HTTP——Cookie
- 什么是Cookie
- 通过Cookie访问网站
我们之前了解了HTTP协议,如果还有小伙伴还不清楚HTTP协议,可以点击这里:
https://blog.csdn.net/qq_67693066/article/details/136895597
我们今天来稍微了解一下HTTP里面一个很小的部分:Cookie:
什么是Cookie
Cookie是一种小型的文本文件,由网站服务器发送到用户的浏览器,并存储在用户的计算机上。它包含着网站的相关信息,如用户的偏好设置、登录状态等。
Cookie的组成包括一个名称(Name)、一个值(Value)和其它几个用于控制Cookie有效期、安全性、使用范围的可选属性。Cookie的尺寸通常不超过4KB。
Cookie的工作原理是,当用户访问一个网站时,网站服务器会在HTTP响应头中添加一个Set-Cookie标头,其中包含了Cookie的信息。浏览器接收到响应后,会将这些Cookie保存在本地。之后,当用户再次访问该网站时,浏览器会在HTTP请求头中添加一个Cookie标头,将之前存储的Cookie信息发送给服务器。服务器通过解析这些Cookie信息,可以获取用户的状态、偏好等信息。
Cookie的发明可以追溯到1994年,由网景公司的程序员Lou Montulli发明。他为了解决HTTP协议无状态的限制而创建了Cookie,以便在用户和网站之间共享信息。
Cookie的主要作用包括跟踪用户行为、保存用户状态、记录用户偏好、实现购物车功能等。它广泛应用于登录状态管理、个性化内容推荐、购物体验改善、广告投放以及网站流量分析等领域。
比如我现在在写博客,如果我们是第一次打开这个网页,我们可以打开浏览器的检查功能,找到“网络”,然后点进去一个GET请求:
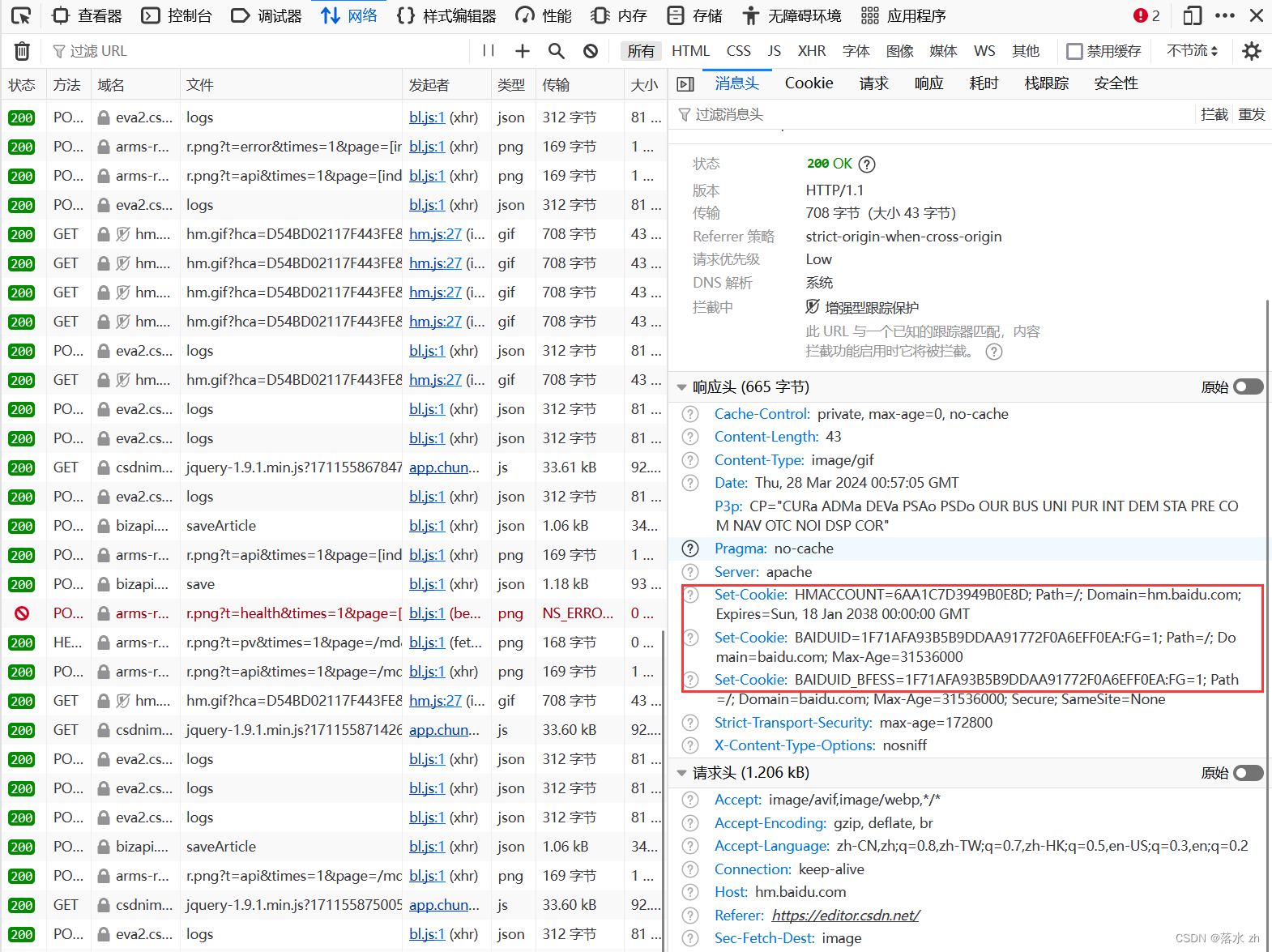
关闭再次打开,这个时候我们可以再次点击检查,再次查看请求头:
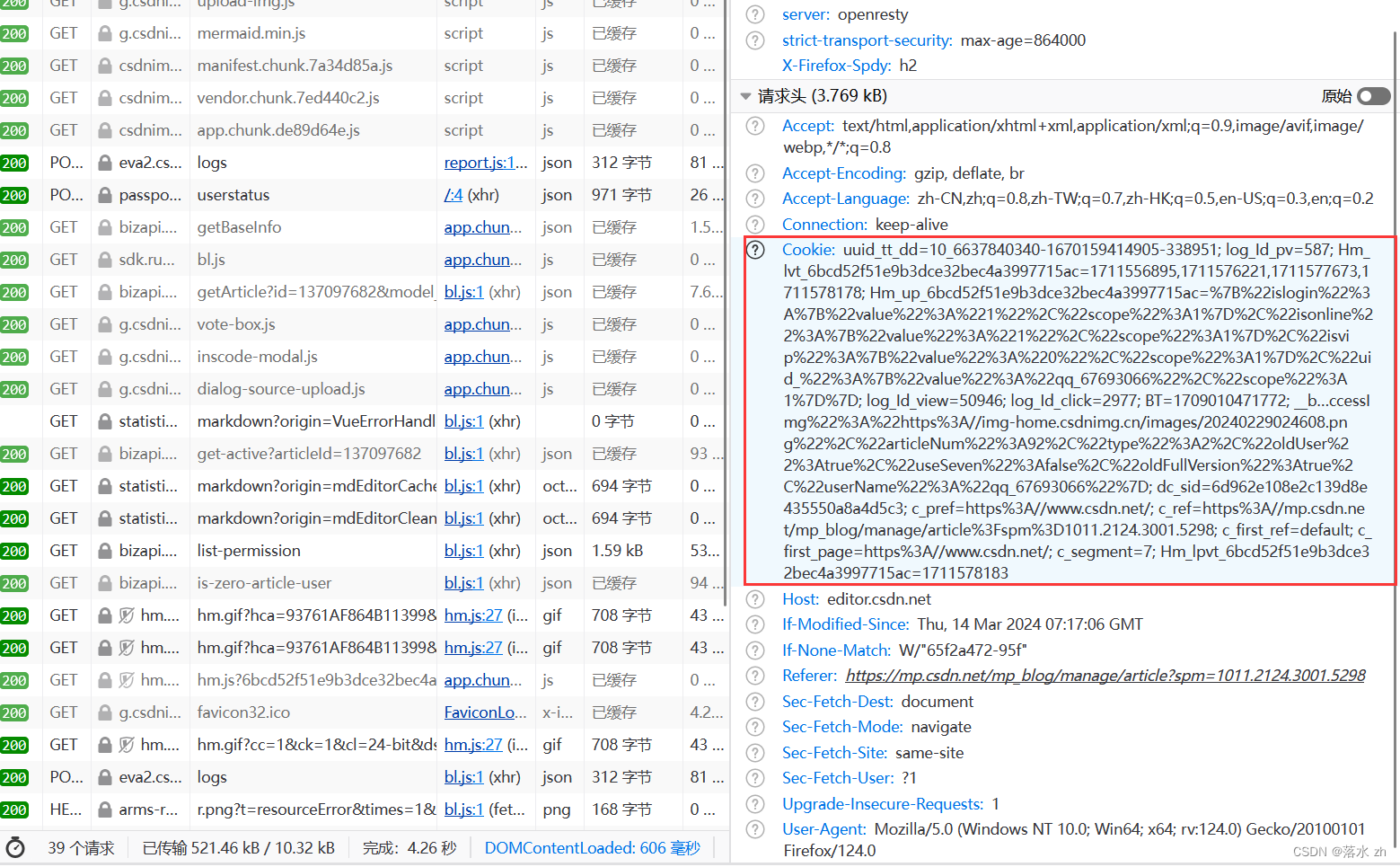
这个时候我们的浏览器就有了Cookie,这个Cookie帮我们存储了一些信息:
在这个Cookie字符串中,有几个重要的字段。以下是这些字段的详细解释:
uuid_tt_dd:这个字段表示用户的唯一标识符。它通常用于跟踪用户的活动和会话。在这个例子中,uuid_tt_dd的值是10_6637840340-1670159414905-338951。log_Id_pv:这个字段表示页面浏览次数。它用于记录用户在网站上浏览的页面数量。在这个例子中,log_Id_pv的值是587。Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac:这个字段是一个用于跟踪用户访问网站的时间戳。它通常用于分析用户在网站上的停留时间和访问模式。在这个例子中,Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac的值是1711556895,1711576221,1711577673,1711578178。Hm_up_6bcd52f51e9b3dce32bec4a3997715ac:这个字段包含了用户的一些属性,如是否登录、是否在线、是否是VIP等。这些属性通常用于个性化推荐和用户分析。在这个例子中,Hm_up_6bcd52f51e9b3dce32bec4a3997715ac的值是%7B%22islogin%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isonline%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isvip%22%3A%7B%22value%22%3A%220%22%2C%22scope%22%3A1%7D%2C%22uid_%22%3A%7B%22value%22%3A%22qq_67693066%22%2C%22scope%22%3A1%7D%7D。dc_sid:这个字段表示用户的会话ID。它通常用于跟踪用户的会话状态和身份验证。在这个例子中,dc_sid的值是6d962e108e2c139d8e435550a8a4d5c3。
这些字段只是Cookie字符串中的一部分,实际上还有其他字段。这些字段通常用于跟踪用户的行为、分析用户的兴趣和偏好,以及提供个性化的服务。
通过Cookie访问网站
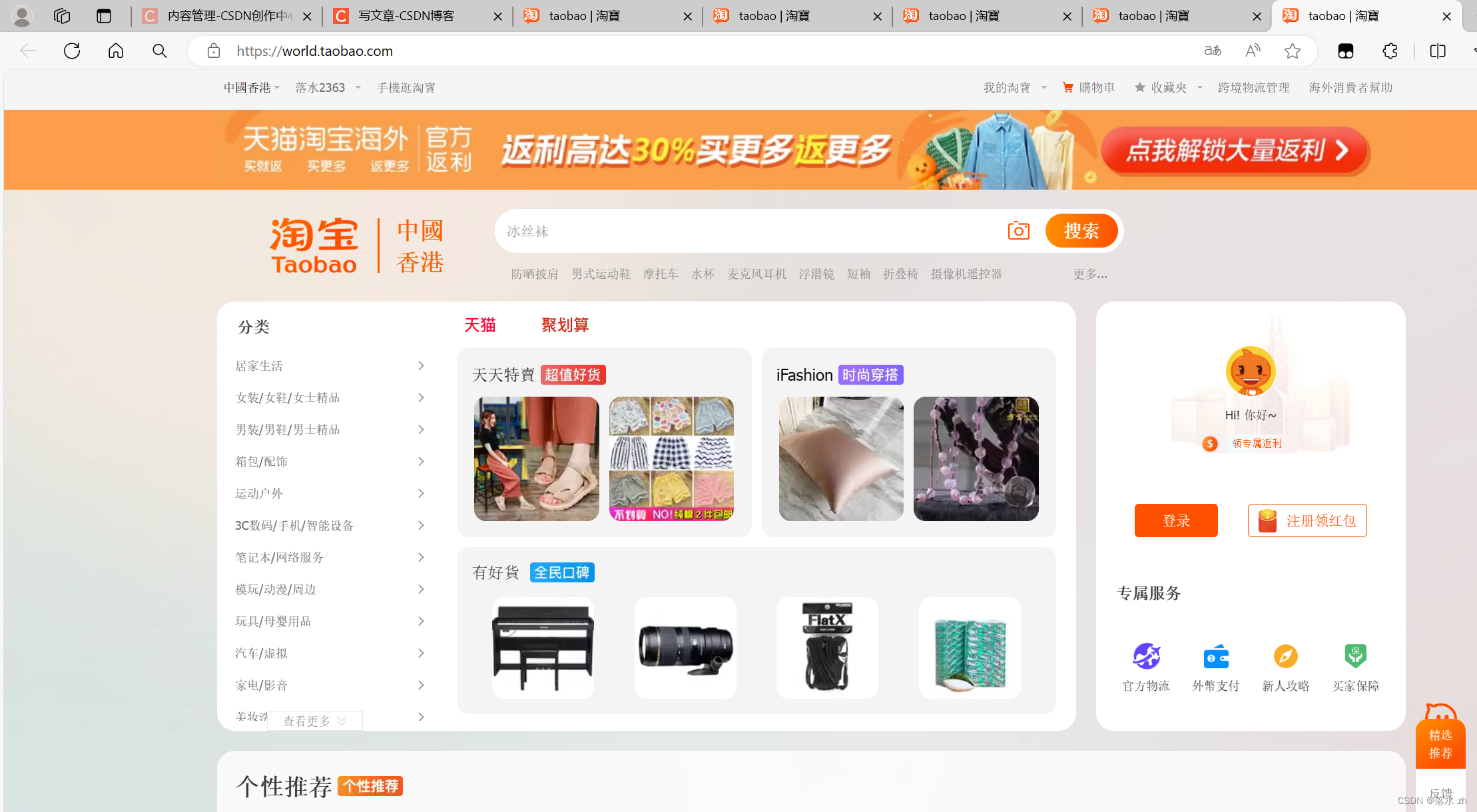
我们这里通过Cookie来访问香港的淘宝,进入淘宝(香港版):
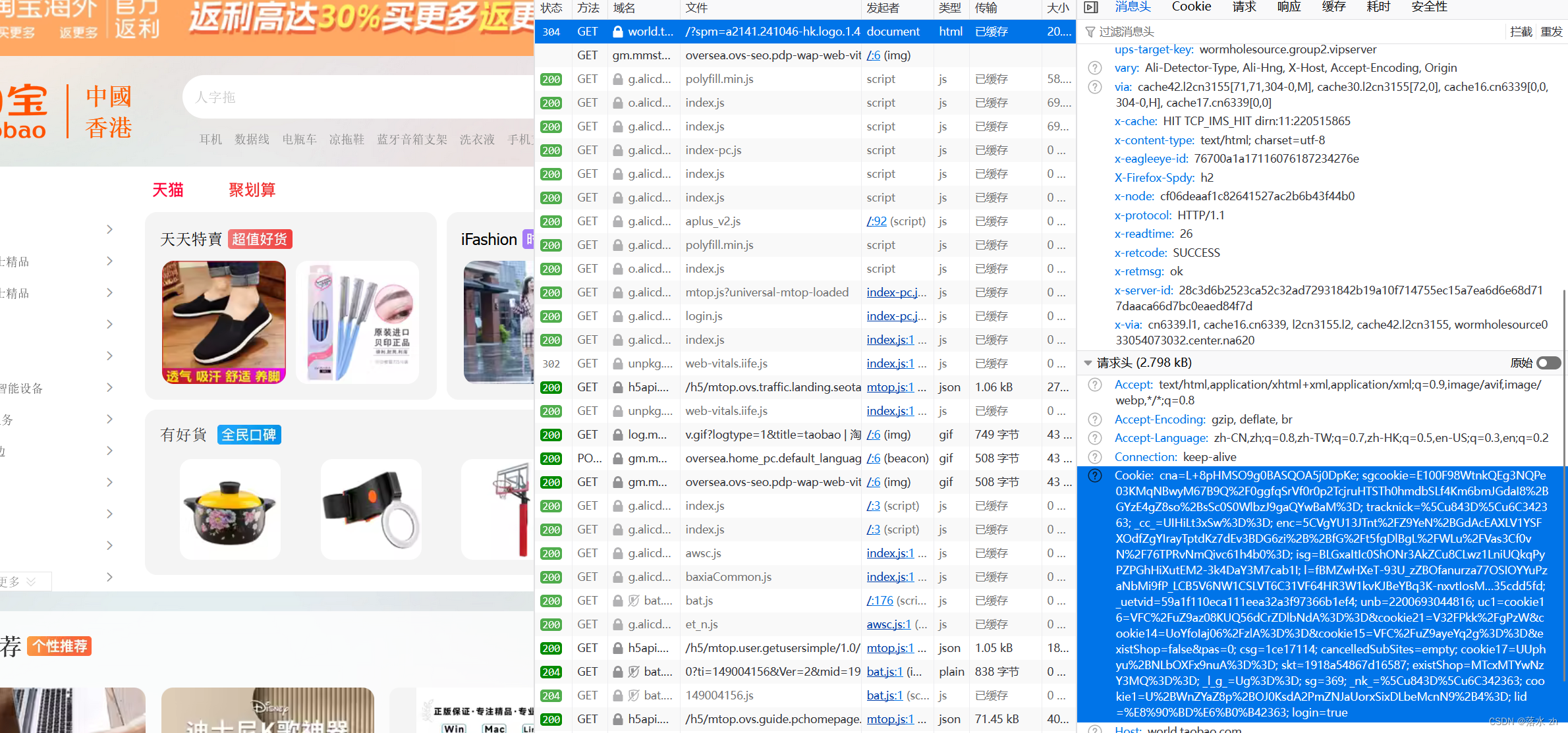
将Cookie的文本内容存放在txt文件中,这里我保存在桌面上:
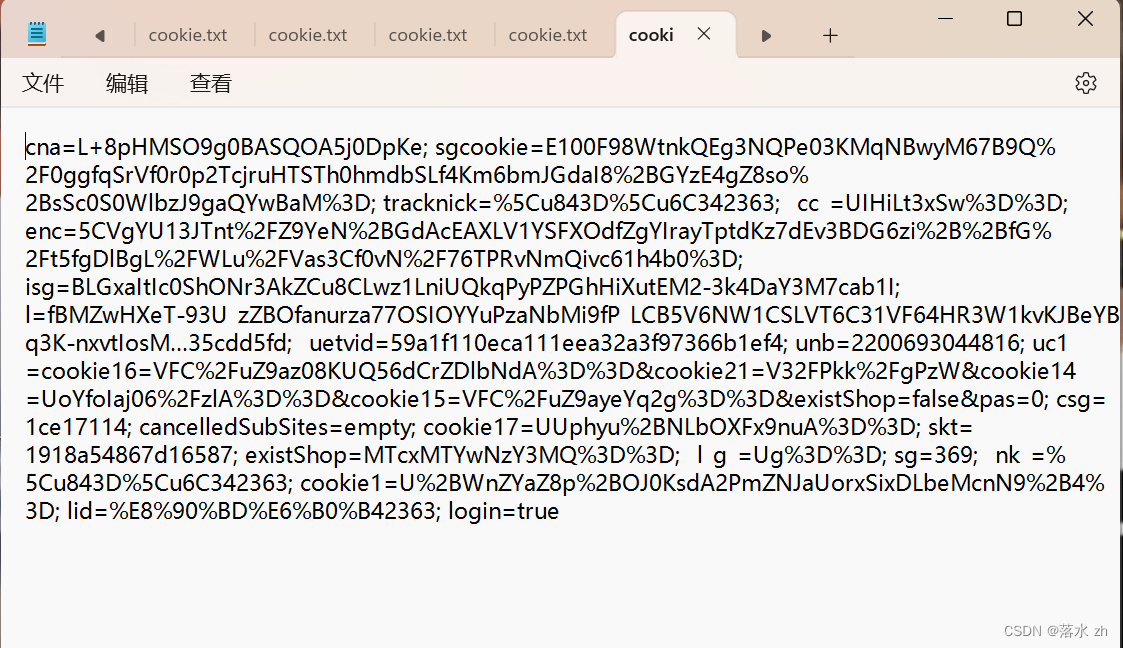
然后在pycharm中编写以下代码:
import requests
from urllib.parse import unquote
import urllib.parse# 打开txt文件并读取内容
url = 'https://world.taobao.com/?spm=a2141.241046-hk.logo.1.41ca5adbDMl5rh' # 香港淘宝地址
with open('C:\\Users\\luoshui\\Desktop\\cookie.txt','r',encoding='utf-8') as file:cookie_str = file.read().strip() # 读取内容并去除两端的空白字符decoded_cookie_str = unquote(cookie_str)# 使用分号将字符串分割成单独的Cookie
decoded_cookie_str = decoded_cookie_str.split(';')# 创建一个字典来存储Cookie键值对
cookies_dict = {}# 遍历分割后的Cookie列表,并添加到字典中
for cookie in decoded_cookie_str:# 去除每个Cookie两端的空格,并使用等号分割键和值key, value = cookie.strip().split('=', 1)# 在循环内解码值value = urllib.parse.quote(value.encode('utf-8'))# 将Cookie添加到字典中cookies_dict[key] = value# 打印分割后的Cookie字典
print(cookies_dict)# 发起请求
response = requests.get(url, cookies= cookies_dict)# 检查请求是否成功
if response.status_code == 200:# 请求成功,可以处理响应内容print("请求成功!")print(response.text) # 打印网页的HTML内容
else:# 请求失败,打印错误信息print(f"请求失败,状态码:{response.status_code}")
运行:
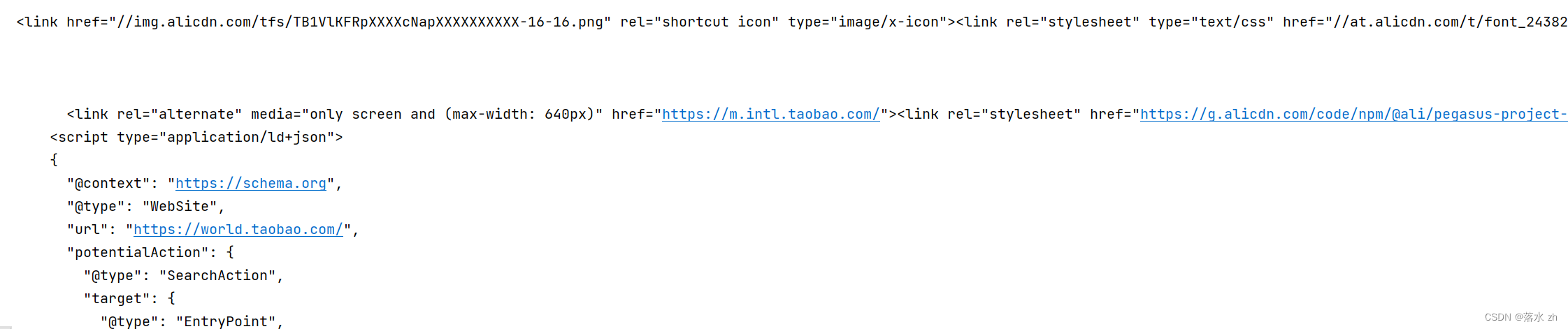
点击url:
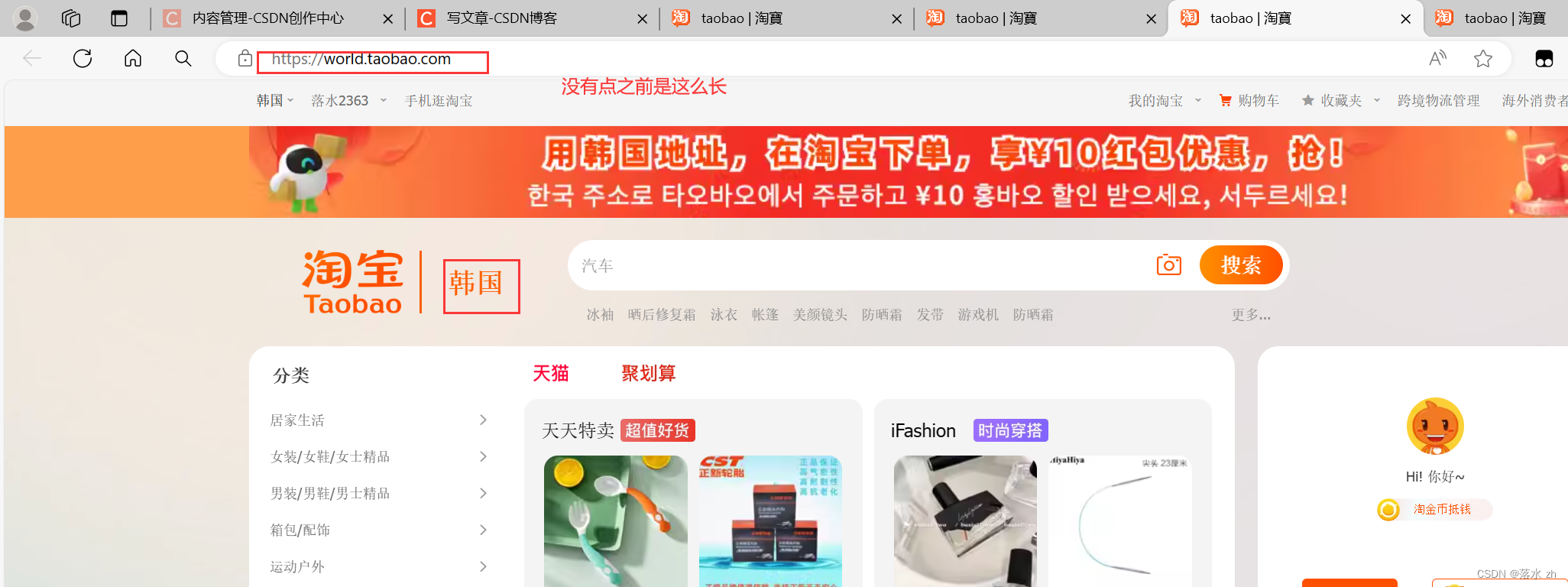
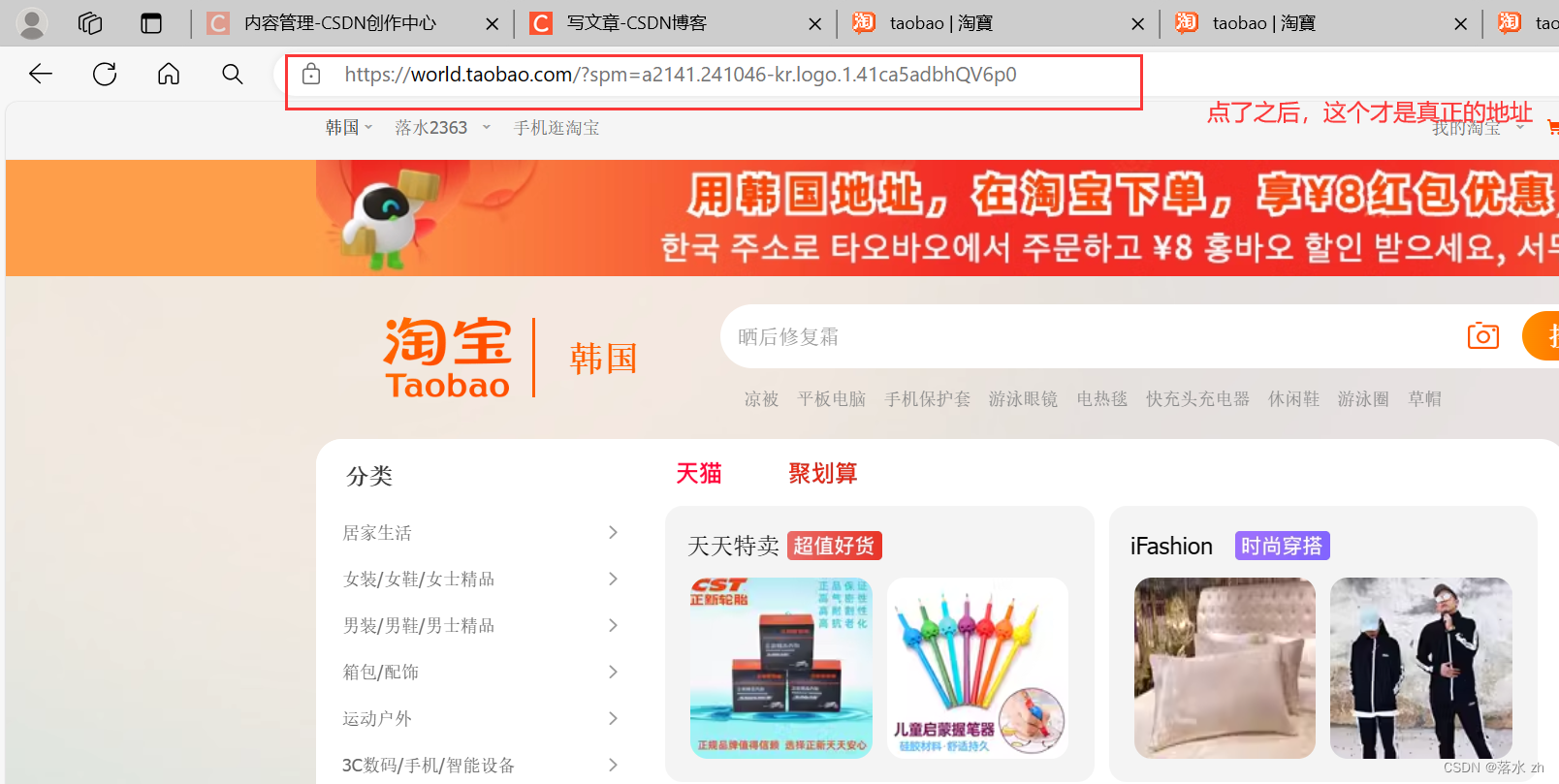
我们还可以切换地址到韩国,访问韩国的淘宝(把url地址换为韩国的,同时cookie也换成韩国的):
import requests
from urllib.parse import unquote
import urllib.parse# 打开txt文件并读取内容
url = 'https://world.taobao.com/?spm=a2141.241046-kr.logo.1.41ca5adbMdFW4f' # 地址换为韩国的
with open('C:\\Users\\luoshui\\Desktop\\cookie.txt','r',encoding='utf-8') as file:cookie_str = file.read().strip() # 读取内容并去除两端的空白字符decoded_cookie_str = unquote(cookie_str)# 使用分号将字符串分割成单独的Cookie
decoded_cookie_str = decoded_cookie_str.split(';')# 创建一个字典来存储Cookie键值对
cookies_dict = {}# 遍历分割后的Cookie列表,并添加到字典中
for cookie in decoded_cookie_str:# 去除每个Cookie两端的空格,并使用等号分割键和值key, value = cookie.strip().split('=', 1)# 在循环内解码值value = urllib.parse.quote(value.encode('utf-8')).replace('%3B', ';').replace('%3D', '=')# 将Cookie添加到字典中cookies_dict[key] = value# 打印分割后的Cookie字典
print(cookies_dict)# 发起请求
response = requests.get(url, cookies= cookies_dict)# 检查请求是否成功
if response.status_code == 200:# 请求成功,可以处理响应内容print("请求成功!")print(response.text) # 打印网页的HTML内容
else:# 请求失败,打印错误信息print(f"请求失败,状态码:{response.status_code}")
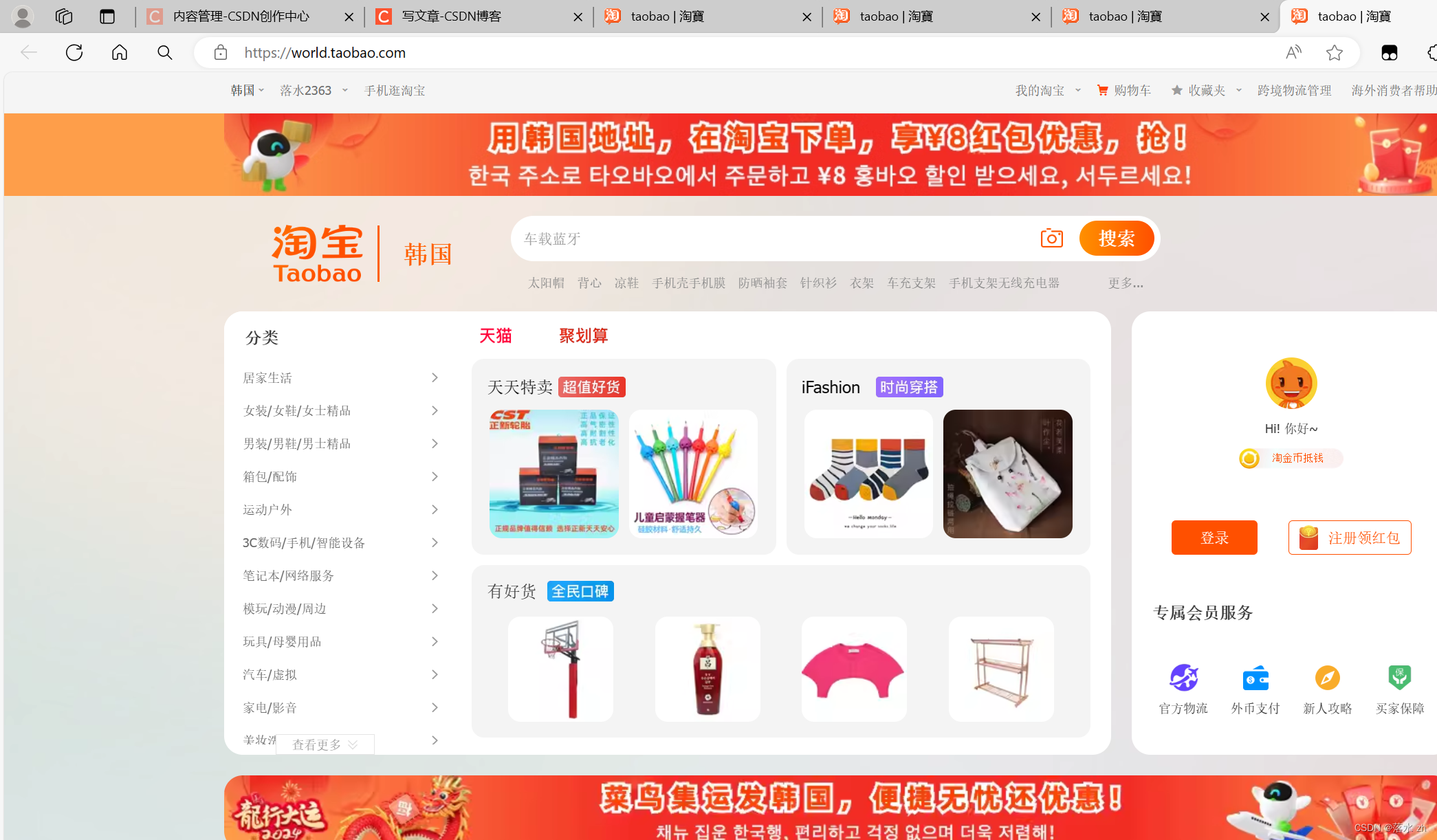
如果不行,大家记得点一下“淘宝”旁边的名字: