本文用于个人算法竞赛学习,仅供参考
目录
一.什么是哈希表
二.哈希函数中的取模映射
三.拉链法(数组实现)
四.拉链法模板
五.开放寻址法
六.开放寻址法模板
七.字符串前缀哈希
九.字符串前缀哈希 模板
十.题目
一.什么是哈希表
哈希表(Hash Table)是一种数据结构,用于存储键值对。它通过将键映射到表中的一个位置来实现快速的查找操作。在哈希表中,每个键都会经过一个哈希函数的计算,得到对应的哈希值,然后将键值对存储在哈希值对应的位置上。
哈希表的主要特点包括:
1. 快速的查找操作:通过哈希函数计算出键对应的位置,可以在常数时间内找到对应的值。
2. 空间效率高:可以根据实际情况动态调整哈希表的大小,使得空间利用率高。
3. 冲突处理:由于哈希函数的映射不是一 一对应的,可能会出现不同键映射到同一个位置的情况,这时需要通过解决冲突的方法来存储这些键值对。
在哈希表中,哈希函数起着至关重要的作用,它决定了键和哈希值之间的映射关系。一个好的哈希函数应该尽可能地减少冲突,使得键能够均匀地分布在哈希表中。
常见的哈希表实现方式包括开放寻址法和拉链法。开放寻址法是指当发生冲突时,依次探测下一个空槽位来存储冲突的键值对;拉链法是指在哈希表的每个位置上存储一个链表,将冲突的键值对存储在链表中。
在实际应用中,哈希表被广泛应用于各种场景,如数据库索引、缓存系统、编程语言中的字典等。

二.哈希函数中的取模映射
假定所需数据区间a(0,10^5),值域x(-10^9, 10^9)
有哈希函数 h(x) ∈(0,10^5),其中h(x) = x mod 10^5
当有多个元素同时映射到同一个值时产生哈希冲突,使用 开放寻址法 和 拉链法来解决
对于取模的数值大小按题目设定,一般设定成一个质数,且离2的整次幂尽可能远,这样发生冲突的概率较小。
三.拉链法(数组实现)
用一个数组来实现拉链法,数组下标是映射后的值,数组存储链表头
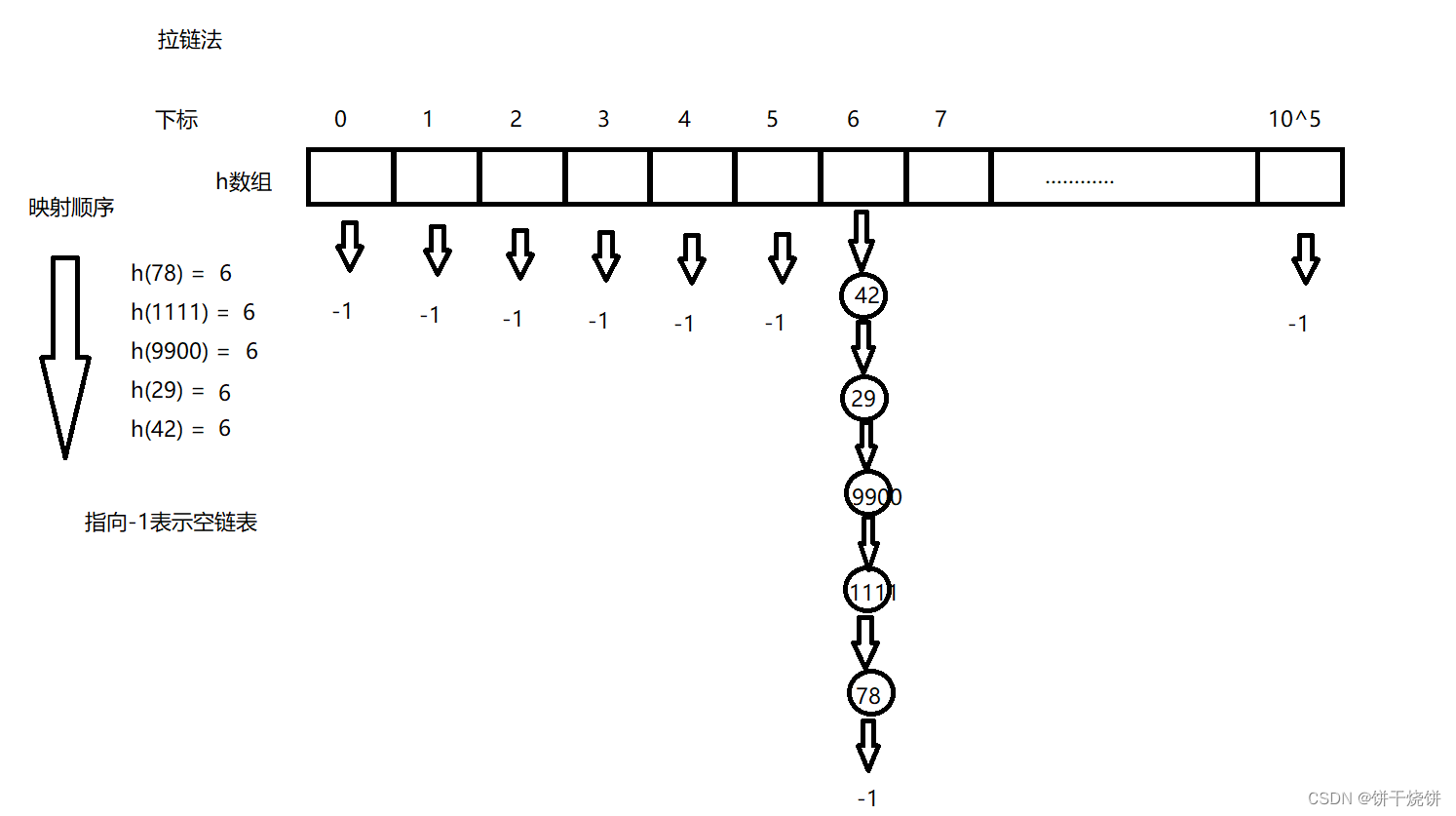
四.拉链法模板
//伪代码
//
//h[]是用来存放链表头的,e[]存放节点数据,ne[]存放节点的next指针
//index相当于节点的地址
const int N = 100010;
int h[N], e[N], ne[N], index, mod;
//bool数组来判断是否存在,true表示存在,false表示已经删除
bool exist[N];void init()
{//将h[]指向-1表示指向空链表memset(h, -1, sizeof(h));
}//求取模mod的值(求第一个大于N的质数)
int getMod(int N)
{for (int i = N; i; i++){bool isMod = true;for (int j = 2; j * j <= i; j++){if (i % j == 0){isMod = false;break;}}if (isMod){return i;}}
}//向哈希表中插入一个数
void insert(int x)
{mod = getMod(N);//因为值域存在负数(c++负数取模是负数),所需数据区间>0,所以加上mod 再取模一个modint k = (x % mod + mod) % mod;exist[index] = true;e[index] = x;ne[index] = h[k];h[k] = index++;
}//查找一个数
bool find(int x)
{mod = getMod(N);int k = (x % mod + mod) % mod;for (int i = h[k]; i != -1; i = ne[i]){if (e[i] == x && exist[i])return true;}return false;
}//删除操作不会直接删除,会再开一个bool数组来判断,true表示存在,false表示已经删除
void del(int x)
{mod = getMod(N);int k = (x % mod + mod) % mod;for (int i = h[k]; i != -1; i = ne[i]){if (e[i] == x)exist[i] = false;}
}五.开放寻址法
在开放寻址法中,当发生哈希冲突时,会尝试在哈希表中的其他位置寻找空闲的位置来存储数据,而不是使用链表等数据结构来处理冲突。可以使用线性探测:当发生冲突时,依次检查下一个位置,直到找到一个空闲位置为止。
在开放寻址法中,为了保证数据能够被正确插入并正确查找,哈希表的大小一般会设置为所需数据个数的2~3倍,这样可以减少冲突的概率,提高查找和插入的效率。
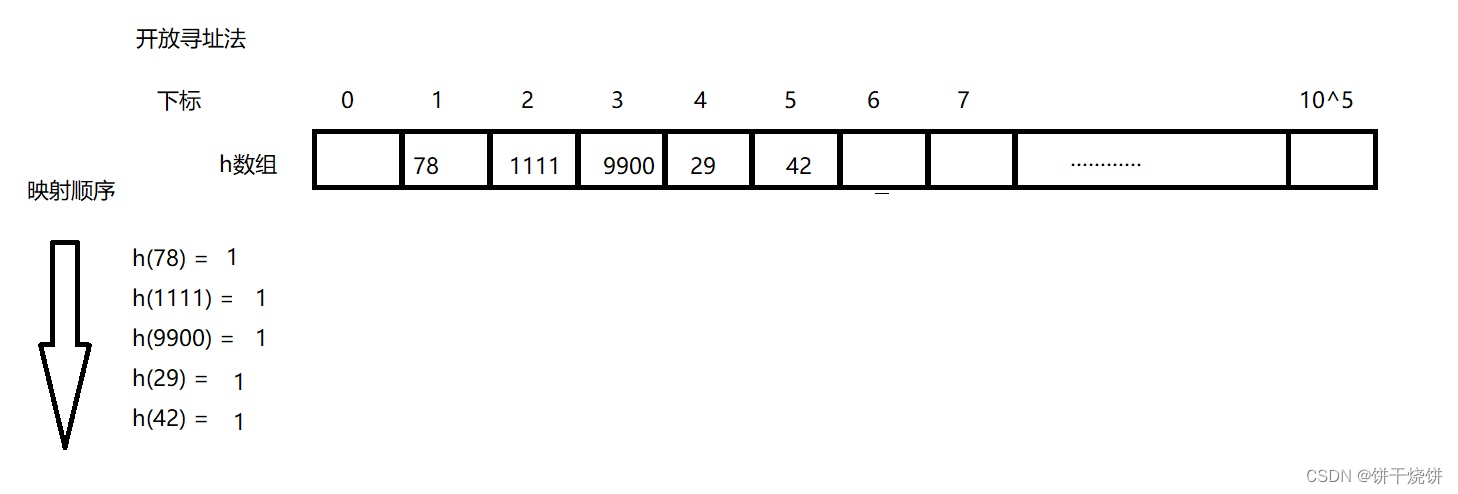
六.开放寻址法模板
//开放寻址法
//数组开辟一般为所需数据个数的2~3倍--可以使冲突概率降低const int N = 300010;
int h[N];
//标记空格
int null = 0x3f3f3f3f;//7717637477//初始化
void init()
{memset(h, 0x3f, sizeof(h));//memset是每个字节赋值
}//如果x在哈希表中,返回x的下标,如果不存在就返回应该插入的位置
int find(int x)
{int t = (x % N + N) % N;while (h[t] != null && h[t] != x){t++;if (t == N)t = 0;//循环回去找}//此时t要么找到了返回对应下标,要么没找到返回应该插入的下标return t;
}//插入一个数
void insert(int a)
{int t = (a % N + N) % N;t = find(t);h[t] = a;
}
七.字符串前缀哈希
字符串前缀哈希是一种用于快速计算字符串前缀哈希值的方法,通常用于字符串匹配算法中。其基本思想是将字符串看作是一个以某个进制表示的数,通过计算前缀的哈希值来快速比较字符串的相等性(快速判断两个字符串是否相等)。
一种常见的计算字符串前缀哈希值的方法是使用多项式哈希,即将字符串中的每个字符看作是一个进制数,并通过多项式运算来计算哈希值。假设字符串 s 的长度为 n ,字符集大小为 P ,则可以使用如下公式计算字符串前缀哈希值:
H[i] = (H[i-1] * P + s[i]) % Q
其中, H[i] 表示字符串 s 的前缀 s[0:i] 的哈希值, P 是一个较大的质数, Q 是一个较大的模数, s[i] 表示字符串 s 的第 i 个字符。
为了避免哈希冲突,对于P一般取值为131或者13331,Q一般取2^64,一般情况下99.99%不会有冲突。
八.通过字符串前缀哈希 求区间哈希值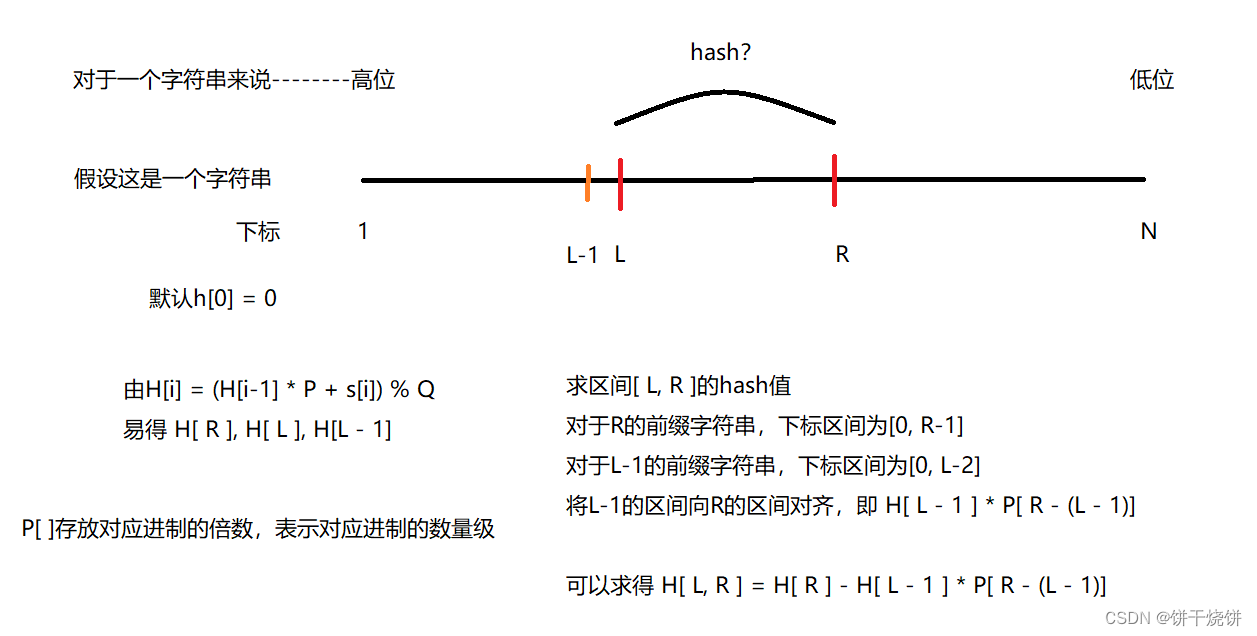
举个例子:
九.字符串前缀哈希 模板
//思想:将字符串看成P进制,P的经验值是131或者13331,Q取2^64, 这样发生冲突的概率较小
//取模Q的数用 2^64 ,这样直接用unsigned long long的存储,因为unsigned long long最大可以存放2^64,超出部分就相当于取模2^64了typedef unsigned long long ULL;
const int N = 100010;
//H[] 存储字符串哈希值,P[] 存储对应对应数量级,p^k % 2^64
ULL H[N], P[N];
int p = 131;
//原字符串
char str[N];
//H[],P[],str[]有效值从下标1开始//初始化
void init()
{H[0] = 0;P[0] = 1;
}//求字符串前缀哈希--str表示字符串
void Hash()
{for (int i = 1; i <= N; i++){H[i] = H[i - 1] * p + str[i];P[i] = P[i - 1] * p;}
}//计算子串str[l~r]的哈希值
ULL get(int l, int r)
{return H[r] - H[l - 1] * P[r - (l - 1)];
}十.题目
P3370 【模板】字符串哈希 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
#include <iostream>
#include <algorithm>
#include <cstring>
#include <vector>
#include <unordered_set>
#include <cstdio>using namespace std;const int N = 10010;
const int M = 1510;
const int P = 131;
typedef unsigned long long ULL;int sizes;//维护一个字符串的长度
vector<ULL> H;int main()
{int n;scanf("%d", &n);while (n--){char str[M];//下标从1开始scanf("%s", str+1);sizes = strlen(str + 1);//求哈希值ULL h = 0;for (int i = 1; i <= sizes; i++){h = h * P + str[i];}H.push_back(h);}unordered_set<ULL> Set(H.begin(), H.end());printf("%llu\n", Set.size());return 0;
}

![[ruby on rails] ruby使用vscode做开发](https://img-blog.csdnimg.cn/direct/40aea98db16944baa4f5ba521698d97d.png)