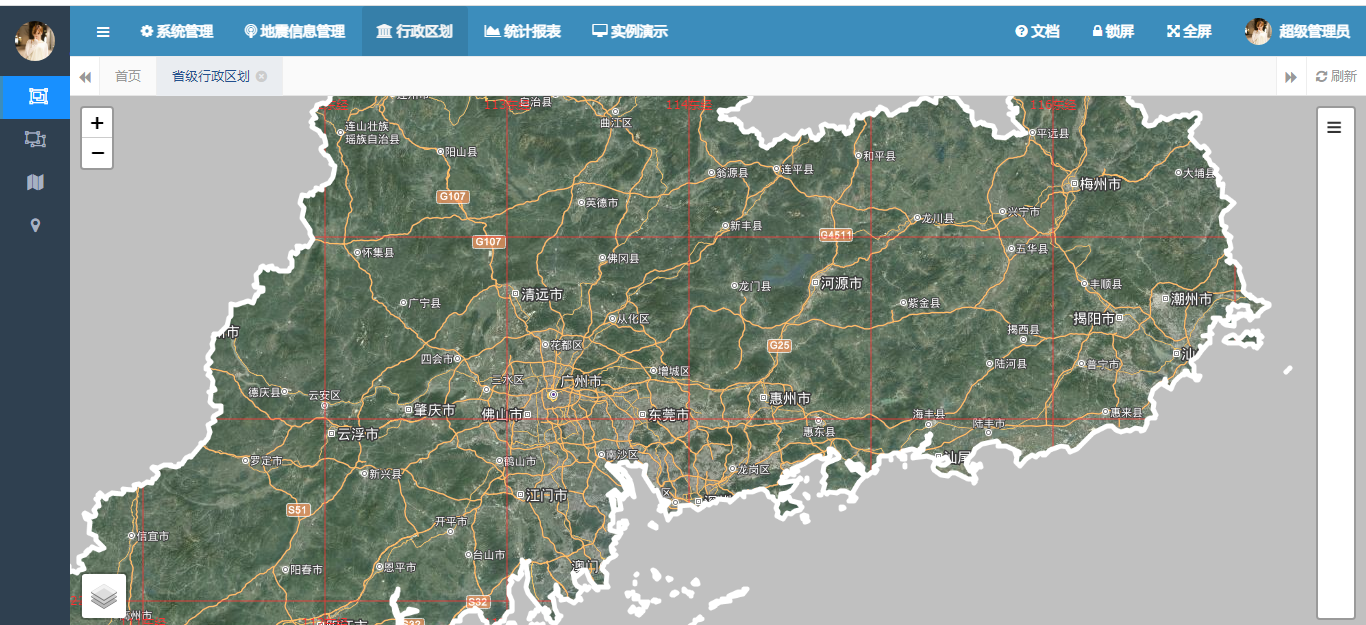
线性回归
- 1.简单线性回归
- 2.多元线性回归
- 3.相关概念熟悉
- 4.损失函数推导
- 5.MSE损失函数
1.简单线性回归
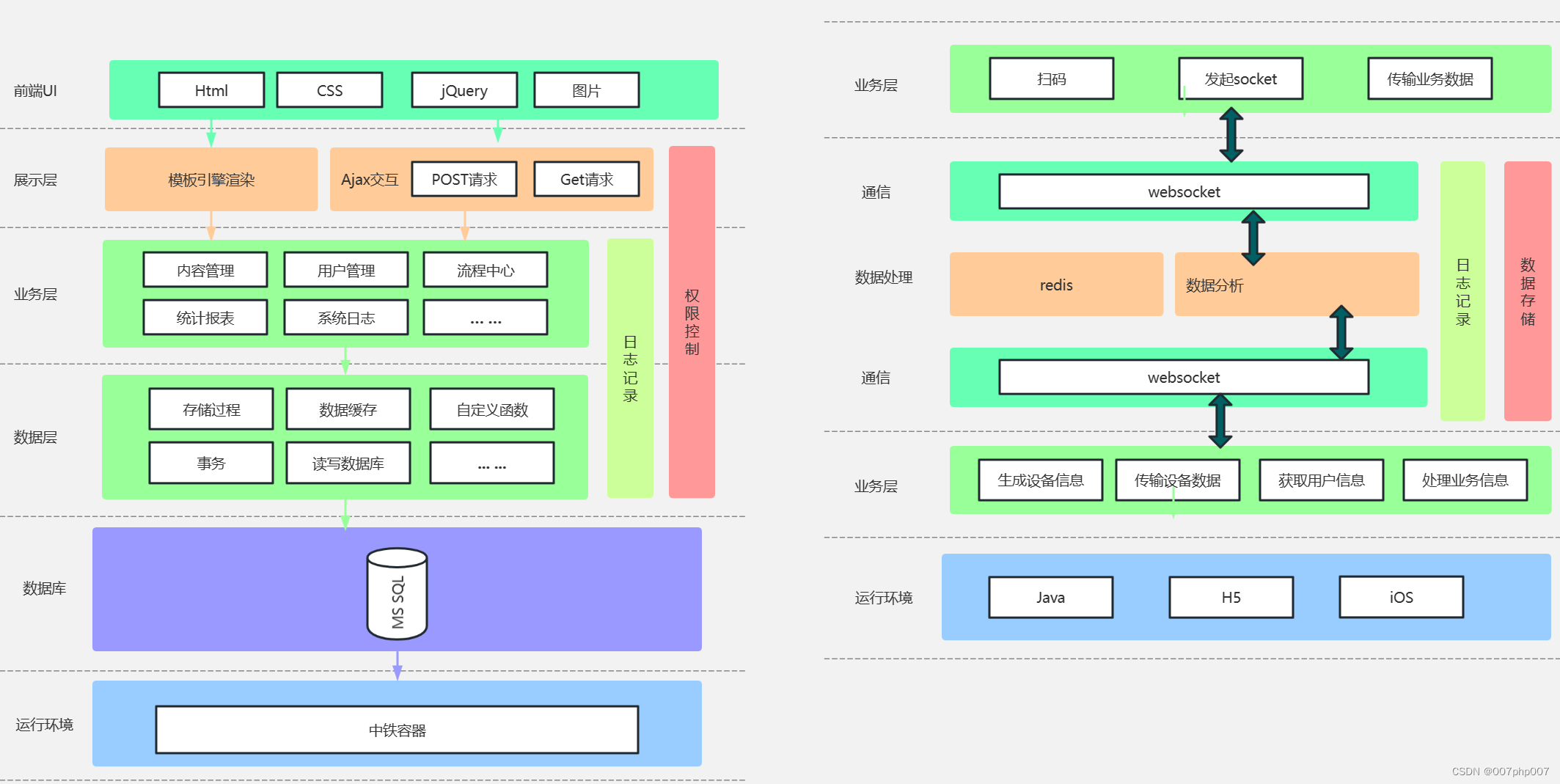
线性回归:有监督机器学习下一种算法思想。用于预测一个或多个连续型目标变量y与数值型自变量x之间的关系,自变量x可以是连续、离散,但是目标变量y必须连续。类似于初中的一元一次方程y = a + bx。不同的是以前可以根据两组值唯一确定a和b的关系,但是机器学习下这种算法是根据多种数据信息,计算出最优解。
方程:

最优解:所有的样本数据都尽可能的贴合(拟合)到该方程(模型model)上方为最优解。说人话是: 我们根据样本数据,计算出很多的a、b值即为多种模型model,从多种模型中预测值Predicted value)和真实值Actual value)进行比较,误差Error越小的模型即为最优解。我们需要让机器知道什么是最优解的话,需要定义个损失函数Loss函数
| 字段 | 描述 |
|---|---|
| Actual value | 真实值,即已知的y |
| Predicted value | 预测值,是把已知的×带入到公式里面和猜出来的参数a,b计算得到的 |
| Error | 误差,预测值和真实值的差距 |
| 最优解 | 尽可能的找到一个模型使得整体的误差最小,整体的误差通常叫做损失Loss |
| Loss函数 | 整体的误差,loss通过损失函数loss function计算得到 |
Loss 函数
平方均值损失
2.多元线性回归
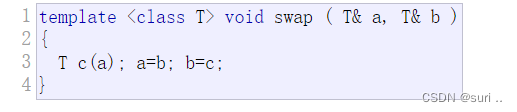
上面的简单线性回归影响其因素只有一个自变量X,但是在现实生活中影响y的可能有多个因素,所以多元线性回归也就用来解决这些问题。方程为:

上面写的过于复杂,学过数学矩阵的同学应该清楚:根据下面的图形示意图可以使用矩阵简写处理:

矩阵简写方程:

用矩阵表示符合我们机器学习相关编程语言的书写方式,便于使用编程语言实现。
3.相关概念熟悉
特征与维度
特征通常指的是影响结果或目标的一系列变量或因素,这些变量或因素构成了模型的 维度。在给定的例子中,x是由n列组成的,这些列可以看作是特征,它们共同构成了x的维度。这些特征会影响最后的结果y。
中心极限定理与正态分布
中心极限定理告诉我们,大量随机变量的总和会趋近于 正态分布。
- 中心极限定理和线性回归的关系:当使用线性回归对大量数据进行处理时,得到的结果可能会符合正态分布。
中心极限定理为线性回归提供了一个理论基础,而这种正态分布的性质,如平均值和标准差,可以被用来评估模型的性能和解释性。
误差
第i个样本实际的值yi等于预测的值yihat加误差Ei,或者公式可以表达为如下

假定所有的样本的误差都是独立的随机变量,足够多的随机变量叠加之后形成的分布,根据中心极限定理,它服从的就是正态分布。
机器学习中我们假设误差符合均值为0,方差为定值的正态分布
最大似然估计
给定一个概率分布D,已知其概率密度函数(连续分布)或概率质量函数(离散分布)为fD以及一个分布参数0我们可以从这个分布中抽出一个具有n个值的采样 ,利用f_D计算出其似然函数:

若D是离散分布,f0即是在参数为0时观测到这一采样的概率。若其是连续分布,f0则为x1,x2…xn联合分布的概率密度函数在观测值处的取值。
| 术语 | 对应的函数术语 | 描述 |
|---|---|---|
| 连续分布 | 概率密度函数 | 连续型随机变量的概率密度函数是一个描述这个随机变量的输出值 |
| 离散分布 | 概率质量函数 | 离散型随机变量的概率质量函数是一个描述这个随机变量的输出值 |
原理:假设样本数据是由某个概率分布生成的(连续分布、离散分布),而这个分布的参数是未知的。最大似然估计的目标是找到那些能使观察值出现的概率最大的参数值。
为啥要了解最大似然估计:上边我们不是假定了误差是符合正态分布的,正态分布又是是连续分布的。如果要求出其中的误差正态分布的相关参数值(均值=0,方差=参数值),则可以通过最大似然估计计算求出。
4.损失函数推导
正态分布的概率密度函数

误差的概率密度函数
误差是一个均值为0,方差为定值的正态分布,所以将误差带入得出:一条样本的概率密度方程如下:

误差属于正态分布,而正态分布的相关参数可以通过最大似然估计算出。
正态分布最大总似然数
上述公式我们只是推导出了一条误差的概率密度函数。接下来我们就是要把最大似然函数通过正太分布概率密度函数表达出来

样本误差服从正态分布也服务互相独立的假设,所以我们可以把上面式子写出连乘的形式概率的公式:

正态分布最大似然函数

等于

引入误差公式

最终推导出来的误差(正态分布)最大似然函数

5.MSE损失函数
因为数学的推导过程比较枯燥且晦涩难懂,所以我们先基于目的梳理一遍过程:获取线性回归的最优解即最优特征值。
- 线性回归最优解对应最小损失函数
- 最小损失函数基于中心极限定理服从正态分布
- 正态分布获取其取值的最大概率则基于最大似然函数
- 得到误差最大似然函数 最终可以求解其特征值
接下来继续推导MSE损失函数。总似然最大的那一时刻对应的参数 θ当成是要求的最优解!
最大总似然
获取最大总似然函数(连乘):

引入对数函数
因为log对数函数中,当底大于1的时候是单调递增,获取θ的最大值可以转换为获取loge的最大值(因为使用对数函数后便于简化公式,结果还是一样的) 公式如下:

基于对数函数的相关运算法则进行继续推导


MSE函数
因为前面有个负号,所以最大总似然变成了最小话负号后面的部分。 到这里,我们就已经推导出来了 MSE 损失函数,从公式我们也可以看出来 MSE 名字的来 历,mean squared error也叫做最小二乘。

那么接下来问题就是 什么时候可以使得损失函数最小了。篇幅有限-下一篇对该问题进行求解。