实验Mapreduce实例——排序(补充程序)
实验环境
Linux Ubuntu 16.04
jdk-8u191-linux-x64
hadoop-3.0.0
hadoop-eclipse-plugin-2.7.3.jar
eclipse-java-juno-SR2-linux-gtk-x86_64
实验内容
在电商网站上,当我们进入某电商页面里浏览商品时,就会产生用户对商品访问情况的数据 ,名为goods_visit1,goods_visit1中包含(商品id ,点击次数)两个字段,内容以“\t”分割,由于数据量很大,所以为了方便统计我们只截取它的一部分数据,内容如下:
- 商品id 点击次数
- 1010037 100
- 1010102 100
- 1010152 97
- 1010178 96
- 1010280 104
- 1010320 103
- 1010510 104
- 1010603 96
- 1010637 97
要求我们编写mapreduce程序来对商品点击次数有低到高进行排序。
实验步骤
1.切换到/apps/hadoop/sbin目录下,开启Hadoop。
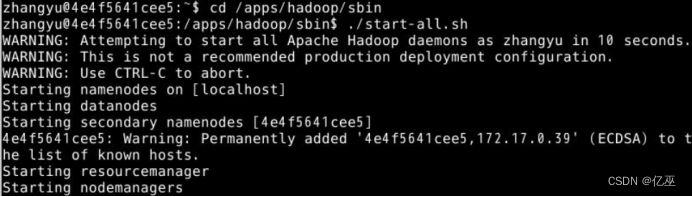 |
2.在Linux本地新建/data/mapreduce3目录。
![]()
- 在Linux中切换到/data/mapreduce3目录下,用wget命令从http://10.2.208.188:60000/allfiles/mapreduce3/goods_visit1网址上下载文本文件goods_visit1。
 |
然后在当前目录下用wget命令从http://10.2.208.188:60000/allfiles/mapreduce3/hadoop2lib.tar.gz网址上下载项目用到的依赖包。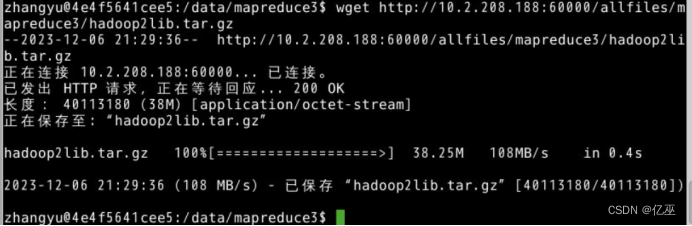
将hadoop2lib.tar.gz解压到当前目录下
首先在HDFS上新建/mymapreduce3/in目录,然后将Linux本地/data/mapreduce3目录下的goods_visit1文件导入到HDFS的/mymapreduce3/in目录中。

- 项目jar包等已就绪
 |
6.填充
Map
num.set(Integer.parseInt(arr[1]));num为获取的第一列,并且设置为整形
goods.set(arr[θ]);Goods为商品名,是获取的第零列
context.write(num,goods);写入设置数量为key,商品名为value,因为后续要按照数量key排序
 |
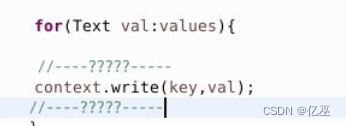
Reduce
就直接填写key value就好
 |
Main
写入路径为hdfs路径下所创的数据goods_visit1,输出路径也要记得改成相应创造的mapreduce3工作目录下的out
 |
运行查看结果
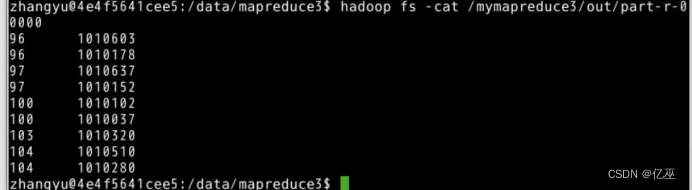 |
7.
实验Mapreduce实例——平均数(补充程序)
实验环境
Linux Ubuntu 16.04
jdk-8u191-linux-x64
hadoop-3.0.0
hadoop-eclipse-plugin-2.7.3.jar
eclipse-java-juno-SR2-linux-gtk-x86_64
实验内容
现有某电商关于商品点击情况的数据文件,表名为goods_click,包含两个字段(商品分类,商品点击次数),分隔符“\t”,由于数据很大,所以为了方便统计我们只截取它的一部分数据,内容如下:
商品分类 商品点击次数
- 52127 5
- 52120 93
- 52092 93
- 52132 38
- 52006 462
- 52109 28
- 52109 43
- 52132 0
- 52132 34
- 52132 9
- 52132 30
- 52132 45
- 52132 24
- 52009 2615
- 52132 25
- 52090 13
- 52132 6
- 52136 0
- 52090 10
- 52024 347
要求使用mapreduce统计出每类商品的平均点击次数
实验步骤
1.切换到/apps/hadoop/sbin目录下,开启Hadoop。
 |
2.在Linux本地新建/data/mapreduce4目录。
![]()
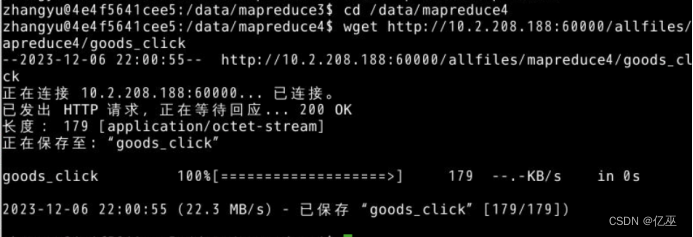
- 在Linux中切换到/data/mapreduce4目录下,用wget命令从http://10.2.208.188:60000/allfiles/mapreduce4/goods_click网址上下载文本文件goods_click。
 |
然后在当前目录下用wget命令从http://10.2.208.188:60000/allfiles/mapreduce3/hadoop2lib.tar.gz网址上下载项目用到的依赖包。
 |
将hadoop2lib.tar.gz解压到当前目录下
 |
- 首先在HDFS上新建/mymapreduce3/in目录,然后将Linux本地/data/mapreduce3目录下的goods_visit1文件导入到HDFS的/mymapreduce3/in目录中。
 |
- 项目jar包等已就绪
- 填充语句
Map
String line=value.toString();保证数据都是string型
String arr[]=line.split("\t");按\t拆分
newkey.set(arr[0]);设置第一列为key,即商品类别为key
Intwritable num=new Intwritable();新建可写入的整型,便于后续记录次数的
num.set(Integer.parseInt(arr[1]));设置第一列为values,即点击次数context.write(newKey,num);
 |
REDUCE
使用val.get()数值加入n中即总次数,然后除以个数,得到均值
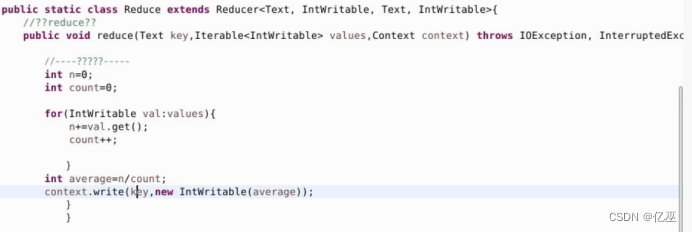
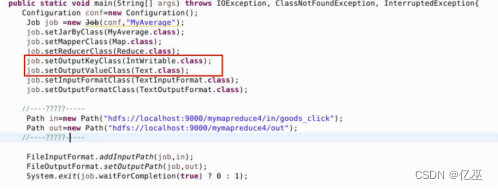
新建一个工作任务,使用map和reduce等类,值得注意的是输出的key为商品类别,是text类型,而输出平均值是可写的整型,然后写入路径为hdfs路径下所创的数据goods_click,输出路径也要记得改成相应创造的mapreduce工作目录下的out
 |
运行查看结果
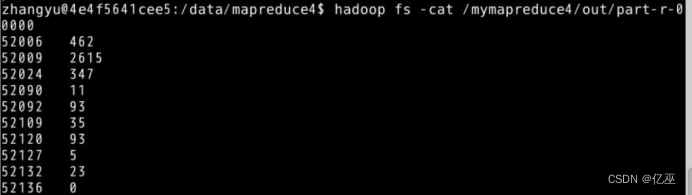 |
遇到的困难和解决方法:
如图所示输出的key和value写反导致不输出内容并再次运行会报错out目录已存在已有内容,需要进行删除再运行。
 |
![[Arduino学习] ESP8266读取DHT11数字温湿度传感器数据](https://img-blog.csdnimg.cn/img_convert/b60776036a0db552385d149d48c7bd4f.png)