论文:TransUNet:Transformers Make Strong Encoders for Medical Image Segmentation
目录
Abstract
Introduction
Related Works
各种研究试图将自注意机制集成到CNN中。
Transformer
Method
Transformer as Encoder
图像序列化
Patch Embedding
TransUNet
CNN-Transformer Hybrid as Encoder
级联上采样
Experiments and Discussion
数据集和评估
消融实验
skip-connection的消融实验
输入分辨率的消融实验
序列长度和补丁大小的消融实验
模型缩放的消融实验
可视化
Conclusion
Abstract
在深度学习医学图像分割领域,UNet结构一直以来都牢牢占据着主导地位,并取得了巨大的成功。然而,由于卷积操作的固有局部性,U-Net通常在远程依赖方面表现出局限性。Transformer是为序列到序列的预测而设计的,已经成为具有固有全局自注意力机制的替代架构,但由于缺乏低级细节,可能导致定位能力有限。
在本文中,作者提出了TransUNet,它兼有transformer和U-Net的优点,作为医学图像分割的强大替代方案。一方面,Transformer对来自卷积神经网络(CNN)特征映射的标记化图像patches进行编码,作为提取全局上下文的输入序列。另一方面,解码器对编码特征进行采样,然后将其与高分辨率CNN特征图相结合,以实现精确的定位。
Introduction
卷积网络的兴起,促进了图像领域的进步。并且广泛应用于图像分类任务,但是在一些特定场景,如生物医学图像处理领域,通常是需要像素级的分类任务,也就是图像分割任务。
生物医学图像的特点:
1、图像语义较为简单,结构较为固定;
2、数据量少;
3、可解释性重要。
Unet是一个包含4层下采样、4层上采样以及一个类似跳跃连接结构的全卷积网络。数据先经过传统的特征提取路径来获取语义信息,将图像压缩为由特征组成的特征图,然后再经过特征复原路径来精准定位,将提取的特征解码为与原始图像尺寸一样的分割后的预测图像。
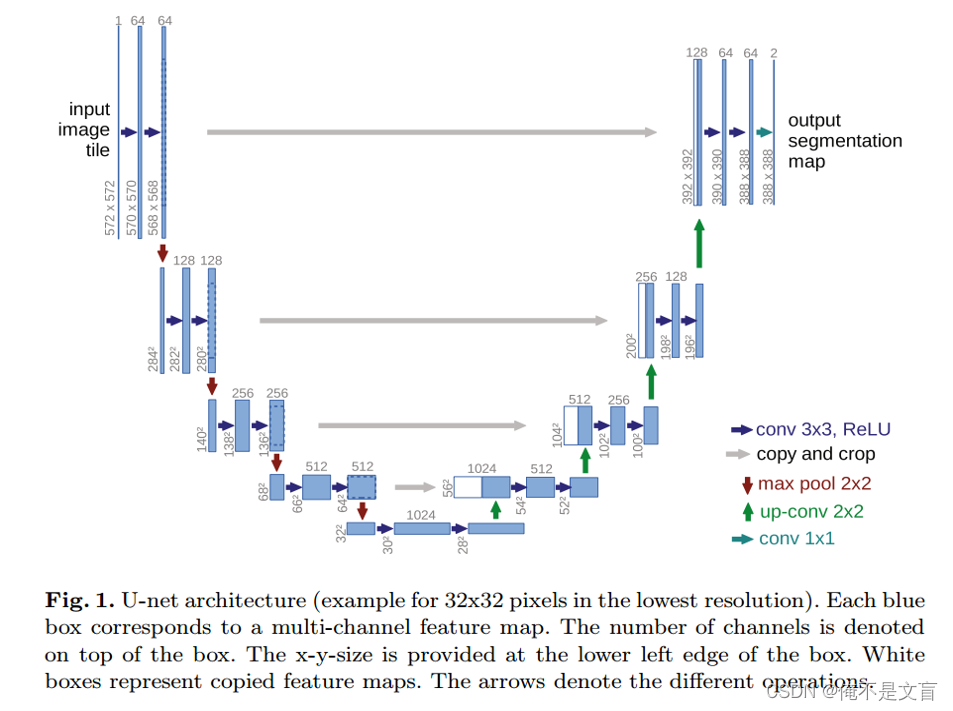
Encoder:左半部分,由两个3x3的卷积层(RELU)再加上一个2x2的max pooling层组成一个下采样的模块;
Decoder:右半部分,由一个上采样的卷积层(去卷积层)+特征拼接concat+两个3x3的卷积层(ReLU)反复构成;这种通过通道数的拼接,可以得到更多的特征。
Related Works
各种研究试图将自注意机制集成到CNN中。
卡内基梅隆大学的王小龙等人设计了一个非局部算子,可插入多个中间卷积层。
Schlemper等人在编码器-解码器u型架构的基础上,提出了集成到跳过连接中的附加注意门模块。
与这些方法不同的是,作者使用了transformer来嵌入全局自注意力机制。
Transformer
Transformer被提出用于机器翻译,并在许多NLP任务中建立了最先进的状态。为了使Transformer也适用于计算机视觉任务,进行了一些修改。
Parmar等对每个查询像素仅在局部邻域应用自注意,而不是全局应用。
Child等人提出了稀疏transformer,它采用可扩展的近似全局自注意力。
最近,Vision Transformer (ViT)通过直接将具有全局自注意力的Transformer应用于全尺寸图像,实现了最先进的ImageNet分类。据我们所知,TransUNet是第一个基于transform的医学图像分割框架,它建立在非常成功的ViT之上。
Method
Transformer as Encoder
图像序列化
首先通过将输入属于
,给定图像其空间分辨率为H*W,通道数为C。用
大小的切片去分割图片可以得到N个切片(N=
是图像切片的数量,即输入序列长度),那么每个切片的尺寸就是P∗P∗C,形成二维的序列,转化为向量,将N个切片重组后向量连接就可以得到𝑁∗𝑃∗𝑃∗𝐶(总的输入变换)的二维矩阵。
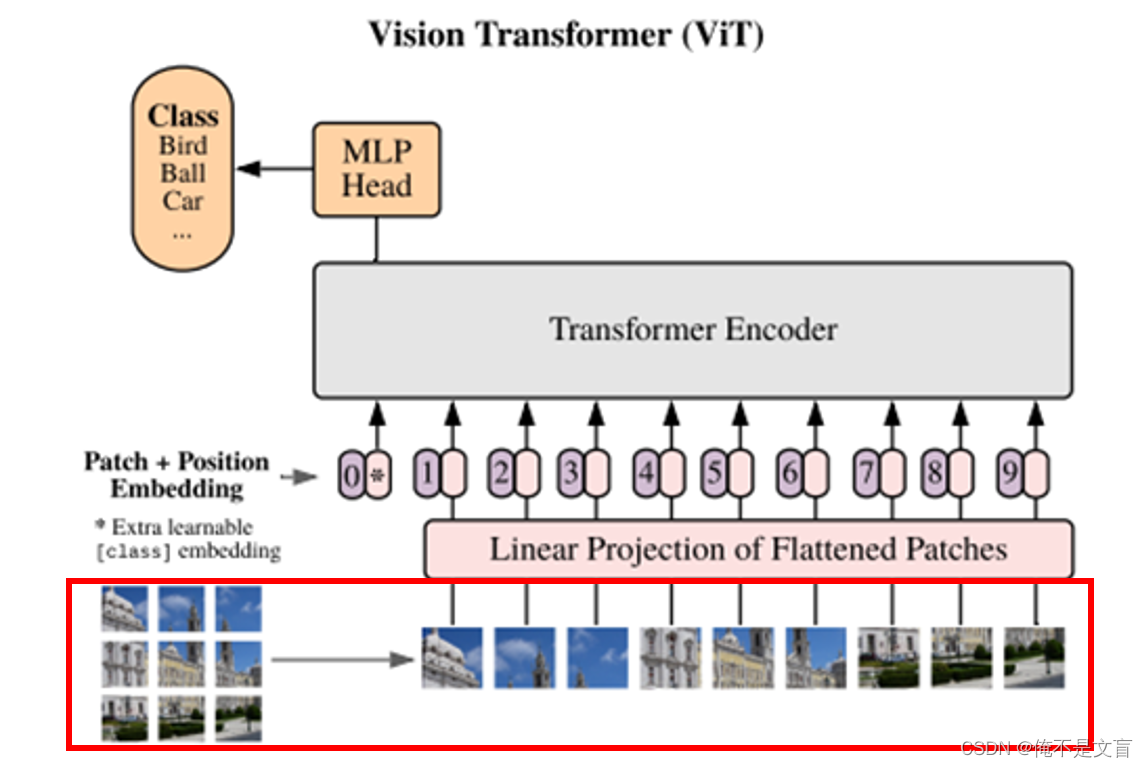
Patch Embedding
需要注意,作者最后进行Patch Embeding的输入并不是图像序列化,而是CNN提取到的特征;
切片𝑥𝑝x_p通过线性投影( linear projection)映射到D维的嵌入空间,为了对patch空间信息进行编码,我们学习特定的位置嵌入,并将其添加到patch嵌入中以保留位置信息,方法如下:
其中为嵌入投影,
为位置投影
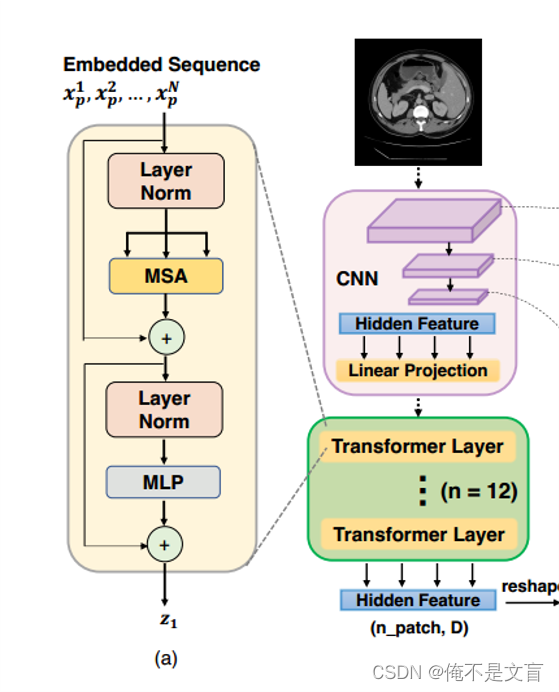
Tranformer编码器由L层多头自注意(MSA)和多层感知器(MLP)块(等式)组成

式中LN(·)为层归一化算子,为编码后的图像表示。
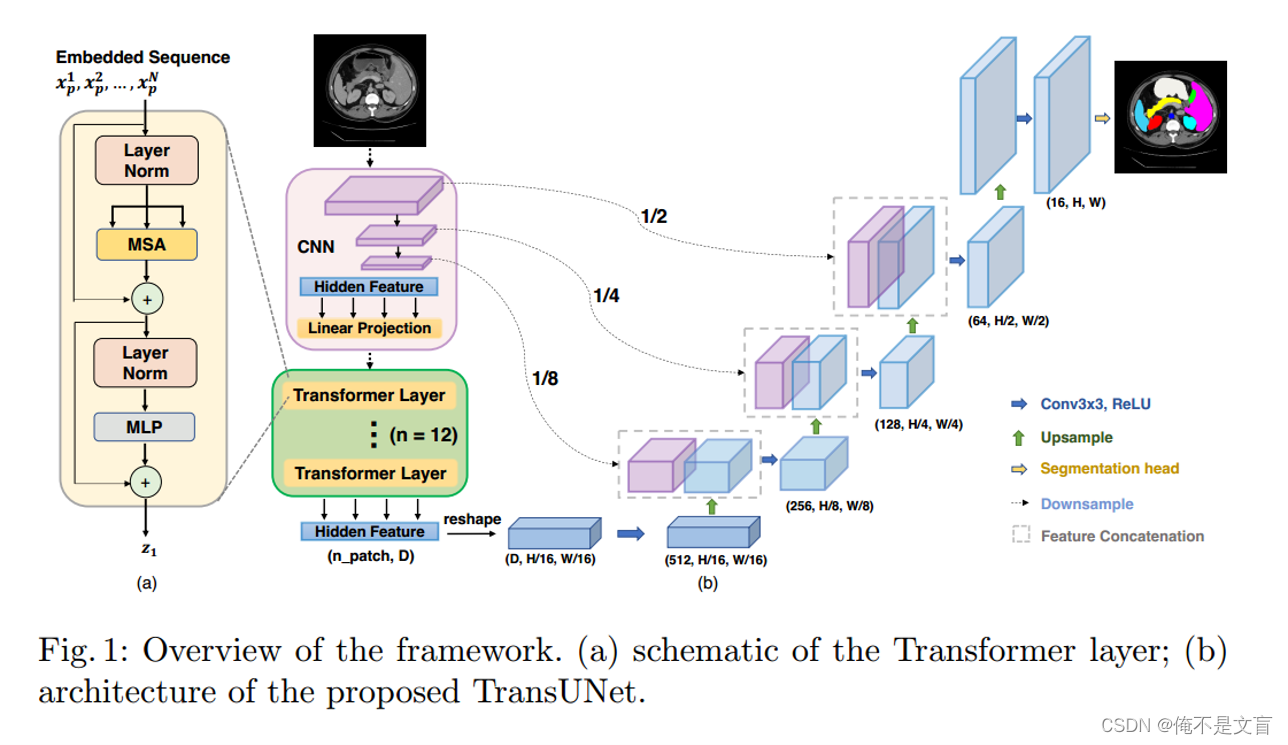
TransUNet
transformer作为encoder部分,对transformer后的编码特征是,为了恢复空间信息,将
恢复至
,然后使用U-Net的decoder部分,上采样恢复分辨率至
。虽然也能产生合理的结果,但结果比较粗糙,缺少高分辨率的细节信息。也就是说此时的结构不是transformer的最佳应用,因为通常
比
小很多,分辨率在恢复至
过程中,不可避免导致定位信息的损失。为了弥补这种定位细节信息的损失,作者继续提出了CNN-Transformer的混合结构。
CNN-Transformer Hybrid as Encoder
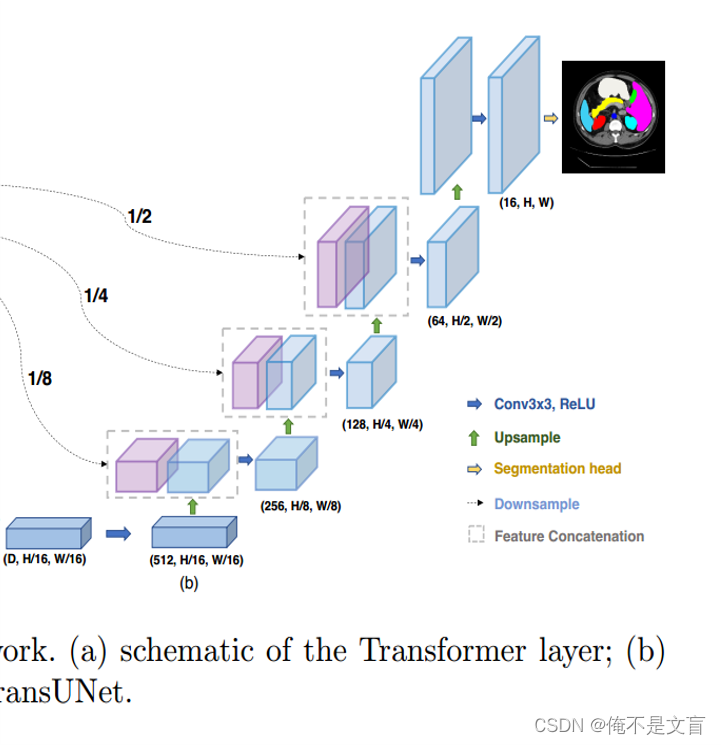
TransUNet不是使用纯Transformer作为编码器,而是使用CNN-Transformer混合模型,其中CNN首先用作特征提取器,为输入生成特征映射。Patch embedding是对CNN feature map中提取的1 × 1的Patch进行嵌入,而不是对原始图像进行嵌入。
我们选择这种设计是因为:
1)它允许我们在解码路径中利用中间高分辨率CNN特征图;
2)我们发现混合CNN-Transformer编码器比简单地使用纯Transformer作为编码器性能更好。
级联上采样
作者引入了一个级联上采样器(CUP),它由多个上采样步骤组成,用于解码隐藏特征以输出最终的分割掩码。在将隐藏特征的序列重塑为
的形状后,我们通过级联多个上采样块来实例化CUP,以达到从
到
的全分辨率,其中每个块依次由上采样算子、3×3卷积层和ReLU层组成。
整体TransUNet框图如下图所示
Experiments and Discussion
数据集和评估
Synapse multi-organ segmentation dataset(Synapse多器官分割数据集)腹部CT扫描 (30次腹部CT扫描 总共有3779张轴向增强腹部临床CT图像)报告了8个腹部器官的平均Dice和平均豪斯多夫距离(HD),随机分为18个训练病例(2212个轴向切片)和12个验证病例。
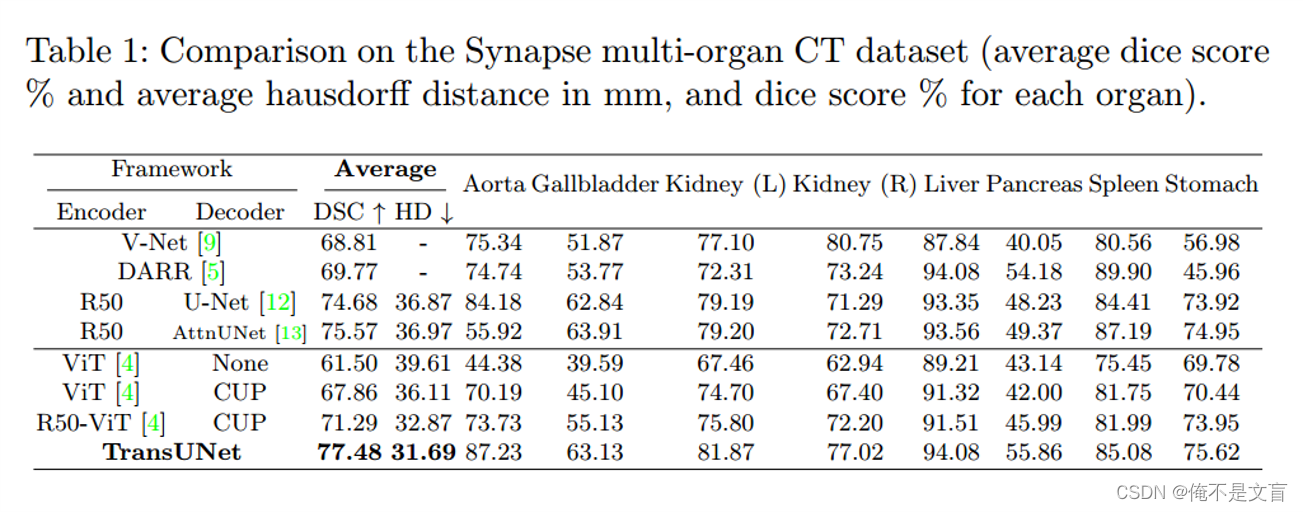 Automated cardiac diagnosis challenge心脏CMR(心脏核磁)一系列短轴切片从左心室底部到顶部覆盖心脏,切片厚度为5至8毫米。短轴平面内空间分辨率从0.83到1.75 mm^2/pixel。每个患者扫描都用手工标注了左心室(LV)、右心室(RV)和心肌(MYO)。报告了平均Dice,随机分为70个训练病例(1930个轴向切片),10个用于验证,20个用于测试。
Automated cardiac diagnosis challenge心脏CMR(心脏核磁)一系列短轴切片从左心室底部到顶部覆盖心脏,切片厚度为5至8毫米。短轴平面内空间分辨率从0.83到1.75 mm^2/pixel。每个患者扫描都用手工标注了左心室(LV)、右心室(RV)和心肌(MYO)。报告了平均Dice,随机分为70个训练病例(1930个轴向切片),10个用于验证,20个用于测试。
消融实验
为了彻底评估TransUNet框架并验证其在不同设置下的性能,进行了各种消融研究
包括:1)跳过连接数;2)输入分辨率;3)序列长度和补丁大小;4)模型缩放。
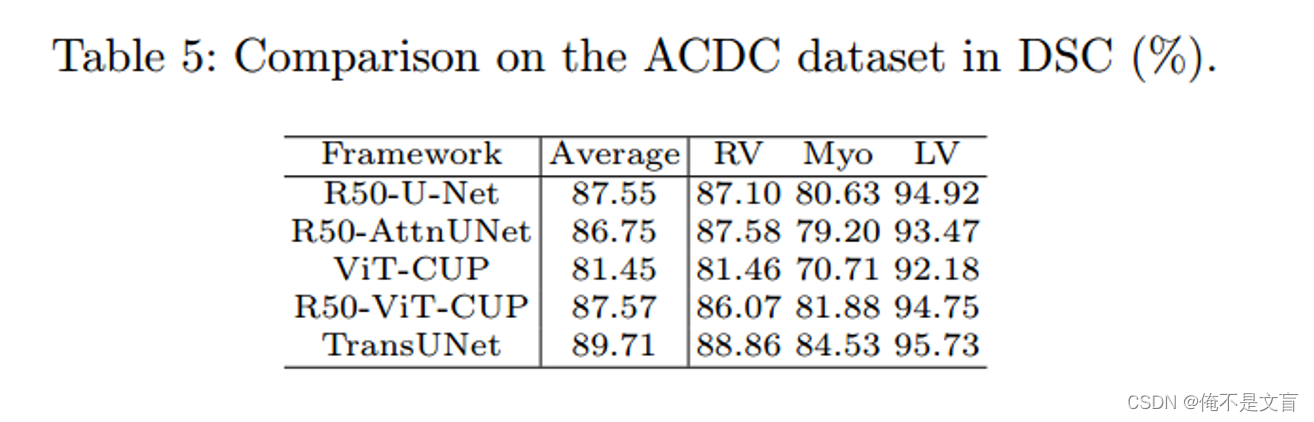
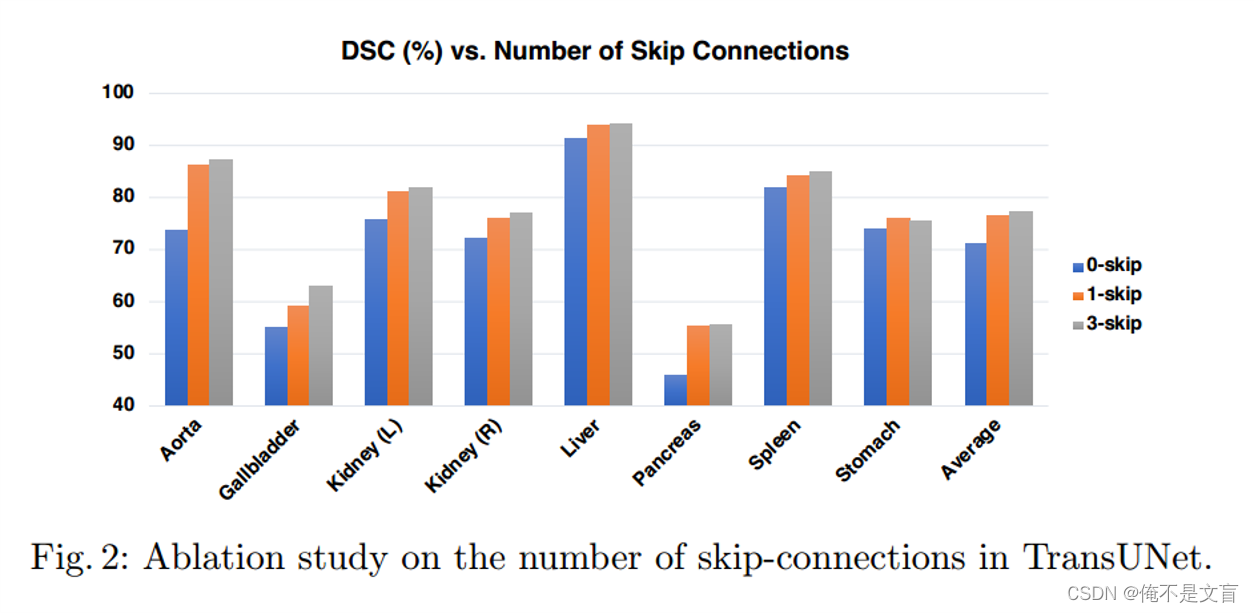
skip-connection的消融实验
首先做了skip-connection的消融实验,可以明显看出3层跳跃连接的DSC更高,代表着跳跃连接的增加对模型是有益的。
输入分辨率的消融实验
作者测试了224×224分辨率和512×512分辨率的DSC,发现512×512分辨率图像作为输入获得了更高的DSC,但是处于性能考虑,还是选择了224×224进行后续测试。

序列长度和补丁大小的消融实验
较小的patch尺寸可以获得较高的分割性能。
Transformer的序列长度与补丁大小的平方成反比

模型缩放的消融实验
最后,我们对不同模型尺寸的TransUNet进行了消融实验。作者研究了两种不同的TransUNet配置, “Base”和“Large”模型。对于“Base”模型,隐藏大小D、层数、MLP大小和头部数量分别设置为12、768、3072和12;而“Large”模型的这些超参数分别设置为24、1024、4096和16。从表4我们得出结论,更大的模型导致更好的性能。考虑到计算成本,所有实验均采用“Base”模型。 
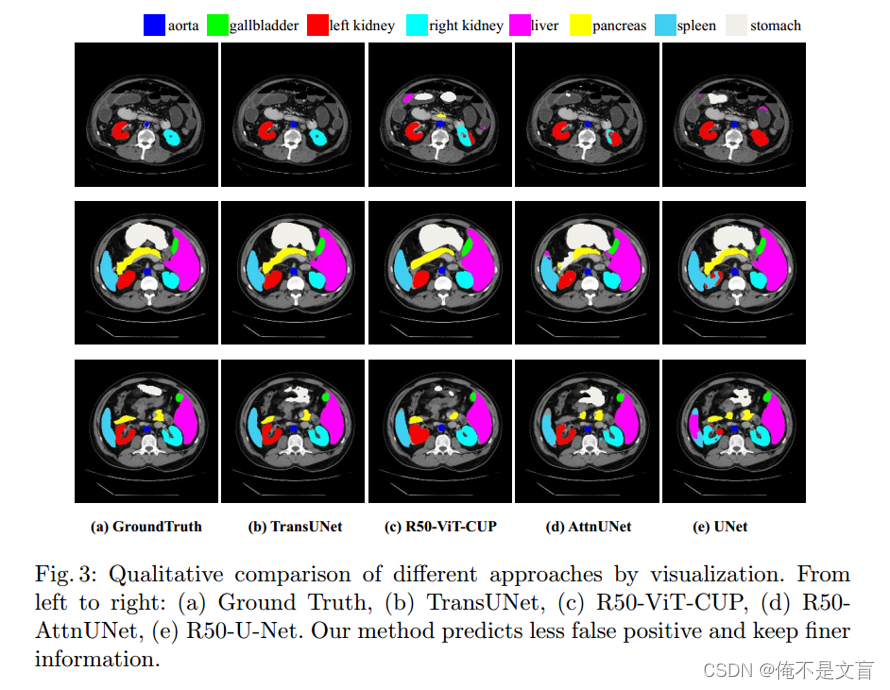
可视化
作者还进行可视化比较,从图中可以看出TransUnet的分割更为精细,错误率更低。
Conclusion
TransUNet是率先将Transformer结构用于医学图像分割工作的研究。TransUNet将重视全局信息的Transformer结构和底层图像特征的CNN一起进行混合编码,能够更大程度上提升UNet的分割效果。Transformer是一种天生具有强大自注意机制的结构。在这篇论文中,作者研究Transformer在一般医学图像分割中的应用。为了充分利用Transformer的力量,提出了TransUNet,它不仅将图像特征作为序列来编码强全局上下文,还通过Unet混合网络设计来很好地利用低层CNN特征。TransUNet可作为一种替代框架用于医学图像分割,其性能优于各种竞争方法,包括基于cnn的自注意力方法。本文为了完整的应用transformer,提出了TransUNet, 不仅通过将图像以序列处理编码全局上下文信息,也通过使用U型结构将低层次CNN特征利用上,作为基于FCN的主流医学图像分割方法的替代框架,在医学图像分割上(包括多器官分割和心脏分割)上均比各种竞争方法(像基于CNN的自注意方法)具有更优的表现。