文章目录
- 前言
- 基础常识
- 代理服务器
- 状态码
- 端口号
- 常见免费ip代理池网站
- 实现思路
- 代码实现
- main.py
- utils.py
- demo.py
- 结果如下
前言
为了防止ip被封后还能爬取网页,最常见的方法就是自己构建一个ip代理池。
本来用的是下面这个开源项目ip代理池,
github开源项目
就是这个开源项目上好多免费的ip网站做了更新,导致它能获取的可用的代理频率不高,且它只是做了获取工作,没有做任何的测试,导致获取的代理匿名性层次不齐。用它获取的ip,用www.example.com来做目标url,一个循环20次,也不能每次都能拿到网页上的数据,于是得自己做一个高质量的ip获取池。
不过它开源的代码上也是有不少可以借鉴的。
基础常识
代理服务器
根据支持的协议分类:
HTTP代理:主要用于普通的网页浏览,可以转发HTTP请求(详见:HTTP请求方法)。
SSL/HTTPS代理:支持HTTPS协议,可以为使用SSL加密的网站提供安全的数据传输。(安全性较高的匿名浏览的好选择)
Socket4/5代理:Socks4和Socks5支持更多的网络协议,不仅限于HTTP和HTTPS,适用于更广泛的网络请求。(支持多种协议代理的好选择)
Socket4:只支持 TCP 协议,不支持 UDP 协议,也不支持域名解析(DNS)。
Socket5:支持 TCP 和 UDP 协议,支持多种身份验证机制,以及服务器端域名解析。(可以完成socket4所有网络请求,首选)
根据匿名程度分类:
透明代理 (Transparent Proxy):服务器知道你是谁,网站也可以知道你的真实IP从而判断在使用代理。
匿名代理 (Anonymous Proxy):网站无法知道你的真实IP,但可以判断你正在使用代理。
混淆代理 (Distorting Proxy):会混淆你的真实IP,同时报告给网站一个虚假的IP地址。
高度匿名代理 (Elite Proxy):对方完全无法得知你的真实IP,网站无法检测到正在使用代理。
根据服务器的位置和范围分类:
全球代理:服务器分布在全球各地,可以提供多个国家和地区的IP地址。
国家特定代理:代理服务器仅位于特定国家或地区,提供该地区的IP地址。
根据IP来源分类:
数据中心IP:这些IP地址来源于数据中心,速度快,稳定性好,但容易被识别为代理。
住宅IP:来源于真实住宅网络,较难被识别为代理,适用于对匿名性要求较高的场景。
移动IP:来源于移动网络运营商,具有高匿名性,但速度和稳定性可能不如数据中心IP。
ISP 代理或静态住宅代理:试图结合数据中心和住宅代理的最佳品质。与住宅代理一样,它们归互联网服务提供商所有,而不是网络托管服务;与数据中心代理一样,它们托管在数据中心的服务器上,不涉及最终用户。
状态码
runoob:状态码解释
端口号
端口号大全
代理端口是什么意思呢?
HTTP代理是目前最为常用的代理,占用的端口一般为80/8080/3128/8081/9080。
HTTPS代理也叫SSL代理,占用端口一般为443。
SOCKS5代理与其他类型的代理都不同,只是起到数据包的传递作用,并不会受应用协议的局限,占用端口一般为1080。
FTP代理(文件传输)占用端口一般为21、2121。
这些端口号允许网络上的计算机识别和管理不同类型的网络流量和服务。正确配置代理端口对于确保网络请求正确路由至目标服务是非常重要的。
常见免费ip代理池网站
警告:请后续爬虫大佬爬取这些能用的代理时温柔以待,可能下次就会有更强大的反爬机制了。
我爬取时也是一天只爬一次,按需取用。(那种一直在爬的代理池应该挺有影响吧)
2022年的一篇博客

现:快代理加入反爬和免费代理库不能用
1、free-proxy-list (无反爬机制) 选择了elite+https (其中google的意思是可以爬外网的意思) 每10min更新一次
2、站大爷(连续爬取三次会给状态码500,三天后会解封但再爬取已爬取不到内容了,不建议爬,用了isp代理才可以爬到)# 选择了 响应时间3s内,存活时间1h以上,高匿 支持https,支持post,排序方式为响应时间从小到大
3、快代理(已使用动态加载安全保护,爬不了(能力不足),弃)(其中的优质私密代理还是挺好的)
4、proxy-list.download(直接调api接口,可爬)选择了https/SSL 每天更新一次
5、66代理(api调用,可爬)选择了超级域名+https 每10分钟更新一次
6、开心代理(可爬)选择了高匿+https 大概是每60min更新一次
7、FateZero (加载不出网页,不可用)
8、小幻代理 (可爬,网站要求控制速度) 选择了高匿+https+post 每天更新一次
9、云代理(可爬(没试过),看起来https的较少以及不能翻页的爬虫警告,弃)
10、89代理(可爬(没试过),但无高匿筛选,弃)
11、免费代理库(加载不出,弃)
12、稻壳代理(加载不出,弃)
其他代理:
用于网络抓取的最佳免费代理列表
可能的其他的爬取IP的方法:(搞个程序打开浏览器截图丢给bing识别保存)
实现思路
1、爬取免费代理ip
2、测试响应时间(按从快到慢排)
3、压力测试(连续爬example网站40次,若能通过,则为高质量ip)
4、post测试(可选)
5、持久化存储
我选取均为可https和可post的代理
测试pos时:使用了有道翻译post
参考:
【60行代码解决】2024年最新版python爬虫有道翻译js逆向
Python爬虫中如何通过post发请求,浏览器控制台抓包教程,有道翻译爬虫程序,通过python伪装翻译(post案例)
压力测试时:使用了线程和互斥锁
可参考:11.网络爬虫—多线程详讲与实战
最佳线程数参考:
计算最佳线程数
python的爬虫请求为CPU密集型,故选择

这里cpu的个数在任务管理器(任务栏上右键打开)上的性能得知:

它有8个核心。这意味着CPU有8个物理核心。物理核心数与逻辑处理器数不同,意味着CPU支持超线程技术,逻辑处理器的数量可能是物理核心数的两倍,此时我的电脑上的逻辑处理器为16,则我可以视作cpus = 16。
代码实现
main.py
from utils import get_free_list, get_proxy_list, get_66_ip, get_kx_ip,get_ihuan_ip,get_zdy_ip,test_connection,test_pressure,test_post
import random
import datetimedef random_proxy():func_inland =[get_free_list, get_proxy_list]func_outland =[get_66_ip, get_kx_ip, get_ihuan_ip, get_zdy_ip]# 从代理池中随机获取一个代理D = int(datetime.datetime.now().strftime('%d'))if D % 2 == 0:ip =get_zdy_ipelse:ip =[]passip_i = random.choice(func_inland)()+ipip_o = random.choice(func_outland)()+ipreturn ip_i+ip_odef save_proxy(ip):#如果没有此文件就创建一个print(ip)with open('./free_proxy_get/proxy.txt', 'w') as f:for i in ip:f.write(i+'\n') #在当前文件夹也保存一份(可选,为了方便)with open('proxy.txt', 'w') as f:for i in ip:f.write(i+'\n')
def open_proxy():with open('./free_proxy_get/proxy.txt', 'r') as f:#一行一行读取ip = [line.strip() for line in f]return ipdef main():ip = open_proxy() #1.打开已经保存的代理,若少于6个则重新获取if len(ip) == 0:ip = random_proxy()ip = test_connection(ip) #2.测试httpsip = test_post(ip) #3.测试post(可选)ip = test_pressure(ip,40) #4.测试压力 max =40save_proxy(ip)#5.保存代理 从快到慢排if __name__ == '__main__':main()
utils.py
在我的github里
欢迎star
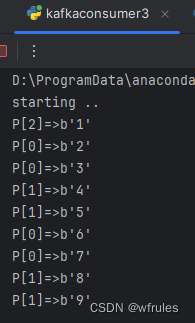
demo.py
运用代理池
def open_proxy():with open('./free_proxy_get/proxy.txt', 'r') as f:#一行一行读取ip = [line.strip() for line in f]return ipif __name__ == '__main__':ip = open_proxy()print(ip)pass
结果如下

保存的文件