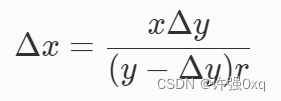🎇个人主页:Ice_Sugar_7
🎇所属专栏:数据库
🎇欢迎点赞收藏加关注哦!
索引&事务
- 🍉索引
- 🍌特点
- 🍌通过 SQL 操作索引
- 🍌底层数据结构
- 🍉事务
- 🍌特性
🍉索引
在数据库中,进行条件查询的时候经常需要遍历表。
我们知道遍历一遍的时间复杂度是O(N),不过由于数据库是把数据存储在硬盘上的,硬盘上的 IO 比内存中的慢很多,即此处的 O(N) 比我们通常说的 O(N) 要慢很多
因此,我们可以给数据库引入索引,提高查询的速度
🍌特点
- 加快查询的速度
- 索引本身是一定的数据结构,也要占据存储空间
- 当我们进行新增、删除、修改的时候,也需要对索引进行更新,这就有额外的开销
由索引的特点,我们不难得出它适用的场景:
- 对于存储空间要求不高的场景(或者存储空间比较充裕)
- 需要进行较多的查询操作,而增加、修改、删除的操作次数相对较少的应用场景
(这种“读多写少”的场景是比较常见的,很多的 web 程序(网站)都是如此)
🍌通过 SQL 操作索引
1. 查看索引
查看某个表是否有索引,以及有几个索引
show index from 表名;
这里有一个结论:MySQL 中的主键、unique 和外键都会自动生成索引
比如我们现在创建一个学生表,它有两列:id 和姓名,其中 id 是主键,姓名用 unique 约束。然后查看它的索引:
create table student(id int primary key,name varchar(20) unique);
查看索引

可以看到 id 和 name 都是这张表的索引
从上面的例子我们也可以看出,一个表可以有多个索引,而每个索引都是根据某个具体的列来展开的,这样,后续按照这个列来查询的时候,就能提高效率
2. 创建索引
除了主键、外键和 unique 作为索引,我们也可以自己创建索引:
create index 索引名 on 表名(列名);
举个例子,假设刚才创建的学生表没有设置主键和 unique,那么查看索引的结果集就为空
然后我们手动创建索引:
create index id_index on student(id);
create index name_index on student(name);
再次查看索引:

注意:创建索引也是一个比较危险的操作。如果表中没有数据或者数据比较少,此时创建索引没问题;但如果表中已经有很多数据,此时创建索引,就会触发大量的硬盘 IO,很可能就把数据库给搞挂了
3. 删除索引
drop index 索引名 on 表名
drop index id_index on student;
drop index name_index on student;
注意:删除索引也是一个危险操作
🍌底层数据结构
数据库的索引使用 B+ 树作为数据结构,其实 B+ 树就是针对数据库这个场景量身定制的
要理解 B+ 树,得先了解 B 树(B-树)
B 树是一个 N叉搜索树,是在二叉搜索树的基础上进行拓展,它一个节点上可能包含 N 个值,这 N 个值划分出(N + 1)个区间
举个例子,现在根节点有三个值,分别为30、40、50
那就会划分出4个区间,分别为:小于30的区间、30到40之间的区间、40到50之间的区间和大于50的区间,然后子节点又会继续划分出多个区间
从 B 树的特性可以看出,同样高度的树,它能表示的元素相比于二叉搜索树来说多了很多,所以使用 B 树来查询的时候,比较的次数比二叉搜索树多
比如上面的例子中,要找46的位置,就得先和30比较,比30大,那就得跟40比,比40大,就要跟50比,比50小,就说明46在40到50这个区间
当然这不意味着 B 树不如二叉搜索树,恰恰相反,因为同一个节点的 key 值都是一次硬盘 IO 就能读出来的。即使总的比较次数多了,但 B 树硬盘 IO 次数少了,而一次硬盘 IO 相当于内存中进行 1w 次比较,所以 B 树完全薄纱二叉搜索树
而 B+树则是在 B 树的基础上,又进行改进
同样是 N 叉搜索树,每个节点包含多个 key,不过 B+树只划分出 N 个区间,少了最右边的区间
还是举个例子
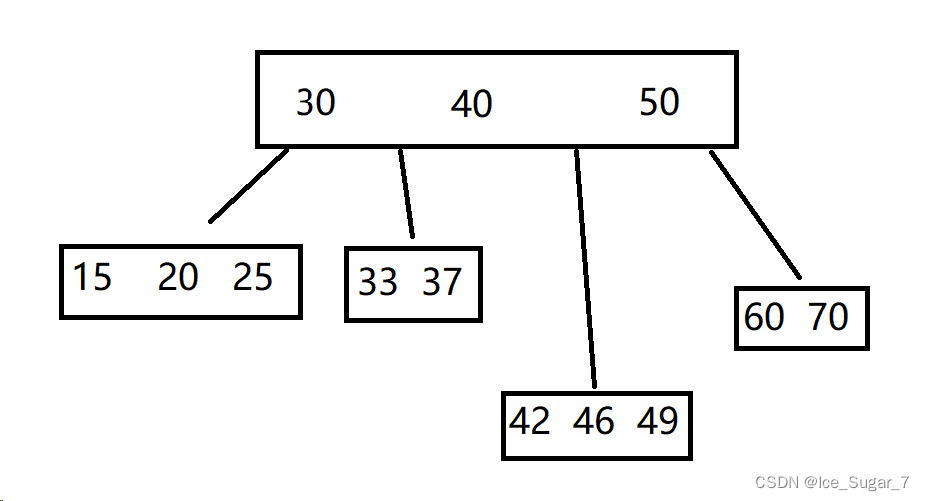
我们可以看到,B+树是没有大于15的区间的,这样就只有两个区间。对于小于8的区间,子节点中包含8;对于8到15的区间,子节点包含15。
也就是说每个节点的 key 会体现在子节点中,直到叶子节点。这样的话叶子节点就包含所有数据(数据全集),这样的好处在于查询过程中经过的硬盘 IO 次数是一样的(B树的硬盘 IO 有时多,有时少),查询时间是稳定的
然后叶子节点之间用链式结构相连(图中红色箭头)
用链式节点的好处在于可以进行范围查询,比如现在要找出4到10这个区间,只需找出4,然后沿着链表往后遍历找到10就 ok 了
反之,如果没有链式结构,那就可能需要反复对树进行回溯,这样就很麻烦(比如找完4之后要回到上一层,然后去找10)
当然,因为现在是在讲数据库,所以关于B+树更详细的讨论,我们放到以后再讲
🍉事务
很多时候对数据库进行的多个操作,我们期望能够“打包”到一起,共同执行
先来看一个经典场景:转账
有一个账户表,记录用户 id、姓名和余额

假如现在张三向李四转账500,那就需要两条SQL语句:
update account set balance = balance - 500 where name = '张三';
update account set balance = balance + 500 where name = '李四';
但是有一个问题,就如果执行完第一个SQL之后,在执行第二个SQL前,数据库挂了,那等到数据库恢复的时候,就会发现张三钱少了,但是李四的钱没有多!
所以需要想个办法,使得即使数据库真挂了,也不会有这样的负面影响
事务就可以做到,它可以保证上述这两个SQL,要么都成功执行,要么都不执行
说是说“不执行”,但实际上还是执行了,只不过在数据库恢复的时候,把数据也还原回去了。这种还原的机制称为回滚机制,事务的原子性本质上就是依托回滚
为什么能回滚呢?因为数据库通过日志(undo log 和 redo log)把之前的数据记录下来了,也就是写到文件里。即使数据库挂了,但是日志已经记录下来了,等到数据库重启之后,读取之前的日志,看看是否有那种执行了一半的事务,如果有,就会把这前面的操作进行回滚,恢复到没有操作之前的状态
🍌特性
谈到事务,我们就需要讲到它4个核心的特性:
- 原子性(最重要的特性)
通过事务,把多个操作打包到一起 - 一致性
相当于是原子性的延伸,就是当数据库中间出问题了,不会出现上述那种“钱凭空消失”这种异常情况;另一方面,通过约束来避免数据出现一些非法的情况 - 持久性
对事务进行的任何修改,都是持久化存在的(因为是写入硬盘的),无论是重启程序,还是重启主机,修改都不会丢失(因为数据库本身就是为了持久化存储) - 隔离性
多个事务并发执行的时候,可能会带来一些问题,通过隔离性对这些问题进行权衡(就是看你是希望数据尽量准确,还是速度尽可能快)
前三个都比较好理解,我们主要来讲隔离性
先理解一个概念——“并发”
并发是计算机领域中一个很大的话题,后面所讲的“多线程”,其实就属于是“并发编程”中的一种典型实现方式
数据库是客户端——服务器结构的程序,一个服务器可能会涉及到多个客户端。那么,如果有多个客户端同时向数据库服务器发起事务请求,这个时候就叫作“并发执行事务”
如果这多个事务修改的是不同的表,那么问题不大;而如果是修改同一张表,就可能产生一些 bug
典型 bug 1:脏读问题
有两个事务1、2,其中事务1修改了某个数据,但此时事务还没有提交,而事务2读取了这个数据(事务2会多次读取这个数据),此时事务2读取到的数据,很可能是一个脏数据,因为事务1后续可能还要再次修改这个数据。
这就导致事务2第一次读取到的数据是A,但是第二次读取到的数据是B,前后不一致
解决脏读问题的核心思路就是降低事务的并发程度
要解决的话就得给写操作加锁,加锁意味着在释放锁之前,这个数据是无法访问的(写的时候不能读)
典型 bug 2:不可重复读
这个有点像脏读,但这是在写操作加锁的前提下导致的问题
还是以上面的脏读为例,此时来了一个事务3,它在事务2读数据的时候,修改了数据,这样也会导致事务2前后读取的数据不一致
要解决这个问题,就需要给读操作加锁,即读的时候不能写
典型 bug 3:幻读
现在有事务1、2,其中事务1修改数据,然后提交,事务2开始读数据。此时来了一个事务3,它新增了一些其他的数据,这就可能导致事务2两次读取的结果集(就是查询的时候,有多少行)不同
要解决幻读问题,就要串行化:不再进行任何并发,让每个事务都是串行执行的(执行完第一个,再执行第二个,再第三个…)
不过其实上述这三种情况,不算真正的 bug,主要还是得看实际的场景,要看你的场景是更关注数据的准确性,还是更关注效率
MySQL在配置中,提供了“隔离级别”的选项,我们可以根据需要,调整隔离级别,用来应对不同的情况
- read uncommitted:读未提交,此时并行程度最高,隔离程度最低,数据是最不靠谱的,可能出现脏读、不可重复读和幻读
- read committed:读已提交,相当于给写操作加锁。并行程度降低了,隔离程度提高了,效率会降低一些,此时可能会出现不可重复读和幻读
- repeatable read(默认的隔离级别):可重复读,相当于给写操作和读操作加锁了。并行程度进一步降低,隔离程度进一步提高。此时仅可能出现幻读
- serializable:串行化,让所有事务都是串行执行。此时并行程度最低,隔离程度最高,效率最低,但是数据是最靠谱的