目录
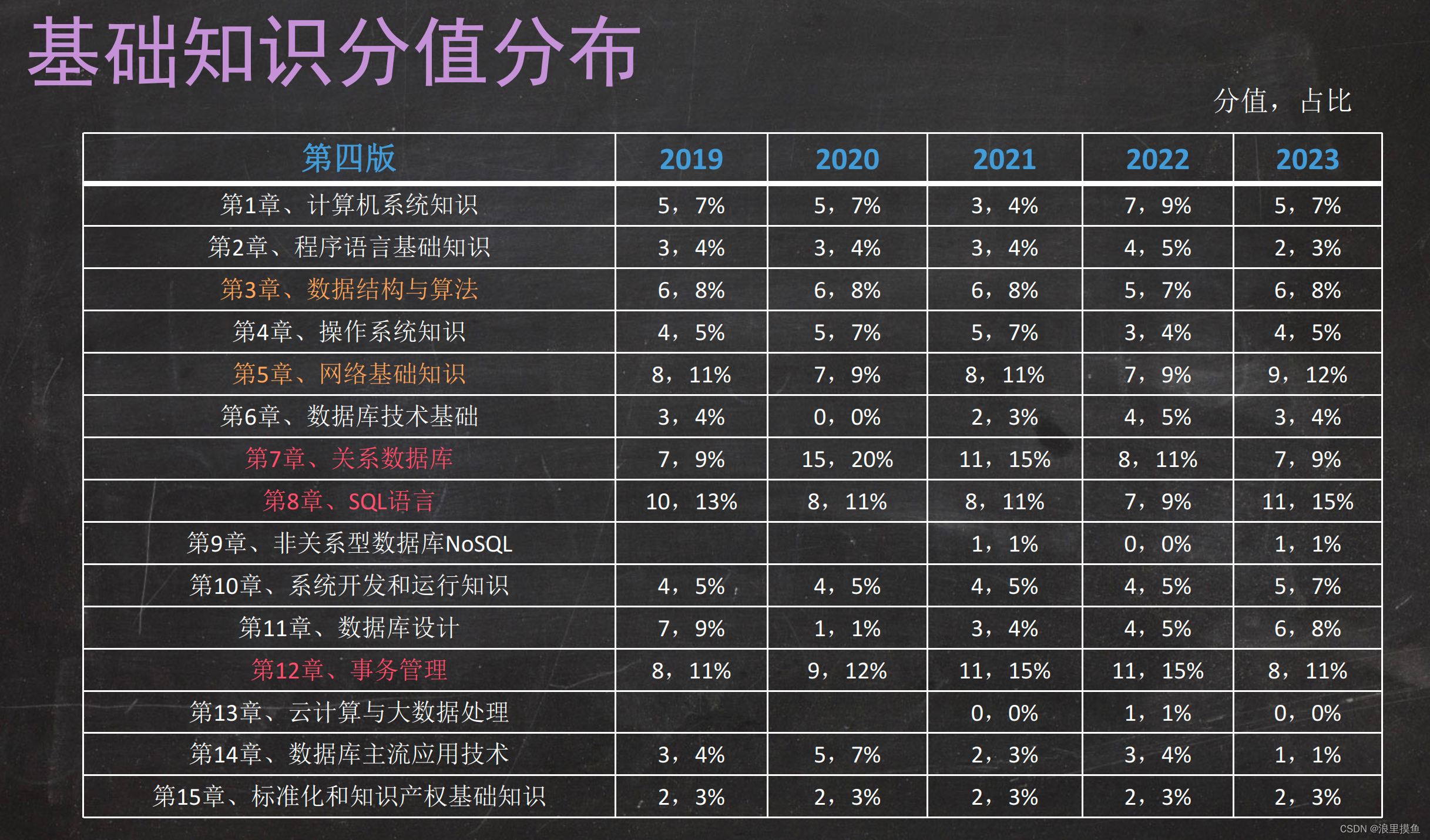
- 分值分布
- 1. 事务管理
- 1.1 事物的基本概念
- 1.2 数据库的并发控制
- 1.2.1 事务调度概念
- 1.2.2 并发操作带来的问题
- 1.2.3 并发控制技术
- 1.2.4 隔离级别:
- 1.3 数据库的备份和恢复
- 1.3.1 故障种类
- 1.3.2 备份方法
- 1.3.3 日志文件
- 1.3.4 恢复
- SQL语言
- 发权限
- 收权限
- 视图
- 触发器
- 创建触发器
- 更改、删除触发器
- 嵌入式SQL
- 游标
- 存储过程
- 回顾
- 数据定义语言 (DDL)
- 数据库和表的操作
- 索引
- 视图
- 数据操纵语言 (DML)
- 数据操作
- 查询数据
- 数据控制语言 (DCL)
- 权限管理
- 其他重要概念与语句
- 存储过程 (Stored Procedure)
- 创建存储过程
- 调用存储过程
- 修改存储过程
- 删除存储过程
- 嵌入式SQL (Embedded SQL)
- 定义与使用主变量
- 预编译与动态SQL
- 游标 (Cursor)
- 声明游标
- 打开游标
- 使用游标读取数据
- 关闭游标
- 游标操作示例
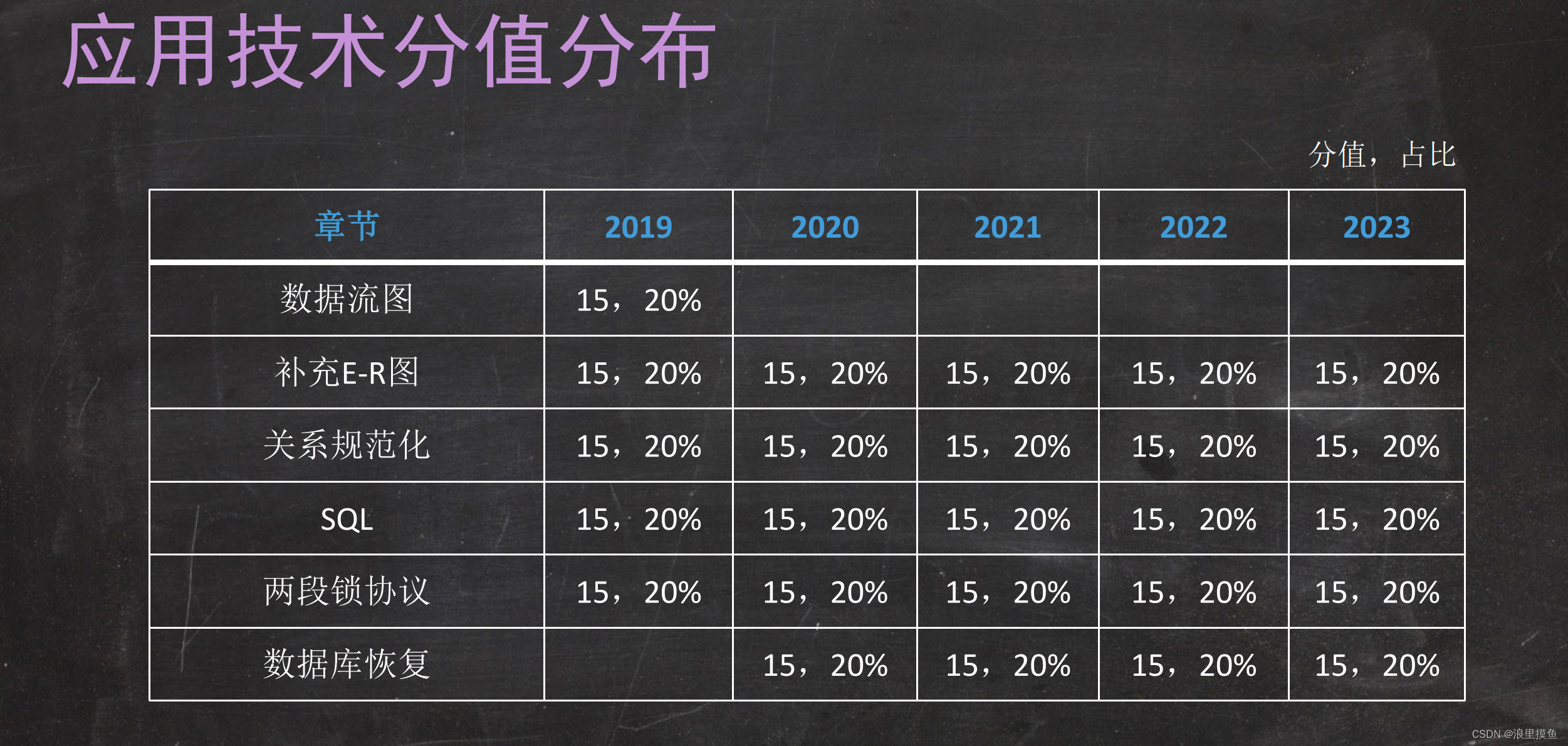
分值分布
1. 事务管理
1.1 事物的基本概念
●概念:一个操作序列,要么都做,要么都不做,是不可分割的逻辑工作单位。
●定义语句:
BEGINTRANSACTION/ENDTRANSACTION:事务开始/事务结束。
ROLLBACK:事务回滚,表示事务非成功地结束。
COMMIT:事务提交,表示事务成功地结束。
●特性
原子性:事务是原子的,要么做,要么都不做。
一致性:事务执行的结果必须保证数据库从一个一致性状态变到另一个一致性状态。
隔离性:事务相互隔离。当多个事务并发执行时,任一事务的更新操作直到其成功提交的整个过程,对其它事物都是不可见的。
持久性:一旦事务成功提交,即使数据库崩溃,其对数据库的更新操作也永久有效。
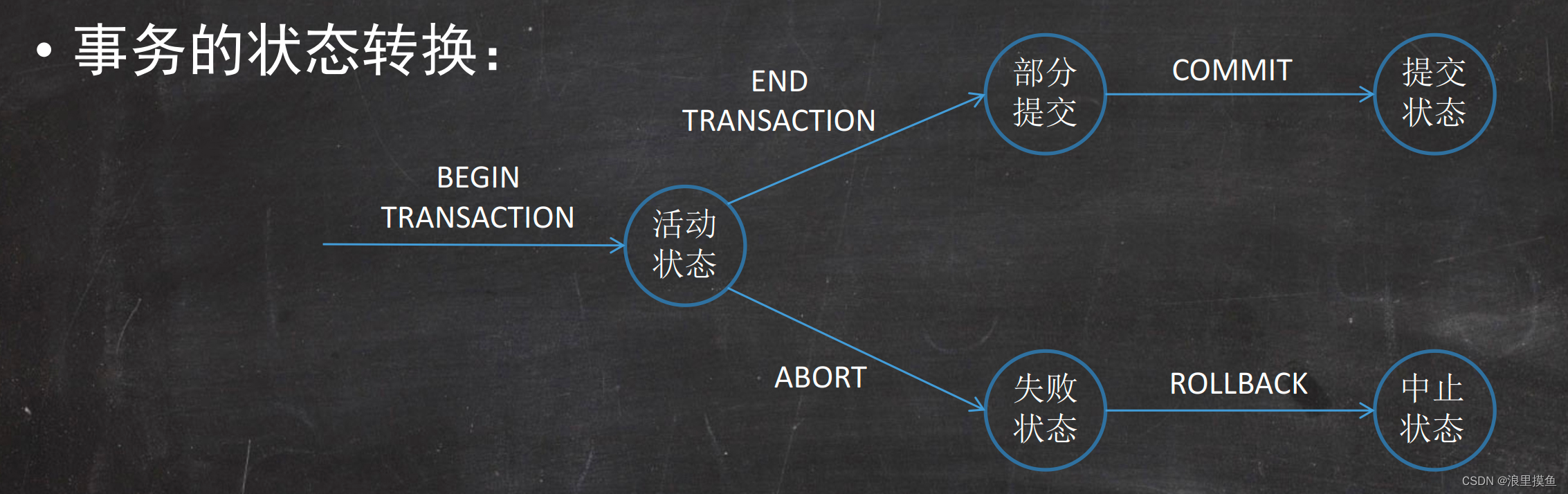
●状态
活动状态:事务的初始状态,事务执行时处于这个状态。
部分提交状态:当操作序列的最后一条语句自动执行后,事务处于部分提交状态。部分提交状态并不等于事务成功执行。
失败状态:由于错误使得事务不能继续正常执行,事务就进入了失败状态。
中止状态:事务回滚并且数据库已被恢复到事务开始执行前的状态。
提交状态:当事务成功完成后,称事务处于提交状态。
1.2 数据库的并发控制
1.2.1 事务调度概念
调度:事务的执行次序。
串行调度:多个事务依次串行执行,且只有当一个事务的所有操作都执行完后才执行另一个事务的所有操作。
并行调度:利用分时的方法同时处理多个事务。
调度错误的定义是结果算错了才叫错,并行的结果要和任意串行结果一致。—>可串行化的调度
多个事务的并发执行是正确的, 当且仅当其结果与某一次序串行地执行它们的结果相同, 称这种调度策略是可串行化的调度。
可串行性是并发事务正确性的准则。 即: 一个给定的并发调度, 当且仅当它是可串行化的才认为是正确调度
错误的调度及产生错误的原因:丢失修改/不可重复读/读脏数,破坏了事务的隔离性
1.2.2 并发操作带来的问题
丢失修改、不可重复读、读脏数据,幻读。
幻读是按照相同条件查询,两次查到不一样。
不可重复读是两个查询同数据,读取数据不一样。
都是违反了隔离性
1.2.3 并发控制技术
封锁(X锁、S锁)、三级封锁协议、两阶段封锁协议。
X锁(排它锁):工作类流程和串行调度一样
S锁(共享锁):只读不改
三级封锁协议:

两阶段封锁协议:

加锁阶段(Growing Phase):事务开始后,可以对任何数据项加锁(读锁或写锁),但不能释放任何锁。
解锁阶段(Shrinking Phase):事务提交(COMMIT)时,释放所有锁;事务回滚(ROLLBACK)时,也必须释放已获取的所有锁。
满足两段锁协议—>可串行化—>并发事务正确执行–x->不能保证不发生死锁
1.2.4 隔离级别:
1、READ UNCOMMITTED(读未提交):可避免丢失修改。
2、READ COMMITTED<读已提交):可避免丢失修改、读脏数据。
3、REPEATABLE READ(可重复读):可避免丢失修改、读脏数据,不可重复读。
4、SERIALIZABLE(串行化):最高级别,可避免丢失修改、读脏数据、不可重复读、幻读。
幻读:事务A查询得到N条数据,然后事务B又插入了M条数据,或者改变了这N条数据之外的N条符合事务A搜索条件的数据,导致事务A再次搜索发现有N+W条数据了,就产生了幻读。
1.3 数据库的备份和恢复
1.3.1 故障种类
1、 事务故障: 是由于程序执行错误而引起事务非预期的、 异常终止的故障。 通常有如下两类错误引起事务执行失败:
(1) 逻辑错误。 如非法输入、 找不到数据、 溢出、 超出资源限制等原因引起的事务执行失败。
(2) 系统错误。 系统进入一种不良状态(如死锁) , 导致事务无法继续执行
2、 系统故障(通常称为软故障):是指硬件故障、 软件(如DBMS、 OS或应用程序) 漏洞的影响, 导致丢失了内存中的信息, 影响正在执行的事务, 但未破坏存储在外存上的信息。
3、 介质故障(通常称为硬故障):是指外存故障,例如磁盘损坏、磁头碰撞,瞬时强磁场干扰等。
1.3.2 备份方法
静态转储:是指在转储期间不允许对数据库进行任务存取、修改操作。用来恢复
动态转储:是在转储期间允许对数据库进行存取、修改操作,转储和用户事务可并行执行。
海量转储:是指每次转储全部数据库。
增量转储:是指每次只转储上次转储后更新过的数据。
1.3.3 日志文件
日志文件是用来记录事务对数据库的更新操作的文件。
数据库镜像。 为了避免磁盘介质出现故障影响数据库的可用性, 许多DBMS提供数据库镜像功能用于数据库恢复
1.3.4 恢复
UNDO:撤销事务,将未完成的事务撤消,使数据库回复到事务执行前的正确状态。
撤销事务的过程: 反向扫描日志文件(由后向前扫描) , 查找事务的更新操作; 对该事务的更新操作执行逆操作, 用日志文件记录中更新前的值写入数据库, 插入的记录从数据库中删除, 删除的记录重新插入数据库中; 继续反向扫描日志文件, 查找该事务的其它更新操作并执行逆操作直至事务开始标志。
REDO:重做事务,将已经提交的事务重新执行。
重做事务的过程: 从事务的开始标志起, 正向扫描日志文件, 重新执行日志文件登记的该事务对数据库的所有操作, 直至事务结束标识。
检查点机制(CHECKPOINT): 在日志中设置检查点, 当发生故障需要利用日志文件恢复时, 反向扫描日志文件, 找到检查点, 确认检查点时刻正在执行的事务(活动事务) , 即检查点前有事务开始标志但没有事务结束标志。
对于检查点后提交的事务, 执行REDO(重做)
对于检查点后未提交的事务, 执行UNDO(撤销)
(1) 事务故障的恢复: 事务故障是事务在运行至正常终止点(SUMMIT或ROLLBACK) 前终止, 日志文件只有该事务的开始标识而没有结束标识。
恢复:撤销(UNDO)
具体做法:
1、 反向扫描日志文件, 查找该事务的更新操作。
2、 对事务的更新操作执行逆操作。
3、 继续反向扫描日志文件, 查找该事务的其他更新操作, 并做同样的处理, 直到事务的开始标志。
注: 事务故障的恢复是由系统自动完成的, 对用户是透明的。
(2) 系统故障的恢复: 系统故障会使数据库的数据不一致:
一是未完成的事务对数据库的更新可能已经写入数据库;
二是已提交的事务对数据库的更新可能还在缓冲区没来得及写入数据库。
恢复:
1、 未完成的事务(UNDO)
2、 已经提交 commit 的事务(REDO)
(3) 介质故障的恢复: 介质故障时数据库遭到破坏, 需要重装数据库, 一般需要DBA的参与, 装载故障前最近一次的备份和故障前的日志文件副本,
恢复:
1、 未完成的事务(UNDO)
2、 已经提交 commit 的事务(REDO)
SQL语言
主要记忆:表、索引、视图操作语句;数据操作;通配符、转义符;授权;存储过程;触发器
这部分等等整理一下:
“”"
1、 数据定义语言。 SQL DDL提供定义关系模式和视图、 删除关系和视图、 修改关系模式的命令。
数据库 DDL 的全称是 Data Definition Language。
2、 交互式数据操纵语言。 SQL DML提供查询、 插入、 删除和修改的命令。
3、 事务控制。 SQL提供定义事务开始和结束的命令。
4、 嵌入式SQL和动态SQL。 用于嵌入到某种通用的高级语言中混合编程。 其中, SQL负责操纵数据库,
高级语言负责控制程序流程。
5、 完整性。 SQL DDL包括定义数据库中的数据必须满足的完整性约束条件的命令, 对于破坏完整性
约束条件的更新将被禁止。
6、 权限管理。 SQL DDL中包括说明对关系和视图的访问权限。
7、 SQL语言中完成核心功能的9个动词:
(1) 数据查询: Select
(2) 数据定义: Create、 Drop、 Alter
(3) 数据操纵: Insert、 Update、 Delete
(4) 数据控制: Grant、 Revoke
不常用的sql语句
check 为什么不用in?
数据库表的复合属性:是指由两个或更多基本属性组成,用来共同描述一个复杂的数据项的属性。复合属性体现了现实世界中某些实体属性的内在联系与结构化特征,它们不能被进一步拆分为独立的、原子性的属性。在数据库设计中,复合属性有助于更准确、更完整地表示实体的复杂特性,同时也便于数据的一致性和完整性管理。以下是对复合属性的详细说明:
示例与特征
示例:
家庭住址:由省、市、区、街道、门牌号等多个部分构成,这些部分一起构成了一个完整的地址信息。
联系电话:可能包括国家代码、区号、电话号码,甚至分机号,整体构成了一个可拨打的电话联系方式。
时间戳:由年、月、日、时、分、秒组成,共同标识一个精确的时间点。
“”"
发权限
grant 允许;同意

赋所有权限:GRANT ALL PRIVILEGES
on 表 to人
收权限
revoke 撤回
RESTRICT 限制
CASCADE 垂直

视图
行级视图:通常指从行的角度来理解和操作矩阵。
列级视图:更强调从列的角度来分析矩阵。
触发器
触发器是一种特殊的数据库对象,它们与特定的表相关联,并且在特定的数据库操作(即事件)发生时自动执行预定义的逻辑。
触发器通常与以下三种数据库操作事件关联:
- INSERT:当向表中插入新行时触发。
- UPDATE:当修改表中已存在的行时触发。
- DELETE:当从表中删除行时触发。
SELECT不使用触发器
这些事件均涉及到对表数据的实际改动,因此触发器可以在这些操作前后执行,以便检查条件、执行额外的数据修改、记录变更历史或其他所需的操作。
行级触发器(Row-Level Trigger): 行级触发器是在对表中的某一行执行 INSERT、UPDATE 或 DELETE 操作时被触发的。每当这样的操作影响到表中的一个具体行时,行级触发器就会被激活并执行一次。这意味着,如果一个 SQL 语句影响到了多行数据(例如,一个批量更新或删除操作),行级触发器会为受影响的每一行单独触发并执行一次。行级触发器可以在触发操作之前(BEFORE 触发器)或之后(AFTER 触发器)执行,适用于需要对每一行变化进行细致控制、日志记录、数据校验、计算派生值等场景。
语句级触发器(Statement-Level Trigger): 语句级触发器则是在执行某个影响表的 SQL 语句时,无论该语句影响了多少行数据,触发器只会被触发一次。也就是说,即使一个 SQL 语句更改了成百上千行,语句级触发器也仅执行一次其定义的逻辑。这类触发器适用于需要对整个操作过程进行统一处理、执行一次性清理或初始化任务、或者在事务层面实施某种策略的情况。
创建触发器时需指定:
(1) 触发器名称
(2) 在其上定义触发器的表
(3) 触发事件: 触发器将何时激发
(3) 触发条件: 满足什么条件时执行触发动作
(4) 触发动作: 指明触发器执行时应做的动作
创建触发器

更改、删除触发器

嵌入式SQL
类似于mybatis,能在c、java等其他代码里面,直接调用sql。
例如:在c语言中的使用
#include <stdio.h>
#include <sql.h> /* 假设为某个数据库提供的头文件 */int main() {int emp_id;char name[50];float salary;/*EXEC SQL 调用 sql*/EXEC SQL SELECT name, salary INTO :name, :salary FROM employees WHERE id = :emp_id;if (sqlca.sqlcode == 0) { /* sqlca 检查SQL执行状态 */printf("Employee Name: %s\nSalary: %.2f\n", name, salary);} else {printf("Error retrieving employee details: %s\n", sqlca.sqlerrm.sqlerrmc); /* 输出错误信息 */}/* 关闭数据库连接等后续操作 */return 0;
}
SQL提供了将SQL语句嵌入到某种高级语言中的方式, 通常采用预编译的方法。
1、 区分主语言与SQL语句的方式:EXEC SQL <SQL语句>
2、 向主语言传递SQL语句执行的状态信息的方式:SQLCA
3、 主变量(共享变量) :
• 主语言通过主变量向SQL语句提供参数, 主变量是由主语言的程序定义的, 并用SQL的DECLARE语句说明。
• 在SQL语句中, 为了与SQL中的属性名区分, 在引用共享变量时, 前面需要加“: ”

游标

这是啥,会不了一点,等等再学。
存储过程
存储过程是指保存的SQL语句集合,可以接受和返回用户提供的参数。
存储过程已在服务器注册。
存储过程具有安全特性(例如权限)和所有权链接,以及可以附加到它们的证书。
存储过程可以强制应用程序的安全性。
存储过程允许模块化程序设计。
存储过程是命名代码,允许延迟绑定。
存储过程可以减少网络通信流量。
回顾
学了一大圈,其实要记得语句并不多,在这里总结个背诵版:
参加软考(全国计算机技术与软件专业技术资格(水平)考试)的数据库相关考试,考生需要熟悉和掌握一系列 SQL 语句以应对试题中涉及的数据库操作与查询任务。以下是一些关键的 SQL 语句类别和具体的语法,这些都是备考时应重点复习和理解的内容:
数据定义语言 (DDL)
数据库和表的操作
-
创建数据库 (
CREATE DATABASE):CREATE DATABASE database_name; -
删除数据库 (
DROP DATABASE):DROP DATABASE database_name; -
创建表 (
CREATE TABLE):CREATE TABLE table_name (column1 datatype [column_constraint],column2 datatype [column_constraint],...[table_constraint] ); -
修改表 (
ALTER TABLE):- 添加列:
ALTER TABLE table_name ADD COLUMN column_name datatype [column_constraint]; - 删除列:
ALTER TABLE table_name DROP COLUMN column_name; - 更改列定义:
ALTER TABLE table_name MODIFY COLUMN column_name new_datatype [column_constraint]; - 重命名列:
ALTER TABLE table_name RENAME COLUMN old_column_name TO new_column_name; - 添加、修改或删除表约束:
ALTER TABLE table_name ADD [CONSTRAINT constraint_name] constraint_type ...; ALTER TABLE table_name DROP CONSTRAINT constraint_name;
- 添加列:
-
删除表 (
DROP TABLE):DROP TABLE table_name;
索引
-
创建索引 (
CREATE INDEX):CREATE [UNIQUE] INDEX index_name ON table_name (column_name [ASC|DESC]); -
删除索引 (
DROP INDEX):DROP INDEX index_name ON table_name;
视图
-
创建视图 (
CREATE VIEW):CREATE VIEW view_name AS SELECT column_list FROM table_name WHERE condition; -
修改视图 (
ALTER VIEW): 视图修改通常限于重定义视图的查询语句。ALTER VIEW view_name AS SELECT column_list FROM table_name WHERE new_condition; -
删除视图 (
DROP VIEW):DROP VIEW view_name;
数据操纵语言 (DML)
数据操作
-
插入数据 (
INSERT):INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...); -
更新数据 (
UPDATE):UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition; -
删除数据 (
DELETE):DELETE FROM table_name WHERE condition;
查询数据
-
基本查询 (
SELECT):SELECT column_list FROM table_name [WHERE condition] [ORDER BY column_name [ASC|DESC]]; -
联接查询 (
JOIN):SELECT column_list FROM table1 JOIN table2ON table1.column = table2.column [WHERE condition]; -- 包含 INNER JOIN, LEFT JOIN, RIGHT JOIN, FULL JOIN -
分组与聚合函数 (
GROUP BY,HAVING,COUNT,SUM,AVG,MIN,MAX):SELECT column1, COUNT(column2), AVG(column3) FROM table_name GROUP BY column1 HAVING condition; -
子查询 (
SELECTwithinSELECT):SELECT column_list FROM table_name WHERE column IN (SELECT subquery_column FROM another_table WHERE condition); -
集合查询 (
UNION,INTERSECT,EXCEPT):SELECT column_list FROM table1 UNION [ALL] SELECT column_list FROM table2;
数据控制语言 (DCL)
权限管理
-
授予权限 (
GRANT):GRANT privilege_list ON object TO user [WITH GRANT OPTION]; -
收回权限 (
REVOKE):REVOKE privilege_list ON object FROM user;
其他重要概念与语句
-
事务处理 (
BEGIN TRANSACTION,COMMIT,ROLLBACK):BEGIN TRANSACTION; -- SQL statements... COMMIT; -- 或 ROLLBACK; -
存储过程 (
CREATE PROCEDURE):CREATE PROCEDURE procedure_name (IN|OUT|INOUT parameter datatype) BEGIN-- SQL statements... END; -
触发器 (
CREATE TRIGGER):CREATE TRIGGER trigger_name [BEFORE|AFTER] event_type ON table_name FOR EACH ROW BEGIN-- SQL statements... END;
存储过程 (Stored Procedure)
存储过程是一种预编译的数据库对象,包含一组可重复使用的SQL语句和控制流语句。存储过程封装了复杂的业务逻辑,提高了代码复用性、执行效率和安全性。在软考中,考生应熟悉以下与存储过程相关的SQL语句:
创建存储过程
CREATE PROCEDURE procedure_name
([IN param1 datatype, OUT param2 datatype, ...]
)
BEGIN-- SQL statements, control flow constructs (IF, CASE, LOOP, etc.)-- and other procedures or functions calls
END;
调用存储过程
CALL procedure_name(param_value1, param_value2, ...);
修改存储过程
ALTER PROCEDURE procedure_name
BEGIN-- Updated SQL statements and logic
END;
删除存储过程
DROP PROCEDURE procedure_name;
嵌入式SQL (Embedded SQL)
嵌入式SQL是将SQL语句直接嵌入到高级程序设计语言(如C、C++、Java等)源代码中的一种编程技术。软考考生需要了解如何在特定编程语言环境中使用嵌入式SQL,包括以下关键概念和语句:
定义与使用主变量
EXEC SQL BEGIN DECLARE SECTION;
int id;
char name[50];
EXEC SQL END DECLARE SECTION;// ...EXEC SQL SELECT id, name INTO :id, :name FROM employees WHERE id = 1;
预编译与动态SQL
- 使用预编译器对嵌入SQL的源代码进行预处理。
- 使用
EXEC SQL INCLUDE或EXEC SQL PREPARE语句处理动态SQL。
游标 (Cursor)
游标是数据库中用于遍历、检索和操作结果集的一种机制。在软考中,考生应掌握以下与游标相关的SQL语句:
声明游标
DECLARE cursor_name CURSOR FOR
SELECT column_list FROM table_name WHERE condition;
打开游标
OPEN cursor_name;
使用游标读取数据
FETCH cursor_name INTO variable_list;
关闭游标
CLOSE cursor_name;
游标操作示例
DECLARE employee_cursor CURSOR FOR
SELECT id, name, salary FROM employees WHERE department = 'IT';OPEN employee_cursor;LOOPFETCH employee_cursor INTO emp_id, emp_name, emp_salary;EXIT WHEN NOT FOUND;-- Process fetched row-- ...
END LOOP;CLOSE employee_cursor;