来自:新智元

【导读】语言模型该怎么增强?
ChatGPT算是点燃了语言模型的一把火,NLP的从业者都在反思与总结未来的研究方向。

最近图灵奖得主Yann LeCun参与撰写了一篇关于「增强语言模型」的综述,回顾了语言模型与推理技能和使用工具的能力相结合的工作,并得出结论,这个新的研究方向有可能解决传统语言模型的局限性,如可解释性、一致性和可扩展性问题。

论文链接:https://arxiv.org/abs/2302.07842
增强语言模型中,推理意为将复杂的任务分解为更简单的子任务,工具包括调用外部模块(如代码解释器、计算器等),LM可以通过启发式方法单独使用或组合利用这些增强措施,或者通过演示学习实现。
在遵循标准的missing token预测目标的同时,增强的LM可以使用各种可能是非参数化的外部模块来扩展上下文处理能力,不局限于纯语言建模范式,可以称之为增强语言模型(ALMs, Augmented Language Models)。
missing token的预测目标可以让ALM学习推理、使用工具甚至行动(act),同时仍然能够执行标准的自然语言任务,甚至在几个基准数据集上性能超过大多数常规LM。
增强语言模型
大型语言模型(LLMs)推动了自然语言处理的巨大进步,并且已经逐步成为数百万用户所用产品的技术核心,包括写代码助手Copilot、谷歌搜索引擎以及最近发布的ChatGPT。
Memorization 与Compositionality 能力相结合,使得LLM能够以前所未有的性能水平执行各种任务,如语言理解或有条件和无条件的文本生成,从而为更广泛的人机互动开辟了一条实用的道路。
然而,目前LLM的发展仍然受到诸多限制,阻碍了其向更广泛应用场景的部署。比如LLMs经常提供非事实但看似合理的预测,也被称为幻觉(hallucinations),很多错误其实完全是可以避免的,包括算术问题和在推理链中出现的小错误。

此外,许多LLM的突破性能力似乎是随着规模的扩大而出现的,以可训练参数的数量来衡量的话,之前的研究人员已经证明,一旦模型达到一定的规模,LLM就能够通过few-shot prompting来完成一些BIG-bench任务。
尽管最近也有工作训练出了一些较小的LMs,同时还能保留一些大模型的能力,但当下LLMs的规模和对数据的需求对于训练和维护都是不切实际的:大型模型的持续学习仍然是一个开放的研究问题。
Meta的研究人员们认为这些问题源于LLMs的一个基本缺陷:其训练过程就是给定一个参数模型和有限的上下文(通常是n个前后的词),然后进行统计语言建模。
虽然近年来,由于软件和硬件的发展,上下文尺寸n一直在增长,但大多数模型仍然使用相对较小的上下文尺寸,所以模型的巨大规模是储存没有出现在上下文知识的一个必要条件,对于执行下游任务来说也很关键。
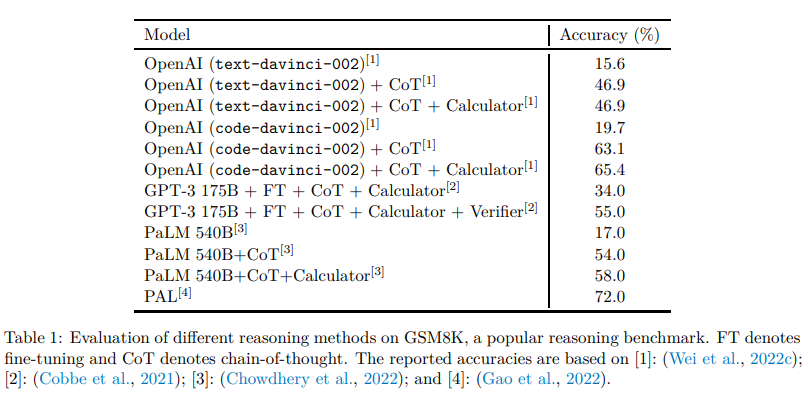
因此,一个不断增长的研究趋势就是用稍微偏离上述的纯统计语言建模范式的方式来解决这些问题。
例如,有一项工作是通过增加从「相关外部文件中提取的信息」计算相关度来规避LLM的有限语境尺寸的问题。通过为LMs配备一个检索模块,从数据库中检索出给定语境下的此类文档,从而实现与更大规模LM的某些能力相匹配,同时拥有更少的参数。
需要注意的是,现在产生的模型是非参数化的,因为它可以查询外部数据源。更一般的,LM还可以通过推理策略改善其上下文,以便在生成答案之前生成更相关的上下文,通过更多的计算来提升性能。
另一个策略是允许LM利用外部工具,用LM的权重中不包含的重要缺失信息来增强当前语境。尽管这些工作大多旨在缓解上述LM的缺点,但可以直接想到,更系统地用推理和工具来增强LM,可能会导致明显更强大的智能体。
研究人员将这些模型统称为增强语言模型(ALMs)。
随着这一趋势的加速,跟踪和理解众多模型变得十分困难,需要对ALMs的工作进行分类,并对有时出于不同目的而使用的技术术语进行定义。
推理Reasoning
在ALM的背景下,推理是将一个潜在的复杂任务分解成更简单的子任务,LM可以自己或使用工具更容易地解决。
目前有各种分解子任务的方法,例如递归或迭代,在某种意义上来说,推理类似于LeCun于2022年发表论文「通往自主机器智能的路线」中定义的计划。

论文链接:
https://openreview.net/pdf?id=BZ5a1r-kVsf
在这篇survey中,推理指的是提高LM中推理能力的各种策略,比如利用少量的几个例子进行step-by-step推理。虽然目前还没有完全理解LM是否真的在推理,或者仅仅是产生了一个更大的背景,增加了正确预测missing tokens的可能性。
鉴于目前的技术水平,推理可能是一个被滥用的说法,但这个术语已经在社区内广泛使用了。在ALM的语境中,推理的一个更务实的定义是在得出prompt的答案之前给模型更多的计算步骤。
工具Tool
对于ALM来说,工具是一个外部模块,通常使用一个规则或一个特殊的token来调用,其输出包含在ALM的上下文中。
工具可以用来收集外部信息,或者对虚拟或物理世界产生影响(一般由ALM感知):比如说文件检索器可以用来作为获取外部信息的工具,或者用机器臂对外部影响进行感知。
工具可以在训练时或推理时被调用,更一般地说,模型需要学习与工具的互动,包括学习调用其API。
行为Act
对于ALM来说,调用一个对虚拟或物理世界有影响的工具并观察其结果,通常是将其纳入ALM的当前上下文。
这篇survey中介绍的一些工作讨论了在网络中搜索(seraching the web),或者通过LMs进行机械臂操纵。在略微滥用术语的情况下,有时会把ALM对一个工具的调用表示为一个行动(action),即使没有对外部世界产生影响。
为什么要同时讨论推理和工具?
LM中推理和工具的结合应该允许在没有启发式的情况下解决广泛的复杂任务,即具有更好的泛化能力。
通常情况下,推理会促进LM将一个给定的问题分解成可能更简单的子任务,而工具则有助于正确地完成每个步骤,例如从数学运算中获得结果。
换句话说,推理是LM结合不同工具以解决复杂任务的一种方式,而工具则是避免推理失败和有效分解的一种方式。
两者都应该受益于对方,并且推理和工具可以放在同一个模块里,因为二者都是通过增强LM的上下文来更好地预测missing tokens,尽管是以不同的方式。
为什么要同时讨论工具和行动?
收集额外信息的工具和对虚拟或物理世界产生影响的工具可以被LM以同样的方式调用。
例如,输出python代码解决数学运算的LM和输出python代码操纵机械臂的LM之间似乎没有什么区别。
这篇综述中讨论的一些工作已经在使用对虚拟或物理世界产生影响的LM,在这种观点下,我们可以说LM有行动的潜力,并期望在LM作为自主智能体的方向上取得重要进展。
分类方法
研究人员将综述中介绍的工作分解上述三个维度,并分别介绍,最后还讨论了其他维度的相关工作。
对读者来说,应该记得,其中很多技术最初是在LM之外的背景下引入的,如果需要的话,尽可能查看提到的论文的介绍和相关工作。
最后,尽管综述专注于LLM,但并非所有的相关工作都采用了大模型,而是以LM的正确性为宗旨。
参考资料:
https://arxiv.org/abs/2302.07842
进NLP群—>加入NLP交流群