网络架构搜索)毫无进展
所以,只要有进化条件,任何构型的生物都能在智能上超越人类。
三 注意力机制 Transformer的核心
大家都知道Transformer诞生的那篇google的论文叫什么什么is all your need。
注意力就是不同位置之间关联有多紧密的权重。
两个向量点积,模的最大值产生于向量夹角为0。也就是说,如果两个word意义相近,embedding向量也就相近,那自然注意力就大。这是最简单的一种情况,不用考虑位置向量。

红框里的计算,就是在去求这个关联的权重,得到一个方阵。毫无疑问,这就是trasformer的核心之处。

多说一句,为什么不直接学右边这个矩阵,而是要学左边这两个矩阵呢?
在NLP里,句子的最大长度在100-1000这个量级,而词向量的维度一般在10000-50000这个量级。
分别按100和10000举例,学左边,要学2000000(=2*100*10000)个参数;右边只要学10000(=100*100)个参数。相差200倍。
这里涉及到了AI原理性的问题,参数越少,训练越容易陷入局部最优,而参数多了,到处都是鞍点(维度高了,所有维度的二阶导都同号的概率低),很容易滑出去。
我们来看这些BEV论文怎么做的:

这里的注意力A是直接学出来的,并没有经过左边的乘法,而且它不是一个方阵,竟是一个标量。和Transformer愿意扩充200倍参数,是完全相反的。
看这个公式,确实只是一个b为0的单层MLP,Nkey的node,输出q维,输入x维。
我们可以看到,右边是BEV坐标(q),左边是相机坐标§,这个公式就是把相机坐标映射到了BEV坐标。我一直没搞明白为什么要分自顶向下和反过来,不就是把等式左右两边换一下。
四 多头 决定Transformer能力的重要维度
关联有多种含义,比如一个人的头和手是关联的,代表了同一个人;一个人的头和另一个人的头是关联的,代表了都是头。
所以,这就是Multi-Head,多头注意力,一个位置在不同意义上和多个其他位置关联。
此外,Multi-Head还能再多出很多倍参数。NLP里,transformer的头数一般是100。

上面是一个8头的示意,先把每个头的输出拼接起来,再降维(找到最突出的方向)。
我们来看这些BEV论文怎么做的:

文中的Nhead是8。
但是,这是求和,其实还是加权,只不过把A的加权维度从8提升到了64.
所以,是单头。
五 位置编码 Transformer的必备要素
Transformer本身不能分辨输入的位置,对它来说,两个词调换位置是无感地(只要后面地向量位置都跟着换),所以处理序列问题(位置很重要)必须要加位置编码。包括Vit。
我们来看这些BEV论文怎么做的:
位置编码是一个学到的矩阵。
看来,这不是位置编码,只是叫这个名字。它们根本不关心输入的顺序。编码都是要精心设计的,要能有区分度,而且至少不能有重复的吧。
那为什么会这样呢?

会不会是因为,CNN压根就不需要位置编码呢。
六 其他
还有很多不像的地方,比如每个encoder都有的那个不参与反向算梯度的上一时刻的输出。
我猜可能不这样,梯度就传不下去,毕竟如前所说太瘦了。
我们回顾一下上次说的transformer的优点:
1 适合并行计算。因为既没有多头,也没有矩阵乘法,标量计算的维度也不大,所以变成了并行计算瓶颈。Transformer的特点没有了。
2 适合做(时间)序列,没有位置编码。
3 对于大模型容易训练 参数少。
4 可以建立长距离的联系 连“距离”这个概念都没有。而且都是在周围局部位置的加权。