以JSON配置的方式去实现通用性和动态调整,当然,这个通用仍然存在一定的局限性,每个项目的代码风格都不同。
想要写出一个适合所有项目的通用性模块并不容易,这里的通用局限于其所在项目,所以该功能代码如果不适用于自己的项目,希望可以以此为参考,稍作修改。
那么现在来分析一下,我们会需要哪些JSON配置项。
导出
基础配置项
先从最简单的导出开始,被导出数据应该支持通过业务层查出,如:Service.search(param),这是大前提,然后为了支持显示导出进度,业务层还需要提供数量查询方法,如:Service.count(param),否则无法实现导出进度。
最后导出文件名也可以定制,如:filename
由上可以得出配置项:
-
serviceClazz: 业务类路径,如:
com.cc.service.UserService,必填 -
methodName: 查询方法名,如:
listByCondition,必填 -
countMethodName: 数量查询方法名,可填,用于支持导出进度
-
filename: 导出文件名
-
searchParams: 查询参数,数组类型,字典元素。用数组是为了支持查询方法需要传多参数的情况
至于查询方法的参数类,不需要填,因为我们可以通过反射去获取到该方法所需要传入的参数类型(注意,以下贴出的是关键代码,仅作参考理解):
Class<?> serviceClass = Class.forName(param.getServiceClazz());// param为请求参数类
Method searchMethod = ReflectUtil.findMethodByName(serviceClass, param.getMethodName());// 方法所需要传入的参数列表
Class<?>[] parameterTypes = searchMethod.getParameterTypes();
/*** 通过反射从指定类中获取方法对象*/
public static Method findMethodByName(Class<?> clazz, String name) {Method[] methods = clazz.getMethods();if (StringUtils.isEmpty(name)) {return null;}for (Method method : methods) {if (method.getName().equals(name)) {return method;}}return null;
}
现在我们来想想,导出都会有哪些场景:
-
列表页的分页查询,可能是当前页数据导出,也可能是所有数据导出,这涉及到分页查询
-
数据总览页的查询,通常是开发者自定义的复杂连表查询,不需要分页
那么本文针对以上两种情况来实现第一版的通用导出功能。
列表页的分页查询
列表页的数据导出分当前页导出和所有数据导出,假设查询流程是这样的:
-
接口层接收参数:
Controller.search(Param param) -
业务层调用查询方法:
Service.search(param) -
持久层访问数据库:
Mapper.search(param)
这种情况很简单,但如果流程是这样的:
-
接口层接收参数:
Controller.search(Param param) -
业务层调用查询方法:
Service.search(new Condition(param)) -
持久层访问数据库:
Mapper.search(condition)
上面代码中,接口请求参数和持久层参数不一致,在业务层经过了包装,那么这种情况也要兼容处理。
但是如果请求参数在业务层经过了包中包中包,那么就算了。
接着是分页参数,我们用pageNum和pageSize来表示页码和数量字段,类似于:
{"pageNum": 1,"pageSize": 10,"name": "老刘" // 此为查询字段,如查询名字为老刘的数据
}
关于当前页导出和所有数据导出,可以用一个bool来表示:onlyCurrentPage,默认false,即导出时会自动分页查询数据,直到所有数据查询完毕,导出所有数据时分页查询很有必要,能提高性能,避免内存溢出,当onlyCurrentPage为true时,则只导出当前页面数据。
得出需要的配置项为:
-
searchParam: 接口分页请求参数,JSON类型,必填
-
conditionClazz: 条件查询类,也可以认为是包装类,如:
com.cc.codition.UserCondition,可填 -
onlyCurrentPage: 仅当前页导出,默认false,可填
数据总览页的查询
数据总览数据没有数量查询方法,即Service.count(xxx),也没有分页查询参数,类似于当前页导出,在也只考虑一层包装类的情况下,没有额外的配置项,上面的已经足够了,要注意的就是代码里面得把分页参数剔除掉。
表头配置
一级表头
模拟一些数据来加深理解,现有一个接口是查询系统用户列表,如:/user/search,返回结果是这样的:
{"code": 0,"msg": "请求成功","data": [{"id": 1,"username": "admin","nickname": "超管","phone": "18818881888","createTime": "2023-06-23 17:16:00"},{"id": 2,"username": "cc","nickname": "管理员","phone": "18818881888","createTime": "2023-06-23 17:16:00"},...]
}
现在贴出EasyExcel的代码:
// 创建excel文件
try (ExcelWriter excelWriter = EasyExcel.write(path).build()) {WriteSheet writeSheet = EasyExcel.writerSheet("sheet索引", "sheet名称").head(getHeader()).build();excelWriter.write(getDataList(), writeSheet);
}
// 模拟表头
private static List<List<String>> getHeader() {List<List<String>> list = new ArrayList<>();list.add(createHead("账号"));list.add(createHead("昵称"));list.add(createHead("联系方式"));list.add(createHead("注册时间"));return list;
}public static List<String> createHead(String... head) {return new ArrayList<>(Arrays.asList(head));
}// 模拟数据
public static List<List<Object>> getDataList() {List<List<Object>> list = new ArrayList<>();list.add(createData("admin", "超管", "18818881888", "2023-06-23 17:16:00"));list.add(createData("cc", "管理员", "18818881888", "2023-06-23 17:16:00"));return list;
}public static List<Object> createData(String... data) {return new ArrayList<>(Arrays.asList(data));
}
然后导出效果是这样的:
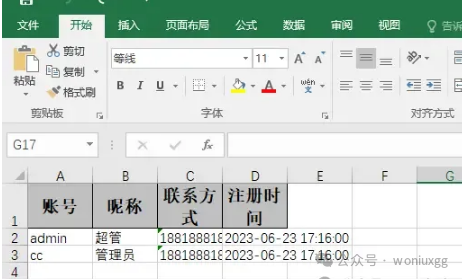
现在先别在乎效果图的excel样式,我们后面都会进行动态配置,比如列宽、表头背景色、字体居中等。
上面我们虽然是写死了代码,但聪明的开发者一定懂得将数据库查询来的数据转换成对应的格式,所以这段就跳过了。
现在我们就可以得出基础的表头配置:
"customHeads": [{"fieldName": "username", "fieldNameZh": "账号"},{"fieldName": "nickname","fieldNameZh": "昵称"},{"fieldName": "phone","fieldNameZh": "联系方式"},{"fieldName": "createTime","fieldNameZh": "注册时间"}
]
也就是:
-
fieldName: 属性名,这样可以从返回结果的数据对象里面通过反射找到该属性以及值
-
fieldNameZh: 属性名肯定不适合作为表头名,增加一个中文说明来代替属性名作为表头
有了上面的基础,我们就可以增加更多的项来实现功能的丰富性,比如
{"fieldName": "username", "fieldNameZh": "账号","width": 20, // 列宽"backgroundColor": 1, // 表头背景色"fontSize": 20, // 字体大小"type": "date(yyyy-MM-dd)" // 字段类型...
}
“注:字段类型可以用作数据格式化,比如该属性是一个status状态,1表示正常,2表示异常,那么导出这个1或2是没有意义的,所以通过字段类型识别出这个状态值对应的中文描述,这样的导出才正常。
一级表头已经可以满足我们许多场景了,但是这并不足够,我的经验中,经常需要用到两行表头甚至是复杂表头,好在EasyExcel是支持多级表头的。
多级表头
先贴出EasyExcel生成二级表头的示例代码:
// 模拟表头
private static List<List<String>> getHeader() {List<List<String>> list = new ArrayList<>();list.add(createHead("用户信息", "账号"));list.add(createHead("用户信息", "昵称"));list.add(createHead("用户信息", "联系方式"));list.add(createHead("用户信息", "注册时间"));list.add(createHead("角色信息", "超管"));list.add(createHead("角色信息", "管理员"));return list;
}public static List<String> createHead(String... head) {return new ArrayList<>(Arrays.asList(head));
}// 模拟数据
public static List<List<Object>> getDataList() {List<List<Object>> list = new ArrayList<>();list.add(createData("admin", "超管", "18818881888", "2023-06-23 17:16:00", "是", "是"));list.add(createData("cc", "管理员", "18818881888", "2023-06-23 17:16:00", "否", "是"));return list;
}public static List<Object> createData(String... data) {return new ArrayList<>(Arrays.asList(data));
}
效果是这样的:
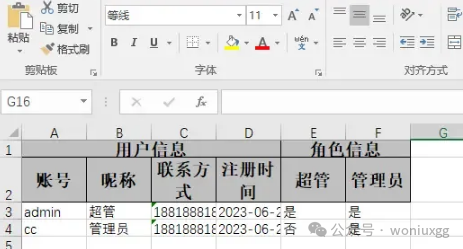
可以看到,前面4列有一个共同表头【用户信息】,后面两列有一个共同表头【角色信息】,从上面的示例代码我们知道,要使表头合并,数据列表得按顺序和相同表头名,这样会被EasyExcel识别到然后才有合并效果,这点需要注意。
同理,当我们需要生成复杂表头的时候,可以这样:
// 模拟表头
private static List<List<String>> getHeader() {List<List<String>> list = new ArrayList<>();list.add(createHead("导出用户数据", "用户信息", "账号"));list.add(createHead("导出用户数据", "用户信息", "昵称"));list.add(createHead("导出用户数据", "用户信息", "联系方式"));list.add(createHead("导出用户数据", "用户信息", "注册时间"));list.add(createHead("导出用户数据", "角色信息", "超管"));list.add(createHead("导出用户数据", "角色信息", "管理员"));return list;
}
效果图:
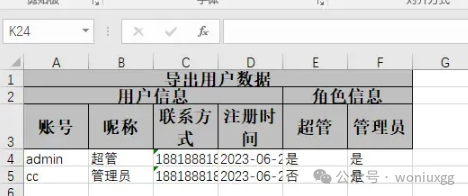
结论
以上是我对导出功能的思考和实现思路,因为篇幅的关系,我没有贴出完整的代码,但是相信以上内容已经足够大家作为参考,缺少的内容,比如列宽、颜色字体等设置,请查阅EasyExcel官方文档来实现,主要方式就是根据前端传过来的JSON配置信息,来动态配置EasyExcel的导出文件。
导入
导入分两个步骤:
-
用户下载导入模板
-
用户填内容进导入模板,然后上传模板文件到系统,实现数据导入操作
下载导入模板
导入模板只需要上面的customHeads参数即可:
"customHeads": [{"fieldName": "username", "fieldNameZh": "账号"},{"fieldName": "nickname","fieldNameZh": "昵称"},{"fieldName": "phone","fieldNameZh": "联系方式"},{"fieldName": "createTime","fieldNameZh": "注册时间"}]
甚至fieldName都可以不要,生成一个只有表头的excel文件。
导入数据
导入数据有两种场景:
-
单表数据导入,该场景很简单
-
复杂数据导入,涉及多表,这种情况就稍微复杂点
单表数据导入
单表只需要考虑对应实体类的属性即可,我们可以通过反射来获取实体类的属性,所以需要的配置项是:
-
modelClazz: 实体类路径,如:
com.cc.entity.User
配置示例:
{"modelClazz": "com.cc.entity.User","customHeads": [{"fieldName": "username", "fieldNameZh": "账号"},{"fieldName": "nickname","fieldNameZh": "昵称"},{"fieldName": "phone","fieldNameZh": "联系方式"},{"fieldName": "createTime","fieldNameZh": "注册时间"}]
}
这样在导入数据,被EasyExcel读取每一行数据的时候,可以识别到如:username项对应com.cc.entity.User类的username属性那么就能做到类似这样的事情:
User user = new User();
user.setUsername(fieldName列的值)
由此可以得到一个List<User> userList数组,再通过系统的UserService或UserMapper保存到数据库,即可实现数据导入操作。
复杂数据导入
复杂数据比如这种场景:excel文件中每行的数据是这样的:

其中是否超管和是否管理员涉及关联表:
-
用户表:
tb_user -
角色表:
tb_role -
用户角色关联表:
tb_user_role_relation
为了支持这种复杂数据导入,系统内需要提供对应的保存方法:
1.新建DTO类:
第一种:
public class UserDto {private String username;private String nickname;private String phone;private Date createTime;private Boolean superAdminFlag;private Boolean adminFlag;
}
第二种:
public class UserDto {private User user;private Role role;
}
这两种DTO的情况我们都应该考虑,第一种不用多说,上面的配置就可以应对,主要看第二种,第二种方式要考虑“路径”这个问题,所以customHeads的写法就要有所改变:
{"modelClazz": "com.cc.model.UserDto","customHeads": [{"fieldName": "user.username", "fieldNameZh": "账号"},...]
}
这样配置账号路径为:user.username,属性的反射查询就要有递归概念,先去查找UserDto类的user属性,得到该属性的类,再去获取其内的username属性,赋值方式就变成了:
UserDto dto = new UserDto();
User user = new User();
user.setUsername(fieldName列的值);
dto.setUser(user);
这样得到一个List<UserDto> dtoList数组。
2.既然有复杂数据导入的业务,那么在Service业务层中,也应该编写复杂数据的保存函数:
public interface UserService {// 单条插入void saveUserDto(UserDto dto);// 批量插入void saveUserDtoBatch(List<UserDto> dtoList);
}
@Service
public class UserServiceImpl implements UserService {@Autowiredprivate UserMapper userMapper;@Autowiredprivate RoleService roleService;@Autowiredprivate UserRoleRelationService relationService;// 事务@Transactional(rollbackFor = Exception.class)@Overridepublic void saveUserDto(UserDto dto) {// 保存用户User user = userMapper.save(dto.getUser());// 保存角色Role role = roleService.save(dto.getRole);// 保存关联UserRoleRelation relation = new UserRoleRelation();relation.setUserId(user.getId());relation.setRoleId(role.getId());relationService.save(relation);}// 批量插入代码省略,原理同上void saveUserDtoBatch(List<UserDto> dtoList);
}
3.通过EasyExcel读取到的每一行数据都能转成UserDto对象,再通过单条或批量来保存数据,这期间有许多可以优化考虑的点,比如:
-
批量比单条保存效率高、性能好,但是批量不容易识别出部分失败的行
-
批量保存的数量不能太多,要考虑系统和数据库的性能,比如每次读取500行就执行一次保存
-
保存的进度显示,先获取excel总行数,再根据当前读取行数来计算进度,并返回给前端
-
导入时间过长,可以做成后台任务进行,至于前端提醒可以是轮询也可以是WebSocket
所以需要指定查询方法,这配置项上面已经给出来了。
配置项总结
最后给出一个总配置项出来参考:
导出数据配置
{"filename": "用户数据导出","serviceClazz": "com.cc.service.UserService","methodName": "listByCondition","countMethodName": "countByCondition","searchParams": [{"nickname": "cc" // 搜索昵称为cc的用户}],"customHeads": [{"fieldName": "username","fieldNameZh": "账号","width": 20, // 列宽"fontSize": 20 // 字体大小},{"fieldName": "createTime","fieldNameZh": "注册时间","type": "date(yyyy-MM-dd)" // 属性类型声明为date,并且转换成指定格式导出}]
}
导入模板配置
{"filename": "用户数据导入","modelClazz": "com.cc.entity.User","customHeads": [{"fieldName": "username","fieldNameZh": "账号","width": 20, // 列宽"fontSize": 20 // 字体大小},{"fieldName": "createTime","fieldNameZh": "注册时间","type": "date(yyyy-MM-dd)" // 属性类型声明为date,并且转换成指定格式导出}]
}
导入数据配置
{"modelClazz": "com.cc.entity.User","serviceClazz": "com.cc.service.UserService","methodName": "save","customHeads": [{"fieldName": "username","fieldNameZh": "账号",},{"fieldName": "createTime","fieldNameZh": "注册时间","type": "date(yyyy-MM-dd)" // 属性类型声明为date,并且转换成指定格式导出}]
}最后说一句(求关注!别白嫖!)
如果这篇文章对您有所帮助,或者有所启发的话,求一键三连:点赞、转发、在看。
关注公众号:woniuxgg,在公众号中回复:笔记 就可以获得蜗牛为你精心准备的java实战语雀笔记,回复面试、开发手册、有超赞的粉丝福利!