大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用26-关于Fast-R-CNN模型的应用场景,Fast-R-CNN模型结构介绍。Fast R-CNN是一种深度学习模型,主要用于目标检测任务,尤其适用于图像中物体的识别与定位。该模型在基于区域的卷积神经网络(R-CNN)系列中具有重要地位,其设计旨在提升检测速度和效率。
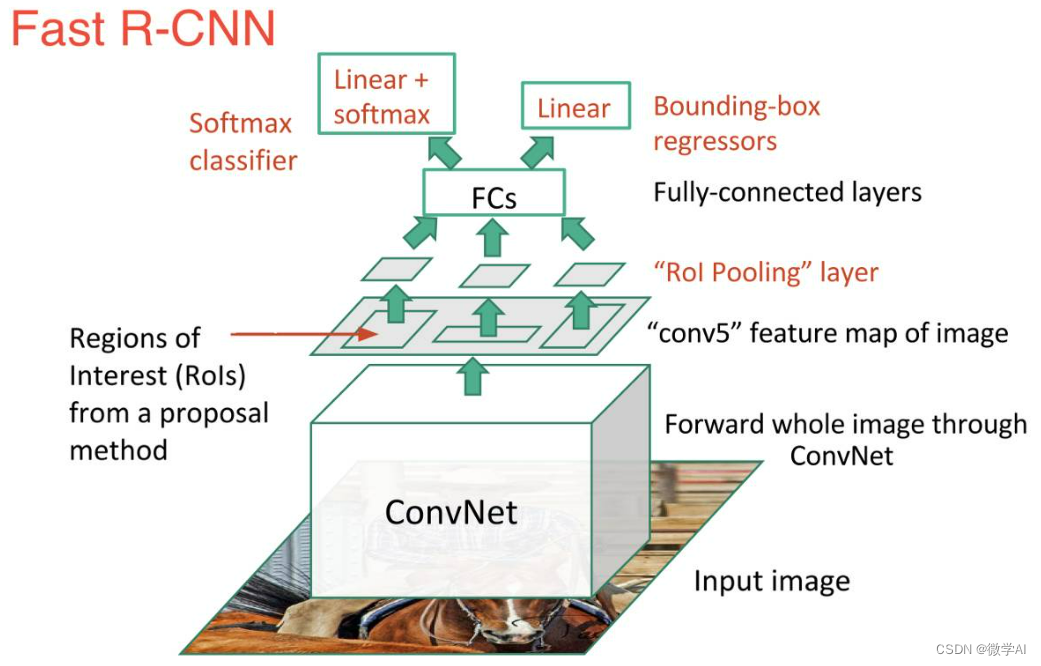
Fast R-CNN模型结构主要包含四个核心部分:首先,对输入图像进行预处理,通过一个预先训练好的卷积神经网络(如VGG或ResNet)提取特征图;其次,使用RoI(Region of Interest)池化层对候选区域进行固定尺寸的特征提取;然后,将这些区域特征送入全连接层进行分类和边界框回归预测;最后,通过多任务损失函数同时优化分类和定位精度。
相比于传统的R-CNN,Fast R-CNN的主要改进在于它仅对整张图像进行一次卷积操作,大大减少了计算量,提高了运行速度。此外,Fast R-CNN的端到端训练方式也使得模型更为高效,从而在实际应用中,如视频监控、自动驾驶、图像检索等领域展现出优越性能。
文章目录
- 一、应用场景介绍
- 计算机视觉任务
- 实时目标检测
- 大规模数据集处理
- 二、Fast-R-CNN模型结构详解
- 整体架构概述
- 特征提取层
- 区域提议网络(RPN)
- RoI池化层
- 多任务损失函数
- 三、模型的数学原理
- 四、模型的代码实现
- 五、总结
一、应用场景介绍
计算机视觉任务
计算机视觉(Computer Vision)是一种科技领域,它使计算机和软件系统能够从图像和视频中获取信息并进行理解,就像人类通过眼睛观察世界一样。这一技术涉及图像处理、机器学习和深度学习等多个领域,旨在让机器“看”并理解看到的内容,进而做出决策或执行特定任务。
在实际应用中,计算机视觉涵盖了多种任务,例如图像分类(识别图片中的物体或场景)、目标检测(在图片中定位并识别特定对象如人脸、车辆等)、图像分割(将图像的不同部分标记出来,如区分天空、道路、行人等)、动作识别(识别人体或其他对象的动作行为)、三维重建(通过二维图像推断三维空间信息)以及光学字符识别(OCR,识别图像中的文字)等。
生活中的一个生动例子是智能手机的人脸解锁功能。这项技术背后就运用了计算机视觉的面部识别技术,首先通过手机摄像头捕捉到用户的面部图像,然后通过算法对图像进行预处理、特征提取和比对,从而实现对用户身份的精准识别。这就是计算机视觉在日常生活中的具体应用,它使得我们的设备更加智能且安全,大大提升了用户体验。此外,无人驾驶汽车也是计算机视觉的重要应用场景,通过实时分析车载摄像头捕获的道路环境图像,识别行人、车辆、交通标志等关键元素,为车辆自主驾驶提供决策依据。
实时目标检测
实时目标检测是一种计算机视觉技术,主要用于在视频流或连续图像中实时地定位和识别特定对象或目标。该技术通过深度学习模型如YOLO(You Only Look Once)、Faster R-CNN等进行训练,能够在大量数据集上学习到不同类别物体的特征,并在新的输入图像中迅速找出这些物体的具体位置和类别。其工作流程包括图像预处理、特征提取、候选区域生成、分类与回归等步骤,实现实时、准确的目标检测。
生活中的一个生动例子是自动驾驶汽车。车辆上的摄像头会持续捕捉周围环境的实时影像,实时目标检测系统则在此过程中扮演关键角色。例如,当车辆行驶在路上时,系统能够快速检测并识别出前方的行人、自行车、其他车辆、交通标志等目标,精确判断它们的位置、大小和运动状态,从而帮助车辆做出合理的行驶决策,如减速避让、保持安全距离等。这种技术极大地提高了驾驶的安全性和智能化程度,为实现全自动驾驶提供了核心技术支撑。
大规模数据集处理
在大数据时代,大规模数据集处理是指对包含海量信息的数据集合进行有效、高效的管理和分析的过程。这一过程涵盖了数据的获取、清洗、整合、存储、索引、查询、计算和挖掘等多个环节。例如,互联网公司每天都会产生数以亿计的用户行为记录,如浏览历史、购买记录、搜索关键词等,这就构成了一个大规模数据集。通过运用分布式计算框架(如Hadoop、Spark)、云计算平台以及各种数据分析工具,我们可以对这些数据进行深度分析,发现用户的消费习惯、兴趣偏好等有价值的信息,进而优化产品设计、提升用户体验,甚至预测市场趋势。
假设你是一家大型电商平台的运营人员,平台上每天有数百万用户进行购物、浏览商品等操作,这就形成了一个庞大的数据集。你需要处理这个大规模数据集来了解用户的购物行为模式,比如什么时间段购买特定商品的人最多,哪些商品经常被一起购买等。通过使用大数据处理技术,你可以快速准确地从海量数据中提取出这些信息,然后制定相应的营销策略,比如在购买高峰时段推送相关商品广告,或者将经常一起购买的商品组合成优惠套餐,从而提高销售额,增强用户粘性。这就是大规模数据集处理在现实生活中的应用实例。
二、Fast-R-CNN模型结构详解
整体架构概述
Fast R-CNN是一种深度学习目标检测算法,其整体架构主要包含以下几个部分:
-
特征提取阶段:首先,将输入图像通过预训练的卷积神经网络(如VGG或ResNet)进行前向传播,得到整个图像的深度特征图。这个阶段的主要目的是从原始图像中提取高层次、抽象且具有辨别性的特征。
-
区域提议网络(Region Proposal Network, RPN):在特征图上并行滑动窗口生成一系列候选框(Anchor Boxes),每个候选框会经过一个共享全连接层预测两类得分(物体存在与否的概率)和四个坐标偏移量(回归修正候选框位置)。RPN能快速生成高质量的物体候选区域。
-
RoI池化层(Region of Interest Pooling, RoIPooling):对每个候选框在特征图上进行RoI池化操作,将不同大小和宽高的候选框映射到固定尺寸的特征向量,以便于后续分类和定位。
-
分类与定位阶段:将RoI池化后的特征向量送入两个全连接层,第一个全连接层用于类别分类,输出每个候选框属于各个类别的概率;第二个全连接层用于边界框回归,进一步精确调整候选框的位置以匹配物体的真实边界。
假设我们正在设计一个智能相册系统,需要自动识别照片中的物体。Fast R-CNN就像一位高效的“照片分析员”,首先会对每张照片进行深入分析(特征提取),找出可能包含物体的区域(RPN生成候选框),然后对这些区域进行精细裁剪和标准化处理(RoI池化),最后判断裁剪出的部分是哪种物体(分类),并精确标定物体在照片中的位置(边界框回归)。这样,无论照片中物体的大小、位置如何变化,系统都能准确地识别和定位它们。
特征提取层
在Fast R-CNN模型中,特征提取层是整个网络的基础部分,它主要负责从输入图像中抽取有意义的特征信息。这一层通常采用预训练的深度卷积神经网络(如VGG16或ResNet)作为backbone,通过一系列卷积和池化操作,逐步将原始图像转化为多层次、多尺度的特征图。这些特征图不仅保留了图像的空间结构信息,还蕴含了丰富的语义信息。
具体来说,特征提取层首先通过一系列卷积层对输入图像进行滤波操作,每个滤波器就像一个探测器,可以识别图像中的特定模式或特征(如边缘、纹理、形状等)。随着网络深度的增加,探测器能够识别的特征越来越抽象和复杂,例如从简单的线条逐渐过渡到人脸、车辆等高层语义特征。
假设我们想要从一张包含各种水果的图片中快速找到苹果。特征提取层就像是一个经验丰富的“挑拣员”,他首先通过“初级筛选”(浅层卷积)找出所有圆形且颜色鲜艳的对象;然后通过“精细辨识”(深层卷积)进一步判断这些对象是否具有苹果特有的特征,如茎部、斑点等。最终,特征提取层将整幅图像转化为了富含苹果特征的“线索图”,为后续的目标检测提供关键信息。
区域提议网络(RPN)
Fast R-CNN是一种深度学习目标检测算法,其中区域提议网络(Region Proposal Network, RPN)是其核心组件之一。RPN与主干网络共享卷积特征图,它能够在一张图像上生成一系列可能包含物体的候选框(region proposals)。
在Fast R-CNN中,RPN是一个全卷积网络,它直接在整张图像的特征图上滑动小窗口,并对每个位置预测多个锚框(Anchor boxes)的偏移量以及对应的物体存在概率。每个锚框具有不同的尺寸和宽高比,以覆盖各种形状和大小的物体。通过softmax分类器判断锚框内是否包含物体,同时利用bounding box回归修正锚框的位置,从而生成高质量的候选框。
假设你正在一个超市的监控视频中寻找偷窃行为,RPN就像是你的“快速扫描仪”。它首先在整个画面中快速移动,对每一小块区域进行分析,这些小块就像不同大小和形状的“锚框”。对于每个锚框,它会判断这个区域内是否存在人或物体(即分类任务),并精确调整这个框的位置和大小以便更准确地包围住人或物体(即回归任务)。这样,RPN就能从整个画面中筛选出可能包含偷窃行为的候选区域,为后续的详细审查(Fast R-CNN的分类和边界框精修阶段)提供线索。
RoI池化层
在深度学习领域,Fast R-CNN是一种用于目标检测的卷积神经网络模型,其中的关键组件之一是Region of Interest (RoI) Pooling层。
RoI Pooling层的主要功能是在整个图像上对预选的区域进行特征提取和尺寸规范化。具体来说,它接收从Selective Search或RPN(区域提议网络)生成的一系列候选框(RoIs),以及经过卷积层处理后的特征图作为输入。对于每个候选框,RoI Pooling层将其映射到特征图上,并将该区域划分为固定大小的小格子(例如7x7)。然后,对每个小格子内的像素值进行最大值池化操作,从而得到固定尺寸的特征向量,这一过程确保了不论原始候选框的尺寸如何变化,输出的特征始终具有统一的维度,便于后续全连接层的处理。
假设你正在为一张包含多个物品的大照片制作拼贴画,每张小拼贴代表一个特定的物体(即RoI)。首先,你已经通过某种方法(如手动选择或智能算法识别)确定了要裁剪的各个物品区域。然后,你需要将这些不同大小、形状的区域转化为相同尺寸的小图片以适应你的拼贴模板(即RoI Pooling)。无论原物品图片大小如何,你都会将它们分割成同样数量的小块,并从每个小块中选取最突出的颜色或特征,这样就能保证所有拼贴都能完美地放入模板中,且保留了各自的核心特征信息。这就是RoI Pooling层在Fast R-CNN模型中的作用。
多任务损失函数
Fast R-CNN是一种深度学习模型,主要用于目标检测任务,其核心创新在于对区域提议网络(RPN)生成的候选框进行特征提取和分类回归一步到位,极大地提升了处理效率。在模型结构中,它首先将整张图片输入预训练的卷积神经网络以提取特征图,然后对于每个候选框,通过RoI Pooling层将其映射到固定尺寸的特征向量,接着通过两个全连接层分别进行类别分类和边界框回归。
Fast R-CNN采用多任务损失函数,包括两个部分:分类损失和定位损失。分类损失通常采用softmax函数,用于判断候选框内物体属于哪个类别;定位损失则通常采用smooth L1损失函数,用于优化预测框与真实框之间的位置偏差。这两个任务同时进行训练,共同优化,相当于在同一个模型中既教它识别物体是什么,又教它精确找到物体的位置。
假设你是一位快递员,需要快速准确地从一堆包裹中找出特定客户的包裹并放到指定位置。Fast R-CNN就像是你的工作流程:首先,你通过扫描(特征提取)获取所有包裹的信息;然后,你重点关注几个可能的目标包裹(RoI Pooling);接着,你不仅判断这个包裹是否是客户所需的(分类损失,类似判断包裹上的标签),还要精确调整包裹摆放的位置使其正好落在指定区域(定位损失,类似微调包裹位置)。这样,通过一次操作,你就完成了识别和定位两个任务,高效且精准。
三、模型的数学原理
Fast R-CNN模型主要基于深度学习网络进行目标检测,其核心思想是在整个图像上进行一次前向传播,然后在RoI(Region of Interest)池化层对每个候选区域进行特征提取。
-
整体流程:
我写出主要的流程:
Input Image → Conv Layers → RoI Pooling → Fully Connected Layers → Classification and Regression Outputs \text{Input Image} \rightarrow \text{Conv Layers} \rightarrow \text{RoI Pooling} \rightarrow \text{Fully Connected Layers} \rightarrow \text{Classification and Regression Outputs} Input Image→Conv Layers→RoI Pooling→Fully Connected Layers→Classification and Regression Outputs -
RoI Pooling Layer:
RoI Pooling层将不同大小的候选区域映射到固定尺寸的特征图上。对于每个候选区域 R R R,它将特征图 f f f上的区域均匀划分为 h × w h \times w h×w个格子,并对每个格子内的像素取最大值作为该格子的值,可以表示为:
y i j = max x ∈ R i j f ( x ) y_{ij} = \max_{x \in R_{ij}} f(x) yij=x∈Rijmaxf(x) -
分类与回归:
Fast R-CNN使用两个全连接层分别进行类别预测和边框回归。类别预测通常采用softmax函数,对于 k k k类问题,第 i i i个RoI的类别预测概率分布可以表示为:
P ( c = k ∣ R i , W ) = e W k T x i ∑ j = 1 k e W j T x i P(c=k|R_i, W) = \frac{e^{W_k^T x_i}}{\sum_{j=1}^{k} e^{W_j^T x_i}} P(c=k∣Ri,W)=∑j=1keWjTxieWkTxi
其中, W W W是全连接层的权重, x i x_i xi是RoI i i i经过全连接层后的特征向量。边框回归则是通过线性回归模型调整候选框的位置,使其更精确地匹配目标物体的真实边界框,可以表示为:
b ^ i = W b T x i + b b \hat{b}_i = W_b^T x_i + b_b b^i=WbTxi+bb
以上为Fast R-CNN模型的部分数学原理,实际模型还包括更多细节和优化策略。
四、模型的代码实现
由于Fast R-CNN模型的实现相对复杂,涉及到图像预处理、特征提取、区域提议网络(RPN)、RoI池化层以及全连接层等多个部分,并且需要预先训练好的CNN模型(如VGG16或ResNet)作为基础网络,因此在这里我将提供一个简化版的Fast R-CNN模型构建和应用的基本框架示例。请注意,这个示例并不能直接运行,因为缺少了必要的数据预处理和模型训练部分,但你可以基于此扩展以满足实际需求。
import torch
import torch.nn as nn
import torchvision.models as models
from torchvision.ops import roi_alignclass FastRCNN(nn.Module):def __init__(self, num_classes=1000, backbone='resnet101', pretrained=True, roi_pool_size=(7, 7),spatial_scale=1.0):super(FastRCNN, self).__init__()# Load the pre-trained backboneif backbone == 'resnet101':self.backbone = models.resnet101(pretrained=pretrained)self.backbone = nn.Sequential(*list(self.backbone.children())[:-2])self.out_channels = 2048else:raise ValueError("Unsupported backbone - only 'resnet101' is supported")# ROI poolerself.roi_pool = roi_alignself.roi_pool_size = roi_pool_sizeself.spatial_scale = spatial_scale# Classifier and Bounding Box Regressorself.fc = nn.Linear(self.out_channels * roi_pool_size[0] * roi_pool_size[1], 4096)self.classifier = nn.Linear(4096, num_classes)self.bbox_regressor = nn.Linear(4096, num_classes * 4) # 4 coordinates for each classdef forward(self, x, rois):# Feature extractionfeature_maps = self.backbone(x)# ROI poolingpooled_features = self.roi_pool(feature_maps, rois, self.roi_pool_size,self.spatial_scale, aligned=True)# Flatten pooled featurespooled_features = pooled_features.view(pooled_features.size(0), -1)# Fully connected layersfc_output = self.fc(pooled_features)# Classification and regressionclass_logits = self.classifier(fc_output)bbox_reg = self.bbox_regressor(fc_output)return class_logits, bbox_reg# Initialize the model
model = FastRCNN(num_classes=2) # For simplicity, let's assume 2 classes including background# Dummy data
# Assuming input images are of shape (1, 3, 600, 600), and there are 2 ROIs provided
dummy_img = torch.randn(1, 3, 600, 600)
dummy_rois = torch.tensor([[0, 50, 50, 150, 150], [0, 100, 100, 200, 200]],dtype=torch.float32) # Format (batch_idx, x1, y1, x2, y2)# Put the model in evaluation mode
model.eval()# Forward pass
with torch.no_grad():class_logits, bbox_reg = model(dummy_img, dummy_rois)print("Class logits:\n", class_logits)
print("Bounding box regressions:\n", bbox_reg)运行结果:
Class logits:tensor([[-0.0050, -0.0124],[-0.0050, -0.0124]])
Bounding box regressions:tensor([[-0.0099, 0.0012, 0.0081, 0.0143, 0.0073, 0.0101, 0.0063, 0.0116],[-0.0099, 0.0012, 0.0081, 0.0143, 0.0073, 0.0101, 0.0063, 0.0116]])
五、总结
Fast R-CNN是一种应用于目标检测任务的深度学习模型,特别适合于图像中物体的识别与定位。该模型在R-CNN系列中占据关键位置,通过优化提升了检测效率和速度。模型架构主要包括四部分:首先利用预训练的卷积神经网络提取输入图像的特征图;接着采用RoI池化层对候选区域进行特征提取并统一尺寸;随后,将提取的区域特征输入全连接层以实现分类预测和边界框回归;最后,运用多任务损失函数同步优化分类准确度和定位精度。相较于传统R-CNN,Fast R-CNN的重大改进是仅对整幅图像执行一次性卷积运算,显著降低了计算负担,提升了运行效率,并采用端到端训练模式,使其在实际应用场景如视频监控、自动驾驶及图像检索等方面表现出卓越性能。